2026-06-29 15:47:43
Over the years, we have received, read and handled way over one thousand vulnerability reports filed against curl. We have seen most kinds.
It is time for me to try to help future reporters by providing a short guide on how to submit a truly excellent vulnerability report to an Open Source project.
We tend to call everyone who reports a security problem a security researcher, because by the act of the submission itself they fulfill the definition. There are however many different kinds of people who submit reports; from the most rookie youngster with limited experience, to the multi-decade experienced senior in the field.
Most reports submitted to a project like curl come from reporters who never submitted anything to the project before and are completely previously unknown. Many reporters use hacker handles or pseudonyms, so there is not a lot to learn about the person behind the report either. We don’t know the reporters’ age, experience level, employer, sex or on which continent they live. But also: none of those things matter.
When you submit a vulnerability report, consider telling the project how you want to get credited, should they consider your report real.
There is a potentially almost unlimited amount of security researchers that can find problems in a project. The project receiving your report only has a limited small number of overloaded maintainers that take care of the reports. Consider this imbalance. Make your report as easy as possible for the team to manage.
To us maintainers who receive a steady stream of vulnerability reports, it rarely matters exactly how the problem was detected. Whether you fell over it by accident, you found it by reading every single line of source code or if an AI pointed it out to you, it has little relevance to the security team. The team primarily cares about if the problem is real and if it is, how serious the impact is.
If the problem is documented, then it likely isn’t a vulnerability. This is a common theme in curl: people report that they can find something strange or peculiar to happen when they do something, only to have one of us point out that the action is either documented to have that side-effect, or the action was done in spite of clear warnings in the documentation.
To make a good vulnerability report, you should make sure you understand what the software is supposed to do – and what the documentation says its limitations and conditions are. A good Open Source project has those things documented.
Figure out where and how to submit your report. If you found several problems, it is considered polite to ask the team how they want to receive the rest. As separate individual submissions or maybe as a curated list. Perhaps paced at a slow rate to avoid overflow.
Never circumvent the submission method suggested by the project. That is impolite.
Consider the initial submitting of the issue to be the first step in a multi-step communication process with the project that will continue for as long as at least one of your reported issues has not been resolved or dismissed. This can be days, weeks or in some cases even months.
Expect responses and follow-up questions. Be prepared to clarify, expand and maybe provide more code and reasoning. Remember that you submit vulnerability reports in order to help and improve the project.
These days people like to create enormously long and detailed reports that have all the details, often explained three times and with several embedded lists using bullet points describing impact and providing more or less good analysis attempts.
Your first paragraph of the report should be a human-written, brief explainer of what the problem is and what badness it leads to. You should be able to explain that in just a few sentences. It is a reality-check, because if you can’t do this, if you don’t understand the flaw enough yourself to write such a paragraph, then you have homework to do. Figure it out, then come back and write the intro paragraph.
Having a quality intro saves a lot of time for the security team receiving your report.
Be aware that the Open Source project you contact may be overloaded, on vacation or seeing your report as yet another duplicate they already saw reported seven times.
Be helpful and respect that you add a load to a small team that probably consists of volunteers working on this in their spare time.
Even if you have used a lot of or just a little AI when finding the issue and writing up the report, you must make sure that you communicate as a human. With your human communication skills.
Your report should contain a reproducer. Ideally a fully contained and stand-alone script or source code that the security team can build and run to see the vulnerability trigger.
A reproducer helps prove to the team that the problem is real or maybe already an accepted risk or behavior. It is also convenient for the developers to first understand and reproduce the issue, and then they can convert the reproducer into a project test case for the pending fix.
Without providing a reproducer in your report, you instead push that work to the receiving end. We still need the reproducer. We still need a test case.
Provide a patch for the problem.
If you can figure out a way to fix the code to make your finding no longer trigger, that is great information for the security team and such a patch usually helps them understand the issue better and get a speedier result. It reduces the load.
