2026-06-27 02:32:41
It’s been an incredibly long few weeks, and as a result my previously-planned Hater’s Guide just isn’t possible within what little time I have left in this week, which is why I’m starting an ongoing series — Notes From The Bubble — where I’m going to dig into the various stories that have stood out to me in the last few weeks and what they mean for the greater tech ecosystem. It’ll be my weapon of choice going forward for the (few) weeks where a greater narrative is taking longer to pull together than usual.
I also think it’s time for something a little more light-hearted after a few hundred thousand words of deeply-researched financial nightmare fuel. As serious as the tech industry’s descent into cargo cultism has become, it’s really important to laugh at how disordered and goofy everybody has become as they realize that we’re flat out of hypergrowth ideas. Every time you see something stupid, desperate, ridiculous or disconnected from reality, know it’s a symptom of the greater fear that AI isn’t the next big thing, and that everything is an attempt to put off accepting that truth or, alternatively, create another hype cycle so we can avoid talking about it.
I know this all sounds a little reductive, but look at the current state of the tech industry. Meta is creating a Polymarket competitor. Snap is launching its third generation of AR glasses that nobody wants, I assume to compete with Meta’s AI glasses that are exclusively owned by influencers and people that should be banned from public restrooms. Microsoft has gone from loving OpenAI to loving Anthropic to loving open source LLMs and decrying the idea that any one company could control the entire AI ecosystem, somehow missing that Microsoft is the largest AI infrastructure provider in the world and is the reason that this industry exists. Google invested $75 million in movie studio A24 as part of some sort of nebulous AI partnership that will likely result in very little actually happening.
Oh, and you can now watch Instagram on your TV.
This is the modern tech industry: a series of cobbled-together ideas pushed out by also-rans with massive monopolies and talent suffocated by executives that haven’t had a human experience in decades. Can you imagine Satya Nadella or Mark Zuckerberg buying something from a hardware store? Do you think they know how to use a vending machine? When did any of these people last pay a bill, or worry about anything other than shareholder value and stock-based compensation? How often do you think Sundar Pichai actually uses Google, Google Docs, or any other products blighted with a Gemini pop-up?
Today’s newsletter will be a longer-form column, a series of thoughts on the current state of the tech industry.
Welcome…to Notes From The Bubble.
2026-06-23 23:23:20
If you liked this piece, you should subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 5,000 to 18,000 words, including vast, detailed analyses of NVIDIA, Anthropic and OpenAI’s finances, and the AI bubble writ large (updated to version 3.0 a few weeks ago). My Hater's Guides To the SaaSpocalypse, Private Credit and Private Equity are essential to understanding our current financial system, and my guide to how OpenAI Kills Oracle pairs nicely with my Hater's Guide To Oracle.
My last two premium newsletters were a deep-dive into the bubbles-within-a-bubble that make up the AI bubble — from the unsustainable and reckless growth of semiconductor companies, to the cults of personality surrounding Sam Altman and Dario Amodei.
Subscribing to premium is both great value and makes it possible to write these large, deeply-researched free pieces every week.
A few weeks ago, I predicted that the AI industry would start pushing the concept of “loops” — effectively LLMs prompting LLMs and being left to their own, token-intensive devices — as a desperate attempt to get users to burn more tokens, I imagine to create more revenue.
Now Jensen Huang and Claude Code chief Boris Cherny have both, within 24 hours of each other, intimated that the age of prompting models is over, as you’d just be “handling loops,” which conveniently also means burning more tokens.
It’s unclear what benefits a loop might have, but at a conference where the first question was mysteriously about “whether loops were for real,” Cherny was emphatic that they were, and attempted to explain why:
Later in the talk [around the 32:00 mark in this YouTube video], Cherny got specific about the loops he keeps running in his own work. One agent is continually looking for ways to improve the code architecture, while another looks for duplicated abstractions that can be unified. They submit pull requests like any other coder, and since the code is constantly changing, they never stop running.
Pretty convenient for a guy who’s allowed to burn upwards of $130,000 a month in tokens by Anthropic. Burn as many tokens as possible, so that the Great Prophecy might occur! If you don’t endlessly use as many tokens as possible, constantly defend the AI industry, and prove yourself worthy of the Great Beast of Capital, you will never ascend! Use loops now! Agents are out! You’re an ape if you use agents now that we have loops!
I realize I sound like I’m being a little dramatic, but the AI industry moves with an alarming speed and consensus to judge those who are deemed unworthy. Don’t you dare report news that might darken the hearts of the chosen! Don’t you dare suggest that the Great Prophecy (Anthropic and OpenAI are able to meet their $1.1 trillion in spending commitments) is untrue! Don’t you dare doubt that large language models are the future! This is Silicon Valley, and Silicon Valley stands for rugged individualism, rationality, and meritocracy, unless, of course, everybody in Silicon Valley agrees that an idea is good, at which point all of that bullshit goes out the window. Any singular piece of information that even slightly rings positive is proof of the Grand Prophecy of Growth that AI promises, and Chosen are those that take said proof, and Cursed are those who would question it.
That being said, if you’re an AI booster, I need you to listen to me. It’s very important everybody does the same thing right now. If Saint Tibo resets the Codex limits and you’re not immediately running loops — if we’re all not running loops — then the Great Prophecy won’t be completed. If you hear anybody question the Great Prophecy, you must immediately attack them, ideally finding a single point that you believe to be wrong (having read at most 200 words of what they have written), and then declare your victory. This is now your job.
If you do not write supportive blogs and tweets about the AI industry, you hate the entire tech industry, because Silicon Valley (see: the supposedly individualistic and meritocratic culture built on challenging consensus) needs you to suppress all dissent of any kind and ostracize those who dare to speak ill of it. Do not fret about non-believers who ask about things like “economics.” If you’re worried, re-read AI 2027, a piece of speculative science fiction that the big, serious, rationality-driven tech industry requires you to take seriously. You’re a big boy! You make your own decisions! Unless those decisions run contrary to the consensus of Silicon Valley, which is currently set to “AI is the literal future of everything and can do anything we agree on eventually.”
This is Silicon Valley — a monoculture that sells itself as outliers, putting everything it has into supporting a generative AI industry that sends the vast majority of its value directly to the largest tech companies in the world. The staunch rationalists of the Bay that have built brands convincing people they’re immune to the influence of groupthink need you to think exactly the same way that they were told to.
Why would everybody agree to do something so stupid? Why would everybody act so crazily?
It’s simple: the tech industry has completely run out of ideas, and all that’s left is a cargo cult that hasn’t had a human experience since 2015.
Last week, Snap CEO Evan Spiegel debuted Snapchat Specs, a $2195 pair of augmented reality glasses with a demo that makes it apparent that nobody in the C-suite has spoken to a normal person in years. The tech industry desperately craves its next iPhone, but years of growth-at-all-cost management consultancy poison has twisted the already-flimsy mission statements of Silicon Valley from creating societal value and innovation to creating shareholder value and a kind of banal, nihilistic accelerationism that mostly comes down to “how do we make the next thing that will make number go up.”
Snapchat Specs are expensive, aesthetically vile, and lack any meaningful use cases. Snap’s own demos are clunky and ugly, looking somewhere between a neutered Vision Pro and the original Google Glass concept video, except even then every example feels like something somebody came up with in a boardroom:
SPIEGEL: What do people do? Drums? They walk around…uh…Tokyo? They look for…uhh…directions, I guess? They look for how to fix a car? People still drive cars, right?
WORMTONGUE-ESQUE PRODUCT MANAGER: Oh yes sir, yes…exactly. Sometimes they even have “boards” of things, for their work, you see.
SPIEGEL: I bet they golf too, right?PM: Yes sir. The person you are imagining — one who can afford a $2195 pair of augmented reality glasses — would play golf, but also be so bad at golf that they need the glass-
SPIEGEL: DID YOU JUST LOOK AT ME? I TOLD YOU NOT TO LOOK ME IN THE EYE! NO EYE CONTACT!
This is, of course, a joke. I have no idea if you’re allowed to look Evan Spiegel in the eye if you work at Snap. I also have no idea if anybody actually considered what a regular human being might do with the product it’s been desperately trying to launch for nearly a decade. A single conversation with a regular person would likely have them tell you that they wish their shit worked better or that the internet wasn’t so full of scams and pop-ups and slop and misinformation. They wish there weren’t so many ads. They wish their apps weren’t confusing and full of dark patterns and ways to trick them into subscriptions or clicking ads or being annoyed.
That’s because there’re only so many things you can do for the user until you start doing stuff to the user.
Per my piece from the end of 2024:
As every single platform we use is desperate to juice growth from every user, everything we interact with is hyper-monetized through plugins, advertising, microtransactions and other things that constantly gnaw at the user experience. We load websites expecting them to be broken, especially on mobile, because every single website has to have 15+ different ad trackers, video ads that cover large chunks of the screen, all while demanding our email or for us to let them send us notifications.
Despite decades of progress in hardware making computers faster, cameras better, and storage larger, the actual experience of using the computer has gotten materially worse. We’ve hit a wall as far as where mobile and desktop user interfaces can take us, and every attempt at making voice-activated platforms like Alexa replace (or even compete with) them has proven fruitless, with Amazon’s various Echo devices and services losing billions of dollars a year.
This is what I call the Rot-Com Bubble. Big tech has hit the wall of what modern software can do, and in turn run out of hyper-growth ideas. Nobody has the next Google Search, iPhone, cloud computing, mobile app store ,or other idea that would allow Google, Microsoft, Apple, and Amazon to keep growing at a rate that justifies their valuations. While this is partly a natural process — there are only so many ways to do things! — it’s also a direct result of incentivizing and promoting products that create revenue growth or sustain monopolies, which in turn focuses your R&D and hiring efforts toward those who can come up with ways to make Numbers Go Up.
Put another way, the tech industry has become the largest cargo cult of all time.
Microsoft, Google, Amazon, and Meta sunk what will soon be over a trillion dollars into AI data centers because they don’t have any other ideas, and because the only thing that the MBA’d elites running the tech industry can do is hire people, fire people and spend money. Their (at least in the first three cases) investments in OpenAI and Anthropic were a successful attempt to build both their largest individual customers and a new revenue stream under, I imagine, the mistaken belief that said customers would eventually become independent enough to pay them without continually raising venture capital. I also imagine they believed that AI data centers would actually make a profit at some point, or that said data centers wouldn’t take two or three years to complete, or that AI, as an idea and a tool, would “take off” in a real sense, rather than an imaginary hype cycle in an economy built on speculation.
The problem is that previous eras of innovation and hypergrowth never came from shoving hundreds of billions of dollars into any one thing. The original iPhone took two and a half years to develop, but was the culmination of multiple different innovations in capacitive touchscreens, smaller batteries, and the condensed talent that helped create a touchscreen keyboard that actually worked, and ended up costing about $150 million (or $271 million in today’s money), or a little less than a third of what SoftBank paid OpenAI in 2025. The reason we haven’t come up with the “next iPhone” is because we’ve maxed out what we can do with the current slate of ways to look at a computer interface, and the next logical step is one that’s effectively screenless, which is an unbelievably big leap, and one that will not be surmounted any time soon.
So our only hope is software, and the limits of our current interfaces. Google Search was created by two college students at Stanford. Instagram was a mobile check-in app called Burbn that realized it couldn’t compete with (lol) Foursquare and pivoted to creating a photo-first social network. In fact, most of the historical success stories in the valley are, for the most part, websites that bring together people or services in a way that’s accessible and readily-available, and most of that innovation came from services like Amazon Web Services. Social media companies were the natural next revenue ascent because they were, at least in theory, relatively cheap to run, as the users themselves (and what the platforms could encourage them to do) were the ones that made the reason for you to log onto the site.
Except everybody forgets how many dead social networks there are, like iTunes Ping, Google+, Google Wave, Microsoft SoCl, Meerkat, App.net, Pownce, Orkut, Jaiku, and YikYak. Everybody forgets that just about every other attempt by Meta or Google or Microsoft or Amazon to expand outside of their core competencies (if you can call them that) has failed. Everybody is desperate to ignore the fact that Silicon Valley startups have, for the most part, not done anything particularly new or interesting for over a decade, and that the reason everybody took these people seriously is a result of conflating them with people that have either entirely left the tech industry or have little to no say in its future.
There’re only so many ways to solve problems with software, and only so many other ways to solve the problems that doing so creates. Two decades of Silicon Valley “innovation” have come from throwing as much software engineering talent and venture capital at as many problems that could, at least in theory, be solved through a combination of cloud compute, storage and code.
And while there might be more problems that code can solve, they aren’t the kinds that create hundreds of billions of dollars of revenue or massive shareholder returns, nor are they things that big tech can copy and bolt onto their current services to keep them growing either.
