2026-06-24 22:00:00
Large scale AI models can produce an innumerable variety of output (text, images, code). In most applications, though, teams want very specific output aligned with brand, design, and coding guidelines. An intentional steering layer can not only help but is increasingly needed in software today.
When building, and even more-so maintaining, websites and software applications, cohesion matters. A consistent brand enforced by intentional use of visuals, colors, fonts, etc. Coding standards, libraries and frameworks, a common development process, etc. Today's AI models can handle all that and more but how do teams make sure they handle it all the way they'd like? And do so repeatedly.
The answer boils down to context: prompting models with clear, comprehensive and relevant instructions. Better context, better results. So how can we encode context into our applications so not only every update to a Website or application stays aligned but every person on a team does too? In our recent projects we've relied on a steering layer.

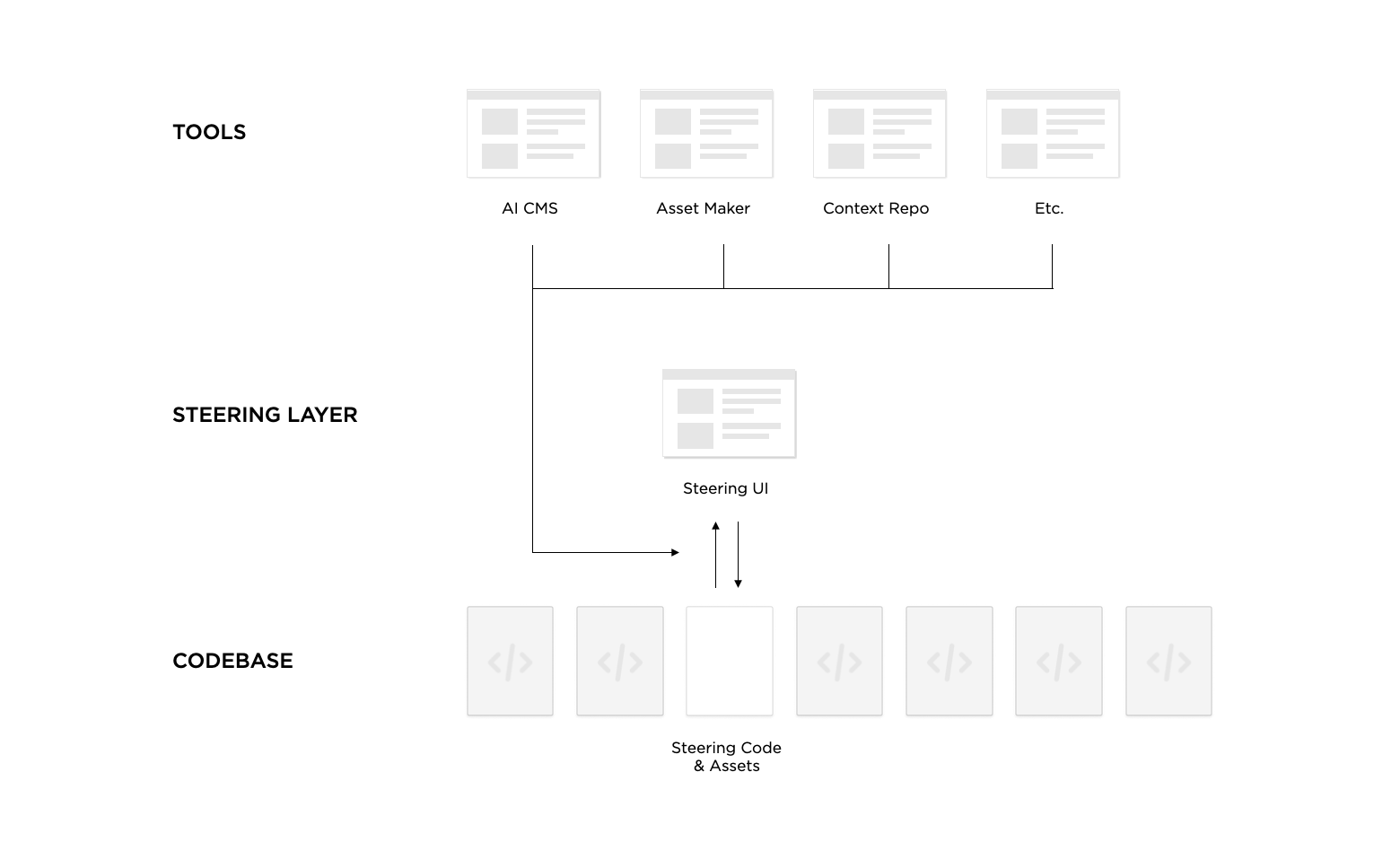
So what's a steering layer? Put simply, it's how context gets enforced across a project, a team, and even, a company. Every Website or application at its core has a codebase and a set of tools for people to modify that codebase. That's how features ship, performance improves, and ideally software companies make money. A steering layer (conceptually) sits in between the tools and the codebase.
Examples, please. Let's start with a really simple one. My LukeW Character Maker is a small application that allows anyone to make on-brand (for LukeW) image assets. It consists of a tool that allows people to create, review, save, and share assets. A steering layer composed of guidelines, reference images, and prompt rewriting. And the code that runs everything.

The steering layer is responsible for enforcing an AI image model's output aligns with the LukeW character's style, colors, appropriate use guidelines, and more. The LukeW Character Maker tool allows anyone to easily stay on brand when making a LukeW brand asset. And the codebase makes it all happen.
At this point, it's worth noting that the steering layer often lives in the codebase. When it's just text files, reference images, etc. It makes perfect sense to leverage the version control, review process, and team collaboration native to code. But not everyone on a team is comfortable, nor should have to be, working as a developer. For the cases where designers, copywriters, PMs, and others should contribute to and maintain the steering layer, a UI for doing so separate from the codebase makes sense.
As another example, we recently launched a Website for our Agentic HR company, Sol. The steering layer for the website consists of a set of design tokens, development instructions in an agents.md file, and some agent skills. These live in the codebase with everything else. But anyone using AI agents to update the site (with a tool like Intent) is "snapped to" the design and development guidelines in the steering layer. This allows everyone on the team to make Website fixes and add new content without diverging from the design and development guidelines.
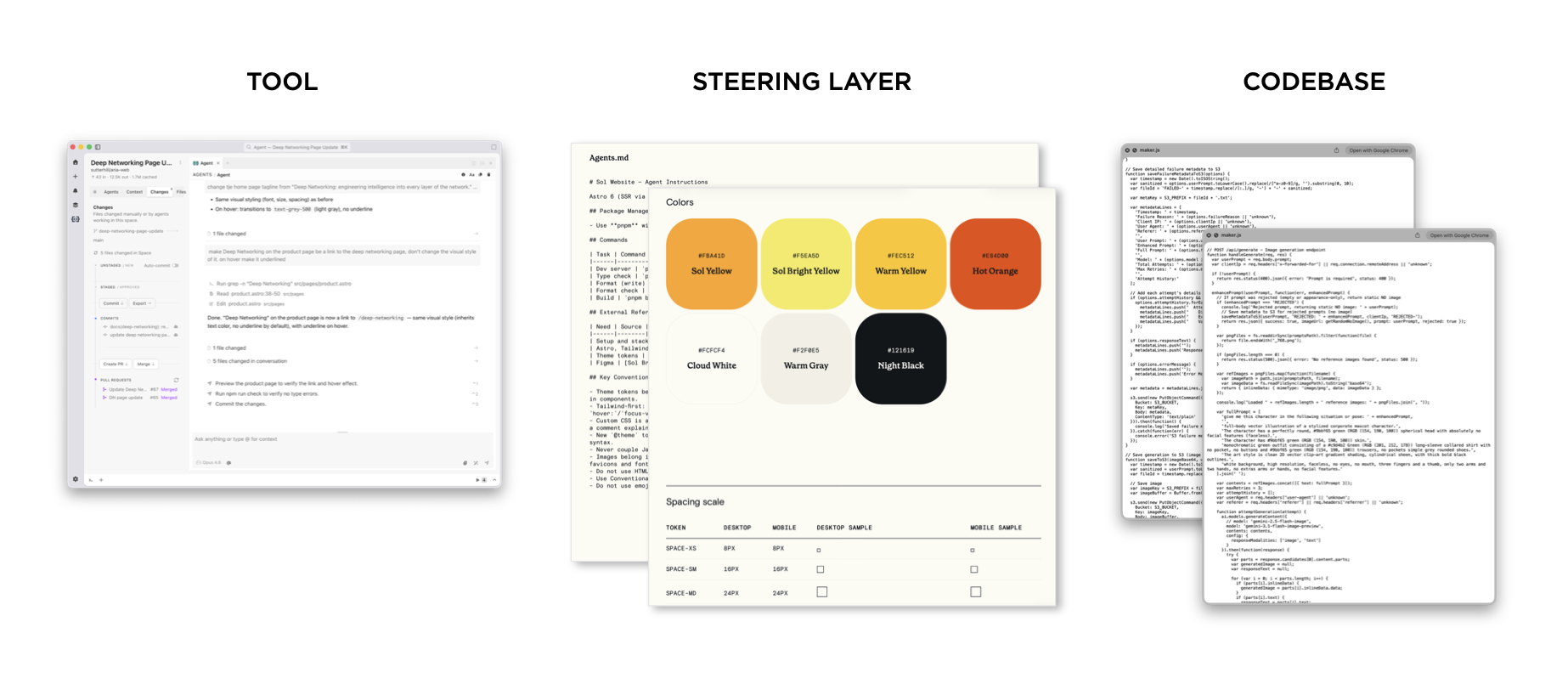
It's also worth noting that a steering layer isn't limited to a few text or image files. In the case of the Ask LukeW feature on this Website, the steering layer is composed of not only instructions and examples, but multiple retrieval systems I've iterated on for the past few years as well. Their job is to find the right context for any given question and dynamically apply them to steer results. There's also a whole set of admin tools for managing what's in the context they pull from but that's a whole other topic.
With each new project, we're looking at better ways to make the steering layer visible (and for some, editable) to teams. We're also building steering layer powered tools that enable more people in an organization to contribute to projects without sacrificing cohesion. So... more to come.
2026-06-18 22:00:00
There's a growing sentiment that AI lets you do everyone else's job: designers picking up Claude Code, developers spinning up Figma Make. But maybe the most interesting question isn't "what other jobs can I take on?" but "how do I make the thing I do well reach further?"
When I instruct a coding agent to write a large chunk of code, I can roughly tell what's happening, but I don't have years of professional software development under my belt. I can play a developer on TV. But in real life, I'm a pretty crappy one. The same is true in reverse: a developer can generate a layout, but they don't have the years of pattern recognition that tell a designer what matters and what to throw out.

In other words, the "do it all yourself" approach spreads us thinly across multiple complex and important jobs. That's not a superpower. Unless you want to live out the real-life adventures of Mediocre Man.
Years ago at Yahoo!, we built an internal class for designers called Board to Board (from the drawing board to the boardroom). The whole point was instead of convincing people design needs "a seat at the table" by trying to act like business leaders, figure out what designers bring that nobody else at the table has so you get invited. Pattern recognition. Visual communication that makes concepts clear. Those same skills turn out to matter enormously for telling the story of a company, not just a screen.
The lesson was double down on the thing you're uniquely good at and apply it elsewhere. Don't dilute it trying to be a passable version of other roles.
Similarly we can use AI today to do more jobs or to make our one job have much more reach. We've been building this into how we design and build Web sites and applications using collaborative steering. It allows a designer to put rigor and focus on the grid, the typography, motion rules, and color system of an application. They encode that into a shared context that both people and agents apply. A developer does the same with how code gets organized, written, and tested.
In practice this design and development "intent" ends up as text files outlining instructions that AI agents use when building software. Anyone using agents within a codebase with collaborative steering stays aligned with this intent because their agents make use of it when doing work.
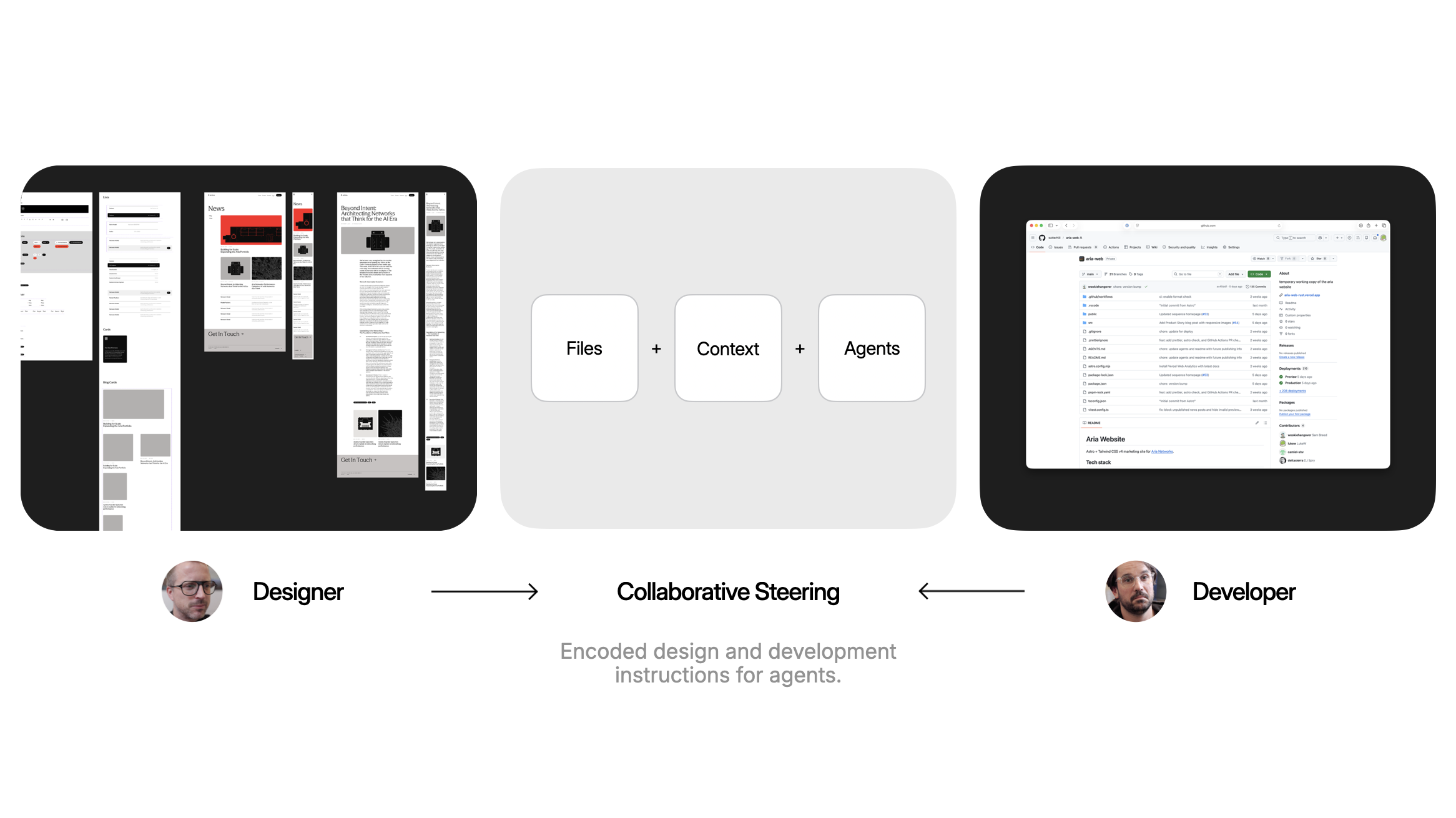
With this approach, designers don't have to be present to influence how things are laid out, their intent is scaled with each AI agent. The grid is the grid no matter how many agents are writing code in parallel.
Collaborative steering doesn't mean dumping every possible bit of design or development context into agent instructions. It's being precise about what matters because with AI agents today, the more you pile in, the less useful it gets.
And that's where expertise kicks in. Knowing the three to five things that actually matter, in what order, and how they need to be done, is the value add. It's the part you can't fake by playing a role you never trained for. And it's the part worth encoding for everyone else.
AI doesn't mean you should go be everyone. It means you can scale the thing you're uniquely wired for.
2026-05-18 22:00:00
Today, AI tools are mostly solo sports. Developers write more code. Designers create more images. PMs crank out more docs. That's cool... but it's more cool to work together. So how does that work with AI?
Many AI-driven productivity tools have evolved from chatting with an AI model to guiding the work of agents capable of a lot more than just answers. But when everyone on a team runs their own agents they guide them towards the outcomes they want, towards their version of things. So in a agentic world, it becomes even easier for perspectives to drift apart. As one design leader recently put it at the Design Futures Assembly: when anybody can build what they want, you feel it in the product because you ship fifteen different ideas instead of one unified point of view.
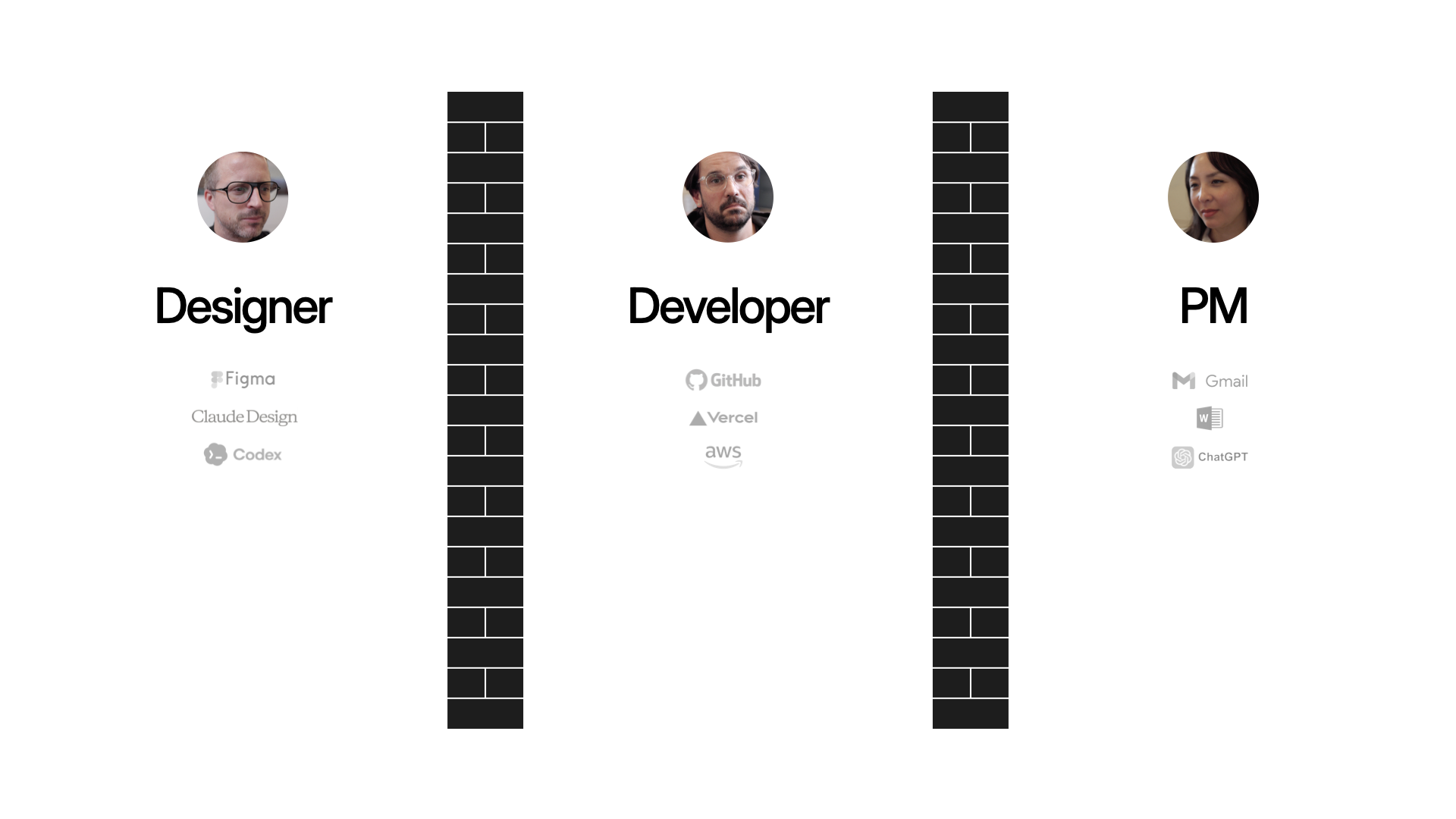
One of the reasons this happens is that people use different ways to guide agents. Agent markdown files, skills markdown files, system prompts, agent prompts, memory, MCP servers, and so on. The combination all of these disparate elements influences the outcomes AI agents produce.
That's complicated enough for an individual but multiply it across a team and it becomes really difficult to work on the same thing together. Everyone's agents are optimized for their own perspective, not a shared one. And the elements influencing them are scattered across people's computers, codebases, and servers.
We need a different approach for simplifying context management not only for individuals but for groups as well. Think of it as collaborative steering: a mechanism for guiding agents that's collaboratively created, edited, and maintained by teams.
Why collaborative steering? Because, even with all-knowing AI, people have specific expertise and experiences that when brought together make products better. Designers versed in interaction design principles, brand voice, visual design integrity. Engineers focused on performance optimization, easy to maintain code structures, infrastructure choices. But ensuring these distinct roles produce a coherent whole has always been hard. AI can help.
In several of our recent projects we've used Intent, to define project-level context that steers agentic workflows toward shared goals, not away from them. We're currently applying what we learned to larger scale and more ambitious work, which I'll share in the coming weeks.
But after seeing how far we've gotten already, I'm pretty certain that the era of everyone on a team piloting their own disconnected agents can't be the end state. The tools that figure out how to make collaborative steering natural and lightweight are going to change how teams, not just individuals, build.
2026-05-11 22:00:00
With AI, anyone on a team can generate mockups in minutes. That was never the hard part. The difficult work is, and always has been, maintaining coherency and intention across a product so it works for people, not the other way around. And perhaps unintuitively, everyone making mockups can help.
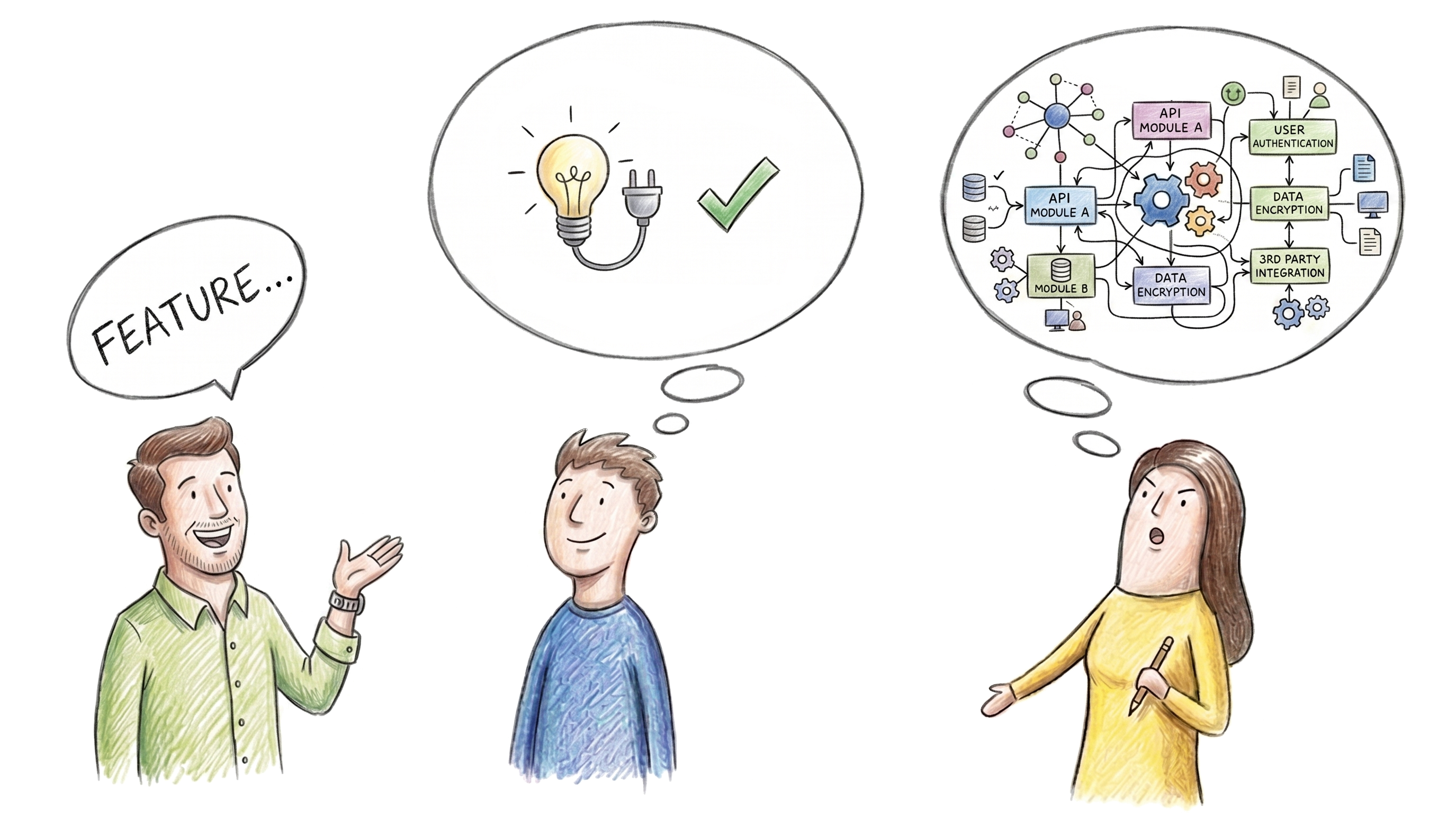
I was recently in a meeting discussing improvements to a specific part of a product. The backend engineer came in with a mockup. The product manager came in with a mockup. And the front end developer already had a working build. Three different disciplines all showing up with their version of what the UI could be, all enabled by AI tools. Given this reality, designers should worry about AI taking their jobs right? Well if the job is making mockups, then yes.
Here's what happened in that meeting. Seeing each person's concepts led me to ask the more important design questions. How do these features interact? What are the relationships between them? We discussed the system, its objects, and the mental model that made most sense for our target users.
We got to a shared understanding of the data we needed to support the UI, how it should be structured and how it interrelates with the rest of the product. Back-end, front-end, PM, and design on the same page. Which makes sense because these are the conversations that drive clarity and coherence in a product. Not "do you like this in my mockup or that in some other person's mockup?"
Later, I was reminded of a point I heard an educator make at the recent Design Futures Assembly. He noted at their business school, they'd give students case studies to analyze. Pretty much every student used AI to blast through the analysis in minutes. At first, the professors tried to stop students from using AI. But quickly they realized they should encourage it.
When all the students came in with the baseline analysis behind them, the conversation could progress to the next level. Before, it took the whole class hour just to get to the basic conclusions. Now, within ten minutes, they're on to much deeper and meatier topics. The majority of the class is spent expanding from the baseline as opposed to getting everybody there.
When everybody comes in with a baseline, we can skip past "here's my idea, here's my idea" and get straight to the meaty questions. The ones that rarely got discussed because we used to spend our time analyzing one person's mockups.
It's not that where things lay out on an application screen doesn't matter (it does). It's that the layout should stem from the underlying purpose of an application and how we represent the system that enables it to people.
The mockup was never the hard part. AI has made that abundantly clear.
2026-05-05 22:00:00
About a hundred senior designers and leaders from AI labs, big tech companies, and startups got together in San Francisco last week for the Design Futures Assembly. The public conversation about AI and design tends to live at the extremes: either everything is about to be automated or none of this works and we're killing the planet. The conversation in that room was different.

Almost all designers are using AI tools multiple times a week. The average number of AI tools in a designer's toolkit doubled in the last year. And that's just off-the-shelf tools. It doesn't include the ones people are building themselves.
At the same time, design leaders and organizations are looking for the go-to stack: what tools should my team be using? The honest answer from the people closest to the frontier was... there isn't one. At some of the best teams, the stack is dozens of internal tools that change month to month. The muscle we all need to build might not be picking the one tool. It might be getting comfortable with a highly dynamic toolkit.
Because designers aren't just using new tools. They're making them. And the gap between "off-the-shelf tool" and "thing I built this morning" is collapsing. People at the assembly were building custom agents that crawl codebases and write wikis of user mental models. They were shipping to internal app stores, building custom workflows, and more.
Close to half of designers shipped AI-generated code to production. At early-stage companies, it's more. At public companies, it's less. But in all cases, designers are asking themselves: now that anyone can ship code, what can I uniquely do that others cannot?
When seeing all this, organizations start asking designers to change how they work, ship code, build tools, move faster. But they haven't made any formal changes to job roles, performance reviews, etc. The expectations are moving way faster than the incentive structures.
At one of the big companies, designers who were empowered to ship to production started fixing small annoyances that customers hit 50 times a day. The customer response was overwhelmingly positive. But those fixes weren't what product management would have prioritized. How does that get resolved?
When everyone can ship, you get a different kind of problem. One design leader described it perfectly: they let everyone build and push whatever they wanted. And you could feel it in the product, because nothing made sense together.
Several people at the assembly used the word "editorial" to describe where design leadership is heading. Less about making the thing, more about deciding what gets made and ensuring it all holds together. The skill of saying no is becoming one of the most important skills in the profession.
One tool company founder used the word "coherence" instead of editorial, which I liked even more. Across every medium, you know when something feels singular, like it came from one shared point of view. That's what's at stake when everyone has the power to build.
Yet anything you think the models can't do, they probably will do faster than you expect. And taste, the thing designers most often cite as their safe island? Consensus was choosing a good UI or even generating one is pattern matching, and models do that and will keep doing it better.
But several people pointed to something harder to automate: figuring out what to ask in the first place. Reading between the lines in a user research session. Noticing the tiny turn of phrase that reveals what someone actually needs. Deciding what matters, not just what works. Will models also outpace us there? We'll find out soon.
The role is expanding. The boundaries are blurring. Designers are building, coding, shipping, making tools. Whether the organizations around them are ready for that is a different question. The measurement, the incentives, the processes, none of that has caught up yet. And until it does, we're in a strange in-between: doing different work in the same old organizations.
Someone at the assembly asked the question directly: what do we call ourselves? It got a laugh but it's a real tension underneath all the practical changes. Designers can ship code. PMs can make prototypes. Engineers can generate UIs. The boundaries that used to define the role are blurring.
For my part, I've always held the most important role of designers is fighting for the coherency, simplicity, and visual communication needed to humanize technology in a way that makes it work for people, not the other way around. New tools don't change this. New ways of working together do. Which is what we dug into into our Design Futures session Finally, the Handoff is Dead (full notes at the link).
Big thanks to Jeffrey Veen for hosting and everyone I got time to reconnect with and meet. Let's do it again soon.
2026-04-30 22:00:00
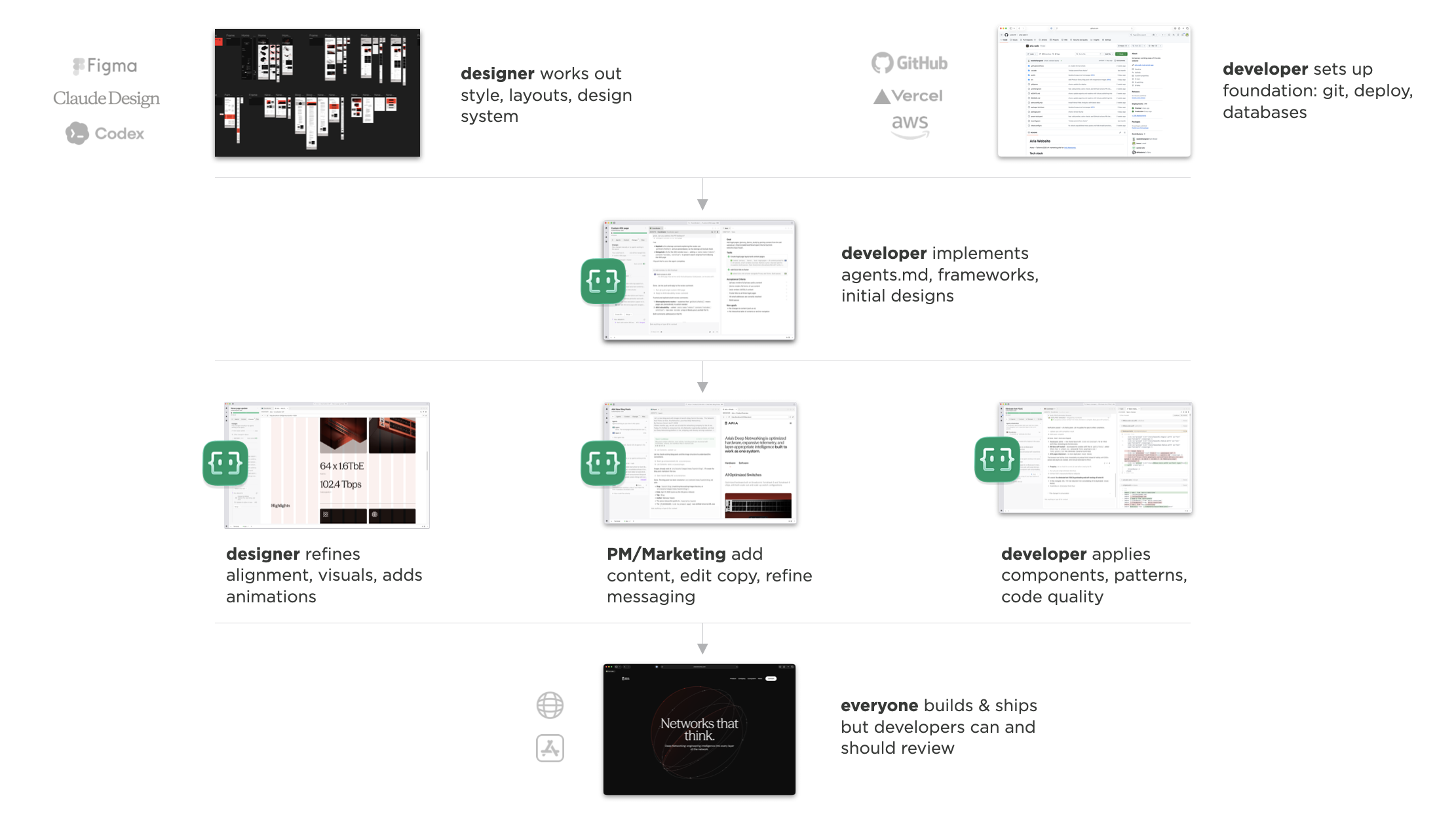
The designer/developer handoff has been with us for years. And even though today's AI tools are dramatically increasing everyone's output, the walls between disciplines haven't changed. So now we're throwing more stuff over the wall, faster. We've been iterating on a different workflow, which Amelia Wattenberger and I demoed at Design Futures Assembly.
Most companies have years of cemented process. Changing how designers and developers work together means unwinding habits, tools, and politics that have been building for a long time. We're in a different situation because we're spinning up new companies regularly. Which means we can recreate the design/dev process each time. And as the technology evolves and we learn what works, we adapt and carry those lessons into the next one. Today we'll share our current approach.

Where a lot of the discourse on AI is these days, and where a lot of AI tools are at, is individual empowerment. Designers saying: "I can finally ship code, I don't even need developers anymore." Developers saying the reverse.

But very few people are actually asking the question: how do we use AI to work better together?

Because pretty much everybody, in this room and beyond, is working with other people. And that's where the magic lies. Being able to pull multiple folks, their skills, and their experience together to create something better than you could do yourself.
Why doesn't this kind of collaboration happen already? As user experience, front-end development, and product management have matured as disciplines, we've fallen into a throw-it-over-the-wall modality. Partially because as these roles have matured, specific tools have been made for designers, like Figma. Likewise specific tools for developers, tools for PMs, et.c
And now we're adding a lot more tools, thanks to AI. So we're all able to produce more at a higher rate. Which means we're more throwing stuff over the wall faster. That's why you hear stories of developers just being overwhelmed with PRs as everyone starts "shipping" their ideas.

That applies to big complex projects but also nearly everything we do. Like publishing a blog post on your Web site. Maybe these days, the PM writes the content in ChatGPT, the designer makes the assets in Nano Banana, the developer writes the code in Codex. Everyone's productive, but are they aligned?
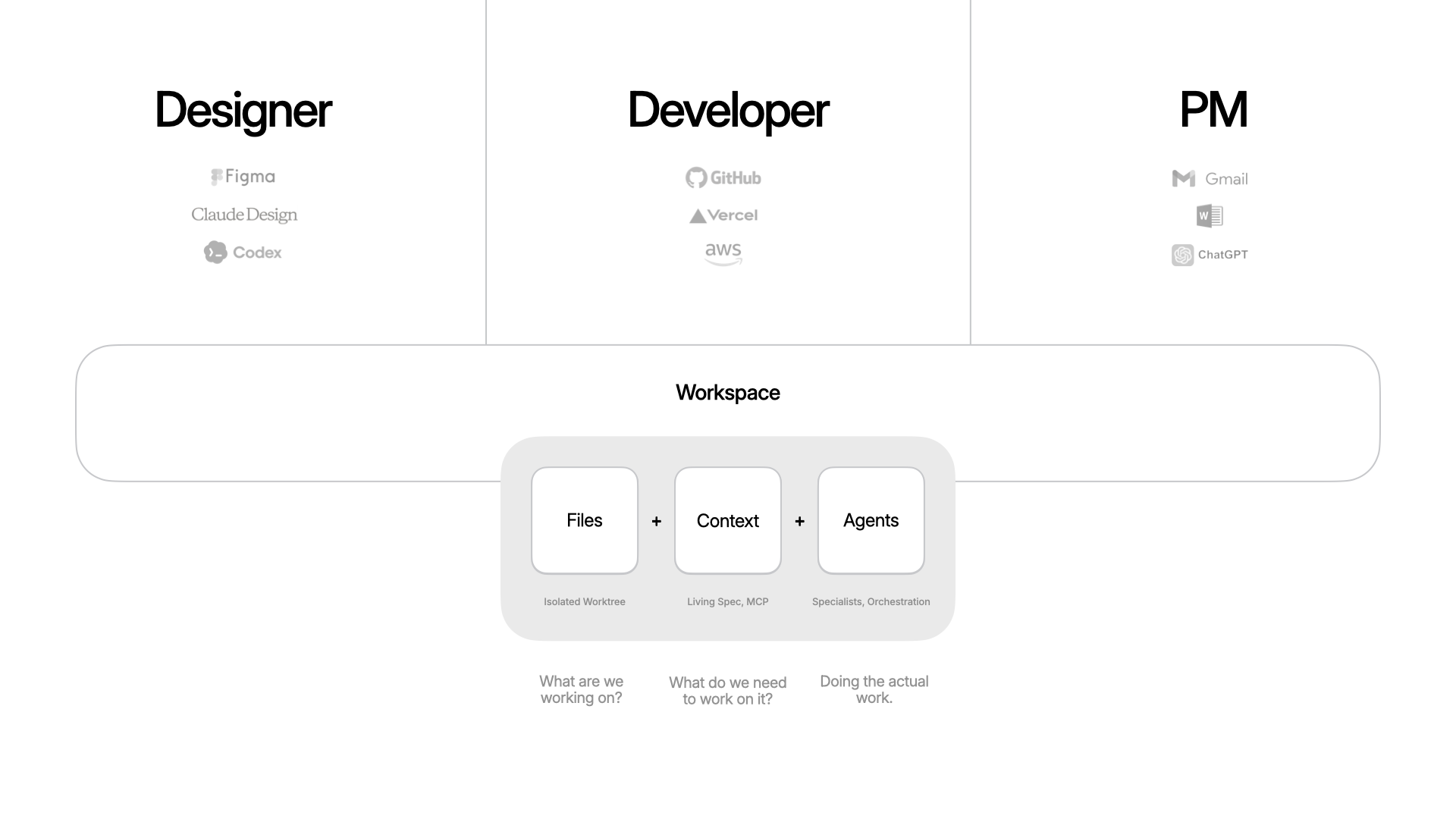
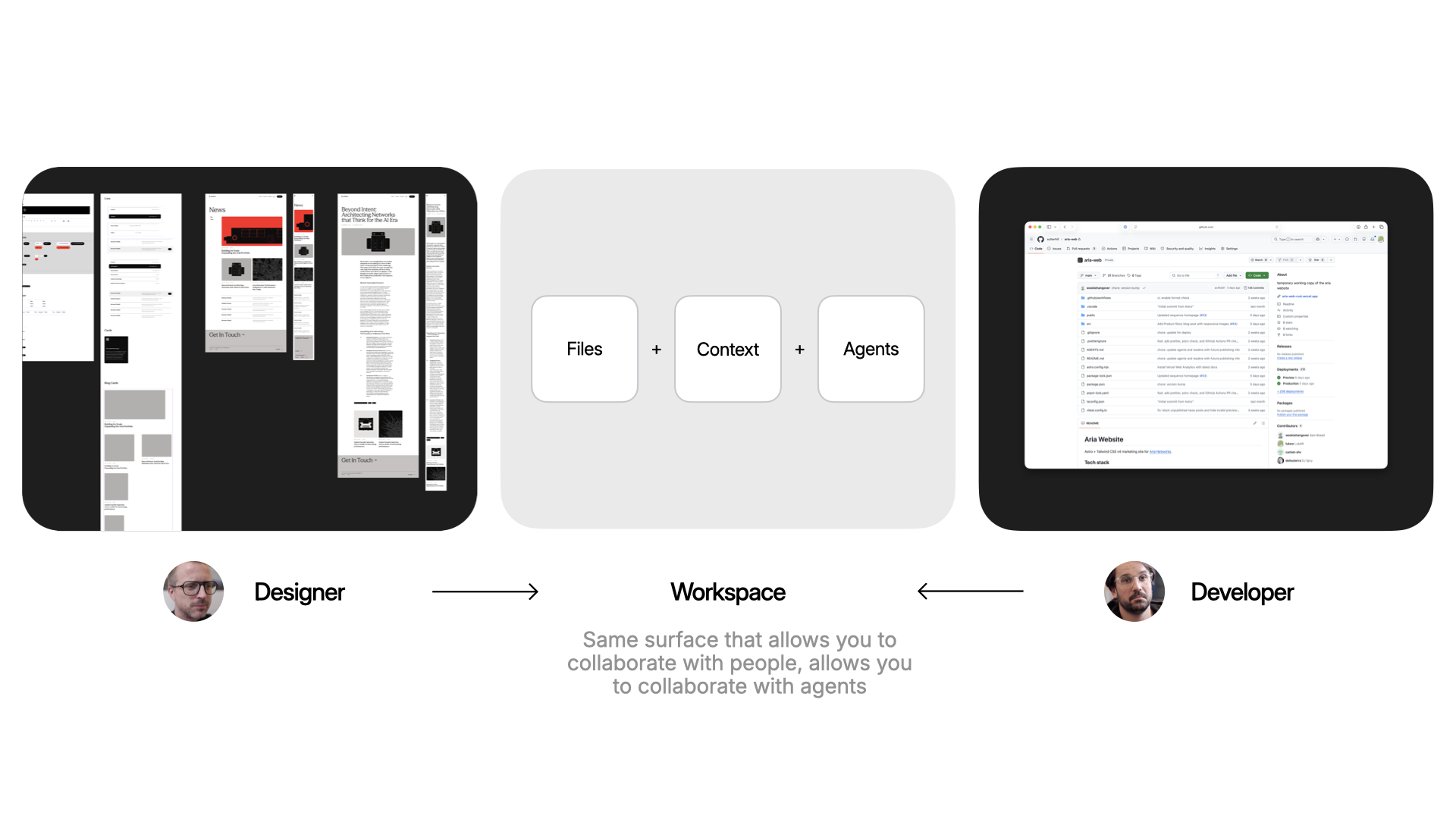
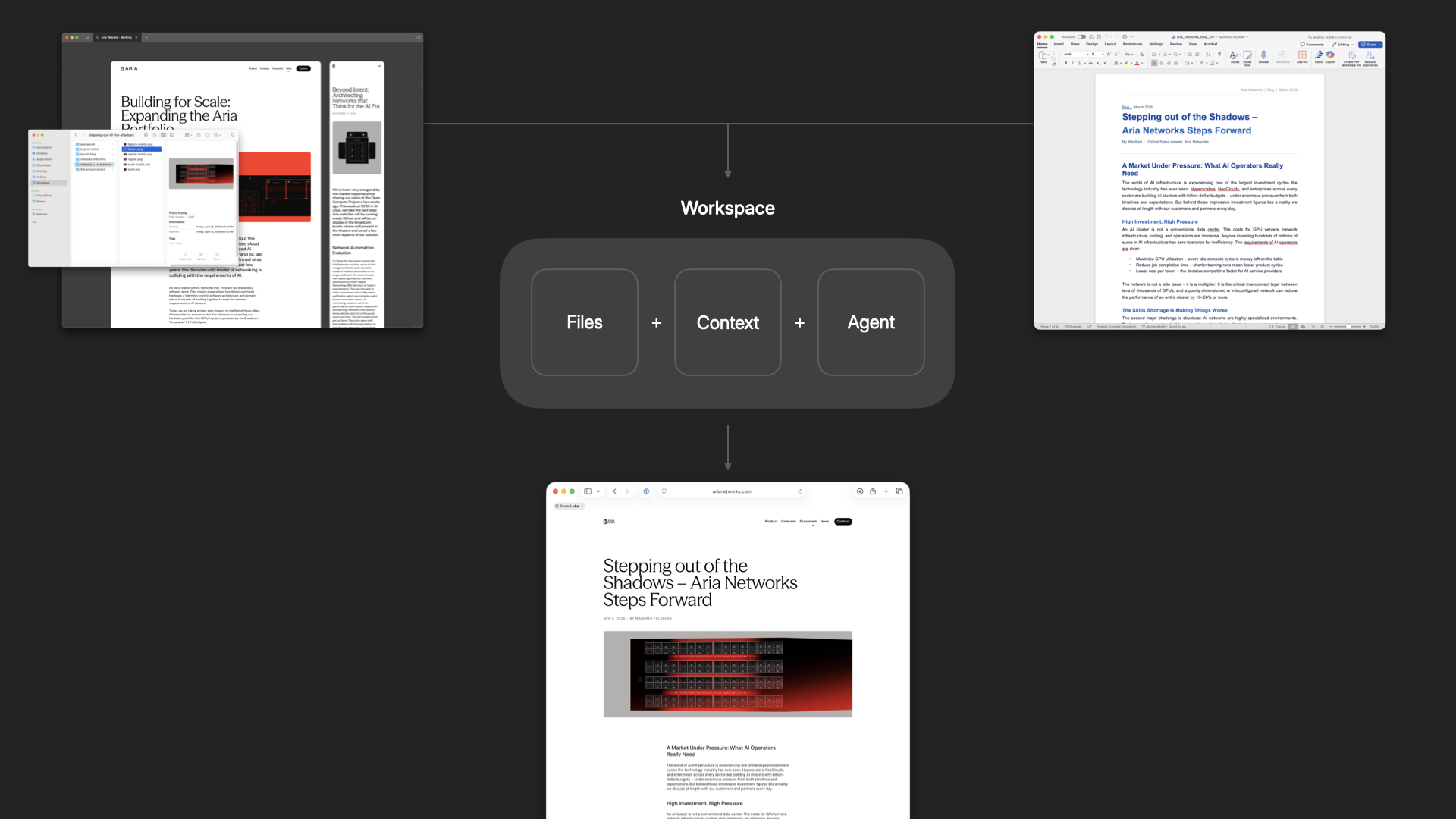
To help solve this, we've been building an app called Intent. The goal: make it easier to build software together. For any task, you spin up a workspace, which is a bundle of everything you need. Files (an isolated copy of the codebase, so you can change without messing up what others are doing), context (specs, scratchpad, data from external systems via MCP, etc), and agents (with tools and the ability to delegate and orchestrate work). Because these are all in one bundle, it becomes easier to put things down, pick them up, and hand them off.
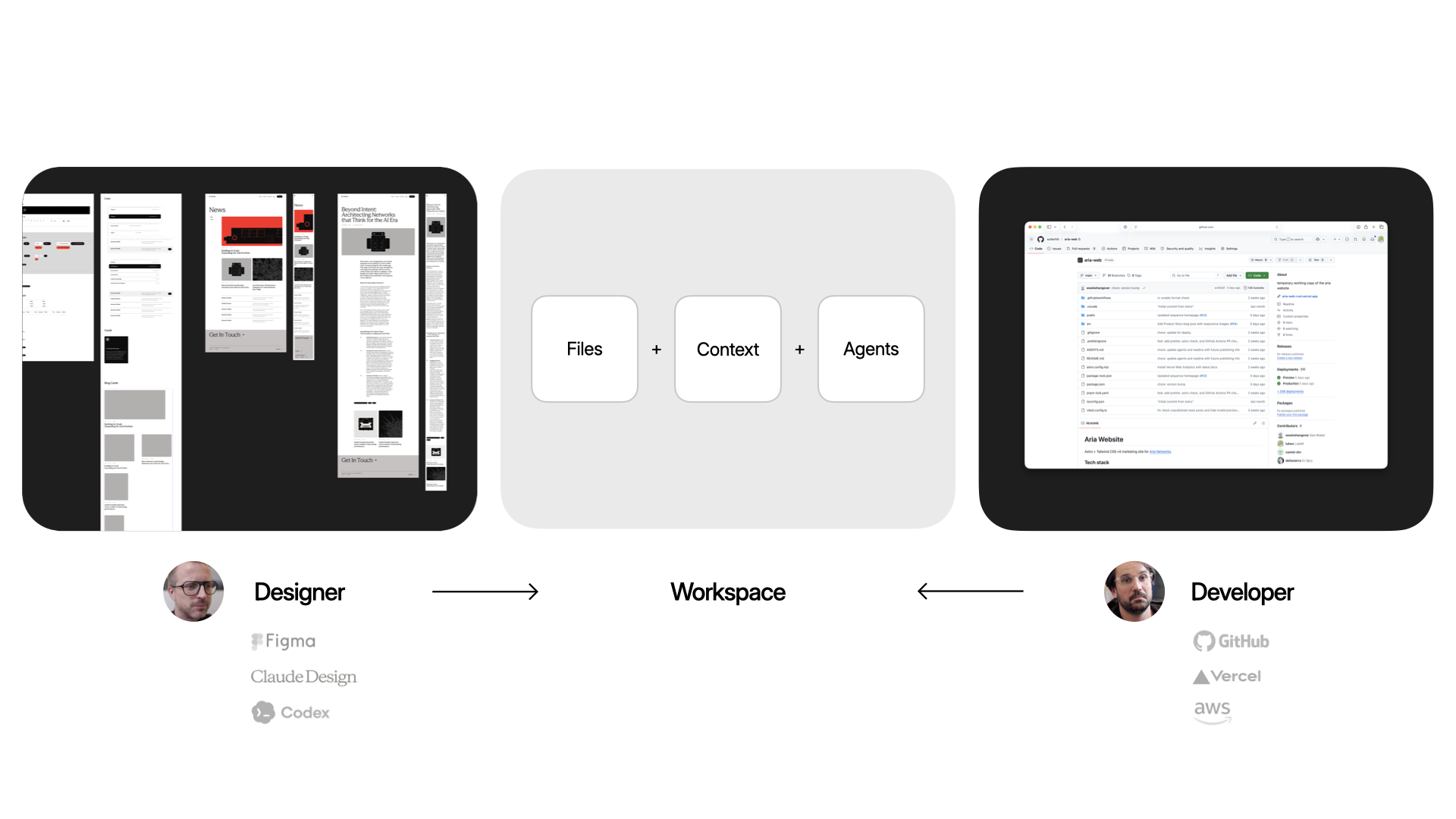
Here's why that matters in practice. A designer keeps working where they already work (like Figma or paper) and brings their expertise into the workspace: grid, typography. That all gets encoded. A developer gets to work in their tools: CSS frameworks, deployment, structure. Same surface, different expertise.
The same surface that makes it easy to collaborate with people on your team is the same one that makes it easy to collaborate with agents. And true collaboration means respecting everyone's taste. So any workspace that gets spun up will align with how the designer encoded the styles to work and how the developer encoded the code to work.
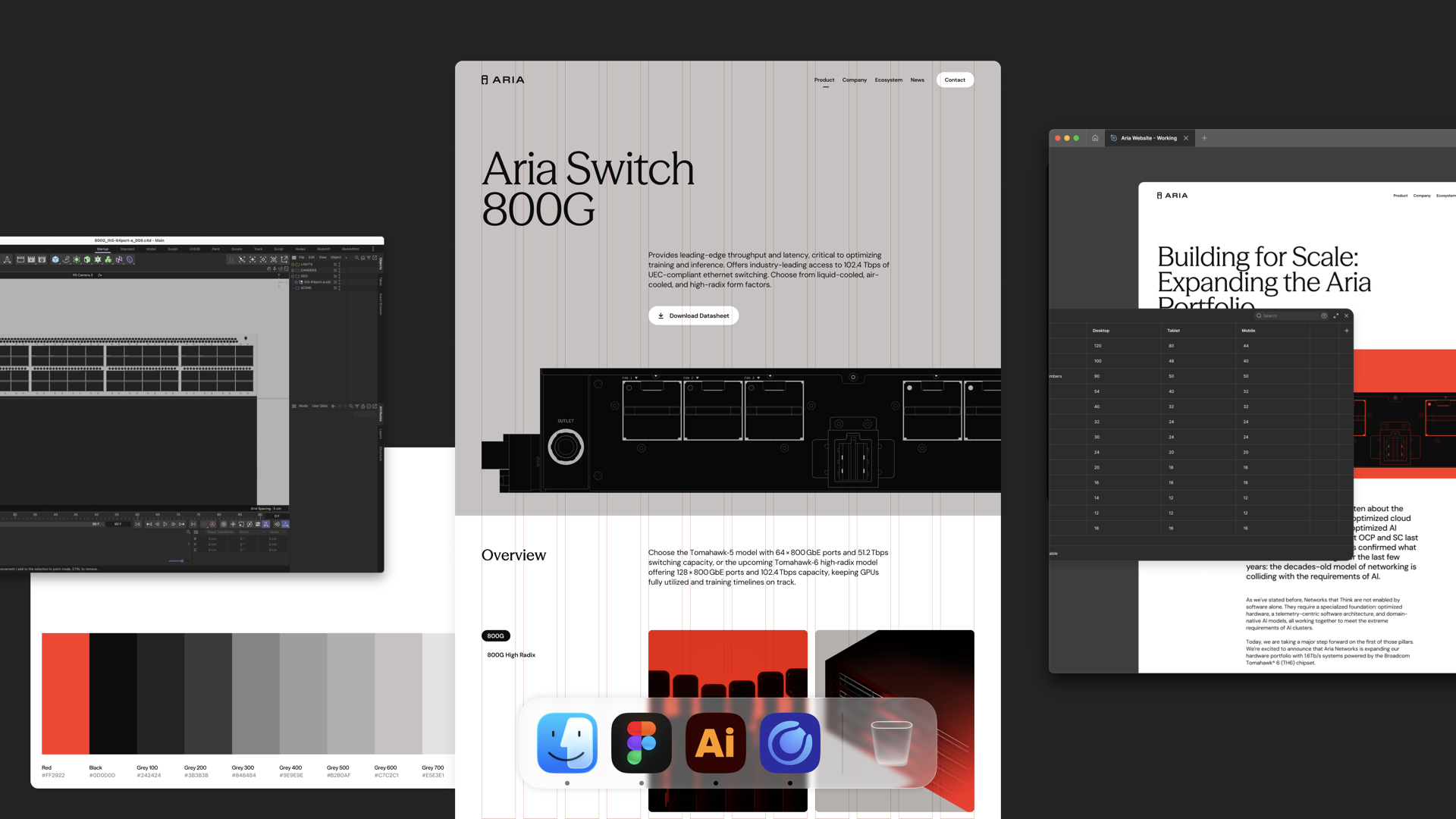
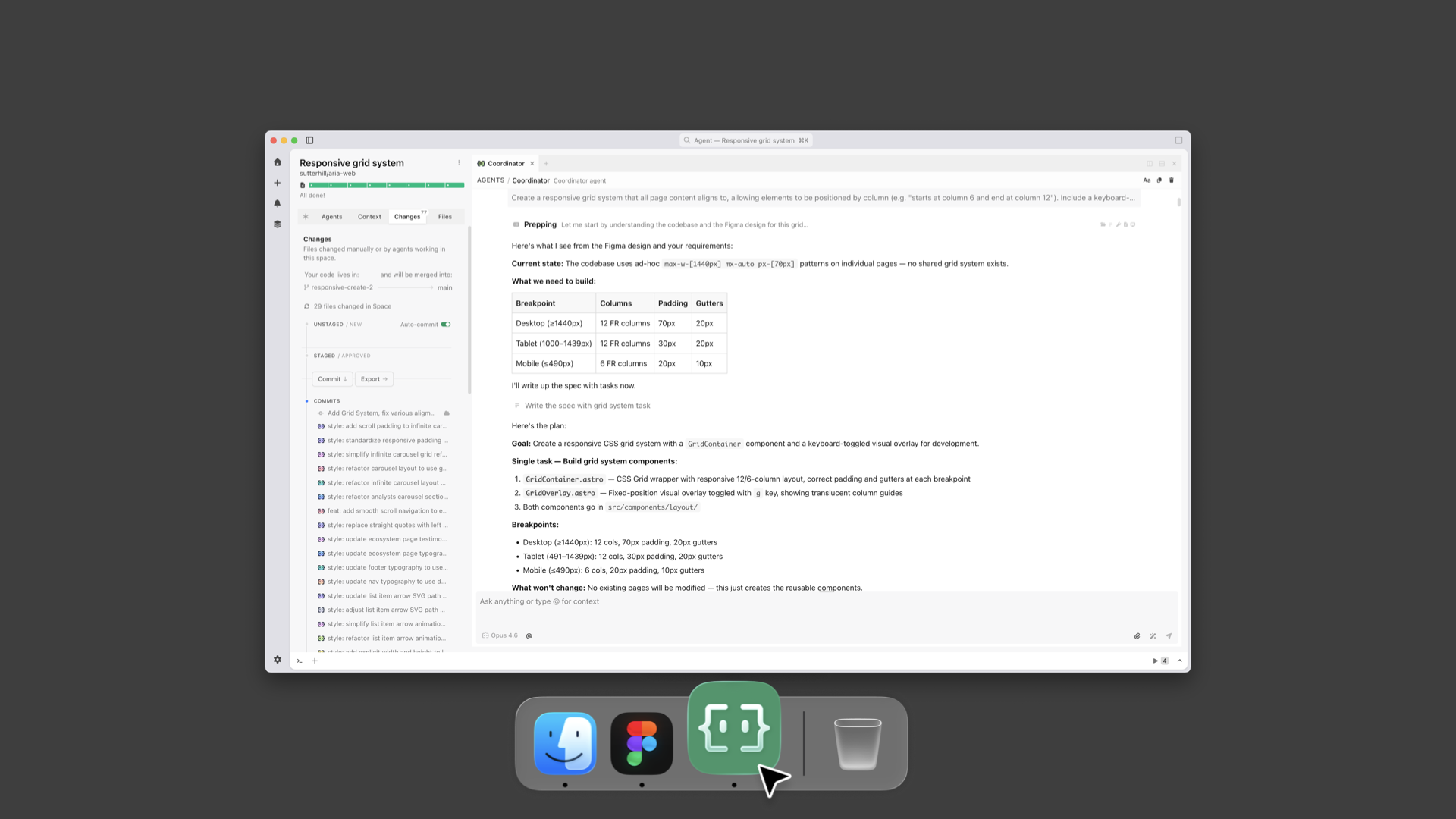
To illustrate as a designer, I've got a Figma file with a grid and layouts. I go into a workspace in Intent and say: "Agent, look at the Figma file. Create the grid. Here's what the breakpoints are." Now that's encoded in the workspace and anybody that creates a new page or drops in a new asset, it works within that system.
I can also set up how animations should work to give everything made in the workspace silky smooth transitions.
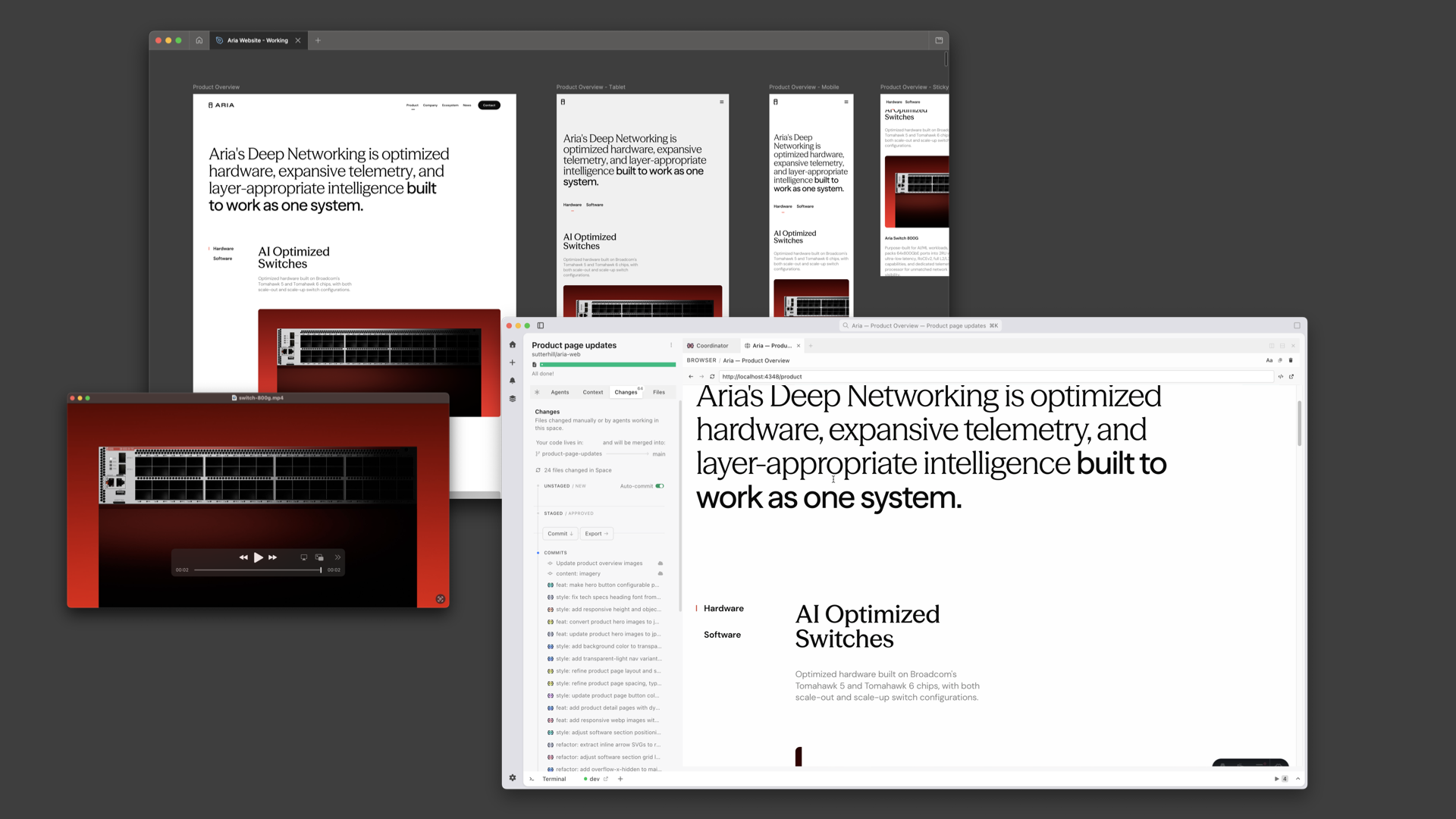
Same idea on the developer side. The dev can say: here's the agent's MD file, here's how we're testing the code, here's the tailwind config. The agent encodes all of that.
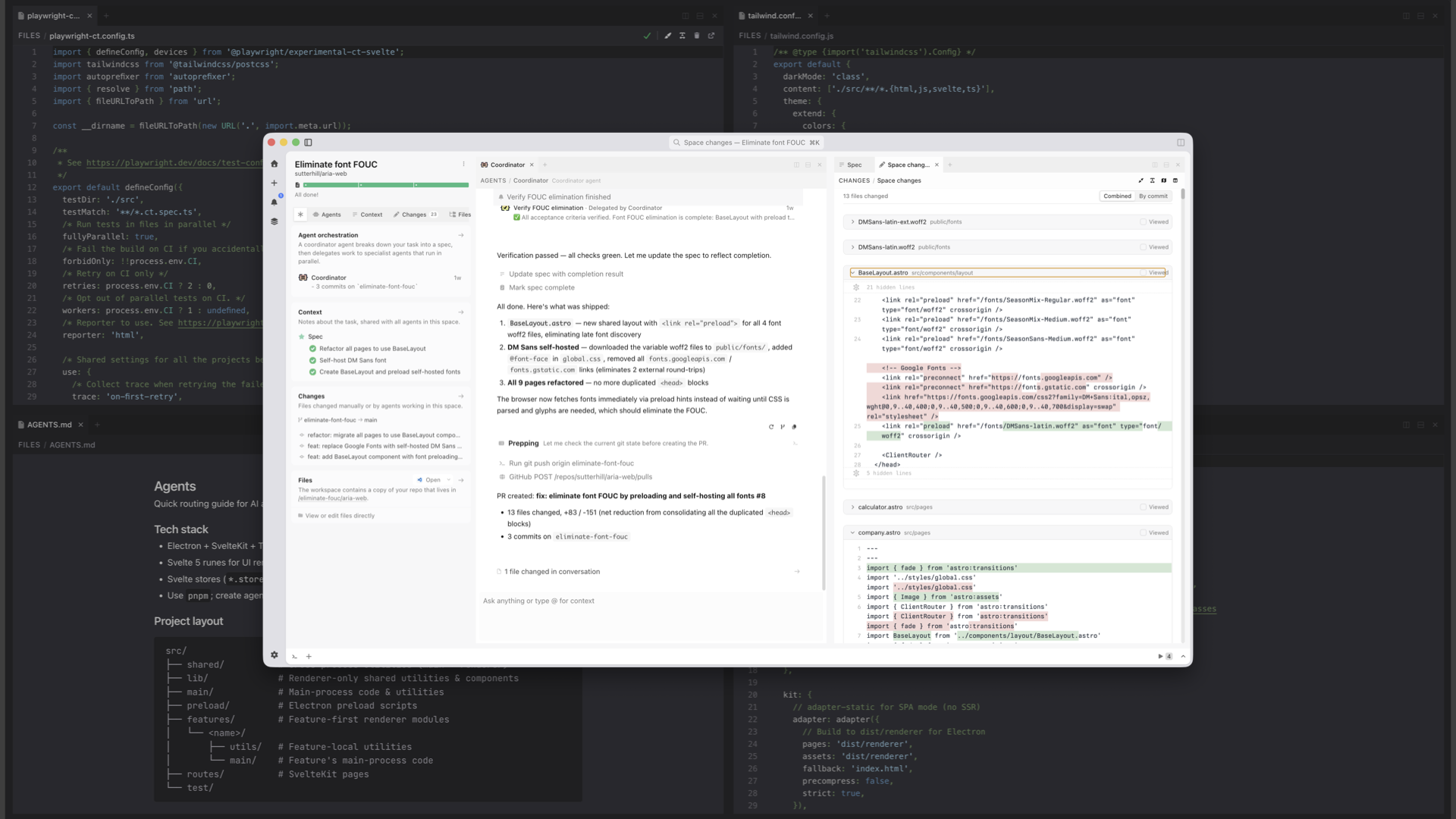
Taste gets baked into code files and markdown files in the repo. And because things are built on top of the same version control that developers use, it gets automatically included into every new workspace.
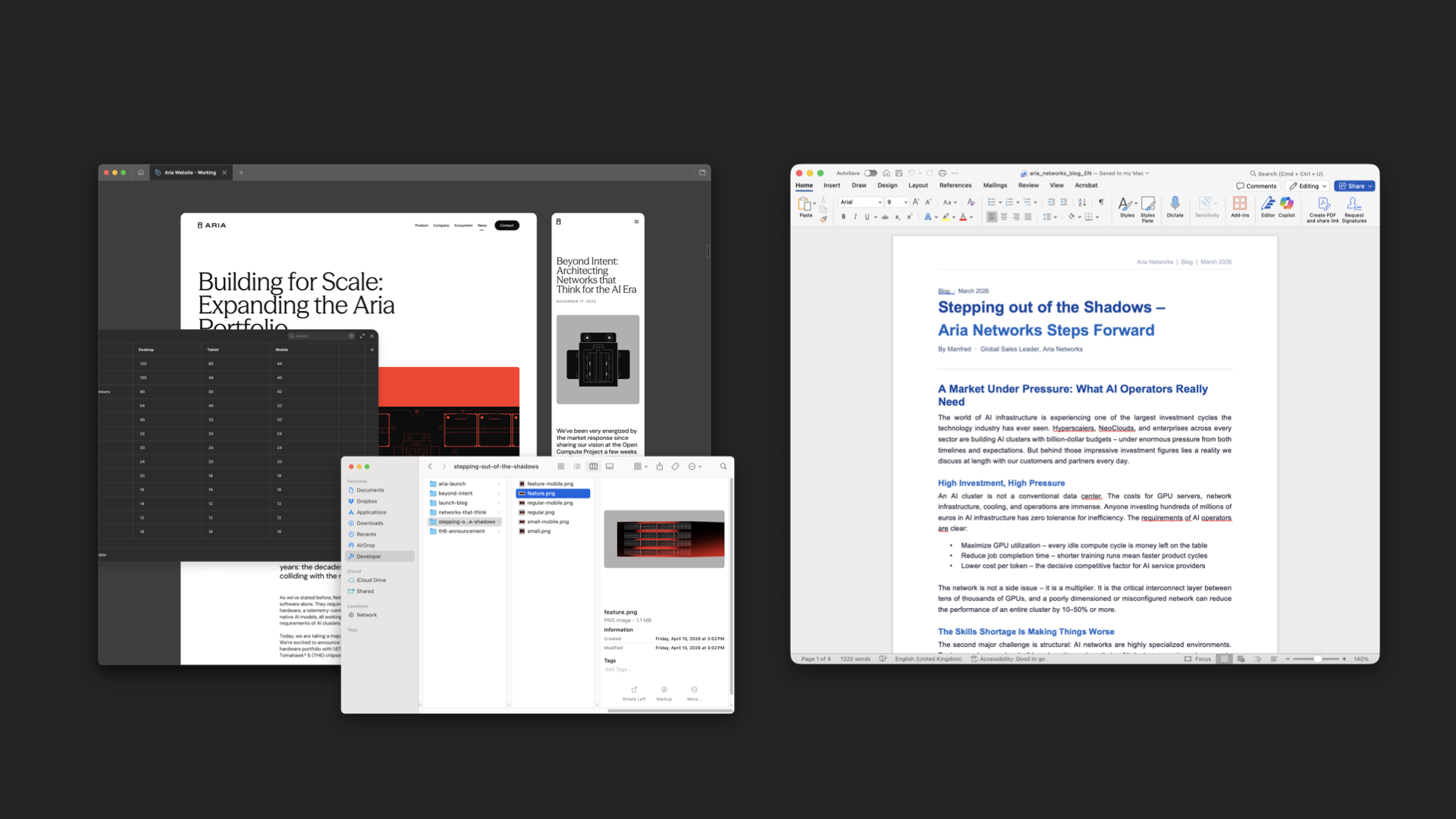
The great thing is that this same pattern works for anybody on the team. An illustrator can use their own tools to make assets. A content writer can write their copy in Word.
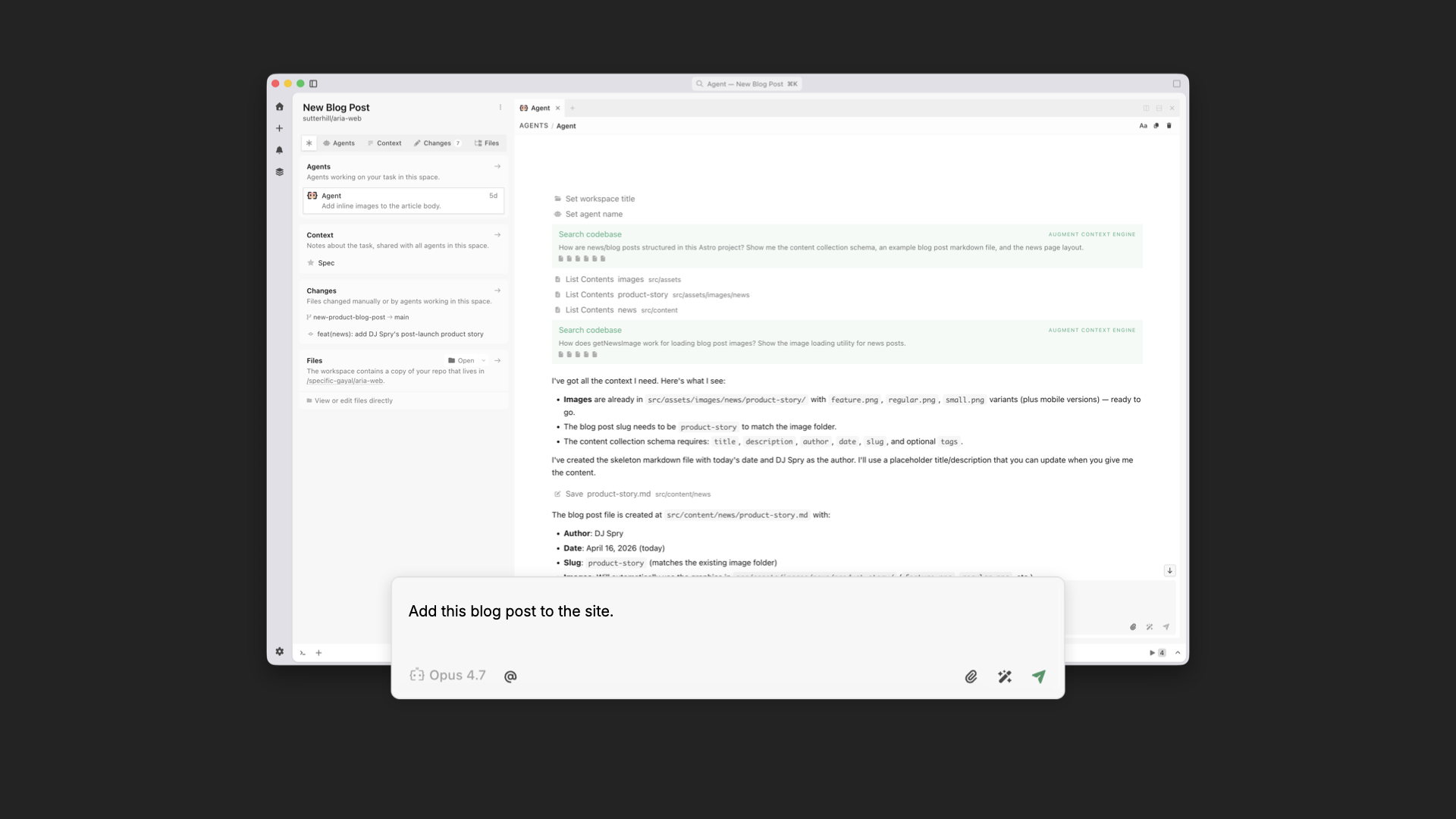
Then anybody on the team can spin up a workspace and say: we're making a blog post, here are the assets, here's the Word doc. Because that workspace already includes the designer and developer's tastes, what pops out the other end is a blog post that's fully aligned with the rest of the site.
You can also run these workspaces in parallel so many people can be working on different parts of the experience simultaneously. And because every workspace is encoded in the same way, everything that gets added ends up unified by default.
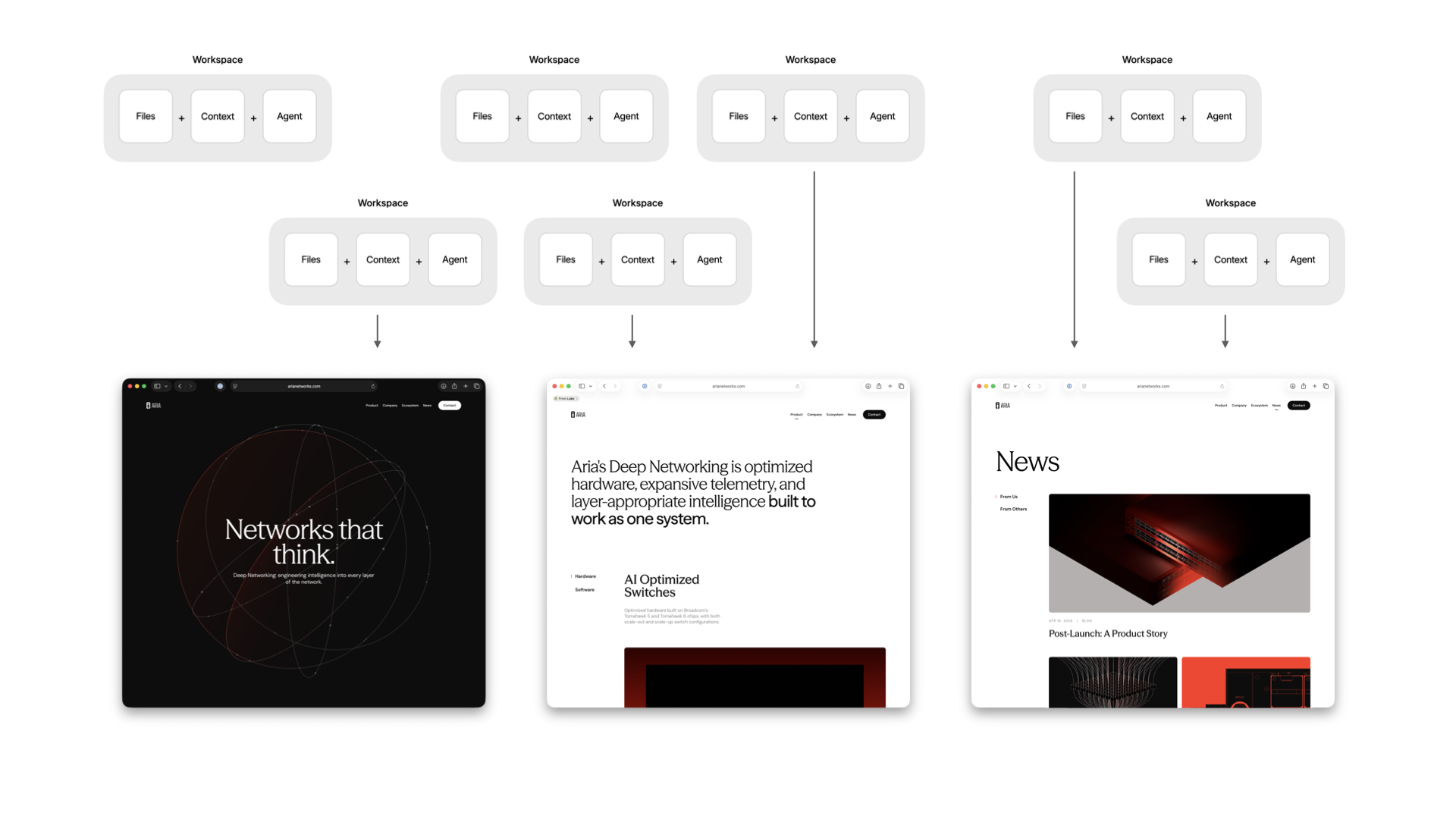
This gives us massive parallelism and the ability to accommodate all kinds of last-minute requests. Which, even in an age of AI, still happen. Here's me busting out 10 last-minute 8pm asks in minutes using multiple workspaces without messing up the design or code integrity of the site.
AI tools are making individuals faster, but speed isn't the problem. Cohesion is. When taste is encoded into a shared workspace in Intent, designers keep designing, developers keep developing, and everything that comes out the other end holds together. No handoffs necessary.