Sure, such a patch is often perhaps not perfect and it can usually be improved and expanded as the developers have a different view and a more nuanced understanding of the problem and the software architecture involved. It still helps. Getting 80% towards the target is still valuable.
Usually you should look for vulnerabilities in the latest version of the software, often even using an up-to-date git repository. Whatever version you used to find it, you need to specify that in your report.
If the problem turns out to be real, which your report claims and you should never report anything if you don’t think so, it is then also immediately interesting to know when this problem first appeared. Which is the earliest version of the software that you can trigger this problem with?
The project will want to know this to write up a proper advisory for the issue. You can help figuring this out by bisecting etc.
Remain available after your initial submission.
In the curl project at least, we want to work with the reporter to make sure we get every angle and detail right. First, when trying to understand and assess the initial report and agreeing on a severity for it.
Then, we jointly produce and agree to a remedy (patch) for the problem, which ideally means taking the reporter’s version and massaging it into perfection.
If the problem is serious enough, there could be reasons to discuss a rushed patch release at an earlier date than the pending release would otherwise happen on. To reduce the time users in the wild remain vulnerable.
Finally, we collaborate on the description and explainer for the problem that goes into the security advisory.
For every CVE that is registered and assigned to a particular vulnerability, there needs to be a detailed security advisory written. It should ideally describe the issue, how it triggers, what it means, the impact, the affected version ranges and more. Everything related to the vulnerability that we can think might help users.
Your job as a security researcher is to make sure the description in the advisory matches your finding, your understanding of the problem and that the description is understandable.
For every confirmed security report, the receiving project will try to learn from it and fix code and practices to avoid making the same mistake again.
As a reporter, your job is to learn from the submission experience and try to improve your reporting procedure and approach for the next time.
Then submit your next report!