This is leading to the slow, agonizing collapse of both the software industry’s revenue and the venture capital business model. The “SaaSpocalypse” narrative claimed that companies writing their own software was a threat to the business models of SaaS companies (and a justification for their dwindling revenue growth), which was an attempt to paper over the fact that the software industry is in decline, with the growth efficiency (revenue growth versus sales and marketing spend) of software companies declining by half between 2021 and 2023, with BDO reporting in a 2025 analysis that across 115 publicly-traded SaaS companies, the industry’s revenue had declined by 2% year-over-year, with mid-sized growing companies at a flat 0%.
The fact the “SaaSpocalypse” narrative took off is all part of the greater cargo cult of the Valley, and the media’s willingness to buy effectively anything they’re selling. Nobody is actually building their own SAP or Salesforce or Office 365 — that’s a fucking stupid idea! — but because that sounds like a directionally-correct idea that affirms the greater bias of the growth of AI, it set in, which meant some stocks went up and some stocks went down. Did they go up or down based on something that actually happened? God no! The market listens to the media and analysts, who mostly just look at the numbers they’re given and the people they talk to, who more often than not are the CEOs and other executives of the companies that plant these narratives as a means of getting away from an uglier truth.
You see, if AI is the reason that the SaaSpocalypse is happening, it fits into the larger imaginary Valley mythology of “disruption,” and gives everybody an excuse to keep believing that every tech company will grow in perpetuity. The cargo cult cannot change its rituals to adapt to a reality that suggests that its gods are dying. Accepting that AI isn’t saving everything means that you have to accept that there might be an end to the era of hypergrowth, which in turn means you have to start thinking about the rationale of, say, venture capital and private equity.
Both have seen far better days.
As of the end of last year, the average TVPI (total value put in) of venture capital funds raised between 2017 and 2024 was between 0.8x and 2.0x, meaning you’d get somewhere between 80 cents and $2 for every dollar invested, with 70% of startup exits between 2022 and 2024 netting a loss for their investors, up from 58% between 2009 and 2014, which included much of the bloodbath from the great financial crisis. Per The Economist, the Valley also faces a glut of “Zombie Unicorns,” startups valued at $1 billion that can’t raise money or exit at their current valuation, and a third of all active US unicorns (per Axios) haven’t raised any funding in the last three years.
Meanwhile, private equity is facing much the same problem, with more than 16,000 “zombie companies” held for more than four years, the longest on record, and holding companies for an average of 7 years in total. Private equity exits have dramatically declined, with a growing amount of exits being funded by “secondaries” — venture or private equity funds selling each other their portfolios in the hopes of avoiding having to dump them at a loss.
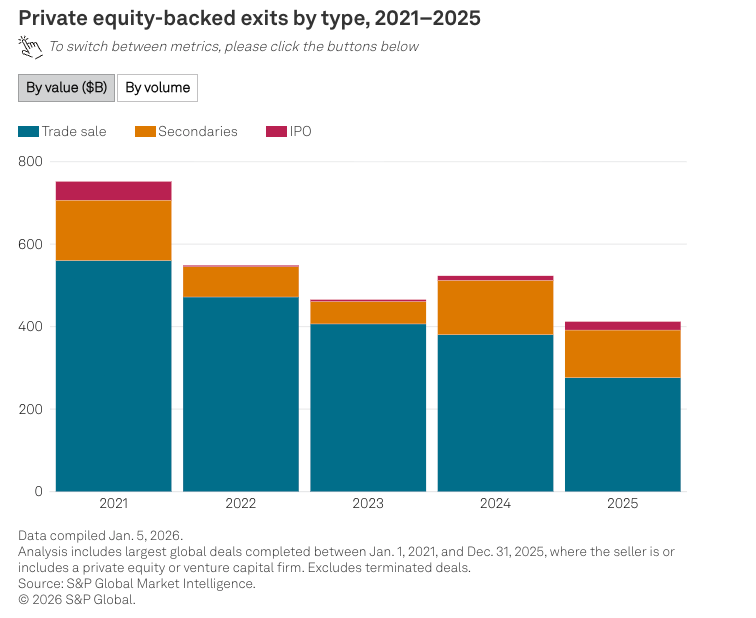
And wouldn’t you know, a big part of the problem is that they piled trillions into software companies assuming they’d all grow forever, massively overvaluing them in the process.
Between 2018 and 2022, (per Apollo) 30% to 40% of private equity deals were in software companies, with firms taking on debt to buy them and then lending them money in the hopes that they’d all become the next Salesforce. In reality, private equity overvalued the vast majority of its software investments, stuffing them full of debt with payments contingent on near-constant growth, which is why Pluralsight lost its investors $4 billion and Medallia lost Thoma Bravo $5 billion. S&P and 451 Research analyst Scott Denne recently put it bluntly, saying that “..."The holding periods are longer and they're going to get longer because there effectively isn't an exit market for these companies.”
It’s almost as if instead of looking at whether the companies were good and making intelligent decisions, private equity instead chose to do what had historically worked and assumed that its investments would continue to grow in perpetuity. You know, vaguely looking at history and doing things in an almost ritualistic way.
In venture’s case, while part of the problem was how easy it was to get money in the ZIRP era, the other is that venture capital has been morphing into a cargo cult for a decade, with seed stage financing collapsing since 2015, and continuing to drop in favor of middle-to-late stage rounds in established players…almost like venture capital just doing stuff in a way that somebody else did because it worked for them in the past. Venture capital no longer really cares about risk at scale, with the vast majority of funds going to late stage, and even “early stage” data poisoned by Series B rounds that are only something you can raise once venture capitalists have arbitrarily decided that you should continue living.
As a result, the vast majority of funds do not go into creating the future or taking risks but doing things that resemble success, which usually means following hype cycles and hoping for the best. Baseten, a company that sells AI inference infrastructure, just raised $1.5 billion in a Series F funding round so that people can use or run their own open source AI models, quite literally allowing people to do things that other companies have been doing and train open source models of their own, so that they too can “do AI.”
Its investors include D.E. Shaw Ventures, Greylock and Altimeter Capital, all of whom invested in both Anthropic and OpenAI. Baseten doesn’t own its own infrastructure, renting instead from hyperscalers, which means that that $1.5 billion goes directly into the pockets of Google, Amazon and Microsoft, much like the money raised by OpenAI and Anthropic, which in turn gets spent buying more NVIDIA GPUs. All that “free thinking” and defiance of incumbents always seems to end up as revenue for the largest companies in the world.
So much for backing the little guy!
While the Valley’s legend has grown from risk-taking and fostering new ideas, venture capital works in reverse, overwhelmingly funding market consensus and piling into deals after somebody else has risked their capital to keep it alive. Decades of encouraging people to fund startups with the express intention of hypergrowth — with Ben Horowitz suggesting in 2010 that having “zero chance of becoming a high-growth company” was tantamount to “being in purgatory” — has created a startup culture focused entirely on its Total Addressable Market and growth trajectory, which means that companies are founded with that express intention.
Venture capital funds companies that appeal to venture capital, which means Silicon Valley innovation is centered around finding ways to convince venture capital to give it money. While this might have worked a decade ago when there were still hypergrowth companies to build, it intellectually stunted the Valley, promoting and celebrating companies not based on the things they’ve built but the shareholder value they’ve created. A startup is considered a “success” not based on its tangible contribution to the future, but its ability to tick boxes either through funding, revenue growth, acquisitions, or valuation. Everything is about creating the signs that your company is part of the big thing that will supposedly lift every Silicon Valley valuation — after all, 61% of venture capital funding went to AI in 2025 — to the point that it isn’t really clear what anything means or what anybody is doing.
Nowhere is this more obvious than the eternal shuffle of different guys between different AI companies. Google paid $2.7 billion in 2024 to acquire Noam Shazeer, one of the authors of the paper that started the generative AI bubble, along with his worthless AI chatbot company Character Dot AI. Two years later, Shazeer is joining OpenAI, and it’s unclear whether his second tenure at Google really did anything, other than helping pad the bags of venture capitalists and possibly having some effect on Google Gemini. It’s unclear what changed at OpenAI when co-founder Andrej Karpathy left in February 2024, nor is it clear what is happening now he’s joined Anthropic. Barret Zoph left OpenAI in October 2024 to become the CTO of Mira Murati’s Thinking Machines, created absolutely nothing of value, went back to OpenAI in January 2026 as its “GM of B2B,” oversaw an era where its enterprise customers had “huge issues” with its costs, then left again, I assume to another AI lab that will give him lots of stock.
I’m going to go out on a limb and suggest none of these guys actually contributed very much in their most-recent tenures, and that their hiring and positions were further cargo cult moves. Noam Shazeer was the original Attention Is All You Need guy! Give him $2.7 billion! Quick, before somebody else does! Quick, hire Andrej Karpathy, a guy who hasn’t worked at OpenAI in years, to do something with your LLMs! His eternal brilliance — which resulted in absolutely nothing since he left OpenAI outside of a placeholder website for a dead education startup with a protected Twitter account — is necessary to doing whatever it is we’re meant to do next! This will help us do hiring too, because everybody wants to work with these great minds that do stuff, somewhere, at some point, or maybe they did stuff, I don’t really know!
Hey, remember when Mark Zuckerberg was paying tens of millions of dollars to hire random AI researchers? Why do you think he did that, other than the fact that everybody else was hiring lots of AI researchers? Hey, while we’re on the subject, what exactly did they end up doing? That’s right, a mid-tier AI model and an AI app that nobody uses! Sure sounds like Mark Zuckerberg was just doing whatever seemed to work in the past, which was “get smart guy, smart guy do stuff, thing happen,” much like when Microsoft hired Deepmind co-founder Mustafa Suleyman for over a billion dollars, with little to show for it other than mid-tier LLMs, a universally-loathed chatbot, massive capex, and AI revenues that are too small to break out in Microsoft’s earnings.
No, sorry, I forgot the latest cargo cult maneuver — OpenClaw, a product that 99% of people have never heard of other than those who intentionally drown themselves in Silicon Valley cultism, which is why Microsoft, NVIDIA, Meta and Amazon all built OpenClaw bullshit and OpenAI hired its founder. Everybody is moving between various different rituals in the hopes that they’ll be the ones that they’ll be The Great Winner of AI, even if nobody really knows what that is and is only doing all this shit because everybody else is doing it.
That’s because the AI bubble has been part of the greater cargo cult of the Valley. Why did Microsoft buy hundreds of thousands of GPUs? Because an engineer told him that if millions of people used ChatGPT via Bing, they’d need “every high-end chip the company had.” Why did everybody freak out about ChatGPT? Because it was the first viral product the tech industry had created, and it was truly different. Why does anybody think LLMs are going to change anything? Because everybody vaguely came to the consensus that ChatGPT was trending in the direction that something would change.
And so the greater tech industry moved into full cargo cult mode. Amazon, Google, and Meta had to buy all those GPUs because Microsoft bought a lot of GPUs. Investors piled into various AI companies because when the tech industry does something at the same time, big things happen. Everybody has acted based on reading the signs — ChatGPT’s meteoric growth meant that it could be the next Google, and because the economics had worked out in the past, they would work out here, which is why everybody tells you that it’s just like Uber (it isn’t) or AWS (which cost $52 billion between 2003 and 2017, or less than a quarter of What OpenAI and Anthropic raised in the last 6 months).
The AI industry is fundamentally judged based on its symbolic similarities to bygone eras. Buying GPUs and building data centers sort of feels like Amazon Web Services, even though the $765 billion that big tech will spend in 2026 will be more than ten times Amazon’s combined capex during the period where AWS was being built. ChatGPT sort of feels like Google Search or Facebook Ads or next app store, but only because it’s a culturally-relevant piece of software, largely driven by the larger cargo cult of tech crystalizing around it.
Most people trying to make these comparisons either don’t remember or are desperate to forget how different the world was when Google Search, the iPhone or Amazon first grew. They don’t want to think too hard about how blatantly obvious the utility of these products was, how they had functional unit economics from their earliest days, or how different their growth stories were. They don’t want you to think about it either, because part of the greater cargo cult is making sure you don’t believe your lying eyes and focus on the greater signs that The Great Prophecy might come true, even if it’s not obvious what that means other than “ChatGPT is the biggest most hugest and most profitable company ever and everybody makes money on their investments.”
OpenAI and Anthropic are the height of the Valley’s mysticism. Both are still referred to as startups, despite the fact that Amazon, Google, and Microsoft paid for their entire infrastructure, spending at least $200 billion just on buying GPUs and building capacity for two companies. They have raised — assuming their most-recent rounds fully close — close to $300 billion in the space of two years, and are on course to burn tens of billions of dollars each in 2026.
