2026-06-28 21:00:00
I keep my recipies on my website, and like most of my website it grew over time instead of being designed. A couple years ago I added some progressive enhancement that puts checkboxes on the ingredients, and today I added a rescaler:
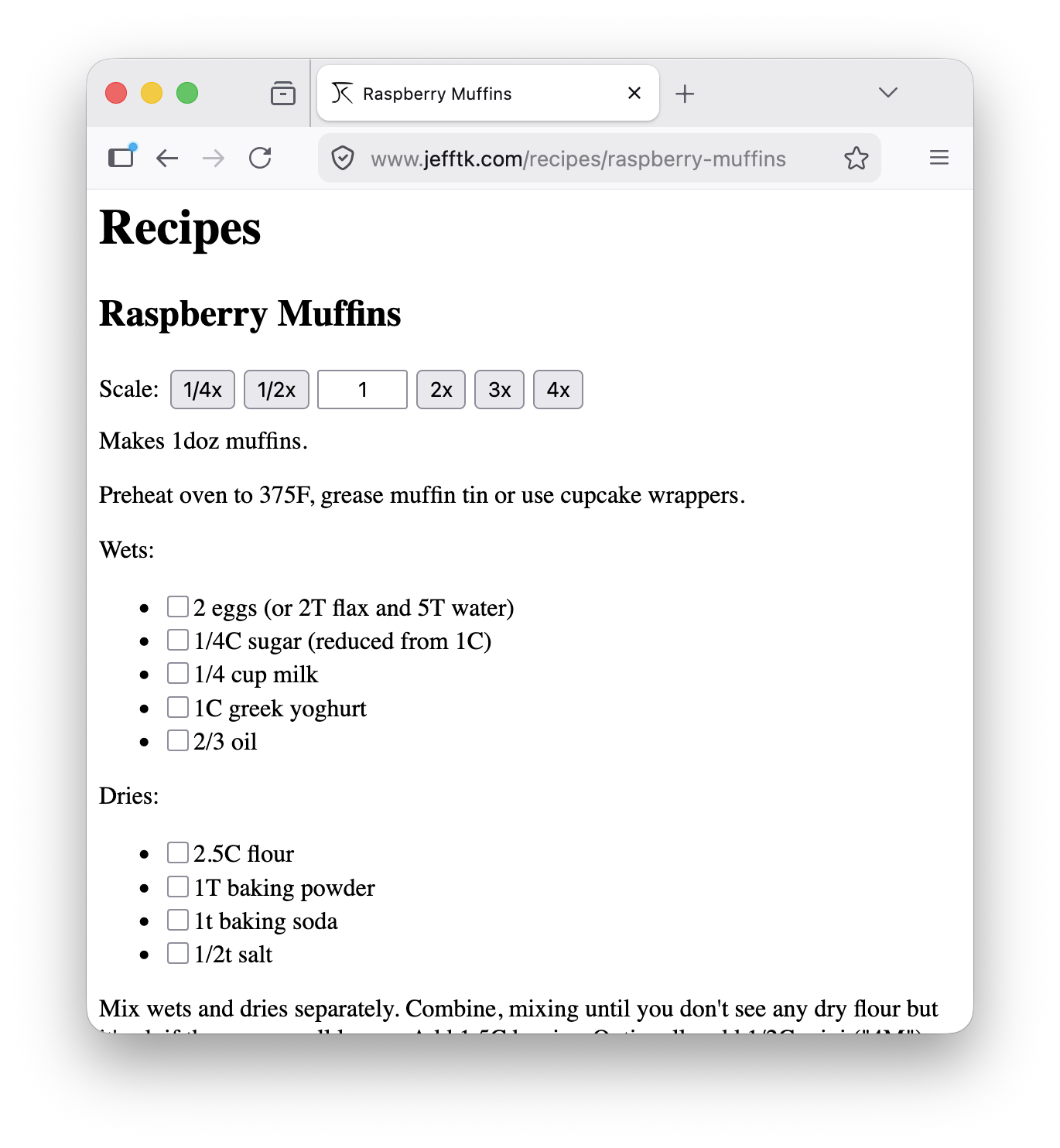
Here's tripling it:
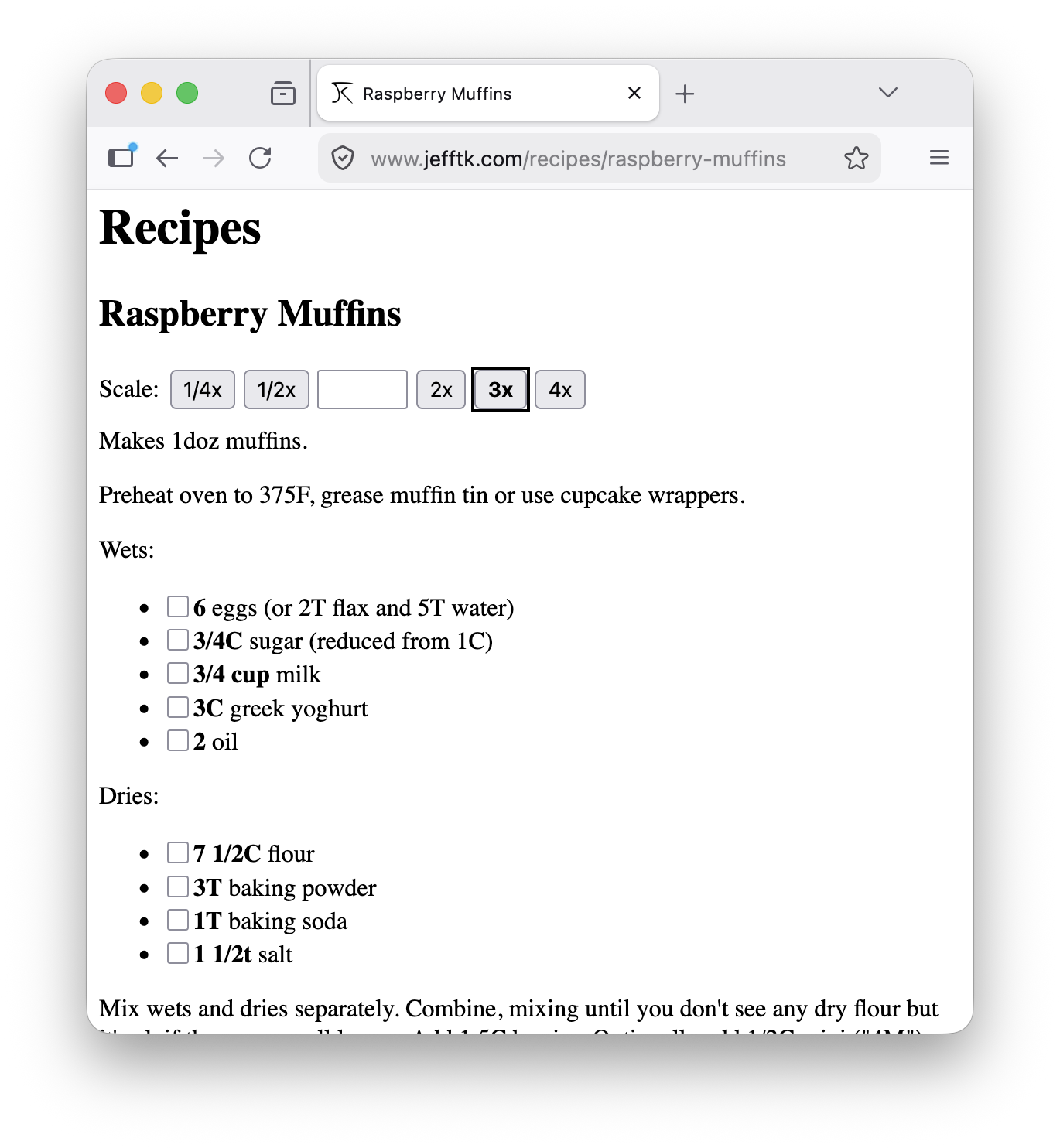
This is another project, like adding transposition to my solstice songbook, where I wouldn't have put in the time if I couldn't delegate to an LLM. It went very quickly, and the code seems reasonable.
Implementation notes:
As you go up and down it converts teaspoons to tablespoons to cups. Yes, I still cook volumetrically.
It handles numeric ranges, like "3-4 cups".
It handles fractions: half of 1 1/4 C is 5/8 C.
It doesn't handle everything. I wanted something simple and reviewable that handles most cases, instead of trying to make something exaustive (that would then have weird bugs). This means with complex items like "2 eggs (or 2T flax and 5T water)" only the "2 eggs" is scaled. To make these failures graceful, all scaled values are bolded, so unscaled values stick out visually.
2026-06-25 21:00:00
Our family is on vacation in North Carolina for a week, spending some time at a pool, and they're playing a (weirdly short) loop of music. Listening to She's In Love With The Boy for the fourth time I was thinking about how it's an example of a common pattern in country music: a repeating motif, recolored by the verses. In this case it's a father saying a boy isn't good enough for his daughter (verses 1 and 2) until his wife reminds him that her own father said the same thing about him (verse 3).
Some others with variations on this pattern:
Don't Take the Girl: fishing at 8yo, mugged at 18yo, potential maternal mortality at 23yo; three senses of "don't take".
Are You Gonna Kiss Me or Not: at the first kiss and then proposal the boy is shy; at their wedding he reverses it.
Five More Minutes: playing by the creek, saying good night to a girl, playing on the football team for the last time, then (big mood switch) grandpa's hospital bed; each iteration wanting a little more time.
Skin (Sarabeth): teenage girl undergoing chemo dreams of dancing with her love, wind in her hair; last chorus her hair has fallen out, her boyfriend shaved in solidarity, and they're dancing together.
Cleaning This Gun (Come On In Boy): as a teen he got a lecture from his girlfriend's dad with an implicit threat; as an adult he gives the same lecture to his daughter's boyfriend.
This pattern is definitely not limited to country (ex: Cat's in the Cradle, where he doesn't have time for his kid and then once grown up his kid doesn't have time for him). But it does seem unusually common in this genre.
2026-06-24 21:00:00
I've been thinking more about disaster preparedness recently, and an important piece of that is food. And for many foods, before you can eat them you need to cook them. For example, a large fraction of the calories in our house are dry rice and pasta. These have ungelatinized starch, where the nutrition is bound up very tightly in starch granules. We mostly can't digest these as-is, but heat and water gelatinize the starch and make it bioavailable. [1]
This means you need some way to heat things up. If the power grid is working then you have lots of options, including immersion heaters and boiling water with a kettle, but in many disasters this is not an option. What else can you do?
Various options with fuel and batteries are possible, but a solar oven is hard to beat. Most would have what they'd need to put one together from tinfoil, cling wrap, tape, and cardboard. It would be worth putting some effort into identifying the best DIY-from-on-hand designs and distributing them. A simple one probably can't get water to the boil, but luckily you don't need that for starch: 180F is enough, and even 160F gets your pasta about halfway bioavailable. You do want to pre-soak, though: as starch gels it becomes less permeable to water, and without stirring or boil to disturb the surface gelling it may not fully hydrate.
The main limitation of a solar oven is, of course, lack of sun. When I look at a place like Boston, though, you should be able to cook a pot of pasta on ~60% of days (~30% in the winter). If you have a mix of foods, including starches that can be eaten without heating, like crackers, cereal, and ramen, you can probably just eat those when there's not enough sun for the cooker. Alternatively a propane stove does pretty well: if you pre-soak, bring to the boil, turn the stove off, and move to an insulated container, you should be able to cook several hundred pounds of pasta with a standard 20lb propane tank.
[1] Now, our stomach isn't the only way to get nutrition out of food:
it can also be fermented in our guts. The best case is that you grind
it and soak it well before eating. The gut bacteria would need time
to adapt to the challenge (replicating to handle the newly abundant
food) and while they're adapting it wouldn't be easy gastricly. You'd
want to ramp up to this, using it to stretch more bioavailable food so
it would last longer while giving our intestines the time to
adjust. Then the caloric content is also lower: half to the bacteria
doing the fermenting (or lost as uncomfortable gas) and half to you in
now-digestible form.
On the uncomfortable gas, it looks like it should be worst initially, and then go down as bacteria propagate that can consume the gas. Whether the gas level (and other gastric symptoms) is tolerable is probably a good gauge for whether the ramp is too steep. It won't drop to nothing, though, and how well it works depends in part on your gut microbiome: if you don't have the appropriate bacteria initially it may never adjust well.
Overall, this really doesn't sound like a good time. Then add in that there's some risk of food poisoning from raw grains that are expected to be boiled before eating, and it seems best to find another way.
2026-06-21 21:00:00
A contra dance organizer in another city wrote to me a while ago because they were stuck: the dance was in a few days and they didn't have anyone to run sound. They were asking if they could use some of my recorded music for the dance. Here's a lightly edited and linkified copy of what I sent them:
This is a tricky situation, and I'm sorry you've ended up here. This is probably not what you want to hear, but I would not hold a dance with recorded music. Instead I'd:
Have musicians play acoustically and accept that it won't be as loud as you'd like. Until a hundred years ago this was the default. [EDIT: This could be an opportunity to gather a giant open band!]
Get a crash course in running sound. While it's a complex job in its entirety, if you're just trying to make a few instruments and a caller a bit louder there are simple options that are not difficult. Depending on what equipment is available you can plug a microphone right into a speaker, and just turn it up or down until it sounds right. If you wanted to do a virtual training session I could do 9pm tonight or tomorrow night.
Reschedule the dance. If you're worried about losing money I could chip in a bit.
All of these have downsides, some of them big, but overall I think it's very important that contra dance goes to live music.
As a practical matter, if you do use recorded music make sure you listen through it while tracking sections to make sure it's square. I'm pretty sure there's at least one track on the Kingfisher album where we edited it in a way that means it won't work for dancing, and same goes for the Free Raisins album.
2026-06-20 21:00:00
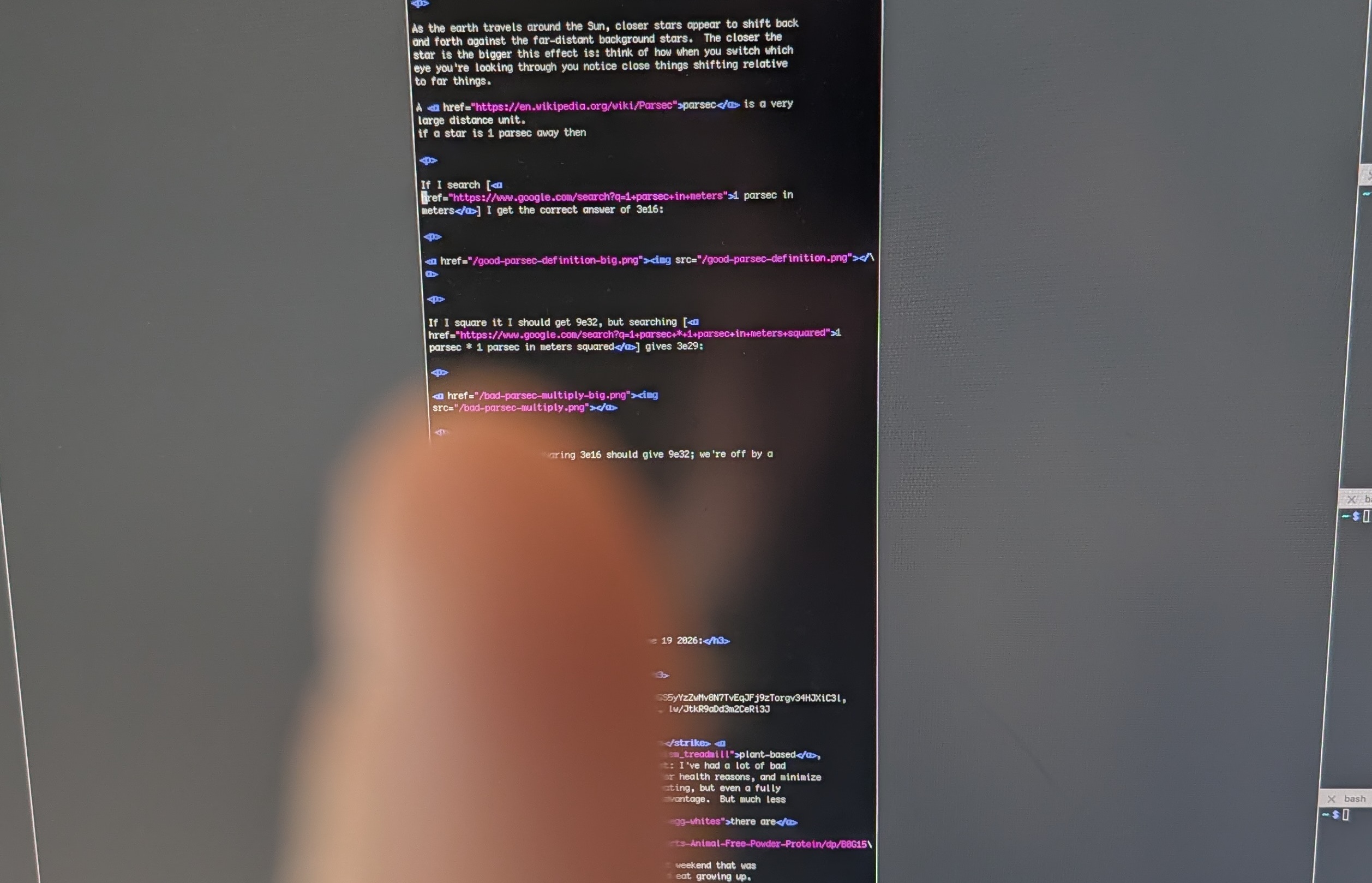
Daniel Drucker pointed me at a fun bug in Google's calculator: the parsec is wrong when you do math on it.