2026-06-26 19:34:00
One of my favorite visuals for known vulnerabilities in curl is the mountain. It shows how many currently known vulnerabilities were present in the code through-out curl’s history.
In the end of June 2026 it looks like this:
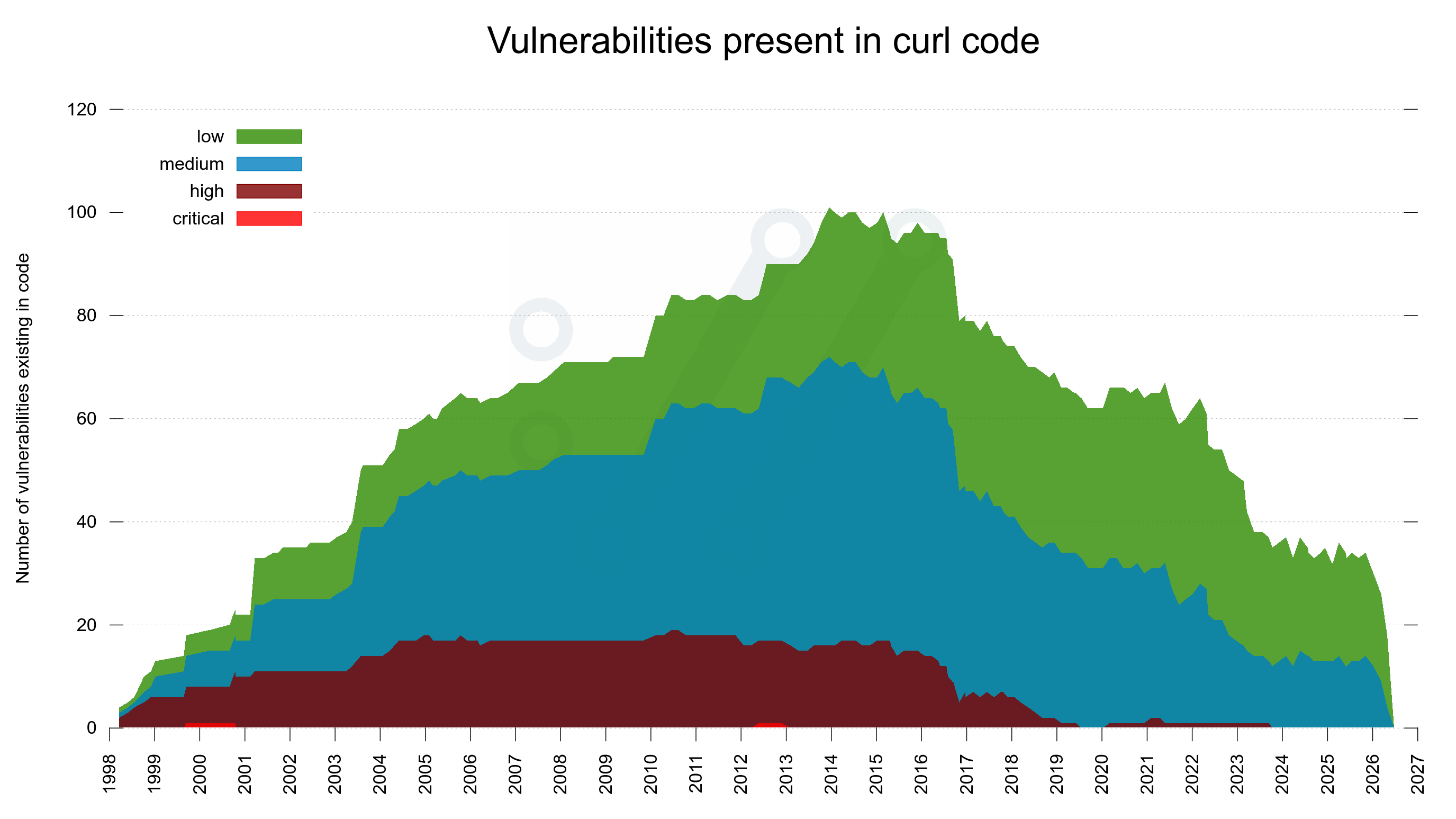
Over time we get more vulnerabilities reported. Since every flaw has a version range during which the problem existed and with more issues that have overlapping version ranges, the mountain grows. It changes shape every time we do a release or we publish a new vulnerability.
At this moment in time, curl version 7.34.0 is the release that contains the most number of known vulnerabilities: 101. The worst one ever if you will. Out of a total of 206.
The mountain uses different colors for different severity levels of the published vulnerabilities, as the legend in the top-left of the image explains.
To illustrate the ever-changing nature of the shape and size, I wrote a script that renders the mountain the way it looked at specific dates in the past up until today. More specifically, the script renders one image for every month since curl started (March 1998). I then turned these 340 individual images into a little movie that shows how it grew into today’s shape. At four months/second.
The data for this come from vuln.pm and the curl git repository. The graph rendering is based on the dashboard scripts. All images put into a movie with ffmpeg of course.
Several people have asked what happened in 2016 that caused the notable drop. A slope if you will.
If we zoom in on that, we can spot that curl 7.51.0 has eleven fewer vulnerabilities than the version before that. This release was the first one after the 2016 Cure53 code audit, but other than that there is no clear distinct process or obvious code changes that explain this trend shift.
Lots of other graphs show just the ordinary pace and growth in various project areas. It was still fairly early days CI-wise but had been running at least a few CI jobs per commit for a few years already by then.
curl was adopted into the OSS-Fuzz project in July 2017, which since then makes us find some issues better, but the drop looks like it happened before then.
We had already been analyzing the code regularly on Coverity since a few years.
Better tooling? New compiler options? We simply don’t know.
As we keep announcing more vulnerabilities going forward, things will continue to change. Maybe I will come back and make another movie in five years?
