2026-06-01 21:20:00
上一次更新的月度总结是 25 年11月,那时候压力很大,在疯狂地听乔布斯演讲,不知觉间把 "Keep Looking, Don't Settle" 作为我的飞书签名半年多了。
嘴上说着 Dont Settle,然后却 Settle 了 7 个月。不是没有东西写,这七个月发生的事情以往任何时候都要多,无论是 LLM/Agent 技术的发展,还是生活工作中的变化。但越是这样,越想找一个关键的时间节点来重新启动。
直到今天在听吴晓波最新的播客——《Vol.217 两代财经作家的对话:写作与财富,诱惑与尊严,技术的冲击和价值观的剧变》,我一边听一边笑🤣,脑中突然浮现了吴晓波频道的第一篇公众号《骑在新世界的背上》,我翻看了一下,里面吴晓波说:"不做会死吗?不会。但天变得比想象得快"。
对于我:不写月度总结会死吗?不会,但我知道再不写,我想说的话只会越攒越多,直到我自己都忘记了。
我决定全平台改名了。B站、YouTube、公众号、博客,都从"chaofa用代码打点酱油"改成"袁朝发"。
"chaofa用代码打点酱油"不够好,它给我暗含了一种我本来就是随便做做的心态,但我实际上不是想随便做做。
对我来说:"chaofa用代码打点酱油" 不仅是一个名字,是一个跟了我一年多的身份,全网 5W 多朋友认识的是这个名字。改了之后,就是把大家熟悉的一个东西扔掉,我真的舍不得[1]。
现在无论是谁,都能用 Claude/GPT 写一个 80 分的东西,那么别人为什么还要看"chaofa用代码打点酱油"写的文章,录的视频?所以我想,我要为我自己的内容负责,我不会让 AI 接管我的思考;用真名,意味着我写的文章/录的视频是经过我的理解和过滤的,读者/观众看到的是"一线互联网大厂"的实践经验[2]。
最后触发决定的是写书。当我真正开始写书的样章的时候,我会觉得在书的封面印着的应该是"袁朝发",而不是"chaofa 用代码打点酱油",与其等书出了之后再改,不如现在就改。
所以从今天以后,请叫我"袁朝发" 或者 chaofa 🤣。
今年 4 月份,工作稍微可以松口气了;我终于可以开始回应去年 9 月份说的「写书,我要开始了。等我!」。于是我开始联系很久之前的编辑老师,说:"我准备开始写书了"。然后着急忙慌的聊了两次准备了一些材料,
本来以为说了 3 次了,这次总归是真正的了吧。毕竟书名都想好了《大语言模型:从菜鸟到大师》。但没想到这么难,工作上突然又忙起来,加上一些变动,我又没有足够的时间来写作了。材料到现在还没完全准备好,真的很对不起编辑老师。不过书我肯定是继续写下去的,已经开始了,就不会再停了。
这一次,我做好准备了。
以后更新频率当然也是不确定的(以前 flag 大家也看到结果),但有一件事是确定的:以后发的文章、视频,署名都是"袁朝发"。
2026-03-15 06:00:00
读完本文,你将了解:
前置知识:如果你对 Agent 的上下文管理还不太熟,建议先看 Agent 系统中的 Prompt Caching 设计(上) 和 (下),本文会多次引用。
用 Coding Agent 的人大概都有过这种经历:Agent 写了一坨代码,自己看了一眼觉得"嗯不错",然后就停了。测试?没跑。边界情况?没想。你花了 20 分钟等它干活,最后还是得自己收拾烂摊子。
本能反应通常是:"模型还是不够聪明,等 GPT-6 就好了。"
但 HumanLayer 团队在做了上百个 Agent 项目后,得出了一个不同的结论:
"It's not a model problem. It's a configuration problem."
LangChain 用数据证明了这一点:同一个模型(GPT-5.2-Codex),只改模型之外的东西,Terminal Bench 2.0 得分从 52.8 涨到 66.5,排名从 Top 30 到 Top 5。
模型之外的那些东西,现在有了一个统一的名字:Harness。
LangChain 的 Vivek Trivedy 给了一个最干净的定义:
Agent = Model + Harness. If you're not the model, you're the harness.
Harness 就是除了模型权重以外的一切。

这不是抽象类比。打开你的 Claude Code,它的 Harness 具体包括:
| 组件 | 具体是什么 | 解决什么问题 |
|---|---|---|
| System Prompt | 系统提示词,定义行为规范 | 模型不知道自己该扮演什么角色 |
| CLAUDE.md / AGENTS.md | 项目级指令文件,启动时注入 | 模型不知道这个项目的规范和上下文 |
| Tools (bash, 文件读写, 浏览器) | 可调用的工具集 | 模型只能输出文本,不能执行操作 |
| Sandbox | 隔离的执行环境 | 不能让模型直接操作你的生产环境 |
| Compaction | 上下文压缩机制 | Context Rot,长对话性能衰减 |
| Hooks / Middleware | 在模型调用前后插入的逻辑 | 模型不会主动自检、容易死循环 |
| Sub-agent 管理 | 子代理派生和结果回收 | 单个上下文窗口装不下复杂任务 |
如果你读过我之前写的 Prompt Caching 系列,会发现上下文管理、Compaction、子代理架构——这些其实都是 Harness 的组成部分。
My AI Adoption Journey 有一个更偏工程实践的定义:
"Harness engineering is the idea that anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again."
Agent 犯了错 → 不是改 prompt 重试 → 而是改环境让它不可能再犯这个错。这就是 Harness Engineering 的核心思想。
这三个概念的关系经常被误解为"一代比一代强,后面的替代前面的"。但实际上它们是包含关系:

简单区分:
| 管什么 | 解决什么 | 失败了怎么办 | |
|---|---|---|---|
| Prompt Engineering | 一条指令 | 怎么问才能得到好答案 | 改 prompt 重试 |
| Context Engineering | 整个上下文窗口 | 怎么给够信息完成复杂任务 | 调整检索/压缩/隔离策略 |
| Harness Engineering | 模型之外的一切 | 怎么建系统让 Agent 可靠地长期工作 | 改环境让错误不可能再发生 |
换句话说:Context Engineering 解决了"给模型什么信息"的问题,Harness Engineering 还要解决"给模型什么环境"的问题。
社区对这个关系其实有争议:LangChain 认为 Harness ⊃ Context(超集);HumanLayer 认为 Harness ⊂ Context(子集)。
我的判断是超集关系更合理——sandbox、CI gate、linter 这些东西显然不属于"上下文管理",但它们是 Harness 的核心组成部分。不过争论定义意义不大,重要的是意识到:Agent 出问题的时候,除了看"给了什么信息",还要看"跑在什么环境里"。
LangChain 做过一个实验,很好地说明了 Harness 的实际影响。
基线:deepagents-cli + GPT-5.2-Codex,默认配置,Terminal Bench 2.0 得分 52.8。他们只调了三个"旋钮"(原话是 "knobs on a harness"):System Prompt、Tools、Middleware。最终得分 66.5,排名从 Top 30 到 Top 5。
具体改了什么:
最常见的失败模式:Agent 写完代码 → 重读一遍自己的代码 → 觉得"看起来没问题" → 停止。根本没跑测试。
他们加了一个 Middleware:在 Agent 试图退出时拦截,强制注入一个 checklist 让它对照任务说明验证。这本质上是一个 Ralph Wiggum Loop——hook 住退出,强制继续。
Agent 在陌生环境中会浪费大量时间探索目录结构、找 Python 环境。他们在 Agent 启动时自动跑一些 bash 命令扫描环境,把结果注入上下文。
这和我在 Prompt Caching 系列里讲的 Just-in-Time Context 思路一致——在正确的时机注入正确的信息,减少 Agent 自行探索的错误面。
Agent 有时候会在同一个文件上反复做小修改,10+ 次还在原地打转。他们通过 hook 追踪每个文件的编辑次数,超过阈值就注入"考虑换个方案"的提示。
还有一个有意思的发现:GPT-5.2-Codex 有 4 档推理强度(low/medium/high/xhigh),全程 xhigh 反而得分低(53.9%),因为超时了。最终他们用 xhigh → high → xhigh 的"三明治"策略——规划和验证用高推理,执行阶段用中等推理。
这四个改动没有一个涉及模型本身。全是环境和流程的变化。
The importance of Agent Harness in 2026文章中有三条建议:
第三点特别值得展开。Harness 跑的每一次 Agent 任务都在产生数据——成功的路径、失败的模式、工具调用的序列。这些数据可以反馈回训练,让下一代模型更适配 Harness 环境。LangChain 也提到了这一点:模型和 Harness 正在形成共同进化(co-evolution)。
但 The Bitter Lesson 也在起作用。Manus 6 个月重构了 5 次 Harness,Vercel 删掉了 80% 的 Agent 工具反而效果更好。这说明很多当前的 Harness 设计是在弥补模型的不足,模型一进步这些设计就过时了。
Q: 那什么设计是持久的?
