2025-06-10 21:08:50
这篇文章很可能是我过去1年所有公开分享内容里最重要的一篇。
从动笔到呈现在你面前前后断断续续写了1年,它是一份AI使用心得,是一份AI行动清单,是未来分享内容的新起点,期待交流。
AI 真正开始改变和侵入我的生活,和不少人类似,开始于 2022 年底的 ChatGPT 尝鲜。
2022 年 11 月 30 号,ChatGPT 上线 后迅速成为现象级产品,据统计发布 5 天后用户突破 100 万。
产品发布第 6 天,我的 homie 在成为 ChatGPT 用户光荣一员后旋即也带我上车,回看那天的聊天记录,彼时我还留下了现在看来仍很有趣的暴论:我觉得最可能被这类 AI 干死的是搜索工具。
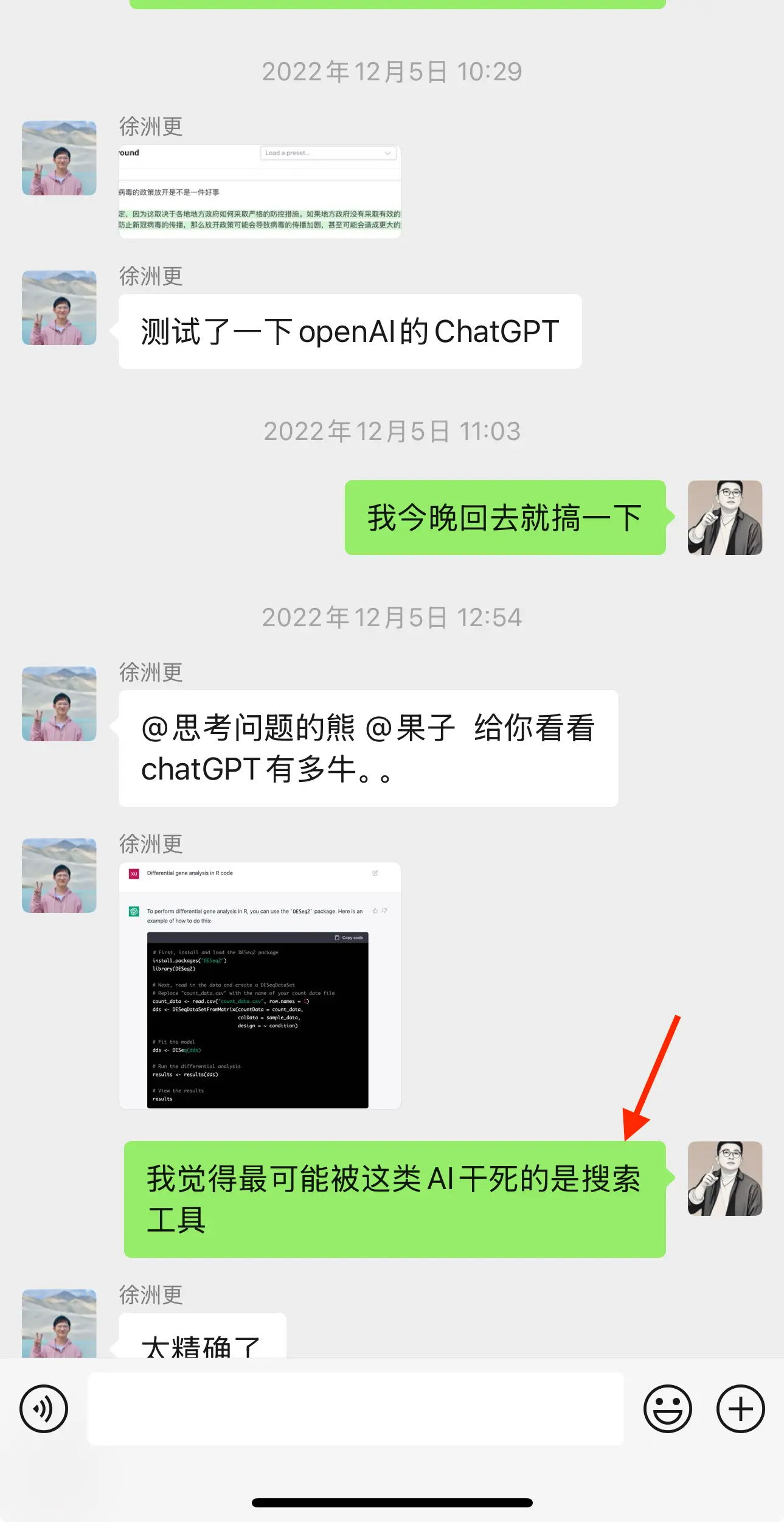
那天开始,我不知道自己将见证什么,但很快发现以前不敢想的事猛的变成现实。
好在震撼过后 AI 很快漏出了能力缺陷,最简单的数学题算不明白,让它介绍“熊言熊语”就开始“胡言乱语”。我们彼此交流 AI 能做什么,不能做什么,转发一些 AI 看起来弱智可笑的案例。
在应用之外,OpenAI 也为开发者提供 API。
时间来到 23 年 3 月 7 日,那天我的邮箱里出现了 OpenAI API 升级的通知,大概意思是:gpt-3-5-turbo 正式开放,价格比 gpt-3-5 降低 10 倍。
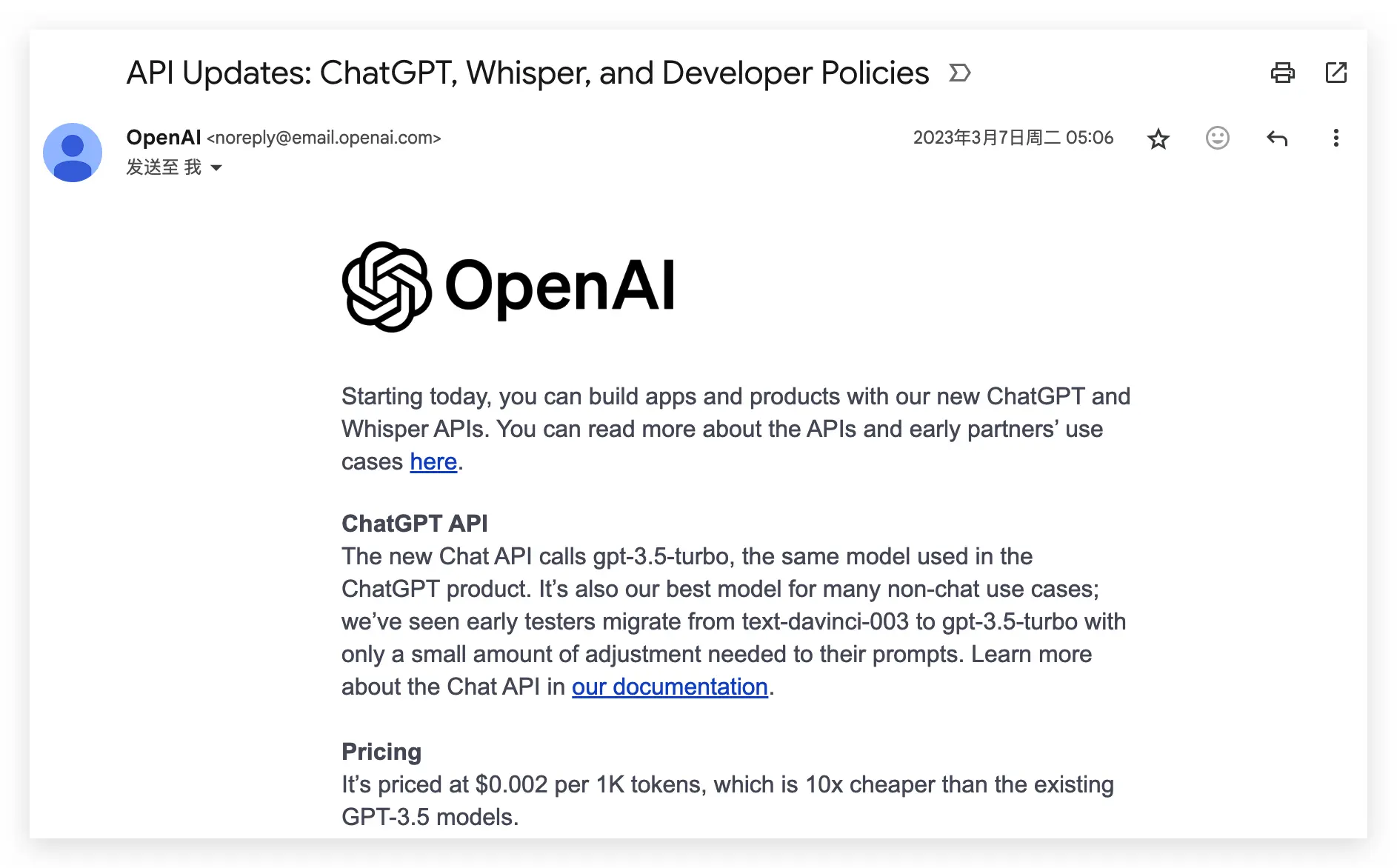
我记不起当时的心情,但清晰能回忆起自己想用它做点什么的冲动。也是从那时起,一个叫做 PaperFlow 的构思记在了 DailyLog 笔记中,我写到:
我一直希望自己所有和 Paper 相关的工作内容,都可以向水一样流动 (flow) 汇聚,现在看这个能量来源应该是大语言模型的 API 能力。
3 个月后的 23 年 6 月 9 日,只有一个功能的 PaperFlow Alpha 版本,一个手撸的不到 1000 行后端代码和不到 1000 行前端代码的极简 Web 网站上线。
我也没想到它会变成如今刚过完 2 周岁生日的 InsightPaper,满脑子就是看到页面上生成的 AI 生成结果后感觉信息流动起来的兴奋。
接着,就是 AI 能力和我自身能力齐头并进的一段时间。
2023 年和 2024 年初,我还密集写过很多专业相关的「雄文」,哦不,是「熊文」。如果你恰好看过那些动辄上万字参考文献几十篇的邮件通讯。
当时我的写作流程大概是:
比如:
随着 homie 加入和助力,更名为 InsightPaper 后的 PaperFlow 功能持续增加,我越来越沉浸在和 AI 高度耦合的协作中。也越来越怀疑在 AI 能力上限快速提高的前提下,我做的工作和写出来的东西,除了成为硅基智能未来某次训练的一点点语料之外,还有什么意义。
那段时间我重度使用所有能接触到的 AI,ChatGPT,Perplexity,Poe,Scite……太多知名或者不知名的工具,我尝试探索每一个工具的能力边界,进而得出自己的优势和存在的意义。
不知道该开心还是难过,这段 AI 刺激下的恐慌和不甘并没有持续太久,当我意识到自己的能力进化和 AI 的能力进化完全不是平行线,我们瞬间就产生了交集,然后我看着它的背影,它扬长而去。
也是在那段时间,我接受了把 AI 作为日常所有学习和工作环节的工具。
推理模型终于让我放下了最后的执念
把 AI 当做工具的阶段持续到 2024 年 9 月,我第一次使用了当时 OpenAI 的推理模型 O1-preview。
此前,我从没有赋予 AI 平等对待的人格化特质,接受和输出的也是诸如 AI 只是基于概率来预测下一个 token、AI 能力是大多数人类平均水平这类观念。
但现在,当你面前实实在在出现一个有“思考”能力的模型,当它聊出你自己无法理解的内容和哲理。第一次,我感觉这些年积累和训练出来的“思考”能力,也面临被 AI 代替。
意识到这一点,我终于放下了最后的执念,放下执念也就自然放下了某种偏见和立场。
随后 AI 领域发生的事情,大家应该都比较清楚了。
2025 年春节,DeepSeek R1 现象级火爆,紧接着字节豆包、腾讯元宝,大厂大肆投入营销,随后 MCP、Agent 成为又一个主流趋势,Manus 一码难求。
似乎,当一种趋势扑面而来,你不去应对和自我升级也没关系,这种趋势会主动找到你。但如果你越主动,就会越早适应今后某一天的生活。
以上,就是我过去三年和 AI 纠缠的心路历程,此刻你可能也正处于某个类似的阶段,我写出来是想说告诉你没关系,都差不多。
2024 年中的一次分享,我曾和大家一起讨论过使用乔哈里视窗,通过评估 AI 能力和自身能力之间的关系,找准 AI 的定位和可以做的事情。
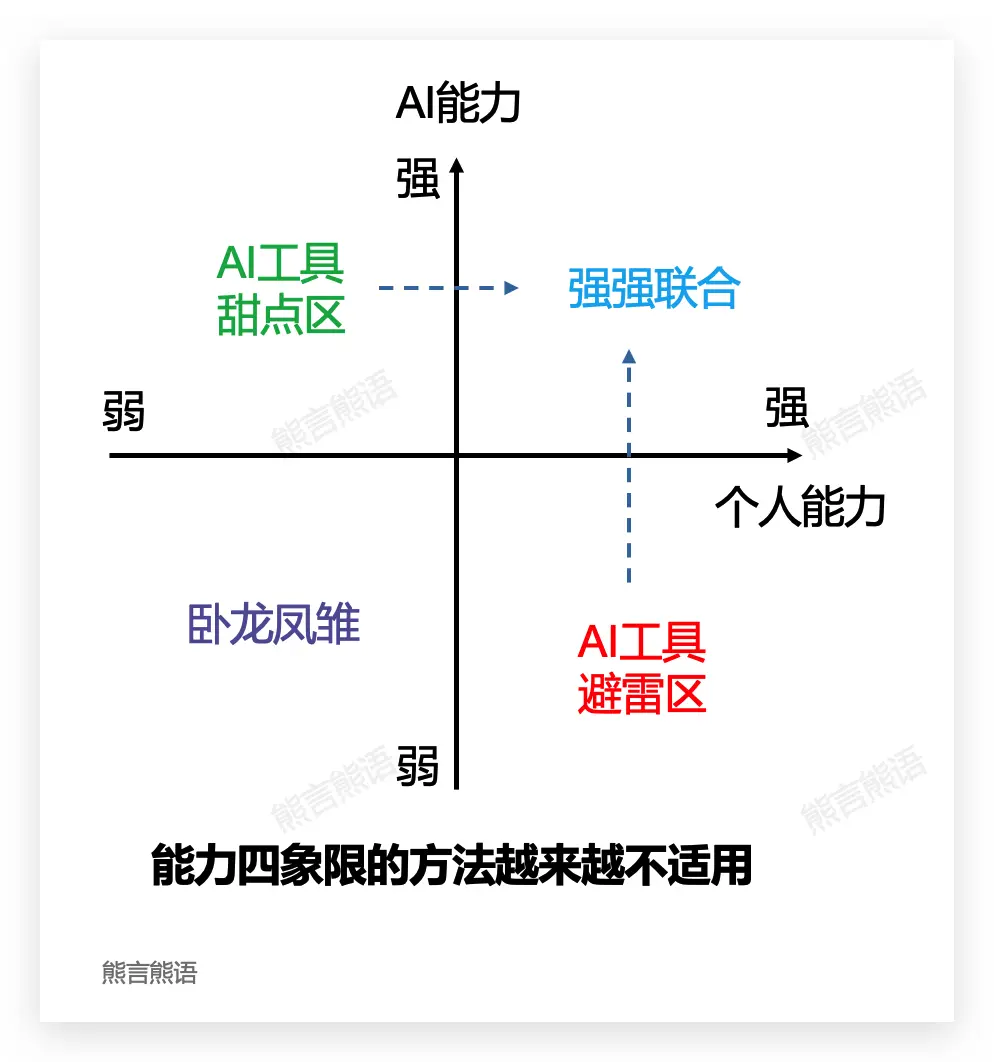
当时 AI 仍被我当做一个工具看待,科室到了 2025 年的今天,能力四象限分类方法越来越不适用。
最强大的 OpenAI O3 或者 Gemini Pro 2.5 以及未来即将推出的 DeepSeek R2 这些模型,AI 工具避雷区正在极限缩小,模型能力必然在绝大多数维度上超过每一个个体。
在科研领域,语法润色和知识性问答,已经不再是顶级 AI 能力的核心优势。相反,信息整合、思维发散、复杂理论理解这些高阶能力才是模型真正赋予你的武器。
**AI 不再是一个工具,而是你极好的合作伙伴。**说到这里,不知道你是否和各种各样的人合作过。
生物信息专业出身,在读研和博士的那些年,我天然需要和很多人合作,逐渐我发现:和别人合作之前,最重要的是要先明确自己的段位,拥有一个正确的姿态。
接下来的这个认知,可能是你今后在科研领域有效使用 AI 的前提。
面对顶级能力的 AI,你应该首先学会定义自己的能力边界,判断自己选择低中高哪一种姿态,针对不同的判断使用不同策略。
不过,科研是一个极复杂的体系,所谓的低中高,并非是给自己贴的标签,而是一种“人 + 任务”的组合判断。
没有人在所有维度上都是“高水平”,一个在自己的领域“高水平”的 PI,面对一个全新的编程语言时就是“低水平”的入门者;一个精通湿实验的博后,在处理高通量测序数据时可能一直在“中水平”中挣扎。
以下,简单写一点三个不同姿态的 AI 使用心得,供你参考。更详细的内容希望有机会可以深入聊聊。
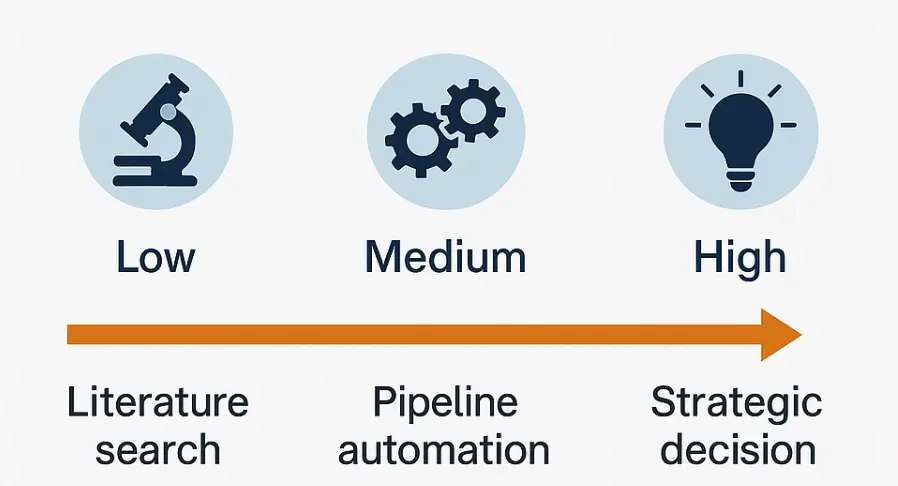
接下来聊聊评价一个 AI 科研类工具的策略。