2026-06-25 15:48:02
Trailing dots after hostnames in URLs remain my worst enemies. I wrote about several problems with them in the past that involved those nasty things. They are still painful. When we shipped curl 8.21.0 on June 24 2026 we fixed at least three brand new problems that involved trailing dots. C’mon, follow me down the trailing dot rabbit hole, episode two. I can just feel that there will be a third episode as well in a future…
Let’s for a second imagine that you create a URL that uses a numerical IPv4 address. Not entirely uncommon. For example lots of people use 127.0.0.1 in local tests etc. Used everywhere since the dawn of time.
Now imagine that you add a trailing dot to this hostname, like “192.168.0.1.”. What does the trailing dot even mean here?
This particular trailing dot caused a problem in curl. To figure out if curl should allow wildcard certificates when connecting to a TLS server, it needs to know if the given hostname is a numerical IP or a hostname. The check uses inet_pton() on the provided hostname extracted from the URL – which incidentally returns false for an IPv4 address that ends with dot! So if it isn’t a numerical address it is a hostname and then we allow wildcards… Argh.
I decided to solve this particular problem like this: if the address is a valid IPv4 address and there is only a single dot afterwards, that dot is “swallowed” as part of the regular IPv4 normalization process that curl always does for IPv4 addresses when parsing URLs. This way, a numerical IPv4 address with a trailing dot will never be passed on to curl internals anymore. And the meaning of the trailing dot for this use case is clear: it is a mistake so we get rid of it. (This also seems to be what browsers do.) Shipping in curl 8.21.0.
This choice has already been reported problematic by at least one user who expected a transfer for a URL like this to return error… I suppose this means that the jury is still out on what the best approach for this trailing dot is.
What could be more fun than trailing dots if not two trailing dots!
Two trailing dots is not possible to use as a hostname when resolving hostnames using DNS. It is an illegal name and causes an error. But as curl provides other ways to populate the DNS cache with a provided name, and you can provide names in /etc/hosts etc you can make curl work with URLs where the hostname has two trailing dots. Or rather, you could up until recently until I made sure it is properly banned always because of the trouble they cause internally.
A double-dot is correctly treated as a host with a trailing dot, but it turns out that in for example the HSTS logic that became problematic as removing the trailing dot for some functions would still have a trailing dot there when there were two of them to begin with… and it would get confused and act up.
No more double trailing dots. One is annoying enough. Shipping in curl 8.21.0.
HTTP cookies are basically name/value pairs set by the server and held by the client to get sent back to the server again in later communications. The server can specify for which domain a cookie should apply to, so that it can be used across multiple domains. (Yes, it is a little crazy,)
To prevent the server from being able to set the cookie on a too wide domain cookie clients check if the specified domain is Public Suffic Domain (PSL) or not. A server is not allowed to set cookies for PSL domains, as that allows it to create “super cookies” that work across domains in ways that are not allowed. Cookies attempted to get set for such a name should be rejected.
In libcurl we check domains against the PSL using the libpsl library.
Turns out this too could be tricked by trailing dots. If you communicate with the URL “example.co.uk.” (with a trailing dot) and it sets a cookie for for “co.uk.” (with a trailing dot), the internal check would ask libpsl about the PSL status and… it did not work with trailing dots. The exact same process without trailing dots correctly says it is a PSL and the cookie is refused. But with the trailing dots present it was fooled and curl would allow the cookie to get stored and later sent back to such a host…
This particular issue ended up considered a vulnerability known as CVE-2026-8924. Fix shipped in curl 8.21.0.
Yes, you can of course quite correctly argue that none of these things are actually new or sudden changes. Trailing dots are there, they have always been there and people will continue to use them in the future. I’m not blaming anyone else. I’m just expressing my frustration.
Trailing dots are the worst.
2026-06-25 05:38:52
A few years years ago the curl project signed up and became a CNA. This means that we are masters of and can allocate our own CVE identifiers. For any security problems within our territory, it is we who decides if the issue should get a CVE or not. No more bogus CVEs.
