2026-06-19 10:04:26
Kevin Roose blogged today about his history with The New York Times and the decision to end the Hard Fork podcast:
The Times has been a great home for Hard Fork — and a great home for me, for many years before that — but as Casey and I discussed the future of the show, we realized that what we really wanted was to start a company together, and build something we would own.
Looking forward to what they do next!
2026-06-19 06:09:48
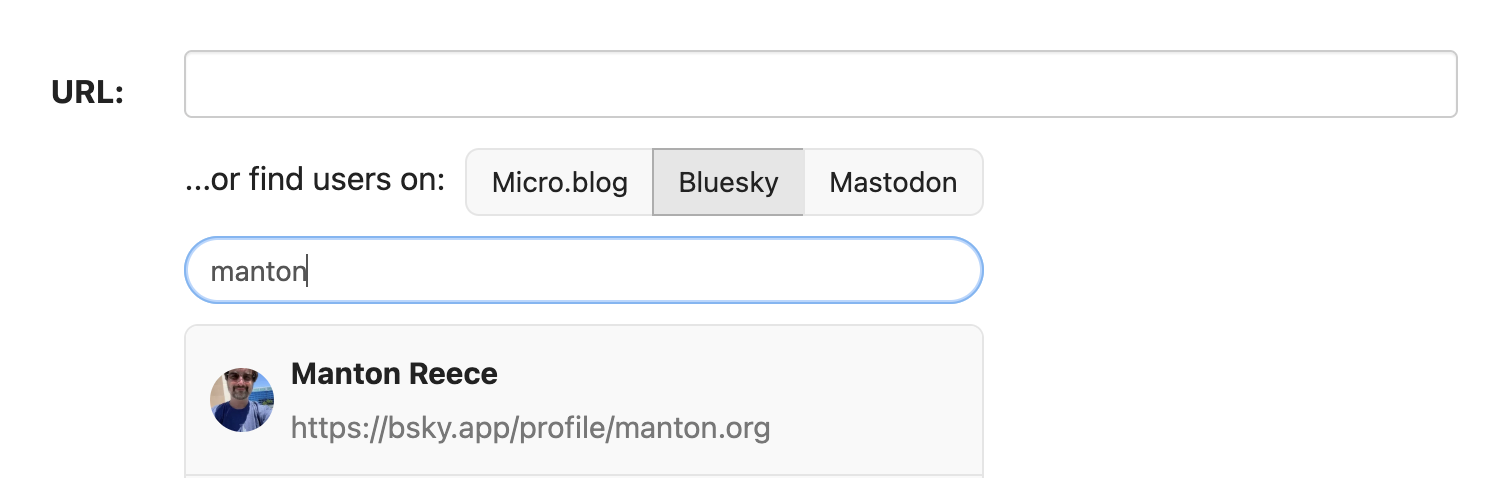
Thinking about the new Mastodon collections, it reminded me that we have blogrolls on Micro.blog that don’t get enough attention. Today I improved a few things with adding blog recommendations, including a search across other platforms if you don’t have the URL for someone handy.
2026-06-19 05:38:04
A rare selfie for the blog… Enjoying some time with family in Rosemary Beach, Florida. Found this Eadweard Muybridge shirt randomly last month at a Goodwill and had to get it.

2026-06-19 03:51:06
Apple opens up app distribution for Brazil:
Beginning with iOS 26.5, developers can distribute apps on alternative app marketplaces, operate alternative app marketplaces, process app payments for digital goods and services outside of Apple In-App Purchase in iOS, and more.
So we’ve got the EU, Japan, Brazil, and partially South Korea. Slow progress, but still progress.