现阶段,大家对于 AI 科研类工具的诉求核心其实是对于上下文准确性的诉求。换言之,AI 搜索是先搜索后处理。
在这个共识下,如下图的金字塔评价策略,AI 科研类工具的专业数据库整合能力、最新论文获取能力,先天决定了一个 AI 科研类工具的下限。这是评价一个 AI 科研工具的基础,即可用还是不可用。
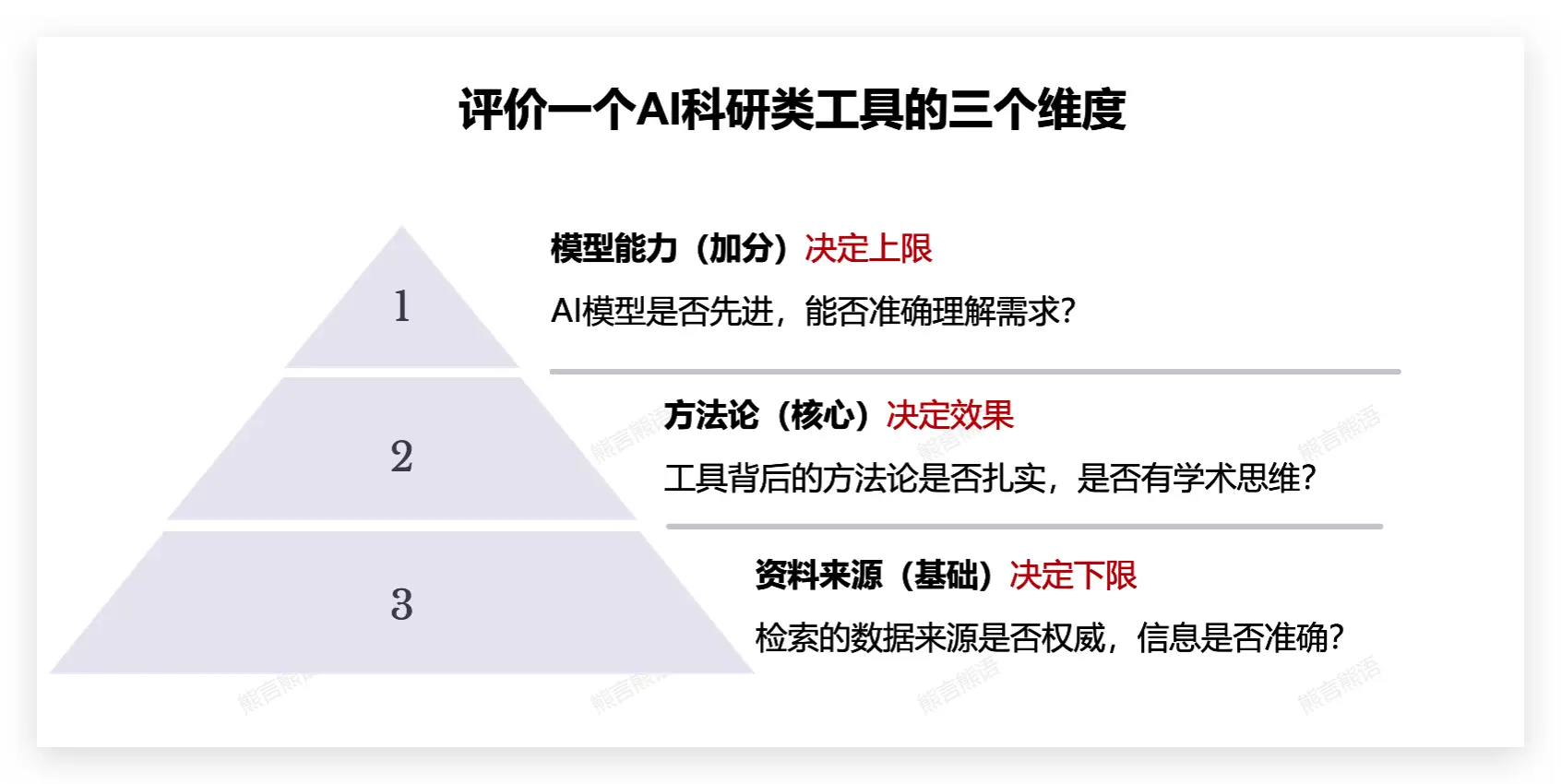
金字塔评价策略的第二个维度是方法论。
AI 科研类工具的本质是开发者团队对科研本身的理解,是科研思维的集中体现,因此也是你评价策略的核心。
回想一下,当你同时使用若干个工具,自己总会因为一些设计和巧思而对某个工具产生偏好,这就是工具背后的方法论刚好契合了你自己的偏好和品味。它决定了工具的表现,即好用还是不好用。
如果一个科研类 AI 工具能够有扎实的最新的数据来源,又有刚好符合你品味的设计思路,已是一个难得的好工具。而回到 AI 本身,工具依赖的大语言模型能力加上工具对模型的把控能力,决定了这类工具的上限。同样的上下文和输入指令,顶级智能模型就是更可能带给你 aha moment。
以上,是我日常评价一个 AI 科研工具的三个核心维度,使用这个金字塔策略,未来再评价一个工具时你想必也会从容些。
焦虑的反面是具体,我没办法治疗你的 AI 焦虑,但可以尝试提供 10 个这 3 年 AI 实践后我具体的行动清单建议。
写到这里我需要坦白,其实这四个章节来源于不同阶段 InsightPaper 天使用户提过的四个问题,而我也前前后后写了一年。这四个问题分别是:
写完每个问题的回复草稿,我把这些问题抽象后,发现它们原来可以彼此联系,刚好组成一篇「我的 AI 实践心得」,在一个值得纪念的节点分享给你。
嗯,即便到了今天,我在第一节里提到多年养成的写作习惯,也依旧能发挥它的价值,这和 AI 本身没有关系。
InsightPaper 在 2023 年 6 月 9 日默默上线,一开始是为了满足我的好奇心和科研学习需求。随着后期 Homie 洲更加入,他提供了很多技术支持和精神鼓励。如今,一直在迭代优化,成为覆盖不少科研学习场景的 AI 工具。
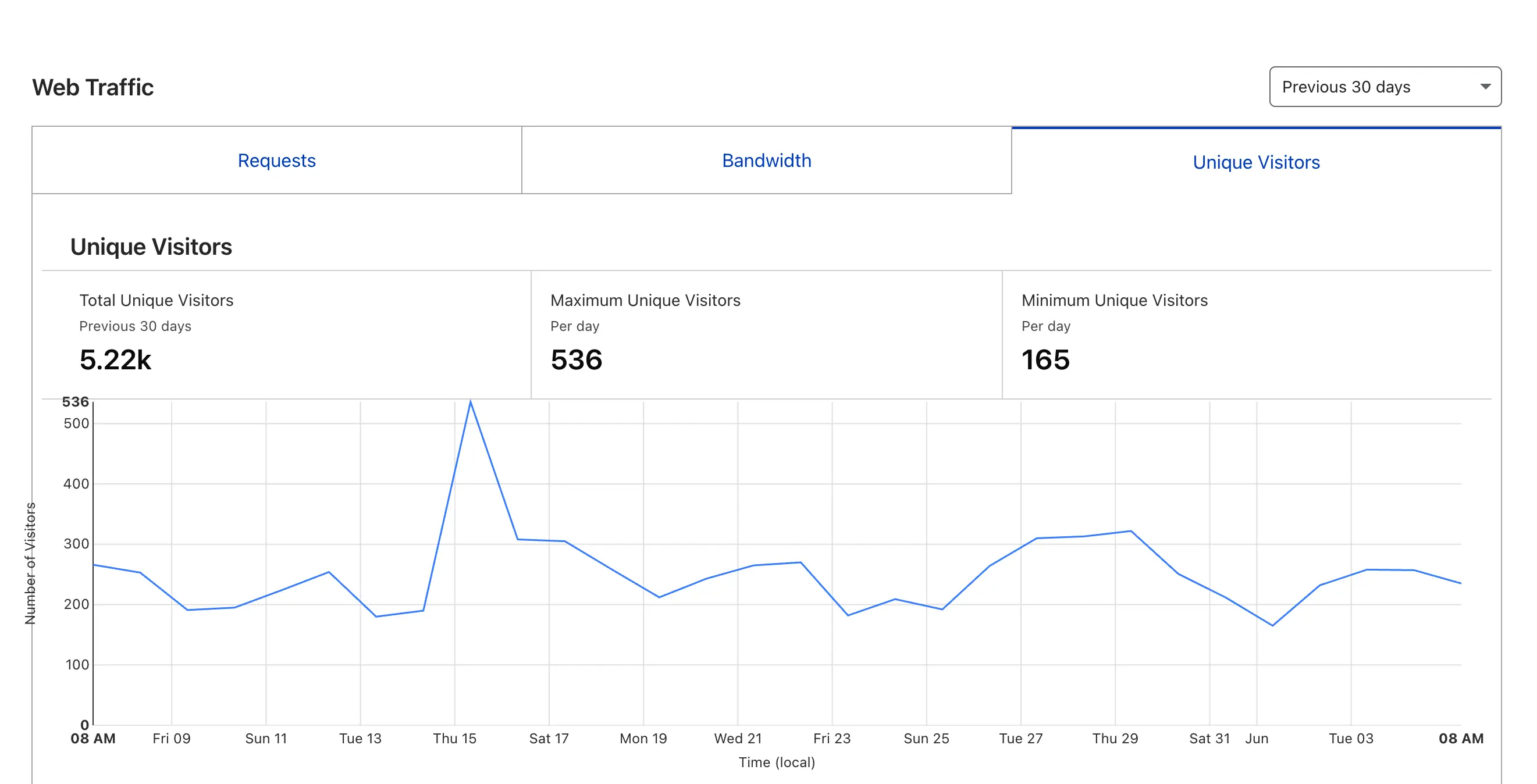
在没有什么公开宣传的情况下,也慢慢有了 1000+ 注册用户,处理了 20000+ 对话消息,并且度过了 2 岁生日。主域名 insightpaper.work 的访问量过去 30 天 unique visitors 也超过了 5000 人,高阶工具版本 得到了非常多朋友的喜欢~
感谢洲更,每一位参与过 InsightPaper 测试、使用、反馈的用户,感谢豪气支持服务器 API 及各种运维成本的朋友。
写完这篇实践分享,我思考后面还能继续为大家做些什么。
看过草稿的朋友说,感觉遵循“从焦虑到具体”的主题非常好,不如建一个 AI 科研为主的实践讨论群,让希望具体行动的伙伴可以有一个互相交流的渠道。
我请在这个提议下,更具体一些不如设定一个目标:用 AI 解决 100 具体的科研问题。
如果你希望加入,可以直接扫下面的二维码免费入群,提示超过人数限制的话可以添加微信 (kaopu_bear) 拉你进群,一起用具体来对抗焦虑,一起实践~

2025-02-27 22:42:09
Hello,熊言熊语的老友,好久没通过博客和你见面了。此刻,家里重新联网,照例需要和你汇报一下我最近一段时间的思考和工作。
正如你看到的标题:这次,我终于可以尝试把自己最好的给你。
关于什么是我最好的东西,这件事情要从很早说起。
2019 年,我曾在少数派发表过一篇 文献管理工具Zotero上手指南。那时我还在读博,有新的师弟师妹到来时,他们遇到看文献和管理文献的需求,总是会找我聊上几句。我感觉到这是一个高频需求,便想着整理出一篇文章分享给大家,或许能帮到有类似问题的朋友。
如今回头想想,那时感觉是对的,但没想到这个需求竟如此高。

看着文章从一万阅读量增长到十万,再到如今的三十四万,我发现了两件事:
自那以后,过去多年,无论是写文章、录播客还是更新这份邮件通讯,无论是分享所思所想还是专业所学,我做的每一件事的本质,都是将自己日常输入的大量信息,通过逐渐形成的一套逻辑方法进行追踪、过滤、加工和整理,变成更清晰的内容输出。
我因此受益,分享后又恰好能帮助一些与我同频的人。这种开心和满足,也是我持续下去的重要动力。
在这个过程中,我逐渐意识到一个似乎无解的问题:我分享的思考和内容越多,似乎起到的作用反而越小。因为读者数量日益庞大,大家的真实问题和兴趣点越来越个性化。
这就像是:我加倍努力磨练自己的渔具和钓法,与你分享我钓到的鱼,但这些鱼可能并不是你真正需要的品种。
某种程度上的不匹配,让我逐渐怀疑这类分享的价值。或许我更应该分享这套钓法和渔具,那才是我最好的东西。 但该如何做到呢?
2022 年 12 月初,OpenAI 发布了 ChatGPT。
作为常年在互联网上冲浪的人,我第一时间注册了账号体验,起初觉得很好玩。转眼到了 2023 年 3 月,OpenAI 正式发布 GPT-3.5 的开发者 API。结合一直想做点什么的念头,我尝试将自己有限的编程能力与它结合起来。
如果能做出一个自己用的产品,那将是一件挺酷的事情。
于是,在 2023 年 6 月,我写下了第一条 InsightPaper 产品更新日志。
后面的细节以后有机会再细讲。
总之,随着之后一年半时间大语言模型能力的快速发展,这个工具从第一天上线,经过了 600 多天的迭代,
也让我真正有机会将这些年自己形成的信息追踪、过滤、加工和整理逻辑,以及不同维度的科研方法提炼并产品化,实现了从鱼到渔的转变。就有了今天的 InsightPaper,一个利用业余时间缓慢但持续迭代优化的小东西。
我自己手撸的一个 InsightPaper主页,也欢迎你访问。

过去半年多,几乎每个晚上和周末,我都在专心做一件事:希望能尽早将它交付给你体验。
正如前面提到的,随着读者基数和范围的扩大,我能学习和了解的信息与知识显得越来越有限。然而,如果我能将这套科研学习的方法和思路转化为可复用的工具,这或许就是我能给你的最好东西。
InsightPaper 是一款深度整合了大语言模型能力的研究进展追踪、论文学习和科研辅助工具。其核心目标是将“追踪、过滤、加工和整理”的信息处理四步法融入科学研究的每个步骤。
如果你打开 InsightPaper 的 基础版网站(最早开发的版本),其核心功能包括论文智能检索总结、预印本智能检索总结和相似论文推荐三大模块。
例如,在论文智能检索总结功能中,你可以根据关键词、杂志、作者和论文类型进行检索,检索结果将由大模型进行智能总结。
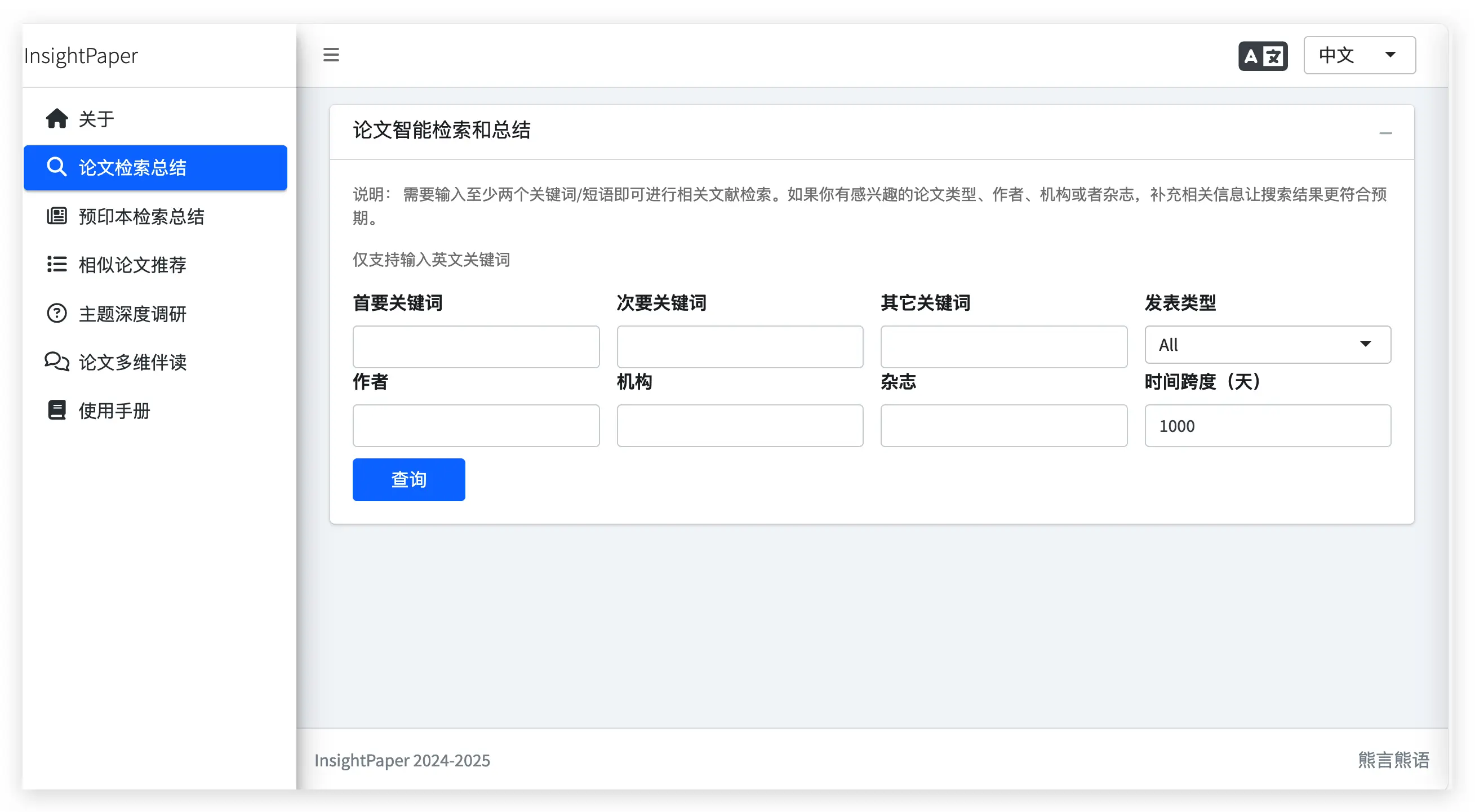
具体使用效果和介绍,你可以访问它的 功能介绍短视频 了解,或直接扫码观看视频。