During these years we have published fifty-seven separate security vulnerabilities with their associated CVE identifiers. Getting a CVE for an issue is easy and really quickly done when you are a CNA. No hassle, no friction and as we are a small and lean security team it just works as smoothly as you could ask. Just an API call and we have new number.
Being a CNA is low maintenance, as there really is nothing extra we need to do. We already had an established and proven process for receiving, managing and assessing vulnerability reports before we became a CNA since we are a responsible and well-run Open Source project. Becoming a CNA just made the process easier as we now don’t need to involve any outsider at all.
For every report we work hard to first assess and decide if the issue is actually a vulnerability or a security problem at all.
If we deem that there is a security problem in there, we then grade it into LOW, MEDIUM, HIGH or CRITICAL. Since we don’t know how users use curl or libcurl we cannot take that into account but rather observe and set a severity of the problem from a pure curl point of view.
It’s a rough indication how we see the problem but of course every user that actually are affected by the problem might rate it differently.
For a rare few issues we can imagine that there could be a minuscule risk but because of the set of extreme requirements and convoluted steps to get there, we deem the risk so small that in practice no user is likely to ever reach it. Internally we tend to call that an issue with a severity level lower than LOW. Issues we believe we serve humanity better by not issuing a CVE for. To avoid the security dance when it seems unnecessary.
libcurl is installed in somewhere around thirty billion instances on the globe. If we imagine that at least a sizeable portion of those installs are managed by people who want to make sure they use a secure version, it means that every CVE we publish trigger activities in many security teams all over the world, leading to a significant number of patches and subsequent software updates.
Every CVE thus has this huge cost tied to it. A cost that does not land on us and we don’t really see or feel it, but a cost on the ecosystem I believe we should not ignore. We should act responsibly. Never ignore real problems of course, but also to make sure we don’t ring the alarm for theoretical problems that will not trigger any vulnerability.
Our first ever CVE dispute since we became a CNA reached us on February 10th, 2026 for a report submitted to us two months earlier. The reporter thinks we should have assigned their reported problem a CVE but we think not. Now they want to force the issue to get a CVE anyway, by escalating the situation to MITRE.
Yes, it makes you wonder why it is that important to have this as a CVE, but I will avoid speculations for now.
I replied to MITRE explaining that we considered and debated the issue and we remain happy with our previous decision. I linked them the original report and discussion to show them.
The issue is quite technical (of course) but is based on a bug in curl’s function that checks if the used hostname matches a wildcard provided in a certificate.
First: the user must use a hostname in a URL with a leading dot, like https://.example.com/
This name is not possible to use with DNS (it is an illegal name there), but you can provide an IP address for it in your /etc/hosts file or similar, but still this condition is already making this issue really niche.
Why would a user ever do this? Well, there could be a redirect to such a host name from a malicious server if the application allows redirects but getting the address for the host is still a challenge and mostly requires a local attacker present add that.
Then: if curl can find an address for the illegal DNS hostname, the site curl connects to, also needs to have a wildcard certificate for the name *.example.com where the tail of the wildcard needs to match the name in the URL.
If curl was built to use an OpenSSL flavor or Schannel for TLS (remember that curl supports many different TLS backends), it then calls the Curl_cert_hostcheck() function to check if the wildcard covers the used hostname.
This function had a bug. The above mention combination then erroneously would return TRUE. A match. When in reality it is not a match according to the spec.
We fixed this problem on December 8, 2025, and we added unit tests for exactly this scenario to make sure that the problem doesn’t come back. For all security issues at several below HIGH, we fix them asap so that was just our normal procedure. We then continued to discuss if this was worthy of a CVE or not.
It should be extremely rare that anyone uses a dot prefixed name, unless you are in an internal and controlled environment where you use something else than DNS for resolving.
It is not possible to trick an application to use a dot prefixed arbitrary name as it will fail to resolve.
The explicitly set, weirdly dot prefixed name, then needs to connect to a host that has a wildcard set for that same name and an attacker manage to run this impostor host and can now serve the application malicious data because curl did not properly reject the connection because of the wildcard mismatch.
