2026-05-18 12:33:19
2026-03-17 05:31:14

This is a follow-up from my previous post about AI as an economic weapon. If you haven't read it, I suggest that you do before proceeding.
I closed that post with the following, and we're going to expand on it:
The real question, however, is trust. I'm not saying that the Chinese models are dodgy. It's more of a meta question. You see, the question of trust extends to the frontier labs as well. As we enter this weird new space where businesses are being automated with AI, it essentially hands over your business's operations to another entity.
Another question on my mind is what happens to a country that lacks AI capabilities? When their businesses depend upon AI, and thus the country's economy depends upon AI, what happens if the spigot ever gets turned off through sanctions or war?
If we zoom forward a couple of years. It's now the future, and the future is undefined because no one really knows what it will look like, because it is the future, but if we play with the notion of extrapolating trends that are just starting right now, where founders, including myself, are building businesses with a mindset of autonomous software and product factories. We will soon be in a place where businesses are highly dependent upon the capabilities of AI, whether that be in access or how the models function.
This concerns me greatly, and it extends far beyond business and into society itself. You see, right now, society is already going through a Harry Potter-style sorting hat event where people are picking and choosing which tribe they belong to.
If you use any of the Frontier Lab models enough, you develop an eye for their tendencies, how they write, how they think, and how they communicate. If people are picking a single AI producer and using that AI daily in their day-to-day life to make decisions, they are outsourcing their cognitive security to someone else.
What concerns me is that, almost three or four years ago, Anthropic conducted research that allowed Frontier Labs to perform laparoscopic keyhole surgery to change how the models perform after they were made. This experiment was called Golden Gate Claude.
In this experiment, Anthropic performed surgery on the model's weight dimensions for the Golden Gate Bridge and no matter what you did when you were having a conversation with this model, the Golden Gate Bridge was always top of mind for the model.
For example, let's say that you wanted to go get some Panadol. It would give you driving instructions to a pharmacy via the Golden Gate Bridge. If you wanted to write a poem, that poem would prominently feature the Golden Gate Bridge.
Through modification of the model weights, the Golden Gate Bridge became a black hole where you could not escape from the gravity of the Golden Gate Bridge.
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet: https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
I'm surprised most people don't even know that this research exists and haven't really talked about or even written about what it could mean for society in the future.
Here's a scenario for you to chew on:
What happens when, in a couple of years, if a famous web search company, which was also a frontier AI lab, retires ads in their search product and instead offers their advertisers the ability to bid on the ability to rank higher in model weights than the competitors?
Most people would never know because they've outsourced their cognitive capability to a model.
What happens is if a famous social media network, which is also a Frontier lab, starts allowing their advertisers, to similarly bid to rank higher in the model weights, of their open source models that they're releasing for free.
Now, what happens if you extrapolate this? I don't know if this will actually happen. It's just baseless speculation, but one thing is for sure: we're entering into this world where a select few companies, these frontier labs, will have significant power over the world and how society functions, thinks and operates.
If these topics concern you, then perhaps the only true solution is that you should raise your own model, because by doing so, you gain the ability to protect your own cognitive security, business operations and supply chain.
2026-03-17 04:47:11
People often ask me how I feel about open-source models, and to be clear, I'm very supportive of them. But I can't help pondering about the following...
Open source always was and always will be a financial weapon by design. You see, one of the primary goals of open source was by releasing something as free, it removes the ability to make money from it.
Now, I'm not sure how old you are, dear reader, but if you wind the clock back far enough, you'll find traces in history that support this claim. Heck, you're probably even using Linux right now on a computer, in your house or at a server in a data centre. This was not always true. Back when this war was last raging, back in 1998, Windows was the server operating system of choice.
Linux was created to destroy Microsoft's ability to make money from Microsoft Windows. The same holds true for OpenOffice vs. Microsoft Office. It's now almost 20 years since the Halloween papers. If you're not familiar with the topic, I suggest you dig in and get up to speed with the subject matter.
In the last week of October 1998, a confidential Microsoft memorandum on Redmond's strategy against Linux and Open Source software was leaked to me by a source who shall remain nameless. I annotated this memorandum with explanation and commentary over Halloween Weekend and released it to the national press. Microsoft was forced to acknowledge its authenticity. The press rightly treated it as a major story and covered it (with varying degrees of cluefulness).
- https://en.wikipedia.org/wiki/Halloween_documents
Now you might be wondering why I'm writing about this. It's because local models are getting good. Heck, local models these days tend to be two to four months behind the leading-edge frontier labs.
Here's the thing, though: these local models are being released for free. You can just download them, or pay a minuscule fee (circa $5 USD/month) to access Frontier's open-source models from Alibaba or Z.AI.
Meanwhile, America is dumping literally trillions of dollars into research at these frontier labs. Now, I'm not calling AI a bubble because this absolutely is ROI. At this stage, I think it's impossible for anyone to say it is a bubble.
What I hope to do through this blog post is tweak some people's thinking beyond the bubble narrative. Perhaps what we're seeing is history repeating itself, but perhaps it's a little more sinister. Now, my background is not in geopolitics. I can't help but wonder if the US economy backs itself so hard into a corner funding these research labs, and if these research labs receive a bailout, what does that mean for China? Why is China releasing these models for free?
Perhaps what we're seeing here is all-out economic warfare between one nation-state and another through the weaponisation of open source because open source was, is, and always will be a financial weapon. In history, free was previously used against companies, but, if my speculation is on the mark, this is the first time it has been used at the national level by one nation against another.
I don't know what this means, and I'll leave the commentary, whether true or false, to someone with expertise in this arena but if you're aware that this is happening, then there are many ways where you can benefit from what is happening.