Neither Anthropic nor OpenAI are actually startups. They have enough money and clout to hire just about anybody, can deploy billions of dollars in stock for acquisitions, have their infrastructure fully paid for by other companies, and because it’s taken so much money to build said infrastructure, effectively nobody else can train models or serve inference at their scale, making them the functional equivalent of a hyperscaler.
And neither company feels anything less than insane outside of outright ignorance or a cargo cult mindset. Both companies have had everything paid for them either by hyperscalers or venture capitalists, and are fundamentally incapable of operating without infinite resources, and the best that anybody has to defend their endless billions of burn is to refer to the 184-year-old railway bubble or the Dot Com Bubble, using them as symbolic proof that everybody can lose a lot of money, and that somehow results in something good, I guess?
The logic centers around the idea of “useful infrastructure,” as if railways or telecommunications equipment have any similarity other than that people spent way too much money on them in bygone eras. AI boosters (and the well-meaning and ignorant) return to these bedtime stories as a means of escaping reality and accepting that it’s very possible for everybody to be wrong in a completely new and innovative way.
This is the same mystical thinking that gets us to the idea of OpenAI or the greater AI industry being “Too Big To Fail,” an ahistorical trope that ignores the Term Securities Lending and Primary Dealer Credit Facilities that plugged trillions (no, really!) of dollars into the side of the banking industry because failing to do so would’ve left America’s financial system insolvent. OpenAI, Anthropic and every AI startup could disappear tomorrow and the world’s financial systems would continue unabated, other than the brutal hit to the stock market and screeching of venture capitalists.
That’s because their actual relevance is, in and of itself, symbolic. OpenAI and Anthropic combined to less than $20 billion in annual revenue in 2025 representing 89% of all AI startup revenues, and spent at least $30 billion on compute on Microsoft Azure, Google Cloud and Amazon Web Services. Their services are sold using the very same cargo cult mentality that got us into this mess — organizations adopting AI at scale and demanding that people use it because “AI is so powerful,” or, put another way, somebody they respect or like suggested it’s the future, and because none of these executives actually build anything or do any work, they have no idea what to do other than whatever it is that everybody else is doing.
Our economy is dominated by companies run by people who didn’t build and who don’t participate in the products or services they sell. They have little or no practical experience about what it was that made the company a success, and their “daring” initiatives usually boil down to “fire a bunch of people and flatten the organization” or “spend a bunch of money because it’s the thing to do.” They do not know what AI does other than the fact it can write code or write copy or generate stuff, but because everybody is “doing AI,” they too must “do AI,” which means “everybody that works for me must do this, and also we must add this somewhere, somehow.”
But that’s all the modern tech industry can do: an impression of something they think is successful in the hopes that they’ll be successful too.
In September 2024, Airbnb CEO Brian Chesky gained an alarming amount of praise for doing “founder mode” at the company:
If I could summarize founder mode in a couple sentences, it’s about being in the details. It’s that great leadership is presence, not absence. It’s about a leader being in the details. And if you as a leader aren’t in the details, guess what? Your leaders aren’t in the details, and their leaders aren’t in the details. And one day you’re going to wake up, and you have 50-year-olds managing 40-year-olds, managing 30-year-olds, managing people two years out of college doing all the work with no oversight, and you have these four unnecessary layers. You have no experts in the company.
So, the antidote to this is to try to be as functional as possible. We are a functional organization. Functional just means expertise-based, not general management-based. I’m the only non-functional person in the company; all functions roll up to me. I generally think the CEO should be the chief product officer of the company. The most important thing a company does is make a product. If the CEO is not the expert in the product, then why are they the CEO? Said differently, I should not be the CEO of SpaceX. I couldn’t be the chief product officer because I do not understand rocketry. So maybe I’m a good CEO, but I can’t be the chief product officer. There may be some exceptions, but I generally think that’s the case.
Your leaders shouldn’t just be “managers” (and I put managers in quotes), they should also be in the details. If we were a military, like a battalion, the cavalry general should know how to ride a horse. It’s crazy that they don’t. And leaders shouldn’t be fungible. So it’s really about being in the details.
Chesky also notes that he was inspired by “studying Steve Jobs,” a person who has been dead for many years, choosing “not to copy everything, but a lot of how he organized and ran the company.”
Airbnb is most decidedly not Apple, and neither Chesky nor his team are anything close to those who built the original iPod, iPhone, or even the Apple HiFi. Airbnb is a cloud service platform that lets people rent their houses out. When Chesky says he’s “studying Steve Jobs,” he likely means that he watched a few movies, documentaries and videos of Jobs speaking about things that have nothing to do with him, looking for similarities that he could copy — almost like he was copying a successful guy’s moves in the hopes that doing so would give him similar results. Airbnb remains a better-than-the-rest front end for you to rent other people’s houses that provides payment and support layers, and the vast majority of its revenues come from monetizing that process. Airbnb’s stock remains effectively flat since Chesky’s “founder mode” designation, and it remains (extremely) modestly profitable.
The irony of the discussion is that it comes from a Paul Graham essay that basically boils down to “the CEO should actually do stuff at the company and know who does stuff at the company,” except written with a Sorkin-esque drama:
For example, Steve Jobs used to run an annual retreat for what he considered the 100 most important people at Apple, and these were not the 100 people highest on the org chart. Can you imagine the force of will it would take to do this at the average company? And yet imagine how useful such a thing could be. It could make a big company feel like a startup. Steve presumably wouldn't have kept having these retreats if they didn't work. But I've never heard of another company doing this. So is it a good idea, or a bad one? We still don't know. That's how little we know about founder mode.
No, actually, this shouldn’t be that hard if you actually talk to people at the company, even at a large organization like Apple, if you have any idea what people do for a living. Sure it’d be a lift, but if you can’t organize a 100-person event with a year’s lead time just because you’re too lazy and inert to understand what’s going on, perhaps you shouldn’t be running a company to begin with?
You see, the Valley can’t just say “yeah you should have an active hand in your company and not delegate everything,” it has to be founder mode because everything is special! If tech firms aren’t run by people going founder mode, then they’re just software companies selling software. If OpenAI and Anthropic are just software companies with huge infrastructural costs, then you have to start treating them like normal companies with those kinds of burdens, which would make you start screaming at the top of your lungs.
This is the hyperreality (and cargo cult mentality) of Silicon Valley. Apple, Google, Microsoft, and Meta were companies that grew out of relatively boring stories — kids getting internships working at tech companies, computer science graduates coming up with software-driven ideas, and so on — with very few actual lessons to learn other than “you should come up with a really good idea and do it at exactly the right time.” Romanticizing the legend of Steve Jobs or Mark Zuckerberg or Bill Gates, rather than their luck and potential ability to hire people who actually build things for them, allows you to pretend that there are lessons to be learned, and that in turn you too could have these otherworldly riches if you just try hard enough.
The success of these large companies has predominantly come from having a few good ideas, great timing, good execution, and building largely-immovable monopolies rather than any incredible acts of genius. Jobs, Zuckerberg, Bezos and Gates all succeeded by finding people who actually did stuff, such as the Sanberg-led growth team that turned Facebook into a monster, and Tony Fadell and Scott Forstall’s hardware and software teams pulling together the original iPhone. Their successes were not the result of some series of things you can mimic or the tone of their voice or a specific series of actions, but being in the right place at the right time with the right idea and the right people, at a point when the underlying hardware or semiconductor infrastructure had reached a point when the idea was possible.
Put another way, there was a shit ton of hard work, innovation, and talent that went into these things that you can’t copy, even by working really hard or yourself having a bunch of talent. The ideas must be possible, economically viable, and you must have the people and infrastructure to execute them. Amazon Web Services may have lost money, but lost significantly less than OpenAI or Anthropic, and was significantly more useful than anything the AI industry has ever produced. In 2013 — the year that Amazon Web Services went profitable — Amazon’s total debt was $5.18 billion.
And really, there’s nothing more cargo cultish than defending OpenAI burning $21 billion in a single year by saying “this other company burned money too.” Even if the losses were comparable, Amazon was building two very different businesses — a digital store and a cloud compute platform — to OpenAI, which is training and selling access to large language models at a massive loss, does not own its infrastructure, and has absolutely no path to profitability outside of “we keep spending other people’s money.”
But that’s all the AI industry is — people doing impressions of things that have worked before in the hopes that they’ll work again. Every AI lab and startup started with cargo cultish subsidized subscriptions, assuming at some point somebody else would solve the problem of costs or that they’d “make it up in volume,” because that’s what worked before. OpenAI and Anthropic threw as much money at pre-training models because a paper had suggested that if they did so there would be infinite gains (versus diminishing returns), and when Anthropic worked out that you could add a bunch of scripts on top of an LLM to do coding better with Claude Code, OpenAI immediately copied that and made Codex.
Both companies are now jousting to make much the same product by giving away API credits and free weeks of access to create the symbolic aura of an “essential” product to continue convincing VCs and the public markets that they’re “building the future” rather than effectively paying their customers to use their products. The “popularity” of AI has come entirely from social pressure and endlessly-discounted access, and the very second that they charged the actual costs, their customers started freaking out and kvetching about whether AI has ROI.
Our economy is dominated by people who have only a symbolic understanding of the world — Business Idiots with little interaction with productivity or production who do not know how value is created and thus can only create facsimiles of valuable companies. Perhaps they’re lucky enough to have businesses that effectively run themselves, or monopolies that can survive having 98% of their free cash flow spent on AI data centers that only lose money, or are smart enough to stay out of the way of the people who actually do work.
But in many cases, the people running companies — especially those most-obsessed with AI — are cargo cultists following “the most valuable companies in the world” into a void that demands they twist every part of a company they don’t understand into a form that ingratiates them and makes them feel like they’re “doing business.” It’s an obscene and childish way to live one’s life, and typical of an economy that optimizes for growth at all costs thinking and coddles those who think that way.
Even the economics of the AI bubble are cargo cultish. The use of annualized revenues (the single-most easily manipulated metric in Valley history) as a means of promoting growth only exists as a means of spreading the symbology of hypergrowth, all while deliberately obfuscating the actual financial health of the company by using a single monthly (or weekly) snapshot to extrapolate an annual figure, something that’s particularly egregious when you realize that it involves non-recurring charges like spending money via Anthropic’s API.
Yet the Valley either realized (or was fortunate enough to find) that the media had bought into their cargo theology. Much like the Valley craves symbols or prophetic signs that today’s startups will become the next Google, modern tech and business journalism runs not on any scrutiny or skepticism of the future but in finding the “next big thing,” which often requires it to find the very same symbols that the Valley craves, often provided by the executives themselves.
They crave to be the ones to find the next Jobs, Zuckerberg, Bezos, or Gates, and in their crazed search only seek to repeat the same mistakes of every bubble, never noticing that the tech industry has had an astonishingly bad record for more than a decade.
The tech industry must always be framed as an impossible-to-decipher monolith full of troubled geniuses that have good intentions, because when you stop thinking that way, you start seeing it for what it really is — a vehicle for symbolic capital that stymies innovation and promotes growth over everything, funding things based on their similarities to the past and how warm and fuzzy doing so makes them feel. And in its incredible success as a vehicle for capital, tech has managed to beguile society and turn journalists, economists and regulators into cargo cultists that can be easily won over by a smart-sounding guy or an emphatic-enough press release.
AI is the natural endpoint of the Valley’s cargo culture — money-hungry models that can vaguely resemble something that might grow into the future, with opportunities to deploy capital that resemble previous infrastructure movements, all with convenient ways to explain away dissent that mostly boil down to “bad thing happen before but then good thing happen after.” Everybody believes that because AI startups can grow their revenue they’ll grow that revenue forever, that because startups in the past lost money that AI startups will stop doing so, and that because something has a lot of users it can never disappear.
I challenge everybody reading this to start living in the present, and to stop taking excuses for the mediocrity of AI. AI boosters are no longer allowed to speak in the future-tense, nor are they allowed to justify AI’s losses based on previous eras.
If you’re an AI booster yourself, know that the AI companies treat you with complete contempt. They force you to defend dogshit, to wheel and deal in dogshit, to celebrate dogshit like it’s caviar, to tell others that they too must defend dogshit, because one day the dogshit will be good.
Nowhere has this been more evident than the response to my exclusive last week.
Some have been mighty confident about inference being profitable (due to a $7.5 billion cost of revenue on $13.07 billion in revenue), but overlooked my reporting from last year verified by the Financial Times showed OpenAI spent $8.67 billion on inference in the first nine months of 2025. It’s very clear OpenAI moved around numbers to make things look better than they are, and I believe that inference costs are being dumped in sales and marketing.