A series of highly unlikely conditions that all need to be fulfilled for this to become a vulnerability. A lower than LOW situation. Too unlikely; no CVE.
On May 28, we were again contacted by MITRE in the same case, asking again for our rationale for not giving this issue a CVE. We responded with virtually the same wording as before and linking again to the same original Hackerone issue and discussion thread. It’s all public information really.
On June 15, we were again contacted by MITRE asking for the reasoning behind our decision to not give a CVE for this issue.
We replied with similar wording again. Linking to the same issue, again.
This seems like a great system.
On June 24 we finally got the verdict. It is not considered a security vulnerability.
Hello Yuhao,
Thank you for your participation in the CVE dispute process regarding the reported issue affecting curl through 8.17.0.
The MITRE TL-Root has completed its review of the information provided by all parties involved,
including the materials submitted by you and the response from the responsible CNA. Based on this
review, the MITRE TL-Root has determined that a CVE ID will not be assigned for the reported issue.
CNA Determination (Summary):
"This is a bug, now fixed in the master branch. It is not considered a security vulnerability because of how it requires a local attacker with privileges present to make it so."
After evaluating the available evidence and the CNA’s assessment, the MITRE TL-Root agrees with this determination and considers the matter resolved. As the adjudicating authority in this dispute process, the decision of the MITRE TL-Root represents the final determination for this case.
We appreciate your engagement with the CVE Program and your efforts to responsibly report and coordinate security issues.
Respectfully,
MITRE TL-Root
2026-06-24 14:00:23
the 275th release
6 changes
56 days (total: 10,817)
276 bugfixes (total: 14,187)
531 commits (total: 39,077)
0 new public libcurl function (total: 100)
0 new curl_easy_setopt() option (total: 308)
1 new curl command line option (total: 274)
102 contributors, 69 new (total: 3,731)
45 authors, 26 new (total: 1,489)
18 security fixes (total: 206)
As mentioned before, the security report volume has been intense lately. We publish eighteen new curl vulnerabilities this time. A new project record for a single release and for the total number of vulnerabilities published within the same calendar year.
As always, we have document each vulnerability in detail and I encourage you to read up on the details.
The huge focus on vulnerability reports during this release cycle made us merge fewer new features than we wanted, but here are the ones we still managed to get to:
We again manage to land more than 250 separate bugfixes, and they are all detailed in the changelog.
Planned upcoming removals include:
If you are concerned about any of these, speak up on the curl-library list ASAP.
Unless we messed up this one and need to do a patch release, the pending next release is scheduled to happen on September 2. This release cycle is extended by two weeks due to the summer of bliss.
2026-06-21 06:34:25
RFC 10008 is brand new a specification detailing the new HTTP method called QUERY:
This specification defines the QUERY method for HTTP. A QUERY requests that the request target process the enclosed content in a safe and idempotent manner and then respond with the result of that processing. This is similar to POST requests but can be automatically repeated or restarted without concern for partial state changes
For all practical purposes you can think of QUERY as a way to send a GET with a body. It looks exactly like POST, but done with another verb.
Contrary to POST, QUERY requests are idempotent – they can be retried or repeated when needed, for instance after a connection failure.
You can use curl to do HTTP requests with QUERY just fine. curl offers the --request option (also known as -X in the short form) that you can use like this:
curl -d "data to send" -X QUERY https://example.com/
There is one little caveat to remember with this curl option that changes the method. When also asking curl to follow any possible redirects, it is important that you use a new enough curl version because you want the --follow option. Not the old --location/-L one.
Why? Because the old option changes the HTTP method on all subsequent requests independently of what the server responds, which in many cases is not what you want.
The newer --follow option instead acts according to what the HTTP response code suggests in should do. Stick to the same method again, or maybe switch to GET in the following request.
Why or when would you use this? First of course you only want to use this if the server supports it, but the spec offers some reasons why this might be a good choice: