2026-06-28 14:32:55
![]()
RE-CS-02,配置 1G+128G。| 项目 | 记录 |
|---|---|
| 商品名 | 京东云无线宝 AX6600 雅典娜 |
| 英文/社区名 | JDCloud AX6600 Athena |
| 设备型号 | RE-CS-02 |
| 本机版本 | 1G RAM + 128G eMMC |
| 设备类型 | Wi-Fi 6 路由器 |
| OpenWrt target | qualcommax/ipq60xx |
| OpenWrt device id | jdcloud_re-cs-02 |
| 当前 OpenWrt 支持状态 | 官方 Techdata 记录为 snapshot,正式 release 支持情况刷机前再查 |
| Bootloader | U-Boot |
| 电源 | 12V/3A 圆口电源 |
| 项目 | 参数 |
|---|---|
| SoC | Qualcomm IPQ6010 |
| CPU | 4 核 A53,1.8GHz |
| RAM | 1024MB |
| 存储 | eMMC,本机为 128GB |
| 交换芯片 | Qualcomm Atheros QCA8075 |
| 2.5G PHY | Qualcomm QCA8081 |
| 网口 | 4 个千兆口 + 1 个 2.5G 口 |
| VLAN | 支持 |
| 无线芯片 | Qualcomm QCN5022 / QCN5052 / QCN9024 |
| 2.4GHz | b/g/n/ax,2x2 MIMO |
| 5GHz | a/n/ac/ax,一组 4x4 MIMO,一组 2x2 MIMO |
| USB | 1 个 USB 3.0 |
| LED / 按键 | 3 个 LED,3 个按键 |
1.5.50.r2204, 0251ebd85+r49254。192.168.68.1。cat /proc/cpuinfo、lsblk、ip link 的实际输出。/tmp 是内存盘,上传大文件和备份分区时注意空间。这一步参考 JDCloud AX6600(雅典娜) 刷机记录 的流程,目标是在原厂系统里启动 dropbear,先拿到 root shell。
jdcloudwifi.com,进入京东云无线宝后台,注册并登录。192.168.68.1,后续命令都按这个地址写;如果实际后台 IP 不同,以浏览器地址栏为准。登录后台后,按 F12 打开浏览器开发者工具,在 Application / 应用 里找到当前后台地址对应的 Cookies,复制 sessionid 的值。
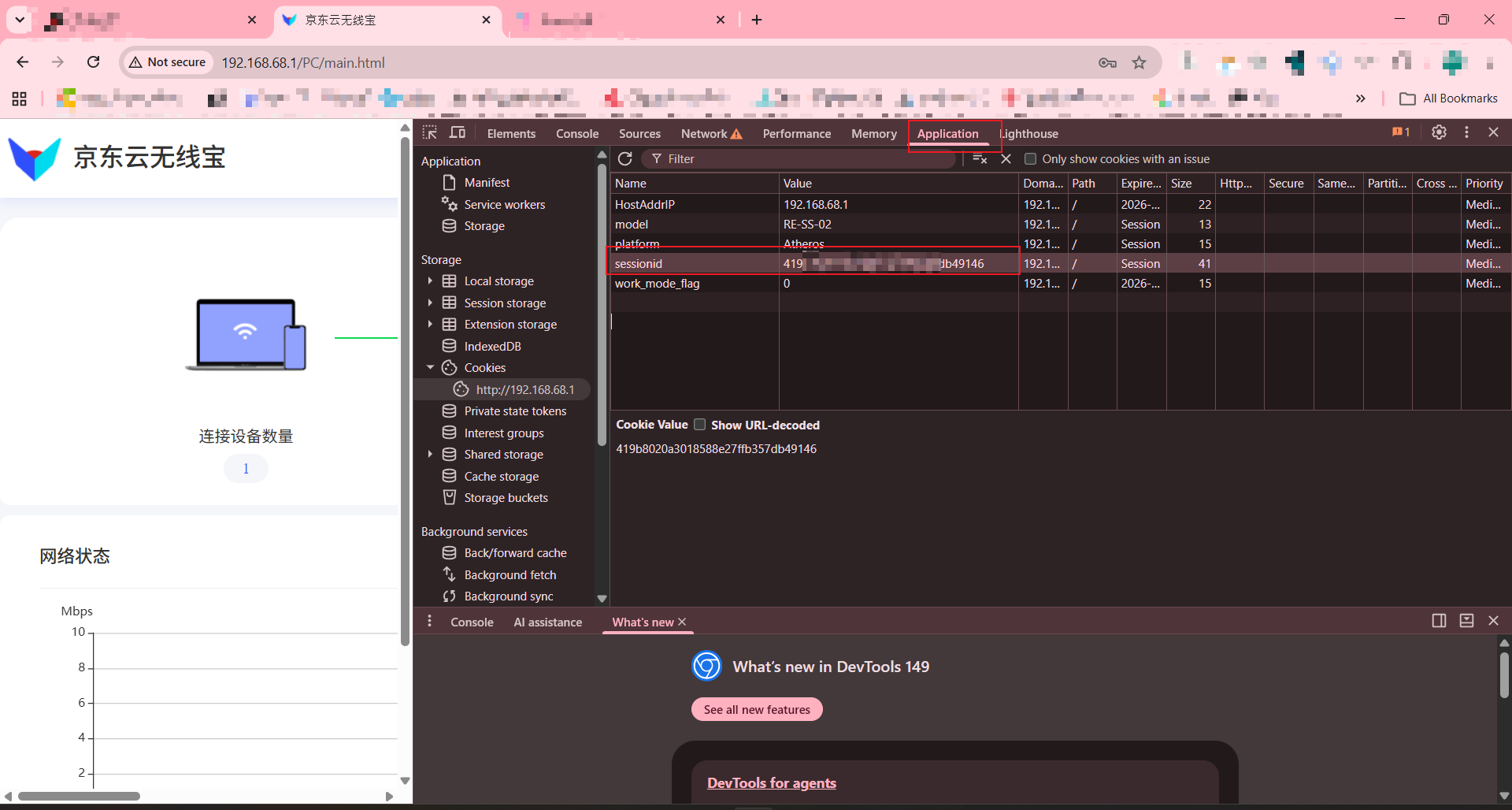
把 sessionid 填入本地脚本 open-ssh.py:
|
|
脚本核心是通过 /jdcapi 调用 uci,把 dhcp.odhcpd.leasetrigger 设置为 /usr/sbin/dropbear,再提交 dhcp 配置:
|
|
运行脚本:
|
|
正常情况下应该返回两次成功结果,关键是里面有两个 0。这时配置已经写入,但还需要触发一次 IPv6 相关流程让 dropbear 启动。
进入后台的 路由设置 -> 上网设置,找到 IPV6网络设置:
上网方式 选择 NAT6。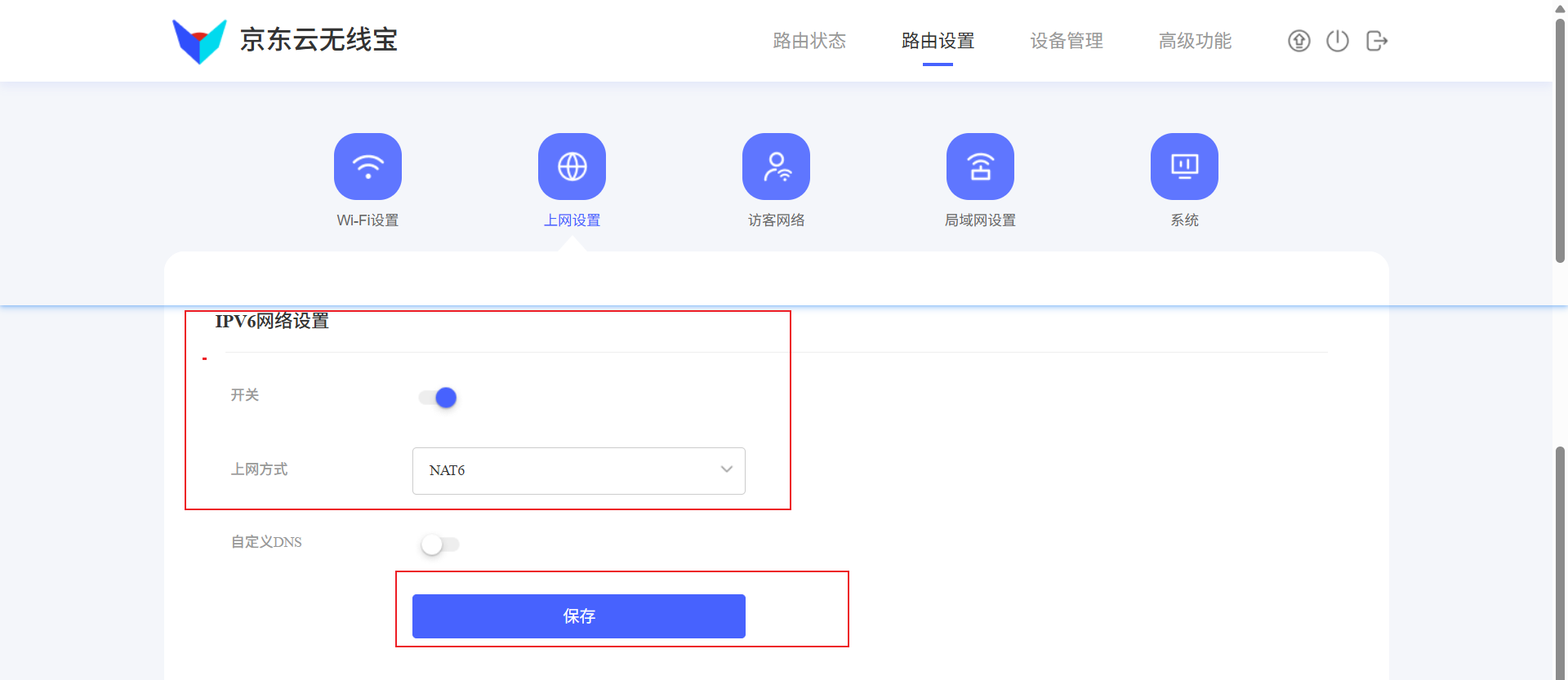
保存后路由器会重启。重启过程中电脑可能自动切到其他 Wi-Fi,导致后续连不上雅典娜;等路由器起来后,重新连接雅典娜 Wi-Fi。
随后在电脑命令行尝试 SSH:
|
|
密码和京东云无线宝管理后台密码相同。
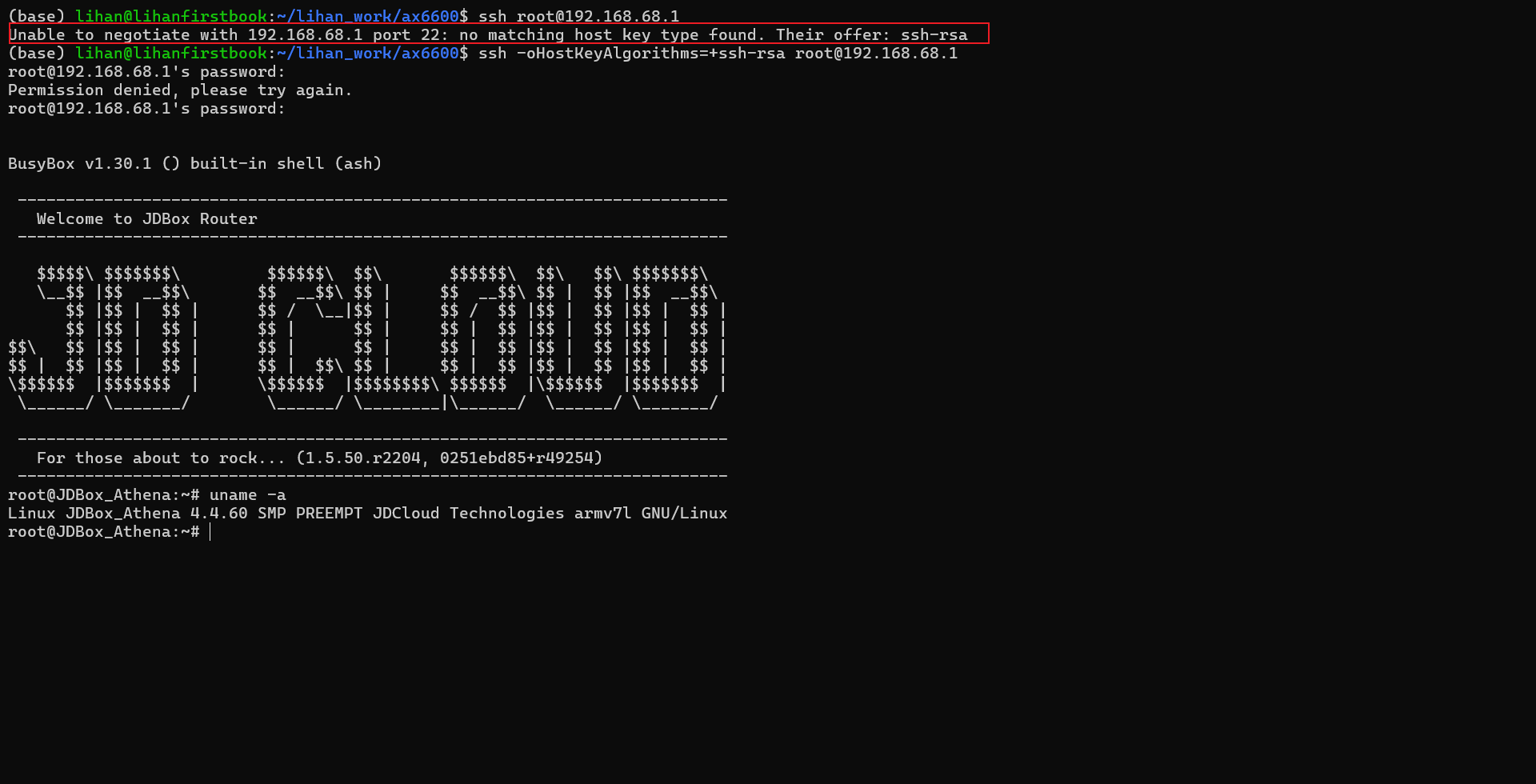
如果本机 SSH 客户端比较新,可能会遇到:
|
|
这是因为原厂系统的 SSH 服务端只提供了旧的 ssh-rsa host key。临时兼容可以加参数:
|
|
成功后会进入 JDBox Router 的 BusyBox shell。本机进入后显示原厂系统版本为 1.5.50.r2204,uname -a 显示内核为 Linux JDBox_Athena 4.4.60 ... armv7l GNU/Linux。
进入 SSH 后先检查系统版本和 eMMC 分区布局。
|
|
本机原厂系统信息:
|
|
blkid 显示整盘是 eMMC GPT:
|
|
关键分区如下:
| 分区 | PARTLABEL | 大小 | 作用 |
|---|---|---|---|
/dev/mmcblk0p1 |
0:SBL1 |
768 KiB | 早期启动链 |
/dev/mmcblk0p2 |
0:BOOTCONFIG |
256 KiB | 启动配置 |
/dev/mmcblk0p3 |
0:BOOTCONFIG1 |
256 KiB | 启动配置备份 |
/dev/mmcblk0p4 |
0:QSEE |
1792 KiB | Qualcomm secure environment |
/dev/mmcblk0p5 |
0:QSEE_1 |
1792 KiB |
QSEE 备份 |
/dev/mmcblk0p10 |
0:CDT |
256 KiB | hardware config / device tree 相关配置 |
/dev/mmcblk0p11 |
0:CDT_1 |
256 KiB |
CDT 备份 |
/dev/mmcblk0p12 |
0:APPSBLENV |
256 KiB | U-Boot 环境变量 |
/dev/mmcblk0p13 |
0:APPSBL |
640 KiB | U-Boot 主分区 |
/dev/mmcblk0p14 |
0:APPSBL_1 |
640 KiB | U-Boot 备份分区 |
/dev/mmcblk0p15 |
0:ART |
512 KiB | 无线校准 / MAC 等设备校准数据,必须备份 |
/dev/mmcblk0p16 |
0:HLOS |
6144 KiB | kernel slot |
/dev/mmcblk0p17 |
0:HLOS_1 |
6144 KiB | kernel backup slot |
/dev/mmcblk0p18 |
rootfs |
61440 KiB | 原厂 rootfs |
/dev/mmcblk0p19 |
0:WIFIFW |
4096 KiB | Wi-Fi firmware |
/dev/mmcblk0p20 |
rootfs_1 |
61440 KiB | 备用 rootfs |
/dev/mmcblk0p21 |
0:WIFIFW_1 |
4096 KiB | 备用 Wi-Fi firmware |
/dev/mmcblk0p22 |
rootfs_data |
20480 KiB | overlay |
/dev/mmcblk0p23 |
0:ETHPHYFW |
512 KiB | Ethernet PHY firmware |
/dev/mmcblk0p24 |
plugin |
89344 KiB | 原厂插件区 |
/dev/mmcblk0p25 |
log |
1048576 KiB | 日志区 |
/dev/mmcblk0p26 |
swap |
524288 KiB | swap |
/dev/mmcblk0p27 |
storage |
118996958 KiB | 大容量存储区 |
/dev/disk/by-partlabel 在原厂系统里没有输出,所以后续不要照抄依赖 PARTLABEL symlink 的命令;如果要按标签定位,需要用 blkid 或固定分区号反查。
当前挂载情况:
|
|
/tmp 只有约 410 MiB 可用,但 /mnt/mmcblk0p27 有约 110 GiB 可用。备份可先写到 /mnt/mmcblk0p27/backup-ax6600-athena/,再用 scp 拉回电脑保存。刷写分区表或完整镜像前,不能只把备份留在路由器本机。
下载参考帖提供的 U-Boot:
|
|
本地先校验文件。本文这次下载到的文件信息:
|
|
上传到路由器 /root/。原厂系统的 SSH 比较老,新版 scp 直接传会遇到两个问题:
no matching host key type found. Their offer: ssh-rsaash: /usr/libexec/sftp-server: not found第一个问题需要允许 ssh-rsa,第二个问题是新版 scp 默认走 SFTP,而原厂系统没有 sftp-server。因此要加 -O 强制使用旧版 SCP 协议:
|
|

进入路由器后再次检查文件完整性:
|
|
确认大小和 hash 无误后刷入 U-Boot。此步骤需要谨慎,刷错可能导致路由器无法启动;如果文件不完整也可能导致路由器无法启动。
|
|
返回写入记录即为成功:

刷完 U-Boot 后拔掉电源下电。
找个牙签顶住 reset 按键,再插上电源。路由器启动时会从红灯闪烁变成持续蓝灯,等出现稳定不变的蓝灯后松开 reset。
用网线连接电脑和雅典娜路由器,最好接 LAN 口。电脑网卡手动配置 IPv4:
|
|
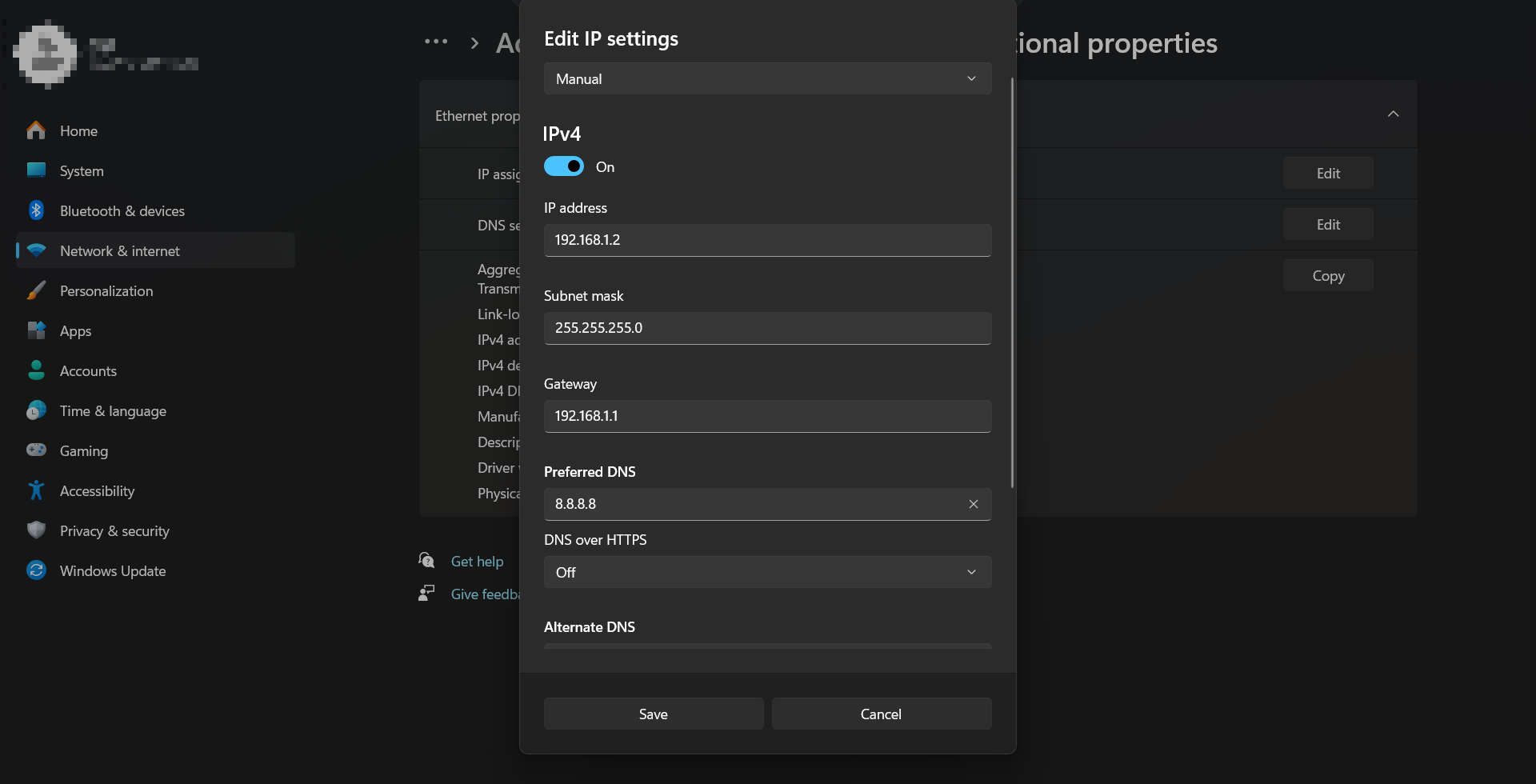
保存后用浏览器访问:
|
|
即可进入 U-Boot Web 刷机页面。这里建议使用无痕浏览器窗口,避免之前访问过其他 192.168.1.1 路由器留下缓存干扰。
这一步最容易传错入口,入口对应关系如下:
| 页面 | 用途 |
|---|---|
http://192.168.1.1/ |
刷 ROM / factory 固件 |
http://192.168.1.1/img.html |
刷 GPT 分区表或完整 eMMC 镜像 |
http://192.168.1.1/uboot.html |
刷 U-Boot |
http://192.168.1.1/uimage.html |
启动 initramfs uImage |
先刷 GPT 分区。注意必须打开:
|
|
然后上传:
|
|
下载地址:
|
|
我第一次把 GPT 文件错传到了 http://192.168.1.1/ 根路径。根路径是刷 ROM 的,不是刷 GPT 的;好在应该被 U-Boot 自动校验拦截失败了。遇到这种情况不要重复乱刷,等页面进度条消失,确认 http://192.168.1.1/ 和 http://192.168.1.1/img.html 都还能打开后,再回到正确的 /img.html 重新刷 GPT。
GPT 刷完后等两分钟。教程说此时路由器会长亮红灯。随后断电,按住 reset 再插电,看到红灯闪烁后变成蓝灯常亮再松开 reset,重新进入:
|
|
然后刷 ROM。本次使用的是 ZqinKing/wrt_release 里的 LibWrt/QWrt 固件,注意选择 jdcloud_re-cs-02 对应型号:
|
|
上传到 http://192.168.1.1/ 根路径刷入。刷完等待路由器亮绿灯。
路由器亮绿灯后,拔掉电脑和雅典娜之间的网线,把电脑网卡恢复为自动 DHCP。
连接雅典娜 Wi-Fi:
|
|
访问后台:
|
|
默认登录:
|
|
进入后可以看到 LibWrt 后台:
由于 192.168.1.1 很容易和家里其他路由器冲突,建议第一时间把 LAN IP 改成不冲突的网段,例如 192.168.101.1:
|
|
网络重启后当前连接会断开,电脑重新获取 IP 后访问:
|
|
前面刷入的 GPT 文件名里带 no-last-partition,意思是没有预先创建最后那个大容量数据分区。刷完 LibWrt 后,系统能正常运行,但大约 100GB+ 的 eMMC 空间还没有被使用。
先检查当前状态:
|
|
本机刷完后可以看到:
|
|
说明系统当前 overlay 已经有约 1.9G,可以正常使用;但 /proc/partitions 里只有 mmcblk0p1 到 mmcblk0p26,没有原厂系统里的大容量 mmcblk0p27。
安装分区和文件系统工具:
|
|
进入分区工具:
|
|
只操作最下面的 Free space:
|
|
这一步不是重做整个盘的分区表,而是在最后未分配空间里新建一个数据分区。退出后先确认新增了 /dev/mmcblk0p27,不要急着格式化:
|
|
确认分区号正确后,后续格式化和挂载直接用 LibWrt 后台 UI 做。
在后台磁盘页面拖动横向滚动条,找到新建分区对应行右侧的 编辑。
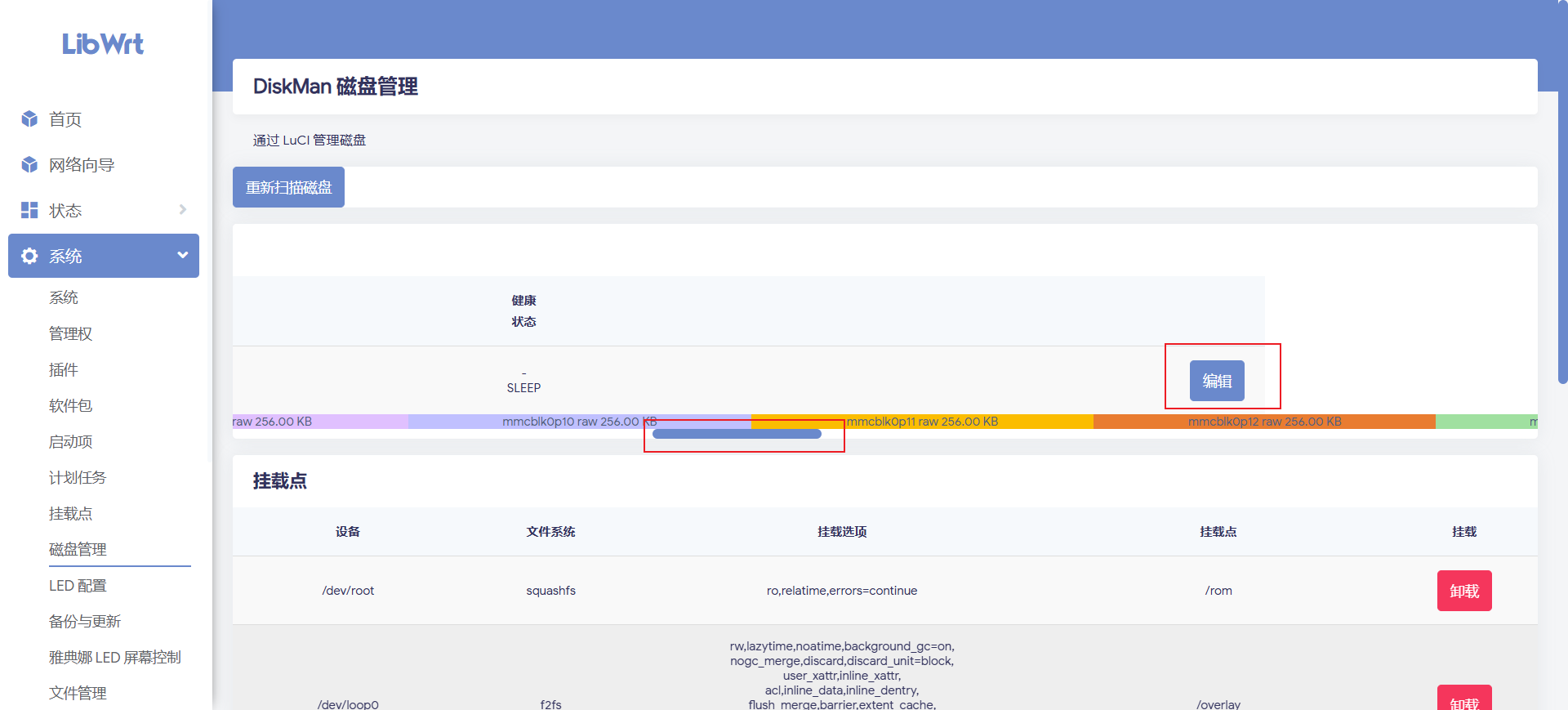
进入编辑后选择格式化。
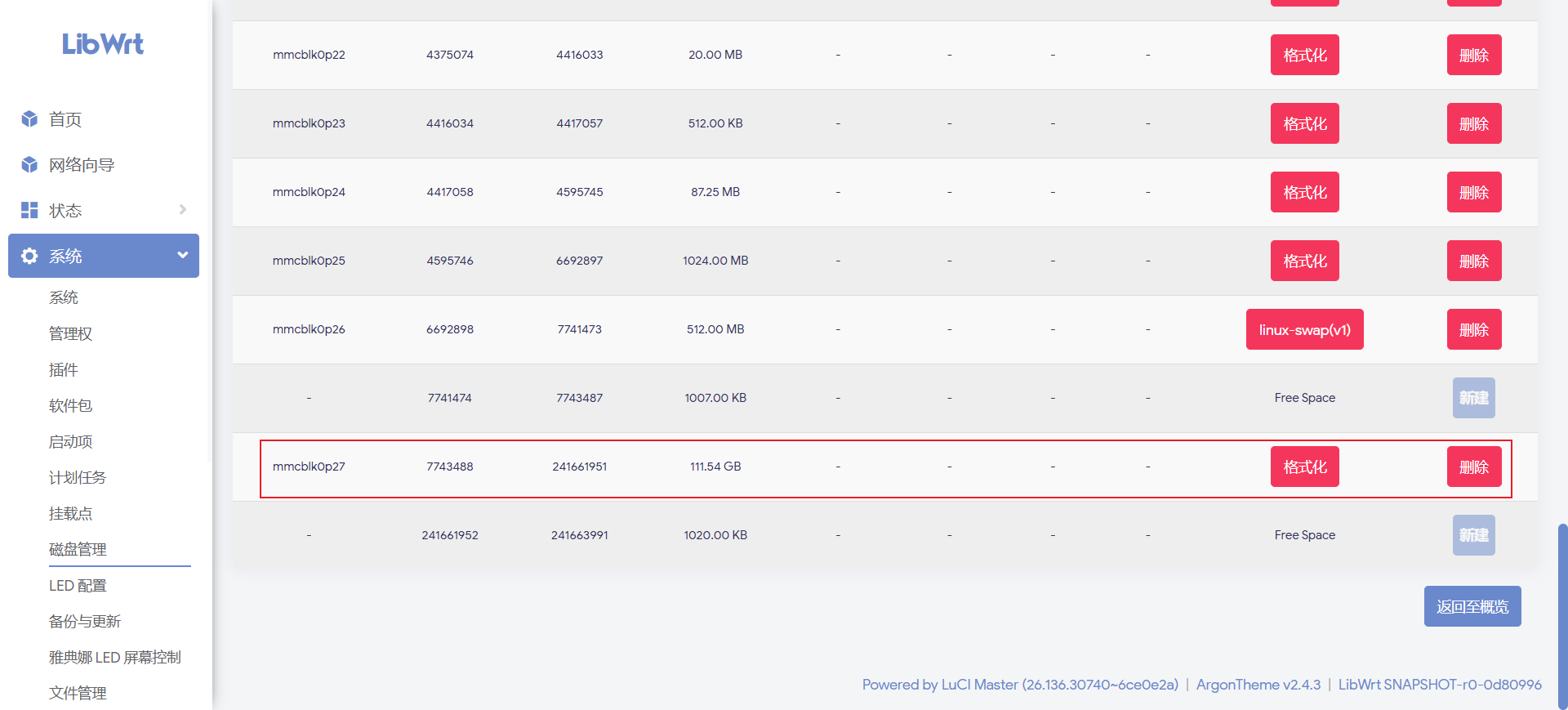
文件系统选择 ext4,确认后等待格式化完成。大分区格式化需要等一会儿,不要中途断电。
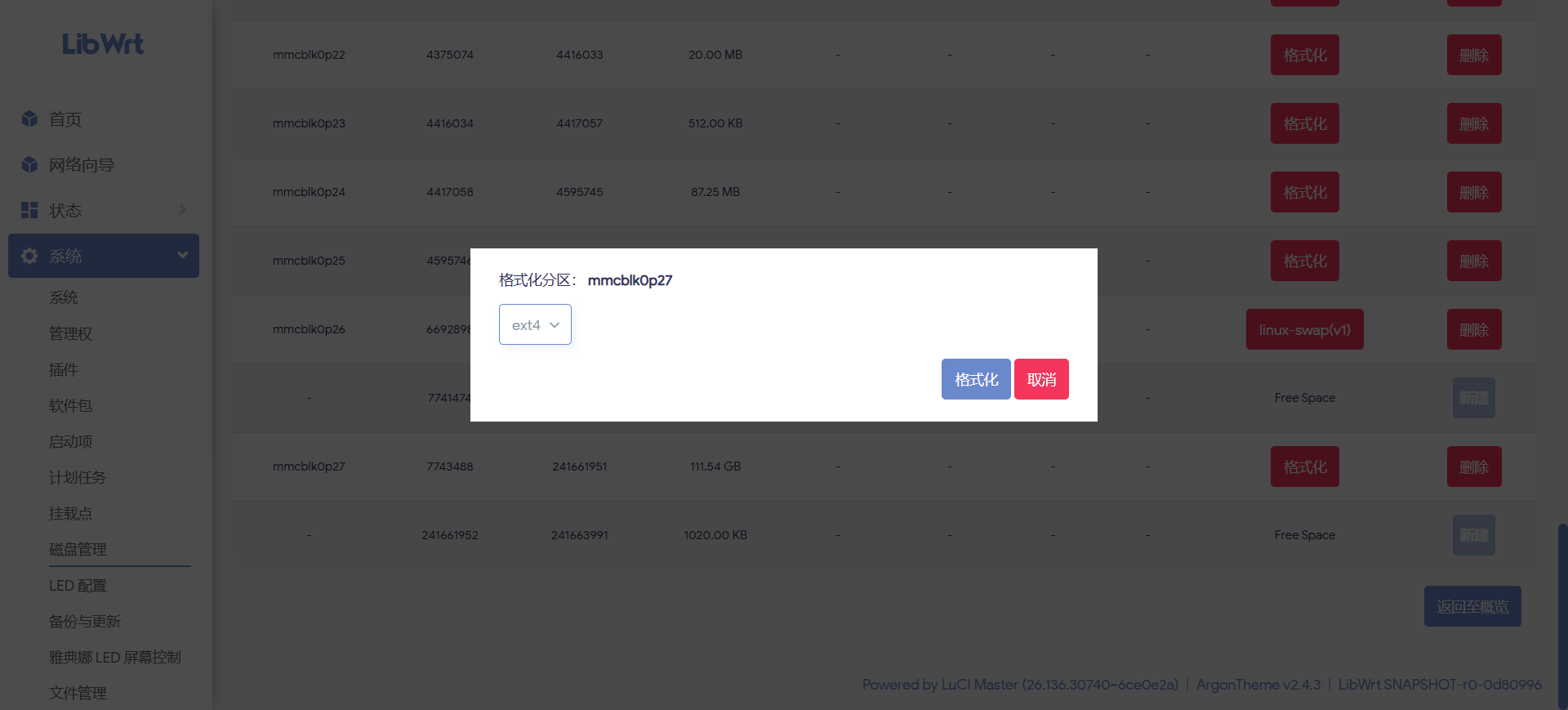
挂载点这里有三个容易混淆的选项:
| 选项 | 含义 | 本次选择 |
|---|---|---|
根文件系统 /
|
直接挂到系统根目录,会遮住当前系统目录 | 不选 |
作为外部 overlay /overlay
|
把大分区变成 OpenWrt 的系统可写层 | 暂时不选 |
| 自定义 | 自己指定挂载点,例如 /opt
|
选择这个 |
本次最终选择自定义挂载到 /opt。这样系统原来的 /overlay 不动,大分区用于 Docker、iStore、下载、NAS、插件数据等应用场景,风险比直接迁移 /overlay 小。
进入挂载点页面,点击 添加。
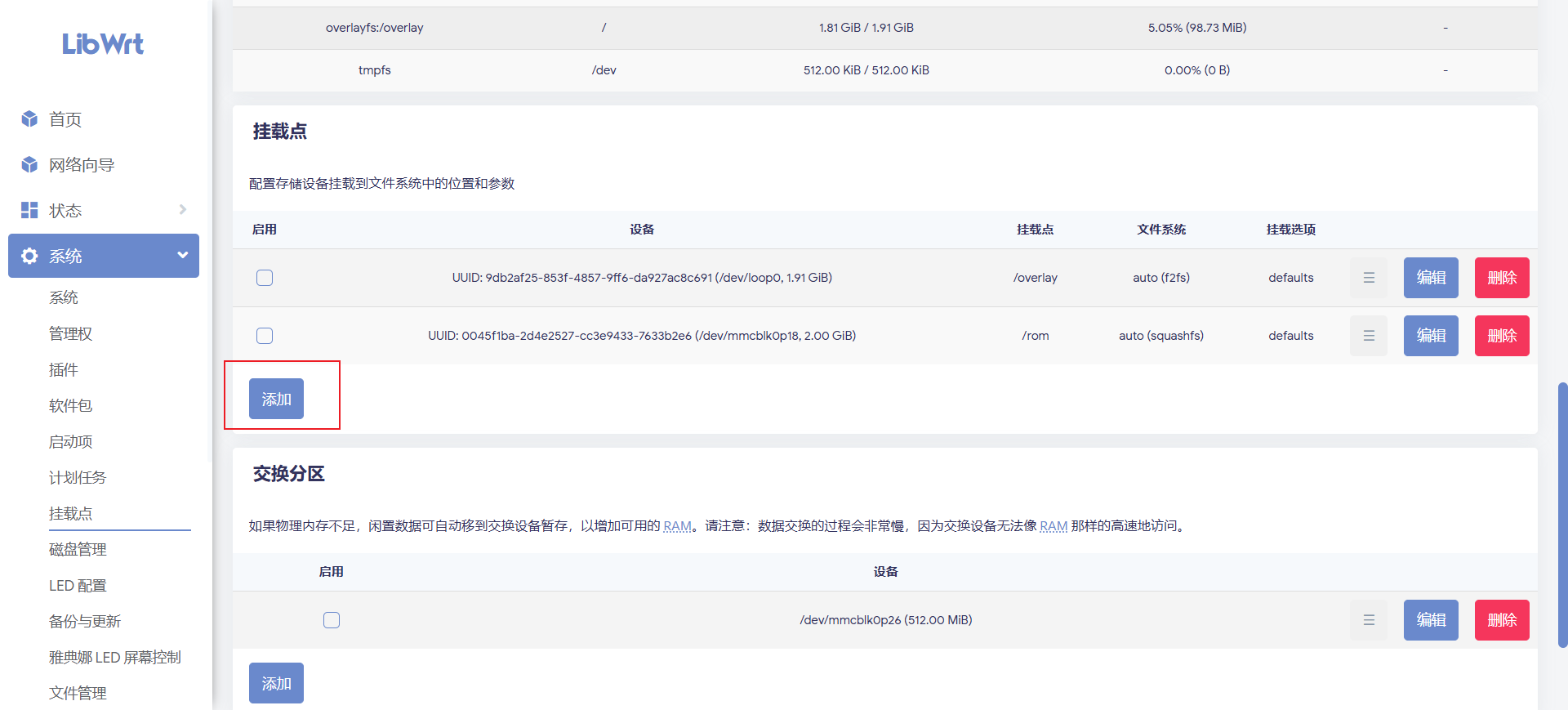
挂载点选择 自定义,输入 /opt,也就是挂载到 /opt。然后保存并应用,最后重启路由器。
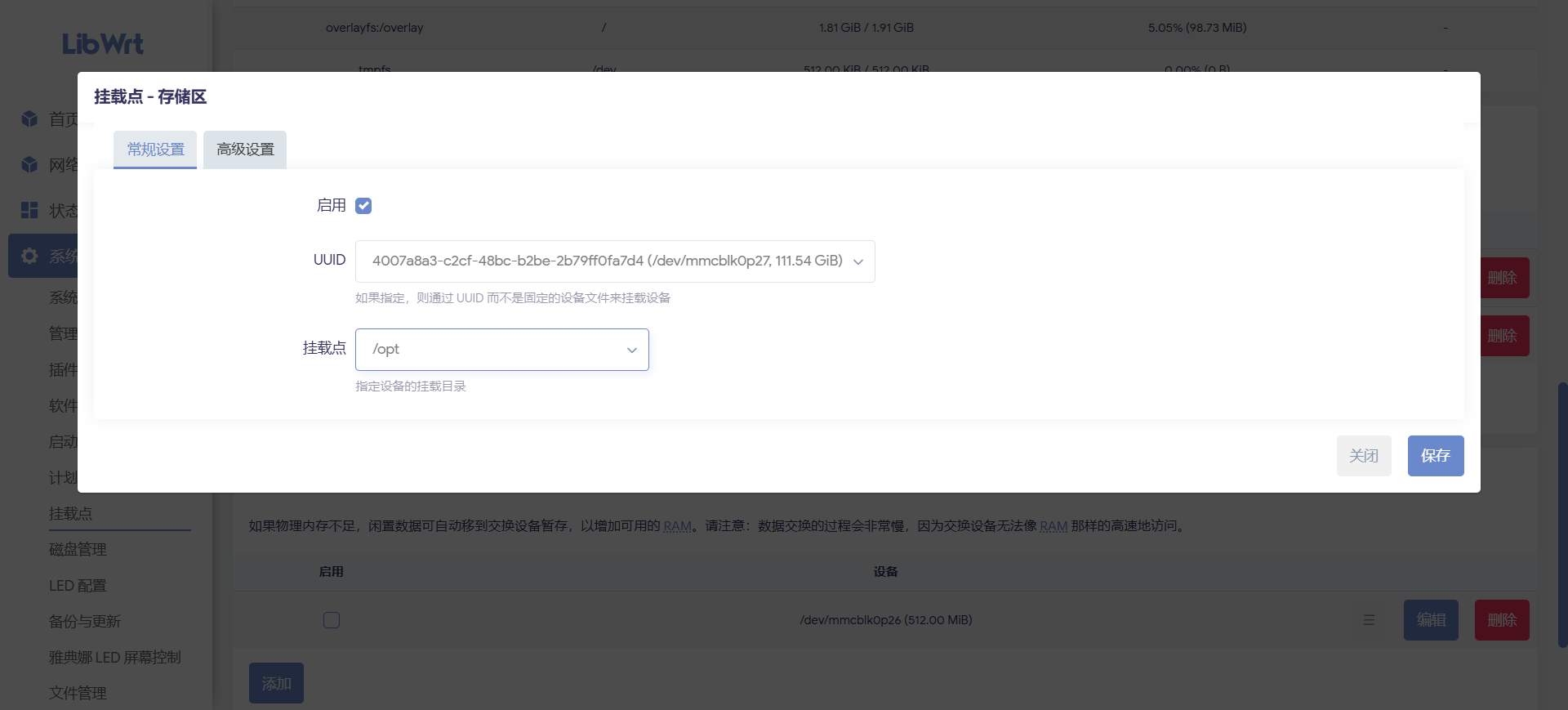
重启后检查:
|
|
本机验证结果:
|
|
/etc/config/fstab 里也有对应的自动挂载项:
|
|
block info 显示:
|
|
说明重启后 /dev/mmcblk0p27 已经自动挂载到 /opt,大容量空间可用。
2026-06-04 18:43:00
![]()
一次性的小坑记录,面向人阅读。结论先放这:APlayer 歌词某些行不显示,十有八九是时间戳格式不对,不是歌词内容缺了。
给博客的 APlayer 播放器挂歌词(.lrc)后,有些歌一切正常,有些歌却有几行死活不显示 / 不滚动——可歌词文件里那几行明明在。控制台也不报错,就是静悄悄地少了几句。
APlayer 的 LRC 解析器对时间戳挑食:它只稳定接受 [mm:ss.xx] 或 [mm:ss.xxx](两位或三位毫秒)这种"规整"写法。遇到下面这些松散写法,它会直接跳过整行:
[02:54.4] —— 只有一位小数[2:54.40] —— 分钟只有一位[02:54] 之外各种位数不齐的组合而很多歌词来源(网易云导出、第三方站点、手抄)恰恰就是这种松散格式。于是同一份歌单里,规整的歌好好的,松散的歌就缺行——表现得很"随机",其实规律就是时间戳。
思路很简单:把每个时间戳重算成总秒数,再补零、把毫秒补齐到两/三位。核心就一段正则替换:
|
|
[02:54.4] → [02:54.400],[2:5] → [02:05],APlayer 就都认了。
这一步已经接进 lihan3238/music 仓库的 CI——lrc_compat.py 里的 normalize_lrc_file 被 test.py 调用,music-sync.yml 在 lrc/** 变更时自动跑,发布前自动规范化。所以现在往歌单里丢任意来源的 .lrc,流水线会自己把时间戳修好,前端再也不会缺行。
APlayer 歌词不显示,先查时间戳是不是
[mm:ss.xx]/[mm:ss.xxx],别先怀疑歌词内容或播放器本身。
2026-06-03 00:00:00
![]()
本文是一次真实迁移的完整走查记录(一次性、面向人阅读)。可被 AI 直接调用、 带可复用 verify 的精简版,见知识卡片
hugo-stack-v4-migration-map(/ai/cards/hugo-stack-v4-migration-map.md)。