至于为什么要这样设计,以及为何要将预印本智能检索总结和相似论文推荐功能独立出来,如果你听过我在中科院信息素养论坛的讲座或早先的 相关播客,就会知道,我曾分享过如何像追剧一样追论文,其中的思考方式和方法在这三个功能中得到了初步体现。
过去两年,我几乎订阅了市面上所有相关类型的付费产品,包括 ChatGPT、Claude、Perplexity、Scite、Consensus 等。
然而,深度使用后,我发现这些工具都无法顺手地满足我的实际需求。
于是我想,为什么不将自己科研过程中的思路和方法按场景划分,开发成自己的一些列工具呢?这个实现过程多少有些美妙。
如果你现在打开 InsightPaper 的 高阶版网站(目前持续迭代的最新版本),会看到已上线 7 个高阶功能。
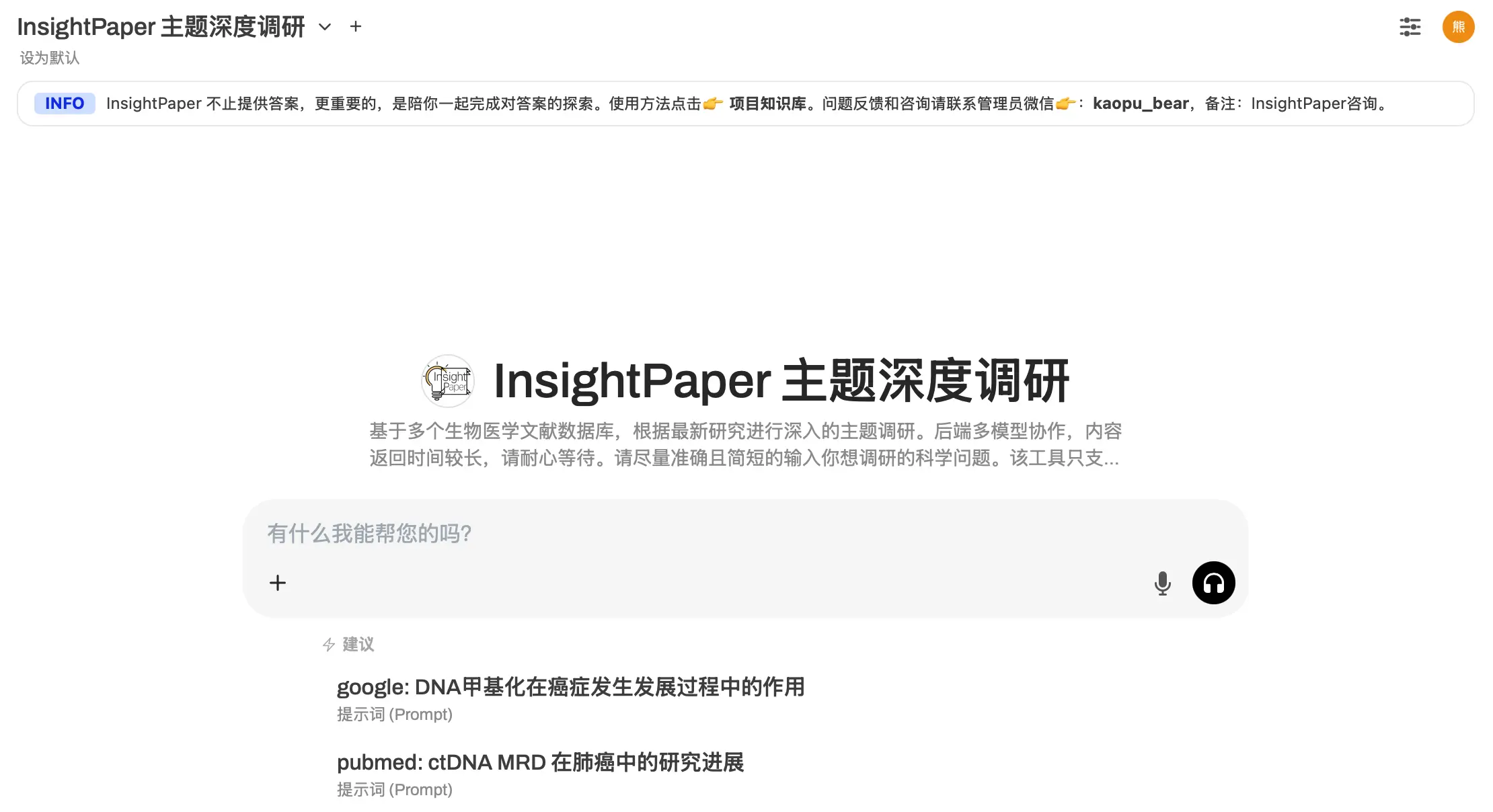
这 7 个高阶功能分别是:

以上每个工具都由多个模型协作完成复杂工作流,其中最复杂的运行一次需调用 25 次不同基座模型和 5-10 次论文检索,你可以将它们每一个都视为独立功能的小软件。
更重要的是,每个工具背后都是我日常科研学习中提炼的一个真实场景和对应方法。
例如,我日常高频使用的 主题深度调研 工具也录制了一个 功能使用短视频 供你参考。你可以点击链接或者扫码观看。

目前上线的 InsightPaper 基础版 和 高阶版工具,只是我梳理出的部分高频场景。
后续计划逐步开发更多类似场景和工具,同时已上线的工具也在不断优化和更新,自己的狗粮自己吃。
正如开头所说,于我而言,利己与利他相辅相成,因为总有人和我有相同的问题和需求。我希望这个工具能成为你我之间新的交流契机。
在规划 InsightPaper 的定位时,我深知 AI 当前的问题和缺陷。
因此,基于 AI 的 InsightPaper 不应仅提供尽可能准确的答案,更重要的是像一个伙伴一样,陪你一起探索答案。
当你看到这封通讯时,为了让更多朋友能直接使用,我在力所能及的范围内为不同的高阶工具都提供了每天更新的使用额度,以满足轻度使用需求, 点击这里直达。
作为业余时间开发的 side project,我深知它还有许多不足,因此欢迎你多多体验并提供反馈。
随着 InsightPaper 第一阶段版本的闭门开发结束并与你见面,接下来,我将继续通过博客分享行业内容和科研进展。
我想,借助 InsightPaper 的能力,自己可以用更高的效率创作更深入的内容。
为了感谢深入支持过自己的老朋友,如果你曾作为「熊言熊语」邮件通讯的年度付费会员并且未领取过 InsightPaper 内测期的老友权益,欢迎你通过微信(kaopu_bear)联系我,告知你的订阅邮箱,我将为你开通一个月的高阶工具会员权限,足以进行更全面深入的使用。
以及,只要你阅读到了这里,也许你也对这个工具很感兴趣,只需要通过微信(kaopu_bear)联系我,并备注「邮件通讯」,我也将可以为你开通一周的高阶工具会员权限,希望你可以喜欢。
以上,下次再见~
2024-08-03 12:13:32
本文是熊言熊语邮件通讯的会员内容,限时同步首发于熊言熊语微信公众号。文章较长,引用较多。
Guardant health Shield 近日官宣获批,从我2021年入行关注至今终于等来了这一天。作为熊言熊语邮件通讯产品系列的早就定下的选题之一,趁热打铁,把零散记录了很久的draft详细整理成文与你分享。
在本次通讯中,你将会:
如果你对这篇文章感兴趣,欢迎通过邮箱订阅我的 「熊言熊语」会员通讯,我将第一时间与你分享肿瘤生物医药领域最新行业研究进展和我的所思所学所想,点此链接 即可进行免费订阅。

7 月 29 日,Guardant Health 在官网宣布 FDA 批准 Shield 作为结直肠癌 (CRC) 的筛查方案。
Shield 因此成为 FDA 批准的第一款用于 CRC 筛查、满足美国医保要求的血液检测产品。其使用范围是 45 岁及以上具有平均患病风险的成年人。

Shield 的获批并不令人意外,似乎这一切都在按照 Guardant Health(下文简称 GH)计划的路线稳步推进。
在 2024 JP Morgan 上 GH 给出了如下清晰的时间线。

今年 5 月,FDA 分子和临床遗传学专家小组经过一番「热烈」讨论,对 Shield 的安全性、有效性和风险收益比都给出了整体积极的评价。这次讨论通过也已经预示着 Shield「有望」成为第一个获 FDA 批准的肠癌血液筛查产品。

如果再往前追溯,是什么促成了这次专家小组的通过呢?
一是基于 Guardant Shield 之前已经获得的上市前批准 (PMA) 申请,二是评估平均风险人群使用 Shield 检测性能关键结果的 ECLIPSE 研究于今年 3 月发表在《新英格兰医学杂志》(NEJM) 上。

ECLIPSE 是一项非随机、前瞻性、多中心研究,纳入了年龄在 45 岁至 84 岁之间计划接受肠镜筛查的患者。
如下图所示,虽然研究招募的患者人数达到 2 万多例,但其中 1.2 万例并没有纳入实际的临床验证队列。研究团队通过下采样方法随机抽样了 1 万人,删删减减之后有 7000 多人进入了最后的临床评估阶段。

ECLIPSE 的主要终点是相对于肠镜检查 CRC 的敏感性和对晚期肿瘤(结直肠癌或晚期癌前病变)的特异性,次要终点是检测晚期癌前病变的敏感性。在 clinicaltrials 注册的临床试验中,次要终点还包括 CRC 检测的阳性预测值 (PPV) 和阴性预测值 (NPV)。

对于 Shield 的性能,GH 在发布的 PROVIDER BROCHURE 中已经给出了一个非常清晰的总结。
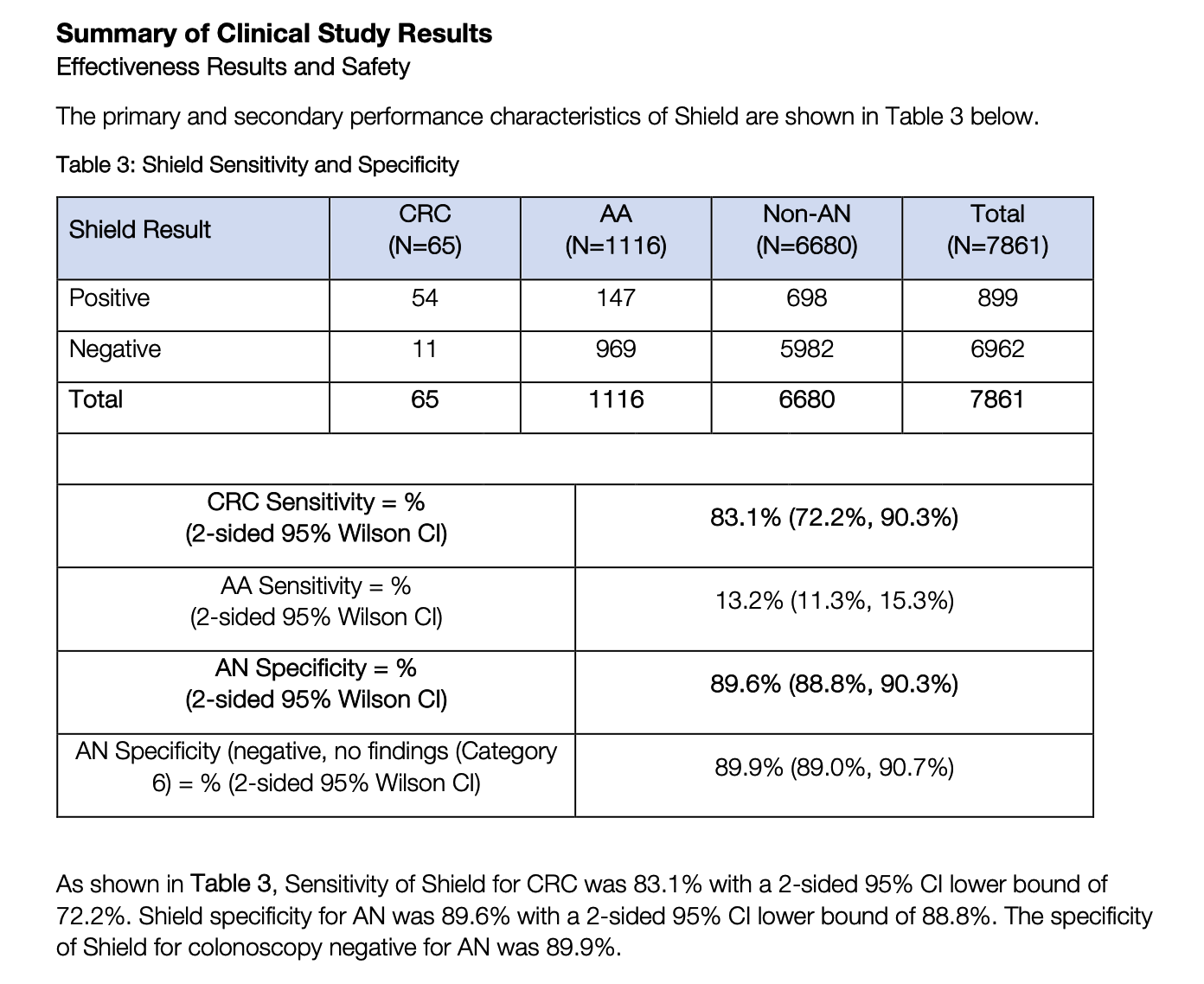
在 NEJM 的论文中,更详细的主要结果总结如下:
如果以上这些数据都还算说得过去,但晚期癌前病变 (AA) 的敏感性仅为 13.2%。
emmm,因为这不是计划中的研究终点,只能算是软肋谈不上硬伤。 关于 AA 的问题,我们还会在后文有一个详细的展开。
在同期 NEJM 上,Exact Sciences Cologuard 和 GH 背靠背发表了自家产品最新一代产品的实验结果。

我们得以给出一个相对清晰(但并不严谨)的对比。
| cfDNA | stool | |
|---|---|---|
| CRC 敏感性 | 83.1% | 93.9% |
| I 期 CRC 敏感性 | 65% | 86% |
| 晚期癌前病变敏感性 | 13.3% | 43.4%(HGD 74.6%) |
| 晚期肿瘤特异性 | 89.6% | 90.6% |
| NPV | 99.92% | 99.97% |
| PPV | 3.16% | 3.4% |
虽然各项指标相比对方都不占优,但是 GH 说:不是比不过,而是你不会比,不考虑依从性的敏感性,在真实世界里就是耍流氓。
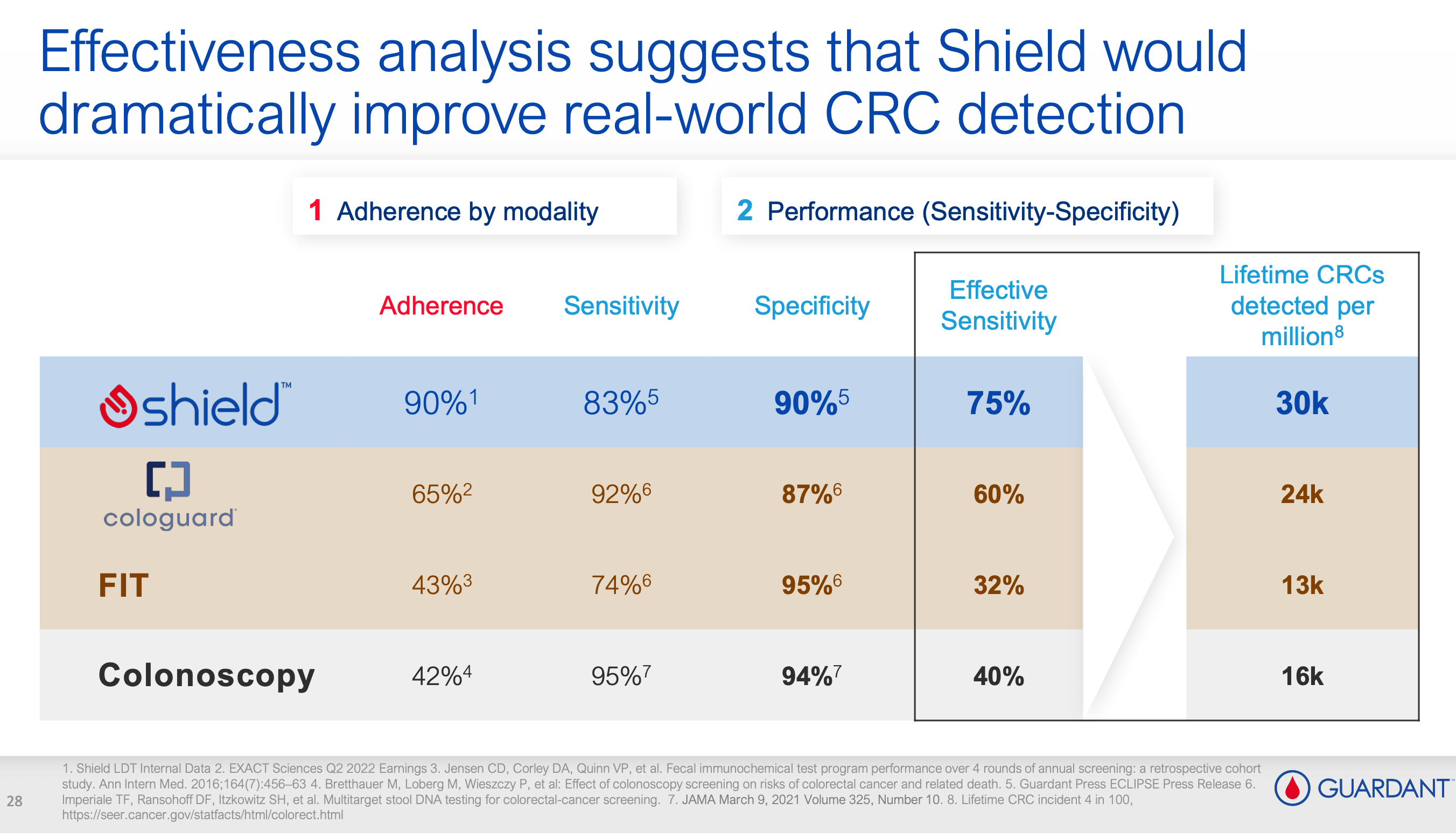
在 2023 年的 JP Morgan 大会上,GH 提出了一个并不算新的新概念——" 有效敏感性 "(Effective Sensitivity)。Shield 的依从性为 90%,敏感性为 83%,两者相乘得出有效敏感性为 75%;而 Cologuard 的依从性为 65%,敏感性虽然略高(87%),但两者相乘后的有效敏感性仅为 60%。
论秀,还是 GH 秀,散了吧。
然而,仔细思考后会发现,这两种检测方法之间的差异其实并不令人意外。无论是微小残留病灶(MRD)还是肿瘤筛查,对于血液检测,我们有一个基本共识:只有脱落的 DNA 进入血液循环系统才有可能被检测到,而且通常来说,越接近病变部位的样本越敏感。这也同样可以解释为什么在泌尿系统相关肿瘤的检测中,尿液样本的早期筛查性能要比血液检测好得多。
Shield 自身具有的便利性和高依从性,在满足同样筛查条件下可以提高筛查率,这一点没有问题。
但我们也需要清楚地认识到,Shield 目前并不能算是真正意义上预防结直肠癌(CRC)的「筛查」工具(其对进展期腺瘤 AA 的检出率仅为 13%),它更像是一种非侵入性的 " 检查 " 方法。即便如此,它仍可能会漏诊接近一半的 1 期患者。
虽然面对投资人描绘着美好的概念,但 GH 比任何人都清楚自己产品的局限性。
这一点从 GH Shield 产品手册中随处可见的防御性极强的限制性说明就能看出。
一起来感受一下。

Precaution:基于临床研究数据,Shield 对 I 期结直肠癌的检测灵敏度有限(55%-65%),并且无法检测到 87% 的癌前病变。每 10 名 Shield 结果为阴性的患者中,可能有 1 名患有癌前病变,而这种病变本可以通过结肠镜筛查检测到。Shield 对 II、III 和 IV 期结直肠癌的检测显示出较高的检测率。

限制性因素众多,我们列举几个主要的:
有趣的是,这些 label 上的预防性声明甚至成为了今天投资者电话说明会的提问重点,多个问题都围绕这些预防性声明可能产生的潜在影响展开。
另外值得注意的是,Shield 检测尚未被美国预防服务工作组(USPSTF)或美国癌症协会(ACS)的指南收录,许多非公立保险公司可能要求产品被纳入指南才会提供覆盖,这意味着 Shield 还有一段路要走。
此外,在 NCT04136002 实验记录中,项目入组人数从最初预估的 2 万人,在 2023 年 4 月修改为 4 万人,到今年 4 月又修改为实际入组人数 44467 人。
在电话会议上,GH 高管一再强调他们与 Medicare 保持着顺畅的沟通。入组人数增加,想必也是有 NEJM 中没有充分回答的问题需要继续回答。
聊完产品获批的 part,我们再回过头来聊聊 Shield 产品本身。
时间回到 2019 年,GH 通过 2019年AACR 首次公开介绍了他们针对结直肠癌(CRC)的检测产品。这个产品的独特之处在于同时分析 ctDNA 的基因组和表观基因组特征。

基因组变异包括:SNV,Indel,fusion 和 CNV;表观遗传变异包括 DNA 甲基化信号和核小体站位/片段组学。

产品设计上,GH 利用晚期癌症患者的 cfDNA 大型数据库,开发了一个 500Kb 大小的靶向测序 panel。这个 panel 可以检测与 CRC 相关转录因子结合位点的体细胞变异、甲基化变化和其他表观基因组变异。技术上能同时检测甲基化和非甲基化的 cfDNA。

初步分析结果显示,相比单独的体细胞突变分析,加入表观基因组分析显著提高了 ctDNA 的检测能力。
2020 年 AACR 会议上,GH 继续发布了 相关研究进展。这时,他们的检测产品被命名为 LUNAR-2 assay(即现在的 Shield),其靶向区域针对常见的致癌突变以及在癌症中可能经历表观基因组修饰变化的区域(差异甲基化和核小体定位变化导致差异的 DNA 片段化模式)。
析过程包括
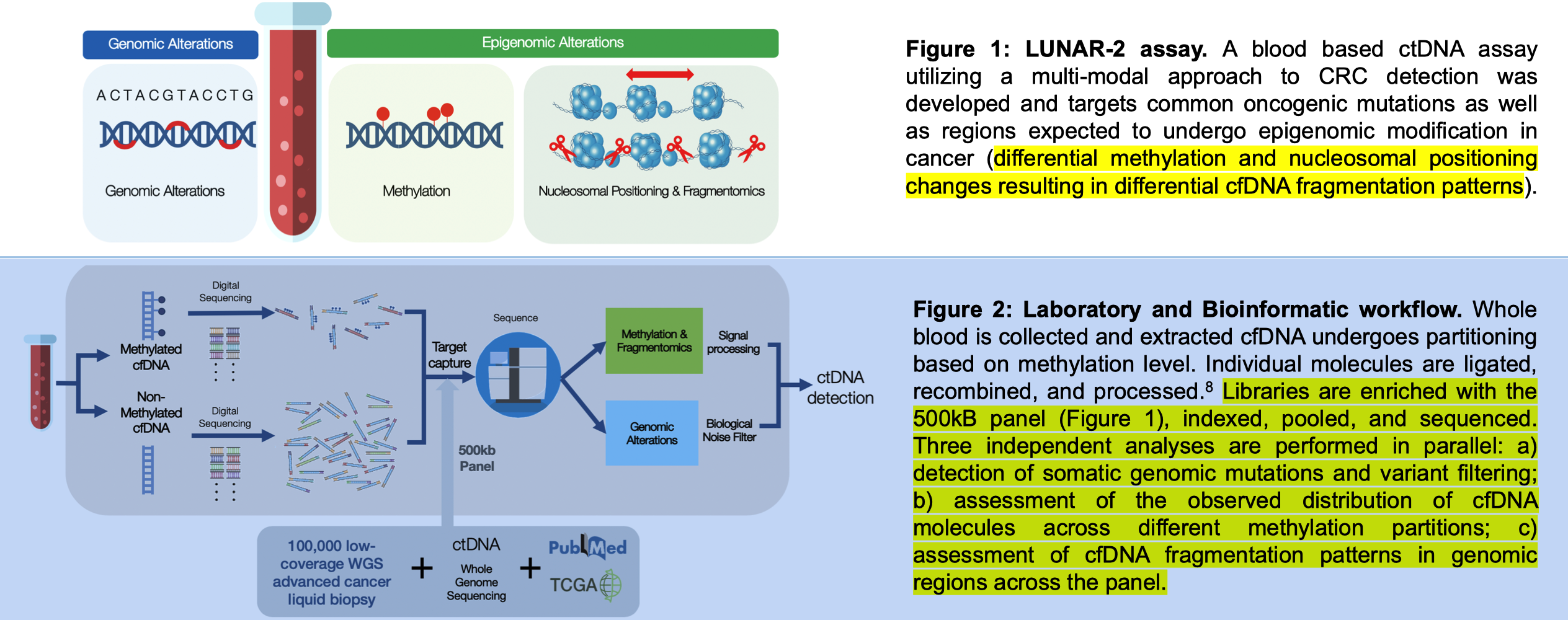
这次的 poster 还明确指出了 panel 设计数据来源于超过 10 万例 Guardant360 数据以及健康人/晚期 CRC 患者的全基因组测序 (WGS) 数据。

研究发现,在 CRC 肿瘤组织中,根据差异甲基化选择的区域显示出明显的甲基化信号。通过比较结肠镜检查阴性的受试者和晚期 CRC 患者的 cfDNA 全基因组测序数据,研究者观察到一致且强烈的甲基化信号差异,提高了区分能力。
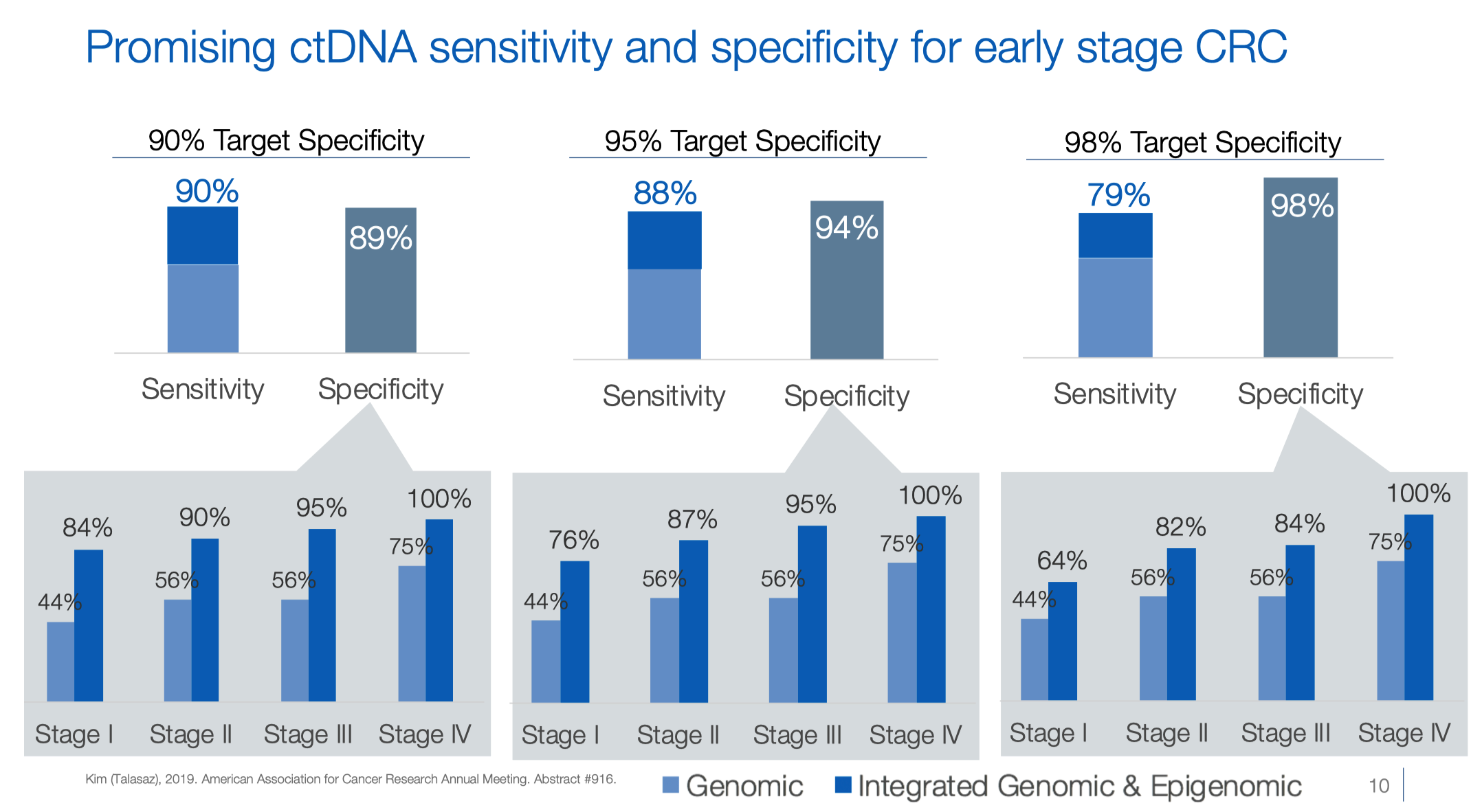
随着算法和技术的逐渐成熟,2021年 ASCO 上,GH 公布了一项涉及 434 名患者和 271 名对照样本的更大规模 LUNAR-2 性能评估。研究结果显示,该检测方法在多个临床特征中都表现出具有临床意义的敏感性。这项 poster 的最后提到:
A prospective registrational study is ongoing to evaluate the test in an average risk CRC screening cohort.

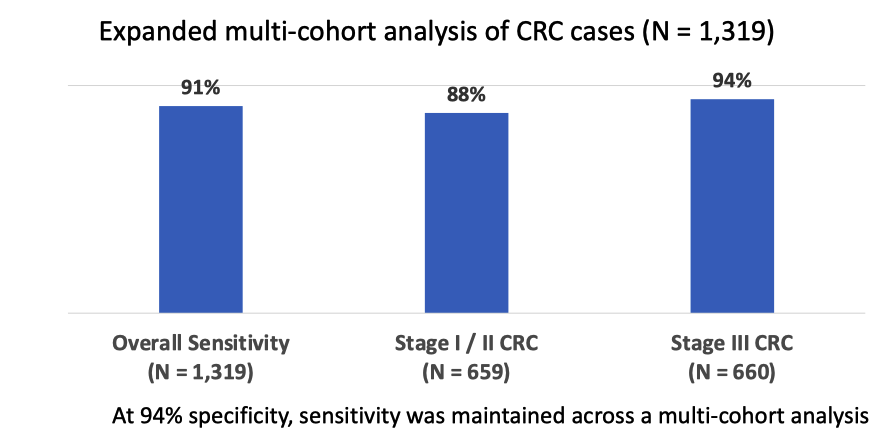
同年,在美国胃肠病学会(American College of Gastroenterology)年会上,GH 发表了一个更详细的口头报告,重点强调了该产品在早期 CRC 筛查中的潜力,以及在一般风险人群中的应用前景。


进而引出了该产品应用于早期 CRC 进行 screening 的潜力,也提到了把它应用在一般风险人群中的应用场景。
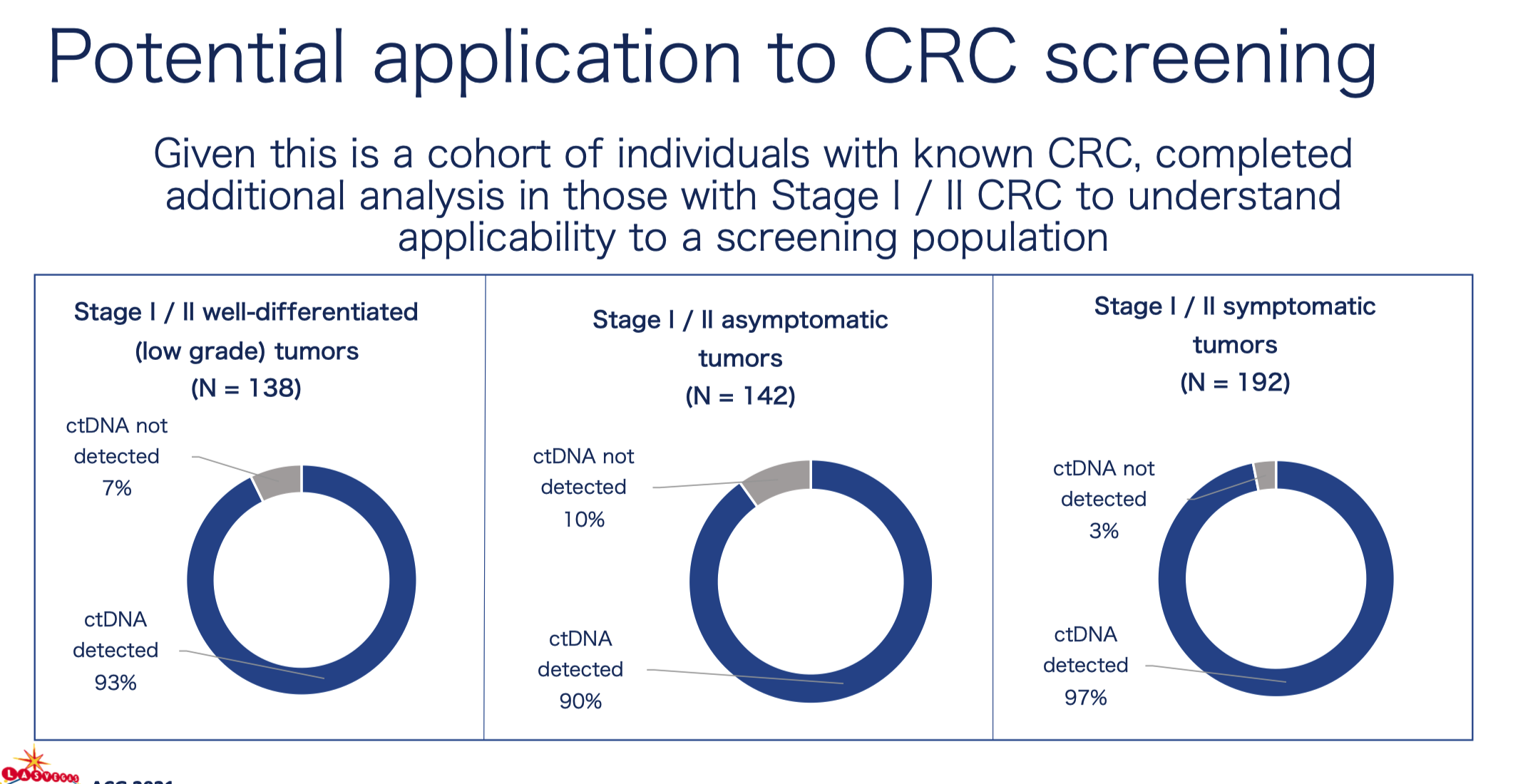