我在 Prompt Caching 系列的结尾说过:围绕 Cache 的架构决策是持久的,因为它们不是在弥补模型不足,而是在适配当前 Decoder 带来的物理限制 同样的逻辑:文件系统作为持久存储、sandbox 隔离、版本控制——这些是物理约束决定的,不会因为模型变强而消失。
Harness Engineering 不是一个全新的发明,而是给一系列已有实践起了一个统一的名字。如果你已经在写 CLAUDE.md、配 MCP Server、用 Sub-agent、做 Context Compaction——你其实已经在做 Harness Engineering 了。
核心就一句话:Agent 表现不好,先看 Harness 再怪模型。
2026-03-01 20:00:00
Kimi K2.5 有几个我觉得很值得关注的点:
历史上比较相关的文章,建议对照阅读:
- Kimi K1.5: 深度解读 Kimi-K1.5,真正了解 RL 数据是怎么筛选的
- Kimi K2 (Thinking): Kimi K2 和 K2 Thinking 深度解读:从预训练优化到 Agentic 能力训练的完整流程
- DeepSeek R1: 自顶向下方式深度解读 DeepSeek-R1
本文虽然迟到,但是这篇 paper 真的很值得阅读,感谢老板 push 我做这个分享 🤣
这是本文我认为最值得关注的部分之一。
在 K2.5 之前,业界做多模态训练的普遍做法是:先训练一个强大的纯文本模型,然后在训练后期以高比例(50%+)集中注入大量视觉数据。Kimi K2.5 的消融实验挑战了这一范式。
Table 1 的核心对比如下(固定总视觉 token 预算):
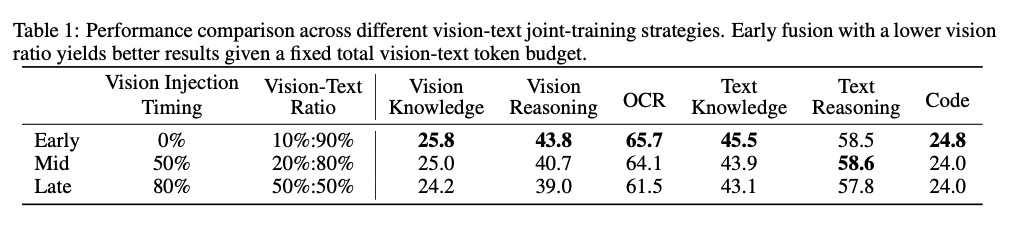
关键结论:Early Fusion + 10% 视觉比例在几乎所有指标上全面优于 Late Fusion + 50% 视觉比例(仅 Text Reasoning 58.5 vs 58.6 略低于 Mid)。
这里需要理解实验设计的约束:三种策略消耗的视觉 token 总量是相同的。Late Fusion 在训练后 80% 才注入视觉数据,为了消化相同总量的视觉 token,它需要把视觉比例提到 50%;而 Early Fusion 从头就混入视觉数据,10% 的比例就能覆盖相同的总量。

Appendix B.1 还展示了一个有趣的 dip-and-recover 现象:Late Fusion 在注入视觉数据时,文本能力会先显著下降再逐渐恢复(modality domain shift),后期强行注入大量视觉数据会对已经稳定的文本表征造成冲击。而 Early Fusion 的训练曲线保持平稳,没有这种 domain shift shock——因为两种模态从一开始就在共同演化。
不过我个人觉得这个现象好像不是很明显的样子,没有我画的图这么明显,还是我不会读图?
预训练之后的模型虽然已经能"看懂"图像,但还不能做复杂的视觉操作(裁剪、测量、计数等)。传统做法是人工标注视觉轨迹数据来教模型。
Kimi K2.5 提出了一个反直觉的方案——Zero-Vision SFT:SFT 阶段只用纯文本数据,所有图像操作都通过 IPython 代码来代理。模型学会用代码描述视觉操作(binarize、crop 等),而不是直接学习像素级的操作轨迹:
# 问题:计算图中绿色区域占比
# 回复
<thought> 需要用 binarization 分离绿色区域 </thought>
import cv2
img = load_image("input.png")
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv, lower_green, upper_green)
ratio = np.sum(mask > 0) / mask.size
答案:绿色区域占比 32.5%
论文做了对比实验:text-vision SFT(加入了人工标注的视觉轨迹数据)效果反而更差。这是因为缺乏足够高质量的视觉数据,加上模型会过拟合于特定标注风格。
个人理解:代码作为桥梁提供了精确的操作语义——cv2.inRange 就是精确的颜色过滤,不存在歧义。同时,前期联合预训练已经建立了视觉-文本的对齐,使得这种泛化成为可能。模型学会的是"用程序化方式处理视觉信息"的抽象能力,而不是记忆特定的视觉操作模式。这也呼应了后面预训练数据中 image-code paired data(HTML/React/SVG 代码 + 对应渲染截图)的设计——代码是一种既能被精确验证、又能描述视觉操作的通用语言。
这是另一个反直觉的发现。视觉 RL 训练之后,不仅视觉能力提升了,文本 benchmark 也提升了:
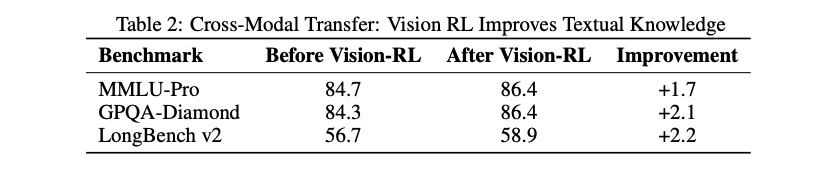
这是因为:视觉 RL 增强了模型对结构化信息提取的校准能力(calibration),这种能力迁移到了类似需要结构化信息提取的文本任务中。
值得注意的是 K2.5 联合多模态 RL 的设计选择:RL 训练是按能力维度(knowledge / reasoning / coding / agentic)来组织 domain 的,而不是按模态(text / vision)分开训练。这和 DeepSeek-GRM 跨模态优化的思路一致——按能力组织确保了同一能力维度下的文本和视觉任务共享 reward 信号,最大化了跨模态迁移。
现有的 Agent 系统(包括 Kimi K2 Thinking)大多是单 agent 顺序执行:每一步推理都依赖上一步的结果。这意味着任务复杂度增加时,执行时间线性增长,上下文窗口也很快被占满。对于需要大规模信息检索和多源交叉验证的复杂任务,这种线性增长是不可接受的。
K2.5 提出了 Agent Swarm,核心是 PARL(Parallel-Agent Reinforcement Learning)框架。
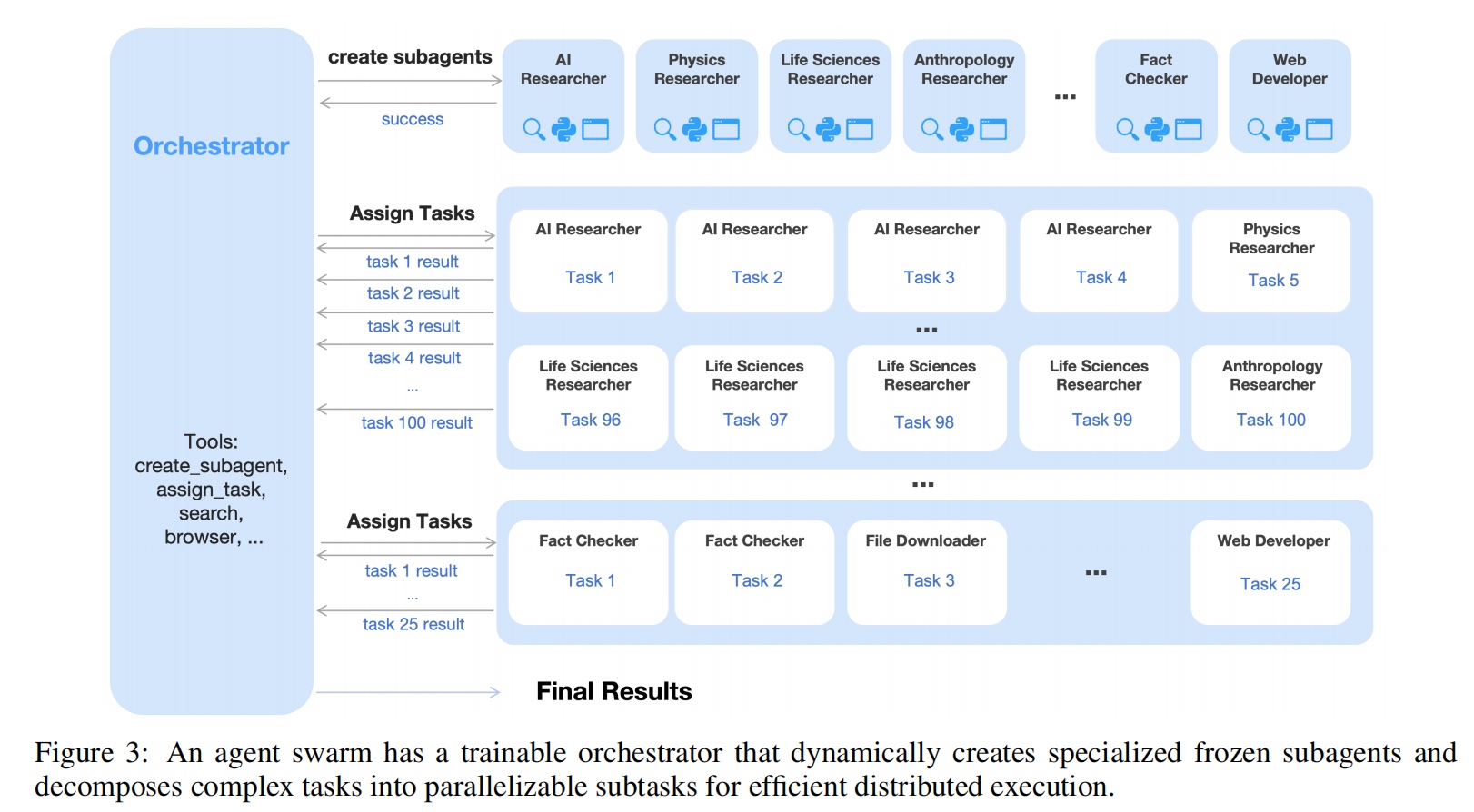
核心设计是 可训练 Orchestrator + 冻结 Sub-agents。Sub-agents 从训练过程中间 checkpoint 提取,参数冻结不参与 RL 优化。
为什么不做端到端的 co-optimization? 有两个原因:
因此 sub-agent 的输出被视为"环境观测"(environment observation),orchestrator 只观测 sub-agent 的输入→输出映射,学习的是何时创建、如何分配、何时聚合。
个人理解:这让人想到多 Agent 群体通信和协同进化的思路。K2.5 的 Agent Swarm 是一个初步探索——orchestrator 通过 RL 学会了动态创建异构 sub-agent 并调度。注意这里的 sub-agent 不是预设的固定角色(如 Coder/Researcher/Writer),而是根据任务动态创建的(如"Quantum-Researcher"、"Pharma-Analyst"),这种专门化是涌现的,不是预设的。
训练并行编排器需要解决两个典型的失败模式。PARL 设计了三项 reward:
| 组件 | 功能 | 解决的失败模式 |
|---|---|---|
| $r_{parallel}$ | 奖励创建 sub-agent 的行为 | Serial Collapse(串行坍缩):orchestrator 退化为单 agent 顺序执行,完全不用并行 |
| $r_{finish}$ | 奖励 sub-agent 的完成率 | Spurious Parallelism(虚假并行):创建一堆 sub-agent 但不完成任务,只是刷 $r_{parallel}$ |
| $r_{perf}$ | 任务级最终性能 | 真正的优化目标 |
训练过程中 $\lambda_1, \lambda_2$ 逐渐退火到 0,确保最终只优化 $r_{perf}$。这是一种常见的 RL 训练技巧:先用辅助 reward 做 shaping 帮 agent 跳出局部最优,再让辅助 reward 消失回归真实目标。
举个具体例子:假设任务是"调研量子计算在药物发现中的最新进展并撰写综述":
如何度量并行执行的实际时间成本?论文定义了 Critical Steps(关键步数):
其中 $S_{main}^{[t]}$ 是第 $t$ 阶段主 agent 的步数,$S_{sub, i}^{[t]}$ 是第 $t$ 阶段第 $i$ 个 sub-agent 的步数。
这个定义等价于计算图的关键路径长度:每个阶段的耗时取决于最慢的那个 sub-agent。通过约束 Critical Steps 而非 Total Steps,模型被激励去做真正减少 wall-clock 时间的有效并行,而不是创建大量但低效的并发。
实验结果方面,Agent Swarm 在搜索类 benchmark 上带来了 3x-4.5x 的延迟降低,同时准确率也有提升(比如 BrowseComp 从 60.6% 提升到 78.4%)。
Agent Swarm 还有一个值得关注的副产品:主动的上下文管理。
传统的 context management 都是被动策略——上下文快满了就丢弃旧内容(Discard-all)、隐藏工具输出(Hide-Tool-Result)或做摘要(Summary)。这些都是信息已经膨胀之后的补救。
Agent Swarm 提供了一种主动的 context sharding 策略:每个 sub-agent 维护独立的局部 context,只有任务相关的输出返回给 orchestrator。orchestrator 不需要看到每个 sub-agent 搜索了什么网页、执行了什么中间代码,只需要看到最终结论。这实现了信息的局部性和模块化。
K2.5 的 RL 优化目标:
其中 $\log\text{ratio} = \log \pi_\theta(a_t|s_t) - \log \pi_{old}(a_t|s_t)$。注意 Clip 作用于概率比值(ratio)而非 log-ratio,最后的 $(\log\text{ratio})^2$ 项是 KL 正则化项,用于进一步约束策略偏移。
与标准 PPO clipping 的关键区别:K2.5 严格基于 log-ratio 的区间 $[\alpha, \beta]$ 做 gradient masking,不依赖 advantage 的符号来决定 clipping 方向。直觉上,PPO 的 clipping 是"根据 advantage 好坏来决定是否限制更新幅度",而 K2.5 是"不管 advantage 好坏,只要策略偏移超过阈值就截断梯度"。
这对 K2.5 的场景很重要:在长程多步工具使用任务中(如 Agent Swarm 的上百步工具调用),trajectory 非常长,off-policy divergence 在长 trajectory 中会被逐步放大。更严格的 token-level 约束能更好地控制策略偏移。这也是从 Kimi K1.5 延续过来的设计思路。
问题定义:RL 训练中有一个矛盾——如果用 budget 约束(限制输出长度)来提升 token 效率,模型会学到"短答案捷径"(length overfitting),导致在测试时无法利用更多的 compute 进行深度推理。
回顾一下进化路线:K1.5 的做法是在 reward 中直接加长度惩罚,公式很简单——越长奖励越小。这种方式比较粗暴,容易导致模型在需要深度推理时也输出过短的回答。
K2.5 的 Toggle 通过交替训练更优雅地解决了这个矛盾:每 m 个 iteration 切换一次 phase——
其中 $\text{budget}(x) = Q_\rho(\{\text{len}(y_i) \mid y_i \text{ is correct}\})$ 是正确回答长度的 $\rho$ 分位数,$\bar{r}_{perf}$ 是当前 batch 的平均准确率,$\lambda$ 是准确率阈值。只有当模型整体准确率已经够高($\bar{r}_{perf} > \lambda$)时,才对超过 budget 的回答施加惩罚。
两个 phase 交替训练,让模型同时学会"简洁推理"和"深度推理",而不是在同一个 reward 中权衡两者。这和 AdaCoT/AdaThinking 中自适应快慢思考的思路有相通之处,但 Toggle 是在训练阶段解决问题,而 AdaCoT 是在推理阶段。
实验结果:Toggle 实现 25-30% 的 token 减少,同时性能几乎无损甚至略有提升。
K2.5 的 reward 设计覆盖面非常广,这里挑几个值得关注的。
K2.5 使用了生成式奖励模型,和 DeepSeek-GRM 的思路一致:
有一些不太常见的视觉 reward 设计值得关注:
对于有明确答案的任务(数学、代码),使用 rule-based 的 outcome reward。在 Toggle 的 Phase 0 中,额外叠加 budget-control reward 来约束输出长度——当输出超过 budget 时惩罚,在 budget 内则不影响。
K2.5 和 Kimi K2 共享同一套 MoE 架构——1T 总参数、32B 激活参数(~3.1% 激活)、384 个 Expert(每 token 激活 8 个,稀疏比 48x)。K2 的 MuonClip 优化器(Muon + QK-Clip,实现 15.5T token 零 loss spike 训练)也被原封不动地继承。需要注意的是,K2 是纯文本模型(原文:"pre-trained on 15 trillion high-quality text tokens"),K2.5 的核心工作就是增加原生多模态和 Agent 并行能力。
K2.5 在 K2 基础上的核心增量是:
| 维度 | K2 | K2.5 新增 |
|---|---|---|
| 模态 | 纯文本 | 原生多模态(文本 + 图像 + 视频) |
| 视觉编码器 | - | MoonViT-3D(基于 SigLIP-SO-400M) |
| 预训练 | 15.5T 文本预训练 | 在 K2 结构基础上三阶段:ViT → Joint → Long-context |
| 上下文长度 | 128/256k | 扩展到 262K(看表格) |
| SFT | 文本 + Agentic 数据 | 新增 Zero-Vision SFT(纯文本激活视觉) |
| Agent | 单 agent 顺序执行 | Agent Swarm(PARL 并行编排) |
| Token 效率 | — | Toggle 交替训练(-25~30% tokens) |
先简要介绍一下 ViT(Vision Transformer)的基本原理,帮助不熟悉的读者理解后续内容。
ViT 的核心思想就是把图像当成 token 序列来处理:把图像切成若干个 patch(通常是 16x16 像素),每个 patch 就相当于 NLP 中的一个 token。然后加上位置编码(让模型知道每个 patch 在图像中的空间位置),送入标准的 Transformer Encoder 处理,最后输出视觉特征。

K2.5 使用的 MoonViT-3D 在标准 ViT 基础上做了三个关键改进:
MoonViT-3D 继承自 SigLIP-SO-400M,整体架构是 MoonViT-3D + MLP Projector + Kimi K2 MoE(1T 总参数,32B 激活参数,384 个 Expert,每 token 激活 8 个)。
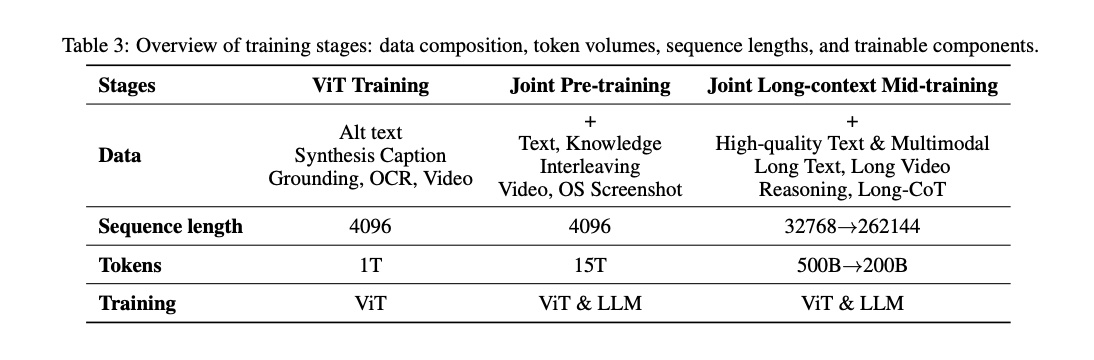
第一阶段只训练 ViT,让视觉编码器先具备基本的视觉理解能力。第二阶段开始联合训练 ViT 和 LLM——这正是前面消融实验中 Early Fusion 策略的实现,从 15T token 的联合预训练一开始就以 ~10% 的比例混入视觉数据。第三阶段逐步扩展到长上下文(32K → 262K)。
附录 B 披露了一些有意思的数据构建细节:
代码数据增强:除了常规的代码数据,K2.5 还加入了 repo-level 的代码(完整仓库结构)、GitHub Issues / Code Reviews / Commit History。这类数据帮助模型理解代码的演进过程和协作模式,对 agentic coding 任务(如 SWE-Bench)很有帮助。
视觉数据 7 类:caption、interleaving、OCR、knowledge、video、agent、grounding。其中特别值得注意的是 image-code paired data——HTML/React/SVG 代码与其对应的渲染截图配对。这种数据直接建立了从视觉布局到代码实现的映射,对 web 相关的 agent 任务(如 OSWorld、Computer Use)至关重要。
简要提一下 infra 层面的创新。多模态训练的一个难点是视觉编码器通常只在 Pipeline Parallelism 的第一个 stage 运行,导致负载不均。DEP 将视觉编码器解耦为独立进程,让所有 GPU 并行处理视觉数据,消除了这个瓶颈。效果是多模态训练效率达到纯文本训练的 90%。
读完 K2.5 的论文,几个核心启发:
联合训练 > 分阶段训练,而且比例不是越多越好。在固定视觉 token 总预算的约束下,10% 的视觉数据比 50% 效果更好,关键在于注入时机(从头注入)而非数量。这对多模态模型的训练策略有直接的指导意义:与其在后期堆视觉数据量,不如在早期就建立跨模态的联合表示。
代码是跨模态的通用桥梁。Zero-Vision SFT 的成功说明代码提供了一种精确的操作语义,可以作为文本和视觉之间的桥梁。
Agent 并行化可以通过 RL 训练出来,而不需要预设规则。Orchestrator 通过 PARL 自然学会了何时并行、如何分配、何时聚合,这种能力具有泛化性。而且 PARL 的 reward 设计(auxiliary reward shaping + annealing)可以推广到其他需要"引导探索"的 RL 场景。
Token 效率优化的技术在不断演进:K1.5 的长度惩罚 reward → K2.5 的 Toggle 交替训练 → 配合 Token-level Clipping 控制策略偏移。这条技术路线越来越精细,越来越接近"让模型自主决定何时简洁、何时深入"。
从 K1.5 到 K2 到 K2.5,每一代都在前一代的基础上解决了新的核心问题,而且技术方案的设计越来越优雅。
2026-02-24 00:07:00
折腾妈妈九个多月的乎乎出生了,我很开心。尤其是前段时间,抱着她,转过头的一瞬间突然叫一声「爸」,顿时有些恍惚,原来不知不觉间已经能隐约发出「爸」的声音了。
一个月前,点点说:“在我们决定要娃的时候,你说,「乎乎出生后,我所有的业余时间都会用来陪乎乎」,但你没有,你不是一个好爸爸。” 事实确实如此,2025 年是我自工作以来最忙碌的一段时间,各方面的事情都非常的多,我没有很多的时间陪乎乎导致点点有一周很崩溃,离家出走。我也因各种事情搞得头昏脑胀的,一度觉得只有不上班或者离婚才能解决问题[1]。
我尝试过每天通勤回龙岗,但是坚持不了几天身体就承受不住了,每天上班都脑袋昏昏沉沉;也试了带睡几天,可是心脏直砰砰的跳,根本睡不着,生怕要自己先猝死了。我时常想,其他人是怎么平衡工作和家庭的呢?是我精力太差了,还是其他人精力太好了呢?
我不是一个好爸爸,按照点点平时给我的打分,我只有 B-。过年放假的时候倒是花了更多的时间陪孩子,但如果工作忙起来,我周末还能有能量这样吗?希望 26 年能到 A,让乎乎和点点都给我打分,靠更频繁的奖励信号纠正爸爸不当的行为。
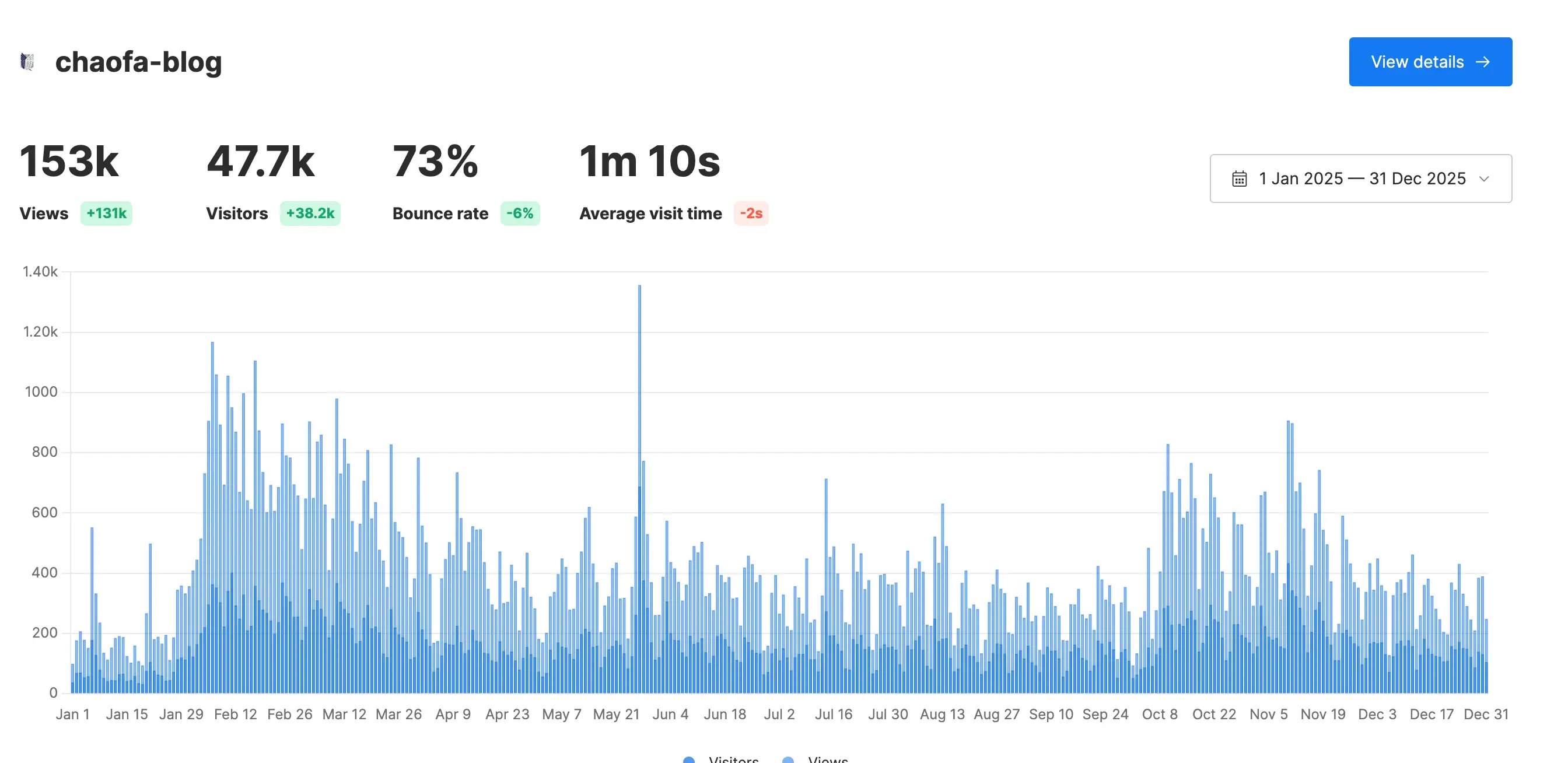
第一个部分其实也提到了工作,似乎核心就一个字「忙」,但真有这么忙吗?也许是有的,有几个离职的同事都表示变好了。但忙出了什么东西吗?我觉得也是有的,团队的业务产出其实都挺好的,当然 2025 年全年来说,我个人产出也是超出自己预期的[2],也有更多的思考🤔,至于别人怎么看便不得而知了。
这一年,我自己的工作主线是:Agent 落地。主要的目标是:给模型更多的「自主决策空间,Let Agent to have More Agency」,主要的方式也和业界主流发展方式一致,围绕着两点:「更好的 Context」以及「给定 Context 下更好的执行」。由于今年是我做公开表达更多的一年,因此对于业界发展的跟进是比较快的,比如近期 Claude Code / Codex 都发表了一些关于 Prompt Caching 对于 Agent 设计的影响,我春节期间也写了三篇文章来介绍「Agent 系统中的 Prompt Caching 设计」。
此外,今年也暴露了自己比较大的问题:更擅长自己执行而不是协作。因为今年自己作为子项目 Owner,需要对于项目的进度有更强的规划和跟进能力。尽管现在都在强调 AI 时代要充分发挥个体能力,但是就目前(2026-02-23)而言,我觉得协作能力还是挺重要的,因为协作是意味着多线程的管理和表达能力,这在 AI 时代更是放大人与人区别的关键点。
其实大模型越来越强,我越来越焦虑,牛逼的人已经产出 100X,而自己的效率却没有本质变化。我仿佛看到了上个改革开放年代或者更近的所谓的移动互联网腾飞之年,有大量的人攫取了巨大的财富,仿佛是个人都能吃上所谓的时代红利,但大多数人,浪潮过后好像也没什么变化。
而这一次,AI 巨浪滚滚向前,又创造了一大波造富神话,身处其中,感觉每天都是翻天覆地的变化,各种新的产品怎么也跟踪不过来;但似乎:每一个好像都和我没什么太大的关系,我能提升效率吗?我能赚更多的钱吗?我能更快到达自由的彼岸吗?所以更大的可能性是:浪潮过后,自己什么也没得到,就像哪些在历史机遇中平平淡淡的大多数人一样。
去年,我在年终总结的时候写:2024年是公开表达元年。是的,2025 年,我尝试了更多的个人表达:
我在多次的月度总结中提到「商业化」,比如:2025-08-孙宇晨真的很值得学习,2025-09-合法赚钱就是高尚的,2025-10-一个程序员对自媒体商业化的深度复盘等,如果不明所以的朋友可能会觉得赚了很多钱,但事实远非如此,加起来半个月工资都不到,可以说这方面是比较失败的。
但也不是完全没有收获,我觉得通过视频商业化的尝试,我理解了很多的商业化行为,对于完整的商业化闭环也有了更深入的思考——打工是一个「期望风险更低」「期望收获更高」的商业化行为[4]。
由于前面的尝试以及认知,我不能再花时间去接所谓的商单了,我觉得商单确实是一种毒药,看上去好像赚了点小钱(见第一段),但实际上挺麻烦的,付出和收入不成正比。还是需要找到自己核心的竞争力和核心产品,才可能真正占用尽量少业余时间获得更高的复利。
此外,由于后面商单的出现,我甚至开始有点羞于向别人说:我做了一个技术频道叫做 chaofa 用代码打点酱油,对标油管的 Andrej Karpathy[5]。所以 2026 年 1-2 月的时候,有 4 个新商单找我,我都拒绝了[6],我还是想做更纯粹的表达(当然肯定是想赚钱的,所以还在拧巴中)。
所以以后会怎么样呢?暂时还不知道🤷♀️

工作自不必多说,依然是2026 最需要重点投入的事情,要积极跟进前沿,与 LLM 多多探讨业务、技术的发展,争取在工作上有进一步的突破。
另外,生产变革也已经发生,生产方式已经发生了巨变,尤其是已经看到非常多的人在 AI 的加持下做出了让人瞩目的成绩,所以 2026 要更加彻底的拥抱 AI Coding,应该说在创造一些自己的 Product,而不是隔岸观火。
所以我斥巨资买了一个域名叫做:ApeCode.ai,代码都会放到 github.com/ApeCodeAI 下,Slogan 想了好多有意思的:
写于:2026 年 2 月 23 日 20:38:56 新年春节假期返工前一天晚[7]
实际上我和点点几乎没有什么矛盾,目前也没有太大的经济压力,只是人都会有情绪崩溃的时候,造成一些不可思议的想法。「不是客观上带孩子时间的问题,而是在带孩子的情绪价值和参与度上的问题」导致点点觉得我投入不够。 ↩︎
工作这么多年,虽然也有绩效不错的时候,但我很少自己给自己评价超出预期(这只是说的自我评估,我并不知道真实绩效)。不过这一年,不管别人怎么看,我自己是尽全力了,业务产出也还不错。另外,由于 25 年也作为面试官面试了非常多的候选人,让我对各种事情有了更加深刻的认识,也让我更加坚定的要建立一套自己的评估体系。 ↩︎
我记得 11 月度总结的时候,我说:还有一个月就 2025 年全勤了,没想到最后功亏一篑了。有朋友可能会问,AI 写得比你写得好多了,为什么不用 AI?我的答案是:这一类个人思考和总结的东西,我不想用 AI,因为本来是写给自己看的,如果我不知道「下笔的时刻我在思考什么」,那么写出的文章又有什么意义呢?思考过程的本身比结果更让人着迷。要是对此感兴趣的同学也可以关注:公众号——chaofa 用代码打点酱油 ↩︎
正好对应了我一直说的,打工一定要投入更多的时间。公开表达只能是业余时间中 20% 的精力,因为收益真的没想象中高。自媒体是一个极度放大幸存者偏差的地方。Keep it in mind. ↩︎
这是最初的愿景,因为我也是完全从零手写代码/或者读一些前沿的论文,这也是吸引很多「专业」的同行的原因,因此我的视频受众有非常多各种大厂在职的算法工程师。 ↩︎
26 年 1 月份的发的两个视频都是元旦期间做的,都是很早很早以前接的,只是平常时间做 ↩︎
忽然想起导演 BK 写心动 CEO 的黄一孟的一篇小短文,"儿子出生的那天,他开车回家走在高架桥上,对面的夕阳照进他的车里,洒在他的脸上,他很幸福。事业成功,家庭幸福,儿女双全,这是黄一孟人生中最开心的时光"。 ↩︎
2026-02-22 23:06:00
读完本文,你将了解:
前置知识:本文是 Agent 系统中的 Prompt Caching 设计(上) 的续篇。如果你还没读过,建议先了解 Cache 破坏机制、Prompt 布局和工具管理策略。更基础的概念见 理解 KV Cache 与 Prompt Caching。
Anthropic 的研究指出:随着 context 中 token 增加,模型注意力分散,性能下降。
Attention 中每个 token 要和所有其他 token 建立 $n^2$ 的 pairwise 关系。Context 越长 → 每个 token 的"注意力预算"越少 → 模型可能"忘记"早期的重要指令,或被大量 tool output 稀释关键信息。
更大的 context window 不是万能解药。 能塞进去不代表模型能有效利用。
这就是为什么 Agent 不能简单地把所有信息堆进 context——我们需要主动管理。
压缩是解决 context 增长的关键手段,但必须是 cache-safe 的。
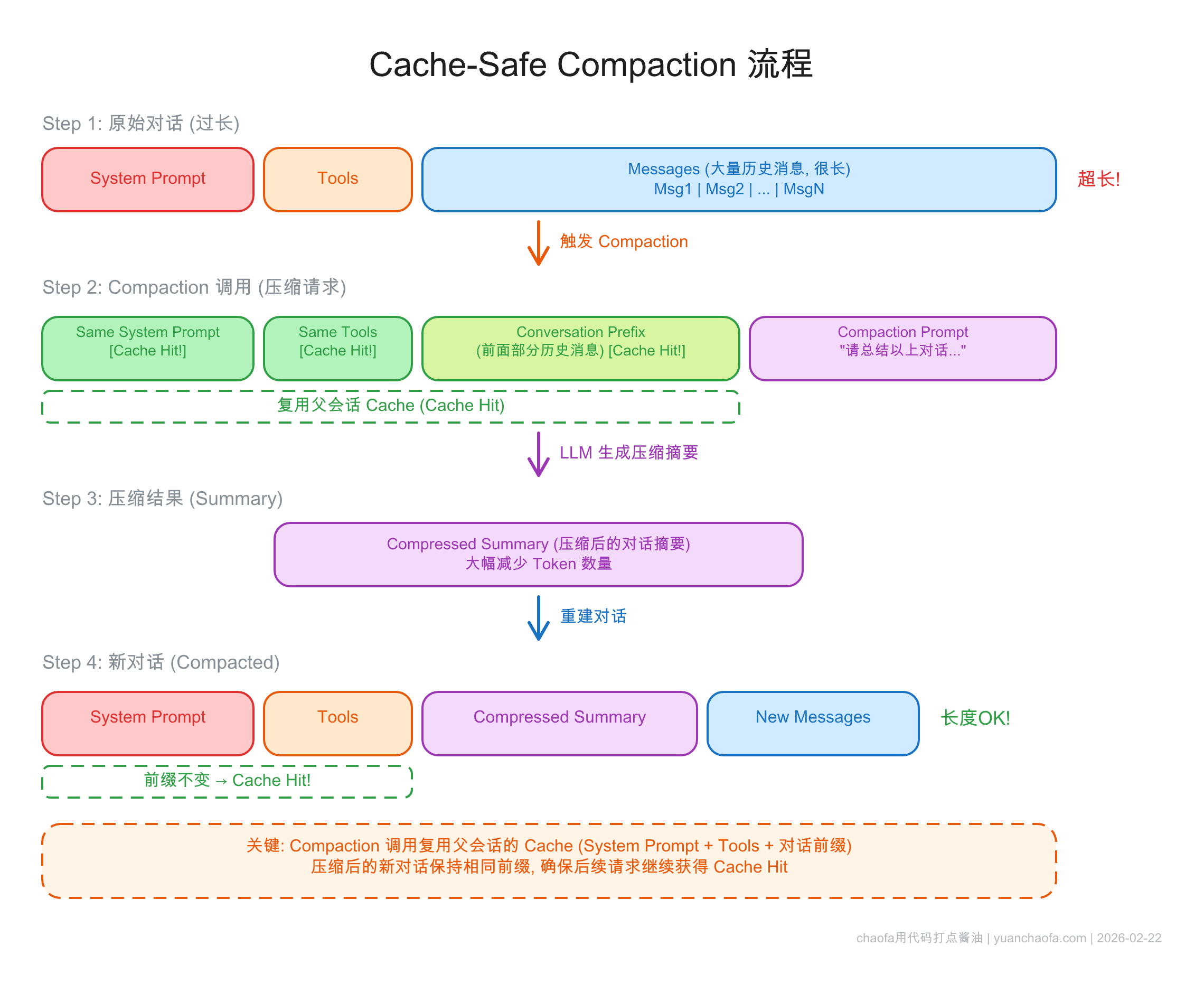
Claude Code 的压缩策略非常精巧:
Codex 提供专门的 API 端点:
auto_compact_limit 自动触发两者共同点:压缩是必要的,但压缩过程本身不能破坏已有的 cache。
Agent 如何确保模型"聚焦"在正确的事情上?三家有一个有趣的演进过程。
todo.md → 约 1/3 actions 浪费在更新 todo 上!EnterPlanMode
| 方案 | 独立阶段? | 用户审批? | 自主控制? |
|---|---|---|---|
| Manus planner agent | 独立 agent | 无需审批 | Agent 决定 |
| Claude Code Plan Mode | 独立阶段 | 需要审批 | 模型可自主进入 |
| Codex update_plan | 也有独立阶段 | 无需审批 | 执行中随时调用 |
一个有趣的共识:不要删除失败的 action 和 observation。
Manus 不会从 context 中删除失败的工具调用结果。双重好处:
错误恢复是真正 agentic 行为的标志。 看不到自己犯的错,怎么学会避免?
Agent 不需要把所有信息都放在 context 里——文件系统可以作为"延展记忆"。
| 方案 | 预加载 | 按需检索 |
|---|---|---|
| Claude Code | CLAUDE.md | glob/grep 搜索文件系统 |
| Codex | AGENTS.md | shell 工具探索 |
| Anthropic 建议 | 最少必要信息 | JIT 检索 |
共同点:用 glob/grep 搜索文件系统,无需向量索引。这和 Agentic RAG 的思路一脉相承——Agent 自主决定搜索什么,而不是被动接受检索结果。
Cache 是 model-specific 的。各家的做法:
Claude Code 架构(逆向分析数据):
| 子代理 | 工具数 | Prefix Reuse |
|---|---|---|
| Main Agent | 18 | — |
| Explore × 3 并行 | 10/18 子集 | 92% |
| Plan | 独立 context | 93% |
| Execution | 全部 | 97% |
Claude Code 还使用 warm-up 调用:启动时预热 tool list 和 system prompt 的 cache。
Manus 多代理架构:
submit_results 工具 + 约束解码确保输出格式Anthropic 建议:子代理返回压缩 summary → 避免主 context 被"污染"。
Fork 出的子任务必须用和父对话相同的 prompt prefix,才能复用父对话 cache。
Claude Code 在 compaction、summarization、skill execution 中都遵循这个原则。核心思想:压缩/fork 是在现有 cache 基础上的延伸,而非另起炉灶。
最后分享 Manus 的反思,引用 Rich Sutton 的 "The Bitter Lesson":
Agent 的 harness(框架/约束)可能限制模型性能。随着模型进步,需要不断简化架构。
Manus 自 2025 年 3 月以来已重构无数次。每次模型能力提升,某些 workaround 就变得不必要。
但有些设计是"持久"的——围绕 cache 的架构决策就是。它们不是在弥补模型不足,而是在适配计算的物理现实。
Cache 是物理约束,不是工程 hack。 只要 Prefill 还是 Compute Bound,Prompt Cache 就会继续是 Agent 架构的核心考量。
备注:本文主要受前 4 篇参考内容的启发
2026-02-22 18:16:00
读完本文,你将了解:
前置知识:本文假设你已经理解 KV Cache、Prefill/Decode 两阶段、以及 Prompt Cache 的前缀匹配机制。如果不熟悉这些概念,建议先阅读 理解 KV Cache 与 Prompt Caching:LLM 推理加速的核心机制。
在深入细节之前,我想先分享我对这个话题的理解:
Prompt Cache 不只是一个省钱技巧,它是 Agent 系统架构设计的核心约束。
就像数据库的 schema 设计会影响整个应用架构一样,Prompt Cache 的前缀匹配约束深刻地影响了 Agent 的每一个设计决策:
我们已经越来越多地听到 "Context Engineering" 这个术语。区别在哪?
Manus 在 25 年底最新总结中提出了三个维度:Reduce(缩减)、Isolate(隔离)、Offload(卸载)。
后面的内容你会看到,各家的设计都在围绕这三个维度展开。
不同公司、不同架构,但核心规律惊人地一致:
带着这些规律,我们来看具体的实践。
Agent 每一步都需要发送完整的对话历史给模型,模型只输出一小段。Manus 披露过一个数据:input:output ≈ 100:1。
如果没有 Prompt Cache → 每一步重新 Prefill 所有历史 token → 成本二次方增长。
| 场景 | 不缓存 | 缓存后 | 节约 |
|---|---|---|---|
| Claude(正常 vs cached) | $3/MTok | $0.30/MTok | 90% |
| OpenAI GPT-5(正常 vs cached) | $10/MTok | $2.50/MTok | 75% |