As the earth travels around the sun, closer stars appear to shift back and forth against the distant background stars. The closer the star is the bigger this effect is. Think of how when you switch which eye you're looking through you notice near things shifting relative to farther ones. For example, holding up my finger I see this out of my right eye:
But this out of my left eye:

If a star moves by two arcseconds (each 1 / 3600th of a degree) as the earth goes halfway around the sun (two "astronomical units" apart) we say the star is 1 parsec away.
This defines a triangle where two of the sides are far larger than the third, which means as long as we measure our angle in radians we can use the small-angle approximation and say a parsec is one AU per arcsecond.
If I search [1 parsec in meters] I get the correct answer of 3e16 meters:
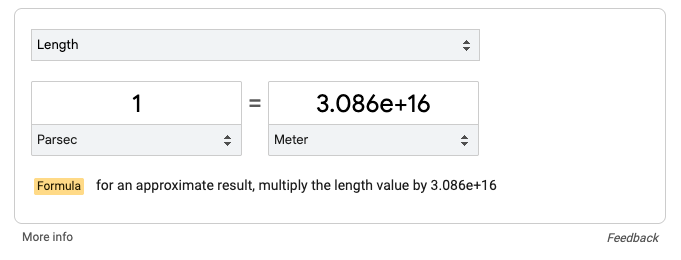 The interactive unit converter seems to be always right, but if we do
any math with it, even multiplying
it by one, we trigger a different flow that uses an incorrect
value of 5e14 meters:
The interactive unit converter seems to be always right, but if we do
any math with it, even multiplying
it by one, we trigger a different flow that uses an incorrect
value of 5e14 meters:

This is off by a factor of 57.3, a very suspicious number! It's the number of degrees in a radian (180 / PI). This is what you'd get if you took the definition of a parsec, 1 AU per arcsecond, but used arcsecond in degrees instead of radians.
For example, here's 1 au / 1 arcsecond in meters giving 5e14:

But then if I ask for it in parsecs it gives 1 parsec:
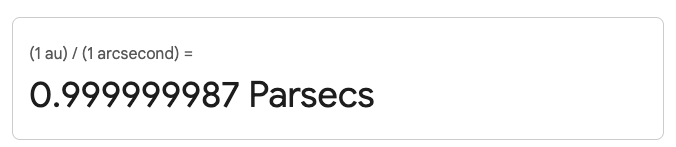
You could make a case for either of these, but not both at once! Similarly, [1 meter / 1 degree] gives "1 meter":

But so does [1 meter / 1 radian]:

I think the bug here is probably in some kind of clever context-dependent interpretation of angles, where they try to use either degrees or radians as appropriate. Or maybe it's confused because degrees and radians are dimensionless units? Regardless, "parsec" is expanding to "AU / arcsecond-in-degrees" and is off by a factor of 57.
This is not a unit of distance that is likely to come up in my daily life, but I hope no astronomers got bitten by this!
2026-06-19 21:00:00
If someone tells me a cake is
vegan
plant-based,
I'm going to downgrade my expected enjoyment: I've had a lot of bad
vegan baked goods. Some bakers are vegan for health reasons, and minimize
all the other things that make food worth eating, but even a fully
hedonistic vegan baker is at a serious disadvantage. But much less
now that
there are
precision-fermented
egg whites! I made an eggless cake last weekend that was
indistinguishable from the summer cakes we'd eat growing up.
Julia and I host a monthly effective altruism dinner. Since many EAs are vegan, we try to have good vegan options. Julia let me cook this time, and I adapted one of my favorite family recipes into a vegan apricot berry cake.
This dessert is all about the fruit, and while quality helps the thing you really need is quantity: it's about 3/4 cup of raw fruit per person and we were expecting a crowd. The best place in Boston for produce in quantity is Haymarket, and my kids love to go there because it's right next to a playground with a very fast (and TikTok-famous) slide. We played there for a while and then bought a lot of fruit:
I paid $8 for 4.5lb of very good blackberries, $1 for 1lb of raspberries (some were moldy, which I knew when I was getting them) and another $8 for about 6lb of very large (but russeted) apricots. We ate a lot fresh, picked out the bad raspberries, and filled each pan about 1" deep with chopped fruit:

I poured the batter over, baked for about 50min at 375F, and took them out when the top was golden brown and they were 200F internally:

I'd tried other egg substitutes and not been happy, but the texture here was just right, and I really think I wouldn't have known:

Several people asked me for the recipe: peach cake.
(Our family calls it peach cake regardless of the fruit content, but I avoided that here as a nod to legibility.)