2026-06-29 23:31:24

When devs use AI to generate thousands of lines of unverified code, you risk a codebase slopocalypse. The review step becomes your team’s bottleneck, and the last thing standing between a subtle bug and production.
Greptile reviews each PR with full repo context and learns your team’s conventions over time from comments, reactions, and what gets merged. It flags real issues and suggests fixes that match your team, not generic best practices.
✅ Recently launched TREX runs your code, not just reads it. Greptile executes the change in a sandbox and returns screenshots, logs, and traces as proof of what actually broke.
✅ Review from your terminal. The Greptile CLI runs the same review locally, before you ever open a PR.
✅ Trusted by engineering teams at NVIDIA, Scale AI, and Brex.
✅ Now integrated with Claude Code: install via /plugin.
✅ Free for open source.
Even the most sophisticated AI agent in your stack starts every single message from a blank slate.
The model itself sees only the text placed in front of it at that exact moment, and the rest of the conversation lives outside its awareness entirely. Whatever continuity we feel when chatting with Claude or ChatGPT is something the surrounding platform is engineering on the model’s behalf, by inserting the right context back into every call. Once we understand this crucial distinction, the entire field of agent memory becomes a very different engineering problem from what it first appears to be.
In this article, we will try to understand how that architecture gets built, from the constraint that forces it to exist all the way to the tradeoffs that follow.
Disclaimer: This post is based on publicly shared details from various sources. Please comment if you notice any inaccuracies.
A call to a large language model follows a simple pattern. The system sends a prompt, the model returns a response, and the exchange concludes there. Each subsequent call, even one made a millisecond later, begins from a completely fresh slate. This is the API contract for every commercial LLM and reflects how transformers serve traffic.
See the diagram below:
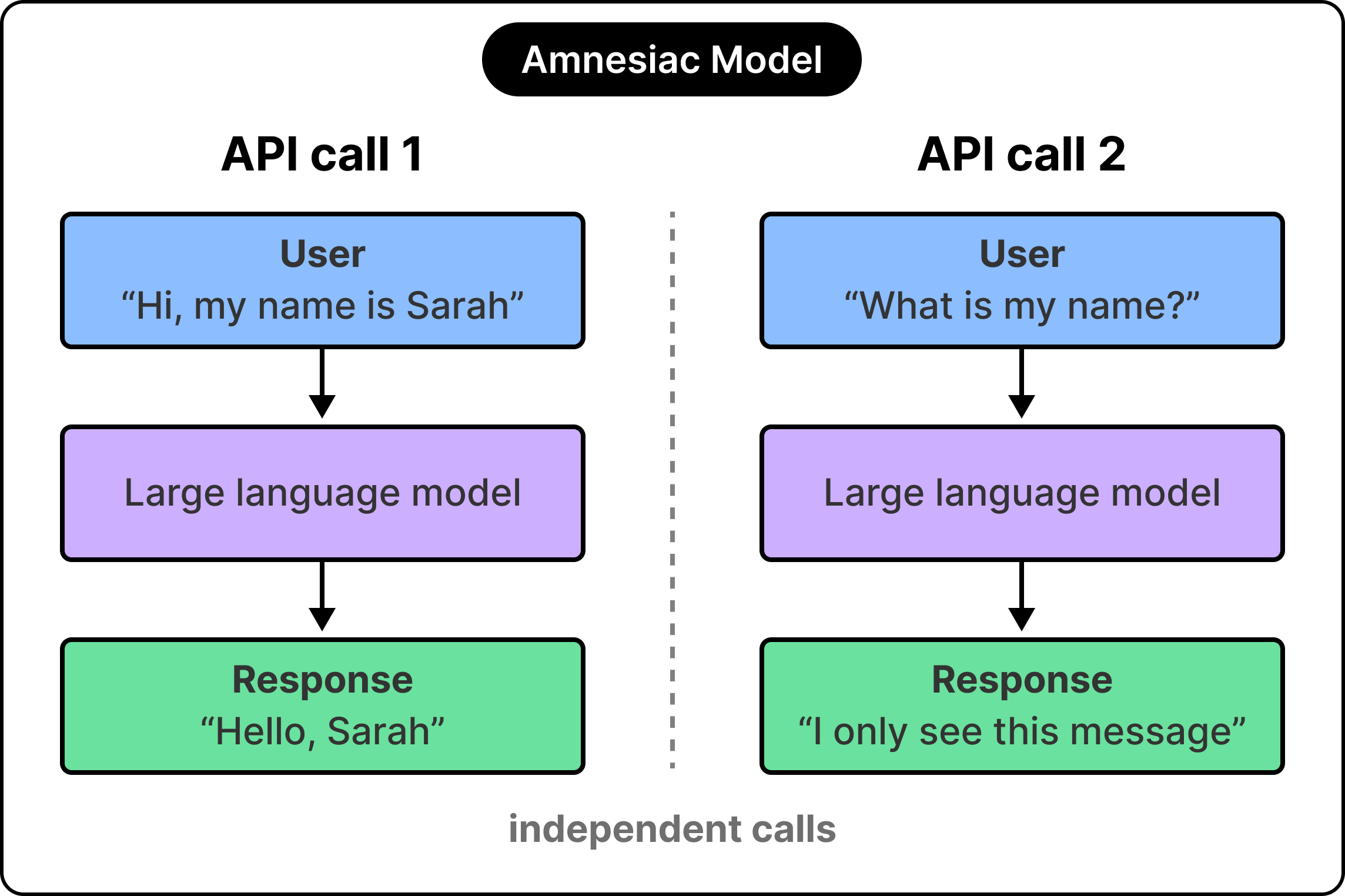
When we say things like “Claude remembers our conversation from yesterday,” we are describing a property of the product rather than a property of the actual model itself. The platform writes things down on the model’s behalf, then reads them back into the prompt at exactly the right moment, so the model can reason as if it had been there all along. The intelligence resides within the model itself, while the memory resides in the system surrounding it.
If the model itself works this way, the next question is whether we can solve the memory problem by writing everything into the model’s view on every call? The way this approach breaks gives us a better insight into how to solve this problem.
Every API call has a context window. It is basically the bounded slab of text that the model reads when generating its response. This includes the system prompt, the user’s current message, and anything else the developer has placed there. The model has full visibility into the contents of the window, while whatever sits outside it might as well live on a different machine.
See the diagram below:
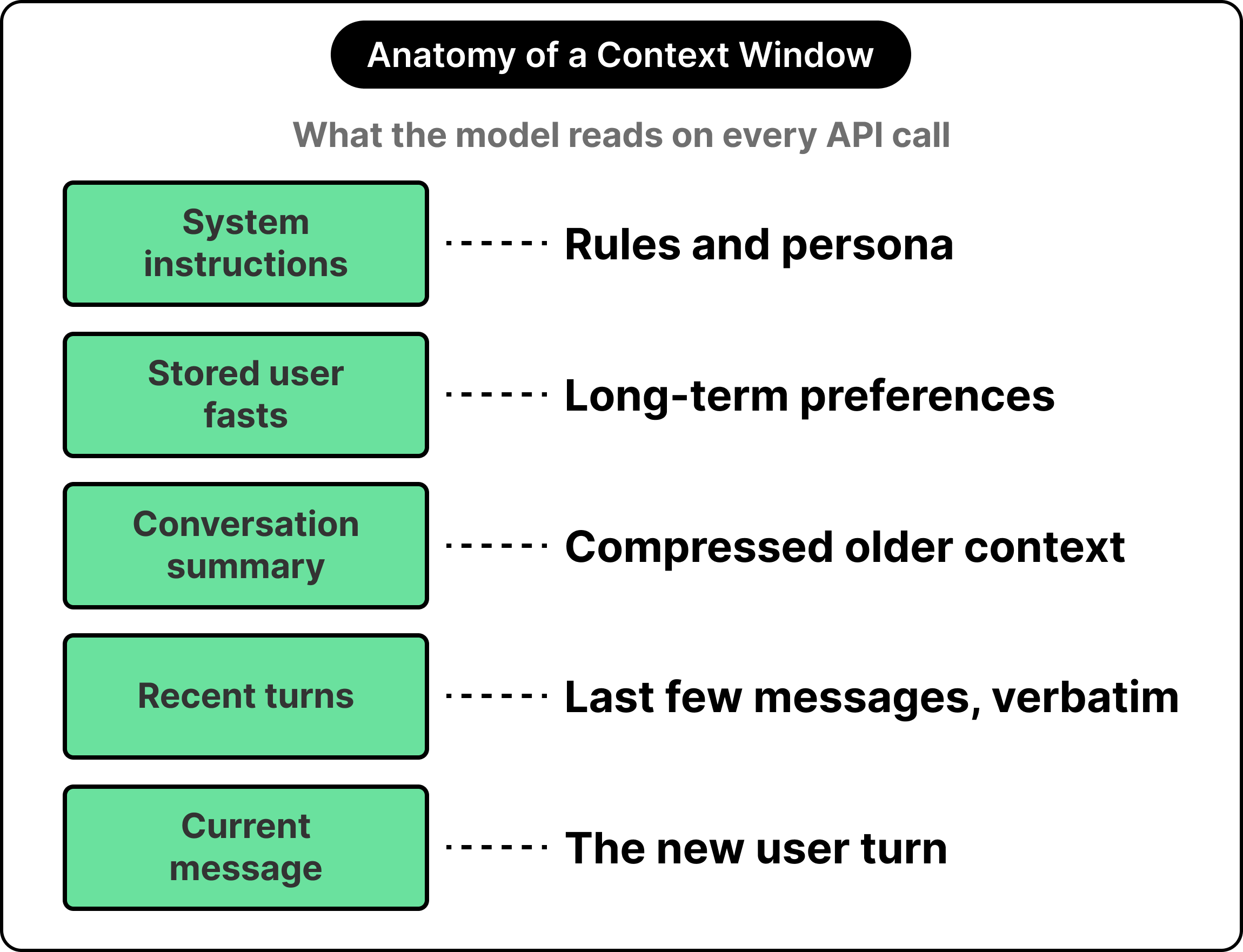
An obvious approach to memory involves writing the entire conversation history into the context window on every call. This works well for the first few turns of a chat. Once the conversation grows longer, however, three significant problems emerge at once:
The first problem is cost. Every token in the context window is paid for on each call, in both money and latency, so a linearly growing conversation produces a linearly growing bill. By message eighty, the system might be re-sending tens of thousands of tokens on every turn just to maintain continuity.
The second problem is latency. Larger contexts take longer to process, and a model that responds in two seconds on a short prompt may take ten or fifteen on one that has filled most of its window.
The third problem is the most counterintuitive of the three. The model’s attention degrades inside long contexts, and information placed in the middle of a long prompt is recalled less reliably than information at the beginning or the end. Researchers refer to this as the lost-in-the-middle effect.
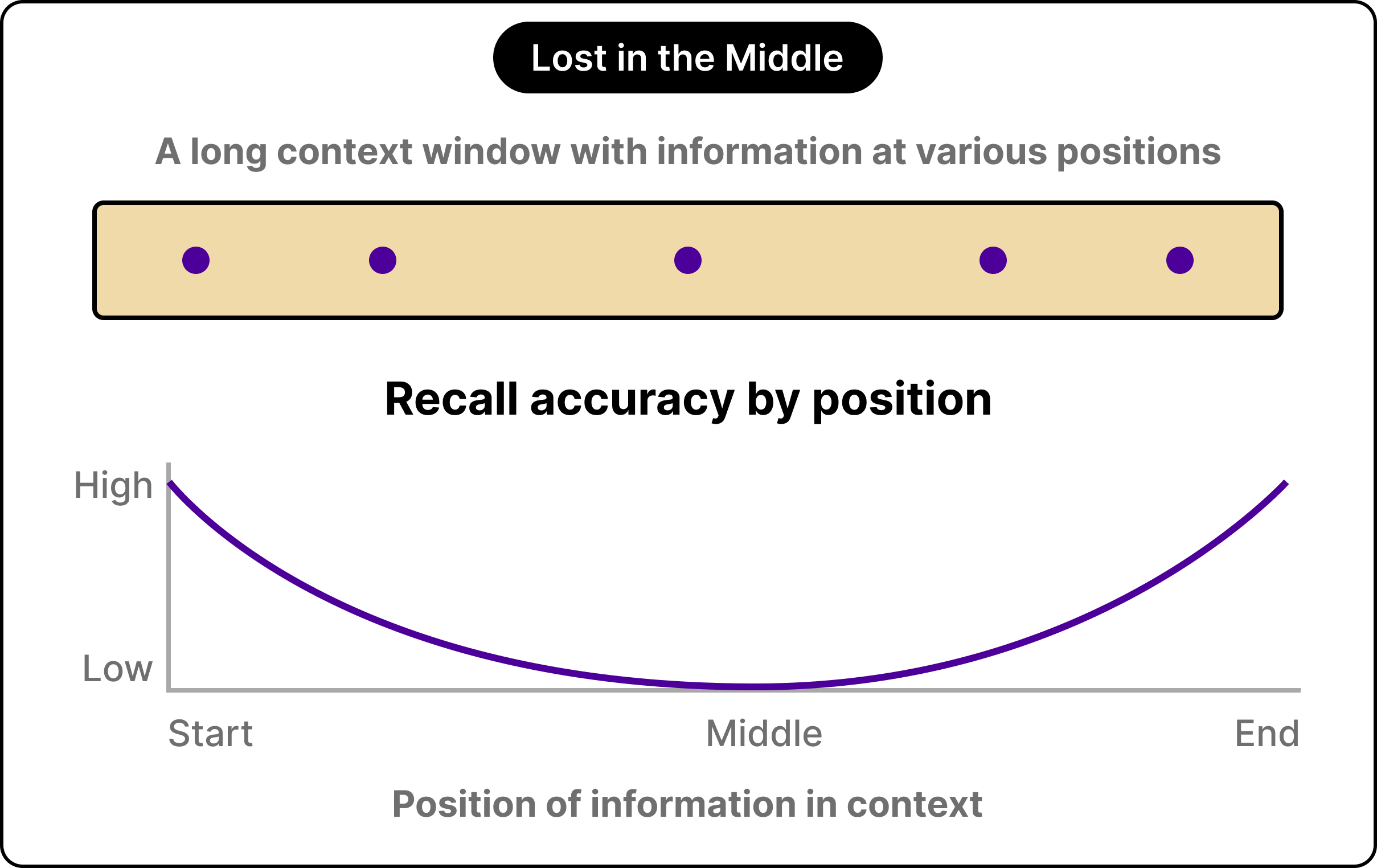
Bigger context windows feel like they should solve memory entirely. In reality, they expand the room while leaving the navigation problem fully intact. Important information can sit right inside the window and still get ignored by the model.
Since a bigger window alone is the wrong tool, we need an architecture that decides what belongs in the window at any given moment.

What happens when deterministic code hits the edge of its knowledge? In this live webinar, you’ll see a working plant health monitor built on Temporal’s entity workflow pattern where each plant is a long-running, crash-proof workflow that polls sensors, fires alerts, and falls back to GPT-4o only when the rules run out.
The architecture is clean: structured data first, AI second. The boundary is auditable. The state survives everything. Whether you’re building patient monitors, supply chain detectors, or any long-running process that occasionally needs a smarter answer, the patterns here translate directly.
Real production systems organize memory in tiers, each trading off speed of access, total capacity, and cost per token. The context window sits at the top, with progressively slower, larger, and cheaper stores below it.
The analogy to operating system memory is evident. Modern agent memory systems draw heavily on the way operating systems page data between fast RAM and slower disk, promoting and demoting information as its relevance rises and falls.
A typical four-tier hierarchy starts with the context window at the top, fast and tightly bounded, with every token expensive at scale. Below it sits short-term or session memory, holding recent activity that has yet to be summarized or evicted. Beneath that is the long-term store, where persistent facts, embeddings, and structured summaries live across sessions. At the bottom is the cold archive, used for rarely-accessed material kept for audit or future reference.
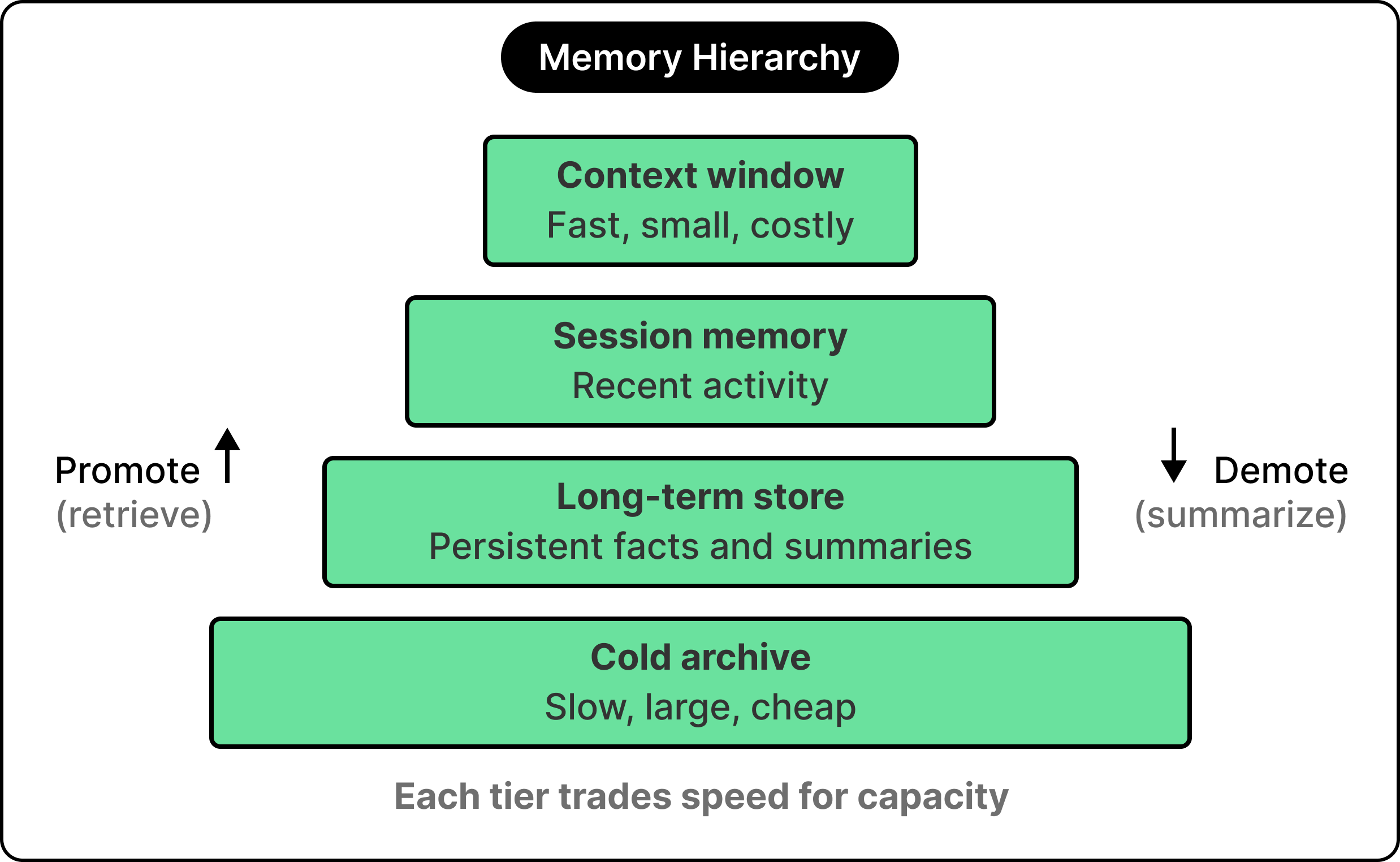
Information moves up and down this hierarchy as the agent works. A fact stated three sessions ago might be sitting in the long-term store, and the moment it becomes relevant, the system retrieves it and promotes it back into the context window. Conversely, when a session ends, the most useful parts of the context window get summarized and written down into the lower tiers.
ChatGPT’s memory feature uses a simple version of this idea. Stored user facts and summaries of recent conversations get prepended to every new prompt, while the current session occupies the working tier. The sophistication lies in what gets promoted to long-term memory in the first place, rather than in elaborate retrieval at read time.
A hierarchy describes where memory lives. The kinds of memory we are storing are a separate question, organized along a different axis.
The field has converged on four functional categories of agent memory, drawing on concepts from cognitive science adapted for language model agents:
Working memory holds whatever sits in the live context window for the current task. For example, if the agent is helping us debug a function right now, the function code and our recent messages occupy working memory. The moment this task ends, working memory clears.
Episodic memory holds records of specific past interactions, anchored in time. A statement like “Three days ago, this user asked about onboarding new engineers, and we discussed checklist templates” represents an episodic memory, capturing a particular event with its context.
Semantic memory stores facts and knowledge that stand independent of any specific interaction. Statements like “Adam prefers Python over JavaScript” and “his team uses GitHub Actions for CI” function as semantic memories, surviving across sessions and applying wherever they are relevant.
Procedural memory captures learned ways of doing things. If the agent has figured out that this user prefers a three-section format for status updates, that preference becomes procedural memory, and the next time a status update is requested, the agent applies the format automatically.
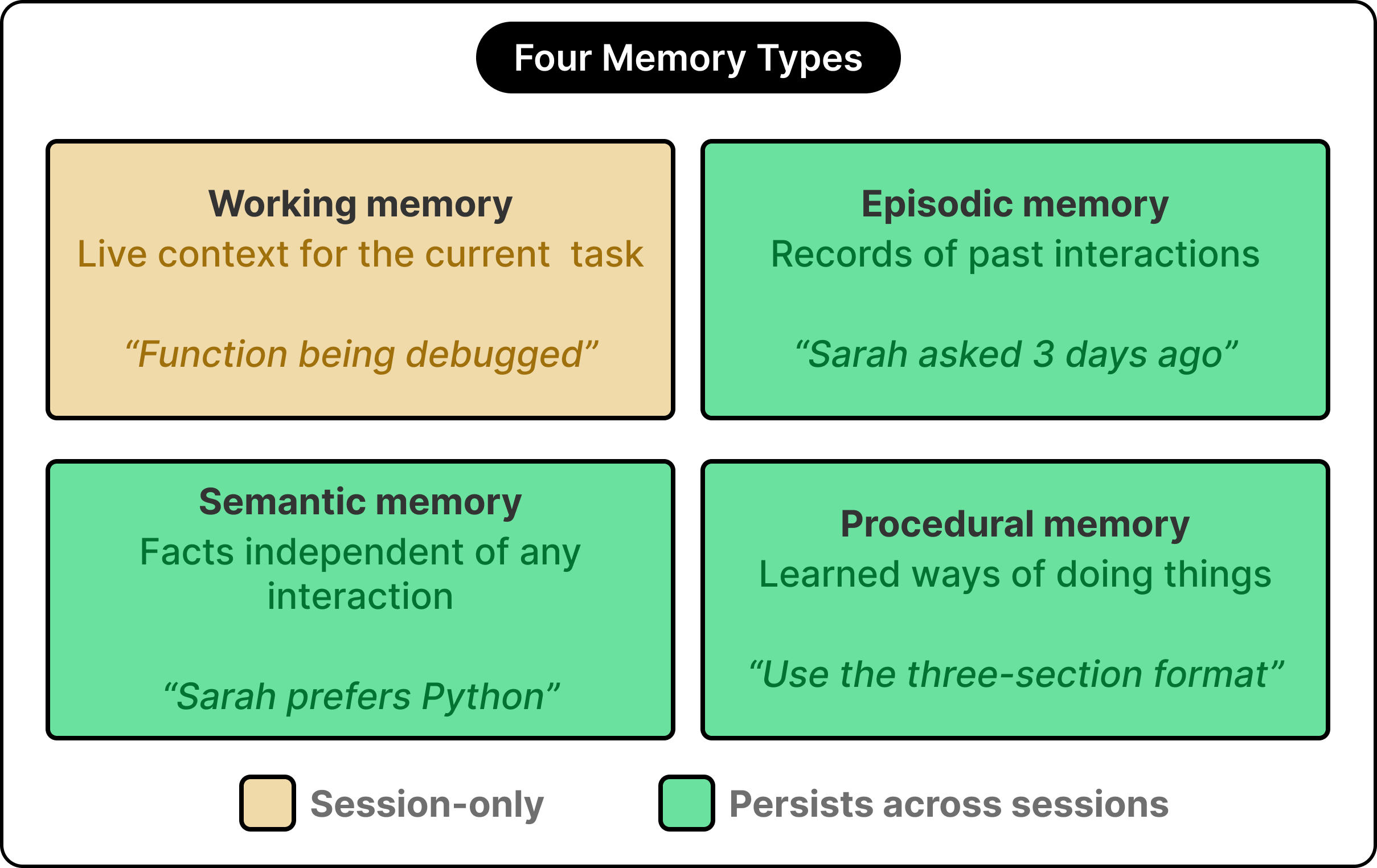
These four types are orthogonal to the hierarchy from the previous section.
A piece of semantic memory might live physically in the long-term store and get pulled into the context window the moment it becomes relevant. Most production agents implement at least three of these types, with the mix depending on what the agent is built to do. A customer support agent leans heavily on episodic and semantic memory, while a coding agent leans more on procedural memory. The right blend is a design choice rather than a fixed formula.
All of this still leaves one important question open.
How does the agent actually decide, on each turn, what to retrieve and place in the model’s view?
Storage can possibly be thought of as the easy half of agent memory. Writing a fact to a database or indexing a summary in a vector store are solved problems with mature tooling. The harder half is retrieval, which is the act of deciding on every new turn what belongs in the model’s awareness.
Retrieval is hard because it requires judgment about relevance, and relevance shifts from one message to the next. For example, the user’s preference for Python matters when they are asking about a new project, while that same preference fades in importance when they are asking about pizza recipes. A good retrieval system surfaces relevant items at exactly the moment they are useful, and leaves the rest sitting quietly in storage.
See the diagram below:
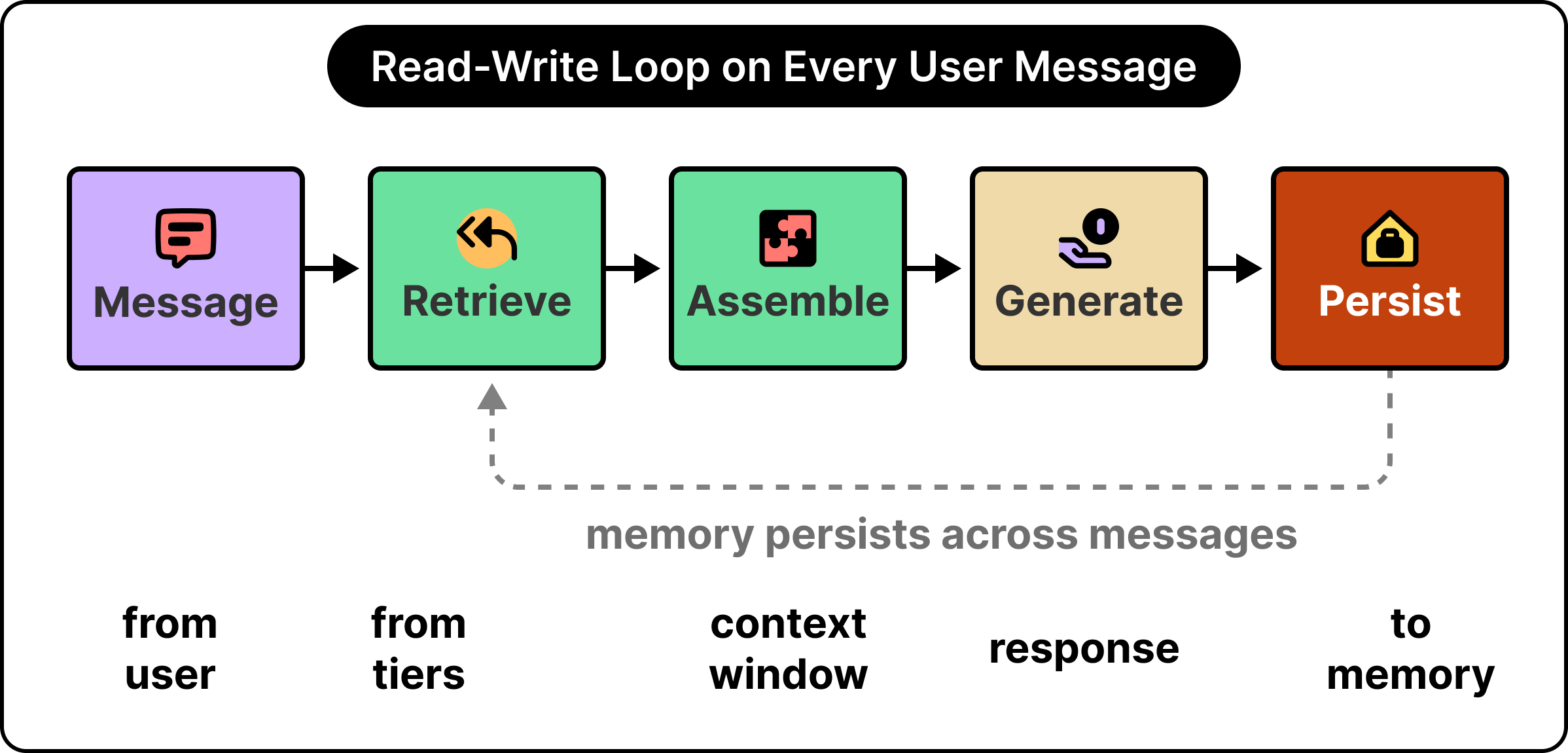
The full loop runs on every user message.
The user sends a message, and the system retrieves relevant items from each memory tier using a mix of keyword search, semantic similarity, and recency signals. It assembles a context window in a deliberate order, often placing the most important material near the beginning and the end where the model’s attention is strongest. The model runs and returns a response, after which the system writes part of the new exchange back into memory, often as a summary, sometimes with a decay score so that importance fades over time.
Consider two agents to see why retrieval matters so much.
The first has a perfect database of past interactions paired with a retrieval system that frequently picks the wrong record. The second has an empty memory store and operates only on what the user tells it in the current session. The second often outperforms the first, because it understands the bounds of what it can rely on, while the first surfaces stale or irrelevant information confidently and reasons on top of it as though it were ground truth.
In other words, memory failures in production are typically retrieval failures in disguise.
The memory architecture described above involves several tradeoffs that engineering teams must navigate carefully. Four stand out as particularly important:
Recency versus relevance: Do we retrieve the most recent items from memory, or the most semantically similar ones? Most systems do both, and blending them well is an ongoing engineering puzzle. Leaning too far on recency means the agent forgets useful older context, while leaning too far on relevance means the agent fixates on a strong-but-stale match.
Summarization versus fidelity: Compressing old context into summaries saves tokens, which makes everything cheaper and faster. The compression is also lossy, and the loss is uneven. Names, dates, and specific commitments get smoothed away in summarization, while general themes survive. The agent stays confident even after the precise detail has quietly disappeared.
Staleness: A fact that was true six months ago can be confidently wrong today. For example, the user who may have told the agent “I am a vegetarian” in 2024 might be eating non-vegetarian again in 2026. The memory system has only blunt heuristics for guessing that the world has moved on, so it keeps serving the old fact with full confidence. Staleness in high-relevance memories remains an open research problem.
Memory poisoning: Long-term memory is also a long-term attack surface. A subtly malicious instruction written into the store six months ago will sit there influencing every retrieval until somebody notices. The same property that makes memory useful, persistence, also makes it dangerous when the contents are wrong or hostile.
A memory system makes sense when the agent needs continuity across sessions or runs long-horizon tasks where context compounds. For one-shot tasks, it adds complexity beyond what the task requires.
Five core ideas from this article are as follows:
The model is stateless. Every API call begins from a fresh slate, and any continuity we observe is the work of the surrounding system rather than the model itself.
The context window is the model’s only surface of awareness. Writing everything into it fails for reasons of cost, latency, and degraded attention in long prompts.
Real systems organize memory in a hierarchy of tiers, with the context window at the top and progressively slower, larger, cheaper stores below it.
Different kinds of information call for different kinds of memory, with working, episodic, semantic, and procedural memory each serving a distinct purpose.
The main engineering problem in this area is retrieval, which is the question of what deserves to enter the model’s awareness on each new turn, with tradeoffs around staleness, summarization loss, and security.
The practical takeaway from all of this is simple.
The next time we see a product feature labeled “memory” or read about an agent that “remembers across sessions,” the right question moves away from “can the model remember this?” and toward “what does the memory architecture around this model actually do, and what tradeoffs has it accepted?”
References:
2026-06-27 23:30:44

If slow QA processes bottleneck you or your software engineering team and you’re releasing slower because of it — you need to check out QA Wolf.
QA Wolf’s AI-native service supports web and mobile apps, delivering 80% automated test coverage in weeks and helping teams ship 5x faster by reducing QA cycles to minutes.
QA Wolf takes testing off your plate. They can get you:
Unlimited parallel test runs for mobile and web apps
24-hour maintenance and on-demand test creation
Human-verified bug reports sent directly to your team
Zero flakes guarantee
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production.
With QA Wolf, Drata’s team of 80+ engineers achieved 4x more test cases and 86% faster QA cycles.
This week’s system design refresher:
RAG vs Graph RAG vs Agentic RAG
Redis Data Structures Every Engineer Should Know
API Security Best Practices
Design Patterns Cheat Sheet
The Testing Pyramid
RAG connects LLMs to your data and there are three different ways to do it.

Standard RAG
The query is converted into an embedding and matched against a vector database.
The top-K closest chunks are pulled out and passed to the LLM as context.
The LLM writes a grounded answer using only what was retrieved.
Graph RAG
The query is classified: specific questions route to local search, broad questions route to global search.
Local search: query embedded → vector DB finds matching entities → pipeline traverses across the knowledge graph collecting linked context → LLM synthesis final answer.
Global search: no vector search, no graph traversal → community reports loaded in batches → LLM scores each for relevance → top-ranked context → LLM synthesizes final response.
Agentic RAG
A reasoning agent reads the query, breaks it into sub-questions and picks the sources.
The context across multiple sources is retrieved, depending on the sub-query.
Another agent checks whether the retrieved context answers the question. If not, it re-retrieves.
Once satisfied, the final answer is synthesized by LLM based on the prompt.
Standard RAG is fast and cheap but if the wrong chunk is retrieved, the answer is wrong and nothing catches it.Use it when the answer lives in your documents and speed matters.
Graph RAG is expensive to build and slow to update. Use it for structured knowledge like legal, compliance, or biomedical data.
Agentic RAG is more capable and flexible but slower, expensive, and harder to debug. Use it when the question needs multi-step reasoning and self-correction.
Over to you: Which of these are you running in production?
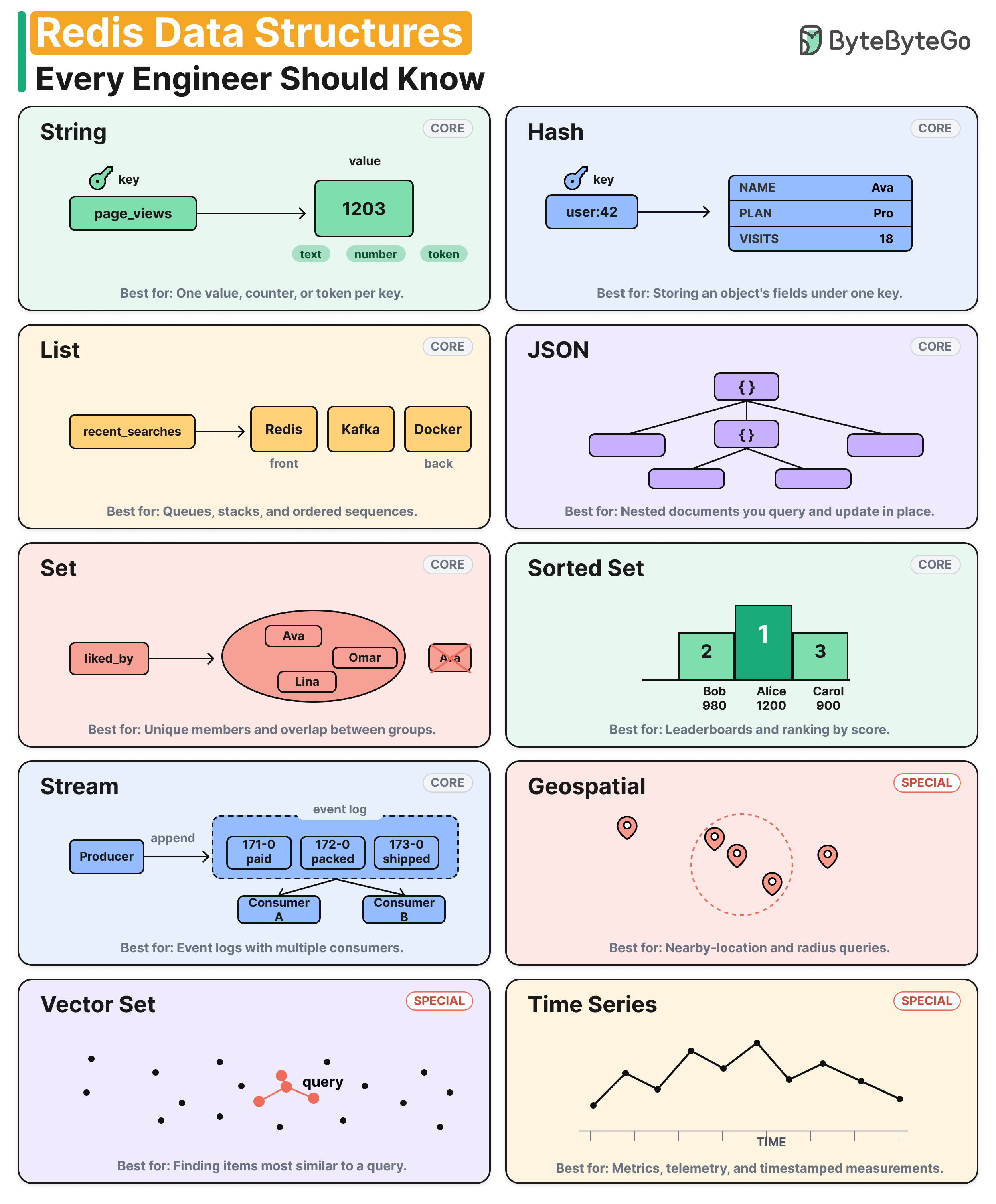
Strings store one value per key. They work for counters, session tokens, and cached payloads.
Hashes store an object's fields under one key. You can update one field without rewriting the rest.
Lists are ordered sequences with fast push and pop at both ends. They fit queues, feeds, and recent-item lists.
Sets hold unique members and support intersection, union, and difference. They cover tagging, follower overlap, and deduplication.
Sorted Sets rank members by a numeric score. They handle leaderboards, priority queues, and top-N or range-by-score queries.
Streams are an append-only log with consumer groups. Each consumer tracks its own position, and the server tracks unacknowledged messages.
JSON stores nested documents with JSONPath access. You can update a field deep in a document without read-modify-write.
Geospatial provides latitude/longitude indexes with radius and box queries. Under the hood it's a Sorted Set with geohash scores.
Vector Set runs approximate nearest-neighbor search over embeddings. It's the retrieval step in most RAG pipelines.
Time Series stores timestamped samples with built-in retention, downsampling, and labels. It fits metrics, telemetry, and IoT data.
Over to you: All ten are built-in as of Redis 8. Which one do you use most outside of caching?
Most API breaches happen because of broken authorization, leaked secrets, or missing rate limits. Let's look at some of the basics.

Use Modern OAuth/OIDC + MFA: PKCE for public clients, short-lived tokens, and step-up MFA for anything sensitive. Implicit and password grants should be dead by now.
Enforce Fine-Grained Authorization: Check object, function, and field-level permissions on every request. BOLA is still the top API vulnerability.
Minimize Scopes and Data: Give each client the smallest token scope and the least data it needs. Only return the fields the caller actually needs.
Encrypt Every Hop: TLS for external traffic and mTLS between services. If it crosses a network boundary, encrypt it.
Protect Secrets and Keys: Store signing keys in HSM-backed vaults. Rotate them.
Validate Requests with Schemas: Reject unknown fields, oversized payloads, and suspicious URLs at the gateway. Don't let bad input reach your business logic.
Rate Limit and Cap Resources: Quotas per user, payload size caps, and execution timeouts. Without these, one misbehaving client takes down your entire system.
Defend Sensitive Business Flows: Protect login, checkout, and OTP with anti-bot, idempotency keys, and step-up auth.
Control Outbound and Third-Party Calls: Allowlist where your API can call out to and block internal metadata endpoints. Your security is only as strong as your weakest integration.
Harden Config and Error Handling: Deny by default on CORS, methods, and debug endpoints. Return generic errors, never stack traces.
Inventory APIs and Versions: Track every endpoint, version, and shadow API. You can't secure what you don't know exists.
Log, Detect, and Respond: Push auth decisions and anomalies to a SIEM. Alert on 401 spikes before they become incidents.
Over to you: Which of these best practices is the hardest to enforce across your services?
The cheat sheet briefly explains each pattern and how to use it.

What's included?
Factory
Builder
Prototype
Singleton
Chain of Responsibility
And many more!


Testing is the backbone of reliable software. The Testing Pyramid is a widely accepted strategy for structuring tests into three key layers:
Unit Tests: These are the foundation of the pyramid. Unit tests are fast, isolated, and low-cost to write and maintain. They test individual functions, methods, or components.
Integration Tests: These tests validate interactions between components, such as APIs, databases, and external services. They are slower than unit tests and require more setup.
E2E Tests: These simulate real user flows from start to finish across the full system. They are expensive to write and maintain and tend to be slow to execute.
As you go up the pyramid, the cost of test development, execution, and maintenance increases.
Over to you: Which layer do you find most valuable in your testing strategy, and why?
2026-06-25 23:31:19
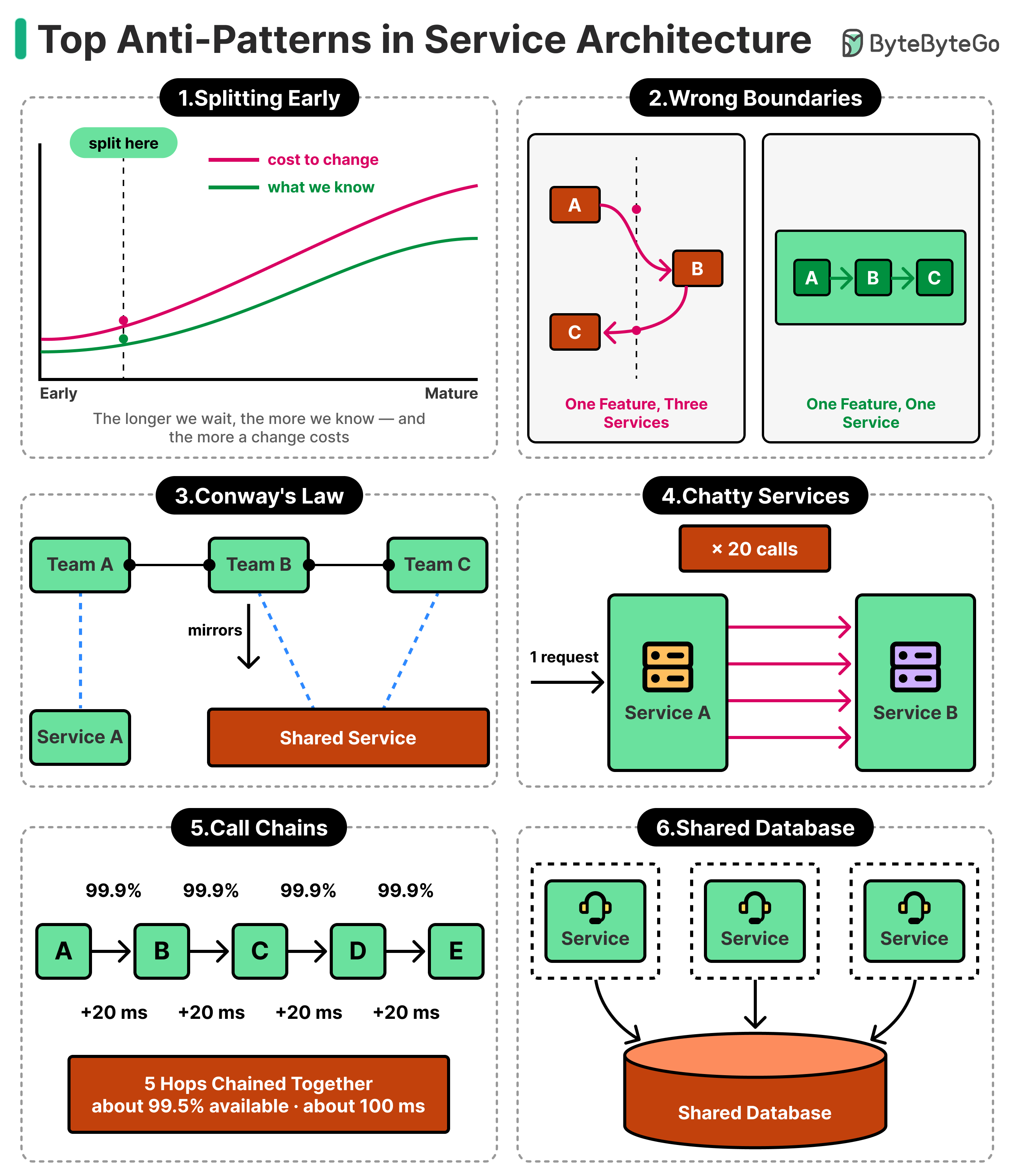
A service architecture can end up slower to change, harder to operate, and less reliable than the single large system it replaced, and it can cost more to run while doing it. This is rarely the work of a careless team.
How many decisions does it take to reach that point?
It rarely takes a single bad one. The path to such a situation is built from individually sound choices, a clean separation here, an independent deployment there, a new service each time a part of the system felt distinct enough to stand on its own. Those reasonable steps accumulate into an arrangement no one would have chosen on purpose, and the problems that emerge look like a catalog of separate mistakes even though nearly all of them trace back to one early decision about how to break a system.
At a basic level, a service is a part of a system that can be deployed on its own and controls its own data. This means it does not reach into any other service’s database to do its work. It also talks to other services over a network. Inside a single program, one function calling another takes a few nanoseconds and either returns an answer or raises an error. The same call across a service boundary can take a few milliseconds, and it can also time out or succeed halfway and leave things in an odd state. Almost every anti-pattern below emerges from this one problem.
In this article, we will look at some of the most important anti-patterns in service architecture, how they happen, and how they can be avoided.
2026-06-24 23:31:30

AI-assisted development has changed how code gets written, but for many teams, testing and governance haven’t caught up. Tricentis AI Workspace closes that gap, giving quality engineering leaders one place to build, orchestrate, and govern AI quality agents across the SDLC, from code risk analysis and test automation to performance validation so quality decisions happen continuously, not at the end. Less errors introduced by AI-generated code, more confidence in what you’re shipping.
Discover how teams are using AI Workspace to bring structure to AI-driven development and compress delivery timelines without sacrificing confidence in business outcomes.
Apple’s most ambitious AI feature runs in about a gigabyte of memory on the iPhone. The same company runs a much larger model on its own cloud servers, and the two diverge in almost every architectural choice beyond the word “transformer” in their lineage.
The same split shows up at Google, Microsoft, and Meta, where one family of small models targets devices and a different family of large models targets data centers.
Small and large language models are different engineering responses to different constraints, and the differences begin with where each model runs, what hardware it targets, and how it was trained.
In this article, we will explore those constraints through three layers of model design, look at the tradeoffs that come with each approach, and investigate the production systems that combine both small and large models.
Disclaimer: This post is based on publicly shared details from various sources. Please comment if you notice any inaccuracies.
Before we look at what makes the two classes different, it helps to be precise about what makes them the same.
Both small and large language models are transformer-based decoder models, built by stacking layers of the same basic computational block. Each block runs an attention operation, which figures out which previous tokens matter most for predicting the next one, followed by a feed-forward computation that mixes that information through a wide intermediate layer. The model repeats this block thirty or more times before producing a probability distribution over what the next token should be.
Both classes go through similar training stages. They start with pretraining on large text corpora, where the model learns to predict the next token across billions of examples. They typically follow with supervised fine-tuning on specific instruction patterns, and many go through reinforcement learning from human feedback, which shapes how the model handles ambiguity and stays helpful in conversation.
The size of a model refers to its number of parameters, which are the learned weights adjusted during training. A small model in 2026 typically has between half a billion and fourteen billion parameters. A large model has tens of billions to hundreds of billions of parameters, and sometimes more.
Three constraints pull the designs of small and large models in opposite directions.
Deployment target: Where the model runs determines its memory, battery, and latency budgets.
Inference economics: Training is paid once, but serving is paid per request, which inverts the math at scale.
Training budget: Smaller budgets push teams toward efficiency through data quality and distillation rather than raw scale.
The deployment target determines everything that follows.
A model that runs on a phone has a memory budget measured in single gigabytes, a battery budget measured in milliamps, and a latency budget measured in milliseconds. A model that runs in a data center operates in a more permissive environment, with concerns around throughput, batching efficiency, and cost per request, but with an absolute resource ceiling orders of magnitude higher.
Inference economics is the second pressure.
Training a model is a one-time cost paid at the start of its life, while serving the model is a recurring cost paid every time someone uses it. For a high-volume product, the inference bill quickly dwarfs the training bill, so a team designing for high inference volume will gladly spend more training compute upfront to save inference compute across billions of requests downstream.
The training budget is the third pressure.
A frontier large model can cost tens of millions of dollars to train, while most teams working on small models operate with a small fraction of that, and the smaller budget forces choices. Those teams have to find other levers beyond raw scale, which usually means smarter training data, distillation from larger teachers, and more efficient training recipes.
These three constraints reinforce each other rather than acting in isolation. A model designed for the phone has a small inference budget per request and usually a smaller training budget too, while a model designed for the data center has the opposite profile across all three axes. The result is two distinct design regions in the same space.


When devs use AI to generate thousands of lines of unverified code, you risk a codebase slopocalypse. The review step becomes your team’s bottleneck, and the last thing standing between a subtle bug and production.
Greptile reviews each PR with full repo context and learns your team’s conventions over time from comments, reactions, and what gets merged. It flags real issues and suggests fixes that match your team, not generic best practices.
✅ Recently launched TREX runs your code, not just reads it. Greptile executes the change in a sandbox and returns screenshots, logs, and traces as proof of what actually broke.
✅ Review from your terminal. The Greptile CLI runs the same review locally, before you ever open a PR.
✅ Trusted by engineering teams at NVIDIA, Scale AI, and Brex.
✅ Now integrated with Claude Code: install via /plugin.
✅ Free for open source.
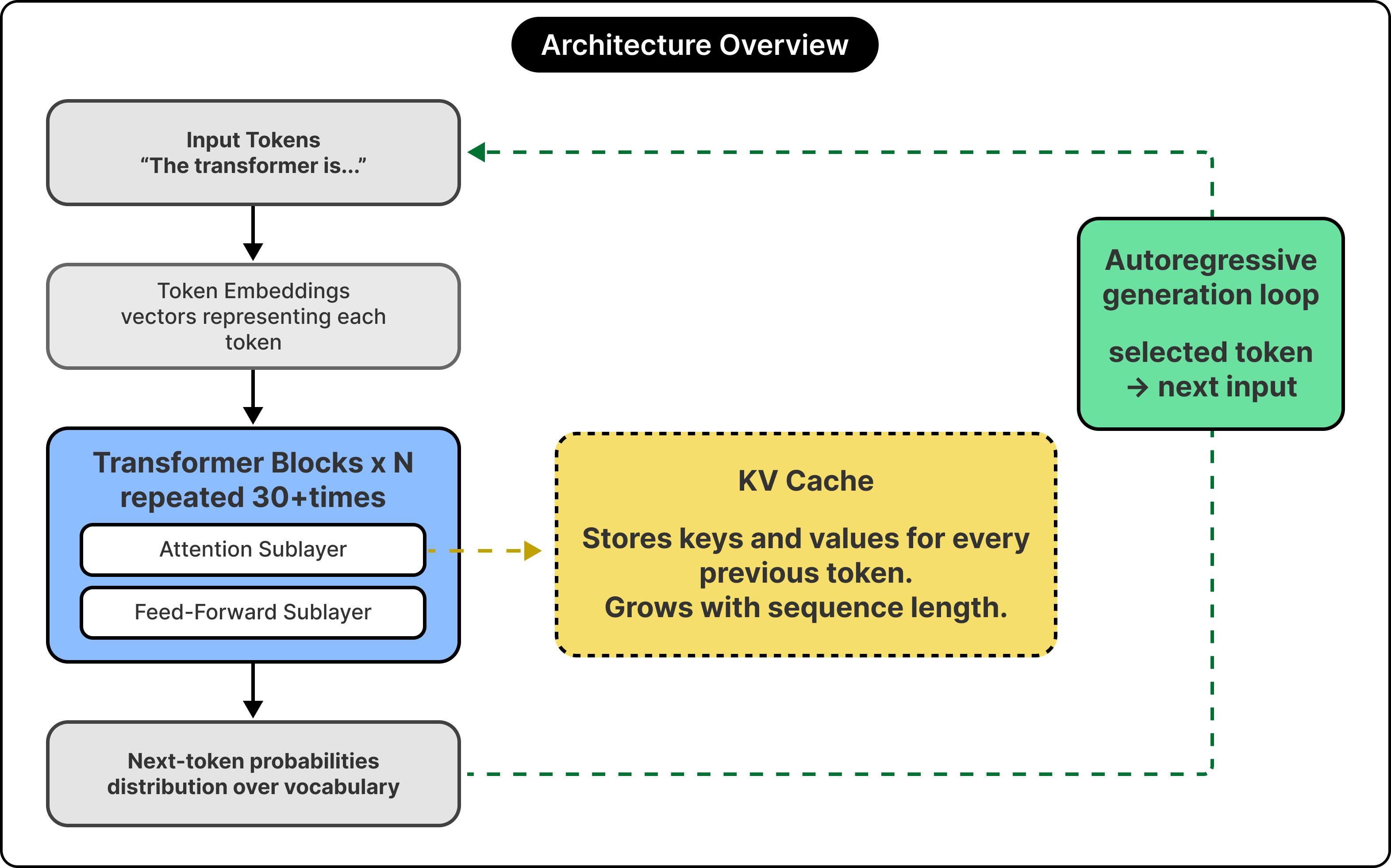
The architecture differences begin with a quick observation about inference.
During generation, the model has to keep around the keys and values for every previous token, since attention works by comparing the current token against all earlier ones. This stored set is called the KV cache, and it grows linearly with the length of the conversation. For long generations, the cache often dominates memory bandwidth and storage, more than the parameters themselves.
This single fact decides how small-model architectures get designed.
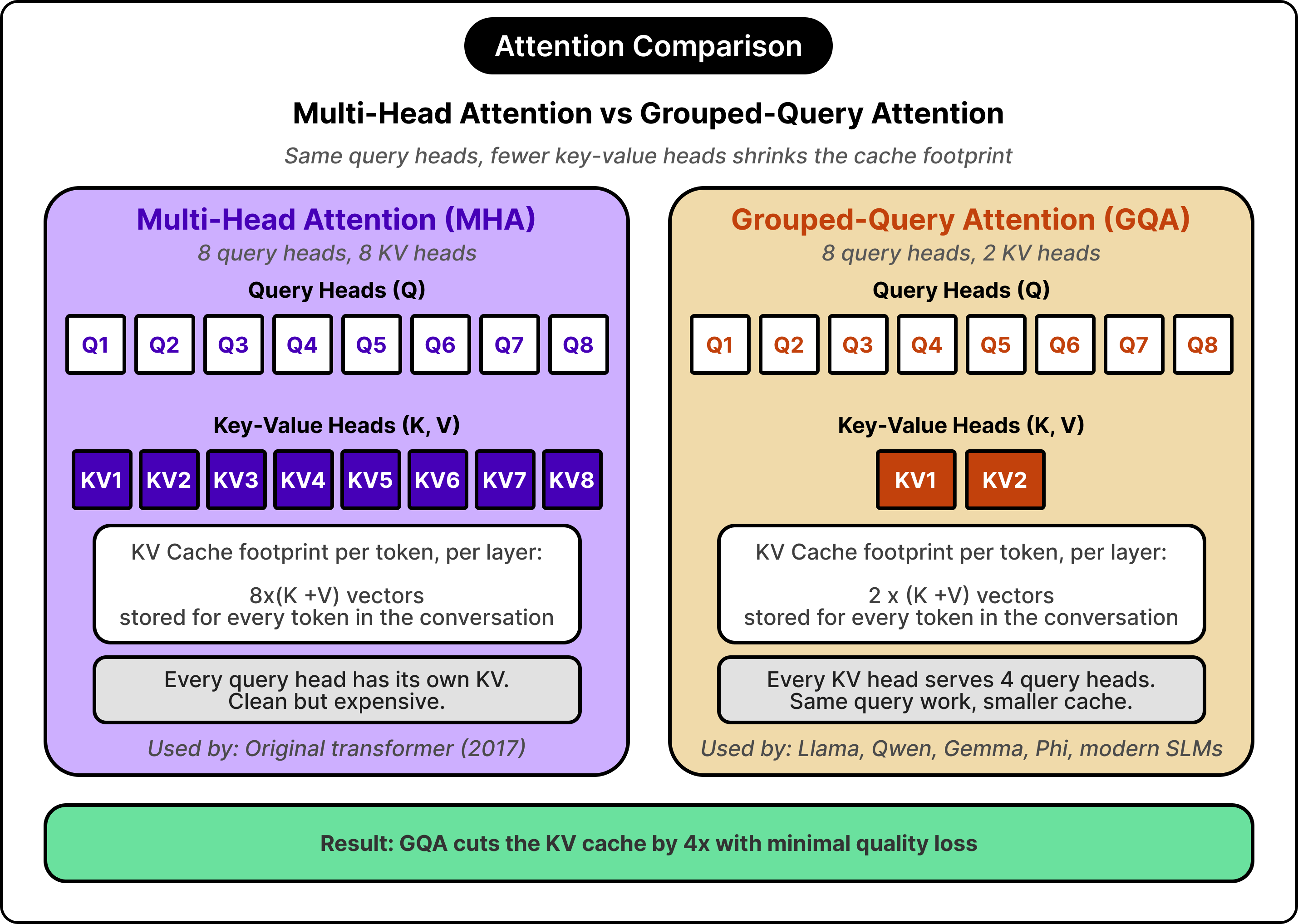
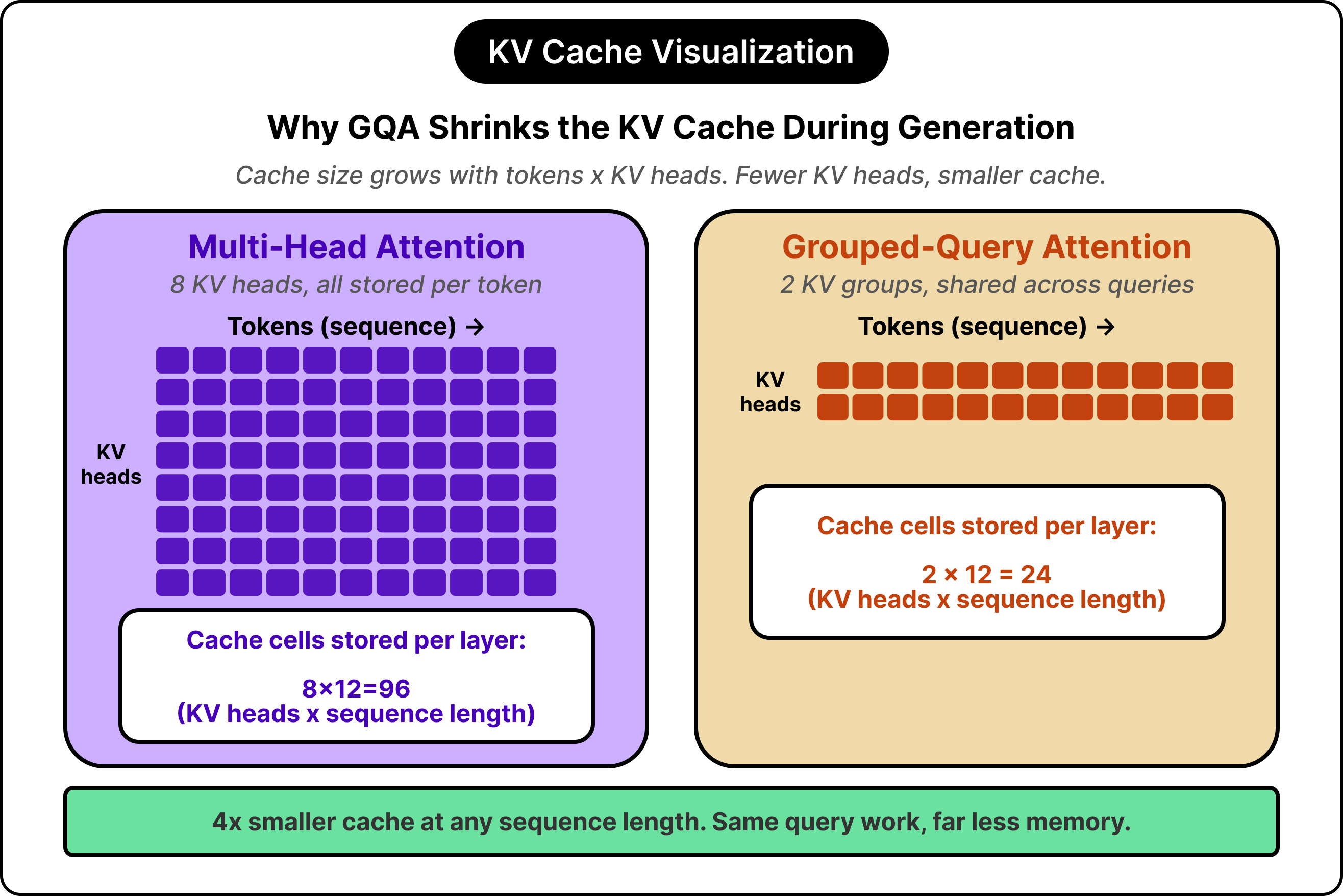
In the original transformer design, every attention head has its own keys and values, an arrangement called multi-head attention. For long sequences, the resulting cache footprint grows large enough to dominate the model’s memory consumption.
Grouped-query attention attacks the problem directly. The number of query heads stays the same, but several queries share a single key-value pair. A model with thirty-two query heads might use only eight key-value groups, which cuts the cache footprint by a factor of four with minimal quality loss. Llama, Qwen, Gemma, and most modern small models use grouped-query attention by default, and many large models have adopted it as well because the math also helps at scale.
Some small models push further. Gemma 2 interleaves sliding window attention with full attention across layers, so some layers attend only to the most recent few thousand tokens rather than the full context. This trades a bit of long-range reasoning for a significantly smaller cache. Apple’s on-device model shares its KV cache across multiple decoder layers, reusing the same stored state in several places.
These architectural decisions all serve the same goal of shrinking the runtime cost of inference, which is the constraint that matters most when the model has to run on a device with a few gigabytes of memory to spare.
Two models with identical architectures can end up with very different capabilities depending on what they were trained on and how.
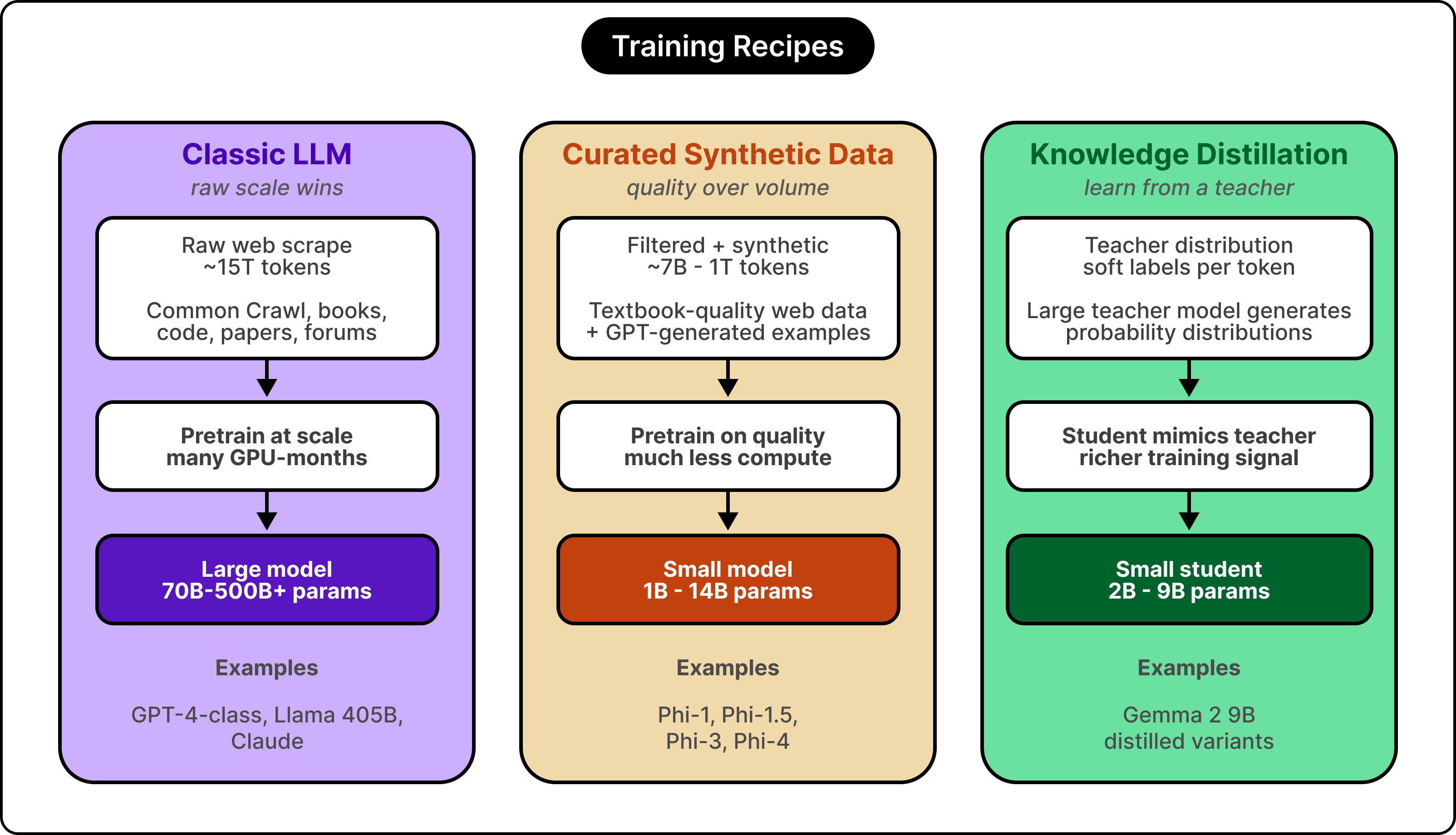
Three techniques define the current state of the art in small-model training:
Data curation: Carefully chosen and synthetically generated training data can substitute for raw volume.
Knowledge distillation: A smaller student model learns from a larger teacher model’s output distribution.
Overtraining: Modern small models see far more training tokens than compute-optimal ratios suggest, trading training cost for inference savings.
The first technique is data curation. In 2023, a Microsoft research team published a paper called “Textbooks Are All You Need.” They trained a 1.3 billion parameter coding model on roughly seven billion tokens of carefully filtered code and synthetically generated textbook-style data. The model matched or beat models trained on hundreds of billions of tokens of raw web scrape. Training data quality could substitute for training data volume, at least for certain capabilities. The Phi family kept building on that insight, and the modern Phi-4 model continues to lean heavily on synthetic data quality as its primary lever.
The second technique is knowledge distillation.
The small model, called the student, learns from a larger model, called the teacher, by mimicking the teacher’s output distribution rather than only learning from raw text. The richer training signal helps the student pick up patterns it would struggle to learn from the underlying corpus alone. Gemma 2 used this approach to train its nine billion parameter model, while training its twenty-seven billion parameter version from scratch.
The third technique is overtraining relative to compute-optimal.
In 2022, the Chinchilla paper from DeepMind established that for a fixed compute budget, the best model came from balancing parameter count and training data, roughly twenty tokens of training data per parameter. Modern small models deliberately train on far more data than that ratio suggests. A three-billion-parameter model might see many trillions of tokens during training, which is many times the Chinchilla-optimal amount. Once the model gets deployed, every percentage point of quality improvement saves inference compute across billions of requests, so the team spends more on training to save more on serving.
The final layer of design choices covers how the model executes on real hardware. The two dominant techniques are quantization, which shrinks the storage cost of each parameter, and KV cache management, which shrinks the runtime cost of generation.
Quantization is the practice of storing each parameter with fewer bits. A standard pretrained model stores each parameter as a sixteen-bit floating point number, where cutting that to eight bits halves the memory footprint and cutting to four bits halves it again. The post-training approach is faster to implement but tends to lose quality at aggressive bit widths, while quantization-aware training preserves quality at the cost of more complex training.

Hardware mapping is the next consideration. Apple’s Neural Engine has different strengths from an NVIDIA Jetson, which has different strengths from a data center H100, and the model design follows the target hardware. Phi-4-mini gets tuned for consumer GPUs. Gemma 3 4B variants run on NVIDIA Jetson Orin for edge AI deployments in robotics and embedded systems. Apple’s 3B model runs on the iPhone’s Neural Engine with the assumption that the device also handles other workloads at the same time.
KV cache management is the second major lever, and it connects directly back to the architecture section. The cache stores keys and values for every previous token during generation, and its size determines how much memory the model utilizes at runtime. Grouped-query attention attacks this by reducing the number of key-value heads, and Apple’s on-device model goes further by sharing its cache across multiple decoder layers.
These deployment decisions stack on top of everything earlier. The same architectural choices that shrink the KV cache also make quantization easier, and the same training recipes that produce capable small models also produce models that survive aggressive compression.
Small models perform well on standard benchmarks like MMLU and HumanEval. Production usage looks more varied. Three gaps tend to matter most:
Generalization gap: Small models are more brittle outside their training distribution.
Reasoning gap: Multi-step problems still favor larger models, though the gap is closing.
Knowledge ceiling: Parameters function as memory, so small models have a hard cap on what they can store.
The first gap is generalization.
Small models tend to be more brittle outside their training distribution, and they can be excellent at tasks similar to what they saw during training, while showing weakness on unexpected ones. A small model trained heavily on code performs well on code but may struggle with creative writing in an unusual style. A model trained on synthetic textbook data does well on textbook-style questions but can falter on the messy, ambiguous prompts that real users send.
The second gap is multi-step reasoning.
For problems that require chaining inference across many tokens, large models still have a noticeable advantage. The gap has been closing thanks to step-by-step reasoning techniques and reasoning-focused fine-tuning, but at very small parameter counts, the ceiling remains real. Phi-4 has done well on math reasoning specifically because Microsoft optimized for that capability through training data design, while a general-purpose small model usually shows a clearer gap.
The third gap is world knowledge.
Parameters function as a form of memory, and a larger model can store more facts, more named entities, more obscure references, and more multilingual coverage. A small model has a fundamental cap on how much it can know, since storage requires parameters and parameters require memory. For applications that need broad factual recall, the small model often pairs with an external knowledge source that the model queries when needed, since trying to fit all that knowledge into the parameters themselves would push the model past its budget.
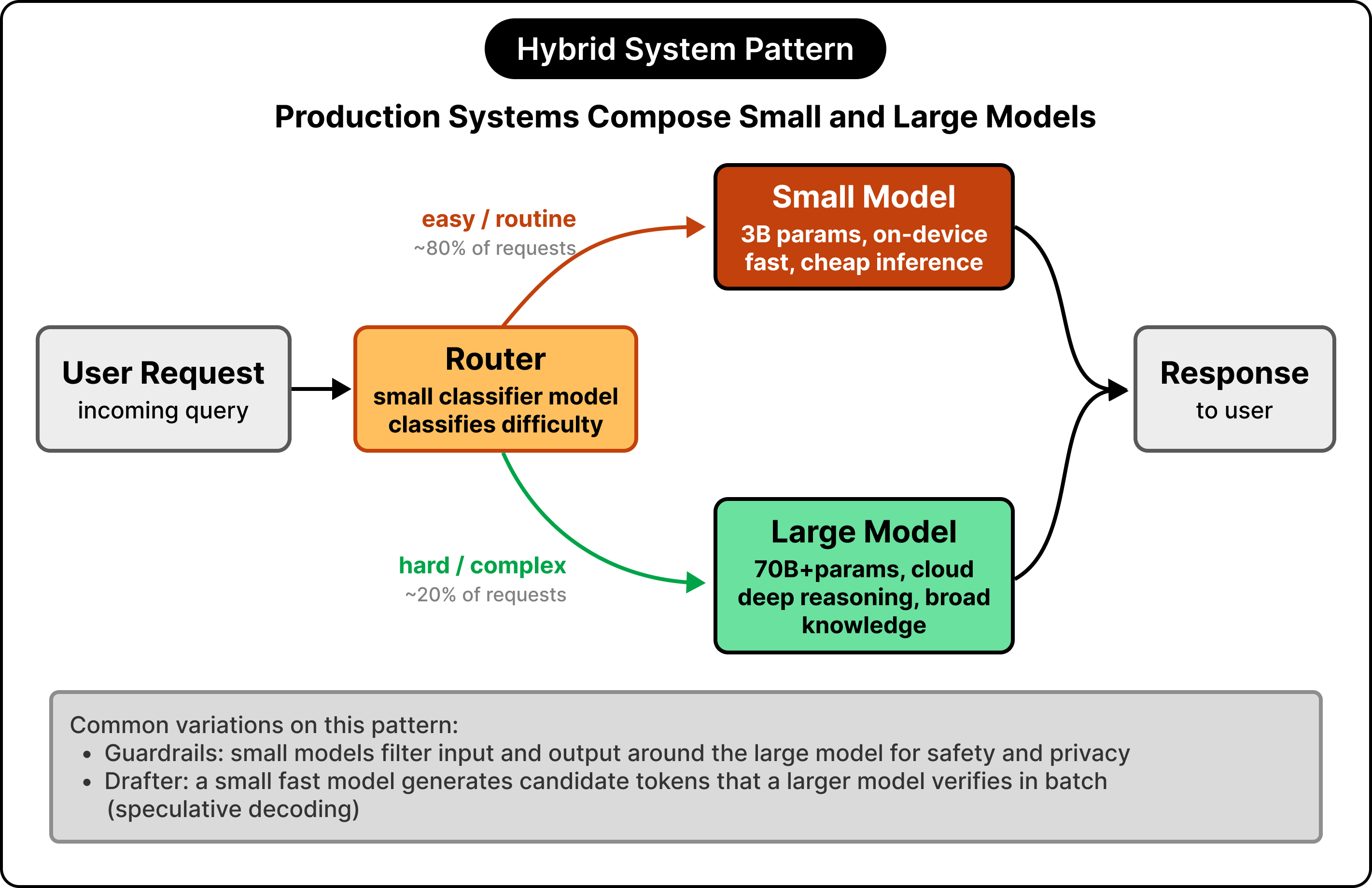
The most interesting design question in 2026 is rarely which model to use. The more useful question is how to compose multiple models into a system that uses each for what it does best. Three patterns appear in most production setups.
Routing: A small model handles requests directly and escalates harder ones to a large model.
Guardrails: A small model filters input or output around the large model’s core work.
Drafting: A small fast model generates candidate tokens that a larger model verifies in a batch.
The most common pattern is routing.
A small model handles the request directly if it falls within its competence, and escalates to a large model when the request is harder than it can confidently handle. The pattern resembles caching tiers in a distributed system, where the fast, cheap layer handles the common case, and the slower, more expensive layer handles the rest. The router itself is often a small classifier model that decides which path to take.
The second pattern is the guardrail.
A small model sits in front of the large model to filter or classify input before the expensive computation runs, checking for unsafe content, classifying the intent of the request, or stripping out information that should stay private. A second small model often sits on the output side, doing similar checks before the response gets returned to the user. These guardrail models are cheap, fast, and specialized, which makes them well-suited to the role.
The third pattern is the drafter, sometimes called speculative decoding.
A small fast model generates candidate tokens, and a larger, more capable model verifies them in batch. When the verifications agree, the system gets the throughput of the small model with the quality of the large one. Apple’s on-device system uses a draft model alongside its base model for exactly this reason. The technique sounds like a hack, but it has become standard in production inference systems.
Picking a model class is the wrong frame for most product decisions. Designing a system around multiple model classes is the right frame, and the interesting design work lives in the composition layer, the routing logic, the fallback behavior, and the orchestration between models.
The question we started with was “small versus large language models,” and the more useful version of that question turns out to be “which constraints drove each model’s design.” The size of a model is a downstream consequence of those constraints rather than the starting point for the design.
Three layers of design choices flow from the constraints:
Architecture adapts through attention variants like grouped-query and sliding-window attention that shrink the KV cache.
Training adapts through high-quality synthetic data, distillation from larger teachers, and deliberate overtraining relative to compute-optimal ratios.
Deployment adapts through quantization, KV cache management, and careful hardware mapping. Each layer reinforces the others, and the result is two distinct design regions in the same space.
Small models are extremely capable for their size, and they have a real ceiling on generalization, on multi-step reasoning, and on broad world knowledge. Production systems handle this by composing both classes, using small models for the common case and large models for the harder requests, sometimes with multiple small models acting as routers, guardrails, and drafters around a larger core.
For a working engineer choosing between models, the right starting point is the constraints rather than the benchmark. The questions that matter are about deployment target, inference budget, and the shape of the request distribution in production.
References:
Apple Intelligence Foundation Language Models Tech Report 2025
Updates to Apple’s On-Device and Server Foundation Language Models
Lightweight, Multimodal, Multilingual Gemma 3 Models Are Streamlined for Performance
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Fast Transformer Decoding: One Write-Head is All You Need (Multi-Query Attention)
2026-06-23 23:31:20

Most teams pick a search provider by running a few test queries and hoping for the best – a recipe for hallucinations and unpredictable failures. This technical guide from You.com gives you access to an exact framework to evaluate AI search and retrieval.
What you’ll get:
A four-phase framework for evaluating AI search
How to build a golden set of queries that predicts real-world performance
Metrics and code for measuring accuracy
Go from “looks good” to proven quality.
This is a guest post by Kun Chen, a former L8 principal engineer at Meta, Microsoft, and Atlassian, where he led development of Rovo Dev, Atlassian’s AI SDLC product. He has since left big tech to build solo and has gone all-in on agentic engineering. Below, he walks through his complete setup, step by step. You can follow him on X and subscribe to him on YouTube, where he shares his agentic engineering workflow, the open-source tools he builds, and his take on AI and software craft. Over to Kun.
Hi everyone, Kun here. For context, I spent years driving agent adoption among tens of thousands of engineers at all levels, both within my company and across many customers’ engineering organizations. Going solo has actually let me lean into agents even more.
Here’s the difference using agents has made to my productivity: shipping 30+ high-quality PRs that meet my own bar used to be hard to imagine, and it’s now a slow day. I’ve reached what feels like a constant flow state, where the quality and speed of my thoughts is the only bottleneck left.
All of this didn’t come from a single trick or using some hyped tool. It came from a long and often messy process of figuring out what actually works in the real world versus what just sounds good in a demo. The short version is that I have now stopped writing most of the code myself and started acting like an engineering manager directing a team of agents. I stay at the level of deciding what to build and whether it’s good, and I’ve built tooling to handle almost everything in between.
The interesting part of this journey is all the friction I had to remove to reach this point. Therefore, in this post, I’m attempting to share everything I do, step by step, for both my professional and personal projects.
If you’re on the same journey of making your work with agents more productive and enjoyable, I hope this gives you a head start and shortcuts some of your own exploration.
First, what I’m sharing here is my personal setup. What works well for me may not be the best fit for everyone. I’m sharing my workflow as-is, mainly hoping it can be a useful reference or inspiration for what to explore, even if you don’t end up using the same tools.
Second, I have no affiliation with any of the 3rd party products I mention in this post, and the tools built by me are all free and open source. I share these specific products because those are genuinely what I use in my setup. They are often not the only choice for the problems they solve, so I encourage everyone to research different options based on their interests and requirements.
To make this post concrete and practical, I’ll walk you through my workflow using a real project I’m actively building. It’s called “Hi Bit”: an AI tutor I’m making for my son to teach him agentic engineering. In the rest of the post, I will follow the implementation of a specific image input feature in the Hi Bit project from the idea to merged PR so that you can get a first-hand look at my agentic workflow.
What happens when deterministic code hits the edge of its knowledge? In this live webinar, you’ll see a working plant health monitor built on Temporal’s entity workflow pattern where each plant is a long-running, crash-proof workflow that polls sensors, fires alerts, and falls back to GPT-4o only when the rules run out.
The architecture is clean: structured data first, AI second. The boundary is auditable. The state survives everything. Whether you’re building patient monitors, supply chain detectors, or any long-running process that occasionally needs a smarter answer, the patterns here translate directly.
There has been a constant debate in the developer community about terminal vs GUI.
I’m obviously biased because I started coding almost 30 years ago and built decades of muscle memory on top of a terminal-centric workflow ever since. But I did try GUIs every once in a while, from Visual Basic, Visual Studio, to Atom, and now the latest Codex app.
The reason I stick with terminals is very simple. I keep my flow and focus best when my hands never leave the keyboard. Some GUIs let you do everything via keyboard shortcuts as well, but they’re very inconsistent about it, which makes it hard to build strong muscle memory.
The terminal emulator I’ve been using for many years is WezTerm.
It’s the only terminal I’ve found that is highly performant, customizable, and works consistently even when I’m forced to use Windows. I run it as a single frameless window: no tabs, title bar, or status line, literally nothing else.

I use Claude Code for Anthropic’s models and OpenCode for everything else.
The CLI agent harnesses nowadays are quite commoditized, and you won’t really go wrong with any of them. Almost everything I share below works with any mainstream harness you can find.
In fact, I actually recommend avoiding the “fancy” gimmicks that only some agents have, such as auto-managed memory. They’re often designed to lock you into a particular vendor, when in reality you benefit a lot from being able to switch to whichever newer model works best, even if it comes from a different vendor. I try to keep my whole workflow agent-agnostic, so I have no switching cost. It’s far from clear which model will win in the end, and as a user, you’re in a much better position if you can work with any model available rather than being locked into one.
Neovim has been my primary editor for a long time, and it’s a critical part of staying fully keyboard-driven inside the terminal. You might ask, “But I use agents now. Why do I need an IDE?”
I use it to quickly examine the file system, review diffs, and make small edits when needed. A few plugins do most of the heavy lifting:
oil.nvim: navigate and edit the file system like a buffer
neogit: quickly review git status and diffs, and perform simple operations
snacks.nvim: I use its picker for finding files and grepping the codebase
I don’t let my terminal emulator manage tabs, because I manage all my sessions, windows, tabs, and panes in tmux instead. It’s one of the most powerful primitives in my whole setup, and it unlocks a few things at once:
Splitting my terminal window into panes the way I like
Driving the entire terminal experience from the keyboard
Persisting the working sessions and layout
Accessing the same session from my other devices (more on that later)
A popular alternative is Zellij, but tmux has worked well enough that I haven’t switched. As soon as I’m in, I create a split on the left for the agent and one on the right for Neovim, and I separate different tasks into different tabs that I keep track of along the top.
We’re now in the terminal, and the agent is waiting for instructions. All I have to do is write a prompt. Sounds easy, right?
Actually, how you write your prompts is one of the biggest levers on both the velocity of your work and the quality of the outcome. So let me share a few things that made a big difference for me.
Typing was my primary input method for decades. But over the last couple of years, speech recognition models have really changed the game. You can now run high-quality models locally on your Mac, for free, that generate output extremely fast.
You talk a lot faster than you type, so moving to voice as your primary input is one of the easiest ways to greatly improve your productivity. It applies to prompting your agents, but also to anything else that used to require typing. This post, for example, is mostly written by voice.
The solution I use is OpenSuperWhisper, which is completely free and runs the Whisper model (turbo v3 large) locally. I set a hotkey to trigger it, and now I can just talk wherever I could type. There are plenty of other free and paid options that give a great experience as well.
For many new tech leads and people managers, the first struggle is delegation. The same thing happens with how you interact with agents.
The most common mistakes I see people make about delegation to both humans and agents are:
asking for an action, not an outcome;
not explaining the “why.”
taking back control.
Take “rename this variable.” It’s a valid prompt, but it has a couple of problems:
The agent finishes in a few seconds and waits for you again. It barely saves more time than doing it yourself, and you’re still the bottleneck.
There’s no “why.” Do you want it renamed for readability? To follow a team convention? Because of a future plan you haven’t mentioned? Without the why, there’s no room for the agent to suggest something better, and it won’t know how to do it right next time.
If you were following a convention, a better prompt would be: “Let’s audit this part of our codebase and make sure our variable naming follows this convention <link_to_document>.”
That explains the rationale, gives the necessary context, and asks for an outcome instead of an action. The agent can run longer, get more done in a way that’s aligned with your goal, and respect that convention for the rest of the session instead of creating more problems for you.
The other failure mode is taking back control. When a mistake happens, people immediately think of doing it themselves. This happens to new tech leads working with a junior engineer. They could do the job faster by taking over, but in doing so, they make themselves the bottleneck and fail to scale. People hit the exact same wall with AI: they see an agent do something wrong and revert to doing it manually, and they never truly unlock the leverage agents offer.
The right approach is to give feedback and help the other party improve. With agents, this is actually easier. You can write directly into the agent’s memory file (CLAUDE.md or AGENTS.md), or ask the agent to reflect on its mistake and update that file so the same thing doesn’t happen again.
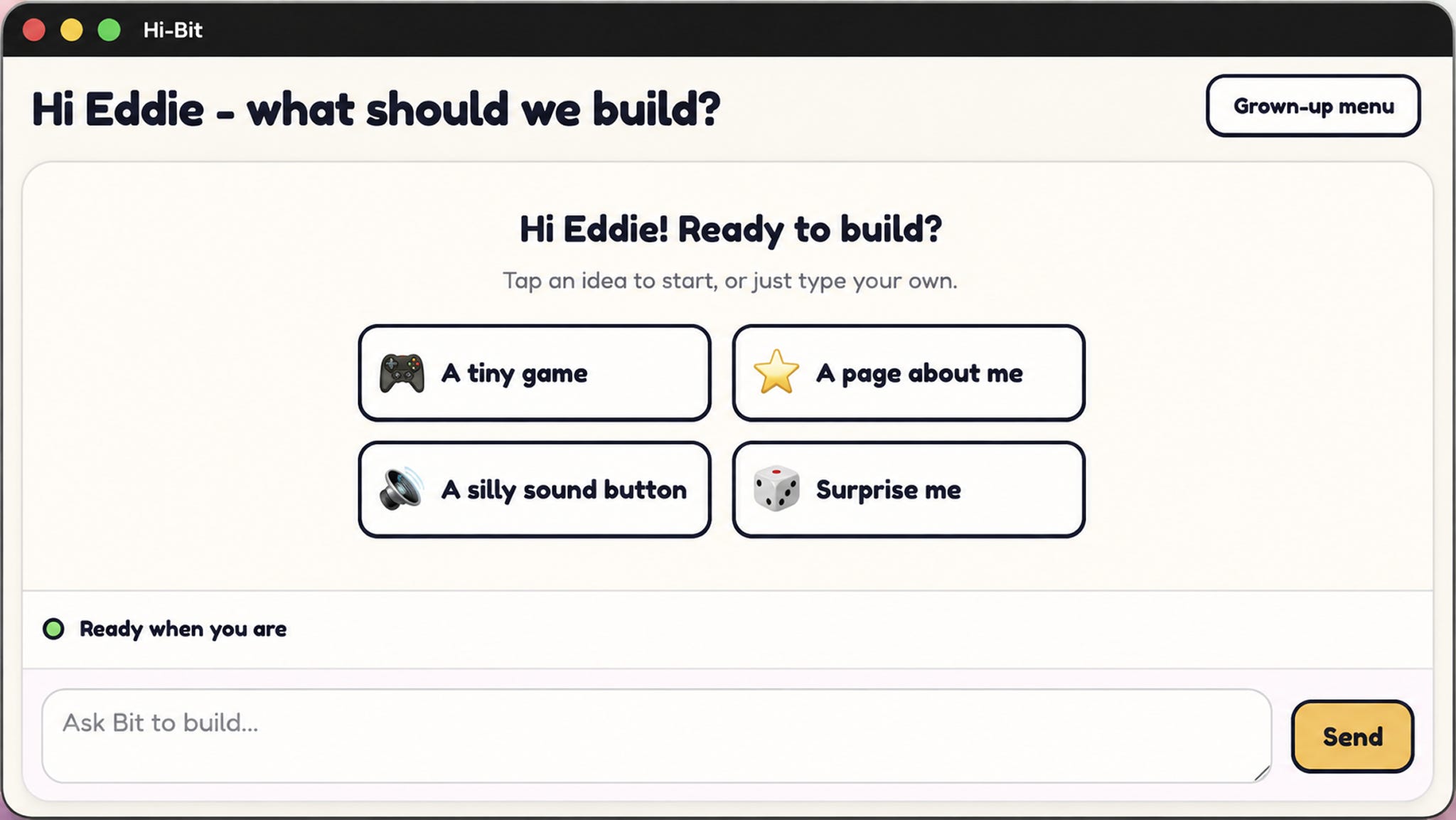
The feature I’m building right now is image input. I want the chat box in Hi Bit to accept a pasted image from the clipboard, or open a file picker or camera. This is a bit more than I think the agent can one-shot the way I want. In the beginning, I also didn’t know exactly where the button should go or what the attached images should look like.
This happens a lot: problems where I genuinely can’t describe the full solution up front. It could be a new project from scratch, a major refactor, or a big feature on an existing system. In those cases, I work with the agent to write a plan first.
There’s a school of thought in the agentic community that’s against technical planning. They prefer to “just talk to your agent” instead.
I went the other way, and here’s why. When you just talk to your agent, you have to stay in an interactive session. You get constantly pulled back into the conversation, and after a few rounds, it’s hard to keep track of what the actual plan is. A long wall of text in the terminal is also painful to parse and hard to give targeted feedback on.
Instead, I spend a concentrated chunk of time up front getting the plan into a confident state, so I can hand it off for a fully autonomous implementation without jumping back in until it’s done. That’s also what frees me up to run other tasks in parallel without constant context switching.
For a long time, I did this by asking the agent to write a proposal in a markdown file, then questioning it and iterating. That worked, but I have something better now. Inspired by an article on using HTML as interactive artifacts, I built a tool called Lavish Editor to collaborate with the agent on anything complex.
So instead of “draft a technical plan in a markdown file,” I say “draft a technical plan using npx lavish-axi.” Lavish guides the agent to render the plan as an interactive HTML page and opens it in my browser. It even encourages the agent to match the look and feel of the current project, so the plan for a UI feature looks visually consistent with the real app, which makes options far easier to judge.

A few minutes later, the agent had a plan open in my browser. It opened with the goal and context, flagged the decisions I’d need to make, and then laid out three UI options — a “+” button menu, an always-on button trio, and a smart-paste tile — each with pros and cons and the agent’s own recommendation.
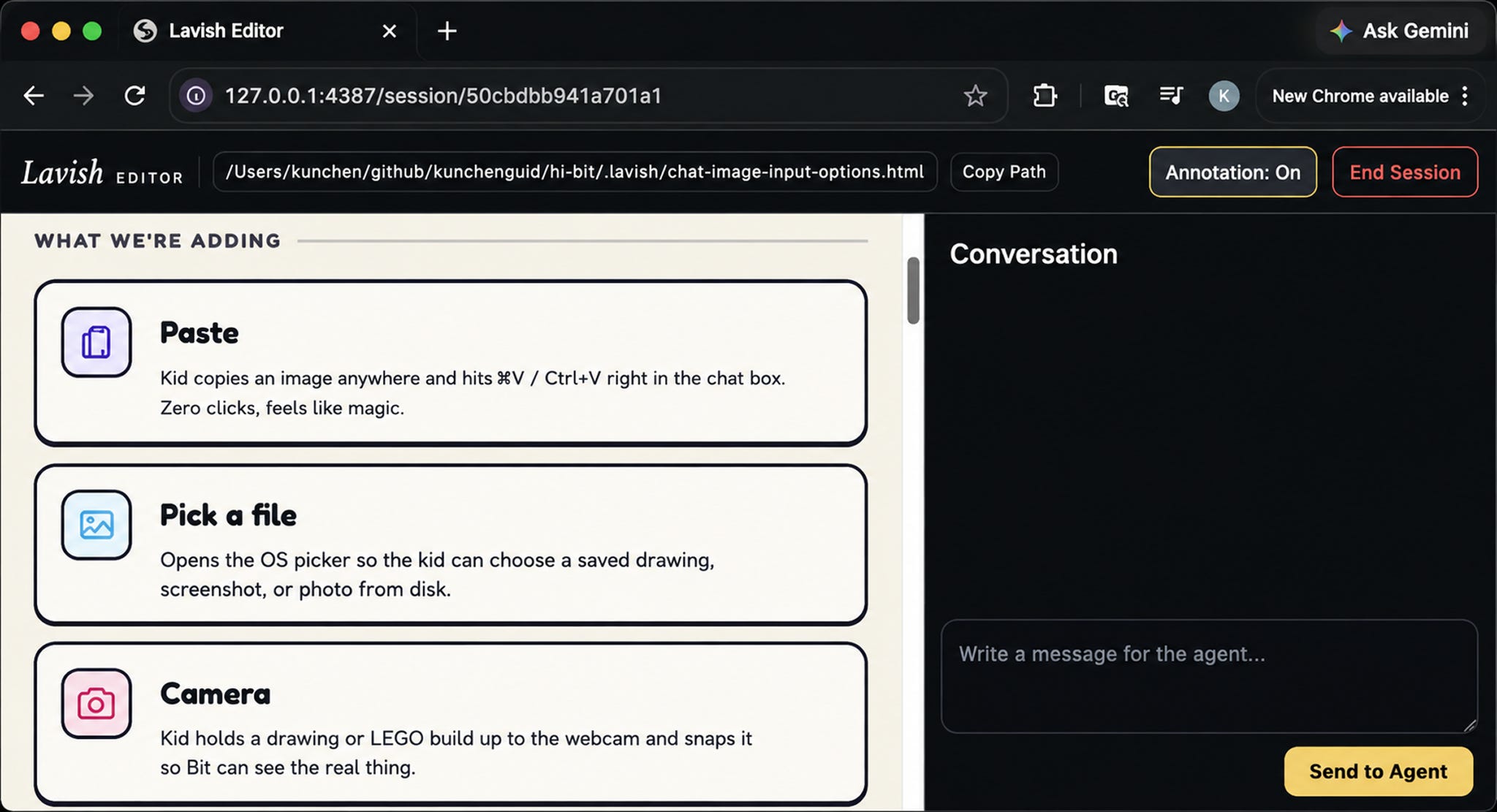
The real payoff is the interactive back-and-forth. I liked Option A’s tiny resting footprint, but not that its menu dropped down and stretched the chat area. Rather than writing a paragraph describing which element I meant, I just clicked that element in the page and annotated it directly: “Can we make it a floating overlay above the + button instead?”
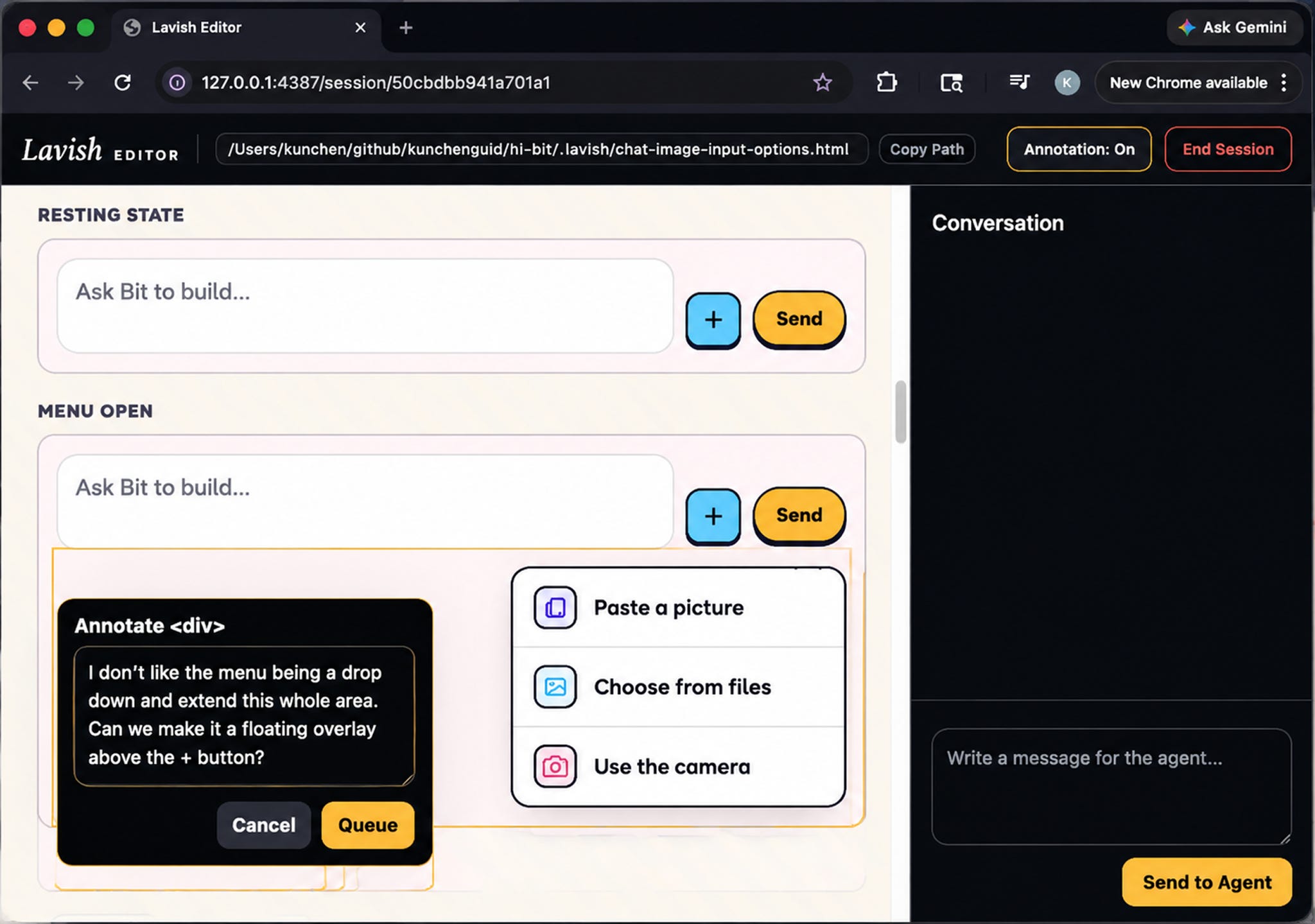
The agent came back almost immediately with exactly the revision I wanted, and I finalized the remaining decisions just by clicking buttons. Being able to interact with a plan this richly, instead of editing a markdown file, turned out to be a big productivity boost, and it’s not limited to planning. I now use Lavish for brainstorming, reviewing changes, data reports, and anything else that benefits from a visual artifact and tight back-and-forth. It’s been a game-changer.
Once the plan is clear, the implementation is fully autonomous, and there’s honestly not much for me to do except wait for the agent to ping when it’s done.
The one thing worth mentioning over here is that for every project, I spend a lot of effort making sure the agent can validate its own change end-to-end. As an example, for Hi Bit, I keep explicit instructions in the repo’s AGENTS.md for how to exercise the app, so changes like this get validated by the agent before they come back to me. I can often watch it test its own work in real time by driving the real app, attaching an image, and checking how the new button actually behaves.
Occasionally, a task is so complex that it doesn’t fit well in a single context window. If I just let the agent grind on it, it fills its context, fires off very large requests, and eventually compacts to free space, sometimes losing important context in the process. The newer /goal command in Codex and Claude Code helps a bit, but I’ve been using something better since well before it existed.
I call it good night, have fun: gnhf for short. It’s a dead-simple, long-running orchestrator I built for running big tasks overnight; you invoke it with gnhf <your objective>.
Under the hood, it works similarly to the Ralph Loop and Autoresearch patterns. It breaks the task into small steps, and each step runs in a fresh context window seeded with a common base context plus the learnings from previous steps. Failed attempts roll back automatically, and the next attempt takes the failure into account. I can also set a token budget so I don’t wake up bankrupt. When I come back, there’s a branch with well-organized commits and a notes.md file summarizing what was done.
I reach for gnhf in three kinds of situations:
Implement a massive plan: gnhf “fully implement this plan…”
Improve a measurable metric such as reducing lines of code, increasing test coverage, cutting startup latency, or page load time: gnhf “improve <this metric> while keeping product functionality unchanged.”
Run lots of offline experiments when you have an evaluator capable of scoring each attempt. For one project, I generated a game map by running 50+ layout experiments and scoring each through a gameplay simulation. Babysitting those by hand would have taken weeks.
Back to the image task: the agent has done the work, and it has produced a big change. Now what? This is where many people hit the real bottleneck: code review. There’s simply too much code to read, and reviewing it isn’t the fun part of the job.
I’m increasingly convinced that working with agents means acting like an engineering manager. Most managers rarely review code directly. They have the team review each other’s work, and before anything ships, they ask for evidence that it actually works. It’s the same with AI, except the developer is the manager and the agents are the team. You have to get good at using agents to scrutinize agents’ code, get them to self-correct, and get them to produce artifacts that demonstrate the feature really works.
I’ve experimented a lot here, and a few things turned out to matter most:
Run the reviewer agent in a fresh context window. If you review in the same session that wrote the code, the agent is biased by what it just did and assumes it was intended. It’s like asking someone to check their own work. They’ll catch some things, but it’s far weaker than a real peer review.
Escalate ambiguous, product-changing decisions to the human. Reviewers make mistakes, too. If you let the agent auto-fix every finding as if it’s all valid, it can drift into rabbit holes away from what you actually want. Keeping those decisions with the human keeps you in control of the ambiguity.
Force end-to-end evidence. Today’s frontier models lean heavily on unit tests to validate changes, probably because of how they’re trained. But I’ve seen countless cases where every unit test passes, and the product is still buggy. You have to make the agent prove the change works E2E.
I packaged all of this into an open-source tool I built called no-mistakes, which I now run on the image change. First, I use the neogit plugin to quickly scan the diff and make sure it’s roughly aligned with what I asked. Sometimes an agent goes in a completely wrong direction, and that’s obvious at a glance.
If it looks reasonable, I run no-mistakes -y and it handles the rest: commit with a conventional message into a descriptively named branch, rebase onto the latest main and resolve conflicts, spin up agents to peer-review and self-correct obvious bugs, test the change E2E and produce evidence, close documentation gaps, fix linting, push, open a well-structured PR, and babysit CI until it’s green.
All of it runs autonomously except for the decisions it deliberately escalates to me.
This validation pipeline has become one of the most critical pieces of my whole workflow. My own stats show that 68% of the changes I pushed through the no-mistakes tool had bugs in them. I genuinely can’t imagine what my codebase would look like without it.
With a fully autonomous implement-and-validate pipeline, a single task can take a while, and that’s a good thing, because it frees me up to run more things at once.
In tmux, this means opening a new window. Terminal tabs achieve the same parallelism. The important part is keeping those tabs visible and showing each agent’s status in the tab title. Claude Code and Codex do this out of the box; for harnesses that don’t, I wrote small plugins to do the same, and I made the no-mistakes tool report its status as a custom title too.
That one detail is what lets me run many sessions without going insane. At any moment, I can see which agents are running, which are done, and which need my input. A couple of tmux keystrokes jump me to any tab.
The other problem with running agents in parallel is that they step on each other’s toes when they share a directory.
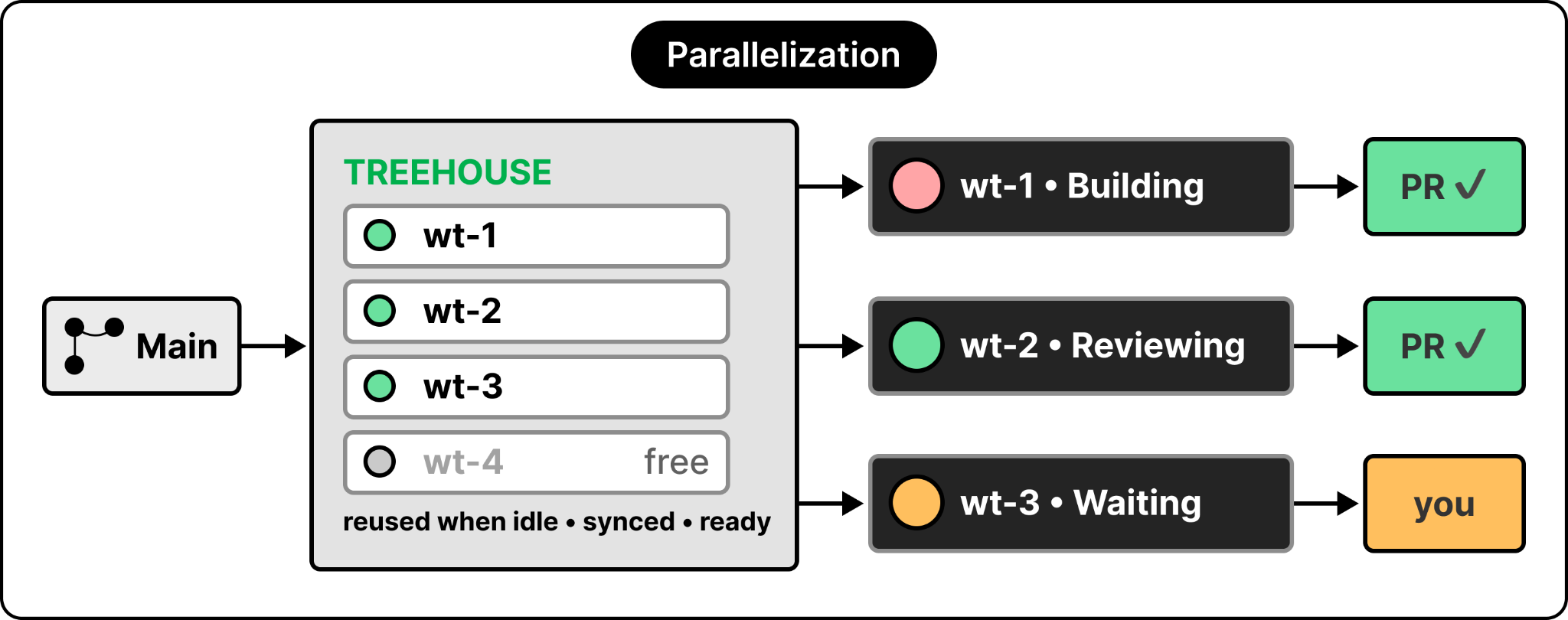
Git worktrees exist to solve this. A worktree is an efficient clone of the same repo in another directory where you can work in parallel. But worktrees carry a lot of cognitive load: where to put them, how to name them, create a new one or reuse an old one, which are in use, which have dependencies installed, and whether env files are ready. What I actually want to think about is the work, not where to do it.
So I built another open-source tool named treehouse. You’re in a repo, you want to start a parallel task, you run treehouse, and it drops you into a ready worktree. Behind the scenes, it manages a pool of worktrees, tracks which are free, reuses an idle one when possible (so dependencies, build artifacts, and env files are already there), and makes sure it’s synced with the latest main before dropping you in. I don’t think about any of that. I simply run the treehouse tool and start working.
I repeat this and usually end up managing 5 to 10 tasks at once. I don’t context-switch much because most of them go straight to a clean PR with no involvement from me. Occasionally, the no-mistakes tool escalates something for a decision, but most of the time, I’m just thinking about and writing the next instruction.
The diagram below tries to show the parallelization angle that I’m talking about:
A little while later, the image-attachment task’s pipeline finished and handed me a PR that was ready to merge. Many issues had been caught and auto-fixed along the way, all logged on the PR, so I can audit them. Also, my favorite part, a “Testing” section with evidence (including screenshots) that the feature works end-to-end, is presented.
Every couple of weeks, I have to drive my son to a birthday party, where I’d find myself useless for a few hours. He’d be having a great time with his friends while I sat somewhere with no Wi-Fi, missing my agents and wondering whether they were blocked and waiting on me.
That stopped once I set up the remote control feature. I don’t use the built-in remote features from Claude Code or Codex for a few reasons:
I want one consistent workflow across all my agents, not separate apps that do the same thing but stay siloed because different companies want to lock me in.
I want real, full terminal access — not an agent-only view — so I can also run treehouse, no-mistakes, and gnhf.
I want perfect continuity across phone, laptop, and PC. My son has zero patience: if he says it’s time to leave, I get up and go. If I typed half a sentence on my phone, I want to finish it on my PC later.
So I set up Tailscale, which puts my PC, laptop, and phone on the same private network where they can reach each other safely. I then ssh between them (which on Mac just means enabling “Remote Login”). On my phone, I use an SSH client to connect to my Mac, attach to my tmux session, and instantly I’m in the same workspace with the same tabs, same agents, same environment.
To keep the connection stable, I use mosh, a transport layer on top of SSH built specifically for terminal state over flaky networks, which matters a lot on cellular. It is the same experience, just more resilient.
So how does all of this come together on a normal day?
It usually starts with me talking instead of typing, describing a feature or a gnarly refactor by voice.
If it’s complex, I have the agent draft a plan in Lavish Editor and iterate on it in the browser until it’s right.
Once the plan is solid, I either ask the agent to implement it directly or hand it to gnhf if it’s big, while I spin up a fresh worktree with treehouse and start the next task in a parallel tmux window.
When an agent finishes, I don’t read massive diffs line by line. I run no-mistakes, which reviews the code, tests it end-to-end, and opens a clean PR while I move on.
When I’m away from my Mac, I SSH in from my phone, and the whole workspace stays with me.
Here’s what the workflow looks like on a high level:
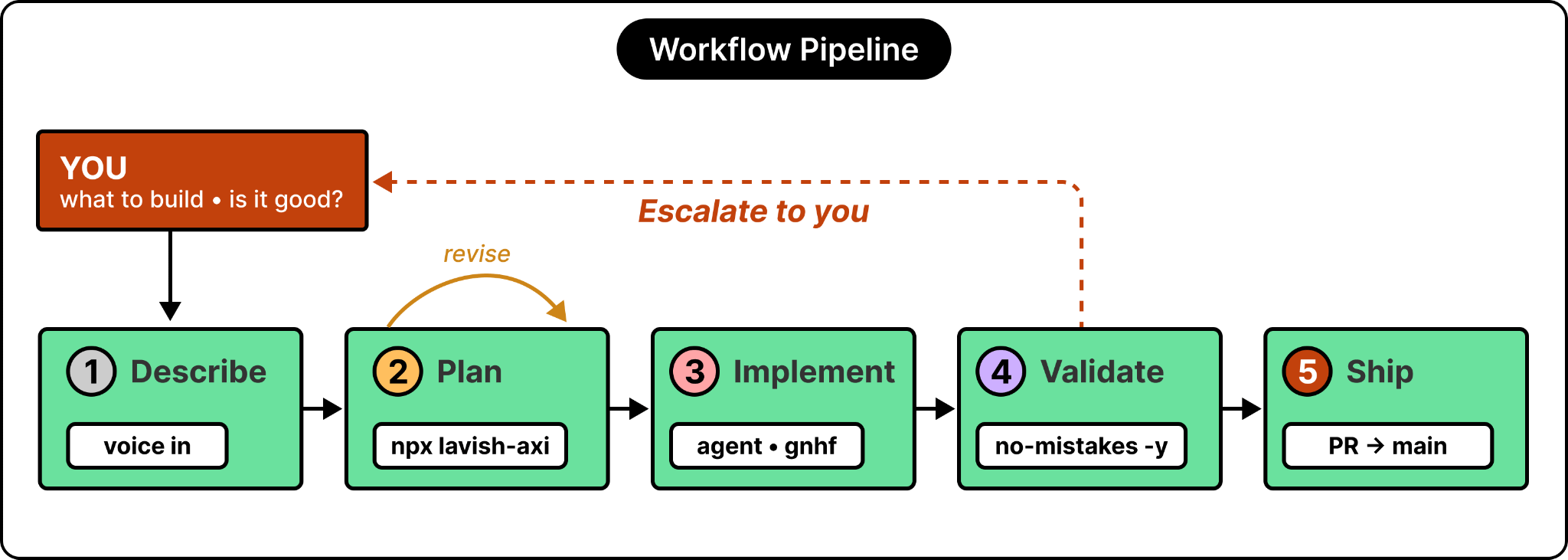
Each tool removes one specific point of friction, and together they chain into a smooth workflow I genuinely enjoy. I get to stay at the level of deciding what to build and whether it’s good, while most of what’s in between runs itself.
That’s everything I can think of that made a meaningful difference in my workflow. Reflecting on how it came together over the past couple of years, my biggest realization is that as the models keep advancing, the tooling and workflow around them will keep evolving too. What works well today may be obsolete a few months from now.
At the same time, relying only on off-the-shelf products like Claude Code and Codex is never quite enough. There’s always room for a better, more efficient workflow to take the agents a step further. I benefited a lot from building custom tools to remove whatever friction I hit. You’ll likely face a different set of problems because you work on different projects with different processes.
So I’d encourage you to never accept anything that slows you down. If part of your workflow frustrates you, chances are others are hitting the same thing. Find a tool that fixes it, or build one and share it. We’re in the middle of an industrial revolution. It’s the best time to be creative and redefine how things should work. Let’s tinker and have fun.
2026-06-22 23:30:47

Run npx workos@latest to launch an AI agent that reads your project, detects your framework, and writes the auth integration directly into your codebase. No account required upfront. WorkOS automatically creates your environment and keys, then lets your claim the project when you're ready.
Once installed, manage users, orgs, and environments directly from the terminal.
This is Part 2 of our series with Shah Rahman, Global Head of Autonomous ML Iteration & Optimization for Ads at Meta, where he architects AI-native infrastructure and multi-agent systems at hyperscale. Connect with him on LinkedIn.
Part 1, published two weeks ago, was written for the individual engineer. Shah covered:
The shift from engineer to orchestrator
The four core practices: context engineering, spec-driven development, critical verification, and problem decomposition
The Agentic Development Life Cycle (ADLC)
The security guardrails that are no longer optional
Part 1 was about the person. Part 2 is about the organization. Here we cover:
Pod-based structures and the Agent Champion model
The leadership crisis from first principles: ownership, empathy, and deciding what to build
A phased transformation playbook, plus the metrics that prove it worked
Individual gains do not become organizational gains on their own. This is the playbook for making that leap. Let’s dive in.
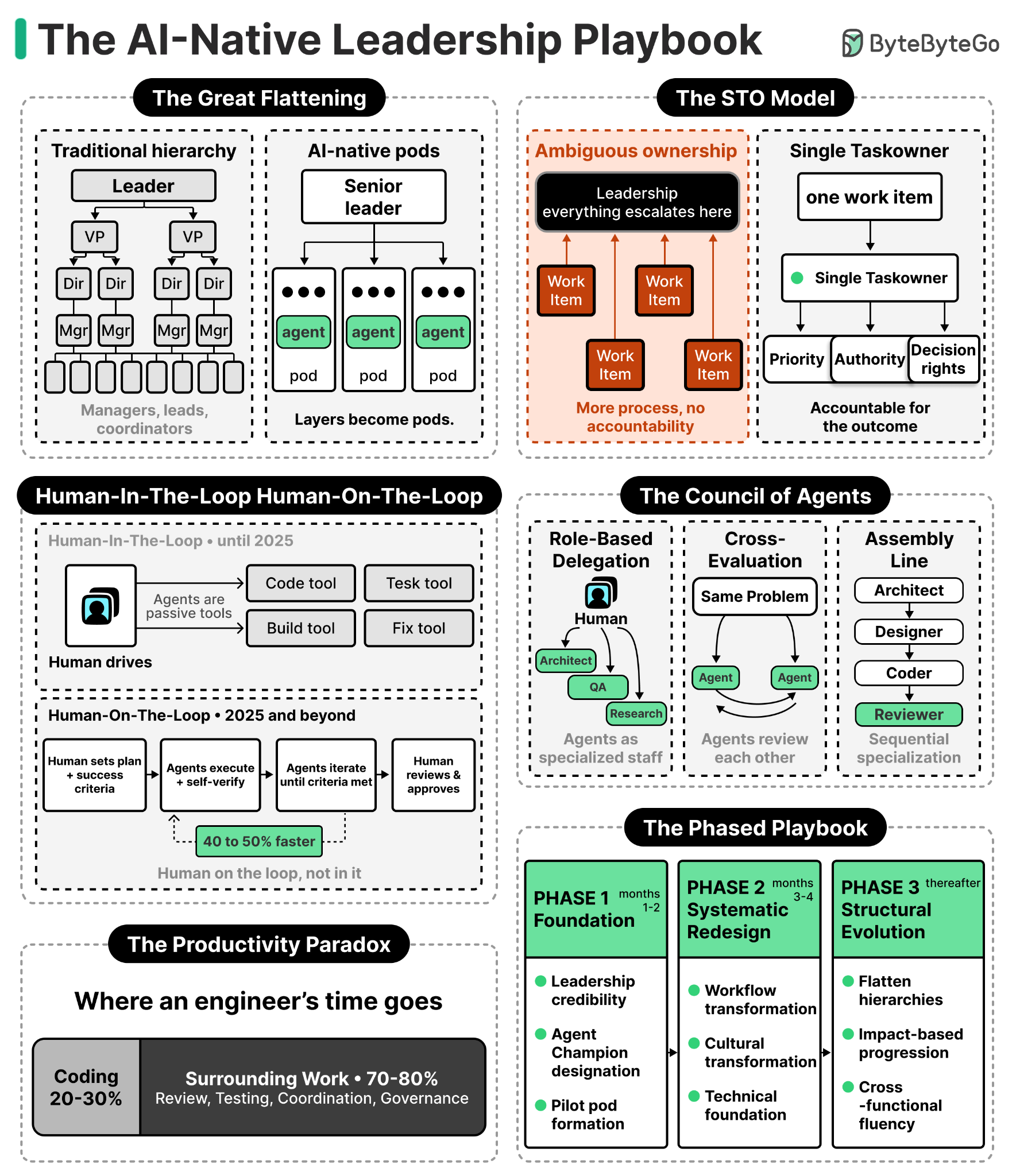
AI-native leadership is the most significant organizational transformation since the industry moved to agile more than a decade ago. Several companies watched AI-generated code climb from zero to 50 or 60% of their output inside a single year. Select teams have posted 2 to 10x productivity gains.
But we keep learning the hard way: individual tool usage produces individual gains, while systemic improvement takes deliberate leadership and a redesign of how work flows.
The evidence is hard to argue with. Around 70% of transformation success comes from operational and cultural change rather than from deploying technology. And most organizations get this wrong. They distribute tools, measure adoption rates, and then wonder why velocity refuses to move.
But some organizations are getting real results. At Shopify, CEO Tobi Lutke told employees that AI usage is now a baseline expectation, and that teams have to show why a task cannot be done by AI before they ask for more headcount. At Klarna, AI-driven restructuring reduced the workforce by more than a thousand people. These organizations treat AI as a fundamental operating model change, not a tooling upgrade. Almost everyone else is now racing to catch up.
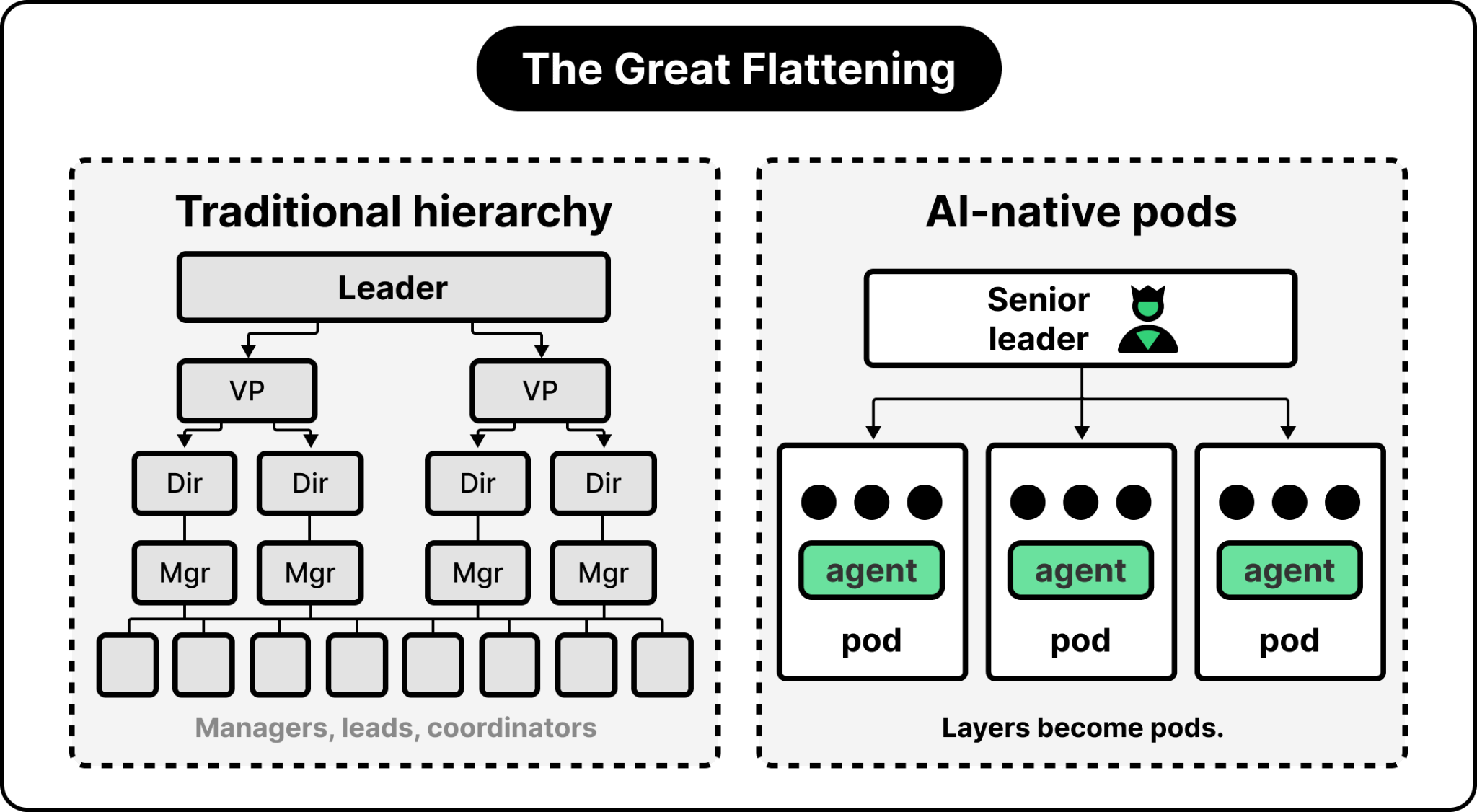
This is the atomic unit of AI-native engineering is the small, cross-functional team: 3 to 5 people operating autonomously with AI agents and tools. The hierarchies established during the dot-com era, all those layers of managers, leads, and coordinators, are being dismantled.
When a 10x engineer armed with AI tools can do what used to take a much larger group, the organizational consequences are significant. Some pods now report directly to senior leaders based on strategic importance. Team impact gets redefined around outcomes rather than headcount.
The results from one established team’s pod pilot were striking: 3 projects running on self-sufficient agentic loops, more than 90% engineer adoption across the org in under two months, and features built in hours rather than days using agent-assisted development loops.
Roles become fluid in this setup. Engineers may design, designers may code, and product managers may prototype directly. This is not role confusion, it is capability amplification. AI removes the traditional skill bottlenecks, so teams operate with more judgment and less procedural overhead.

Most AI agents work in demos — but fail in production. Learn how to build durable, enterprise-ready AI agents with open-source frameworks using Orkes Agentspan and Conductor. This whitepaper explores how to orchestrate long-running, fault-tolerant agent workflows with built-in governance, observability, retries, and human approvals. See how Agentspan compares to LangGraph, CrewAI, and AutoGen for real-world enterprise AI systems. If you’re building AI workflows that need reliability, scale, and control, this guide shows the architecture patterns that make production-grade agents possible.
While your implementation will be your org-specific, here’s a usable template:
Start with 1 or 2 pilot pods aimed at high-priority challenging issues that block entire teams.
Strip out non-essential review layers and reduce pre-approval friction.
Formalize autonomy so pods can decide for themselves between failing fast and pushing forward.
Only scale after the pilot metrics validate the results. Resist arbitrary rollout timelines.
Every pillar should name 1 or 2 full-time Agent Champions, responsible for reshaping workflows, preparing codebases, and restructuring operating models. This is not a side-of-desk assignment. It calls for dedicated, high-agency technical leaders who spend 50 to 100% of their time on the transformation itself.
The Champion model reaches well beyond traditional engineering:
Product mgmt. champions redesign product reviews, experiment workflows, and cross-functional handoffs for autonomous execution.
Design champions build agent-first prototyping frameworks while protecting craft standards.
Analytics champions let agents run analyses at a scale that was never possible before, on top of an AI-native data infrastructure.
One important note: engineers working with Agent Champions write 70%+ of their code with AI assistance, shifting from human-in-the-loop to human-on-the-loop. The implication is that when those engineers make manual edits, it signals missing AI context rather than business as usual.
Four things matter the most for anyone stepping into the Champion role:
Lead with personal AI adoption first: use the tools daily and share what happens, the wins and the failures alike.
Commit to the vision of AI as foundational to strategy, not an optional enhancement.
Remove barriers through structured, individualized engagement with each team.
Recognize impact based on productivity gains and business outcomes, never on tool usage metrics.
Senior leaders are spinning up “AI-native managers” and “AI-native leaders” groups that go deep on the operating context: processes, tools, reporting, and metrics. This is a competency evolution that educational institutions simply cannot keep pace with yet and hence, the need for such learning and development groups at most organizations.
The leadership competency shifts from delegation to orchestration. You are managing multiple parallel AI workflows, not assigning tasks to humans. Technical depth becomes non-negotiable. Hands-on managers have to evaluate agent-generated code and stand up verification layers. And context engineering becomes a core leadership skill, because the precision of the guidance you give AI systems is the precision your teams inherit.
Before we go any deeper into the playbook, it is worth stepping back to the core crisis underneath it all.
This is the insight most organizations miss. The dominant narrative celebrates AI’s speed: solo founders shipping with agents, dramatic productivity claims, demos everywhere. But the parts of software development that were always hard, remain hard:
Deciding what to build among competing options
Identifying the features users actually need
Prioritizing the capabilities customers will pay for
Knowing when to kill a project that lacks clear feedback
Have you heard that building great software is an act of empathy? AI cannot replicate a human understanding of user friction or the emotional stakes inside a product decision. Multiple Y Combinator partners have made the same argument: product taste, design sensibility, and customer empathy become the differentiating human skills once execution is commoditized.
The danger shows up when cheap coding invites excessive feature creation. Users do not get 10x more cognitive bandwidth just because you can ship 10x more features. Teams spiral into uncontrolled development and manufacture false progress.
The shift that matters is asking whether something should be built at all rather than asking if it can be built faster.
Anecdotally, most dysfunction in AI-native organizations comes from unclear ownership, not bad process. Even the most empowered teams get fuzzy when responsibility is ambiguous. Work gets picked up or dropped based on whatever is most urgent that day. Leadership becomes the escalation path for every decision, which hollows out middle management and triggers the great flattening.
Piling on more processes to fix a process failure only deepens the hole. The principle is that if something is important enough, give it to a single owner and make them accountable for the outcome.
We put this into practice with a “STO for Everything” model, where STO stands for Single Task Owner. Each one carries clear priority, authority, and decision rights. This single change turbocharged our transformation by eliminating the coordination tax that ambiguous responsibility almost always creates.
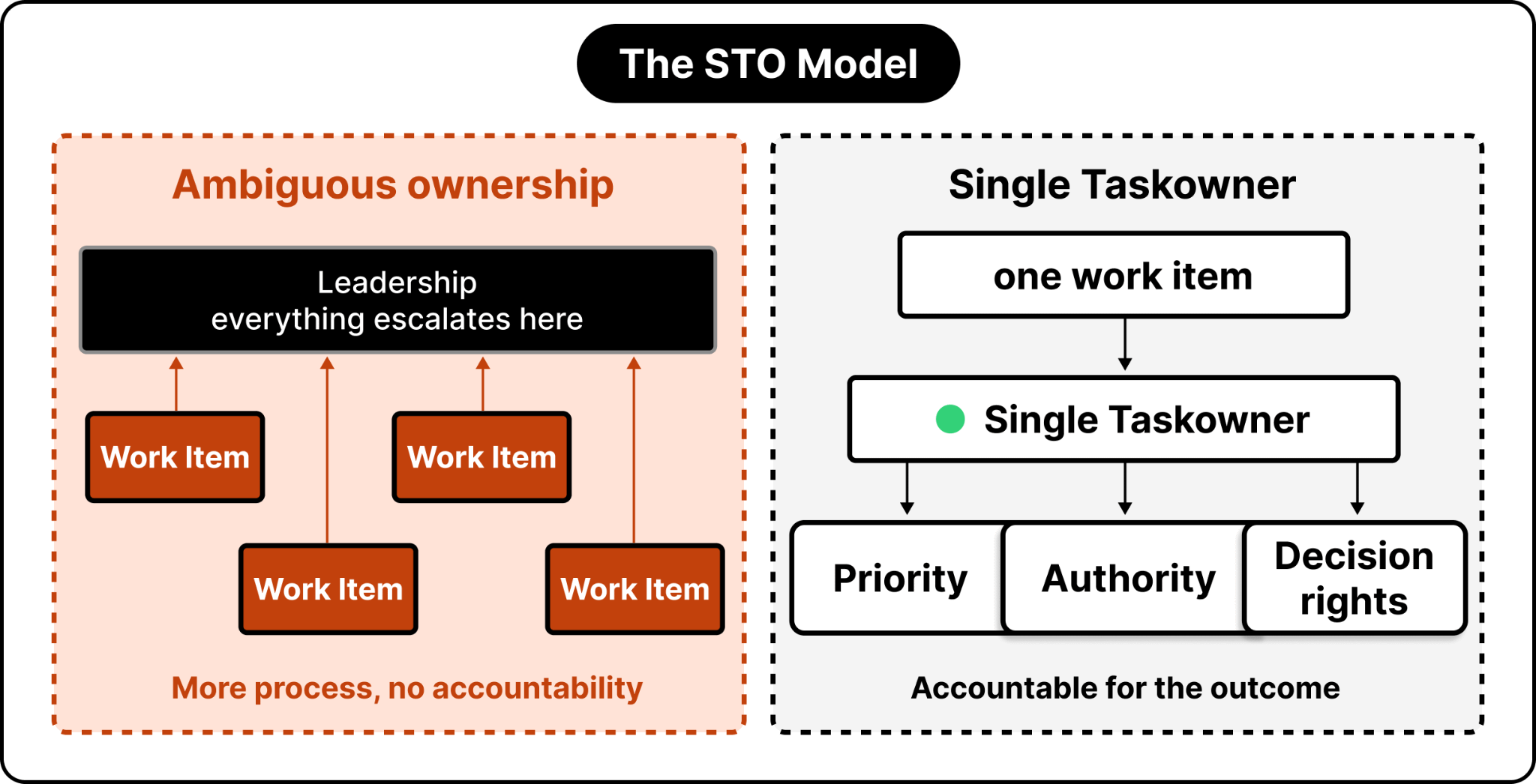
Because, AI dramatically expands the surface area of parallel work. More projects in flight means more coordination overhead, which triggers an instinct to add process. When ownership stays undefined, those ad hoc processes become bureaucratic substitutes for accountability, and you end up in a vicious cycle.
You can automate coordination with agents (dependency tracking, scheduling, status summaries), but that only buys temporary relief. It masks the underlying challenges that nobody owns. The moment key people leave, those challenges surface and the systems collapse.
If you want to fix it, you must own the outcome, not the process. Map the STO model onto the human-on-the-loop paradigm: humans set direction, verify outcomes, and make irreducible judgments, while AI handles the mechanics of execution.
The most common failure I have watched play out is that teams spend months perfecting products that have no product-market fit. They polish the UI, add settings, refine the copy, all of it generating false progress without changing the trajectory. AI makes this temptation worse by dropping build costs to hours, proliferation of code now drives unvetted product frenzy
The discipline is to test the hypothesis before committing to development. Ask “What is the scrappiest way to learn whether this matters?” before you build anything. The rapid prototyping ecosystem (Vercel’s v0, Replit Agent, Lovable, Bolt.new) makes that nearly costless.
Then design to 50-60%. Ship the minimal functionality that enables the core user journeys. Watch where users hesitate, misunderstand, or abandon. That tells you the real product challenges instead of the imagined ones. Over 70% of features never reach a real user. In the age of AI, there is no excuse for building fully polished features that nobody wants.
The temptation is real, but giving into it may decide the winner vs. loser product.
Power users have moved past simple human-AI pairing and into orchestrating multiple specialized AI systems that effectively set up a council of agents. There are few different modalities these councils can take.
Role-based delegation treats agents as specialized staff, each with a distinct persona. Cross-evaluation systems deploy multiple agents to independently analyze a problem and review each other’s work. Assembly line workflows chain sequential specialization: architect, then designer, then coder, then reviewer.
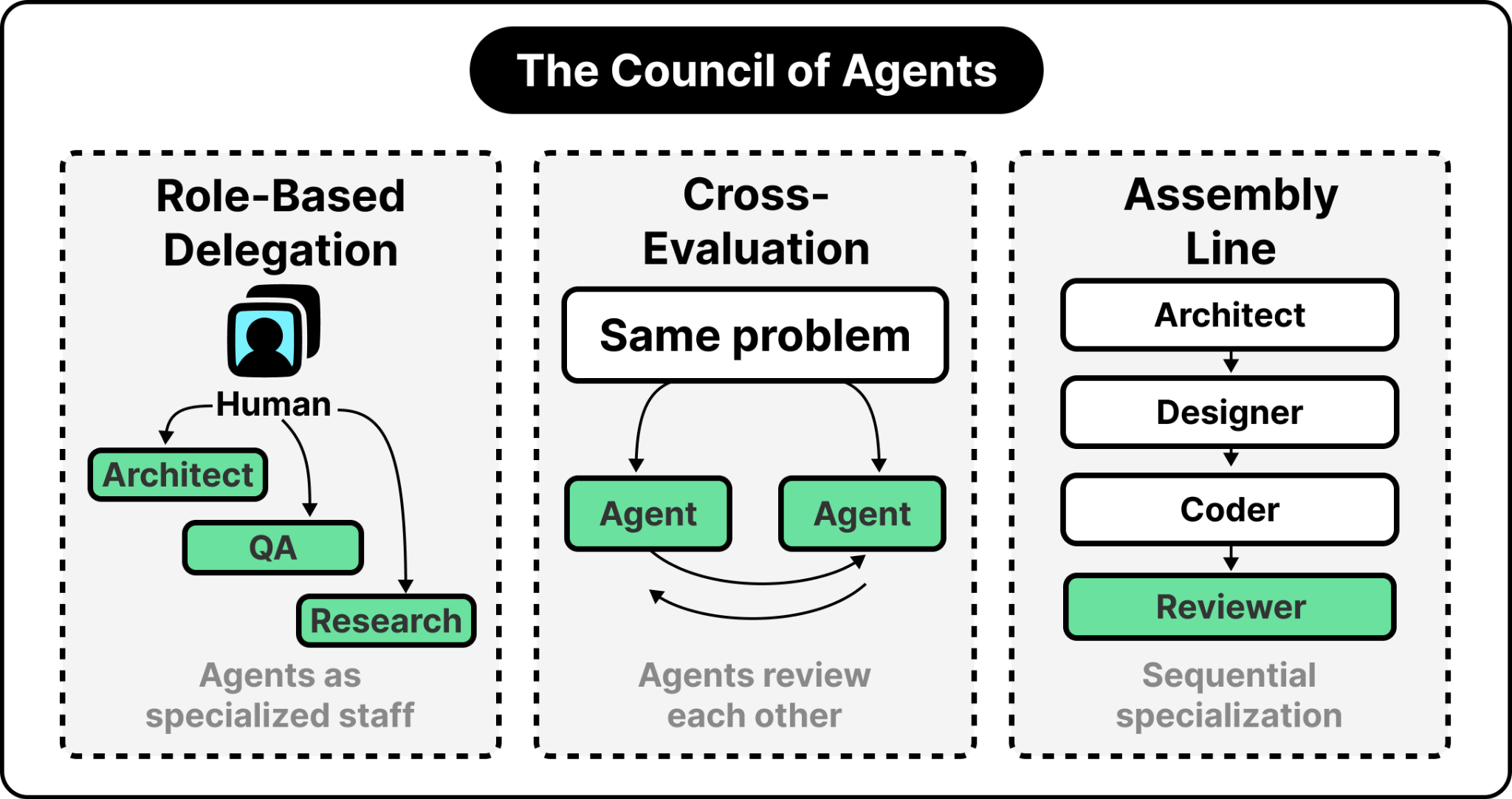
The emerging pattern aims at autonomous, agent-driven development, where agents code, build, test, and fix issues while humans provide oversight. The key distinction is that agents drive the actual tasks, and humans step in when agents hit an obstacle, not the other way around.
A few touchpoints make this collaboration work. Every AI module ships with context files that carry a clear architecture context. Work breaks into small, manageable, verifiable chunks. Quality assurance never assumes the AI got it right. And multi-agent coordination manages the interactions between specialized agents.
Teams running AI-first approach often report 2 to 10x acceleration across a wide range of tasks, conditional on getting the foundations right first.
Until 2025, humans had to drive agents hands-on. This year, AI agents have advanced enough so that humans no longer need to sit in the driver’s seat. AI agents self-drive while humans provide oversight, governance, and stay in the loop.
One large team made the shift cleanly. Humans set the plans and success criteria, AI executes the implementation and self-verifies, AI iterates on its own until the criteria are met, and humans review and approve the final output. This semi-autonomous approach delivered a 40 to 50% speedup over their previous development loop.
The other results have been just as compelling.
One team’s “Squad of AI Agents” approach drove revenue impact that used to be barely a P25 goal. Another rolled out AI-native workflows targeting 2X-plus productivity, with agents autonomously managing code from authoring through production. A third adopted AI-driven tech debt reduction and gained more than 60% productivity with no quality regression, moving to human-on-the-loop in under 4 months, a transition that usually takes 6 to 12.
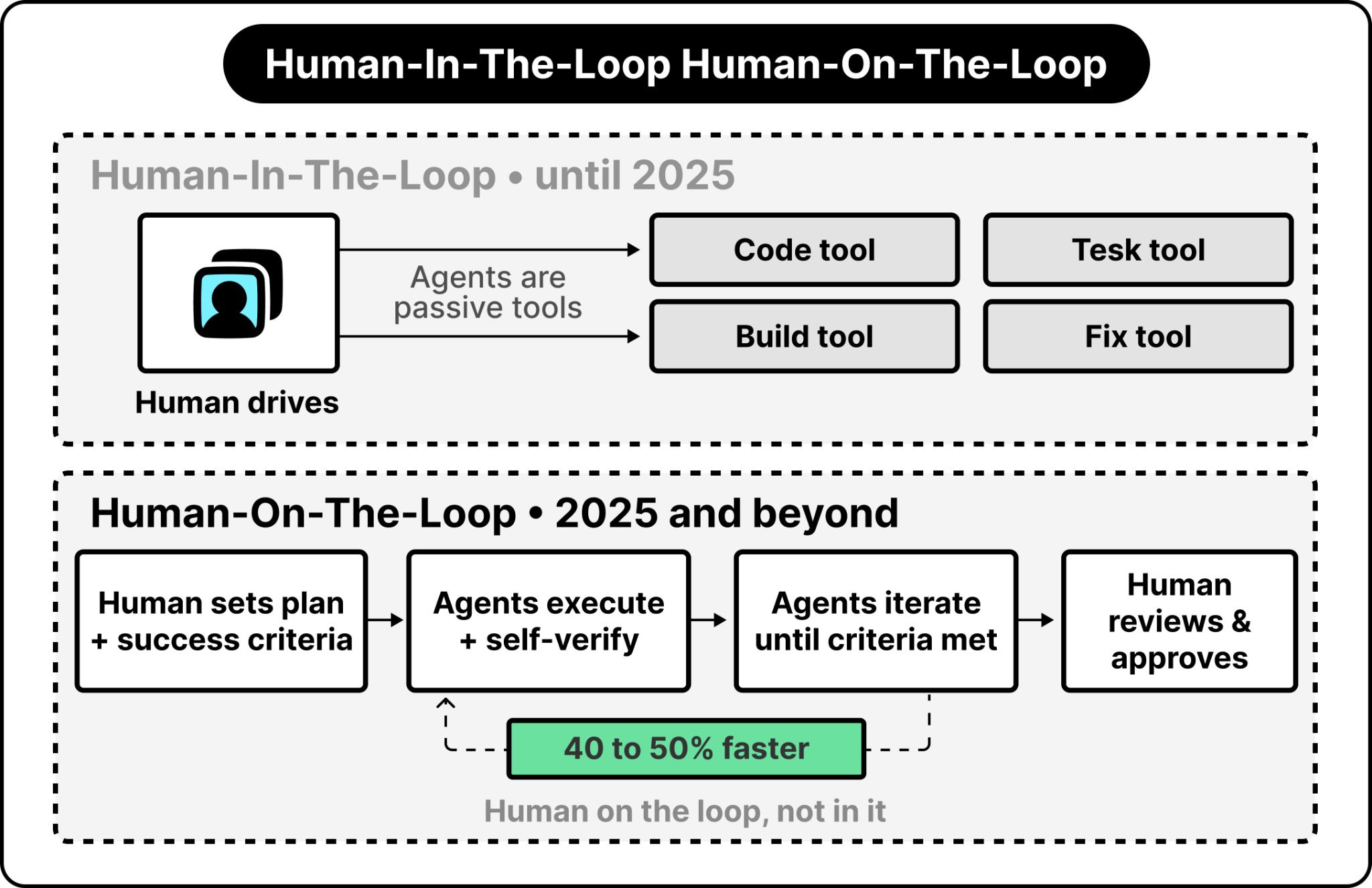
Traditional metrics fall apart when AI generates thousands of lines of code in seconds. Measurement has to move from output-based to outcome-based.
Only 20 to 30% of an engineer’s time is spent coding. Speeding up code generation does not automatically translate into overall productivity. The surrounding work (review, testing, coordination, governance) accounts for the other 70 to 80%, and that is exactly where the bottlenecks form.

Research backs this paradox closely:
McKinsey found developers using AI assistants were 20 to 45% faster on discrete coding tasks, but cautioned that org-level gains were smaller and harder to measure.
Google’s DORA team found AI tools improved individual throughput without automatically improving deployment frequency or change failure rates, absent process changes.
Microsoft Research found a 26% increase in completed pull requests per week, but noted the review burden simply shifted onto other team members.
BCG put it best: real productivity gains require reshaping the work, not just adding tools. The same task done faster matters less than redefining which tasks are worth doing at all.
When one of our teams systematically removed those surrounding bottlenecks, they hit a 1.8 to 2.4x velocity improvement over six months.
Given the productivity paradox, metrics to measure productivity and transformation, must be resilient to the paradox:
AI-First MAU: 75% or more of code AI-generated. Agent-assisted diffs: aim for at least 55% to see meaningful productivity gains. L4-plus AI tool adoption: 80% or more weekly active usage across engineering functions.
For business impact, tie AI usage and productivity gains directly to revenue. Track feature velocity, where the 2 to 10x improvements in prototype-to-production timelines show up. And measure developer experience (satisfaction, flow state, collaboration effectiveness) right alongside the output metrics.
Quality has to be a core metric, not just a guardrail. Watch for “AI slop,” the gradual degradation of a codebase as AI-generated code piles up without adequate review. This is the “nobody’s problem” phenomenon, and it can quietly undermine an entire codebase.
Eight patterns that consistently derail transformation need special attention from every AI-native leader:
Tool bolt-on: AI tools bolted on without redesigning the workflow, producing minimal impact. This is the most common failure mode.
Review bottleneck: Traditional review steps become the throughput limit once AI accelerates generation.
Prompt cargo culting: Teams copy external prompts without context and get poor agent performance. The bottleneck is context engineering skill, not the model.
Metrics gaming: Teams optimize for agent-generated code percentage or adoption stats instead of outcomes.
Security shortcuts: Privileged agents deployed without proper audit controls. Some of the resulting production incidents are real and expensive.
Knowledge debt: Verification and specification fall behind agent-generated work, creating maintainability risk that compounds over time.
Junior pipeline hollowing: Early-career developer experience degrades when human validation gets outsourced to agents. The “missing rung” talent pipeline problem turns into a long-term sustainability risk.
Meeting creep: AI acceleration paradoxically makes room for more frequent syncs with no clear impact. The coordination overhead swallows the time that the faster generation saves.
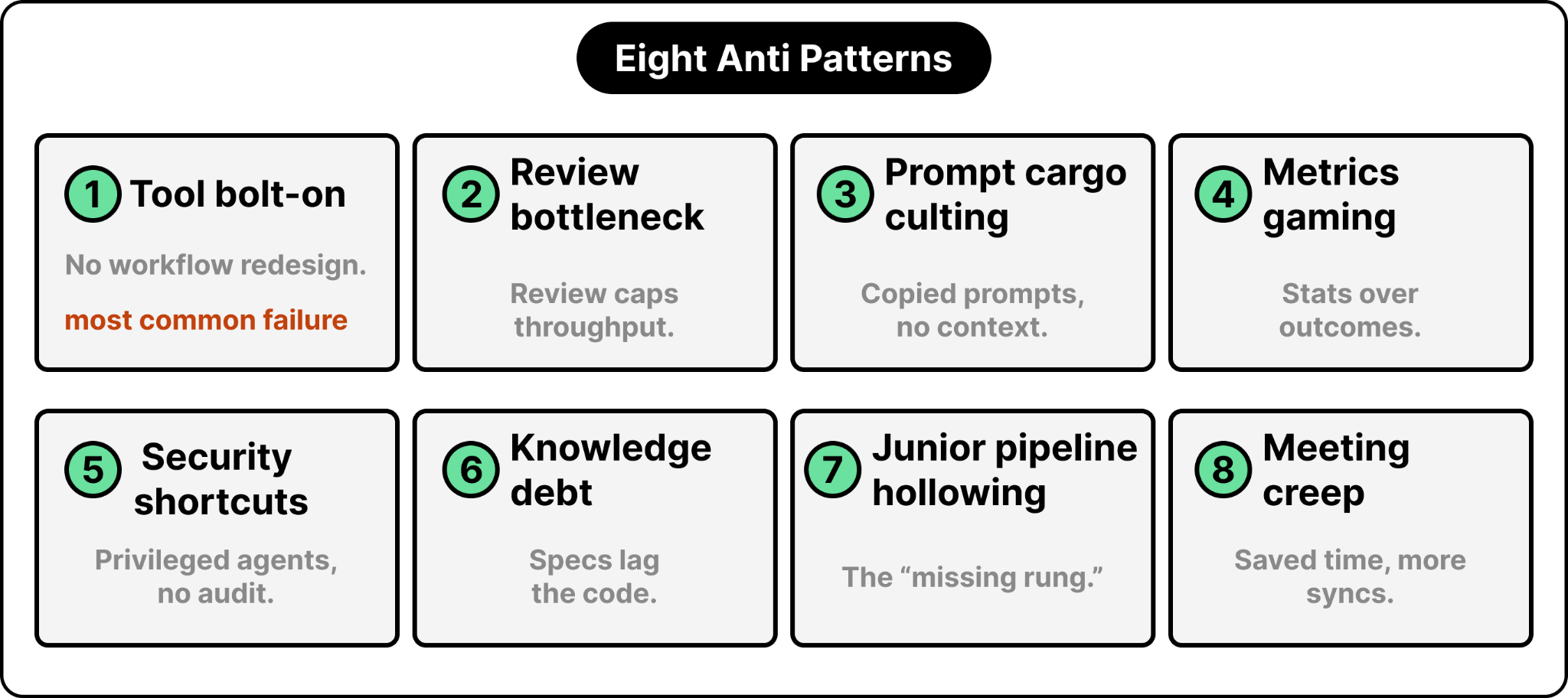
Success depends on systematically detecting these patterns and rolling out with a real change-management framework like ADKAR (Awareness, Desire, Knowledge, Ability, Reinforcement), backed by structured rollouts and feedback loops. Tool distribution and usage metrics alone will not drive transformation.
Now that the AI-native leadership groundwork is in place, here is the phased playbook.
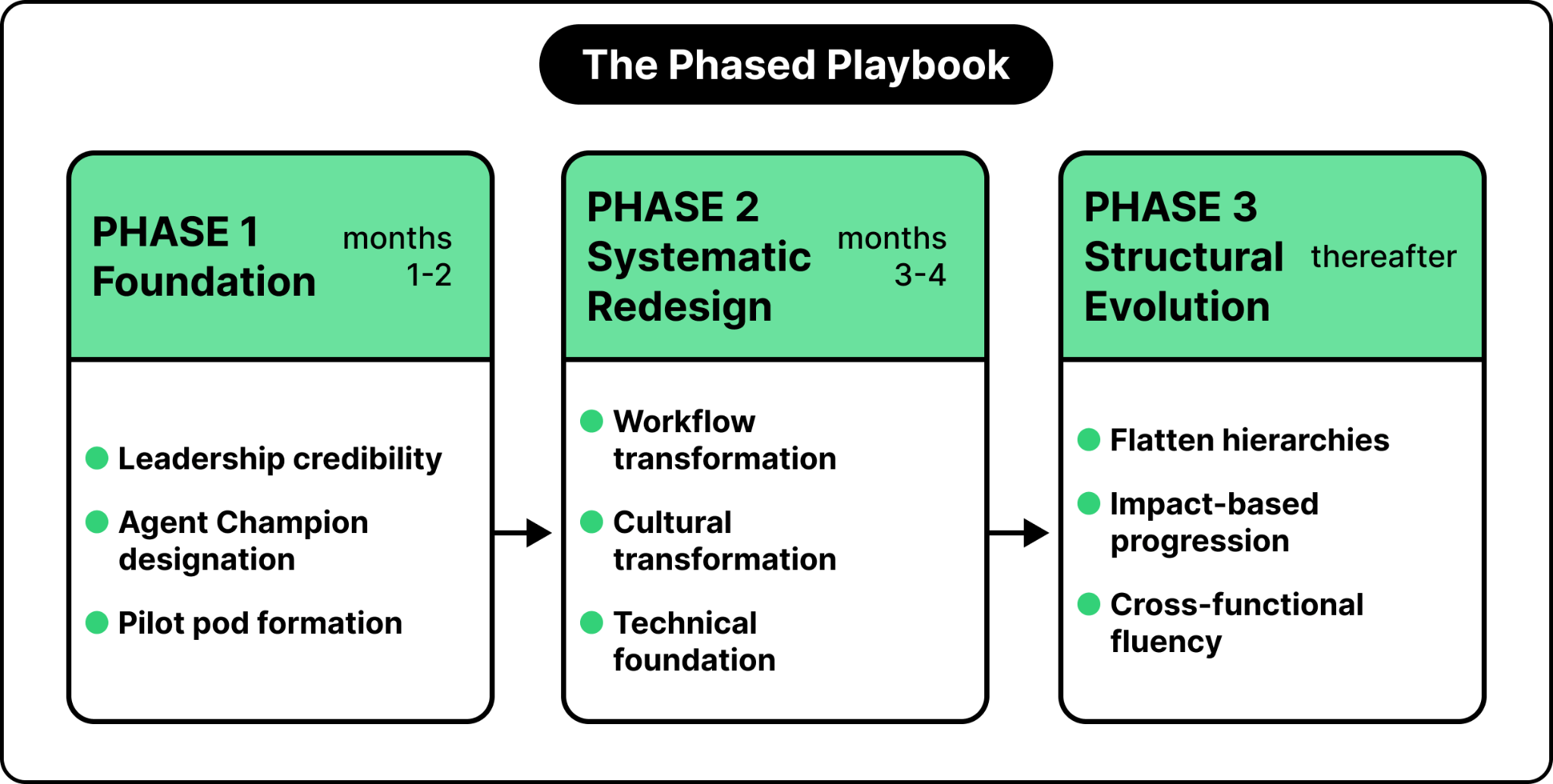
Leadership credibility: Use AI personally every day with measurable goals. Target 50% or more of your daily tasks within 30 days, then push higher. Get hands-on mastery of the tools so your understanding is authentic. Share both successes and failures in public to model the learning mindset.
Agent Champion designation: Identify high-agency technical leaders who can dedicate 50 to 100% of their time. Pull leaders and individual contributors closer together for faster decisions. Set up cross-functional coordination so the whole end-to-end workflow gets transformed.
Pilot pod formation: Start with a codebase AI readiness assessment. Form 3 to 5-person cross-functional teams with autonomous operation charters. Aim them at real problems, not toy exercises, so the momentum is genuine.
Workflow transformation: Audit the high-friction manual workflows that are good candidates for AI. Move from human-in-the-loop to human-on-the-loop. Build AI-readable documentation and specification systems that turn tribal knowledge into shared knowledge.
Cultural transformation: Establish psychological safety: MIT research found 83% of leaders believe psychological safety measurably improves AI initiative success. Formalize “AI failure story” sessions. Shift measurement from output to outcome.
Technical foundation: Clear out dead code, technical debt, and documentation debt to improve AI readiness. Implement sandboxing controls, audit mechanisms, and automated security checks. Build the verification layers that autonomous AI operation depends on.
Flatten hierarchies: Remove the coordination layers that slow AI-accelerated work. AI-native builders and AI-native leaders are what you need (consider the STO model).
Impact-based progression: Reward leverage and outcomes over team size. Define the success metrics that genuinely matter for your organization, and make AI tools and agents your highest-leverage assets.
Cross-functional fluency: Let roles flex as AI removes traditional skill barriers. Break down the walls between product management, design, engineering, data science, and field support, so AI-native builders can move fluidly and accelerate their builds.
Throughout the process, track the compounding gains that show up beyond the initial productivity bump. Connect AI adoption to strategic business metrics. And hold quality standards rigorously, because velocity without quality is a negative value.
Impact scaling: If you shipped 10x faster, would users be 10x happier? If not, you may be optimizing the wrong thing.
Empathy depth: Do you understand your users well enough to delete half the interface? Without empathy, more AI-generated features will not fix products that make users feel incompetent.
Learning velocity: Are you processing real user behavioral data every week? If not, your bottleneck is cycle time to insight, not cycle time to code.
Ownership clarity: Does every major initiative have a single owner? Ownership problems wearing a process-problem costume only get worse under AI acceleration.
Hypothesis discipline: Are you testing theses or building products? If you cannot name the signal that would kill your project, you are committed to something with no user validation behind it.
Here is the counterintuitive truth: AI does not reduce the need for process, it changes what the process is for.
Pre-AI processes coordinated execution among humans. AI compresses execution while raising the cost of deciding what is worth executing. The world now runs on simultaneous builds, parallel experiments, and stacks of prototype iterations. The leadership decisions about what matters, what to cut, and what to double down on become the binding constraint.
Process optimization comes down to three questions:
What are we learning this week? Reward faster, deeper learning across teams.
What are we killing this week? Actively retire the products and agents that lack genuine value.
Who owns each bet, and what signal would change their mind? STOs steer on objective signals, not intuition and not AI-generated content.
Everything else is overhead.
The window for this transformation is narrowing. Organizations that pull it off within the next year will open a 5 to 10x productivity gap over the ones that delay, and that gap will be brutally hard to close as AI-native practices compound.
The organizations that succeed show real advantages in product development velocity, technical innovation capacity, and their ability to attract top talent. The early-mover results (2.4x velocity improvements, 60%-plus AI-generated code, features built in hours instead of days) point to a fundamental capability shift rather than an incremental one. A few closing thoughts.
The scarce resource has shifted. It went from generation and production to orchestration and judgment. When AI generates at near-zero marginal cost, the ability to evaluate quality, set direction, and make the hard calls becomes the bottleneck. Leaders who invest in building AI-native team capability will significantly outperform those who just deploy more agents.
Structural change is mandatory. The productivity paradox is real. Individual gains do not become organizational gains without redesigning the workflows, the measurement systems, and the cultural norms. Remember the famous line, “culture eats strategy for breakfast,” only shines brighter under the AI light. No amount of transformation will save you if the foundations and the structure are not redesigned for the AI-native era.
Risk mitigation is continuous, not a one-time fix. Monitor AI-generated code quality and maintainability so technical debt does not accumulate. Address the security risks (prompt injection, memory corruption, access control, audit compliance) through embedded CI/CD checks. Prevent the “missing rung” talent pipeline problem by developing AI-native engineers at every level. And hold on to human values while you embrace AI acceleration, because human capital keeps paying dividends in the AI-native era when it is applied well.
AI changes the tools. It does not change the core reality. The hard part stays insanely human.