How else are you to explain how a company spends more than 43% of its revenue ($5.73 billion) on sales and marketing — more than the Coca-Cola corporation, which has three ad agencies and a vast web of different print, digital, and physical ad spend. Microsoft had $500 million of “sales and marketing” spend too. What do you think that is? OpenAI spending $500 million on sales and marketing through Microsoft? Or itemizing promotional spend or the inference from free users as a sales and marketing cost?
If you disagree, please explain in any level of detail how OpenAI has spent $5.67 billion on sales and marketing. Its first major advertising campaign was in September 2025. If it’s spending $250,000 a year on its 500 sales staff, that’s still only $125 million. Unless OpenAI is one of the single largest accounts in digital advertising, I think it’s far more likely that there are actual costs being hidden.
This is the kind of thing a company does when it has utter loathing for its investors and the general public — a brazen attempt to bury costs to make things feel better for an audience that’s directly incentivized to take any shred of proof that things are okay, even if said “thing” is the suggestion that a company that lost $21 billion only actually lost $8 billion.
Alternatively, it’s what an industry does when it believes everybody is gullible enough to accept and promote any rationalization that confirms their beliefs.
So far, they’ve been proven right. Every time I show somebody the kind of tangible proof that these companies are economic septic tanks, somebody uses some sort of theological, mythological or historical statement as proof that what I’m saying doesn’t mean anything. Silicon Valley, the so-called hub of meritocracy and rugged individualism, runs on a kind of empty cultish ephemera that usually ends with sedative-laden Kool Aid.
In the end, faith can’t fill your belly, or cover $1.1 trillion in compute commitments. It can’t magic up $2 trillion in revenue by 2030 for an industry that basically doesn’t exist without OpenAI or Anthropic.
And however you feel about AI, you should demand better proof of its inevitability than a bunch of mythology, hype, and cargo cult bullshit.
If you liked this piece, you should subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 10,000 to 18,000 words, including vast, detailed analyses of the biggest events and companies in the AI bubble.
2026-06-20 01:03:48
So it’s been a big week for me after I published an exclusive covering OpenAI’s audited financials from 2024 and 2025, with reactions ranging from “oh my god, OpenAI spent $34 billion to make $13.07 billion in revenue!” to “actually, it’s good the company lost $21 billion.”
And that, my friends, is the Silicon Valley Bubble writ large – an industry that grew rich and famous off the back of a mythical pragmatism and meritocracy that’s morphed into a pseudo-cult built to protect venture capital investments at the cost of reality.
OpenAI lost $21 billion in 2025. $867 million – or around 6.6% – of its revenue came from SoftBank, I posit (though cannot confirm) is something to do with its supposed “Crystal Intelligence” (formerly Cristal Intelligence) initiative with OpenAI, announced in February 2025 as part of the alleged formation of SB OAI Japan, which only actually formed in November 2025.
I severely doubt that SoftBank was a significant cost center for OpenAI given the timeframe, which means that this likely inflated its revenue significantly, and in a way that was disproportionate to its expenses.
There is no justification for this kind of burnrate. There is no sensible, logical or rational reason to look at this company and think that there’s some magical way it’ll become profitable or sustainable. The fact that OpenAI magicked away billions of dollars of costs using bizarre “net losses attributable to noncontrolling members capital” suggests that there are connected entities that the company has yet to disclose, and nothing about this accountancy voodoo changes the fact that OpenAI spent $34 billion to make $13.07 billion. While I cannot speak to its exact intentions, I can see no reason to do this kind of thing outside of trying to obfuscate the horrible state of the company.
Every attempt to rationalize these losses only serves to prove that Silicon Valley itself is a bubble. This is no longer a community concerned with building the future, but building a capitalized consensus, an idea of where money should flow and to whom it should flow to. Gone are the days when plucky software engineers built “bootstrapped” companies that raised rounds based on their theoretical growth, total addressable market, and potential for industry capture. They’ve been replaced by a pseudo-philosophical belief that spending billions on training large language models will somehow turn into a theoretical computer that does its own research, eliminating the need for Silicon Valley to ever have another idea again.
That’s because the Valley has been captured by people that haven’t done any real work in years, haven’t built very much of anything, and thus will fall, well, for just about anything. They don’t see the problem in describing relatively boring cloud software that can write code based on natural language prompts as the path to a sentient computer, or the fact that these companies have mostly sold their software based on fear-mongering.
Per Cal Newport in the New York Times:
When it comes to A.I., we’ve become so used to this tone of helpless, stress-inducing prognostication that we’ve lost sight of its strangeness. Imagine if the Ford Motor Company put out a report saying that it feared its popular F-150 trucks might soon start bursting into flames, but that there was nothing the company could do about it because automotive technology was too inevitable and important to slow down. You’re probably struggling to picture this scenario because no reasonable consumer product company would ever act like this.
The A.I. companies could start behaving the same way. To do so would require that they stop treating A.I. like some inevitable force that they’re struggling to steward. It’s not. It’s a collection of specific tools that these companies are choosing to design and sell according to specific business plans. Accordingly, they need to talk about their offerings like any other consumer product. This means explaining clearly whom these products are for, justifying their benefits and, critically, taking full responsibility for any harm they might cause. Just because A.I. currently enjoys a high-tech sheen doesn’t make it exceptional with respect to common-sense safety standards.
This kind of specious hype and doom trolling exists to make you ignore the current state of AI models in favor of a theoretical better state that you can extrapolate from what you’re being fed by the companies. If you’re scared of AI, you assume that being able to get Claude Code to barf out a copy of some open source software is merely a precursor to automating all software, or even all jobs. If you’re excited about AI, you’re excited because you believe you’re on the ground floor, which will give you incredible advantages when all the things that Dario Amodei and Sam Altman have vaguely promised have come true.
To engage with AI hype is to become its supplicant. You cannot talk in the present tense. You cannot accept any negativity. You must ignore any signs that things are bad and repeat the necessary shibboleths. You must applaud literally any chart or weird, meandering blog that suggests that at some point something good will happen. The Silicon Valley bubble demands you ignore your lying eyes, because if you start thinking about things rationally — as in talking about the stuff LLMs do today and the underlying economics — things become increasingly more-worrying.
In a conversation with Cal on my podcast Better Offline, he also noted that some have tied their pride to their belief in the “incredible” future of AI, interpreting any naysayers as directly attacking their identity rather than critiquing software and the people building it. Perhaps it’s that they swallowed the hype after a particularly vigorous Claude Code session, perhaps it’s that they want to believe that Silicon Valley has “still got it,” but many AI boosters act as if they’re living in the cold, harsh realm of reality as they desperately grasp at straws.
They don’t actually want to hear contrarian points, nor do they want to know about the financials. All they want are more ephemeral talking points to parrot so that they can fool themselves into believing they’ll be rewarded by an industry built on doomerism, fantasy, deception and outright lies. While this existed in different forms in the past — with cryptocurrency, for example — nothing has ever captured the minds and wallets and hearts and social media presence of Silicon Valley more than AI, a technology that can mean anything you need it to, even if it can’t really do anything you’re promising.
The problem is that the world looks to Silicon Valley to explain what the future might be, and when Silicon Valley is captured by people that are either deranged pseudo-philosophers or cynical growth-drunk egoists, very little actual, real value is created. The stock market depends on Silicon Valley to create the next generation of growth — both in the form of new companies and the next chum for the Magnificent Seven to force upon its monopolized customers — but has never let a hype cycle poison its veins this thoroughly or destructively.
Today’s piece — the second (and final) part of the Silicon Valley Bubble series — is focused on how Silicon Valley’s reality distortion field has escaped containment, exploiting intellectual weaknesses throughout organizations and economies by promising a near-infinite source of capital.
The AI bubble has grown by promising everybody something — a cure for a tech industry that’s run out of hypergrowth ideas, a way for public (and private) companies to promise infinite growth, a way to paper over the collapse of growth throughout the software industry, and a way to convince the general public that the tech industry is an infinite flywheel of ideas rather than a machine custom-tweaked to extract capital through monopolies.
The problem isn’t simply that it will eventually need to make good on those promises, but rather, what those promises do in-and-of-themselves. Like a caustic acid, they’ve deformed and reshaped so much of what we consider to be the tech industry, changing incentives and eliminating what was once considered the guardrails against the kinds of reckless exuberance we’re now seeing.
Coming Up On This Week’s Where’s Your Ed At Premium
2026-06-16 11:58:20
Soundtrack: In Flames - Colony
To further support my independent journalism, please subscribe to my premium newsletter. It’s $7 a month or $70 a year. If you’re subscribed to the free newsletter and logged in, you should see at the bottom right hand corner of your screen a little circle you can click, and you’ll be able to sign up for premium.
Also, if you have anything to share - like, say, the audited financials or cloud spend of any major AI lab - please hit me up at ezitron.76 on Signal.
Today, I can exclusively report, based on audited financial documents viewed by this publication that have been independently verified by the Financial Times, that OpenAI lost around $38.5 billion in 2025, as well as other crucial details about the financial condition of the company.
Due to the seriousness of this story, I am not going to do very much editorializing, as the numbers speak for themselves.
OpenAI’s financial statements tell the story of a company with incredible losses.
Additional factors – including interest income and interest expense – left it with a net loss of $8.84 billion. It then marked $3.74 billion of losses as “net loss attributable to noncontrolling members capital,” leaving the net loss attributable to the company as $5.09 billion.
It’s unclear what this means, nor how OpenAI reconciled the removal of $3.74 billion in costs. I will not speculate further.
Please note that 2025 was the year that OpenAI converted from a non-profit to a for-profit entity, leading to a $41.55 billion loss due to changes in fair value of convertible interests and warrant liability.
Taking into account other minor factors like interest income and interest expense, OpenAI is left with a net loss of $60.35 billion, which it lowered to $38.53 billion by removing $17.87 billion in costs via that “net loss attributable to noncontrolling members capital” and another $3.95 billion via a “net loss attributable to redeemable noncontrolling interests.”
Ultimately, the net loss attributable to OpenAI in 2025 was $38.5 billion.
At the end of the year, OpenAI had just over $50 billion in assets, with almost half of that in cash.
In 2025, SoftBank paid OpenAI $867 million. Microsoft paid it $303 million.
The documents revealed how much OpenAI paid Microsoft for services. In the 2025 calendar year, OpenAI paid Microsoft $10.59 billion for “Research and development” expenses. We believe this most likely refers to the cost of training OpenAI’s models.
The documents also mention a $6.047 billion charge related to “cost of revenue,” a $527 million charge for sales and marketing, and $42 million in “general and administrative expenses.” In total, OpenAI’s expenses to Microsoft amounted to $17.2 billion.
According to the figures, OpenAI had liabilities to Microsoft of $3.64 billion at the close of the calendar year, and additional $21 million in “accrued expenses and other current liabilities.” The documents also mention a further $58 million in non-current liabilities.
I intend to follow up this story in the next month with more in-depth reporting related to the documents. The documents are detailed, and I need time to fully parse them. Once I have done so, you’ll know.
The financial condition of OpenAI is deeply concerning. $38.53 billion in losses are astronomical, and far higher than most believed it would be. Losses also appear to be mounting year-over-year at a dramatic rate, and I’m not sure how this company finds a way toward any kind of sustainability or profitability.
As discussed, I have not editorialized much today. I believe the best thing I can do for the general public is to deliver this news as plainly as possible.
As I mentioned at the beginning, if you liked this piece, you should subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 5,000 to 18,000 words, including vast, detailed analyses of NVIDIA, Anthropic and OpenAI’s finances, and the AI bubble writ large. My Hater's Guides To the SaaSpocalypse, Private Credit and Private Equity are essential to understanding our current financial system, and my guide to how OpenAI Kills Oracle pairs nicely with my Hater's Guide To Oracle.
2026-06-16 03:28:23
If you liked this piece, you should subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 5,000 to 18,000 words, including vast, detailed analyses of NVIDIA, Anthropic and OpenAI’s finances, and the AI bubble writ large (updated to version 3.0 last week). My Hater's Guides To the SaaSpocalypse, Private Credit and Private Equity are essential to understanding our current financial system, and my guide to how OpenAI Kills Oracle pairs nicely with my Hater's Guide To Oracle.
Last Friday, I published the first of a two-part series where I explore the many bubbles that form the basis of the AI bubble — including the tokenomics bubble, and the cult of personality bubbles surrounding Sam Altman and Dario Amodei.
Subscribing to premium is both great value and makes it possible to write these large, deeply-researched free pieces every week.
Soundtrack — Local H — Manifest Destiny (Part 2)
We live in a time of deep uncertainty. On Friday, Anthropic was forced to shut off access to its Mythos and Fable models after the US government imposed an export control ban barring any non-US citizens both inside and outside of the country from accessing them.
To explain, Fable is basically Anthropic’s supposedly “too dangerous to release” Mythos model with guardrails forbidding you from what appears to be anything biological weapons and cybersecurity, except it was jailbroken within days by Amazon researchers, leading to Amazon CEO Andy Jassy (and other unnamed companies) reporting it to the US commerce department which gave Anthropic 90 minutes to roll back Fable and Mythos due to “national security risks.” Semafor also reports that this all might have happened because China got access to Mythos.
This situation is a complete mess. PCast co-chair and podcaster David Sacks claimed that Anthropic refused to fix the issue, claiming it wasn’t serious, per Business Insider:
During the calls, Amodei tried to clear up what he assumed was a misunderstanding. He pushed back on the administration's concerns, defended the guardrails, and argued that the type of bypass that occurred, which he believed to be specific, did not pose the same risk as a broader "jailbreak" that would allow it to be used without any of the guardrails put in place by Anthropic.
In a blog post after the export controls were put in place, Anthropic said that "no testers have yet been able to find a universal jailbreak — a jailbreak method that can very broadly bypass the model's safeguards, unblocking a wide range of cyber capabilities," and that total avoidance of any jailbreaks isn't now possible for them or any other companies. They defended their systems, which they said "are so strong that many users have complained that they are overly broad."
A White House official told Business Insider that “export controls were a last resort after begging them for hours to work with us”:
Shortly after the call, the Trump administration imposed its export control on the Fable 5 and Mythos 5 models, citing national security authority and banning their use by foreign nationals, according to Anthropic. The company said the "net effect" of the order was to "abruptly disable" the models for all customers "to ensure compliance."
Anthropic claims no begging occurred, and all it got was (as noted above) 90 minutes. According to Axios, the company has dispatched some of its senior technical staff to D.C to negotiate with the Trump Administration, after virtual meetings with White House officials failed to bear fruit.
In any case, this is a reaping/sowing for the ages. Dario Amodei has spent years selling AI models based on completely fantastical scaremongering about the “rapid advancements” of large language models, cresting the hill in April when he announced Claude Mythos, an LLM that was “too powerful to release” until June 2, when it was released to 150 organizations in 15 countries, and June 9, when it was released with said guardrails under the name “Fable.”
Fable is, of course, just another large language model that’s an indeterminate amount of “better” than the last one. Having talked to multiple people that claim to have used Mythos and deeply enjoyed Davi Ottenheimer’s takedown of its system card, it appears to be much the same model but with security protocols flimsy enough to last only a few days before anonymous researcher Pliny The Liberator broke them. Anthropic has not created recursive self-improvement, nor has it done much more than create a very large language model that gets higher benchmarks in tests built for large language models, wrapped in a veneer of mysticism and panic-hype built to scare organizations in paying them to use it.
The problem with this kind of hype is that you can only use it for so long before somebody believes you. The outright mythology of Mythos existed to scare people and help Anthropic raise at a $965 billion valuation, and because the tech industry has existed fairly divorced from reality, scrutiny, and regulation, Dario Amodei continued to inflate the “Anthropic is too powerful” bubble, believing that all that would happen would that he’d create a new enterprise API business.
Some are attempting to read this story as bullish for Anthropic — that the government will work with it to bring the models back online, creating a proxy marketing campaign for its models — and while I think that’s possible, if not likely, I think there’re many other possibilities.
On Sunday, slopagandist and Microsoft CEO Satya Nadella posted a mealy-mouthed blog on Twitter that didn’t really say very much of anything, but had two interesting comments:
The last thing any of us want is a world where every company across every sector is ceding value to a few models that eat everything they see. If all the value is accrued by only a few models, the political economy will simply not tolerate it. There is no societal permission for an AI future that hollows out entire industries.
…
In my view, our priority has to be building a frontier ecosystem, not just a frontier model, so value flows broadly across every company, every industry, and every country. One where every organization can own the learning loop that encodes its institutional knowledge, compounding its human and token capital.
This, combined with Microsoft AI CEO Mustafa Suleyman saying Anthropic’s models were too expensive and Andy Jassy likely being part of the reason that Anthropic got banned makes me think that hyperscalers might be trying to cast doubt on the inevitability of AI labs. While Nadella’s piece has clearly gone through 8 PR people and 16 lawyers, it seems to smell of a company saying that no one model actually matters, and given that it was posted on a Sunday, I’m going to guess it’s about the current Anthropic situation.
It’s hard to see how everything goes back to normal from here. Even if Anthropic gets its models greenlit for availability, it’s clear the government has some animus against it after Q1’s battle with the Department of Defense, and may or may not have been waiting for an opportunity to rattle Dario Amodei’s cage.
And, according to Axios, there’s a real animus between the US government and Anthropic, caused in part because of its “inability to communicate effectively,” with one source saying that “Anthropic has not done a great job at trying to speak to the administration and appreciate the ideological differences."
Alternatively, the government has taken Anthropic’s (nonsensical) marketing seriously, and thus decided to take the kind of blunt-force authoritarian position you’d expect — shut the whole thing down, as China might use Mythos to uh, do something!
The other problem is that this is terrible, terrible timing for an AI industry in the throes of a cost crisis. Anthropic and OpenAI’s IPOs depend on myth, hype, and certainty that their growth will never slow. The government’s ability to cut off access at random based on genuine concerns or politicking isn’t a great advertisement at a time when everybody is struggling to find the ROI of AI.
This isn’t a Too Big To Fail or nationalization situation. Amazon and Microsoft are far more scared of the White House than they are of killing their golden goose, and may honestly be relieved to find a reason to bring this era to an end.
You see, Anthropic and OpenAI have much bigger problems than regulation or pissing off Pete Hegseth.
Their business models don’t fucking work.
I’ve been saying for years that the underlying economics of AI don’t make sense — that AI labs were intentionally obfuscating the costs of subscriptions and heavily subsidizing users’ compute, and that the moment that that changed, everything would begin to fall apart, and god damn has it finally begun.
As I discussed in last week’s premium newsletter, the AI Tokenomics Bubble is the simplest and most consequential of them all, because it comes back to something I’ve been saying for years: that the majority of users will refuse to pay the actual cost of AI.
Said bubble inflated through the combined failure of the tech and business media to question AI’s economics and the unprecedented subsidy con perpetuated by Anthropic and OpenAI. Those who dared to suggest that OpenAI burning $5 billion was some sort of problem were dismissed as haters and skeptics that “didn’t care about the future,” with the vast majority of the media completely ignoring the economics until the latter half of 2025.
The Tokenomics Bubble inflated because everybody aggressively ignored the AI industry’s greatest weakness, choosing instead to repeat tired mythologies about how Uber lost a lot of money (which I’ve refuted here) or Amazon Web Services cost a lot of money (Amazon’s total capex between 2003 and 2017 was $52 billion normalized for inflation) instead of being skeptical of…well, anything.
And now it’s bursting because Anthropic and OpenAI’s customers are in revolt, to the point that they’re planning “drastic” price cuts.
Alright, let’s do this one last time.
Sometime early in Q1 2026, Anthropic and OpenAI moved all of their enterprise customers to token-based billing, meaning that instead of using subsidized subscriptions with varying (and ridiculous, as I’ll get into) rate limits, big businesses suddenly had to pay for their AI usage based on the actual tokens they used.
Many hailed this as a masterful gambit, assuming that organizations would have near-infinite budgets for AI services that had yet to prove themselves useful.
It only took a few months for OpenAI and Anthropic’s customers to start sweating.
In the middle of April, The Information’s Laura Bratton likely burst the AI bubble with a piece about how Uber had burned through its entire annual token budget in a single quarter.
This kicked off an industry-wide anxiety about the mounting costs of AI, with multiple other companies burning millions of dollars in the space of a few months, including Zillow, which destroyed its annual Cursor budget by the end of May. What really began the downfall was a comment by Uber COO Andrew Macdonald:
"That link is not there yet, right?" he said. "I think maybe implicitly there is more that is getting shipped, but it's very hard to draw a line between one of those stats and, 'Okay, now we're actually producing 25% more useful consumer features."
He said that the trade-off costs from AI are harder to justify because he can't draw a direct link. Earlier this month, CEO Dara Khosrowshahi said in an earnings call that Uber was slowing hiring to counter its investments in AI.
In a single podcast, Andrew Macdonald gave the entire tech industry permission to say the truth: that nobody was actually able to show any ROI despite its massive costs.
This was always going to be a problem. By starting everybody off with subsidized subscriptions, AI labs shielded users from the costs, training them by proxy to use AI models without any concern for efficiency.
That, and organizations are run by Business Idiots beguiled by a captured tech and business media and a complete disconnection from actual work, meaning that they’d encouraged (or forced) their workers to use AI as much as humanly possible, never once thinking about the costs until they were made to by the AI labs. All it took was a few months of tokenmaxxing to start turning organizations’ stomachs.
This began an increasingly-anxious conversation around AI’s ROI, made worse by the fact that you can’t measure the cost of a task because of the sheer number of models and harnesses, and can’t cleanly translate “AI spend” into “actual financial outcomes.” Toward the end of May, Axios would publish a story about how a company somehow spent $500 million on Anthropic tokens in a single month after failing to set up cost controls.
A few days later, Sam Altman would make a massive fuckup, saying that customers were “totally happy” with their AI spend at the beginning of the year (before token-based billing), and that spend was now a “huge issue,” likely because the costs vastly increased.
Boosters would immediately argue that these massive costs were, in fact, proof that AI was very successful, even if said “success” came from organizations that let their workers burn as many tokens as humanly possible without any consideration of the cost. As I’ve argued previously, the vast majority of Anthropic’s recent surge in revenue comes from experimental revenue from paypigs that it doesn’t deign worthy of clear visibility into their organizational token spend.
In any case, OpenAI and Anthropic need to make a combined $358 billion in annual revenue by 2029 to keep up with their $1.1 trillion in compute commitments. Any slowdown in their growth, as I discussed last week, would be fatal to two companies that have marketed themselves almost entirely by putting the cart before the horse.
It turns out that Altman wasn’t kidding that costs were a “huge issue” for his customers.
Around a week later, The Wall Street Journal reported that OpenAI was planning “drastic” price cuts to its token prices in response to Anthropic potentially doing the same:
OpenAI is considering drastically lowering the prices it charges users as it seeks to win customers from its rival Anthropic.
The company is weighing significant cuts to what it charges for tokens, the unit of measurement artificial-intelligence firms use to bill for their products, according to people familiar with the matter. The move would be in anticipation of similar cuts the company expects at Anthropic, the people said.
Business executives have begun to balk at the high prices for AI usage. OpenAI Chief Executive Sam Altman said at a recent event that costs had become “a huge issue.”
If you’re wondering why they might be doing so, earlier in the day, Cisco President and Chief Product Officer Jeetu Patel said exactly what everybody had been thinking but were too scared to admit: that “...the costs of [AI tokens] are far higher than the actual value that these tokens are generating at scale.
I cannot express how deadly these price cuts would be to the AI industry, and how dangerous this conversation has become. The move to token-based billing has created a revolt in the AI industry’s customer base, coming from (as I’ve discussed) a confusion around the actual ROI and utter despair around the costs.
Depending on how “drastic” these discounts are, any (entirely theoretical) gross margin these companies make on inference will be eaten alive…all so that OpenAI and Anthropic can…uh…decrease their revenues? It’s a desperate strategy being deployed, I imagine, because of a massive wall of customer churn as a result of Business Idiots spunking millions of dollars on tokens they’re no longer able to justify.
Remember: we’re less than three months in to organizations paying the actual costs of LLM-based services, and they’re clearly so outraged at the spiralling costs that both Anthropic and OpenAI are planning to cut the prices of an already-unprofitable service, likely collapsing their revenues while increasing their overall costs.
I anticipate a few booster quips in response, so let’s address them head-on:
Here’s what Jevon’s Paradox means, per Planet Money:
It was within this context that economists rediscovered the Jevons paradox. And they created a modern formulation that's a bit more nuanced. The idea is that making things like cars and appliances more energy efficient creates a "rebound effect." When you make a machine more energy efficient, it effectively lowers the cost of using it. And — hello, the classic law of demand from economics — when stuff gets cheaper, people tend to use or consume more of it.
So, for example, with more-fuel-efficient cars, it gets cheaper to travel every mile, so people drive more miles. Some may decide to stop riding the bus and buy a car. Some families may buy a second car. Others may buy bigger vehicles, like SUVs. With more-efficient light bulbs, people may keep their lights on for longer or build things like the Sphere in Las Vegas.
Newsflash! These price cuts are not happening because Anthropic or OpenAI made their products more efficient! They’re making these price cuts because their customers don’t want to pay their current prices!
In fact, their costs appear to be increasing, which is why they’ve raised (assuming the rounds completely close) over $230 billion in the last six months. You don’t do that unless you think your costs are about to explode or, I dunno, you’re about to massively increase your losses, though the timing and velocity of these price cuts suggests this was a very recent idea.
Oh, right, Jevon’s Paradox! This isn’t that. These companies aren’t getting more efficient. They don’t have any bright ideas to make their businesses lose money, and in fact seem pretty incompetent when it comes to growing their revenues outside of scamming dimwits and selling people $40 for $1.
And that is not hyperbole.
So, you know how I keep going on about “subsidized subscriptions”? And how people online keep saying that they’re not really subsidized?
Well, SemiAnalysis, an extremely pro-AI semiconductor analyst, ran a test made up of random long-horizon coding tasks until they maxed out the limit on OpenAI and Anthropic’s various subscription levels.
Their findings were shocking.
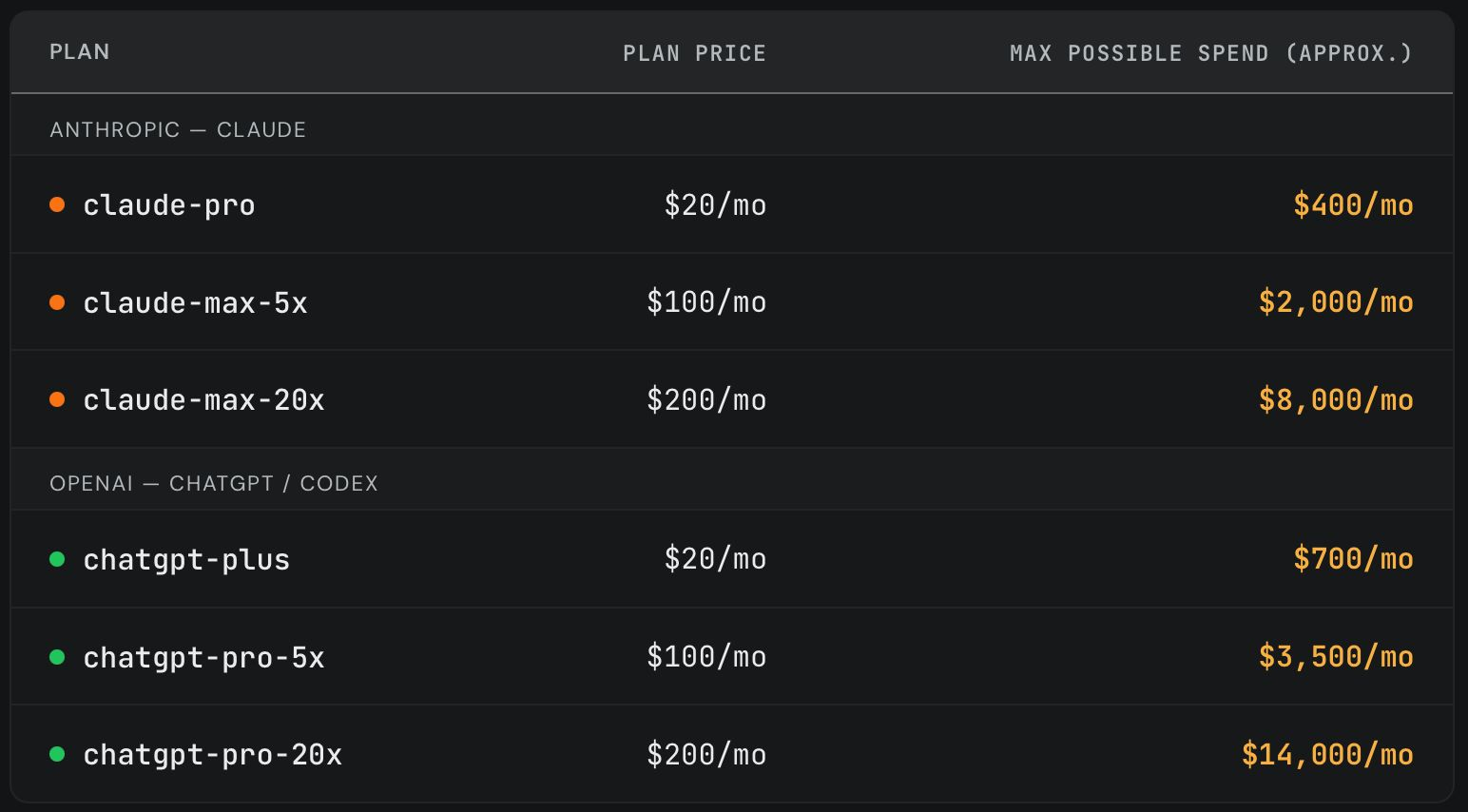
That’s right. Anyone with a $200-a-month Anthropic subscription can burn $8000 in tokens, and with a $200-a-month ChatGPT subscription, you can burn $14,000 in tokens.
This business fucking stinks! It’s not even a real business! OpenAI and Anthropic have to give away somewhere between 20 and 70 times the cost of their subscription in API tokens, which means that they realize that the vast majority of people value these tokens at a fraction of their real cost. This obscene and wasteful subsidy is what you do when you have little to no confidence in the actual value of your product!
Sidenote booster quip: But Ed It’s The Gym Model! Newsflash, chuckles! If you’ve got 2000 people who pay $20 a month but barely cost anything it only takes three people spending $14,000 to eat every single dollar of that revenue! And trust me, I’m about to get to the margins.
SemiAnalysis also modeled out — based on the ridiculous assumption that OpenAI and Anthropic have a 75% gross margin on their tokens — what the margin of a user looks like, and I’m sure it’s f-OH MY GOD!
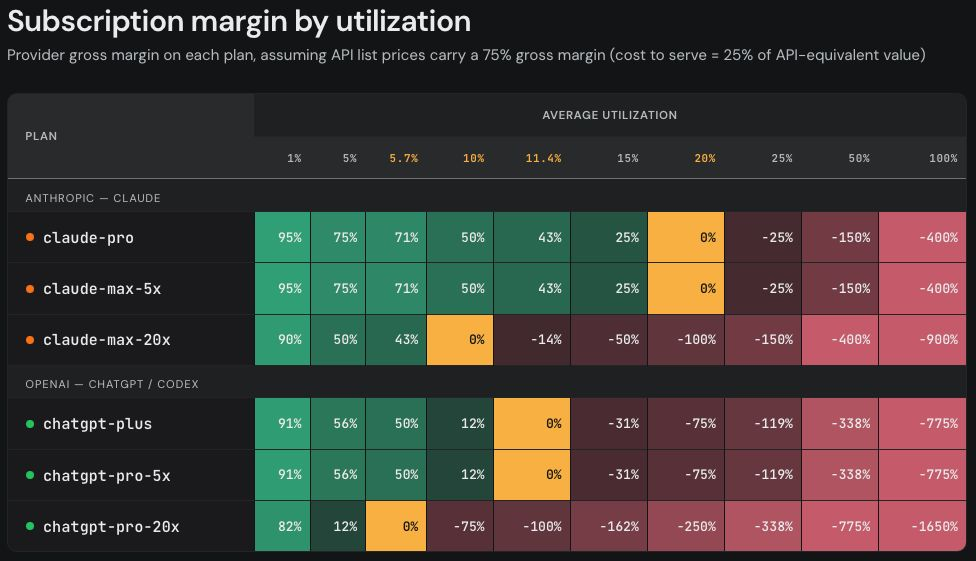
That’s right folks. With the current subsidies, all it takes for a user to have a gross margin of at best negative 25% is for them to use as little as 25% of their rate limit. And this is based on the generous assumption that they have a 75% gross margin on tokens!
I’ll repeat myself: this is not a real business! This is a joke business, a comedy business, a business invented by the Gods as a means of mocking venture capital! For Sam Altman and Dario Amodei to run a business in this fashion is a sign that they have utter contempt for their investors, the tech media, sell-side analysts, and the general public. If you or I ran our lives in this way, we’d be called fiscally irresponsible millennials that believe the world owes us everything.
This isn’t a real business model because generative AI companies are not real businesses.
Generative AI does not have a business model. It is not a tool with value remotely commensurate with its costs. It isn’t getting cheaper for the providers or the customers. It isn’t becoming “better” in a way that’s measurable using anything other than benchmarks invented specifically for generative AI — an industry-wide coddling of a mediocre technology that only makes money through massive subsidies, FOMO and executive ignorance. It requires endless pre-training, post-training and script-based MacGuffins to do tasks with mathematically-guaranteed hallucinations that burn more tokens, raising costs on customers who are already in mutiny less than a quarter into being forced to pay a cost that is already unprofitable.
Boosters and the recently-concussed will say that these companies can simply stop training, to which I say if that was possible they’d have already done it, and if they stop training, the models will eventually drift into obscurity. If stopping training was all that it’d take to turn these businesses profitable, they’d have done it already, because inference would be a money-printer rather than a cursed object eating away at Altman and Amodei’s souls.
I’ve said it once and I’ll say it again: I believe a large majority of AI token spend — and specifically Anthropic’s revenue growth — has come from Business Idiots disconnected from any real work that have become convinced that “lots of AI” would do something other than rack up massive bills.
And wouldn’t you know I was right!
A little over a month after encouraging its workers to “tokenmaxx,” Meta is now planning to pull back on its AI token spend after realizing it was on track to spend billions on tokens, per The Information:
Meta Platforms plans to clamp down on skyrocketing AI costs inside the company by imposing limits on employees’ token usage, the company told staff in a memo on Tuesday, just weeks after it pushed them to adopt AI tools in their work.
The company is building an internal platform to track employee AI usage and spending in real time, set budgets and establish limits on employees’ token spend, according to an internal memo reviewed by The Information, which Meta shared with about 6,000 staffers earlier this week. The effort is part of a broader efficiency program aimed at cutting costs.
“We’ve seen an exponential increase in AI usage and [we] are tracking to spend billions on internal use alone in 2026,” the memo said. “At the same time, individuals and teams have limited visibility into and control over how they use AI. In 2027, we expect Meta will move toward managing AI tokens in a more structured way—with budgets, allocation decisions, and supporting tools.”
It didn’t even take two months for Meta to go from encouraging its employees to compete to burn the most tokens to talking like a British MP giving a speech about austerity measures.
Meanwhile, The Times reports that banks are running up massive nine-to-ten figure bills from “experiments with artificial intelligence tools”:
Ben Faes, chief executive of RWS, said that businesses were becoming increasingly conscious of the costs involved, without a clear outcome on how it should be used.
“It is very exciting, but you know the cost of playing around with all this AI is rising quite dramatically,” he said.
Faes, 54, said he had spoken to two large banks which between them had racked up $1 billion in costs from experimenting with AI without generating a significant return on investment.
“It is a serious point,” he said. “AI isn’t about generating pictures of cats on skateboards. It’s becoming a serious cost centre for businesses.”
These are the kinds of things you say when you’re planning to drastically cut costs, and I think Uber’s COO gave everybody permission to admit the lack of ROI or, well, any measurable benefits of spending millions of dollars on AI tokens.
Remember: Business Idiots are lemmings! The only reason they wanted to “do AI” was because they read it in the newspaper or heard somebody they thought was intelligent insist that it was the future. These people are extremely sensitive to suggestion (see: Nik Suresh’s Brainwash an Executive Today) and marketing hype, which means they’re also extremely sensitive to peer judgment, meaning that if the worm turns and everybody starts saying “I’m not sure we should spend as much money on AI,” they’ll become anxious to be judged as wasteful for doing something that was considered innovative mere months ago.
Some are suggesting that lower-priced open source models (including some developed in China) for some operations could be the solution, per the Wall Street Journal:
The ecosystem allows autonomous AI systems, or agents, to use cheap models—including those made by Chinese companies like Alibaba and DeepSeek—for many functions. The agents only tap the most capable versions of OpenAI’s ChatGPT and Anthropic’s Claude for more complex tasks. That can reduce costs for some AI-assisted work by as much as 95%, according to executives using the tools.
“Once we find something that is working well and engineers love, we find ways to make it cost effective,” said Dan Robinson, founder of Detail, a startup that identifies bugs. “There’s really an embarrassment of riches right now coming out of the open source labs.”
Robinson shifted 90% of Detail’s workload from Claude and Google’s Gemini to custom models and GLM, a family of models developed in China.
The problem with this argument is that we’re yet to prove if running these models is profitable (or even sustainable) for any provider, nor do we have tangible proof that they can compete at scale with Anthropic or OpenAI’s more-complex LLMs.
Citadel Securities argued late last week that they might be:
For the economy at large, simpler models may be the more cost-effective, productivity-augmenting pathway until physical constraints are eased. We hence see growing signs of a bifurcation in frontier vs “everyday” AI usage.
The problem is that the hundreds of billions of dollars of AI data centers full of NVIDIA GPUs are being built with the expectation that there will be incredible demand — over $150 billion a year just to cover what’s under construction — for very large and compute-intensive models. I am still skeptical that this is a real shift away, if only because using open source models requires you to either work with an inference provider or run your own GPUs.
Nevertheless, even the hint of this migration is enough to start making Business Idiots say “hmmm, what about open source?” even if they don’t know what that means.
But everything comes back to one very simple point: that a lot of AI use (and by extension AI spend) is from the cargo cult mentality of an economy run by the most easily-led dullards in history. They jumped on the AI train because they saw a webinar or read a LinkedIn post or saw a news story about Sam Altman saying his tech was scary or an Atlantic piece saying that Claude Code was ChatGPT 2.0 and thought “fuck, I better throw as much money at this as possible.”
In the end, what is it these organizations are paying for? They’re not replacing anyone, and there isn’t compelling evidence that AI models speed people up. Allowing non-technical people to use LLMs to write code isn’t speeding up the delivery of software in a measurable way, and introduces obvious problems in the sense that, well, you’ve got a bunch of code written by somebody who can’t read or understand it.
People will argue that AI is “really helpful with research,” despite the fact that any research you receive from AI will absolutely have hallucinations, meaning that if you don’t actually know what the answer is to a particular question (which, I assume, is why you researched it), you’re certain to have some sort of small (or large) fuckup.
In a story that’s a little on the nose, The Financial Times reported last week (covering a study by GPTZero) that a KPMG report (that’s now been taken down) about the benefits of AI had exaggerated the scale of its adoption through multiple AI hallucinations:
The October report, “Redefining excellence in the age of agentic AI”, made numerous false claims about the use of AI by organisations including the Swiss bank UBS, the UK’s National Health Service and the public transit groups Swiss Federal Railways and Transport for London.
The inaccuracies were identified as AI hallucinations by the research group GPTZero and verified by the FT. After being alerted to the issue, UBS said it would ask KPMG to remove the false claims, and the Big Four firm on Thursday pulled the report from some of its websites.
The KPMG report claimed global wealth manager UBS “integrates AI agents across investment advisory, risk management and compliance monitoring”. A spokesperson for [UBS] told the FT the assertions were “factually incorrect”.
The report also included hallucinations about AI agent use by Swiss Federal Railways, Transport for London and NHS Greater Manchester, fabricating entire integrations and product lines in a report that was likely used to justify billions of dollars of spend.
Per GPTZero, 40 out of 45 of the report’s citations are either fake, make critical mistakes about the contents, or lack enough detail to be used as proof. They also believe that whoever wrote the report let the AI do most of the work:
Our team suspects that the authors of Total Experience used an AI-powered referencing tool to generate the report’s citations because the errors are both mistakes typical of Large Language Models (LLMs) and consistent throughout the reference list. A human would not consistently paraphrase titles, mistake topics for authors (e.g., citation 9), or repeat information across multiple components (e.g., citation 2).
GPTZero also notes that the report is being cited by LLMs as evidence to prove the success of AI agents, poisoning the already-hallucinatory well of information that these models draw upon.
KPMG has annual revenues of over $39 billion, and sells something called KPMG Workbench which promises to “supercharge your business with [its] multi-agent AI platform, combining advanced, trusted AI agents with insights and deep industry expertise of KPMG professionals.” I assume these are the same professionals that greenlit the report.
It’s likely that this was a mixture of laziness and ignorance, but I also think it might be a situation where the person (or people) writing the report simply couldn’t find any real citations to prove their point, choosing instead to let an LLM crap out some thought-slop in the hopes that nobody would notice.
The fact that Anthropic and OpenAI have any business left after stories like these is proof that the vast majority of companies paying for these services are doing so because they feel pressured to by their peers, investors or the media.
That’s not a tenable business model! You can only get so far on FOMO, gaslighting, and the vague promise that something good will happen if you hand over your credit card.
Hell, let’s take it one step further: neither OpenAI nor Anthropic is a real business.
Let’s cut to the chase: these aren’t real companies!
Their businesses only function by subsidizing or swindling their customer base using deceptive media campaigns that say “let people use as much AI as possible,” and it’s becoming clear that token-based billing might genuinely not work as a viable business line.
The only hope that these companies had was the possibility that they could actually charge something approximating their real costs, though I’d argue that was only the case if there was the option for OpenAI or Anthropic to increase their token costs in the future.
To make matters worse, it’s abundantly clear that the vast majority of people would never actually pay for the tokens they burn. If OpenAI and Anthropic are allowing their customers to burn such egregious amounts of tokens, it’s because they’ve seen that their customers churn when they don’t get to do so. Anthropic’s aggressive rate limiting in March — which still allowed people to burn far more than their subscription cost! — likely scared the everliving shit out of them, to the point that they signed up to pay Elon Musk $1.25 billion a month for access to his Colossus data centers specifically so that they could give people higher usage limits.
The only way that these companies can make money is by giving it away. Both OpenAI and Anthropic have recently started handing out $1000 in API credits to convince people to move over to Codex or Claude Code.
Sidenote: Now OpenAI is allowing its users to “bank” their rate limits — meaning that instead of waiting for the weekly (or hourly) reset, you can choose to save them up and, I assume, use them back to back, allowing power users to effectively double-tap OpenAI’s servers once they’ve run through their usage.
Also, for the next two weeks, anyone they refer gets a free trial of Codex and both of them get another banked reset. This is a transparent attempt to juice user numbers at a cost of hundreds (or thousands) of dollars, and will almost exclusively be used by power users gaming the system.
Their services are not valuable enough for people to cover their business expenses, even if you remove the cost of training, which is so severe it drowns out every dollar of revenue on its own. They cannot raise prices — or even bring them in line with their costs — without their users flipping out. Their training costs are necessary to continue making their models an indeterminate level of “better,” which means that they’re a cost of goods sold, and not a capital expenditure.
As an aside: I’ve been told by somebody that Anthropic has been telling people that they can consider token spend a capital expenditure. I am warning any company in the entire world that if I find out you did this, I will haunt you for the rest of time. I will watch everything you do forever, as this is bullshit accounting that verges on fraudulent, and I can imagine some asshole is going to do it.
Anthropic and OpenAI want you to believe that their businesses can somehow turn profitable, yet neither of them have any explanation as to how. Anthropic negotiated discounted compute for the first two months of its SpaceX deal as a means of pretending to be profitable for a single quarter, but any price cut — or even customer churn! — will immediately put its finances in a kind of red usually reserved for the deeply embarrassed or steroid-enhanced.
They do not have a plan.
You can go on about TPUs, Trainium, Inferentia, and custom silicon for as long as you like — it’s not profitable to run these companies, their costs are too high, and their customers are price-sensitive. Their customers lasted less than three months paying for their actual token burn before crying for mercy. There is no reversing this trend, because if there were, OpenAI and Anthropic would’ve reversed it in any way, shape or form, rather than raising more money than anyone has ever raised before for what appears to be no reason other than to burn it.
OpenAI and Anthropic are unsustainable and recklessly-run companies that do not make sense outside of the broken world of Silicon Valley. The tech industry and venture capital are run by a coterie of has-beens who create no value, and the vague memories of the pre-2015 era, before investors gave up on investing on seed stage companies and decided to joylessly trend-hop for years until they were driven insane by COVID lockdowns and “X: The Everything App.”
The tech industry is run by people who do not experience real problems or have to run real businesses, because a cluster of fellow grifters will vault them back into the black. Investments are no longer made based on rugged meritocracy or any interest in creating the future — it’s only about the Rot Economy’s mediocre growth-at-all-costs accelerationism and making varying numbers go up, though very rarely ones associated with profits.
I think it’s fair at this point to ask whether you could’ve just hired real people to do the shit that AI has done given its enormous cost. $14,000 could probably get you a great deal out of a real software engineer — hell, you could’ve probably hired an agency to do the work for you and actually have someone manage the risk.
The completely imaginary assumption about the AI industry is that it’ll magically get cheaper. That is not something that’s happening. More data centers will not make OpenAI or Anthropic profitable. More data centers will not make customers more willing to pay the actual cost of AI. More venture capital funding will not make Anthropic or OpenAI real businesses.
I agree with anyone saying there should be a pause in the development of generative AI, but I do so based on the belief that this is a doomed grift and science experiment masquerading as an industry that has only gone on this long because it allowed the hardware industry to extract hundreds of billions of dollars from startups, venture capitalists, asset managers, and retirement and insurance funds.
And anyone in Silicon Valley fooling themselves into believing they’re anything other than a corporate stooge is a mark.
The AI industry is the direct opposite of what made Silicon Valley famous.
It is a flattening of everything, absorbing the majority of venture capital funding, media attention, talent, and intellectual oxygen, invading whatever space you’re in because investors insist you must have something to do with AI and because everybody has been convinced they have to use it. It is an intellectual black hole, dragging every conversation toward it, demanding the most money, the most focus, endless justifications and defenses from people that must be rejected for questioning whether LLMs are the future. It debases and humiliates its fans by forcing them to constantly face indignities and embarrassments like it deleting entire databases or breaking AWS. It stunts the intellects of those who use it and, in demanding complete devotion to be considered “part of Silicon Valley,” suffocates the kind of meritocratic skepticism that allegedly got these fuckers so rich.
Silicon Valley was founded on the potentially fictional idea of plucky software developers that rejected the bounds of corporatism. It’s now ingested the worst qualities of corporate America — groupthink, trend-hopping, tribalism, hero-worship, managerial feudalism, and wasteful spending chasing things based on what might make a rich, heavily-coddled oaf smile. There is nothing daring or individualistic about Silicon Valley. At this point, you may as well work at fucking McKinsey.
Silicon Valley is the establishment. OpenAI and Anthropic are effectively owned by Microsoft, Google and Amazon — they do not have infrastructural or financial dependence, they principally run on their hardware, and if anything happens to them, they will likely be absorbed into multiple arms of the Magnificent Seven.
Their financial success benefits only the richest people in Silicon Valley and the wealthiest companies on the stock market. They sell themselves as democratizing software as they extract as many dollars as possible from venture capital, all while selling them back a story of spreading “abundance.”
AI represents the commoditization of startups as a fuel for tech firms with trillion-dollar market caps. AI startups exist only to send money upwards, burning Claude or GPT tokens that run on infrastructure built and owned by the very incumbents that the Valley allegedly takes pride in unseating.
The groupthink and monoculture of the Valley has gaslit these poor individuals into believing that there’s some sort of happy ending rather than a slow descent into insolvency, duping them into defending expensive, unsustainable tools using mythology that benefits only the richest people on Earth.
Someone recently said they think Anthropic and OpenAI are “the last startups,” saying that there was no point in building anything else as “everything has been solved or will be shortly.”
I agree, though for totally different reasons.
Anthropic and OpenAI represent what I believe may be the last hypergrowth startups, and their collapse (however it may happen) will represent the end of the dream of founding a little company that turns into the next Google or Meta.
Neither company was possible without the involvement of Microsoft, Google or Amazon, who provided their earliest funding and, most importantly, their entire physical infrastructure. Anthropic and OpenAI were always entirely dependent on these hyperscalers to shoulder the $100bn+ in infrastructure costs to make training their earliest models or serving inference possible.
The reason there are no other Anthropic or OpenAI-sized startups is that neither of them are actually startups. These are not plucky underdogs who shoulder-barged their way to near-trillion dollar valuations — they’re quite literally subsidiaries of the largest companies in the world, using the mythology of the startup ecosystem to create the mistaken belief that anyone can actually compete with big tech. AI startups are all entirely dependent on big tech, yet sell themselves as rugged individuals.
The fact that Amazon deliberately dobbed Anthropic in to the Commerce Department and neither Microsoft nor Google have shown any interest in defending it suggests that neither really cares if it lives or dies. This would be the exact situation that would prove that Anthropic (or OpenAI) had real leverage over their hyperscale benefactors. Instead, the largest companies in the world have left them to the wolves.
Anthropic believed it was too big to fail, or at least too big to be stopped. It likely believed it would see a flood of support as it did with its argument with the Department of Defense, but nobody seems particularly interested in defending it. Instead, everybody seems kind of confused and annoyed, and the largest companies in the world are making vague statements about how no one model can be “the best.”
Silicon Valley, this is your King — a company that grew through conning and scaring and lying to people at scale, overstating both the capabilities and possibilities of its models in the hopes that everybody would be too scared not to pay for them, only to find its business model collapse because you can’t wish your way to a fucking business model.
While OpenAI is no better, Anthropic is offensive in that it resembles everything that’s ruined the tech industry — a company with a product that costs billions of dollars that can only be sold by talking about what it might do in the future, a masterpiece of grift and hubris that I believe will stumble and crumble in the future.
The next generation of startups will not get built in a system more interested in Twitter clout and trend-chasing than making good software that solves real problems. Braindead, growth-drunk “accelerationists” conflate economic growth with human progress, and as long as they’re in power, the only ones who will build things of note will be the actual outcasts.
You can’t win as a startup anymore. There is no competing with or scaling without the Magnificent Seven, at least not under the current terms of Silicon Valley.
And there never will be again without aggressively flushing away the hubris and ignorance of the current generation of venture capitalists that have abandoned building the future in favor of praying at the feet of management consultants and grifters.
—
If you liked this piece, you should subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 10,000 to 18,000 words, including vast, detailed analyses of the biggest events and companies in the AI bubble.
2026-06-13 01:16:51
Friends, I believe we’re approaching the end of this era. Both OpenAI and Anthropic have filed the paperwork to go public, starting a race for exit liquidity for two companies that burn billions of dollars a year and have no path to profitability.
Both of these companies are dogs. No matter how much financial engineering or how many oafish suggestions about the government taking 50% of every AI firm they make, the underlying economics of AI labs simply do not make sense, which is likely why Clammy Sam Altman is so vague about IPO timing, per The Information:
OpenAI CEO Sam Altman told staff in a Slack message on Monday that he expects OpenAI to go public “within the next year” and that “many things could cause it to be sooner or later in that range, but filing now gives us optionality if we want to go sooner.” Another OpenAI leader also teased an upcoming new AI model that the company is preparing to release.
So, yes, OpenAI is expected to go public within the next year, or sooner, or later, at some point it’ll go public, but when it does, well, I dunno. I really don’t know, actually. I have it on good authority that the underlying financials of OpenAI look like the horrible dog from John Carpenter’s The Thing, and any dithering on Altman’s part is an attempt to delay the inevitable, by which I mean “OpenAI needs $865 billion in the next four years to meet its commitments, and the only way to keep raising money is via the public markets”:
However, he said, the magnitude of capital OpenAI needs for its compute and infrastructure buildout could cause it to accelerate IPO plans. (The Information on Tuesday reported on OpenAI’s discussions to lease a proposed Ohio data center campus that would require it to raise or get financing for hundreds of billions of dollars of Nvidia chips, in addition to making substantial lease payments.)
Altman isn’t alone. Anthropic President and Co-Founder Daniela Amodei said at a recent conference that “it’s a very capital-intensive business to train AI models,” adding that the public market is “very well-suited to that.”
As ever, Anthropic is saying one thing and doing another. Last week, Anthropic rankled investors in bonds associated with its $35 billion deal with Broadcom and Google by, to quote Semafor, “resisting sharing financial information” around its section of the bonds:
Some of the lenders being pitched to buy a slice of the $4.6 billion [editor’s note: it was $4.4 billion in the end] notes that don't have a backstop from Broadcom — meaning they are pure exposure to Anthropic — say they haven't received a detailed look at the AI company's numbers, causing some to pass on the deal, the people said. Such disclosures are standard in lending deals.
Hey, quick question: do you think Anthropic is neglecting to share its financials with lenders because they’re good or because they’re bad? As Semafor noted, the standard in basically any lending deal is that you have to share something more robust than the non-GAAPslop investor decks that Anthropic uses to con venture capitalists, but then again, this is private credit, baby! Anthropic can share as much or as little as it wants as long as there are willing marks.
To be explicit, Anthropic is the one on the hook for every payment of this $35 billion debt deal.
According to the Financial Times, asset managers Apollo and Blackstone are finalizing a $35 billion private credit deal to “finance Anthropic’s growth plans,” specifically using the money to buy Google’s TPUs from Broadcom, at which point Google will install them in a data center and rent them back to Anthropic:
The $35bn financing package is the initial step to fund about 1 gigawatt of Broadcom’s planned AI computing capacity, which is expected to expand to 20 gigawatts through 2028, according to a joint statement by Broadcom, Apollo and Blackstone on Tuesday.
A special purpose vehicle formed by Apollo’s Atlas SP Partners named “Compute SPV” would issue the debt, and Anthropic’s five-year lease payments for the chips underpinned the value of the transaction, said people briefed on the matter.
Apollo and Blackstone structured the loan across three tranches, with interest payments on the two senior segments backstopped by Broadcom. The chipmaker is making the so-called tensor processing units, or TPUs, with Google. Its agreement to provide support if Anthropic misses an interest payment helped vastly reduce the costs on the debt.
That’s right — everything sits off balance sheet in a Special Purpose Vehicle (SPV), legally shielding everybody involved…other than Broadcom, which (per Investing dot com) backstopped $30 billion of the debt.
To be specific, if Anthropic defaults on its payments, Broadcom has to step up and pay off bondholders with something called a residual value guarantee, which means that in the event of default, the TPUs would be sold off and Broadcom would cover whatever the difference was between what they cost and what they sold for.
This is some incredibly dodgy shit, but also suggests that Anthropic has abysmal credit, which makes me wonder how Ms. Amodei thinks raising capital in the public markets will go for a company that now very publicly holds $35 billion in off-balance sheet debt to go with its $2.5 billion revolving credit line.
In truth, the Amodei siblings have complete and utter contempt for the media, the markets and their investors. They know that quite literally anything they say will be taken with complete seriousness, to the point that a long winded and specious slog of a blog about “AI that builds itself” is quoted by the media as if recursive self-improvement were anything other than a pipedream.
Yet this still-theoretical concept is being used as a potential excuse for OpenAI to delay its IPO, per The Information:
Altman said that if the company’s technology advances at a rapid pace to the point where the AI itself is able to create new AI—known as recursive self-improvement—that would lessen the chance of a quicker public listing. “The faster the potential RSI takeoff looks like it could be, the more it could be advantageous to delay an IPO,” because the “technology and the world may change in surprising ways, and there might be good reasons to be a private company during that time,” Altman said.
RSI is the wet dream of an AI industry that’s incapable of working out a sustainable or profitable business model. Nobody — not Altman, not Amodei, not Pichai, not Dean, not Hassabis, not Zuckerberg and most certainly not Musk — has managed to work out a viable business model based on large language models, and despite having an effective monopoly over all tech talent and venture capital, the best idea these fucknuts have is “what if we made the LLM work out how to train itself?”
The fact that the media is taking this with any degree of seriousness is one of the loudest bubble indicators we’ve had in a while. If these companies had anything approaching AI that trained itself…they’d be using it. The AI would be training itself. We’d know, because they wouldn’t shut up about it, but instead we have to deal with yet another agonizing, ten-thousand-word-long blog from Dario Amodei (hey, that’s my job!). Ironically, this may be the first time that somebody has ever ripped off Mark Zuckerberg, who wrote his own blog in the middle of 2025 that claimed that Meta had “...seen glimpses of [its] AI systems improving themselves,” which was, of course, a blatant lie that was nevertheless repeated by the media ad verbatim.
RSI is also, I’d argue, a sign that they’re kind of giving up. Instead of talking about things that the thousands of overpaid academics farting around Anthropic or OpenAI are doing, both companies appear to be leaning on the idea that their models are so special that the people themselves don’t matter. RSI is as theoretical as AGI (artificial general intelligence, or a conscious AI), but feels far more tangible because, at least in theory, it’s just a model that’s doing model stuff without a human being.
If I had to guess, the reason that both OpenAI and Anthropic’s representative coding televangelists are talking about creating “loops” where LLMs prompt themselves is to try and claim that they’re on the verge of RSI:
I expect that “loops” will become the next thing that journalists pick up on and start oinking about. To be clear, “loops” already exist, in that you can make an LLM decide to keep taking actions whether or not a user prompts it for as long as you’d like. Whether the output works at the end isn’t Peter or Boris’ problem, as both of them are allowed to burn anywhere from $130,000 to $1.3 million a month in tokens.
Loops are, of course, literally having a hallucination-prone LLM prompt itself or another LLM, with all the chaos and mistakes that you’d expect to follow. Neither Cherny nor Steinberger give a fuck about how much any of this costs as long as it allows their representative CEOs to keep feeding them endless tokens, even if in doing so they inspire a brief and painful bubble of wasteful token spend in the pursuit of “AI that builds itself.”
There’s a very real possibility that the RSI bubble is the last phase of the larger AI bubble. Recursive Superintelligence raised $500 million a month ago without a product or, well, anything other than a vague theory that (to quote VentureBurn) “human intervention is the bottleneck for AI progress”:
“We are building a system that doesn’t just process information; it processes its own logic,” said one source close to the founders. “The goal is an AI stack that designs its own next-generation architecture. If successful, the leap from one version of the model to the next won’t take eighteen months; it could take eighteen hours.”
That’s a load-bearing “if,” buddy. That “if” refers to the idea that they’ll magically create the literal future of computer science — a self-training AI model that, in theory, could sit around and innovate all on its own, which also begs the question as to what all the researchers would do when that happens.
Nevertheless, I expect RSI to become the next — and hopefully the last — hot topic in AI as everybody gives up on coming up with ideas other than “what if the AI came up with the ideas for us.”
The RSI bubble neatly fits into an idea I’ve been working on for a while — that the AI bubble is, in fact, multiple bubbles wrapped into one, led by the largest one of all — The Rot-Com Bubble, my theory that everything we see today is the result of Silicon Valley running out of hypergrowth ideas.
The frenzied, reality-defying hype around Anthropic, OpenAI and Large Language Models is a direct symptom of a tech industry with nowhere else to go. There are no other industries that have any sign of becoming the next Google Search or Facebook or Smartphone, which is why everybody — the media, the markets, and every hyperscaler — is conspiring to try and keep the bubble inflated through accepting effectively any viable narrative and blessing even the most vulgar of circular financing arrangements. If anybody for even a second breaks the kayfabe that AI is the biggest, most hugest, most important bubble of all time, everybody has to accept that none of this makes sense…
…and that there’s nothing else on the other side.
The many bubbles that make up the larger AI bubble all represent different aspects of the same desperation. Microsoft, Google, Amazon and Meta are buying all those GPUs and shoving AI in every crevice of their experience because they know that their core businesses will eventually slow down, with nothing else to replace them. Oracle is spending $340 billion or more on capex entirely for OpenAI because its core business lines are plateauing or collapsing. SoftBank is mortgaging its entire future on OpenAI because it desperately needs another Alibaba or ARM to keep up with its ruinous debt. Broadcom needs to backstop $30 billion in bonds for Anthropic, an unprofitable and unsustainable venture capital welfare recipient, because it knows that its other business units can’t keep up with the Rot Economy’s demands for eternal growth.
AI feels, on some level, like the final stage of the modern era of technology. It’s flattened effectively every startup and tech company into some sort of aberration of Large Language Models, turned every semiconductor firm into an AI firm, made every venture capitalist an AI investor, made every tech journalist an AI journalist, and crowded out effectively every other subject in favor of a larger argument about whether one specific technology is the future.
These many bubbles always come back to a singular point: that the people building modern technology have effectively abandoned innovation, twisted by the Rot Economy’s growth-at-all-costs mindset. The result is that the majority of venture capital goes to latter-stage companies and established founders, turning venture capital into a cult of personality more interested in Twitter clout and view counts than anything to do with the future.
Venture capital is now dominated by people that don’t build anything but worship at the altar of what they imagine a “builder” looks like. As a result, these people flock to founders that confirm their biases — those who are usually men, usually white, usually software engineers from big schools, usually building things that look and sound like everybody else. Seed stage investment is dead, and all that remains is a follower culture.
The AI bubble is sold as the future, but actually resembles the death of Silicon Valley. Only a tech industry dominated by symbolic wealth and value creation would ever abide a trillion dollars of waste for a still-theoretical outcome, and only an intellectually-rotten Valley would be so easily-grifted by people like Dario Amodei and Sam Altman.
The myth of the Valley was always that investors were smart and took risks. In reality, investors follow other investors based on whatever people are excited about in a group chat or on Twitter or TBPN or any other hype-slop they can get their hands on. Modern venture capitalists hate thinking and introspection, invest in basically the same things at the same time, and haven’t done a real job since the early 2000s.
The result is that Silicon Valley stopped building the future, and started investing in its own destruction.
This series will cover the many parts that make up the larger Silicon Valley bubble, and the many collapses that will lead to the end.
This will, as with my What If? Series, be a two-parter, with the option to extend to three.
And man, am I gonna have some fun with it.
Coming Up On This Week’s Where’s Your Ed At Premium