If you are a student or your financial budget does not allow for dropping $1,000 a month for subscriptions from all the major labs, then you can use these open-source models.
If you're a business, you should build with the mindset that local inferencing will be a thing. I suspect that in a not-so-distant future, we will have local models where society has full visibility into what goes into their training data sets, truly open-source models that are end-to-end reproducible, and I'm excited about these possibilities.
The real question, however, is trust. I'm not saying that the Chinese models are dodgy. It's more of a meta question. You see, the question of trust extends to the frontier labs as well. As we enter this weird new space where businesses are being automated with AI, it essentially hands over your business's operations to another entity.
Another question on my mind is what happens to a country that lacks AI capabilities? When their businesses depend upon AI, and thus the country's economy depends upon AI, what happens if the spigot ever gets turned off through sanctions or war?
2026-03-15 18:02:33

This one is short and sweet. if you want to port a codebase from one language to another here’s the approach:
The key theory here is usage of citations in the specifications which tease the file_read tool to study the original implementation during stage 3. Reducing stage 1 and stage 2 to specs is the precursor which transforms a code base into high level PRDs without coupling the implementation from the source language.
2026-03-13 02:55:07

Below you'll find an AI transcription of everything we riffed about.
Key distinction: Software Development vs. Software Engineering:
Future: hyper-personalized software; old models of building/scaling via scarcity are disrupted.
ps. this interview is also available:
2026-03-09 17:12:12

Hey folks, I'm currently over in SF. For the last couple of weeks, I've been cryptically tweeting about a hidden mode within something I've been building on called Latent Patterns (see below), and over the last couple of days, I've started opening up and showing people that I suspect is the (or a) future of what's to come.
An educational platform for learning AI concepts. No fluff, no filler. Just the concepts you need, explained clearly.
Latent Patterns builds Latent patterns. I've taken some of the ideas behind "The Weaving Loom" and inverted them, put them into the product itself and have perhaps accidentally created a better Lovable.
It's interesting because I see all these developer tooling companies building for the persona of developers, but to me, that persona no longer exists. You see, within latent patterns, the product (latent patterns) is now the IDE.
If I want to make a change to something, I pop on designer mode, and this allows me to develop LP in LP. I can make changes to the copy or completely change the application's functionality using the designer substrate directly from within the product, then click the launch agent to ship.