一年之后,2022 年 ASCO 会议 中 GH 进一步发声。这次他们带来了在西班牙四家医院开展的前瞻性研究分析结果。
值得注意的是,这次 Shield 代替 LUNAR-2 成为了产品名,而整个检测方案里增加了一个看起来「不怎么和谐」的蛋白质组学结果。这一变化也不难理解,既然 GH 选择了结合突变信息和表观遗传学的多组学策略,那么在产品迭代过程中自然会考虑到蛋白质组学。
不过,事后证明,蛋白质检测结果整合到最终的 YES or No 判断中,这一策略似乎对也不对,并没有真实提高检测性能(后面我们会具体提到)。

在这项研究中,GH 对超过 6000 个样本上进行了训练,其中包括 2685 个 ACN 阴性样本和 1698 个 ACN 阳性样本。通过 1072 个 ACN 阴性样本和 551 个 ACN 阳性样本确定阈值,在验证之前,以 91.5% 的特异性为目标锁定模型阈值。
随后在六个中心验证中得到了如下结果。两个小细节,I 期癌症的敏感性高达 90%,AA 的敏感性还在 20%。


时间来到,2023 年 5 月,在著名的消化系统疾病年会(Digestive Disease Week)上,GH 首次正式对外公布了 ECLIPSE 研究的初步结果。

这次公布的分期敏感性和我们在 NEJM 看到的已经基本一致。
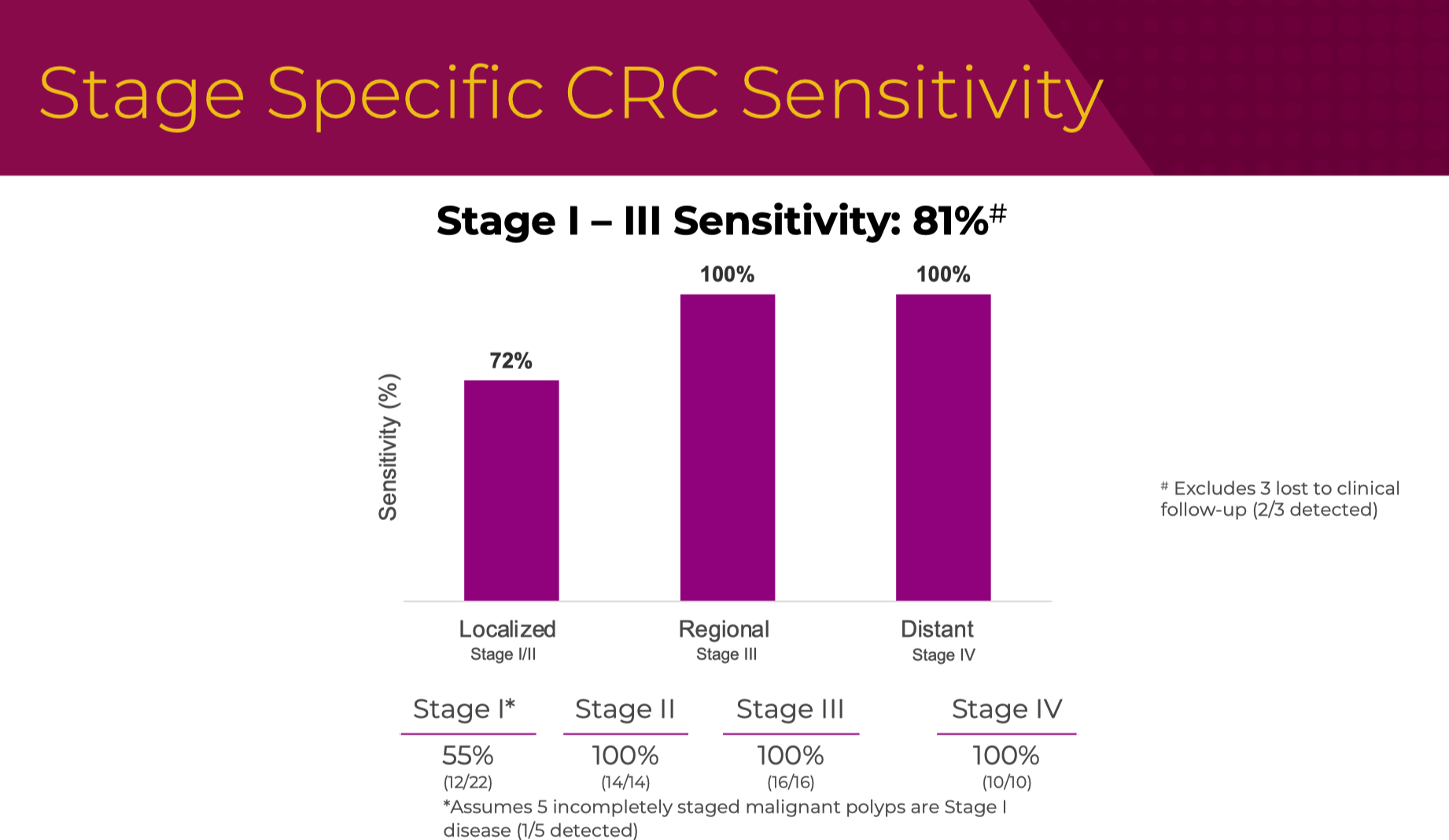
AA 的敏感性掉到了 13%,当时还公布了 HGD 的性能(23%),但在最终的 NEJM 文章中并未提及。

同时,GH 也提到了如何在真实世界中考虑依从性的问题:评估筛查项目时需要考虑真实世界的条件和患者因素。倡导从理想化条件下的有效性评估向更实际、更贴近临床实践的效果评估转变。

从 Shield 的发展历程来看,从 19 年开始,基本每年都会有非常稳定的产出,整体的产品技术路径和临床应用场景也越来越清晰。点赞 GH Shield 的研发和科学团队。
在这次展示内容的最后,GH 提到 Further assay development to expand detection capabilities。而这件事, Shield 一直在尝试。
如果说 Shield 的 FDA 获批之路看起来顺风顺水按部就班,那它的性能提升之路似乎就只能摸着石头过河。
在上文,我留了一个扣子,2022 年 6 月 ASCO 的 Poster 里,GH 提到在既往的分析方法基础上新整合了蛋白质检测的结果。

可到了 2023 年 5 月 DDW 大会的结果展示中,蛋白质组学又默默地消失了。

发生了什么?
这其中的缘由,我们可以从 2023 年 10 月 GH 在 Annals of Oncology 发表的结果和 2024 年 NEJM ECLIPSE 主文章中窥见一二。

2023 年 10 月的 Annals of Oncology 论文中,GH 提到:
The aim of this study was to determine the performance of a novel multimodal ctDNA-based blood assay (that includes detection of genomic mutations, methylations, fragmentomics and proteomics) to detect CRC at different Tumor-node-metastasis (TNM) stages (primary endpoint) and advanced precancerous lesions (secondary endpoint), in a pilot study of FIT-positive individuals from a population-based screening program and individuals with known CRC.
emm,看来最初并未打算放弃晚期癌前病变的检测。

在这项涉及 623 例样本的研究中,首先使用不包含蛋白的算法进行分析,晚期癌前病变的敏感性为 14%

GH 似乎对这个结果并不满意,还想挣扎一下。于是他们说道:
In order to improve the accuracy to detect precancerous lesions, an exploratory analysis that used a refined version of the blood multimodal ctDNA-based test was carried out in a subgroup of 86 individuals from cohort 1.
他们的做法是加入蛋白质组学数据。
首先在癌症样本和健康样本之间对表达水平存在差异的多种蛋白质标记物进行分析,然后开发统计模型整合这些蛋白质标记物的水平,生成蛋白质分类结果,最终与之前的结果整合,生成一个二分类判断。(合理怀疑是 Olink 的销售手段高超,说服了他们😂)
一顿操作猛如虎,性能提升 5%。
在这 86 个样本的小队列中,AA 的敏感性被提升到了 23%(小队列不加蛋白的原始版本 AA 敏感性是 18%)。可随之而来的小问题是特异性也从之前的 90% 掉到了 86%。

虽然文章发在 Annals of Oncology,但是如果通过蛋白质组学加成让 AA 提升 5% 敏感性的代价是牺牲 4% 的特异性。我想,这是除AA 性能党之外所有人都不能接受的。
别忘了,Shield 的底线是坚守 90% 特异性,满足 Medicare 的要求。
于是,在 2024 年 3 月 NEJM 主文章的附件材料中,我读到了这样一段话。

虽然只是一句轻描淡写的「添加蛋白质反而不如只用 cfDNA 效果好」。懂得都懂:两全相害取其轻,特异性上不放松。
从 2019 年开始到 NEJM 文章发表前,公开的学术资料中凡是涉及到产品设计路线图的,GH 一直宣称 LUNAR2 的 panel 大小为 500Kb,甚至 2024 ASCO 一篇摘要中,方法学部分仍然标注了 500Kb。
但到了 MEJM 的文章中 panel 大小默默变成了 1Mb,无奖竞猜,多出来的 500Kb 是干什么的?

Cologuard 有 V2,Shield 同样也并非不思进取。
早在 2023 年的几次公开会议中,GH 就已经透露了 Shield V2 版本的消息。
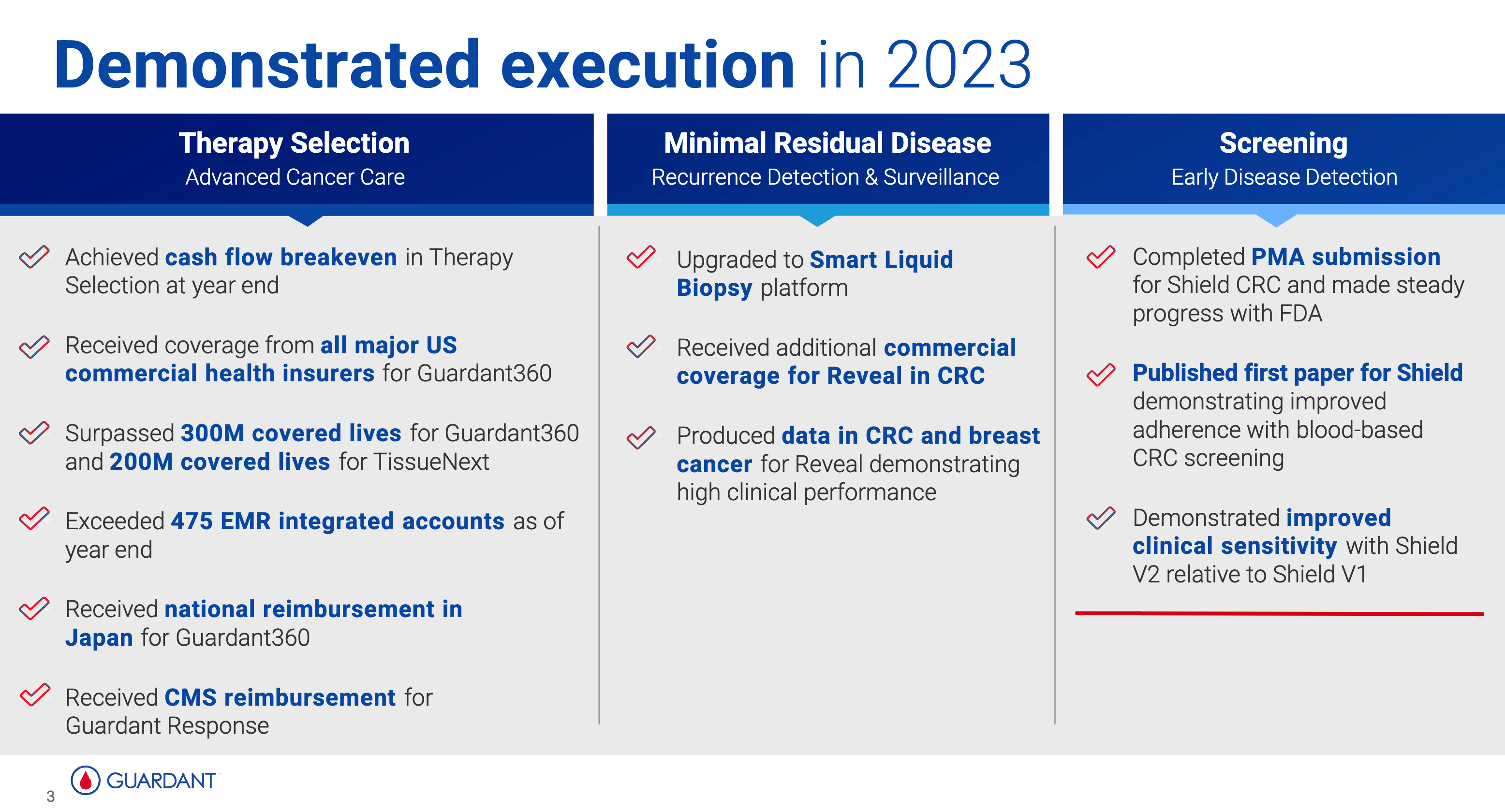

在放弃 AA 性能的挣扎之后,V2 版本的 Shield 保证特异性不降的前提下,将整体敏感性从 V1 版本的 84% 提升到了 91%。
这一结果最终正式发表在 2024 年 ASCO-GI 会议 中。GH 1M panel,10X 测序深度的数据中,通过提高噪声过滤和模型调参,更好地检测了 ctDNA 低脱落的肿瘤样本。相比 ECLIPSE 实验中的模型,LoD95 下降到十万分之四,I/II 期敏感性从 76% 提高到 88%。

在 Guardant 用 Shield 对标 Cologuard 的这几年里,他们面对 Grail 左手右手的几个大动作,想必也无法视而不见。
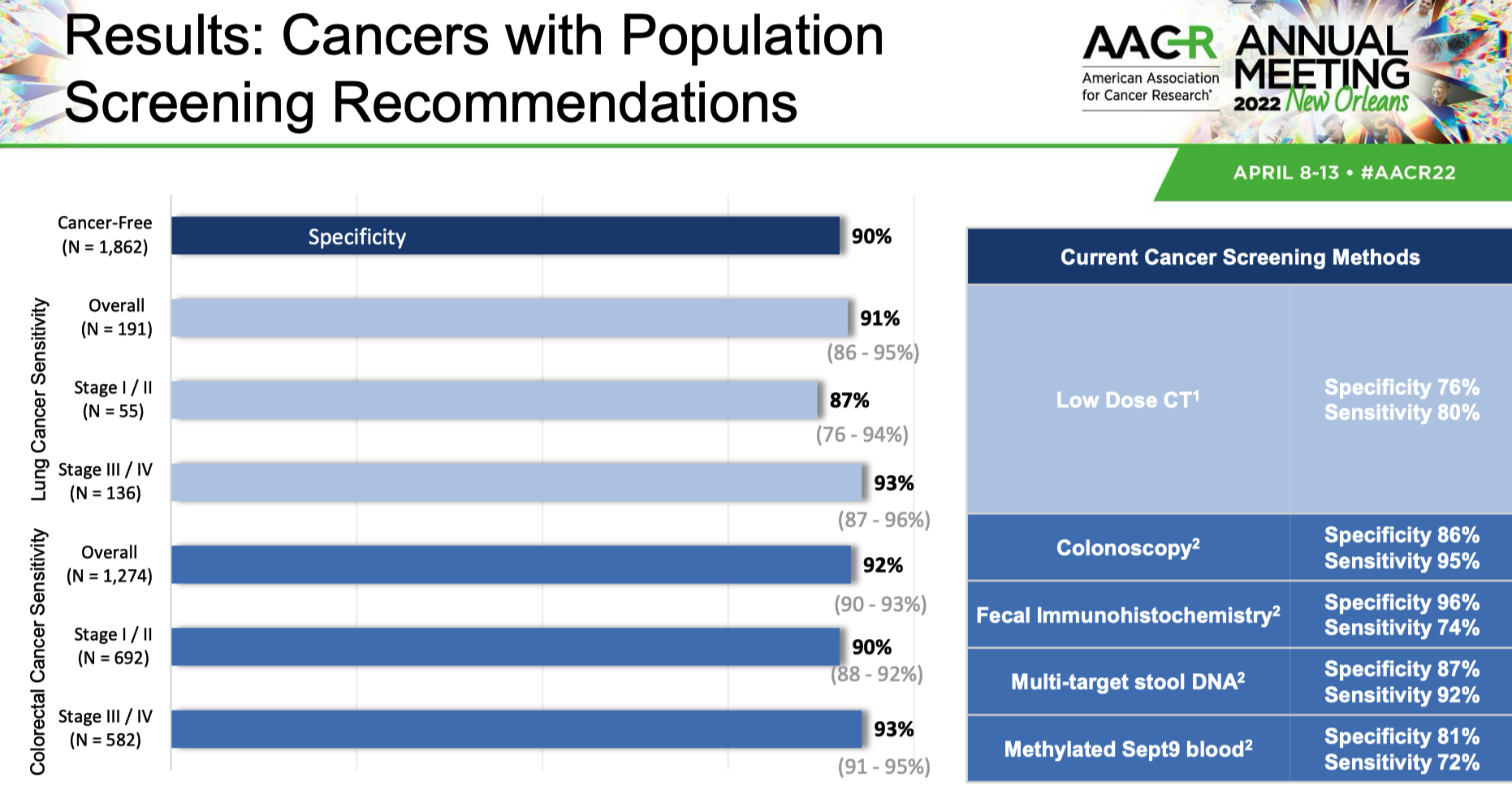
早在 2022 年 AACR 年会上,GH 的口头报告就介绍了其 多癌筛查规划。

依旧基于 Shield 的甲基化信号富集技术,完成多模态信号输出。

这种技术能在降低测序成本的同时提高信噪比。当时披露的 SHIELD 面板大小为 1M,测序量接近 40M。而新一代 Shield 在 15Mb 面板(据报道包括约 20000 个表观基因组生物标志物)的基础上,只需不到 20M 的测序量。

在这次研究结果中,他们也公布了结直肠癌、肺癌、胰腺癌和膀胱癌四种癌症的初步分析结果。

一年后的 ASCO 年会,GH 再次详细介绍了他们计划开展的 一项针对多癌种的前瞻性、观察性、多中心篮子研究 SHIELD (Screening for High Frequency Malignant Disease)

该研究的主要目标是评估基于血液的多癌筛查测试(Guardant LUNAR-2)与标准筛查方式相比的检测性能。每个研究队列代表一种(或多种)癌症类型。
符合条件的个人在相应癌症类型的标准护理筛查的 90 天内进行全血采集,临床诊断按照标准护理进行。
主要目标:基于血液多癌筛查测试的敏感性、特异性、PPV 和 NPV。次要目标:每 1000 名筛查者中检测到的癌症数量、早期和晚期数量。同时随访收集一年和两年的临床结果。
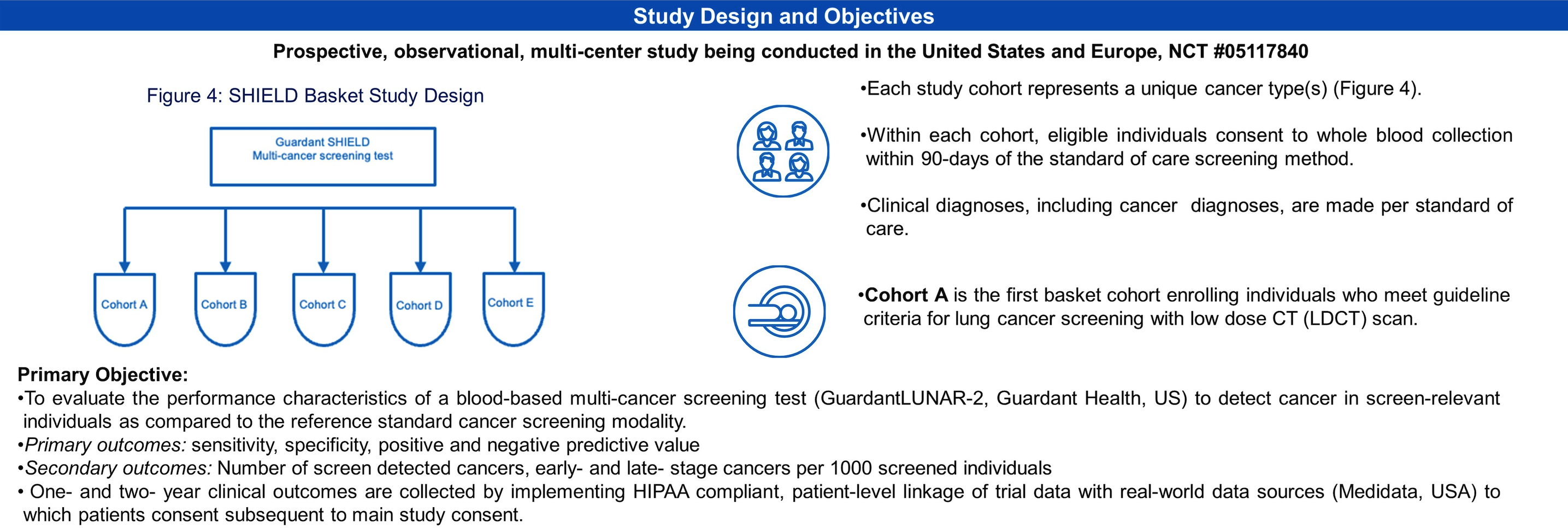
正在进行的队列 A 为肺癌筛查队列,入组条件与 USPSTF 筛查推荐一致。当时的公布内容显示该队列将在 24 个月内招募 9000 名受试者。启动一年后入组 4866 人并预计在 2023 年底达到目标,2024 年 12 月完成主要结果数据收集。
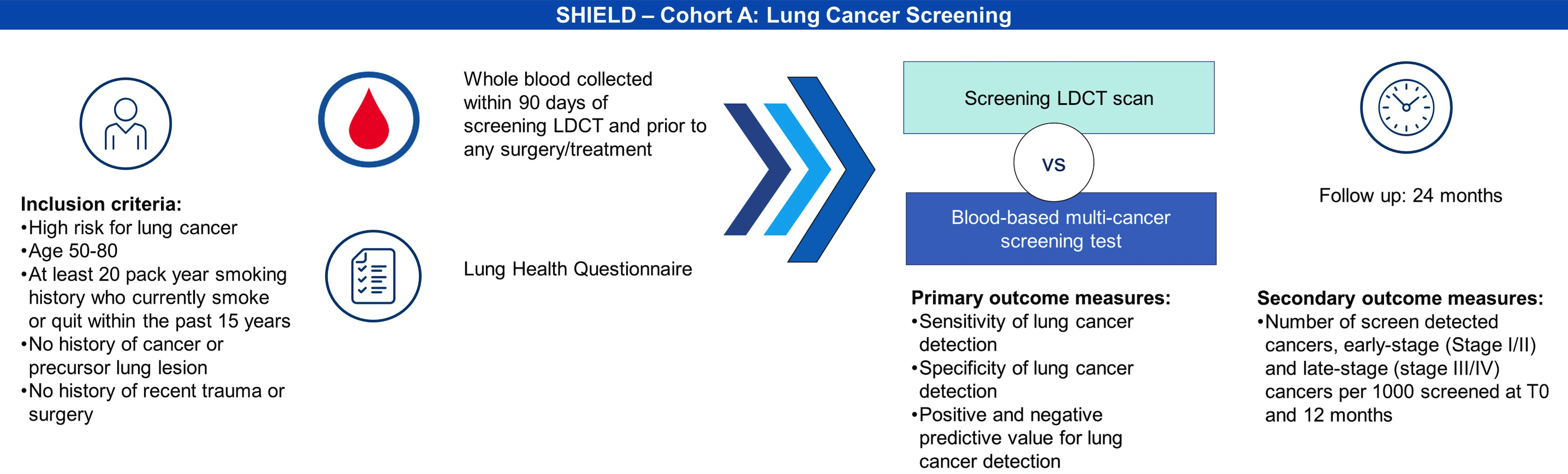

如果查看实际的 临床实验注册信息,A 队列又增加了 3000 名受试者入组配额,2024 年 7 月状态修改为停止招募。随访计划也从原来的 1 年和 2 年各随访一次调整为仅 1 年随访一次,预计今年底就会有主要结果。
以及,从 GH 的对外发言中,我们可以大致了解他们的癌症筛查产品线规划:

肠癌目前已经完成 FDA 获批,随后启动 IVD 和 ADLT,针对一般风险人群每 1 年进行 1 次检测,预计 2026 年搞定 USPSTF。
肺癌在路上,目标是针对一般风险人群 3 年检测 1 次,针对高风险人群推荐 1 年检测 1 次。
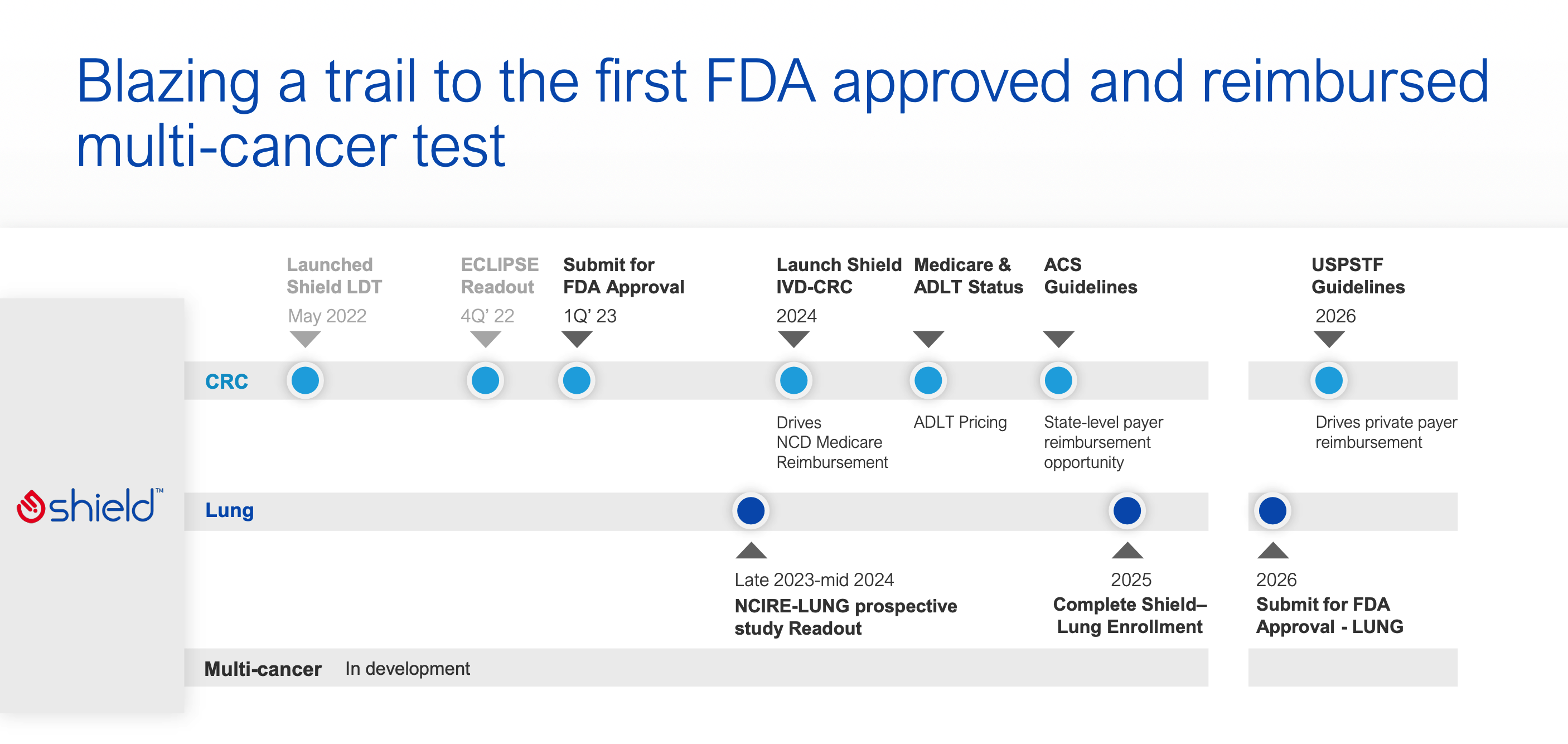
更有趣的是,他们要如何做到:用相同的检测和费用,只需简单的软件升级就完成新癌种的检测呢?

如果你对这篇文章感兴趣,欢迎通过邮箱订阅我的 「熊言熊语」会员通讯,我将第一时间与你分享肿瘤生物医药领域最新行业研究进展和我的所思所学所想,点此链接即可进行免费订阅。
2024-07-21 21:24:27
你好,我是思考问题的熊,熊言熊语公众号/播客的主理人。一个超过半年没有和你通过邮件通讯相见的拖更作者。诚惶诚恐,不知道你这半年可好。
不只是没有和你交流,2024 年过去半年多时间里自己基本处于断网状态,变成了一个只有线下模式的 NPC。
此刻,当我打开电脑准备写点什么,感觉熟悉又有些陌生。就像准备要和很久没联系的朋友见一面,难免会觉得忐忑。纠结许久,还是只能先说一句:好久不见。
在本期通讯内容中,我将和你分享过去一段时间我的经历感受和反思,也会为你推荐一个我在进行的秘密项目,邀请你参与体验。
过去半年多,我扎扎实实地经历了几种情绪和几件事:亲人的离开、价值感的缺失、不知道被什么裹挟着看起来的努力,还有重新理解人和人的各种亲密关系。
很多时候我都想把这些事情和感受分享给你,甚至有两次一大早起来已经打开话筒准备录一期播客,但又都放弃了。
我起初把这种心态变化归结于年龄上涨之后「表达欲」的降低。但这半年密集经历的事情让我明白,这种变化可能来源于:经历了新的一件事之后就会发现之前经历过的似乎也没什么。
有趣的是,16 型人格测试的结果一年前我是 ENFJ,但是前一段时间又进行了一次检测自己变成了 INFP。我从E人变成了I人,不知道预示着什么。
我习惯一段时间内对一件事情异常投入。这个性格和方法上的缺陷会导致我容易在「一件事情上」周期性地出现和消失。而这种转变往往是因为我突然「阶段性」地想明白了一点东西。
2023 年 11 月初,我曾经摘录了这样一段读书笔记:

美化智商的表现之一,是把别人的见解转述出来,以获得影响力。重要的不是通过美化智商提升影响力,而是亲身实践后获得的观点或洞察。by《笔记的方法》
《笔记的方法》这本书里提到一种「美化智商」的概念。作为一个几乎不用美图功能的人,看到这段内容之后不得不承认,公共视野下的自己是不是偶尔也有美智的行为。
我曾经和一位好友聊过关于「分享」的话题,当时表达了关于「分享」的三种理解,也在这里转述给你讨论。
分享这件事,根据我的观察有 3 个层次。
第一层是利用信息差,把我看到但你还没看到的信息转达给你。 这件事本身不存在能力差别(emm,也许快速接触到信息也是一种能力)。做好这一层的要务是「快」,同一个信息在不同节点间流动,只能争取做第一个信息传递节点,而且这个节点的辐射范围越大越好。
第二层是整合转述和总结未经实践的他人观点。 其实,能做到这一点已经有很高的要求,也是绝大多数创作者的终点。日常学习、读文献和读书都是如此,我在大多数时间也才停留在这一层。做好这一层的要务是「想」,和别人接触到的信息没有什么区别,但是肯花功夫理解和思考,这样就不需要一直追热点和时效。
第三层是躬身入局把手弄脏。 你分享的是真实地实践反馈与感悟。做好这一层的要务是「做」,这个过程中你可能会重复自己看到的,验证自己想到的,也可能发现一些从未有人提到的洞察。
一句话总结这三个层次就是:你看到了什么,想到了什么,做到了什么。有效的分享不仅仅是传播信息,更需要深入理解分析和思考并将其应用于实践。
过去半年,我把大量时间放在了一个真实的研究项目上。有自己的数据,尝试了各种方法希望能从中获得 Know how,也经历了各种波折和困难。这个项目的部分研究结果会在今年 ESMO 会议上发表。
在这个过程中,如书中写的,我希望让那些看到想到的观点穿过自己,沉淀出属于自己的知识。我也希望,今后带给你更多的是第二层和第三层的内容。
在这个过程中,我又一次深刻理解了所谓解释深度错觉(Illusion of Explanatory Depth, IOED) 这种认知偏差。IOED 是由耶鲁大学研究人员 Leonid Rozenblit 和 Frank Keil 在 2002 年提出的概念。这种认知偏差指出:人们倾向于认为自己对某个主题的理解程度比实际上要好得多。
如你所感,对别人,我们总是会看到一些文章,看起来感觉头头是道,但只要让他再稍微要求多一步解释就会露馅。对自己,我们有时候会以为自己已经很了解一件事,但只有动手做一下才能意识到自己并不清楚。
也是在过去半年时间里,各种大语言模型层出不穷。借着自己能写一点的代码,我尝试将 LLM 融入到自己各项日常学习和工作流中。
虽来不及思考 AI 会不会替代人或者何时会替代人,但我一直努力尝试用 AI 替代自己。我把自己会做的每一件事都尝试用AI做一遍,去探索今天 AI 的边界,也重新认识今天的自己。
到目前为止,大概日常 20% 的重复性工作和信息获取与整理可以丝滑地让 AI 配合我完成,不到 30% 可以让 AI 参与进来。而剩下的一半我还在持续探索,这也让我看到了目前即便最强大的LLM仍然存在局限。
在让AI替代自己的过程中,我反复审视过去几年一直在坚持的内容输出。
发现除了时效性信息的传达和知识性内容的归纳,在 LLM 逐渐可以成为基建能力的今天,和你分享我一直完善和践行的各种方法,反而可以产生更重要的价值。也是因为有了 LLM 这个趁手工具,「授人以鱼不如授人以渔」这个道理越来越格外正确。
在我既往和你分享过的各种思考碎片中,我一直反复安利我们每个人应该持续拥有两个东西。
一个是好奇心,有了好奇心,我们才可能不只做有明确目标和熟悉的事情,才能有机会做出一些好玩的东西。
另一个是属于自己的产品,它可以是一本书、一个软件或者是一个实际的物件。总之你要全程参与决策它的构思、生产和未来发展。
一个属于自己的产品,会帮助我们顺其自然地完成从看到什么到想到什么再到做到什么的三级跳,也会自然地帮助我们克服"解释深度错觉"的认知偏误。
类似的观点我前几天也在万维刚的一篇文章中看到,他提到:人应该有个自己的"秘密项目",做个 maker 去设法创造一个东西。你对这个东西的要求应该是,除你之外至少还有一个人很愿意用它。
写到这里,我就再和你汇报过去半年我一直在"秘密"进行的另一个项目:

过去几年,无论是写博客还是录播客,无论是分享思考还是专业知识,我做的每一件事,本质都是将自己日常输入的海量信息,通过自己逐渐形成的逻辑和方法进行追踪、过滤、加工和整理,变成一种更优质的内容进行输出。
如今,我希望可以把这一套逻辑方法进行提炼总结和产品化,让更多的人可以高效的获取信息和吸收知识。于是,就有了第一步 InsightPaper。 by 思考问题的熊
InsightPaper 是一款整合了大语言模型能力的研究进展追踪和文献辅助阅读工具,其背后的开发逻辑是我自己这些年摸索出的一套完整的研究进展追踪和文献学习方法体系。
InsightPaper 不止提供答案,更重要的,是配合你一起完成答案的探索。
如果你是最近一年关注和订阅了熊言熊语,我想大概是因为你看到了我很多关于最新研究进展的梳理和总结,你也一定对"读文献这件事并没有那么简单"有所体会。
读什么和怎么读,这两个最根本的问题就让很多人感到困扰。当想把这件事的系统理解讲清楚时,我发现通过写文章把这件事情说明白远不如直接做一个工具让需要它的人用起来实在。
于是,在几十个夜晚和周末的反复测试和完善后,就有了目前这个前端后端加起来接近 3000 行代码的工具。
目前测试版形态大概是下面的样子(虽然不炫酷,但是挺好用)
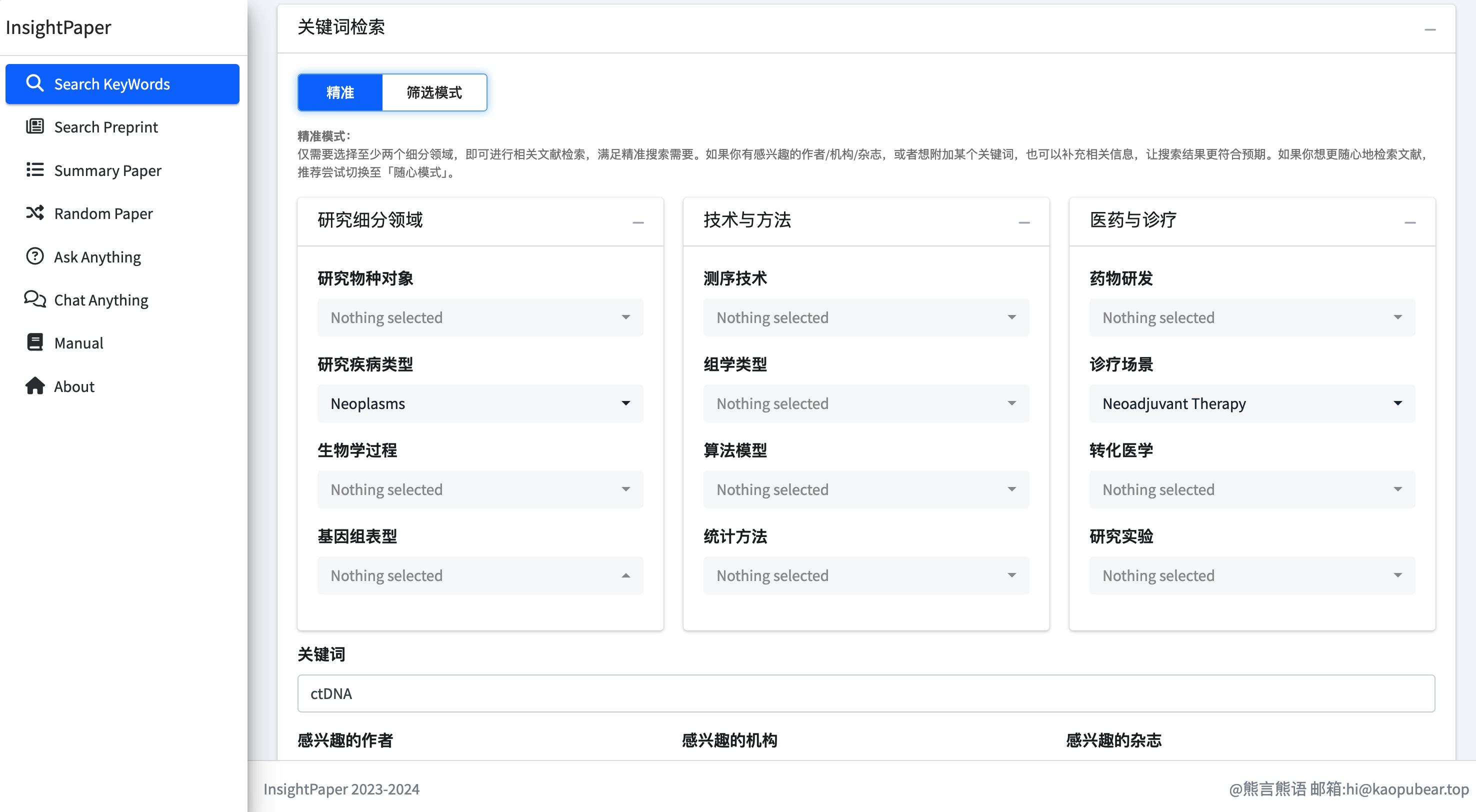
文献检索小结

核心文献检索

核心信息提炼
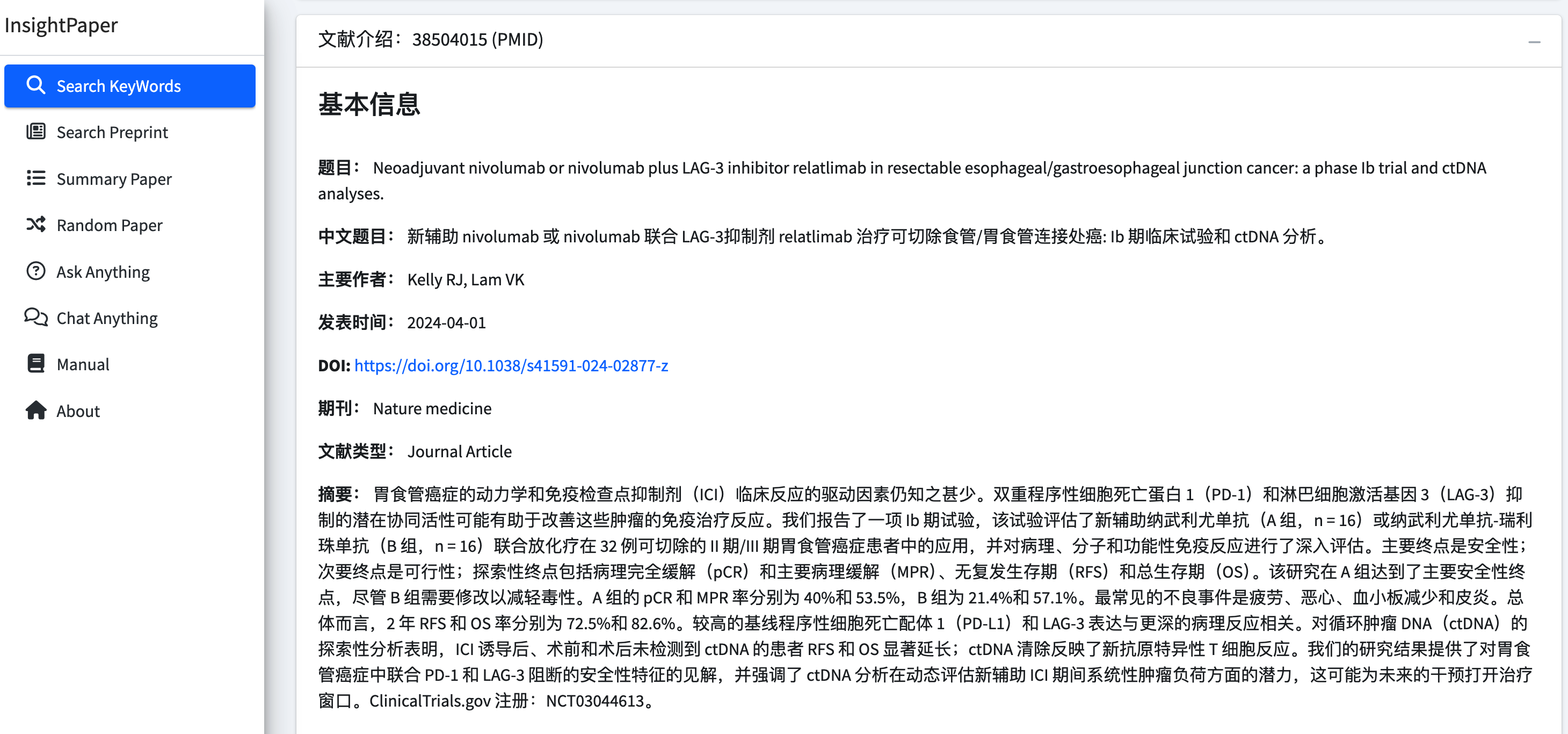

最新相似内容推荐

一些好朋友在内测 InsightPaper 的过程中给出的反馈大多数是:
InsightPaper 今天正式面向所有熊言熊语订阅读者发出小范围公测邀请。
如果你对于文献阅读有需求,对 InsightPaper 感兴趣,可以**通过添加我的微信 kaopu_bear 备注"InsightPaper 内测"**获取 InsightPaper 的使用方式,并进入测试交流群随时沟通。
以上,就是我过去一段时间的思考感悟和insightPaper介绍。在本期内容最后,我想说一下关于熊言熊语邮件通讯本身。
过去一年多的时间,相继有一百多位认可信任我的朋友,先后通过付费会员的方式支持熊言熊语,但是如你所见,我并没有为大家完成足够的交付。这点一直让我惴惴不安,如鲠在喉。而绝大多数朋友表现出的理解和宽容,又让我感谢满满和有所亏欠。
从本周开始,熊言熊语邮件通讯将在「insightPaper」能力加持下正式恢复更新。
过去半年,我完成了自己信息获取工作流和写作工作流的升级,在有能力保证常规内容更新的基础上,也可以拿出更多精力完成上文中我提到的第二层次和第三层次的输出和分享。
很快再见,这次就写到这儿。
如果你对这篇文章感兴趣,欢迎通过邮箱订阅我的 「熊言熊语」会员通讯,我将第一时间与你分享肿瘤生物医药领域最新行业研究进展和我的所思所学所想,点此链接即可进行免费订阅。
2023-05-03 19:52:38
本文为熊言熊语邮件通讯会员计划内容的试读版,完整内容请点击通讯主页订阅并查看。
你好,我是思考问题的熊,本内容是参加会员计划读·者的专属内容,感谢你通过会员计划支持我持续创作。展信佳~
本期内容:
在关于生物标志物 HRD 的前两期内容中,我们分别了解了 HRD 作为生物标志物的提出和临床核心应用场景,具象感受了一个生物标志物从逐渐被人们认知到接受,究竟需要经历怎样的过程。
在本期内容中,我们将继续了解 HRD 这种生物学现象可以如何检测以及目前市面上那些相关的国内外产品,共同感受一下当 HRD 被人们认可后,各家国内外厂商的跟进方式。(本期内容字数 5700+)
下期预告
下期内容中,我将和你分享一些自己关于 HRD 及相关产品目前临床应用的困惑和思考。
了解了 HRD 作为生物标志物目前在临床上的核心应用场景,下一个主要话题就是了解 HRD 这种生物学现象应该如何检测以及目前市面上对应的产品。
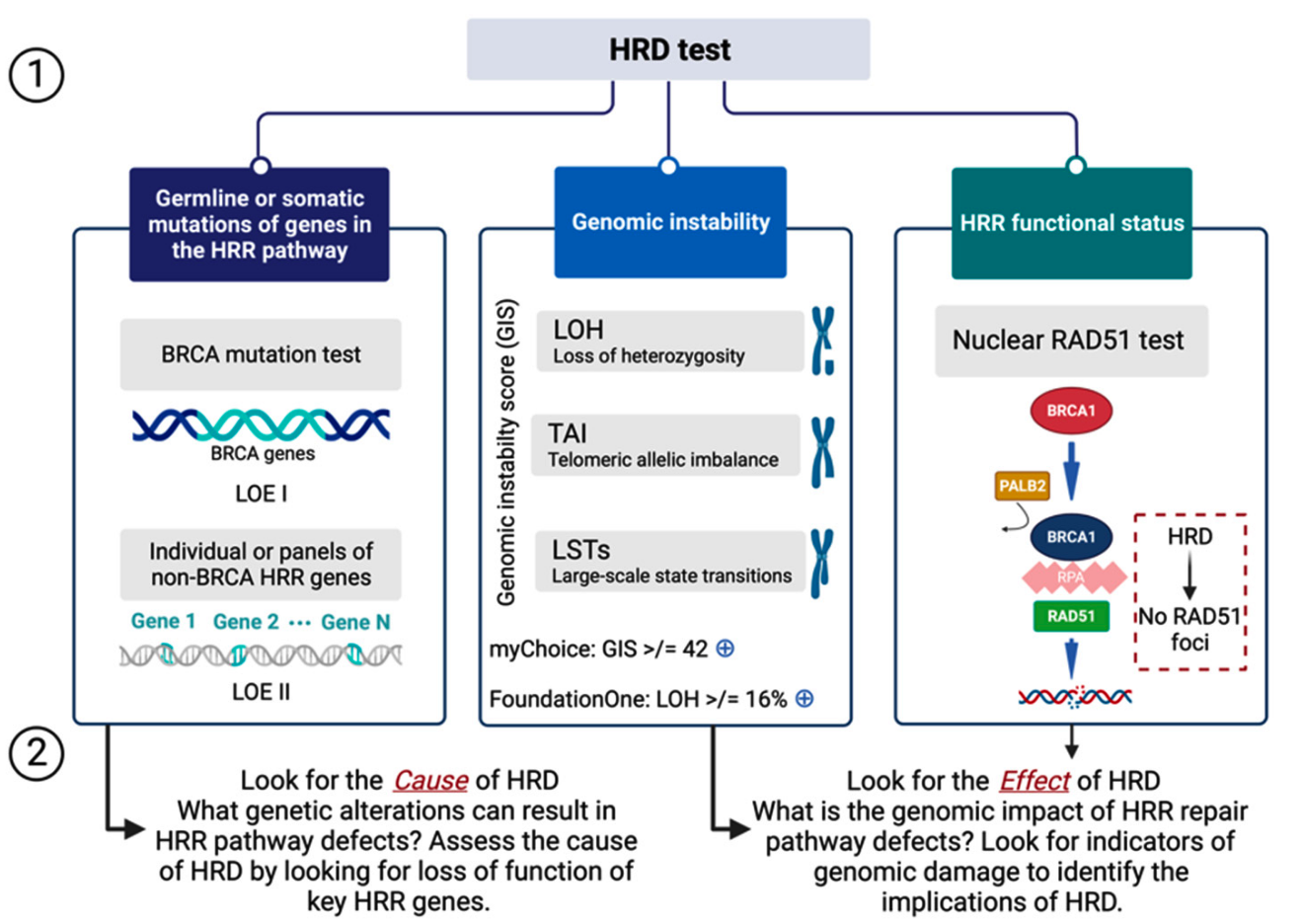
笼统讲,检测一个生物学现象可以从两个维度出发:检测造成这个生物学现象的原因;检测这个生物学现象导致的结果。
具体讲,针对同源重组修复缺陷,我们既可以考虑检测其原因,例如对应通路的 BRCA 或其它基因突变,BRCA 启动子甲基化等等;也可以考虑检测同源重组修复缺陷造成的结果,也就是所体现出的基因组不稳定性。
在介绍 HRD 的临床验证过程时,其实我们就反复提到了 Myriad 这家公司和它的 HRD 检测产品。说到 Myriad,这家成立于 1991 年的公司在肿瘤 NGS 检测历史上有这非常重要的地位。在后续国内外知名公司的系列内容中,我们会继续深入了解它。
在这里,你只需要知道他们早在 1994 年就申请了关于 BRCA 遗传基因以及其诊断方法的相关专利,且这件事情引发了后来一系列接近 20 年的基因是否可以作为专利的争论。从 BRCA 到 HRD,Myriad 能走在 HRD 检测的最前列也似乎是情理之中。正如在上一期通讯的中,我写到:
至此,这几项大型的三期临床研究一方面证实了几家 PARPi 在卵巢癌维持治疗中的作用,另一方面因为他们都不约而同选择了 Myriad 的 MyChoice 检测产品,也让 Myriad MyChoice 事实上成为了 HRD 检测临床使用的「金标准」。

HRD 会产生特定、可量化、稳定的基因组改变,其中包含可鉴别突变、插入 / 缺失,以及染色体结构异常、基因拷贝数变异等,这也是当前构建 HRD 临床检测方法的理论基础。
HRD 临床检测所描述的肿瘤基因组特定改变也被称为「基因组瘢痕」。自 2012 年以来,杂合性缺失(loss of heterozygosity,LOH)、端粒等位基因不平衡(telomeric allelic imbalance,TAI)、大片段迁移(large-scale state transition,LST)等被作为基因组瘢痕标志物,以量化基因组瘢痕程度。
如同他们在 2016 年发表的论文,Myriad 将自己家 HRD 评估的产品命名为 MyChoice 和后来升级版的 MyChoice Plus,并将 HRD score 定义为 LOH + TAI + LST 加和(这部分具体内容可以参考 part1 部分正文)。
详细地说,LOH 定义为大于 15 Mb 且小于整个染色体长度的杂合性缺失;TAI 定义为延伸到其中一个亚端粒但不超过着丝粒且大于 11 Mb 的等位基因不平衡的染色体片段;LST 定义为两个相邻区域(两个区域长度均大于等于 10 Mb,且区域间距小于 3 Mb)之间的染色体断裂位点的总数。
LOH、TAI 和 LST 等 3 个指标都有独特的定义,在一定程度上都能描述细胞 HRD 状态的程度。然而,相较单个指标描述,三者组合综合计算评分能更全面反映基因组瘢痕状态,进而对基因组不稳定状态进行评估。所以 MyChoice 就是以 BRCA 1/2 的致病性变异状态加上基因组不稳定评分(genomic instability score,GIS)来评估 HRD 状态。
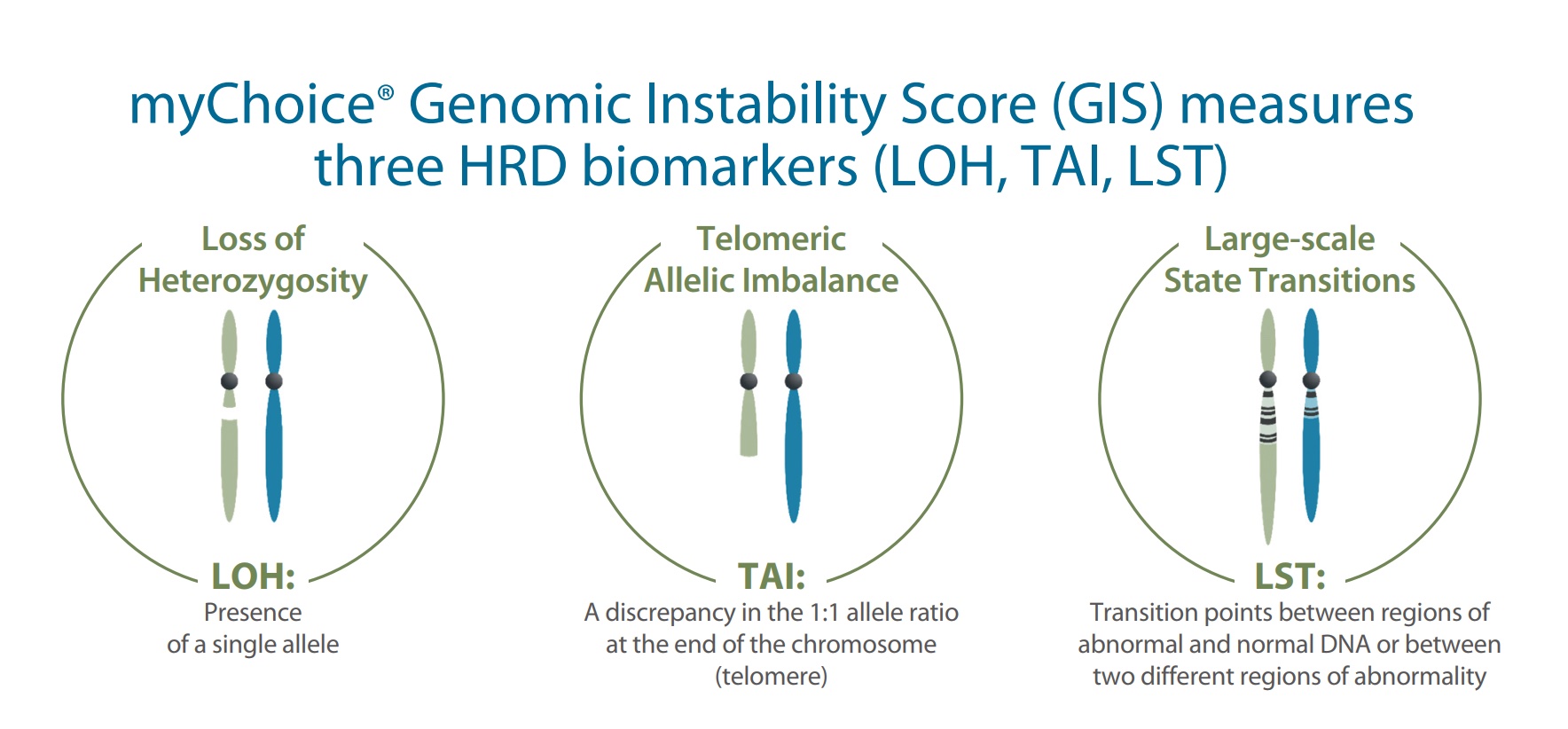
如果你还记得在 part1 中,我们提到了最早的论文中 LST 这个指标需要进行基因组倍性矫正,进而会产生负数,但随后它们取消了这个矫正,让这个计算更容易理解。
这里多说几句,对于不同组合构成的模型,我们往往会通过添加系数的方式,给每个不同的指标分配不同的权重,进而取得最好的预测效果,类似与 index = 0.2A + 0.65B + 0.3C,但是为什么 LOH TAI 和 LST 这三者刚好就是同等系数的简单加和效果最好呢?
其实,很早一期 Myriad 团队成员自己录制的播客节目 Myriad Live - Let's Talk HRD 中,它们给了这样一个解释:看似同等重要,其实并非如此。
如果你看一下等式,它们看起来是同等权重的,因为我们所做的就是把它们加在一起,但实际上,LST 分数的动态范围大约是其他两个分数的两倍,所以这意味着它对最终分数的贡献比 LOH 或 TAI 更大。
它往往比其他两个分数更高,所以我们实际得到的结果是,大约一半的最终分数来自 LST,平均大约四分之一来自 LST 和 TAI。
我们之所以对最后的设置感到满意,并发现它表现最好,部分原因是在我们早期的研究中发现 LST 实际上是 HRD 的最佳预测因子。因此,它比 LOH TAI 在数值上更重要,几乎占最终分数的一半。
如果你想更加具体的了解 myriad 官网自己对于这款产品的介绍,可以详细阅读下面的两个链接。
🍺🍺试读结束🍺🍺
剩余内容是参加会员计划读者的专属内容
欢迎你通过会员计划支持我持续创作
如果你对这篇文章感兴趣,欢迎通过邮箱订阅我的 「熊言熊语」会员通讯,我将第一时间与你分享肿瘤生物医药领域最新行业研究进展和我的所思所学所想,点此链接即可进行免费订阅。
2023-05-03 19:50:18
本文为熊言熊语邮件通讯会员计划内容的试读版,完整内容请点击通讯主页订阅并查看。
本期内容:
你将阅读到HRD临床验证的后半部分历程(2016-2020年),这几年内多个重要的临床实验证实了PARPi的临床价值,同时也顺便验证了HRD的应用价值(主要是 Myriad MyChoice 产品)。结合上期和本期内容,我们可以具象感受到一个生物标志物从逐渐被人们认知到接受,究竟需要经历怎样的过程。
下期预告
了解了 HRD 作为生物标志物目前在临床的核心应用场景后,下期我们就会了解 HRD 这种生物学现象应该如何检测以及目前市面上对应的那些国内外产品。

2014年12月FDA批准了首个PARP抑制剂——奥拉帕利(orlaparib),用于治疗晚期卵巢癌或携带BRCA基因突变的卵巢癌。
2016年发表在NEJM的一项名为NOVA的随机双盲 3 期试验中,另一款PARPi 尼拉帕利(niraparib)在铂敏感型复发卵巢癌患者维持治疗中展现了极为良好的疗效。研究人员招募了553例铂类化疗后复发卵巢癌患者,并根据是否带有生殖系_BRCA_基因突变,进行了安慰剂对照的随机临床试验。在带有BRCA突变的组中,经过尼拉帕利治疗的患者无进展生存期的中位数长达21个月,明显长于对照组的5.5个月。
令人兴奋的是,该研究还证实:不论患者为何种基因背景,尼拉帕利均可显著延长患者的无进展生存期,只是该作用在BRCA基因突变携带者或DNA同源重组修复功能缺陷(HRD)的人群中更明显。彼时尼拉帕利为治疗铂敏感型复发的卵巢癌患者带来了新曙光。
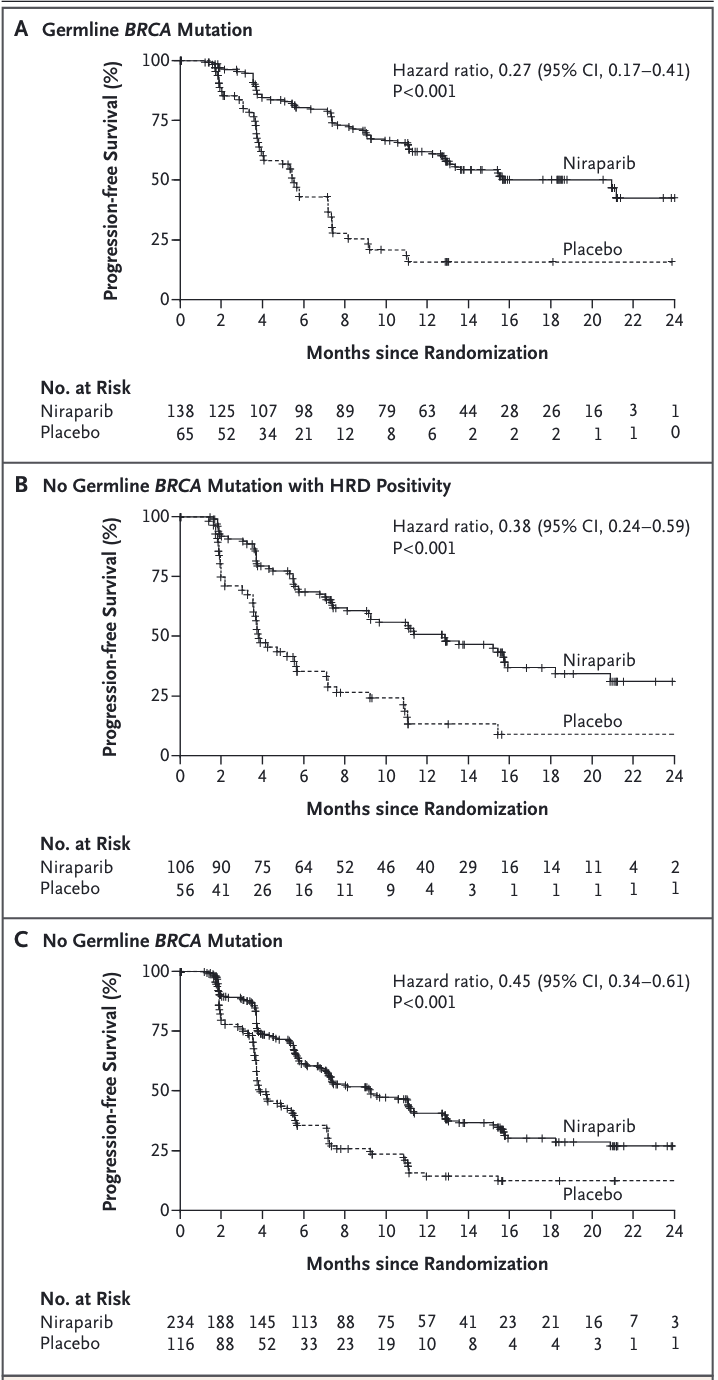
如果详细对论文相关材料,可以发现,有趣的是在制定研究方案时尚不清楚几个候选生物标志物中,哪一个适合作为接受过多种铂类疗法的患者使用尼拉帕利作为维持治疗的辅助诊断(CDx)进行评估。因此,最初的临床研究目标之一是利用研究数据来选择一个生物标志物并确定一个适当的阳性阈值。
研究开展后不久,Myriad 便开发了一种基于DNA测序的HRD检测方法:myChoice HRD,原理就是我们在上一篇文章末尾提到的检测方法。
于是这个研究目标也就不再需要探索,而是决定直接使用HRDscore >= 42 作为同源重组修复缺陷的标准进行分组研究。在 HRD-阳性加体细胞BRCA突变的患者以及那些具有胚系BRCA突变的患者中观察到类似风险比,体现了该药物在患者人群中反应的一致性。
再来说说奥拉帕利。
名为 SOLO 1 的三期试验在 2018 年底发表,结果说明患有新诊断的晚期 BRCA 突变卵巢癌患者,手术和化疗后接受 PARP 抑制剂奥拉帕利(Olaparib)的维持治疗与不接受维持治疗相比,疾病进展或死亡风险降低了 70%。
这个结果结果不仅使 FDA 批准了奥拉帕利(Olaparib)用于这一适应症,也代表着在治疗BRCA突变卵巢癌患者方面又向前迈出了一大步。不过这项研究使用了 Myriad 的 BRACAnalysis test 产品进行 BRCA 检测,并未涉及到 HRD 评分。
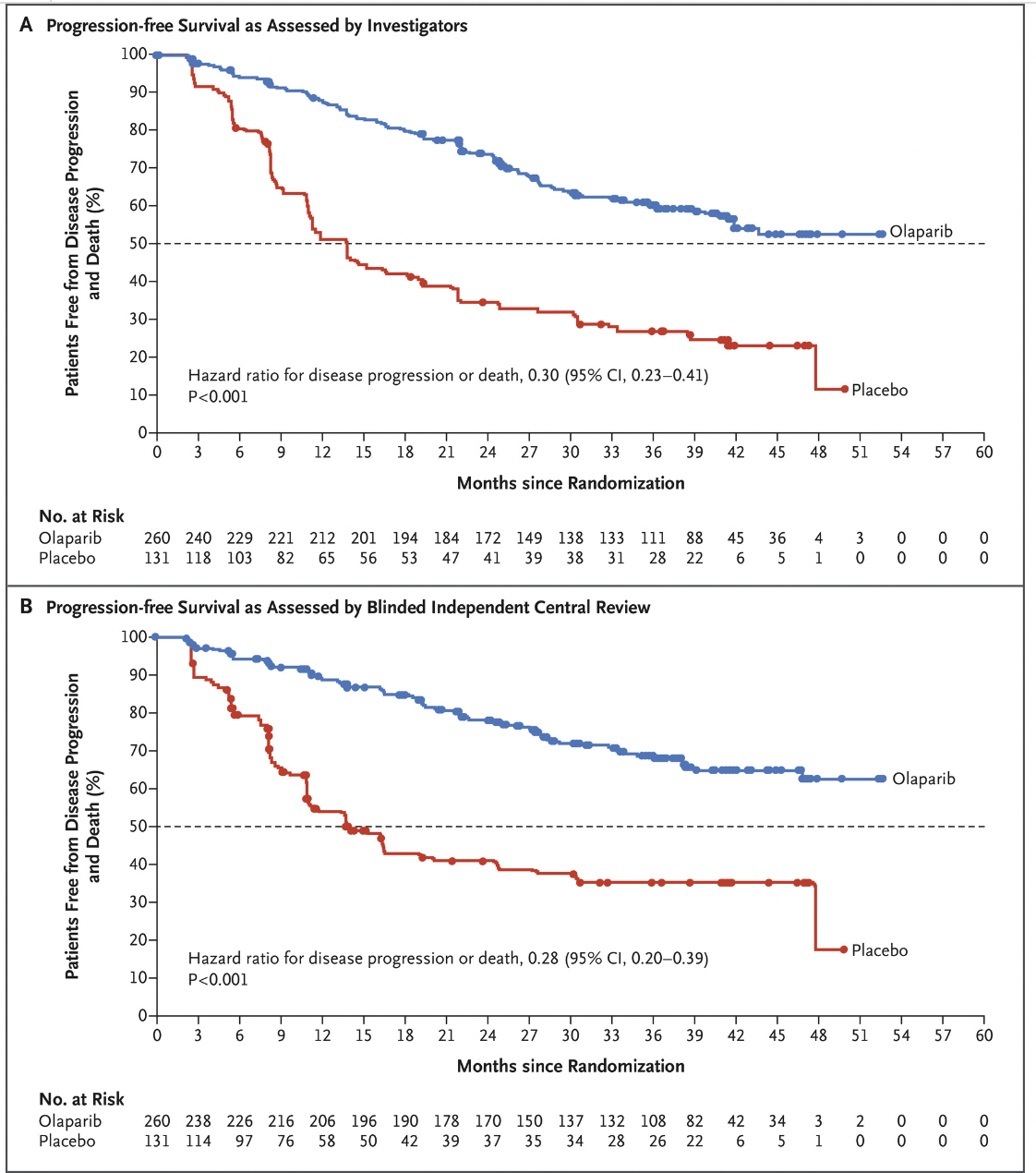
紧接着,2019 年又有三项三期临床试验结果发表。它们分别是 PRIMA、 PAOLA-1 和 VELIA 研究,这些试验考察了 BRCA1/2 突变患者以外的一线 PARP 抑制剂使用,它们分分展示了 HRD 相关亚组的临床结果。
🍺🍺试读结束🍺🍺
剩余内容是参加会员计划读者的专属内容
欢迎你通过会员计划支持我持续创作
如果你对这篇文章感兴趣,欢迎通过邮箱订阅我的 「熊言熊语」会员通讯,我将第一时间与你分享肿瘤生物医药领域最新行业研究进展和我的所思所学所想,点此链接即可进行免费订阅。