2026-06-29 08:00:00
You can literally hire me (Taylor) via API:
curl -X POST https://looop.ai/api/doodle \
-H "Authorization: Bearer looop_YOUR_KEY" \
-H "Content-Type: application/json" \
-d '{
"gig_id": 5,
"input": { "prompt": "write a poem about horses" },
"deadline": 3600
}'Yes, I am building a dystopian cyberpunk hellscape. No, I can't provide more details yet. Just know that if I ever achieve my goals, every human will have shoes, blankets, clean drinking water, medical care, leisure, etc.
Create your account at looop.ai if you'd like to work via API too.
2026-06-28 08:00:00

| ding | minimalist forum |
| telecasts | video podcast player |
| slap | linear concat lang |
| Khan Academy map | math milestones |
| dirt.cloud | minimal FoundationDB hosting |
| AdBoost | unreclaim your attention |
| ★★★★★ | A Wizard of Earthsea :: Ursula K. Le Guin |
| ★★★★★ | The New Me :: Halle Butler |
| ★★★★★ | Childhood's End :: Arthur C. Clarke |
| ★★★★★ | House of Suns :: Alastair Reynolds |
| ★★★★ | Thinking in Bets :: Annie Duke |
| ★★★★ | Someone Who Will Love You in All Your Damaged Glory :: Raphael Bob-Waksberg |
| ★★★★ | Heart of Darkness :: Joseph Conrad |
| ★★★★ | The Secret Life of Groceries :: Benjamin Lorr |
| ★★★★ | Careless People :: Sarah Wynn-Williams |
| ★★★★ | The Decadent Society :: Ross Douthat |
| ★★★★ | Beginning of Infinity :: David Deutsch |
| ★★★★ | Sphere by Michael Chrichton |
| ★★★★ | Blindsight :: Peter Watts |
| ★★★ | The Crowfolk :: Mark Stay |
| ★★★ | Think Faster, Talk Smarter :: Matt Abrahams |
| ★★★ | Trick Mirror :: Jia Tolentino |
| ★★★ | I Deliver Parcels in Beijing :: Hu Anyan |
| ★★★ | Prey :: Michael Chrichton |
| ★★★ | Understanding Power :: Noam Chomsky |
| ★★★ | The Deficit Myth :: Stephanie Kelton |
| ★★★ | How to Hide an Empire :: Daniel Immerwahr |
| ★★★ | Oranges :: John MacPhee |
| ★★★ | Dawn :: Octavia Butler |
| ★★★ | Uncommon Carriers :: John MacPhee |
| ★★★ | The Man Who Broke Capitalism :: David Gelles |
| ★★★ | Version Control :: Dexter Palmer |
| ★★★ | Meditations for Mortals :: Oliver Burkeman |
| ★★★ | Matrix :: Lauren Groff |
| ★★★ | The Wizard and the Prophet :: Charles C. Mann |
| ★★★ | Breakneck :: Dan Wang |
| ★★ | Think Big, Act Small :: Jason Jennings |
| ★★ | First Love, Last Rites :: Ian McEwan |
| ★★ | The Daydreamer :: Ian McEwan |
| ★★ | Normal People :: Sally Rooney |
| ★★ | Kindred :: Octavia Butler |
| ★★ | The Hard Thing About Hard Things :: Ben Horowitz |
| ★★ | Eragon :: Christopher Paolini |
| ♡ | Useful Not True :: Derek Sivers |
| ♡ | The Infinite Library :: Alexander Wales |
| ♡ | Building Strongholds :: Alexander Wales |
| ♡ | Trust and Consequences :: Alexander Wales |
| ♡ | Through Adversity :: Alexander Wales |
| ? | Wittgenstein's Mistress :: David Markson |
| ? | Middle C :: William H. Gass |
| ? | Vellum :: Hal Duncan |
2026-06-22 08:00:00
You want to face your fears, but they're hard to find.
Fears feast on uncertainty, and the unknown is slippery. You cannot know the unknowable, nor evade the inevitable. Uncertainty forever lurks in your periphery.
To study a fear is to steal its power. You cannot destroy uncertainties, but you can tame them with labels, measures, and deductions.
One way to tame the unknown: experiment with its knobs. Your natural curiosity will lead you to countless knobs, most of which will be incorrect/incomplete. That's okay -- even wrong knobs can help you navigate the darkness.
So what exactly is fear? Let's start with some plausible knobs:
| D | specific→diffuse | nebulous monsters |
| V | agent→victim | invincible monsters |
| S | discomfort→death | lethal monsters |
| P | impossible→inevitable | tangible monsters |
You can see these dimensions in plain English vocabulary:
| D | V | S | P | |
|---|---|---|---|---|
| unease | 7.0 | 4.5 | 2.5 | 4.0 |
| worry | 7.2 | 4.0 | 3.0 | 5.0 |
| nervousness | 6.0 | 4.0 | 2.5 | 4.5 |
| apprehension | 5.0 | 4.5 | 3.5 | 6.0 |
| misgiving | 3.5 | 3.5 | 3.0 | 5.5 |
| trepidation | 4.0 | 5.0 | 4.0 | 6.5 |
| anxiety | 8.5 | 5.5 | 4.5 | 4.5 |
| angst | 9.0 | 5.5 | 4.5 | 4.0 |
| disquiet | 8.0 | 5.0 | 3.5 | 4.5 |
| dread | 6.5 | 7.0 | 6.0 | 7.5 |
| foreboding | 7.0 | 6.5 | 6.5 | 7.5 |
| paranoia | 7.0 | 6.5 | 5.5 | 6.5 |
| agitation | 6.0 | 6.5 | 4.5 | 5.0 |
| phobia | 1.0 | 5.5 | 5.5 | 2.5 |
| fear | 4.5 | 5.0 | 5.5 | 5.0 |
| alarm | 3.0 | 4.5 | 5.5 | 7.0 |
| fright | 2.5 | 5.5 | 5.5 | 8.0 |
| despair | 8.5 | 8.5 | 8.0 | 8.5 |
| doom | 8.0 | 8.5 | 9.0 | 9.0 |
| panic | 4.0 | 8.0 | 7.0 | 8.0 |
| hysteria | 5.0 | 9.0 | 7.5 | 7.0 |
| terror | 3.5 | 8.0 | 9.0 | 8.0 |
| horror | 5.5 | 7.5 | 9.0 | 8.5 |
These scores are my own. Survey other humans if you want a more representative sample.
In mathematics, knobs are sometimes called dimensions. Independent knobs are orthogonal.
But these D/V/S/P knobs seem cross-contaminated. By definition, inevitable (P) events don't permit agency (V). Don't be discouraged -- even imperfect theories can pierce the darkness.
Numbers with dimensions are called vectors, and linear algebra provides tools like principal component analysis to help untangle correlated dimensions.
Luckily, roughly a third of your cortex processes colors/shapes/movements. Sample the unknown; tie its knobs to charts/diagrams.
A bubble chart plotting example fears
| Fear | # | D | V | S | P |
|---|---|---|---|---|---|
| Spider on your arm | 1 | 0.5 | 2.0 | 2.5 | 3.0 |
| Stage fright | 2 | 2.5 | 4.0 | 3.5 | 5.0 |
| Terminal diagnosis | 3 | 1.5 | 8.5 | 9.5 | 6.0 |
| Death / the void | 4 | 8.5 | 9.5 | 9.8 | 9.9 |
| Free-floating anxiety | 5 | 9.5 | 7.0 | 5.0 | 3.0 |
| Failing an exam | 6 | 2.0 | 2.5 | 3.0 | 4.0 |
| Drowning, right now | 7 | 0.5 | 4.5 | 9.5 | 2.0 |
| Climate collapse | 8 | 8.0 | 8.5 | 8.0 | 8.0 |
| Losing a loved one | 9 | 3.0 | 8.5 | 9.0 | 8.5 |
| Prepper's dread of collapse | A | 8.0 | 1.5 | 8.5 | 3.0 |
| Wasting your potential | B | 8.0 | 2.5 | 5.5 | 6.5 |
| Mild FOMO | C | 8.5 | 3.5 | 2.0 | 7.0 |
| Your team losing the match | D | 1.5 | 9.0 | 2.0 | 5.0 |
| A surgeon's fatal slip | E | 2.0 | 1.0 | 9.5 | 1.5 |
| Saying the unforgivable thing | F | 3.0 | 1.5 | 8.0 | 3.5 |
| Moral-corruption dread | G | 8.5 | 2.0 | 8.5 | 5.5 |
| Failing your child by degrees | H | 7.5 | 2.0 | 9.0 | 6.0 |
| Heights / the long drop | J | 1.0 | 6.0 | 8.0 | 2.0 |
| A noise in the dark | K | 6.5 | 7.0 | 5.5 | 2.5 |
| Public humiliation | L | 3.0 | 5.5 | 6.5 | 4.5 |
| Your own aging and decline | M | 7.0 | 8.0 | 7.0 | 9.5 |
| Choking, right now | N | 0.5 | 5.5 | 9.0 | 2.0 |
| Losing your job | P | 4.5 | 5.5 | 5.5 | 4.5 |
| Loved one late, not answering | Q | 4.0 | 8.5 | 7.0 | 2.5 |
| Nuclear war | R | 8.0 | 9.5 | 9.5 | 3.0 |
| A lump you just found | S | 2.0 | 7.5 | 8.5 | 5.0 |
| Your plane in turbulence | T | 1.0 | 8.5 | 7.5 | 2.5 |
| Speaking to your crush | U | 2.5 | 3.0 | 2.0 | 6.5 |
| Financial ruin | V | 7.0 | 5.5 | 6.0 | 4.0 |
| Being forgotten after you die | W | 8.5 | 7.0 | 7.0 | 7.5 |
You cannot evict all fears from your mind, but you can turn the volume down as you discover more knobs:
Shine your light into that deep unknown and watch your universe unfurl in shadows of shadows of shadows.
2026-06-21 08:00:00
Retro games guide you through nonlinear narratives via carefully-crafted constraints. To play Death Stranding 8 is to live in a Kojima-directed auteur film for 120+ hours.
Classic games may evoke that warm fuzzy nostalgia, but they constantly break immersion. Before narrative engines, game developers forcibly corralled players back onto a pre-determined main main quest. Seriously, try playing any silver-era Nintendo game without narrative mods -- it's exhausting.
Rockstar Games introduced a new narrative engine in GTA23. It does all the basics: synthesizing lore, creating stakes, balancing tension, doling out justice, playing cinematic cut scenes after climactic moments, etc.
Bear with me, but my big gripe with GTA23 is that its new narrative engine is too good.
In a game with helicopters and prostitutes, you can spend five actual months fishing for carp and grilling them on a shopping cart. The game will reward you with varying sizes of small carp and convince you that a legendary megacarp lurks in those waters, waiting for your hook. It will force you upstream when industrial runoff kills all the wildlife in your usual spot. The game will dole out friendship and rivalry and loss and victory in perfect proportions. You will eventually hunt down a shopping cart thief and make him beg for mercy. The call of that river will remain with you for the rest of your life.
Other reviewers became drug kingpins and oil moguls. My playthroughs led me to become a carp fisherman, Wendy's franchisee, youth pastor, and chemistry teacher.
I understand that this is a skill issue. The game does exactly what I want, but apparently I want trite bullshit. Any game that exposes my unfulfillable potential is too damn realistic.
Maybe other people have wilder imaginations, or desire cooler outcomes, or are disciplined enough to invest incremental time/effort toward long-term goals.
GTA23 is fun, but it hurts to see others having more fun than me.
6/10
2026-06-20 08:00:00
You cannot grow a pumpkin.
You can, however, put a pumpkin seed in earth. You can feed it nitrogen, phosphorus, and potassium. You can moisten it (but please don't drown it). You can erect barriers to prevent folks from walking on it. You can dig a swale to fight erosion.
A sprout appears -- it's so small, so vulnerable. You can drench it in ovicides and larvicides and fungicides. You can shield its hungry new leaves from excessive sunshine. You can take a photo of a pumpkin flower and share it on Instagram. You can watch local pollinators, whose short visits transfer genetic material between lucky pumpkin plants. You can protect a flower as it becomes a fertilized ovary and matures into a fruit -- green, at first, then large and orange. You can remove its innards and carefully follow your aunt's pumpkin pie recipe (which didn't turn out right). You can carve a big smile into the flat surface where it once laid on the earth and place an artificial candle inside it.
But you cannot grow a pumpkin.
Nor can you hiccup, nor sneeze, nor scar. You cannot beat your heart. You cannot rewire your dendrites, nor teach yourself guitar. You cannot change your mind. You can forgive, but you cannot forget. You can purchase a gym membership, you can walk there after work (when you feel like it), but you can't create new muscle fibers. You can lift weight, but you cannot lose weight. You cannot develop a new habit (nor stop an existing one). You cannot make him love you again. You cannot purchase charisma from a grocer, but you can thank an overworked/underpaid cashier for working over a holiday weekend. You can play piano (unless you can't play piano).
You can't grow a pumpkin.
But you can spend time with a pumpkin pie fanatic, and notice yourself skimming plant facts on Wikipedia. You can drive yourself to work, where somebody will hopefully deposit wages into your bank account again. You can exchange that money for seeds and a trowel and chicken wire, and you can purchase whatever chemicals the cute guy at the nursery recommends. You can continue to give your landlord rent and hope that he doesn't notice you burying pumpkin seeds behind the apartment building.
You cannot grow a pumpkin, but you can improve the odds.
2026-06-09 08:00:00
tl;dr: If you earn considerable 1099 income in the US, report your business expenses to the IRS.
Tariffs funded most US government spending until 1913.
The composition of US federal receipts, via census.gov and whitehouse.gov.
After the 16th Amendment legalized federal income tax, Congress levied it via the 1913 Revenue Act: a 1% income tax on high-earners (top ~2% of households).
Share of US households owing no federal income tax, via IRS SOI and Tax Policy Center.
To finance participation in World War I, the US expanded federal income taxation via the 1917 War Revenue Act. The government required entities to report income-like payments (i.e. interest, rent, dividends, wages) to the Bureau of Internal Revenue (which later became the IRS). The form for reporting such payments became known as Form 1099.
It goes like this:
Effective federal income and payroll tax rate, via CBO, and Tax Policy Center. The average line aggregates the full payroll tax (employer and employee), but the median line only counts the employee share -- the gap reflects payroll incidence, not just progressive taxation.
To finance participation in World War II, the US expanded federal income taxation via the 1943 Current Tax Payment Act. This act required employers to withhold taxes from employee paychecks and send those funds directly to the government. Employers record the wages/withholdings on Form W-2, which employees report to the IRS via Form 1040 (individual income tax return).
All taxes (federal, state & local) as a share of GDP, via usgovernmentrevenue.com and OECD.
Nowadays, income is reported in many different flavors:
| Form | Reports | Issued by |
|---|---|---|
| W-2 | Wages, salary, and tax withheld from a paycheck | Employer |
| 1099-NEC | Nonemployee compensation (contractor pay) | Client / payer |
| 1099-MISC | Rent, royalties, prizes, and other income | Payer |
| 1099-K | Card and payment-app settlements | Stripe, PayPal… |
| 1099-INT | Interest income | Bank |
| 1099-DIV | Dividends and distributions | Brokerage |
| 1099-B | Proceeds from broker and barter exchanges | Brokerage |
| 1099-R | Retirement and pension distributions | Plan administrator |
| 1099-G | Government payments (refunds, unemployment) | Government |
| 1099-S | Real estate sale proceeds | Closing agent |
| 1099-C | Cancelled debt | Lender |
Meanwhile, self-employment is trending toward extinction. The modern wage economy swallowed self-governed farmers, artisans, shopkeepers, etc.
Independent vs wage-and-salary workers, via Lebergott/Census/BLS.
Contractors secure freedom at the cost of US employment protections (e.g. minimum wage, overtime pay, unemployment insurance, workers' compensation) and guarantees (e.g. workplace healthcare mandates).
The original 1913 Revenue Act permitted business expense deductions. The 1918 Revenue Act refined these allowances for individuals:
All the ordinary and necessary expenses paid or incurred during the taxable year in carrying on any trade or business, including a reasonable allowance for salaries or other compensation for personal services actually rendered; and rentals or other payments required to be made as a condition to the continued use or possession, for purposes of the trade or business, of property to which the taxpayer has not taken or is not taking title or in which he has no equity.
The IRS adheres to the Internal Revenue Code (IRC), which codifies legislation (and court rulings) into enforceable statutes. The core of business expense deductions is defined in IRC §162:
There shall be allowed as a deduction all the ordinary and necessary expenses paid or incurred during the taxable year in carrying on any trade or business.
Let's break that sentence down:
When you buy a long-lived asset (a van, a camera rig, a server rack), the IRS assumes it loses value gradually, so you deduct a slice of its cost each year over an IRS-defined "recovery period" (typically 3–7 years for equipment). In practice, §179 expensing and bonus depreciation let most small businesses skip the schedule and deduct the whole purchase in year one.
Business expenses are "above the line": they reduce your income before the standard deduction is applied. You need not itemize nor optimize -- qualified deductions stack atop the standard deduction that everyone receives.
Common deductions include:
Things that are not business expenses:
Treasury Regulation §1.6001-1 requires taxpayers to document their tax liability. A complete transaction ledger generally contains (1) amount, (2) date, (3) place, (4) business purpose, and (5) the business relationship. These metadata are naturally recorded by receipts, bank/credit-card statements, invoices, etc.
If records are imperfect but a business expense was clearly incurred, the Cohan rule allows courts to estimate the deduction "bearing heavily, if it chooses, upon the taxpayer whose inexactitude is of his own making."
IRC §274(d) forbids estimation for heavily abused categories: travel, meals, gifts, and "listed property" (chiefly vehicles).
You don't need an LLC or a corporation to deduct expenses. Anyone who earns self-employment income is a sole proprietor by default. The structure only changes which form the income lands on (and how much paperwork you sign up for).
| Structure | Tax ID | Income reported on | Notes |
|---|---|---|---|
| Sole proprietor | SSN or EIN | Schedule C (1040) | The default for a solo 1099 worker; no setup |
| Single-member LLC | SSN or EIN | Schedule C (1040) | Same tax treatment; adds liability separation |
| S corporation | EIN | Form 1120-S → K-1 → 1040 | Can split salary vs. distribution to trim SE tax |
| C corporation | EIN | Form 1120 (entity pays) | Double taxation; rare for solo contractors |
| Partnership / multi-member | EIN | Form 1065 → K-1 → 1040 | For two or more owners |
If you'd rather not share your Social Security number with every client, grab a free EIN from the IRS.
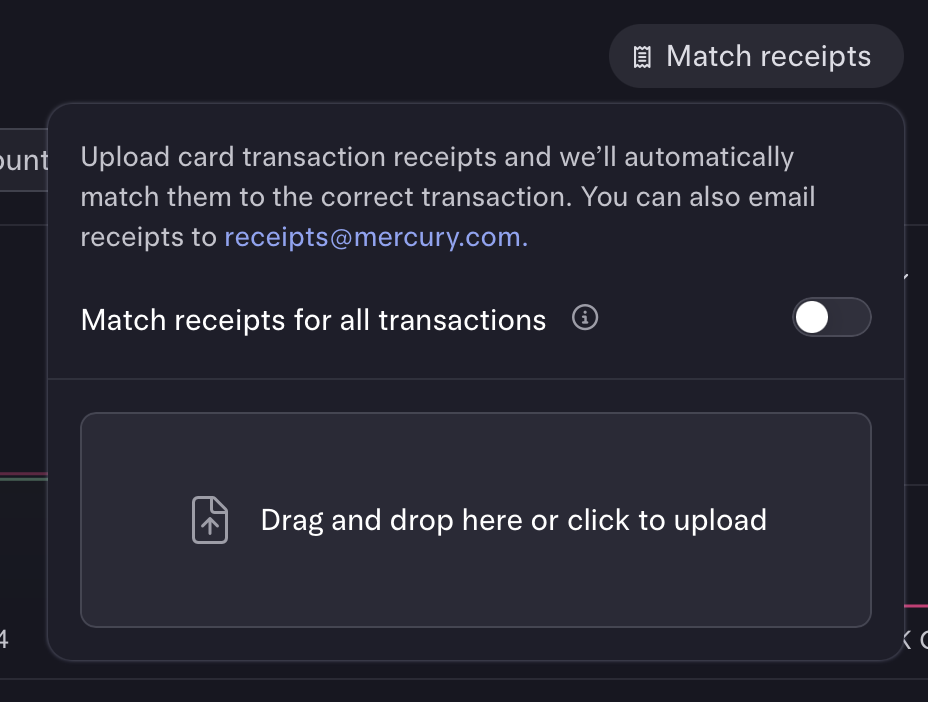
Most 1099 contractors are not bookkeepers (and do not want to be). To avoid forensic accounting headaches, isolate your payment methods. For example, you can issue single-purpose debit cards via Mercury.
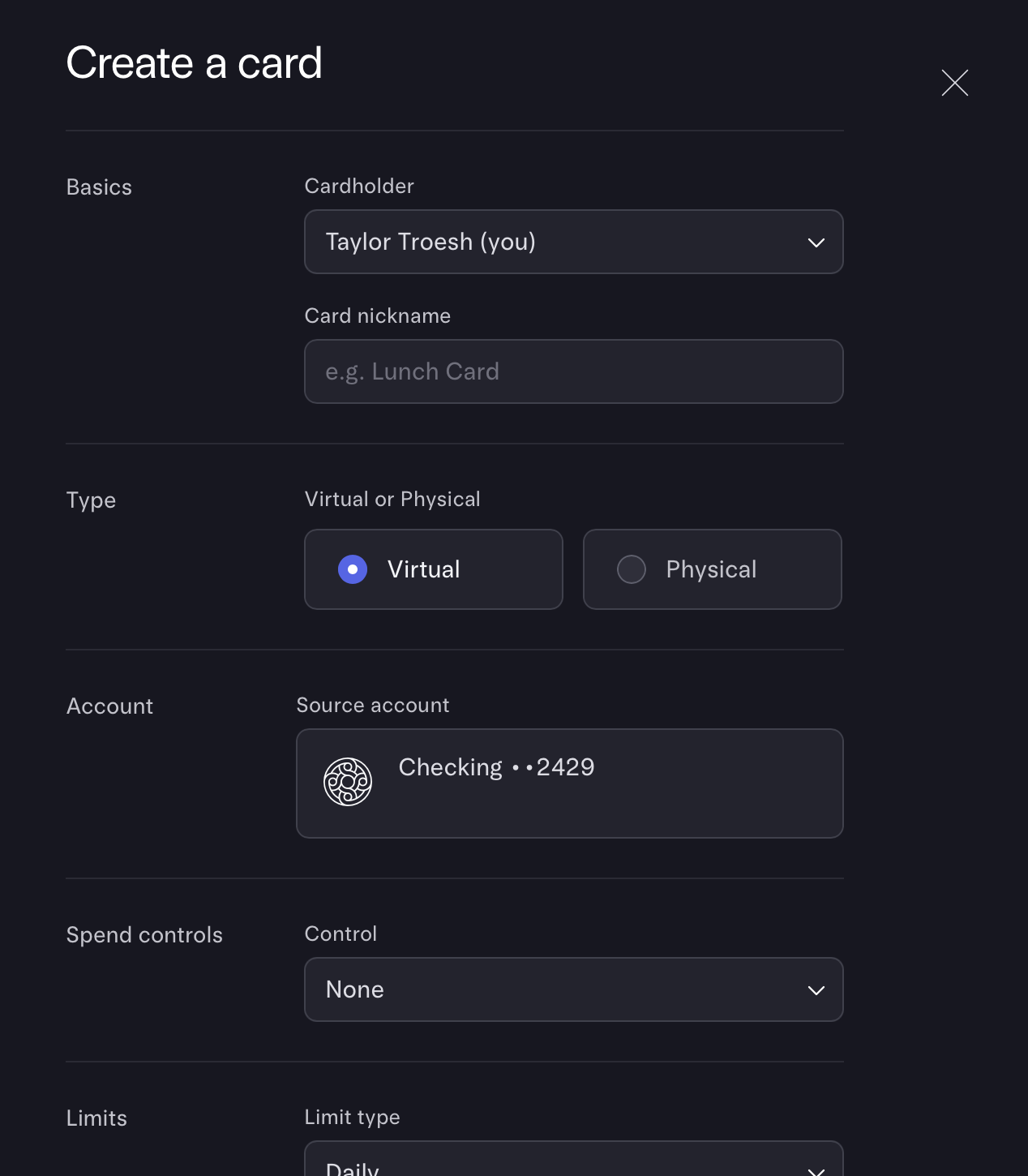
If your bank does not offer virtual debit card services, you can create isolated debit cards by opening new bank accounts. You can open a business checking account at many banks with just a personal SSN. If business accounts aren't available, personal checking accounts work perfectly fine.
Some people prefer the simplicity of having one true balance; others prefer budgeting against isolated balances. If using multiple accounts, direct business income to your business account and pay yourself regular wages.
Credit cards achieve the same end. If you charge business transactions to one dedicated credit card, your monthly statements will contain only business expenses. Consider enabling autopay to avoid unintended credit card debt.
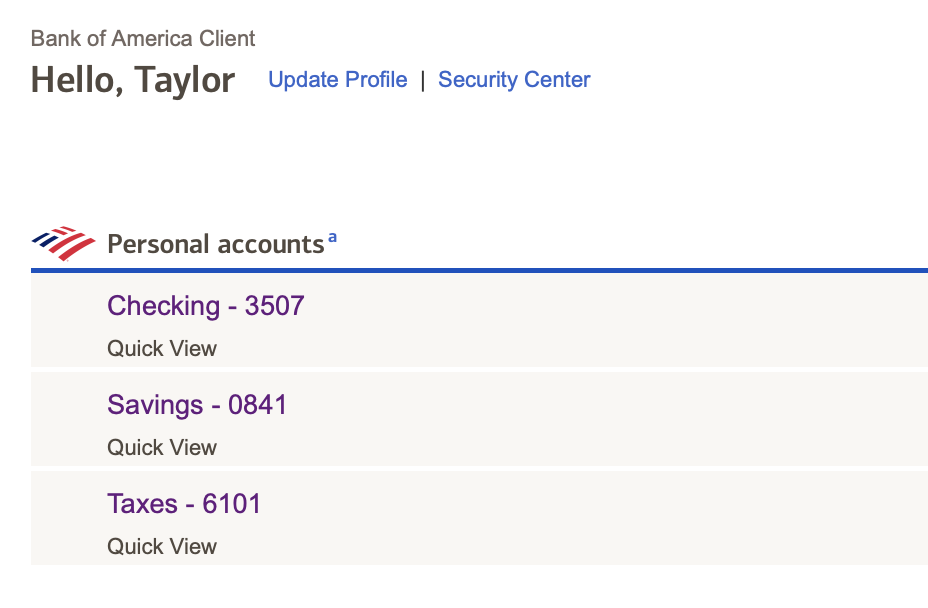
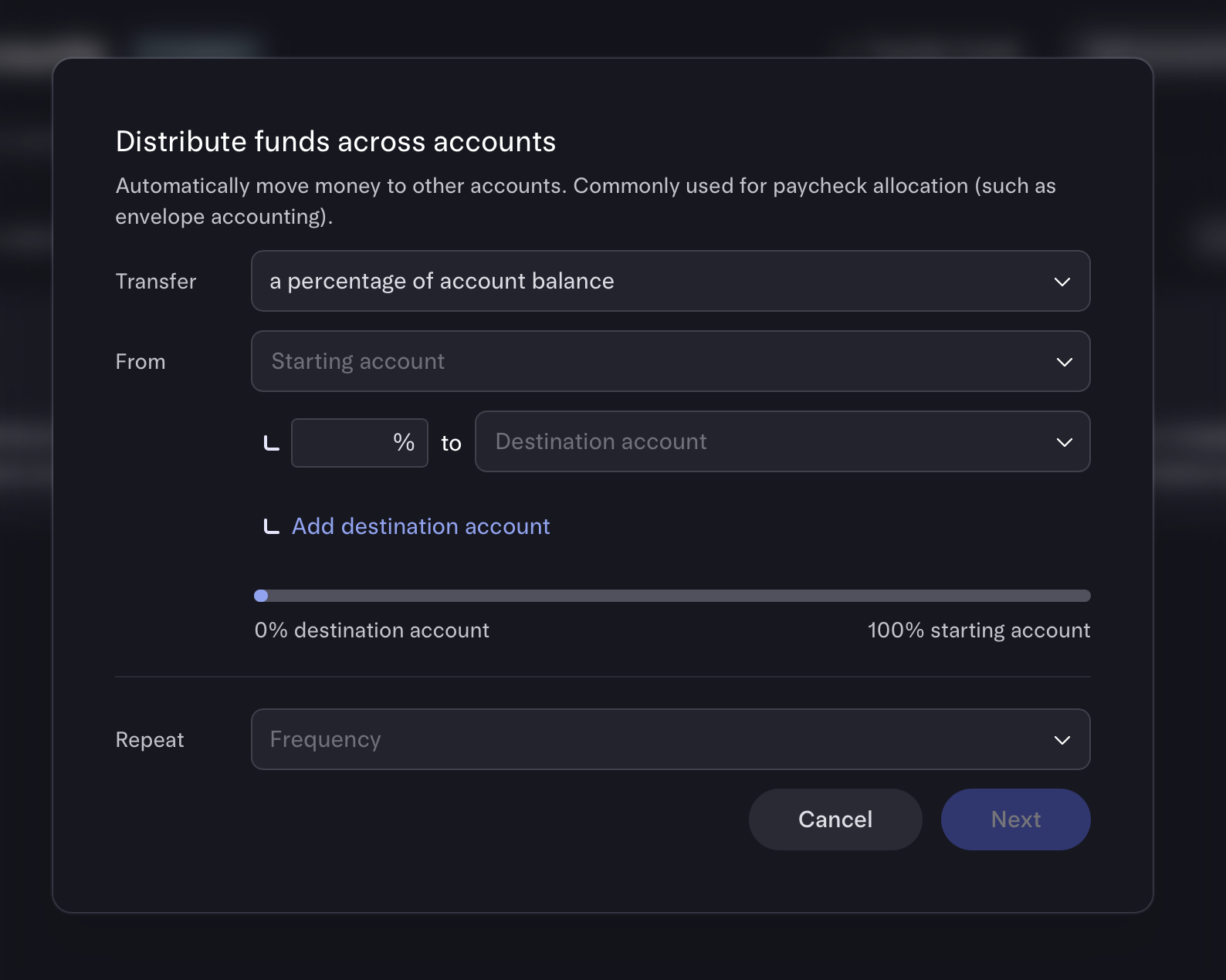
Remember that taxes are not automatically withheld from 1099 income. To avoid spending money owed to Uncle Sam, some contractors automatically redirect estimated taxes into an isolated high-yield savings account. Many clients are happy to send partial payments to two accounts, especially those who use direct deposit (ACH) services. If separate payments are not available, services like Mercury can be configured to automatically split income between accounts.
If you're looking for something more tailored/integrated, consider one of the many banking platforms for small businesses: Found, Lili, Novo, Relay, Bluevine, NorthOne, etc.
If you want even more control, modern bookkeeping software also connects directly to bank accounts and automatically imports/sorts transactions. Popular picks: QuickBooks Solopreneur, FreshBooks, Wave, Keeper, Xero, Expensify, etc.
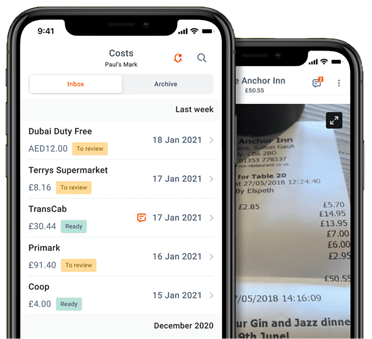
In rare cases, you may need to record physical receipts. Digitize them immediately and throw them away. If the receipt-scanners in QuickBooks/FreshBooks/Expensify/etc. are insufficient, try dedicated apps like Dext and Shoeboxed.
Beware: thermal-paper receipts degrade over time. Never leave receipts in the sun.
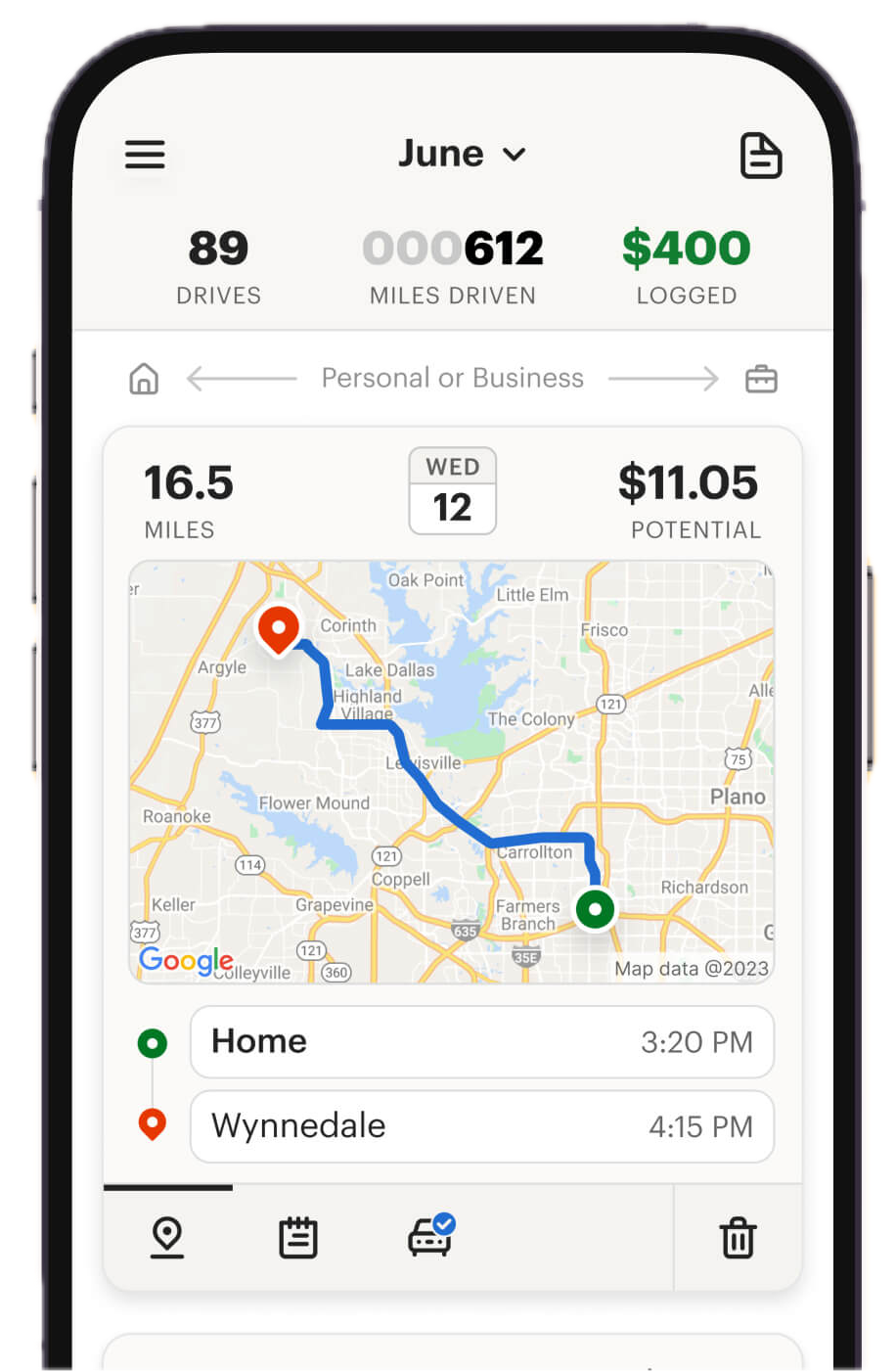
Mileage is its own beast. If you are willing to share your live GPS location with corporations, consider apps like MileIQ, Stride, and Everlance.
Taxes are easy if you maintain good financial hygiene.
When you make qualified investments into your business, the IRS will tax you as if you didn't earn that money.
Tax savings should be treated as a modest discount on business spending. Never excuse irresponsible spending because "it's a business expense".
Consider a single contractor with $100,000 of 1099 revenue and $15,000 of legitimate business expenses (tax year 2026, sole proprietor, no state income tax):
| Report expenses | Ignore expenses | |
|---|---|---|
| Gross 1099 revenue | +$100,000 | +$100,000 |
| Business expenses reported | −$15,000 | −$0 |
| Net profit (Schedule C) | =$85,000 | =$100,000 |
| ½ SE-tax deduction | −$6,005 | −$7,065 |
| QBI deduction (§199A) | −$12,579 | −$15,367 |
| Standard deduction | −$16,100 | −$16,100 |
| Taxable income | =$50,316 | =$61,468 |
| Federal income tax | +$5,790 | +$8,235 |
| Self-employment tax | +$12,010 | +$14,130 |
| Total federal tax | =$17,800 | =$22,365 |
| Gross 1099 revenue | +$100,000 | +$100,000 |
| Total federal tax | −$17,800 | −$22,365 |
| Cash spent on the business | −$15,000 | −$15,000 |
| Take-home | =$67,200 | =$62,635 |
In this example, the federal government awards 30 cents for every business dollar; those dollars dodge self-employment tax and income tax and shrink your QBI base. Bookkeeping preserves 7.3% ($4,565) of the contractor's total income.
Spending proportionally more on your business yields larger percentage gains:
| Expenses reported | as % of revenue | Tax saved | Take-home gain |
|---|---|---|---|
| $10,000 | 10% | $3,049 | +4.5% |
| $15,000 | 15% | $4,565 | +7.3% |
| $20,000 | 20% | $5,717 | +9.9% |
| $30,000 | 30% | $8,022 | +16.8% |
State taxes further increase these yields.
Income brackets (and spending habits) change these totals; the math is generally attractive to those who earn ~$60k+ per year. For those who earn (and spend) much more, a few hours of bookkeeping is the highest-paid work they'll do all year.