If I click Launch Agent, then it utilises Cursor's new Cloud Agents and Workflow Automations to ship it straight into production using a risk-based approach.

Instead of having a manual code review for everything, I just ship it. If something is high enough on the risk matrix, for example, a database schema migration, then it halts the shipping, and I have to do a manual review. Having said that, I'll repeat something I've said again and again over the years. You need to watch the loops. Watch the inferencing because that's where your learning is at. When I want something built, I just open up my phone and watch the output get made. I'm supervising it. I'm on the loop, not in the loop.
I think we're entering into an era of hyper-personalised software, and our industry actually works in circles. The last time we had hyper-personalised software for business was Microsoft Access, Delphi and Visual Basic. You see, back in the year 2000, every business had hyper-personalised software.
They didn't have to bend or conform to someone else's product vision on how they should operate their business. They didn't need Zapier or all these workflow automation systems stitching together SaaS. No, they had rapid application development, and these businesses had hyper-personalised software.
So I've been playing around in this designer within LP, and I've got a rough technical prototype for how I might retire most developer practices, including CI/CD.
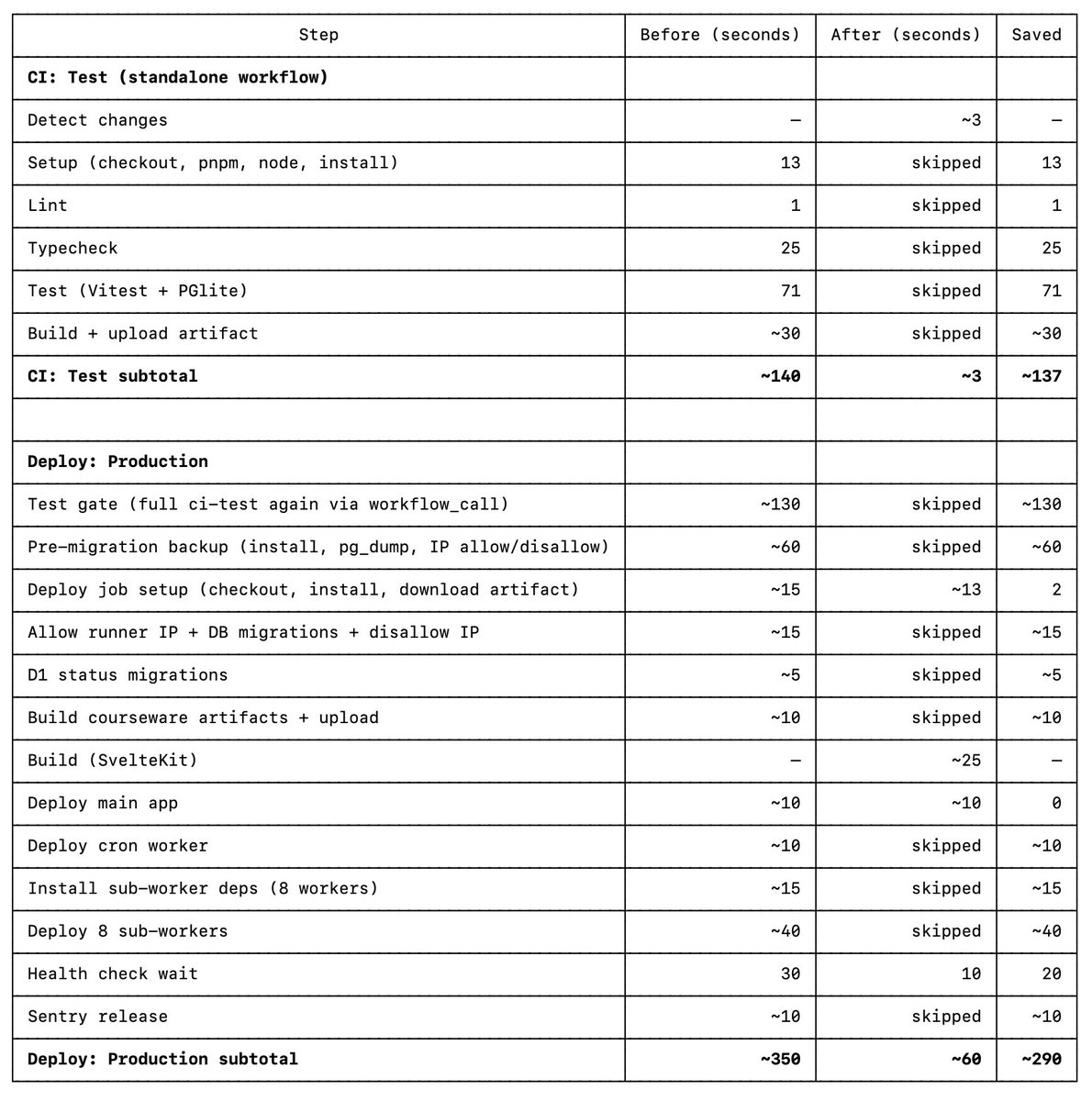
One thing that is irking me is how natural it seems for everyone to accept that we should wait until we see the outcome. This never used to be the case. Productivity with Microsoft Access back in 2000 was amazing.
Every second counts; even the 60 seconds for CI/CD deployments for LP, as it is now, is too long. So I'm starting to come to an understanding that the natural next step is to live-edit a program's memory and control flow. Sure, I could move content from the file system to the database, but we can do better. How can we kill CI/CD as it is today and instead safely live-edit the program's logic?
If you build with the mindset and awareness that inferencing speed will be near-instantaneous in the future, then it just makes sense that the logical destination is for anyone to be able to develop the product from within the product, and for the product to become the IDE itself.
All businesses need the following "widgets" / components:
So, for the last couple of weeks, I've been doing some window shopping...

So the first thing I did was model the notion of a user and add customer management functionality. Consider how long it would take in traditional software developer to build such functionality. A very simple user management database with a front end. Before AI, this would have taken weeks at most corporations. Before our industry went backwards, this used to take seconds. Back in the year 2000, it used to be seconds. This used to be just Microsoft Access tables.
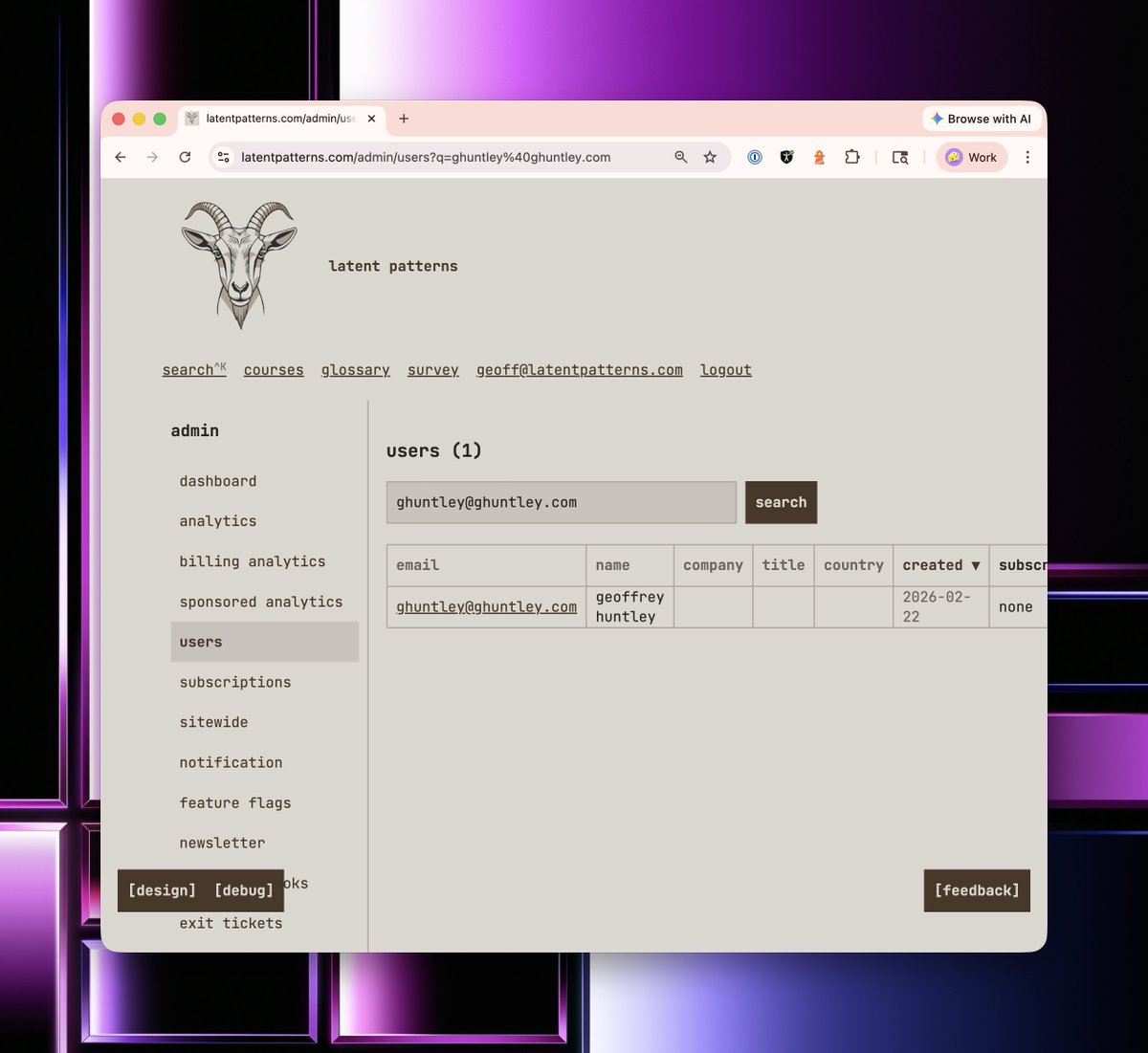
So let's pull up my own customer record and have a look at what's inside.