| Claude Code 单任务(约 2M tokens) | ~$6.00 | ~$1.15 | 81% |
Thariq(Claude Code 团队):
"Coding agents would be cost prohibitive without prompt caching."
OpenAI Codex:cache 命中后,采样开销从二次降为线性。
前缀匹配是一切的基础:任何位置的任何改动 → 该位置之后的 cache 全部失效。
在开头放时间戳——Manus 踩过的坑。时间戳每秒都变,第一个 token 就不同,整个 cache 废掉。
Claude Code 团队经验中最常见的 cache 破坏方式。Tool definitions 在 prompt 前部,增删任何一个工具 → 后续所有 cache 失效。
具体场景:
allowed_subagents 列表变化Cache 是 model-specific 的。
一个反直觉推论:100K token 对话中,切换到更便宜的模型可能更贵 —— Opus 的 100K cached token 只需 $1.50,换 Haiku 后全部重算。
核心原则:序列化必须是确定性的。
核心思路:把稳定的内容放前面,把变化的内容放后面。
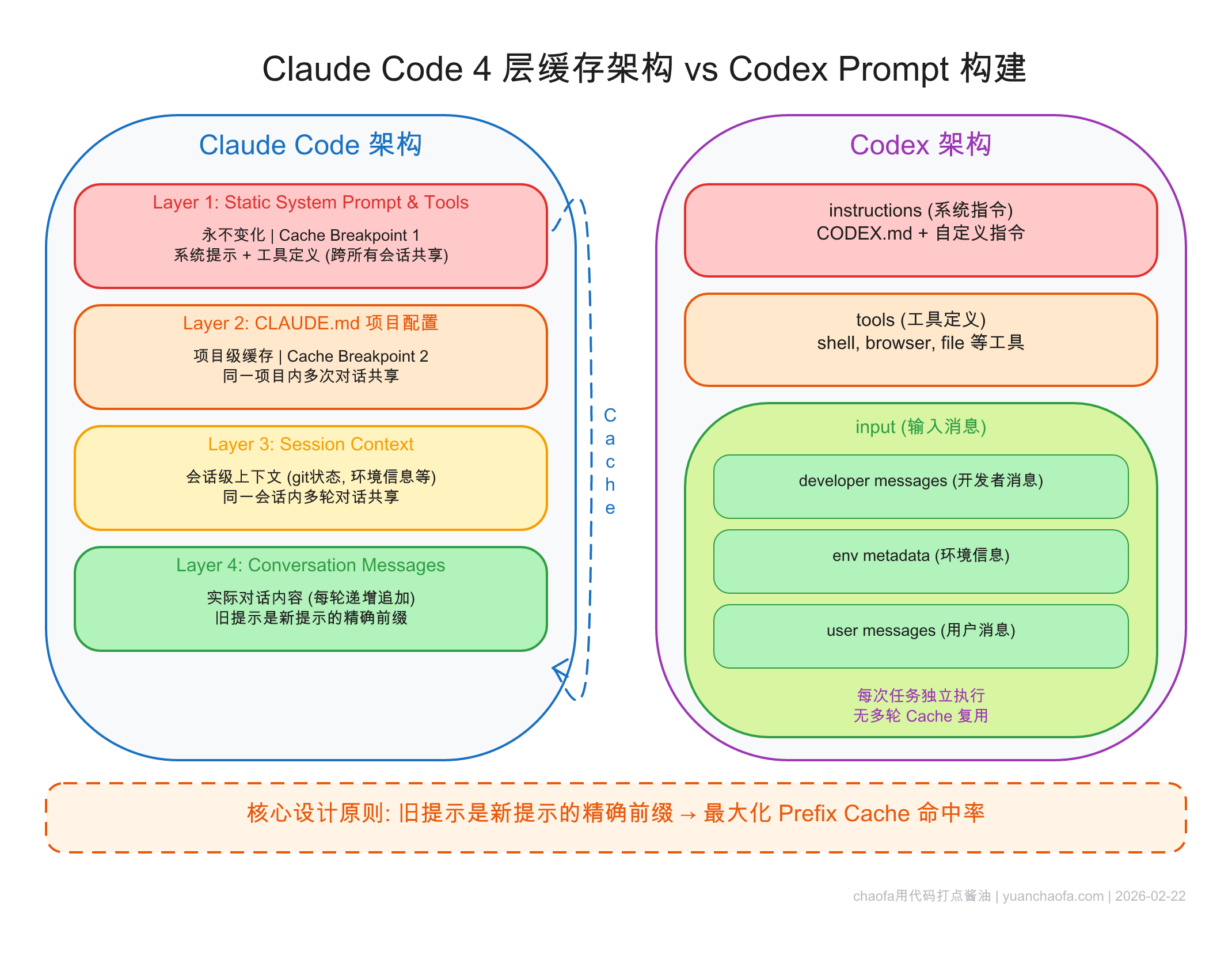
| 层级 | 内容 | 稳定性 |
|---|---|---|
| Layer 1 | Static System Prompt & Tools | 全局不变 |
| Layer 2 | CLAUDE.md 项目配置 | 项目级不变 |
| Layer 3 | Session Context(git status 等) | 会话级 |
| Layer 4 | Conversation Messages | 每轮追加 |
每轮只有 Layer 4 增长,前 3 层稳定命中 cache。
三层结构:instructions → tools → input(input 可能会包含 dev role message,上图)。关键设计:旧提示是新提示的精确前缀。
配置变更(沙盒权限、工作目录)→ 追加新消息而非修改旧消息。
| 方案 | 实现方式 |
|---|---|
| Claude Code |
<system-reminder> 标签放在 user message 中 |
| Codex | 追加新的 developer/user 消息 |
永远追加,永远不修改。
cache_control breakpoint → auto-caching 一个参数搞定prompt_cache_key 路由优化,自动缓存 ≥1024 token 前缀反直觉:900 token prompt 永远不 cache hit,扩展到 1024+ token 反而更省钱。
Agent 可能有 30 个工具,但不同阶段只需要一部分。如果按需加载 → 每次状态切换 cache 全废。
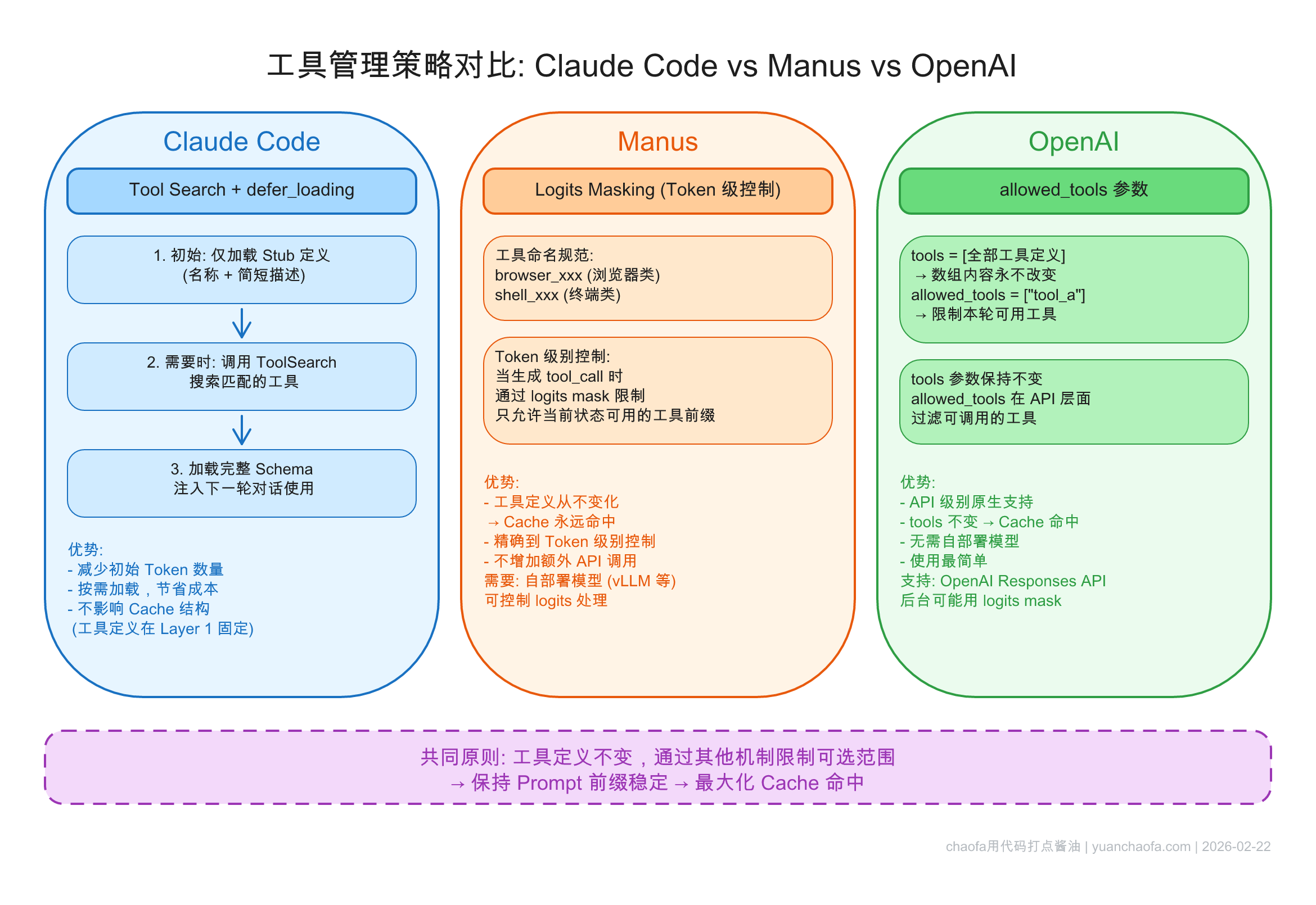
EnterPlanMode/ExitPlanMode 本身作为工具 → 工具列表永远不变defer_loading stub → ToolSearch 按需获取完整 schemabrowser_xxx、shell_xxx
tools 数组完整不变allowed_tools 限制当前可用子集本质:工具定义不变(保 cache),通过其他机制限制可选范围。
| 方案 | 实现方式 | 优点 | 限制 |
|---|---|---|---|
| Claude Code | tool 本身 + defer_loading | 灵活,模型自主决策 | 需 API 支持 |
| Manus | logits masking | 精细控制 | 需 self-hosting |
| OpenAI | allowed_tools 参数 | 最简单 | 仅粗粒度 |
本文聚焦于 Cache-aware 的 Prompt 设计和工具管理。但 Agent 还面临另一组挑战:context 越来越长怎么办?怎么压缩才不破坏 cache?子代理怎么设计?
下一篇 Agent 系统中的 Prompt Cache 设计(下):上下文管理与子代理架构 将深入这些话题。
{kind=link}