把本博客从 Stack v3 升级到 v4。验证于 2026-06-03 UTC(北京时间 2026-06-04), 环境为 WSL。适用场景:升级本博客或其他基于 Stack 主题的 Hugo 站点到 v4,尤其 当出现 CI 卡住、自定义 partial 消失、link-card 页面在构建期抓取远程图片、或旧 frontmatter 不再影响页面可见性时。
>=0.157.0;本博客 CI 使用
0.162.1。github.com/CaiJimmy/hugo-theme-stack/v4,并在 go.mod
中 require github.com/CaiJimmy/hugo-theme-stack/v4 v4.x。layouts/_partials/**,而非
layouts/partials/**。把自定义 partial 移到那里。zh,不是 zh-cn;使用 locale = "zh" 与
defaultContentLanguage = "zh"。favicon = "favicon.ico" 并把文件放到 assets/ 下;
仅为了向后兼容旧 URL 才保留 static/favicon.ico。[sidebar] avatar = "img/avatar.jpg",而非 v3 的
[sidebar.avatar] enabled/local/src 对象。imageProcessing.cover 改名为
imageProcessing.thumbnail;内容图片处理仍保留 [imageProcessing.content]。hidden frontmatter 行为。对必须不出现在
列表中的页面,改用 Hugo 构建选项,例如 build.list = "never"。params.icon;不要再依赖 .Pre。[defaultImage.opengraph]。SortBy = "lastmod"。为了 CI 行为稳定,配合
enableGitInfo = true、完整的 checkout 历史,以及
[frontmatter].lastmod = ["lastmod", "modified", ":git", "date", "publishDate"]。article/components/links.html,直接渲染 <img src="...">,
让浏览器加载 favicon,CI 不依赖远程站点。[article.alertIcon] 原生支持;普通 note/tip/warning
块不再需要自定义 admonition shortcode。[article.mermaid] 原生支持;图表不再需要自定义 Mermaid
shortcode 或页面级加载器。SortBy = "lastmod" 可替换本地的列表 hack。go.mod、go.sum、语言键、favicon、头像、图片处理,
以及被移除的配置块。layouts/partials/** 移到 layouts/_partials/**;
同步更新任何 workflow 路径(例如 music sync)。hidden: true、imageProcessing.cover、
layouts/partials/、.Pre,以及被误写成 Markdown 图片的普通链接。
|
|
期望:Hugo >=0.157 无警告构建;workflow 通过 lint;diff 无空白错误;合并前
PR 的 Pages 构建通过。若失败,检查模块路径、partial 覆盖位置、
avatar/favicon/imageProcessing 键、隐藏 frontmatter,以及构建期远程资源抓取。
2026-06-02 20:00:00
![]()
用一台有公网入口的 Rocky Linux VPS 做 WireGuard Hub,把宿舍 OpenWrt、工位 Linux、工位 Windows 等设备接入同一个私有网段,并通过宿舍 OpenWrt 远程唤醒宿舍 Windows PC。
本文不是 WireGuard 原理课,而是一份部署和维护手册。以后忘了命令、要新增 peer、要排查握手和路由问题时,优先按本文检查。
当前策略:
192.168.1.0/24。/32 地址。386.14_2 上强行部署 WireGuard 主链路。注意:本文是公开博客版本,所有私钥、公钥、MAC 地址、VPS 公网 IP 都用占位符表示。真实值只应保存在对应设备本机配置中,不要放进 GitHub、截图或聊天记录。
|
|
推荐访问方式:
|
|
当前网段:
|
|
后续如果有条件统一调整 LAN,建议改成不容易冲突的编号:
|
|
但当前阶段不强行修改 LAN。远程组网最怕“边调边失联”,先把 WireGuard 跑稳,再做地址治理。
本方案采用:
|
|
理由:
WireGuard 的 AllowedIPs 同时承担两件事:
|
|
因此它既像访问控制列表,又像路由表。配置错误时,经常表现为“有 handshake,但 ping 不通”。
规则:
10.77.0.2/32 和 192.168.1.0/24。10.77.0.x/32。192.168.50.0/24,除非它真的是工位网关。AllowedIPs 写“远端目标”,不要把自己的本地 LAN 写进去。错误示例:
|
|
这里两个 peer 同时宣告 192.168.1.0/24,会造成路由冲突。
正确示例:
|
|
|
|
正常应看到:
|
|
|
|
查看公钥:
|
|
注意:
|
|
/etc/wireguard/wg0.conf
|
|
推荐模板:
|
|
建议固定:
|
|
原因是配置文件才是真源。否则运行时的临时变更可能被 wg-quick 写回文件,长期维护时容易混乱。
|
|
期望:
|
|
放行 WireGuard 端口:
|
|
建议把 wg0 放入 trusted zone,减少 VPN 内部转发被 firewalld 拦截的概率:
|
|
如果 VPS 还有云厂商安全组,也要放行:
|
|
启动:
|
|
重启:
|
|
停止:
|
|
查看状态:
|
|
查看关键路由:
|
|
正常状态应至少包含:
|
|
如果旧 OpenVPN 仍在,可能还会看到:
|
|
宿舍 OpenWrt 当前 LAN:
|
|
后续 WOL 必须从 br-lan 发,不要从 wg0 或 pppoe-wan 发。
|
|
|
|
将输出的 DORM_OPENWRT_PUBLIC_KEY 填到 VPS 的 dorm-openwrt peer 中。
先设置变量:
|
|
配置接口和 peer:
|
|
关键点:
|
|
查看:
|
|
只保留 WireGuard 网段:
|
|
如果将来某远端子网也通过 VPS 可达,再按需添加,例如:
|
|
当前不建议把工位 192.168.50.0/24 交给 WireGuard,除非工位网关也接入 WireGuard。
创建 vpn zone,并允许 lan <-> vpn:
|
|
检查:
|
|
在 OpenWrt 上:
|
|
从 VPS 测:
|
|
如果 10.77.0.2 通,但 192.168.1.1 不通,优先查:
|
|
Ubuntu / Debian:
|
|
Rocky / RHEL / Fedora:
|
|
|
|
查看公钥:
|
|
把输出的 OFFICE_LINUX_PUBLIC_KEY 加到 VPS。
/etc/wireguard/wg0.conf
|
|
配置:
|
|
说明:
10.77.0.0/24 用于访问 WireGuard 内所有 peer。192.168.1.0/24 用于访问宿舍 LAN。192.168.1.0/24。Endpoint 写成 VPS 当前内网可达 IP;长期使用应改成 VPS 公网 IP 或稳定域名。权限:
|
|
启动:
|
|
重启:
|
|
检查:
|
|
测试:
|
|
安装 Windows 官方 WireGuard 客户端后:
|
|
客户端会自动生成 PrivateKey 和 PublicKey。
Windows 配置模板:
|
|
VPS 上添加:
|
|
应用 VPS 配置:
|
|
PowerShell:
|
|
注意:
|
|
TUN 模式代理可能截获 WireGuard 外层 UDP 流量:
|
|
如果这条流量被代理接管,常见现象:
|
|
必须 DIRECT:
|
|
Clash 规则示例:
|
|
建议 WireGuard Endpoint 用 IP,不用域名:
|
|
这样可以避免 DNS 查询被 TUN 代理影响。若必须用域名,则 DNS 也要确认不被代理规则错误接管。
推荐链路:
|
|
不要优先尝试远端直接向 192.168.1.255 广播。WireGuard 是三层隧道,广播不一定穿透。最稳的是让 OpenWrt 在宿舍 LAN 本地发 WOL。
BIOS / UEFI:
|
|
MSI 主板进 BIOS:
|
|
Windows 网卡设置:
|
|
如果要从关机状态唤醒,建议关闭 Fast Startup:
|
|
如果只从睡眠唤醒,可以先不关 Fast Startup,先把最小链路测通。
|
|
只用命令行:
|
|
Windows:
|
|
找有线网卡:
|
|
OpenWrt 上也可以查:
|
|
MAC 格式统一写成:
|
|
OpenWrt 上执行:
|
|
宿舍 LAN 接口是:
|
|
不要从 wg0 或 pppoe-wan 发 WOL。
如果使用 LuCI:
|
|
建议开启 Send to broadcast address。
理由:
|
|
不要做:
|
|
|
|
远程唤醒:
|
|
宿舍内网唤醒:
|
|
先测试睡眠唤醒:
|
|
再测试关机唤醒。
如果睡眠能醒、关机不能醒,优先检查:
|
|
如果完全不能醒,优先检查:
|
|
|
|
重点看:
|
|
典型问题:
|
|
|
|
日志:
|
|
应用配置:
|
|
|
|
重载网络:
|
|
重启防火墙:
|
|
|
|
重启:
|
|
从工位 Linux 测:
|
|
从 VPS 测:
|
|
从宿舍 OpenWrt 测:
|
|
判断顺序:
|
|
不要一开始就测 RDP、SSH 或 WOL。先把三层连通性验证完。
建议:
|
|
Linux:
|
|
Windows / macOS / 手机:
|
|
|
|
重启 VPS:
|
|
单设备客户端模板:
|
|
如果只想访问 WireGuard peer,不访问宿舍 LAN:
|
|
如果想全局代理,才写:
|
|
当前不建议默认全局代理。这个方案的目标是远程组网和运维,不是替代所有代理流量。
|
|
VPS 只需要暴露:
|
|
不要为了 WOL 暴露:
|
|
WOL 只从 OpenWrt 的 br-lan 本地发。公网只允许进入 WireGuard。
宿舍 192.168.1.0/24 下的普通设备不需要安装 WireGuard,也可以访问 10.77.0.0/24,前提是:
|
|
如果普通设备自己也安装 WireGuard,可以,但它只能宣告自己的 /32,不能宣告整个 LAN。
工位 Linux/Windows 如果只是单设备 peer,就只写:
|
|
不要写:
|
|
除非这台设备真的是工位 LAN 的默认网关,并且已经配置好 IP 转发、防火墙和回程路由。
应保持:
|
|
不要做:
|
|
VPS:
|
|
OpenWrt:
|
|
Linux peer:
|
|
WOL:
|
|
如果只记一个排障原则:
|
|
2026-05-29 06:45:00
![]()
敲下了标题,已是凌晨 6:47,一夜未眠,先去吃个早饭。
忘了拍照,雪菜粉丝包和豆腐脑还是比北京的好吃多了,倒是鸡蛋灌饼没冬天热乎好吃了,应该是换了厨子。
经典睡不着红温,索性下床学习通宵算了。好吧,倒也没有那么经典,上次还是大三吧,不过这次不能下床就趴在桌前敲笔记本,得跑去工位了。
其实说实话有点傻逼真的,自以为摆脱思想桎梏的人现在天天晚上为世俗的前途焦虑地睡不着觉,最喜欢玩的人迷上了 Vibe Coding 后一个月没打开过游戏。归根结底,还是被困在了这个毫无希望的学校里。
回归正题,敲完这篇就回去睡觉了。
对大模型的接触自然要追溯到 2022 年末的 ChatGPT 了,它从 11 月 30 日发布到突破 100 万用户只用了短短五天。我的第一个账号也是在当时注册的,一篇知乎让我花了一个半小时从接码到注册用上了大模型。
用上 GPT 后的第一个“工程实践”就震惊了我,它不仅能够根据 Java 老师的作业要求给出能跑的代码,甚至还会授人以渔和代码纠错,这对当时只会机械执行一行行代码的机器人般的我来说简直是个奇迹!
说实话,后面的一年里,GPT 和其他大模型于我只有一个作用:水掉作业。于是在疫情宅家的日子里,我不是在打游戏就是在打游戏,与此同时 DaleChu 同学似乎在那段时间深耕了键政和计算机技术。
时间一晃来到了 2023 年的九月开学,在 lihan 开始模仿 DaleChu 的博客时,对大模型的使用也慢吞吞地进入了下一个阶段——代码补全。申请了 GitHub Copilot 的学生会员后,代码补全 + ChatGPT 的组合一方面让刚准备开始发奋学习技术的我得以更快上手,另一方面也让我第一次意识到似乎手搓代码就跟提笔写字一样要被淘汰了。

自此之后,一直到研一,我对大模型的使用与研究便停滞于此了,从 GPT-4 到 GPT-5,对我而言不过是一次次版本号的迭代,以及模型能力的日常提升。除了越来越多人开始使用大模型,越来越多的垂类产品也开始涌现之外,并没有什么特别的感觉。当然,这也源于我对当时那些所谓的“Prompt 工程”的不屑一顾了。如今再看,真的很难想象自己居然纯靠网页 ChatGPT 完成我的 DSSE 毕业设计。
AI 的热情再度被点燃是在研一的十月份了,在 lyx 的教导下,我开始试着接触科研和实验。第一次看到他用 Copilot Vibe Coding 写代码时我简直像极了面对流水线鲜花饼产线的老手艺人——还能这样?
现在说什么都来不及了,Vibe Coding 沾上了就戒不掉了,纵使一开始对失去项目与代码掌控权的疑虑到现在还没完全打消,我已然是无法回到最开始的手搓代码了。
lemoncchi 说,大模型害惨了我们这些没跟上这趟科研快车的程序员。诚然,倘若没有大模型的出现,我们仍然能够凭借编程的技术,在刷 LeetCode、背面经后,一路实习、面试,最终找到一份凭借着剩余价值转移得以维持高薪的码农工作。但现在,可见的未来,简历上的“熟悉 C++”几乎和“熟悉 WPS”要画上等号了,更可恶的是,精心(也许精心吧嘿嘿)维护的博客里的技术贴已经完全失去意义了,也再不会有无知美少女抱着电脑一脸崇拜地请教你某个小技术问题了(说实话感觉主要是 DaleChu 和 lemoncchi 在经历这个,我只能给壮汉讲呜呜呜)。
但倘若不从功利的角度出发,大模型的出现几乎是一个让人美梦成真的奇迹!今年初开始让老程序员们重燃青春的 OpenClaw 和 Hermes,让无数像家父和我导师这样的老程序员们上头了几个月还没退烧,纵使一个月几千的 Token 账单贴在脸前,一个真的能把你的想法实现的魔法机器摆在面前,谁能不心动呢?是啊,记得小时候,看着网上所谓“脚本小子”为游戏制作外挂,听起来好像得学好多年才能到这个地步,现如今十几分钟就能让大模型给我用 YOLOv8 跑起来挂机脚本了;困扰了我两年的博客音乐列表全自动更新功能,也不过是一杯咖啡的功夫就能给我完美实现了。大模型的出现对于不考虑以此谋生的程序员来说,真的是原神了。
导师其实早就紧跟时代了,给我们发模型让我们用 ClaudeCode 做横向项目了,从他的 GitLab 记录来看,过年期间他也上了 OpenClaw 这趟车,直到今天还在兴致满满地安排着他的 Agents 用 Vibe Coding 做各种项目。相比之下,我这个老古董学生倒是在 Copilot 报废后,才勉强开始把他发的 GLM 接入 ClaudeCode 使用。
用 ClaudeCode 的第一天就把卡了我几周的 Bug 轻松秒掉了。
今年三月左右开始,让我白嫖了多年的 Copilot 开始抠搜了,先是旗舰模型被移入更高价位的套餐,然后是使用次数被一次又一次限制,月限、周限、五小时限,一直不想“自费打工”的我总算在四月尾巴坚持不住,开始转向 Codex 和 ClaudeCode 了。
2026 年 4 月 27 日,面对额度耗尽的 GLM,lihan 打开了当年偷瞄 DaleChu 屏幕看到的那个神奇论坛——LinuxDO,在通宵达旦地高强度刷了一天帖子后,终于跟上了这波“中转站 - Vibe Coding - AI Workflow”浪潮。在几个中转站里摸爬滚打了一两天后,从“福利羊毛”区的大善人们的投喂和“跳蚤市场”区的低价 GPT Team 车开始,走上了一趟狂热的 Vibe Coding 之旅。
在牺牲了原本备考数学期末的时间、用 Vibe Coding 给开源项目提交 PR 后,我很快意识到不能把精力砸在抠搜上——强大先进的生产力应当不计代价地立刻投入使用!于是在考完后的当天,我就开始通宵搭建我这个基于 New API + CliProxyAPI 的中转站 lihan API 了。
一扫以往买域名、买服务器、买节点的犹豫,花了五天时间,我便部署好中转站投入使用了。从一开始三天报销掉三个 GPT Plus 的周限,到现在后台额度波澜不惊,即便小小地给周围同学朋友推广使用、企图回血,也很少再出现额度不足的情况了,我这才开始缓慢地真正掌握 Coder Agent 这把尚方宝剑。
在 Vibe Coding 中的摸爬滚打难以言喻,总结下来,不过是以下几点:
希望年末我能笑着去香港喜提 MacBook Pro M6 Pro 和 iPhone 18 Pro Max!
2026-05-21 00:00:00
![]()
本文是一次真实配置的完整走查记录(一次性、面向人阅读)。这套环境配好一次就长期 复用,我大概率不会再从头踩坑,所以收成博文而不是知识卡片。
想用 Codex 的 remote-connect 功能从 Mac 驱动一台 Windows 机器。连上之后,Codex
在远端跑 bootstrap 一上来就失败:报 pwsh 看不懂的 token、&&、$(...) 之类的
错误,或者客户端报远端 shell 没返回预期的握手。
根因是 shell 不匹配:
适用场景:用 Mac 通过 Codex remote-connect(或其他假定 sh 的远程开发工具,比如 JetBrains Gateway、bootstrap 脚本只认 sh 的 VS Code Remote-SSH)去驱动一台装了 WSL 的 Windows 机器,且连接在 bootstrap 阶段挂在 shell 不兼容 / pwsh / command-not-found 上。
不适用:远端本身就是原生 Linux(没有 shell 不匹配)、远程工具明确支持 Windows 侧 pwsh、或者那台 Windows 上压根没装 WSL 发行版。
第 1–3 步每台 Windows 主机一次性;第 4 步每台 Mac 一次性。
在 Windows 上打开 WSL Ubuntu:
|
|
确认:
|
|
在 Mac 上:
|
|
复制整行。进到 WSL 里:
|
|
在 Windows 上以管理员 PowerShell 执行:
|
|
编辑 Mac 上的 ~/.ssh/config:
|
|
然后在 Codex 里把 remote-connect 指向 Host 别名 lihan_pc_02_wsl——Codex 看到
的是一个 POSIX 远端,bootstrap 就能干净跑通。
$wslIp 当成一个快照写死了。一旦
wsl --shutdown 或 Windows 重启,要重跑 netsh interface portproxy add
(先用 netsh interface portproxy delete v4tov4 listenaddress=0.0.0.0 listenport=2222 删掉旧的)。可以把它写成一个开机自动跑的计划任务。10.88.0.6:10808)跟这条 SSH 路径无关,别混在一起。在 Mac 上:
|
|
返回一个 Linux 内核串(形如 Linux ... microsoft-standard-WSL2)且退出码为
0,就说明这台 Host 上的 Codex remote-connect 能用了。
连不上时按顺序排查:
sudo service ssh status;netsh interface portproxy show v4tov4 与 wsl hostname -I
(每次 WSL 重启 IP 都会漂);WSL SSH 2222 是否存在;~/.ssh/authorized_keys 里有没有 Mac 公钥,且权限是 600。