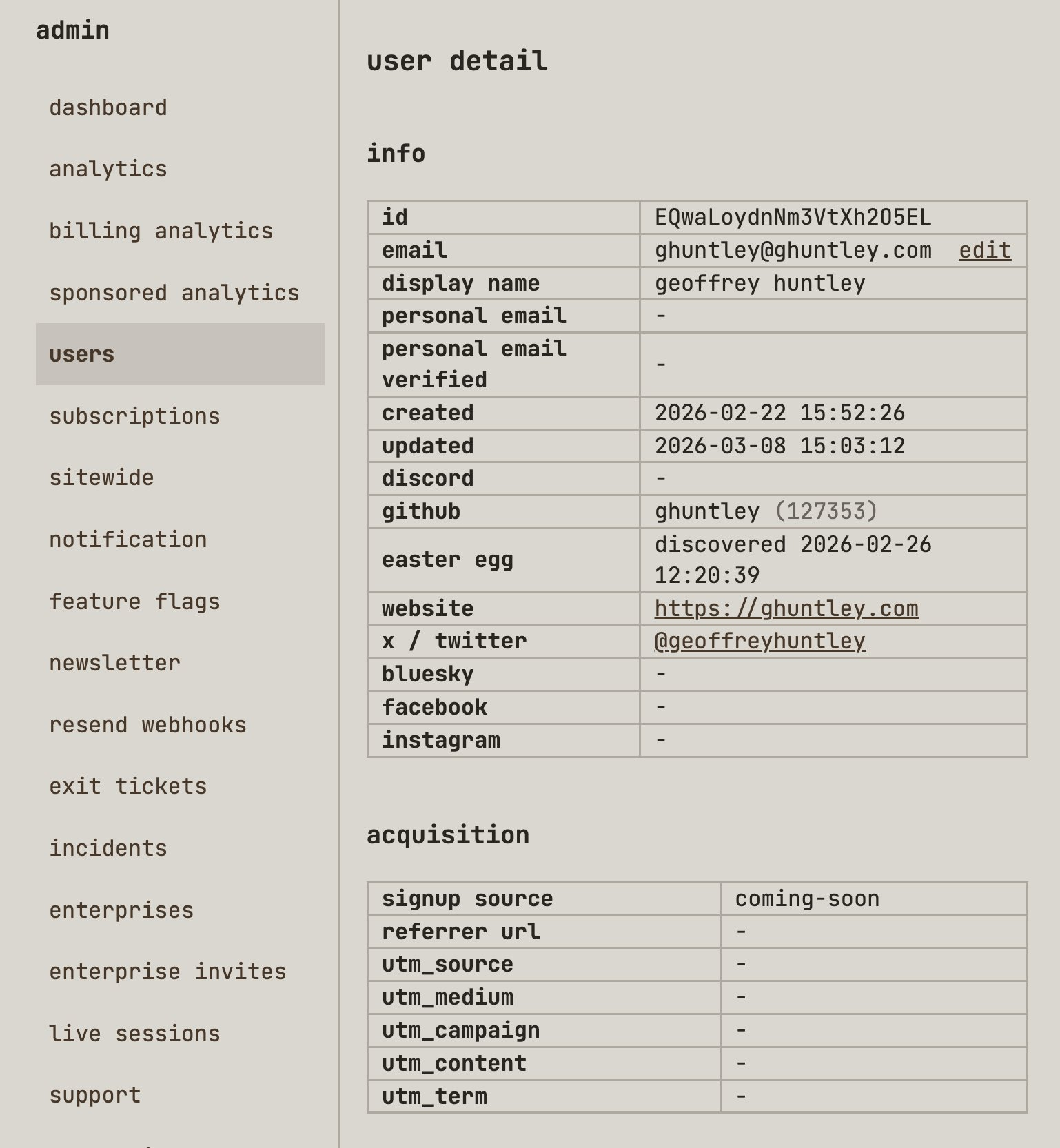
Seems pretty from vanilla, right? But do you notice the acquisition section? latentpatterns.com has first-party analytics built in and is horizontally and vertically integrated throughout the platform. To do this, I literally just ripped a fart into my coding harness and said,
"Hey, I want PostHog. Make it happen".
The 'coming-soon' UTM is my landing page. You see, LP has not launched yet. I'm building it out in the open and hitting the pavement in San Francisco, New York, and around the world to validate the business case and am doing steak-and-handshake deals to shape the product through conversations with prospective customers. Doing all the unscalable things. Instead of doing LLM outreach and sales automation that way, I'm doing it the old-fashioned way.
Once someone signs up via LinkedIn or provides information in the three fields above, they get registered as a customer within the database. That might seem quite vanilla, but it's anything but.
