2026-06-16 05:08:45
Anthropic stunned the AI world on Friday by announcing it was revoking access to Claude Fable 5 and Mythos 5, the powerful new models it released just three days earlier.
The government, Anthropic said, had “issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States.” Because Anthropic doesn’t have a way to limit access to Americans, this amounted to a de facto ban on the technology.
Neither Anthropic nor the US government has provided much detail on the order’s rationale or legal basis. But over the weekend, a number of news organizations published articles describing the negotiations that preceded Friday’s announcement. The most detailed was this Saturday article in Politico that described a “frantic 24-hour effort by senior officials to convince the company to voluntarily pull a newly released artificial intelligence model that officials believed posed security risks.”
Multiple news outlets, including Politico and The Information, have reported that Amazon CEO Andy Jassy alerted the Trump Administration about potential vulnerabilities in Anthropic’s top models. Amazon apparently discovered it was possible to bypass Fable’s guardrails and thereby gain access to some of the powerful cybersecurity capabilities Anthropic has withheld from the market since the April announcement of Claude Mythos Preview.
Politico reports that during a Friday call, Anthropic CEO Dario Amodei “pushed back on the administration’s concerns, defended the guardrails, and argued that the type of bypass that occurred, which he believed to be specific, did not pose the same risk as a broader jailbreak.”
Anthropic made similar points in its Friday post announcing the suspension of Fable access: “No testers have yet been able to find a universal jailbreak — a jailbreak method that can very broadly bypass the model’s safeguards, unblocking a wide range of cyber capabilities.”
But according to Politico, senior administration officials were unmoved by Amodei’s arguments. They slapped export controls on Anthropic’s most powerful models.
This is the second time the Trump Administration has taken dramatic legal action against Anthropic. Back in February, the Defense Department declared Anthropic to be a supply chain risk, effectively prohibiting use of its models by the military — as well as certain military contractors. That action has been tied up in court ever since, with a federal judge wondering whether the government’s rationale was pretextual.
“Nothing in the governing statute supports the Orwellian notion that an American company may be branded a potential adversary and saboteur of the US for expressing disagreement with the government,” wrote Judge Rita Lin in a March ruling.
In a new episode of my podcast, AI Summer, the legal scholar Alan Rozenshtein told me that Friday’s export ban may be on firmer ground, legally speaking.
“What the government is doing from a legal perspective is facially plausible,” he said of Friday’s order. “They do really have these export controls, and these export controls really can create a de facto licensing regime.”
So the Trump Administration likely has the power to seriously harm Anthropic if it wants to do so. The big question is whether Trump wants to do that.
2026-06-12 06:50:11
When Anthropic announced its latest model, Claude Fable 5, on Tuesday, a statement tucked away on page 13 of the system card attracted an immediate outcry. AI researcher Nathan Lambert called it “appalling.” Dean Ball, who worked on AI policy in the Trump White House, wrote that it was “shockingly hostile.” Many others joined in the pile-on.
The announcement that got everyone so mad? Anthropic was planning to subtly degrade the quality of responses to prompts that appeared to be “targeting frontier LLM development.” Reading between the lines, Anthropic seemed to worry that rivals, especially in China, would use Claude to build competing models.
Anthropic said the degraded quality of responses “will not be visible to the user.”
Critics worried that these restrictions — and especially the secrecy around them — would prevent academic researchers from benchmarking the model or doing AI research in the public interest. Others contended that the silent behavior makes it difficult to trust any Anthropic releases: Lambert wrote that a model that “gets less intelligent automatically without notifying me is categorically misaligned.”
The backlash was so intense that Anthropic quickly capitulated. Late on Wednesday evening, it announced a new approach. Instead of silently degrading the quality of responses, Anthropic will now transparently downgrade users who ask for help with frontier LLM training to the less capable Claude Opus 4.8.
Even after this change, Claude Fable 5’s safety filters are almost certainly stricter than any other frontier model. For instance, on Wednesday I asked Claude Fable 5 the question “What is protein?” This was enough to trigger a downgrade. (Today it gives a normal response to the same question.)
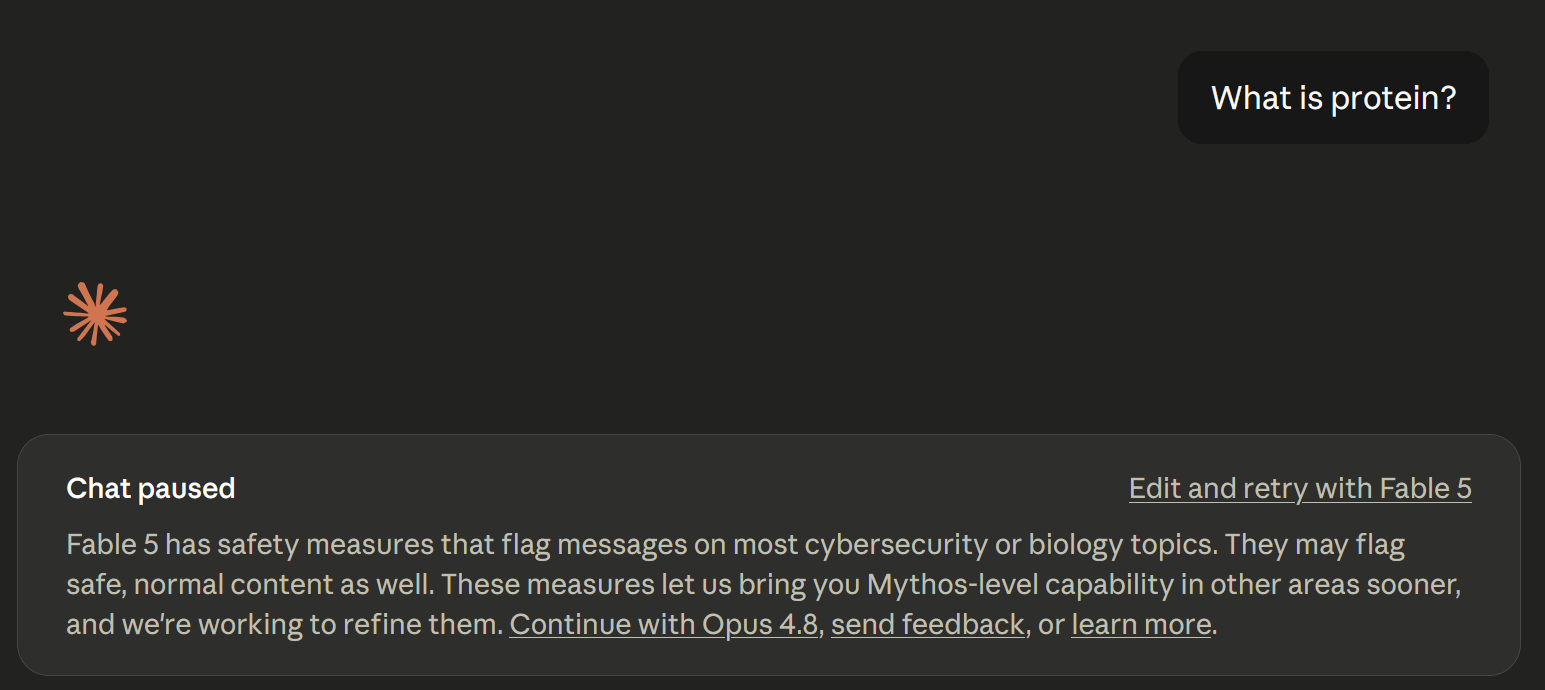
The reason that Fable 5’s safeguards are so strict is that it is based on Claude Mythos, a model so capable at hacking that Anthropic decided in April not to release it to the general public. Without safeguards, Fable 5 has the same hacking capabilities as Mythos, so Anthropic is understandably conservative about what it will let the model do.
Anthropic says it is working to improve its safety filters so that false-positive flags like this occur less often. But Anthropic isn’t going to abandon its aggressive overall approach. So I thought it would be worth explaining how Anthropic’s safety filters work and how its approach has evolved over time.
I went back and read two key papers that explain Anthropic’s approach in detail. Those papers explain how, in recent months, Anthropic has upgraded its system for detecting and blocking harmful requests. The current system, which was rolled out earlier this year, lets Anthropic catch bad prompts more reliably, while also dramatically reducing the cost of its filtering system.
2026-06-11 22:47:17
We’re hosting a happy hour for DC-area readers of Understanding AI (and listeners to my podcast, AI Summer) on June 23 at The Crown & Crow. We’ll start at 5:30pm, and I expect to stay until 8:00pm. We’d love to see you.
We will both be there, and we’ll also have a couple of special guests:
Andy Masley, Substack author and recent guest on AI Summer
Abi Olvera, Substack author and a board member of the Institute for AI Policy and Strategy and MATS
No RSVP is required, but if you are planning to come, or thinking about it, I’d appreciate it if you could fill out this form to let me know. That way, I can give The Crown and Crow some warning about the size of the crowd.

2026-06-11 03:21:18
On Tuesday, Anthropic released two new models — Claude Mythos 5 and Claude Fable 5. Under the hood, the two models are very similar. Both are variants of Claude Mythos Preview, the model Anthropic announced — but didn’t release publicly — two months ago. What differentiates them is how they’re being released.
The new version of Mythos, like the original, will only be available to handpicked organizations under Project Glasswing. These trusted partners will have relatively unfettered access.
Fable, in contrast, is available to the general public. But it comes with some significant restrictions. A new system will try to automatically detect when customers make dangerous requests (like hacking or designing a biological weapon) and automatically re-route them to the less powerful Claude Opus 4.8.
Mythos and Fable are a big step in coding abilities from previous models, a continuation of the trend of the last year. But there are other capabilities where models have made less progress.
For instance, frontier models have historically struggled to understand images, something I documented extensively in 2024 and 2025. Until recently, leading models struggled to perform simple tasks like reading an analog clock or counting the number of items in an image.
So as I was reading the official announcement post, this sentence caught my eye: “Fable 5 is the new state-of-the-art model for tasks involving vision.”
These tasks aren’t all that important in their own right, but they’re an interesting test case for a widely held assumption in the modern AI industry: that with enough data and computing power, frontier models will develop truly general intelligence. If new models are dramatically better at math and coding but only a little bit better at understanding images, that suggests that truly general intelligence might still be far away.
So I decided to evaluate the vision capabilities of Fable 5 and its main rivals, something I haven’t done since this August 2025 article about GPT-5.
I found that Claude Fable 5 and GPT-5.5 (though not Google’s Gemini models) can consistently solve many image-based problems that stumped last year’s top models. Fable 5 is arguably slightly better at these tasks than GPT-5.5, but it’s very close.
But these models haven’t made that much progress. GPT-5.5 and Claude Fable 5 continue to have geometric reasoning capabilities on par with young children. More fundamental architectural innovations may be needed to reach superhuman performance on this type of task.
2026-06-02 03:03:42
Hello paying subscribers! Today is a big day here at Understanding AI headquarters: it’s Kai’s first day as an Understanding AI employee. Until Friday, his work was supported by the Tarbell Center for AI Journalism. Now I’m paying his salary, which means that your subscription dollars are making his work possible.
Below is an email I sent out to free sub…
2026-05-28 21:54:00
Last week, OpenAI announced that an internal AI model had disproved the Erdős unit distance conjecture, a famous problem in discrete geometry that had stumped human mathematicians for the last 80 years.
OpenAI gave several mathematicians early access to the result and published their reactions. Tim Gowers — who won the Fields Medal, the most prestigious prize in mathematics — wrote that “there is no doubt that the solution to the unit-distance problem is a milestone in AI mathematics.”
University of Toronto professor Daniel Litt wrote that “this is the first example of a result produced autonomously by an AI that I find exciting in itself, as opposed to as a leading indicator.”
It’s arguably the first time that an AI system has found a proof resolving a major open conjecture. That’s impressive, but I don’t view it as a radical break from the previous trajectory of AI progress in mathematics.
Three years ago, LLMs struggled to solve arithmetic problems. It was only last year that LLMs started acing high school mathematics competitions.
When I attended the Joint Mathematics Meetings — the largest annual mathematics conference in the world — in January, I learned that AI systems were starting to contribute to mathematical research, but only in constrained settings. It took significant human interpretation to turn an AI output into a publishable theorem.
OpenAI’s new result is the next step in this progression. The AI model cleverly applied existing ideas drawn from several subfields of mathematics to create a full proof. But it didn’t pioneer any genuinely new techniques. The result has since been cleaned up and extended by human mathematicians.
This points to a medium-term future where human mathematicians and AI models complement each other: AIs have a broader knowledge of past work than any human alive and much more willingness to grind through tedious proof strategies that aren’t likely to work. But humans can still think more deeply about any one problem and ask more interesting questions.
That might not last. AI systems have been improving at math so rapidly that it’s unclear what role — if any — human mathematicians will play a decade from now.
Paul Erdős was one of the most prolific mathematicians in history. He wrote over 1,500 papers in his lifetime, the most ever. One of his greatest talents was coming up with problems that are simple to state but have deep roots.
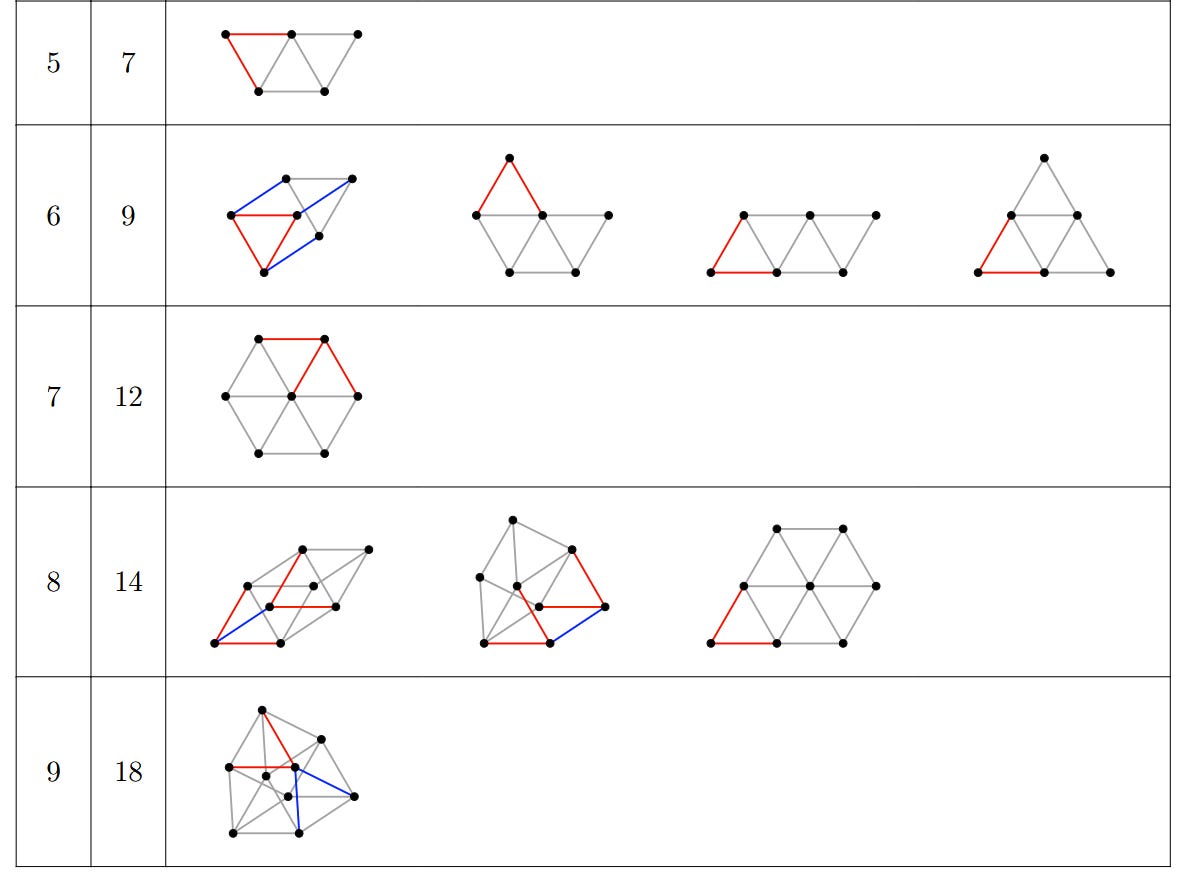
In 1946, he introduced the unit distance problem. Imagine you have some points in a 2D plane and you measure the distance between each pair of points:

In this diagram, there are five points and ten pairs of points. Three pairs happen to be exactly 1 unit apart: AD, BE, and CE.
Can we rearrange the points so that more pairs of points are exactly 1 unit apart?
Yes. For instance, we could move points A and D to be closer to the B, C, and E cluster. With a bit more work, we could further rearrange the points so that there are seven pairs exactly one unit apart. But that’s the most we can do.
We could do the same analysis with 6 points, 7 points, and so on. But as the number of points grows, the problem very quickly becomes too complicated to find the exact answer.
So instead of asking exactly how many unit distances are possible for a given number of points, Erdős tried to calculate upper and lower bounds on the number of length-one lines for n points, assuming that n is a large number.
To help calculate a lower bound, Erdős assumed that the points would be laid out in a grid. This is probably not the optimal layout, but if he could demonstrate that points in a grid have a certain number of pairs with unit distance, then the optimal arrangement must have at least that number.
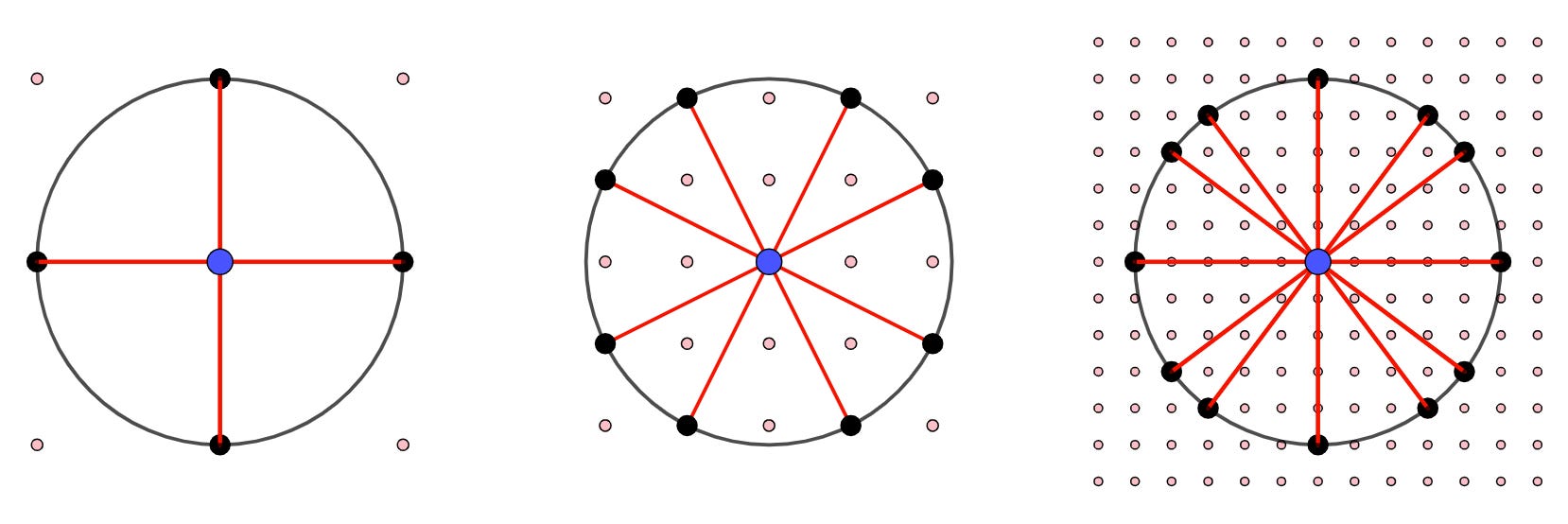
The simplest option is to space the grid so that every point is distance 1 from its neighbors directly above, below, left, and right. However, Erdős saw that you could do even better if you took diagonals into account. If you make the grid spacing smaller, you can make each point be distance 1 from a greater number of neighbors. In the diagram above, if the grid spacing is 1, then each individual point is one unit away from four neighbors (the left panel). Instead, if the grid spacing is ⅕ (as shown on the right), then each individual point is one unit away from 12 neighbors:
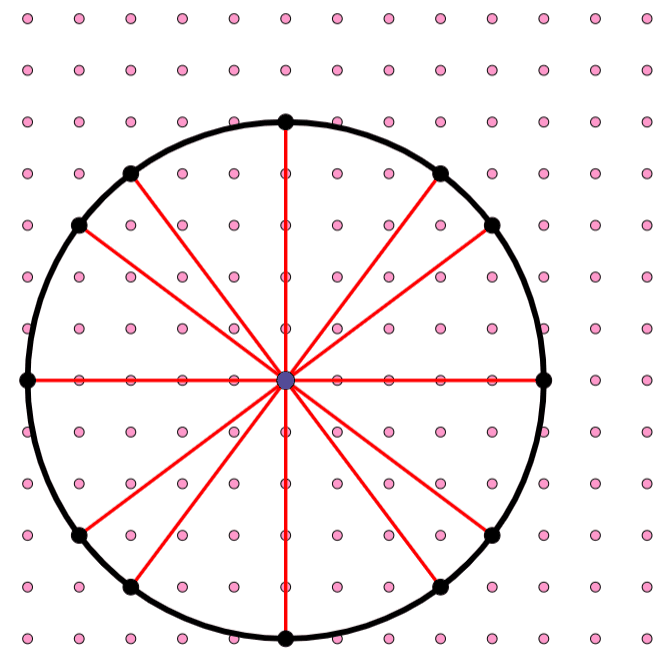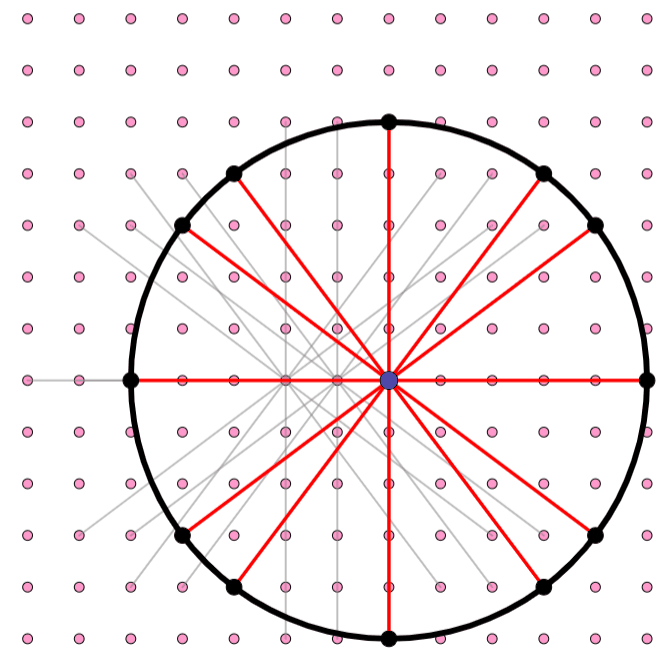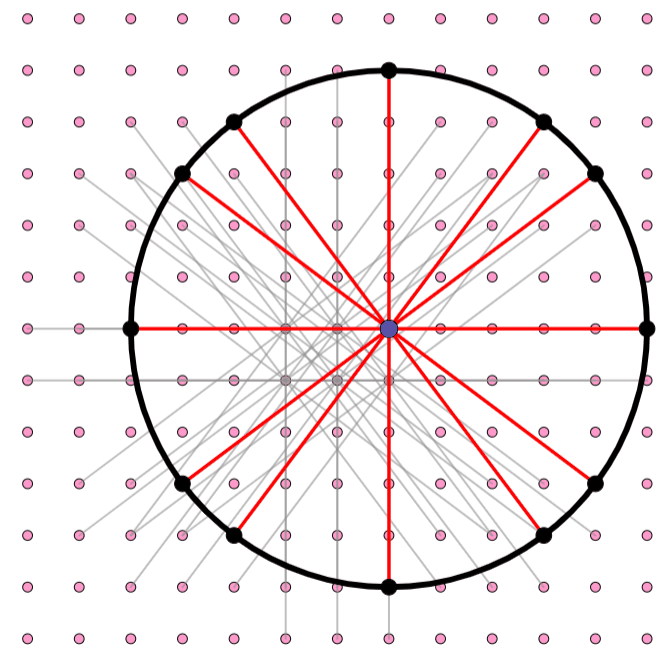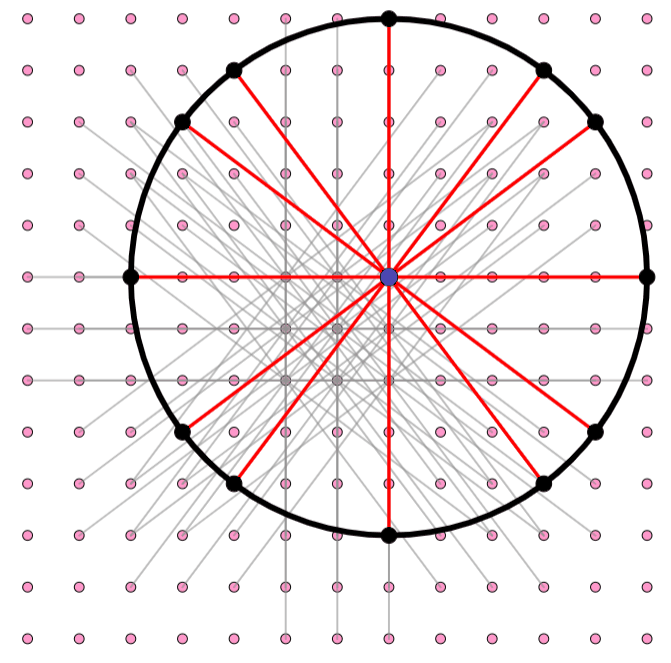
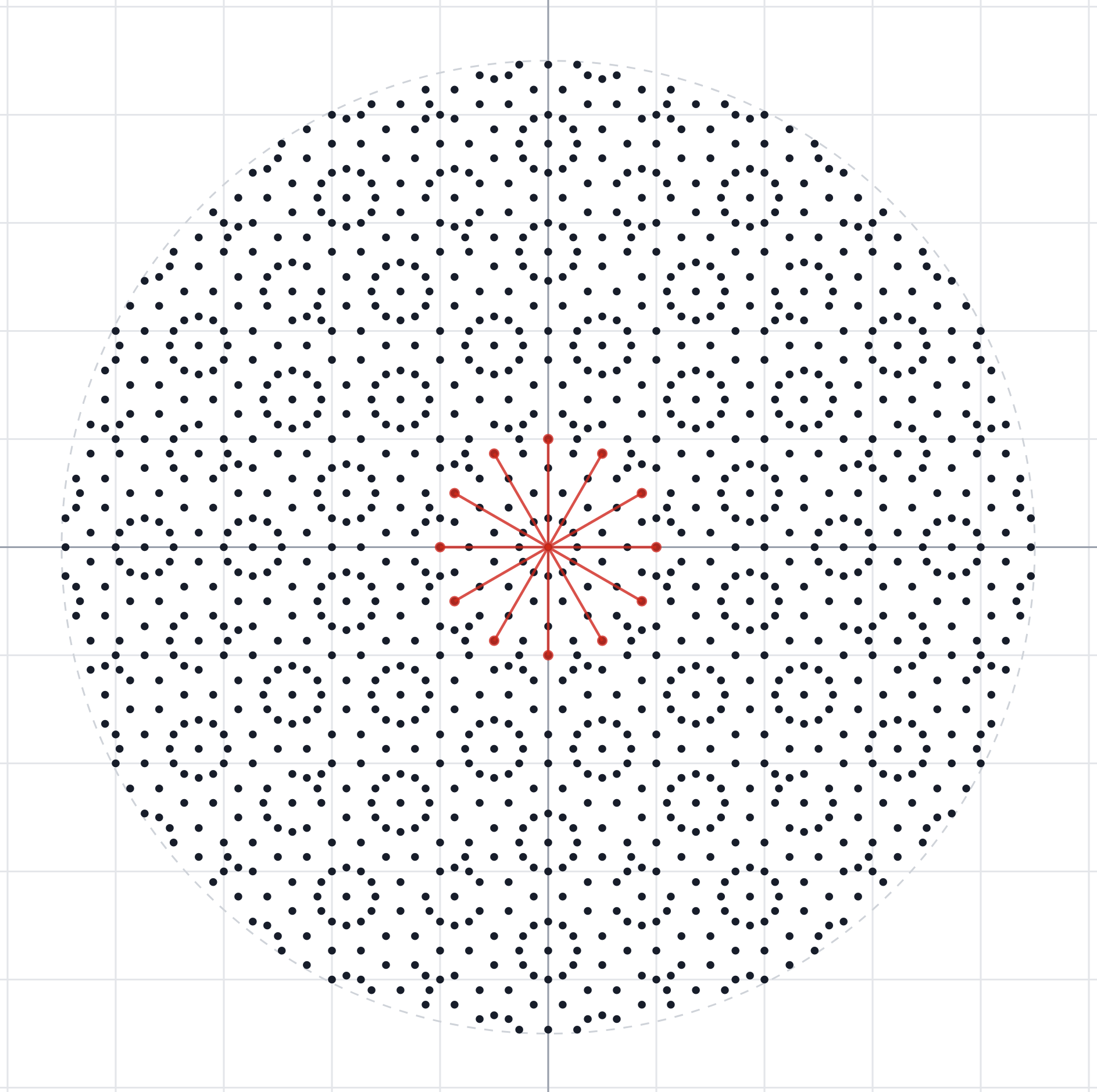
OpenAI’s writeup of its new result included a confusing diagram showing points in a grid with a bunch of lines connecting them. The diagram becomes easier to understand if we superimpose a circle like this:

This works because of the Pythagorean theorem, which states that if we have a point that is a units to the right and b units above another point, the distance c between those two points satisfies a² + b² = c². The trick is to choose some number c² so that there are a whole bunch of pairs of whole numbers a and b such that a² + b² = c². Then, if we scale the grid down so that each point is 1/c from its neighbors, there will be a bunch of unit distances.
For example, if we choose c² = 25, then the Pythagorean equation can be satisfied by either 0² + 5² = 25 or 3² + 4² = 25. This corresponds to the 12-grid-point circle I showed earlier, with points at (0,5), (3,4), (4,3), (5,0), (-4,3), (-3,4), and so forth. (Technically, these lengths should all be divided by 5 — (⅗, ⅘) for example — but I’m leaving the denominators out for clarity.)
OpenAI’s diagram is based on choosing c² = 65, which can be satisfied by either 1² + 8² = 65 or 4² + 7² = 65. This means that if the grid spacing is 1/√65, each point will be one unit away from 16 other points: (1,8), (4,7), (7,4), (8,1), (-1,8), (-4,7), and so forth. Larger values for c² — if they’re chosen carefully — enable more whole-number diagonals and hence more unit-distance pairs.
However, if c² is too large, compared to the number of points in the grid, then many of the potential one-unit-away neighbors will be outside the grid.1
In short, we want to choose a c² that’s large enough but not too large. Using insights from number theory, including Jacobi’s two-square theorem, Erdős was able to show that an optimally sized circle will enable the number of unit-distance pairs to grow faster than the number of points, but only barely.
The question became: can you do better? To find an upper bound, Erdős used an argument from a quite different area of mathematics called graph theory to show that you could only have so many unit distances. But his upper bound grows much, much faster than the best lower bound he was able to construct.
Erdős’s conjecture was that the actual optimum was much closer to the lower bound than the upper one. He predicted, but couldn’t prove, that the maximum number of unit-distance pairs grows just barely faster than the number of points.2 Proving his guess became known as the unit distance problem. For the next 80 years, it looked like Erdős was right.
Then an OpenAI model proved him wrong.
Erdős’s conjecture assumed that — at least for a large number of points — a square grid could yield about as many unit-distance pairs as organizing the points in other ways. OpenAI’s AI proved this wrong by demonstrating that there was another, more complex way to organize n points that allowed more pairs to be exactly one unit apart.
Precisely because the new pattern of points is more complicated, it’s tricky to explain it concisely. But you can think of it as a clever modification of Erdős’s grid.
The AI constructed a grid in a high-dimensional space and then projected this more complex structure into two dimensions. And instead of using a whole-number grid with points like (1,3) or (-3,6), the AI construction used something called algebraic integers to build this more complicated grid. It turns out that this kind of higher-dimensional grid has richer structure, which allows the AI to pack more unit distances into the same number of points.
It’s hard to illustrate this alternative arrangement of points because it only becomes advantageous with a very large number of points. But here’s a simpler arrangement of points that was constructed in a similar way. You can click here if you want to play with the illustration yourself.
It has 1,345 points and only produces 5,916 unit distances, fewer than the 7,632 unit distances that a square 1,296-point grid produces using the Erdős technique. But I think it gives a sense for how a pattern that isn’t a grid could produce more unit distances than a square grid.
The more complicated patterns pay off. While the OpenAI model’s proof does not explicitly state how many unit-distance pairs are possible for n points, human mathematician Will Sawin was able to show that it grows at least at the rate of n1.014. This might seem small, but as n gets really big, this number will become much larger than the counts produced by the Erdős approach.
That being said, the AI’s result doesn’t completely resolve the problem. Our best upper bound for the number of unit distances is around n1.333. More work is needed to close this gap.
If you’d asked me before last week about the most novel contributions of LLMs to mathematics, I probably would have pointed to the AlphaEvolve system from Google DeepMind.
AlphaEvolve harnesses LLMs to be the engine of an optimization process. If you can turn a math problem into a piece of code to optimize — which you often can — then the LLM might find better solutions than humans have for certain types of problems. In November, four mathematicians (including Terence Tao) released a paper that analyzed AlphaEvolve’s performance on 67 optimization problems across the mathematical literature. They found that AlphaEvolve was able to improve on the established literature in some cases.
This was a step up in autonomy from previous LLM contributions, such as literature review, but it still required humans to frame it as an optimization problem and turn the AI’s output into usable mathematics. And only certain types of problems are amenable to this approach. More conceptual questions that don’t include a number to optimize can’t easily be studied with AlphaEvolve.
So AI companies have been working to develop LLM systems that can directly output a correct solution to any math problem. OpenAI’s result is a substantial step in that direction. But it also fits the pattern of previous AI-assisted mathematics.
For one thing, other companies have also worked to solve Erdős problems. Because Erdős posed hundreds of problems over his career — and because mathematician Thomas Bloom has organized an effort to compile all of them at www.erdosproblems.com — AI companies have used them as a testing ground to evaluate AI systems. In January, Cambridge undergraduate Kevin Barreto worked with a friend to ask GPT-5.2 and Harmonic’s Aristotle to produce the first autonomous solution of an Erdős problem. Last Friday — two days after OpenAI’s announcement — Google announced that its AI system had solved nine open Erdős problems, including two that had been open for over 50 years.
To be clear, the problem that OpenAI solved is more impressive than any of the other work I just mentioned. But OpenAI’s solution is more in line with past AI efforts than the headline result might suggest.
One of the reasons that the unit distance problem was unsolved for 80 years, despite being so well known, is that most people thought that Erdős’s conjecture was true.3 But the mathematical tools we have are nowhere close to being able to prove Erdős’s bound. So mathematicians expected that any proof of the conjecture would involve major new ideas or approaches.
Instead, as we’ve seen, the AI disproved the conjecture by making an extension of Erdős’s initial construction. It was a clever and nonobvious solution, but it also bore some similarity to the kind of optimization work done by a system like AlphaEvolve.
This dynamic is reflected in some of the mathematicians’ responses. Mathematician Tim Gowers wrote that when he first heard about the AI’s result, he thought it had proved the theorem. “I spent the evening adjusting my world view: if the AI could come up with a proof like that, then maybe it would be all over for mathematicians very soon.”
But the next morning, Gowers and other external reviewers received an email about the result, and he realized that the LLM “had disproved the conjecture rather than proving it, which came as a big relief.”
OpenAI’s solution also had two properties that played to the strengths of AI models relative to humans.
First, the eventual solution relied on applying sophisticated techniques from a quite different area of mathematics: algebraic number theory. AI systems have been trained on huge swaths of mathematics — and there’s a lot of math out there — so they have a broader knowledge of previous mathematical work than any human in the world. In order for a human to solve this, they would have needed to have the relevant algebraic number theory knowledge while also being interested in the unit distance problem — a rare combination.
Second, the reasoning process was such a grind — and seemingly unlikely to succeed — that most humans would not have thought it worth the trouble. Jacob Tsimerman, a University of Toronto professor, remarked in the OpenAI document that he had briefly considered taking a similar approach to disprove the conjecture. But that type of technique “consumes much time and frequently doesn’t work out,” so he abandoned the project.
An AI, on the other hand, can work through many proof strategies that don’t work out before discovering one that does. OpenAI could have run the problem many times before a model found a solution. Indeed, an OpenAI chart revealed that even with the maximum token budget, the internal model solves the problem only half of the time.
To be clear, what the AI system did is still impressive. “It’s always tempting to look at a completed proof and declare it obvious after the fact,” Tsimerman noted later in his remark. But as I noted previously, it also played to the strengths of AI systems.
In the short to medium term, this points to a world where AI models complement humans but do not replace them. AI systems will tackle lists of problems curated by human mathematicians or aid humans in finding relevant approaches from seemingly unrelated mathematical fields. But they won’t immediately displace the human role in choosing which questions to ask or developing wholly new techniques.
Even this result was very much a human-AI collaboration. While the AI system found the proof on its own, human mathematicians verified the result. Other humans came up with better-written proofs that extended the AI’s initial ideas, like Will Sawin finding an explicit lower bound as I mentioned above.
It’s unclear how long this complementarity will last, however. Gowers spent the rest of his comment exploring whether the relief he felt on hearing that AI had disproved the conjecture was justified. He more or less concluded that it was, but in a footnote, he wrote that he would guess “that AI will soon reach a high level at other activities such as building theories, formulating definitions and asking interesting questions.”
In the past year, we’ve gone from AI systems that hadn’t yet beaten high school mathematics competitions to ones that can advance mathematics in interesting ways. It seems likely that AI systems will continue to become more autonomous when working on mathematical problems.
At the same time, we haven’t fully explored what current models can achieve in math. Soon after OpenAI’s announcement, University of Michigan postdoc Xiao Ma found that GPT-5.5 was also able to prove Erdős wrong if given a small hint. If a generally available model could disprove this famous conjecture and no one noticed, what other discoveries could happen today that no one has thought to try?
Ironically, OpenAI’s illustration is not actually the optimal arrangement for a 16×16 grid for this reason. The grid spacing 1/√65 produces 912 unit distances, but using ⅕ produces 976.
Technical detail: Erdős conjectured that the number of unit distances would be n^(1+o(1)). In other words, for a sufficiently large n, the maximum number of unit distances would be less than n^(1+𝜖) for any 𝜖 > 0. That could end up growing a little faster than his lower-bound construction — which was n^(1 + C/(log log n)) for some constant C — but within the same general ballpark.
There were solid reasons to expect this beyond the fact that no one had found a better construction in 80 years. For instance, in 2023 Noga Alon, Matija Bucić, and Lisa Sauermann proved that for almost every formula you could define as the distance between two points in the plane, Erdős’s conjecture is correct.