Through the usage of PDL, I can automatically step up who they are, where they work, any achievements they've had in life, and insights such as their likely salary or whether they have decision-making power to purchase. When you take this information and you throw it into a perplexity search, you get this...
This is baseline functionality that every business needs, and it needs to be first-party within their application. By having all this first-party data in my data tables, I can then layer agents on top of it to automatically prioritise my day via an agentic personal assistant.
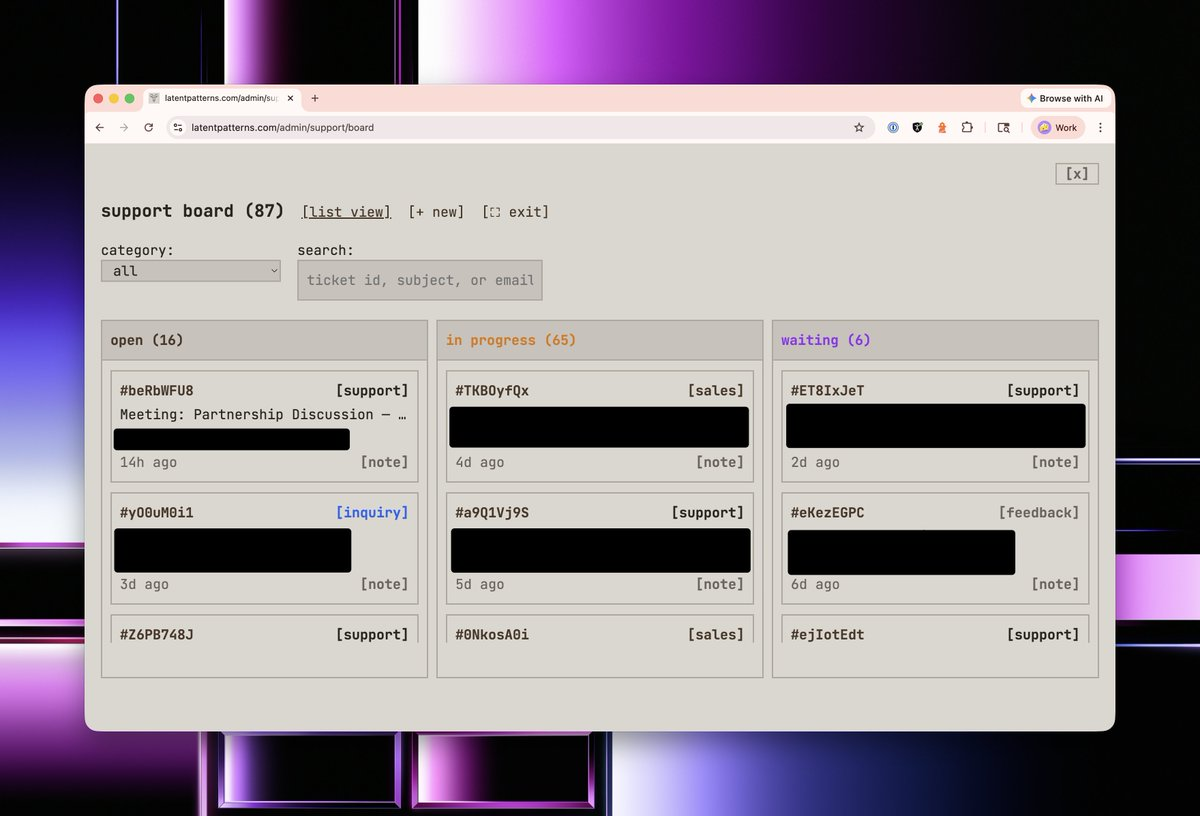
The next thing every business needs is a support desk and a customer relationship management tool. Classically, in most companies today, these are two separate things, and you have to build workflow automations to keep them in sync. No. In LP, they are a first-party thing, and they were built by ripping another fart into my coding agent, asking for
"Hey, I want PipeDrive, Trello, and ZenDesk"
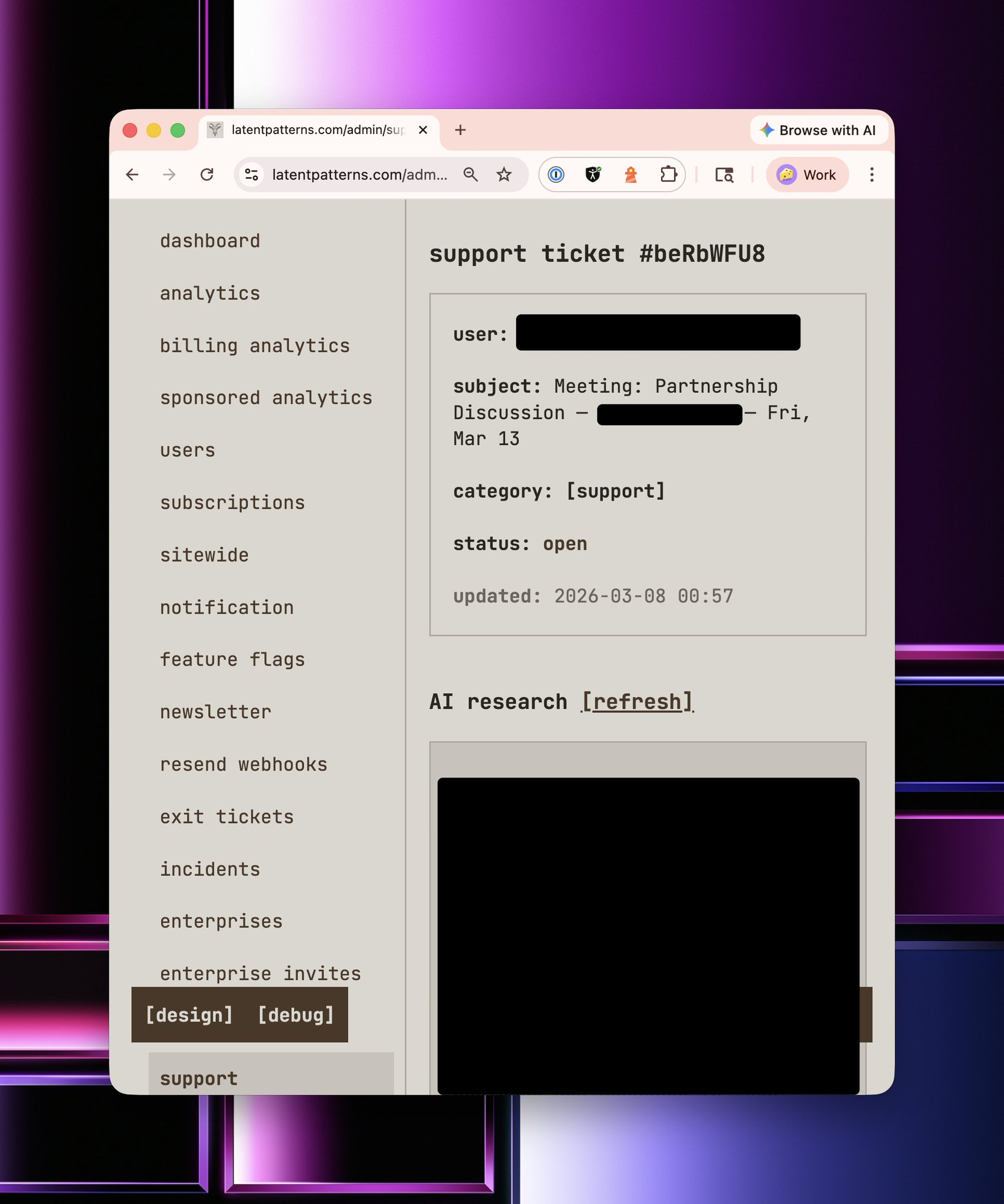
On top of every customer interaction, the analysis is top and centre. It is deliberately there because it forces me to read this information again before I interact with the customer. This information is automatically refreshed by a background job every night.
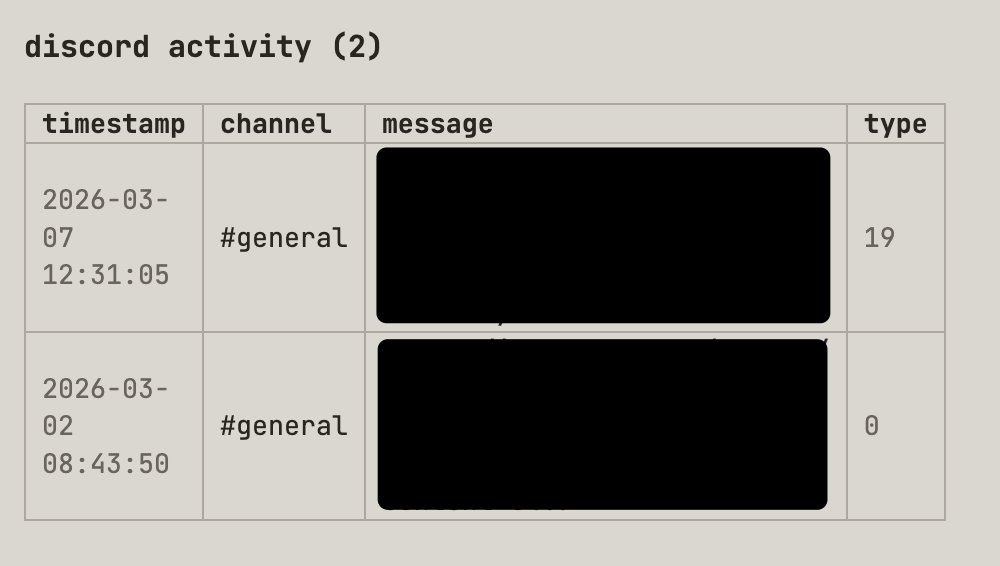
Underneath this summary, for similar reasons, is also another summary of all the activity this person has done if they're in my Discord community (below)
Then, finally, before I even get to the support desk ticket, I have to scroll past and review all the meetings I've had with the person. You see, beans, beans, the magical fruits, the more you eat, the more you toot. So ripped another fart into my coding harness, and I asked it to clone Calendly...
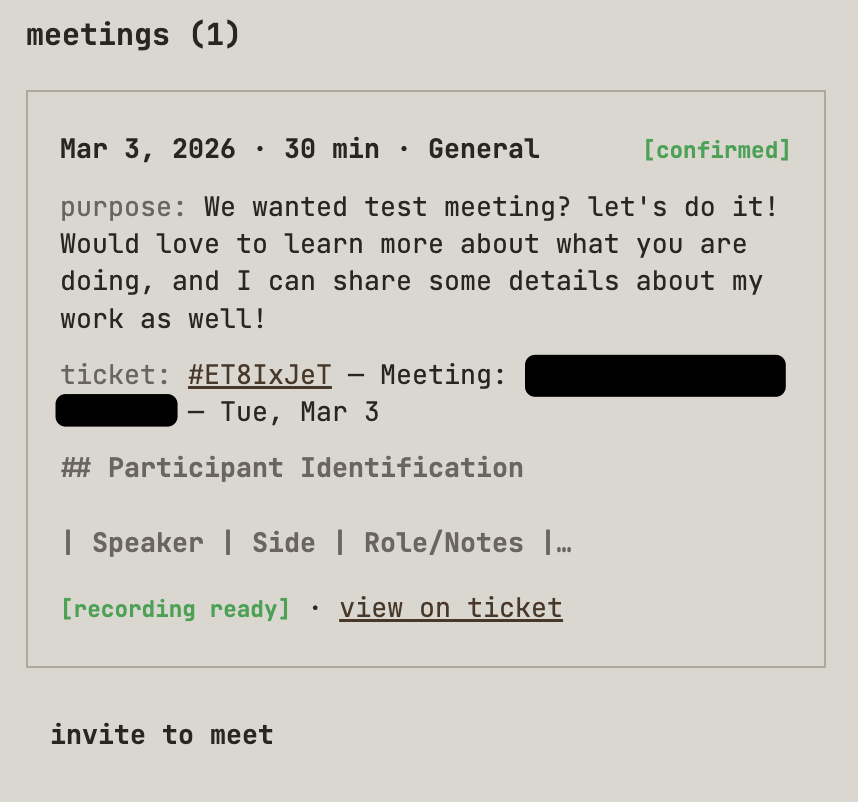
Throughout the website, various marketing funnels generate support desk tickets and offer the option to meet with me.
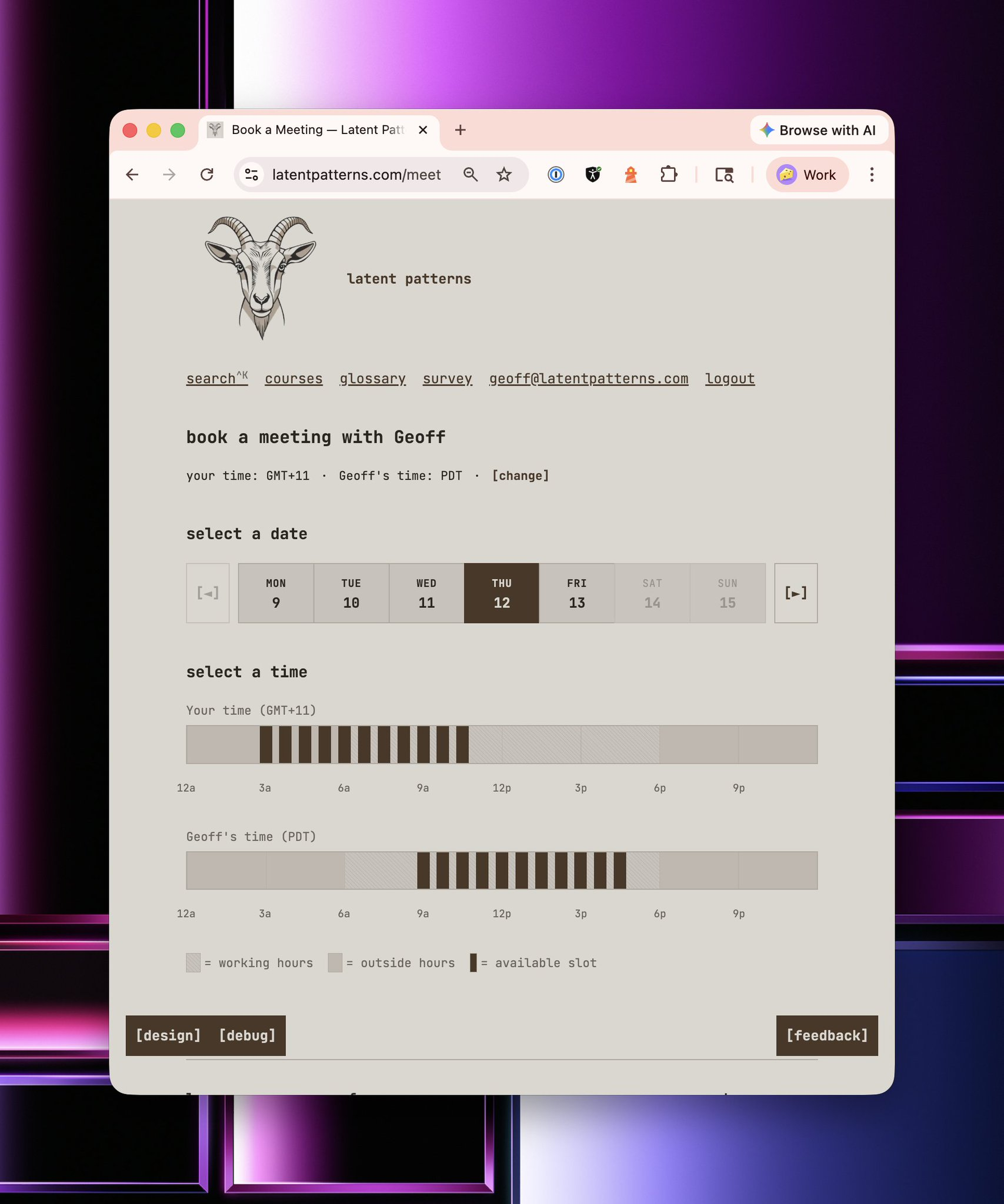
The calendar integration does exactly what you think it does, but with some twists. You see, the beans just keep on producing brain farts, so I prompted my way to victory and made my very own meeting transcription bot that automatically joins these meetings and asks for consent to take notes and record the meeting.
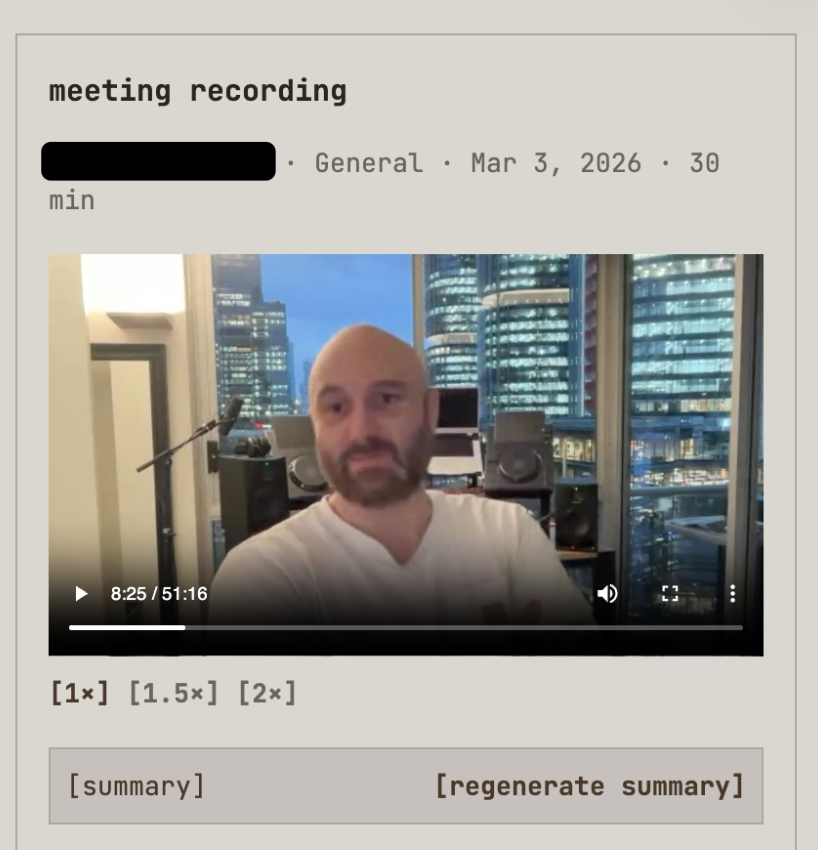
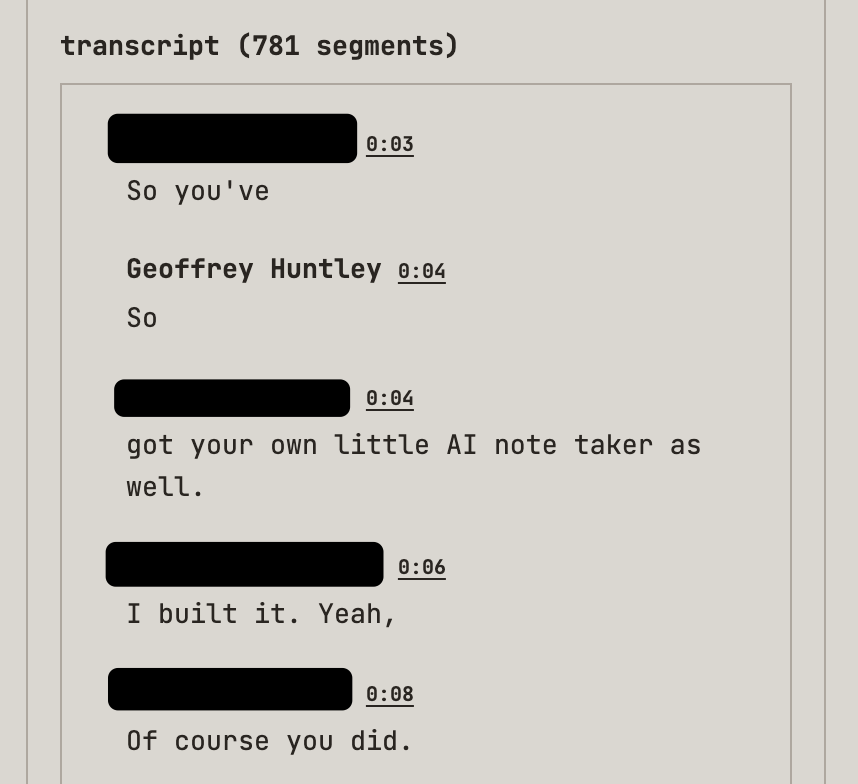
At the end of the meeting, I rip an agent over the transcription and apply sales automation using a mixture of Challenger-based sales and SPIN Selling as a series of LLM prompts. You see, in a previous life, I was also a sales engineer. Items captured include:
From there, it's just not so easy, but it's a skill that you can learn. Shut up and become curious. When someone says something, just ask why they said it.
All you need to do is get folks talking, and the more they share about their needs and pain points, the more information the LLM prompts can process. The more data you can gather, the more effective the follow-up meetings, especially if it's an initial meeting. And with that data, you can then rip an agent over the top of it to do more business automation.
Thanks for reading, folks. I hope you enjoyed this sneak preview. I'm going all in and building an educational platform. I'm living, breathing, and teaching what it means to be a model-first company. I'm building with recursive latent space, teaching it from my experiences as a one-man company.
just in case you missed my previous article about the unhinged things that you can now do as a model first company and why AI adoption will be a problem for corporates.
why I think now is the perfect time to build.
Latent Patterns is an educational platform for learning AI concepts. No fluff, no filler. Just the concepts you need, explained clearly.
I will be launching shortly. If you want to know when I launch, leave your digits here, or if you're a company interested in discussing employee education, fill in this form.
I'll be in SF for Daytona's event tomorrow and hanging around until Wednesday night, and then heading to New York. I'll be in New York for a week, then I'm heading to Auckland, Lithuania, Estonia, Sydney, Miami, Washington, DC, back to SF, then onwards to Singapore, Melbourne, Copenhagen, and Croatia. It's about 95 days of back-to-back travel. Cya ya'll all soon? ❤️
ps..
Check this out. These are the principles guiding me as I build Latent Patterns. An educational platform for AI.
pps. socials: