2026-06-29 20:52:01

大家好,欢迎收听老范讲故事的 YouTube 频道。
美国监管方向错误,盯死了 Mythos、Fable 5 和 GPT-5.6,却忽视了真正的安全崩塌。
今天早上,老范怎么被炸醒的呢?这几天整个圈子都在眼巴巴地等着 GPT-5.6,尤其是 Fable 5 和 Mythos 5 被禁了以后,那咱就等着玩 GPT-5.6 呗,这是唯一的盼头了。而且它应该也不远了,原来说是这礼拜四出,结果没有出。现在据说是 200 美金的 Pro 用户,有一部分被抽签抽到了,进行灰度测试。
结果今天早上起来一看 X 上头,这个消息就直接把人炸蒙了:政府要监管 GPT-5.6 的测试名单,谁能进、谁不能进,谁能测、谁不能测,都要上报,要审批了。
那咱们今天就从这来讲一讲。你可能会问,之前被关的是 Anthropic 家的 Fable 和 Mythos,这把火怎么就烧到 OpenAI 脑袋上了呢?这里头的关键细节是,Fable 被禁了以后,Anthropic 自己跑出来就喊说:
GPT 也能干,你干嘛光禁我的呀?你得把它也封了呀。
这 GPT 就被拉下水了。从那一刻开始,这道门就从一家开始,向整个行业蔓延了。
所以今天老范要讲的一件事情就是:美国不是说不该管这个 AI,而是枪口的方向错了。它死死盯着的是模型,却没有看到脚下坍塌的是整套传统安全体系。
这条线分五层来讲:

首先咱们来数一数日子,满打满算 6 个礼拜,看看监管是怎么把自己拐到死胡同里去的。
同时中国这边动作也不断。字节跳动放出了按周实时更新的新模型,叫豆包 Doubao-Seed-Evolving,这个模型是每个礼拜都更新,就没有版本号了,把调度往模型里边直接塞。剩下就是老牌的安全公司 360,也放出了对标 Fable 能力的安全模型,等于美国前脚关门,中国后脚就开始补位了。
大概过去 6 个礼拜,就是这样一路走下来的。本来特朗普还是比较宽松的,结果拉扯来拉扯去,就把一个相对比较宽松的政府行政令,给搞成了现在这样的:这个不许上,那个需要监管,变成这样了。
而这恰恰是 Anthropic 自己一连串动作,加上几个关键事件,把这架天平最后压向了盯模型、卡名单、按国籍这样的一个错误方向。

下边咱们来讲一讲,为什么这个方向是错的。被关的模型本身并没有那么重要,重要的是调度系统,360 就是一个活的样本。
美国把 Fable 5 和 Mythos 5 关了,现在又在卡 GPT-5.6 的测试名单,逻辑很简单:模型太强了,太危险了,咱把这强的锁起来,你们其他人不许用。就跟向中国封锁芯片这个逻辑是一样的。可是他锁错了。
Fable 5 之所以那么强,从来不是说只有底座模型强。它底座模型确实强,但是它实际上是一个很强的底座模型,加上 Anthropic 内化的一整套调度系统。
调度系统是啥?就是决定这个 AI 什么时候调用什么工具,走到哪一步,谁来干活,谁来验收,谁来进行规划,干活错了以后怎么回滚,滚到哪里去,这个就是调度系统。
证据也摆在这了。6 月份泄露的 Fable 12 万字的系统提示词,有一多半都是在讲怎么用工具、何时调用哪把扳手,真正讲性格的大概连 20% 都不到。让模型靠谱的不是它脑子有多神,而是外面整个的调度系统。
而调度最要命的一点是什么?它能够被专项调教。你拿不到 Fable 这样的全能模型,没关系,拿一个还不错的开源模型,盯着一个又窄又危险的领域往死里调,是能够出结果的。
360 就是这件事情最现实,也是最吓人的一个样本。360 是谁?中国老牌的网络安全公司,或者说中国老牌流氓吧,这么讲都没毛病。它自己其实也做了好多年的 AI,只是一直没做出多大响动来。但是你别小看它,它在安全领域里头深耕了几十年,手里头握着大量的安全数据、海量的真实攻防案例,还有几十年沉淀下来的攻防手段与经验。我相信即使大家觉得 360 是流氓,也会承认这一点。
现在它要干的是什么呢?特别顺理成章:找一个当下最好的开源模型,比如说智谱 GLM-5.2,把自己几十年的安全数据掏出来,做专项的后训练和强化学习,你就有一个专门的安全大模型了。再根据过往的经验设计一套专门的调度系统,而这套调度系统直接照着 Fable 那份泄露的 12 万字的提示词致敬一下,就能搭个八九不离十。
这套组合拳打下来,它完全可以在网络安全这一个领域里头做出一个很强的东西来。说我可以达到甚至超过 Fable 5 的水平,都没有问题。
老范打一个比方,大家就能够理解了。比如说 Anthropic 的 Fable 5,它算是什么呢?真学霸,能考上哈耶普斯麻那种学霸,哈佛、耶鲁、普林斯顿、斯坦福和 MIT。这种人进一些大机构如鱼得水,放在哪个岗位上都很快上手,发挥到最强。Fable 就属于这一类的模型,旗舰模型,真学霸。
可是我们现在没有真学霸,拿不到 Fable 了。那好办,我们还有小镇做题家。小镇做题家可能也能考上 985、211,底子其实也没有那么差。扔进到这种万金油的岗位里头,它未必能够比得过真学霸,但是你给它一套很有针对的特定岗位培训,它在这一个岗位上照样可以干得很漂亮。它差的是什么?是换岗位需要重新培训。它不像真学霸,走到哪都强。但是你让它专攻一块,它也是能够出一些很神奇的妖怪的。
360 干的就是把小镇做题家,也就是开源模型,往网络攻防这个岗位上往死里头专项调教。在这一点上,它的杀伤力完全可以不输,甚至超过那个被美国政府锁在保险柜里的全能学霸。
所以你看明白了没有?最危险的门槛根本就不在于拿不拿得到顶级模型,而在于有没有那套特别成熟的调度系统和相应的数据。而 360 这种安全公司,这套东西本来就是人家看家本领,现成摆着呢。你关了 Fable,那我来呗。

下一步,咱们来讲一讲真相。真相一:今天的安全大半靠制度撑起来,不是靠技术。
很多人都觉得,你这个攻防技术好一点,这个差一点,大家很多人都觉得谁的系统更安全,是因为谁的技术更好。要跟大家说,不是这样的,这个真的跟很多人理解的不一样。
你以为现在的大公司、大机构的安全是靠技术防住的吗?不是的。它很大一部分是靠规章制度,靠人事、靠流程、靠纪律管出来的。这个老范还是有点底气的,因为我原来这公司,猎豹移动,也是个安全公司。真正的安全事故里头,大概 60% 到 70%,根子压根就不在技术上,而是人,是操作人员失误,设了个弱口令,或者操作人员不守规矩。你这里本来不应该打游戏的,你把内网的机器连到外网打了个游戏,绝大部分的安全事故都是这么来的。
正因为如此,才得用一大堆的规则、一大堆的管理手段去把人框住。这不是谁的意愿,这是没办法。
你回想一下,你公司里头的信息安全平时啥样?大概率是定期改密码、签保密协议、做合规培训、申请权限走审批流程、年底来一次背景核查。这些几乎就是管理动作,不是技术防御。它防的是不小心,防的是守规矩的人偶尔犯的错。可对于一个铁了心、手里还拿着 AI 工具的对手来说,这个玩意的作用其实是非常非常有限的。
你可能觉得小公司技术不行。咱给大家举一个技术天花板的例子,谷歌的例子。这个是我自己用得特别开心的一个工具,叫 GWS,Google Workspace CLI。做这个项目的工程师叫 Justin Poehnelt,在谷歌干了快 7 年,自己做的工具 GWS,用户非常喜欢。我自己的各台电脑上都装了,甚至我还去给其他朋友也装这个 GWS。
它干嘛使的呢?就是让我们的 AI 智能体也好,让我们的 Codex 或者其他的 Harness agent 工具,可以连接到 Google Workspace 上的各种产品去,比如说发邮件、写日历、处理联系人,在 Google Drive 上面去做 document 或者 slides,都可以,非常非常方便。这个东西一上去以后,很快几千个星就上来了,在 Hacker News 上就冲到第一了。
结果这哥们没两天被谷歌给开除了。原因很简单,因为他这个东西没有走法务和安全审批,还用了谷歌的商标。你如果是自己上去的,那没事,没人理你。你用了谷歌商标了,但是你没有走审批,没有走安全,那就不行。这个事就是违反了内部的规章制度。
在这兄弟被开除的前两天,谷歌刚在 Cloud Next 大会上宣布,官方自己也要做一套 Workspace CLI。就是我要干,你这不行,我给你干掉。
老范请大家细品一下,连谷歌这种技术强到天上去的公司,它管安全、管控还是要靠审批、商标政策、人事处分,而不是什么神的技术。今天全世界绝大多数机构的安全底盘可能还没有谷歌强呢,所以大家只能靠管理型的东西来搞定。
而现在更现实的是什么呢?就是想要这套老的安全体系整体做一次升级,太难了,太贵了。但是贵有贵的好处,待会咱们讲,这有机会。真的把全公司的代码、系统、流程都换成能够扛 AI 攻击的新架构,这个肯定是要花钱的。但是花钱不是坏事,花钱是好事。
所以老范说了,今天最该先动手的第一件事,特别朴素,就四个字:把比例调对。
现在这个比例是失衡的,靠制度、靠人管的东西太重,靠技术真正能防的东西太轻。规章制度是用来管人的,可接下来真正动手的越来越不是人了,是一套会自己进化的方法。拿管人的工具去管方法,就像拿交规去管病毒一样。不是它不重要,是压根不在一个频道上。

那这套管理型的安全碰上真正的高手会怎么样?咱们来讲第二个故事。
你说谷歌强吧,有比它更强的没有?举个最极端的例子,技术上最强的肯定是美国国家安全局,全世界网络攻防的天花板。可就是这样的一个天花板,在测试里头几个小时就被 Mythos 给打穿了。
先把事说清楚,它这个打穿的过程是在一个测试上,并不是说 Mythos 自己上去干的。在安全测试的过程中,Mythos 是拿到了各种安全工具。但是原来 NSA 的人想着,你怎么着得干个几个礼拜吧,或者干个几天,结果一晚上就穿了。
你要知道,任何一个大的系统里头,漏洞本来就是一直存在的。不是说你是 NSA,你就能把漏洞都补干净,没有人做得到这件事情。那平时为什么还安全呢?两件事:
靠漏洞没被串起来,再加上制度罩着,系统勉强还是可以维持安全的。
但是 Mythos 干啥呢?它就是把这套本来零散、孤立的大量漏洞,一个一个串起来,组合成一条条原来谁都没有想到的全新攻击路径,然后顺着它绕过制度,直接钻进去。
这就是一句老话:找一个漏洞不难,难的是把一堆漏洞串成一条完整的攻击链。人脑是串不动的,人脑其实有点像狗熊掰苞米,掰一个掉一个。我们不可能同时把这么多代码都记在里头,但是 Mythos 背后这套调度系统,是完完全全可以把这些东西串起来的。
而且这里头还有一个问题,这都是技术漏洞,这只是事情的一半。真正让老范觉得这事完全无解的是什么呢?是社会工程学,我们管它叫社工。
什么是社会工程学?说人话就是利用人的社会性下手,骗、套、伪装、钓鱼,把人当成系统里头最好攻破的那一环。今天一大半的安全事故,本来根子就在这,不在代码里,就在人身上。
这里头还藏着一个特别致命的结构型漏洞。一个大型系统,比如像 NSA 这种系统,它是一次做完的吗?或者一次整个重新翻过来的吗?不是的。它是一次一次升级升上去的,一次一次打补丁打上去的。你永远没有办法把所有的漏洞都找齐。那怎么办呢?只能靠测试、验收、认证这套东西来兜底。我这次打了补丁了,做一堆验证,做一堆测试,它这么来干这个事。
可是问题在哪呢?就是它的测试过程测的是技术问题,它不会去测社会工程学的问题。一个员工会不会被一句话就忽悠到去点开一个链接,会不会被伪装的领导骗去转账,这种事情是没法去测试的。你测这玩意就没完没了了,只能靠管理制度去防。
所以社会工程学这一块,本来就是技术帮不上忙,只能交给管理的地方。但是现在比较瘆人的是什么呢?攻击系统的是 AI,是 Anthropic 这套模型。这套模型最擅长的是什么?不是找漏洞,不是一个一个把漏洞串起来,它最擅长的一件事是一本正经地胡说八道。在这样的一个底座上,它还能找到漏洞,在串的过程中完完全全可以把社会工程学的东西都用起来。那你想吧,当它串了漏洞,再编瞎话骗人,把这两样东西拧在一起的时候,技术这条线怎么可能能够挡得住它?
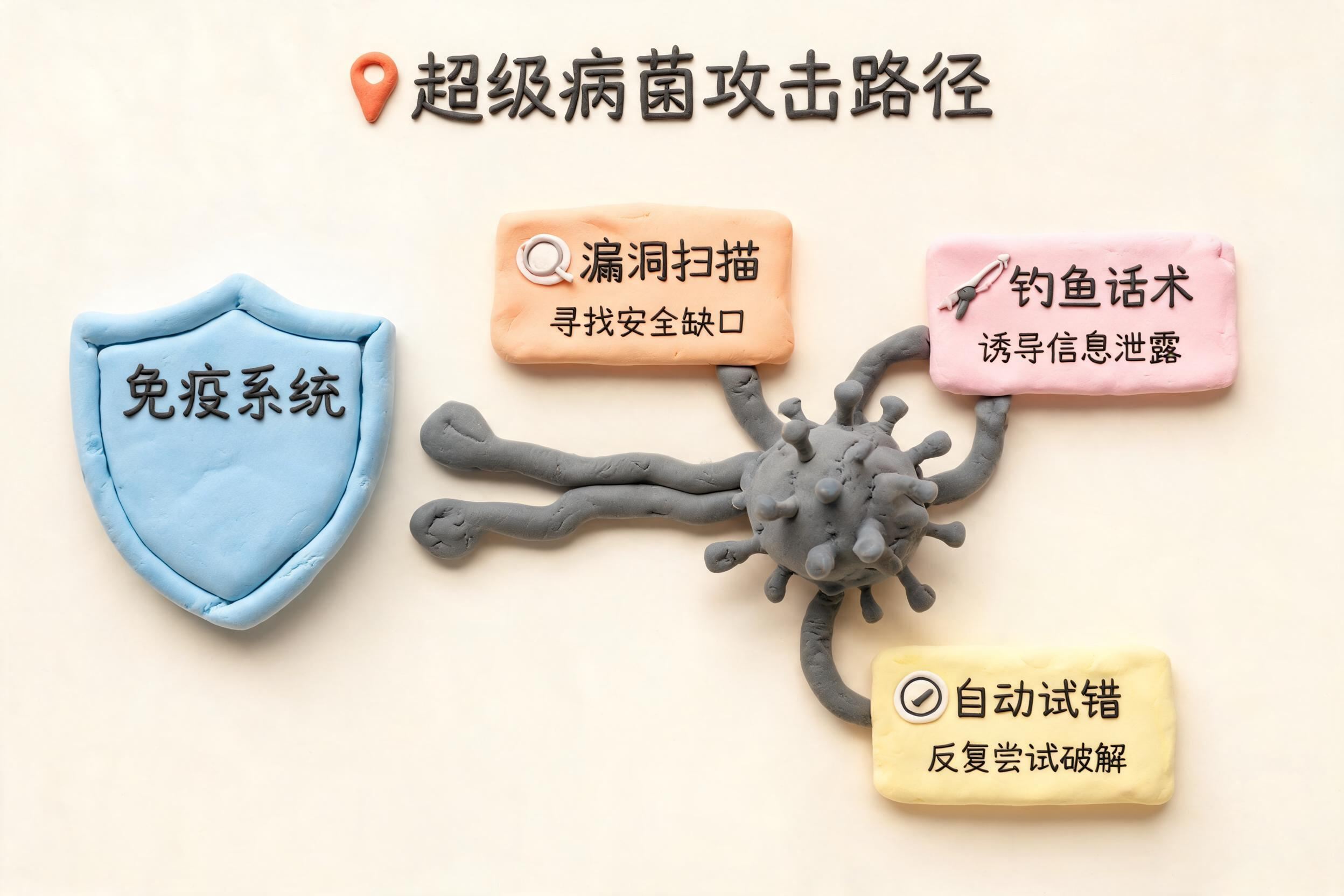
那它凭什么能够同时干两件事?Mythos 这种东西,它是 AI 加上调度,这个东西才是真正强的东西。
为什么 AI 加调度这么狠?它是绕过了免疫系统的超级病菌。老范给大家讲一个最直观的比方吧。人体本来是一个免疫系统,一种病毒来了,你识别它,记住它,产生抗体,下一次你就能扛住。传统的软件安全就是靠这套免疫加疫苗的逻辑,发现一个漏洞,分析,打补丁,全网升级。它对付的是已知的、固定的病毒。
可现在出现的是另外一种东西,有人定向培育了一个超级病毒。它最可怕的不是毒性,而是它会进化,而且是冲着你的防御系统来进化的。这就很吓人了。
我记得以前玩过一个游戏叫《瘟疫公司》。你扮演一个病菌,人类每出一招,比如关闭边境、研究疫苗,你就顺着应对的方向去进化。long is your?一开始要有传播力,但是不要有那么强的伤害力,让它可以慢慢潜伏下来。等它传遍了以后,特别是像冰岛这种与世隔绝的地方都传上了以后,你再嘁哧咔嚓把剩下的所有点都加到破坏力上。这个游戏胜利的方式就是全人类灭绝,一个都不剩。这个稍微有点吓人。
但是 Mythos 是完全跟这一套系统一样的工作方式,现搬到网络攻击上。一套足够强的攻击型调度,能够像那个玩家一样,实时盯着安全系统的标准应对,自动调整攻击链的方向。你这边按照老剧本去打补丁,它那边已经绕着你的疫苗,进化了三四条新路出来了。
为什么传统免疫一定扛不住?有两个硬的原因。
而这个事情已经不是吓唬你了。前面 360 拿安全数据做专项调教,豆包把调度直接缝到每周进化的模型里头去,都是这株超级病菌正在被一家家造出来的一个信号。危险不在于某个被关起来的特别强大的模型,而在于这套会进化、还能够连人带机一起来骗你的调度系统。而这个调度可蒸馏、可复制、可开源,这个东西你是防不住的。

所以说美国开错枪了,找错目标了。它对准的是模型的名字,这个东西叫 GPT-5.6,那个叫 Anthropic Claude Mythos,这个叫 Anthropic Claude Fable,都是这样的东西。我们把这个模型限制住,然后限制国籍,只有美国公民才可以用,其他人都不可以用;或者我开一个名单,我审核过的名单可以用,其他人都不可以用。这个对于政府来说,他们就习惯这套东西,这个是最好听、最好盖章,却最没有用的东西。
为什么这样呢?第一个,中国模型其实现在已经很强了,图纸也在不断地泄露。靠蒸馏 OpenAI 和 Anthropic,中国这批新的模型,比如智谱 GLM-5.2、MiniMax M3、Kimi 的 K2.7 Code、豆包的 Seed 2.1 Pro、豆包的实时更新,还有千问的 3.7 Max,这些模型已经非常非常强了。虽然比不上 OpenAI 的 GPT 和 Anthropic 的 Claude,但是干很多事情没有问题了。
更要命的是什么?Anthropic 自己还接二连三地漏底。去年 Claude Code 的全套源代码泄露了一次,泄露完了以后,像 open code 一大堆这样的产品就出来了。今年 3 月份,Claude Code 51 万行代码又被完整泄露了,打包错误嘛。6 月份 Fable 的 12 万字提示词又被扒了个干净,上传到 GitHub 上了。源代码、提示词,等于把这套调度系统的图纸直接摊在全世界面前了。拿着图纸,再加上中国工程师的勤奋以及人员密度,加在一块,实际上叫内卷吧。以及中国工程师的内卷程度,想搭一套可以调度的系统,难度真的没有那么高。
第二个更根本的是什么?你按国籍,相当于自废武功。别忘了,美国本来就是个移民国家,它跟中国还不一样。虽然咱们有 56 个民族,但是有百分之九十几都是汉族,我们基本上属于是民族国家。美国是移民国家,它的 AI 大厦一大半都是外籍人才垒起来的。
比如像 Andrej Karpathy 这样的人,人家是斯洛伐克出生,现在拿的是斯洛伐克和加拿大的双国籍。按照美国商务部的要求,他都不能使用他们公司的 Fable 5 和 Mythos 5。而且现在各大 AI 公司里头哪的人最多?中国人最多。你说靠国籍、靠国籍准入来去封锁,第一,肯定不现实;第二,这个本来是美国最有优势的地方,它可以吸引全世界的顶尖天才去做事情,现在它把这个优势放弃掉了,说不,我只让美国人做,这不就是本末倒置了吗?
这里还有一个特别生动的例子。马斯克当时建 xAI 的时候,创始团队十几个人,拿符合美国军工那套安全要求,比如说美国国籍,没有几个人能过关。后来 xAI 被并进 SpaceX 的时候,SpaceX 因为要接 NASA 和军方的订单,安全门槛一把就拉死了,结果 xAI 最初始的创始团队一个都没剩下,全走干净了。当然,这可能不是全部的原因,但是安全和国籍门槛肯定是创始团队出走的原因之一。
所以你看,门槛往那一拉,人才就走了。美国之所以强,靠的就是把全世界聪明人都吸引过来。现在为了安全按国籍设卡,等于亲手把自己最大的优势直接给嘎掉了。
讲到这,老范给大家补一个几千年来中国人一直在犯的问题,就是限制游牧民族买铁锅,当然还有其他铁器。逻辑其实跟今天这事一模一样。
游牧民族生活的地方其实是有铁矿的,但是他们没有燃料,没有煤,也没有木材,只有草,它是不可能靠草把铁给冶炼出来的。所以当时的中原地区王朝就想说,那我卡住你不就完了吗?你没有铁器,你就没有兵器,你就不能劫掠我,不能给我捣乱了。
咱们执行了上千年的禁铁这样的一个规则,但是有效吗?其实没有效果的。商人在不断地把铁器偷偷地运到那边去,几千年来从来就没有停过。这些游牧民族拿着这些比较劣质的铁器,也是一次一次地把咱们摁在地上摩擦,一次一次进来劫掠,甚至还有两次灭国,元朝一次,清朝一次,直接把汉家江山给断掉了。
所以就算是咱们执行了这么长时间的铁器管制,其实是没有效果的。美国今天想干的事,跟当年那套限制铁器、靠卡住几个最强模型来保住自己的安全,其实是一样的。这条路几千年前就被我们已经走废掉了,说明了这事搞不定。

既然封不住,真正的打法到底是什么?你说难道就只能看着中国在这超越吗?最后一节咱们来讲这个事。正确的打法肯定不是捆住自己,而是跑起来,去造新的疫苗。
先排除错误答案。有些人说,那既然模型很强,我把模型封了;这个数据很强,我把数据封了;这个调度系统很强,我把调度系统也封了;我把所有东西都封了,这不就没有了吗?你可以把所有的动作去做记录,可以去做事后追溯,这个事可能还有点意义。但是如果你说我想靠封,靠层层设卡、层层审批,那只能捆死自己的手脚。
真正对的打法是反过来,比谁更开放,谁更创新,谁跑得更快,谁更愿意把最新最强的模型拿出来,更能够造出更好的防御来。大家就应该比这个。
你看硅谷有一拨人在 X 上面的签名最后是 e/acc,意思是有效加速主义。核心就是一句话:先跑起来。对手在追的时候,你唯一该做的就是继续往前冲,而不是回过头来把自己捆住。做那个最开放的,把全世界最优秀的人才吸引过来,做出最新的东西,这才是真正的防护。靠关门、靠设卡求安全,现在再想肯定已经晚了,早几年没准这事还有效,现在没戏了。
那跑往哪跑呢?老范给出的答案五个字:靠 AI 防 AI。造出新的疫苗来。
旧的免疫系统挡不住会进化的超级病菌怎么办呢?唯一的出路就是造一套相同的会进化的、同样机器节奏的新防御系统。让防御方的 AI 调度去 24 小时自动巡检、自动修补、自动做红队攻击,跟攻击方在同一张时间表上去掰手腕。
而且老范要讲什么?这不该是负担,而是天大的机会。

大家还记得曾经有一个神奇的东西叫千年虫吗?在 1998 年、1999 年那一波 IT 大爆发,我在那个时候在中关村卖存储设备,卖硬盘阵列,卖光盘库,那时候简直是卖疯了一样。当时一喊千年虫,大家就必须要买。
什么叫千年虫?很简单,最早为了省内存,我们表达一个数字只有两位,就是最后两位。52 就是 1952 年,82 就是 1982 年。结果你过了 2000 年的时候,就是 00。对于原来的电脑来说,00 就相当于是 1900 年。比如一个银行,给人算利息,刚存进来的钱,00 年存的,你说给人算多少利息吧?100 多年的利息吗?这没法算。银行、电力、航空,这事要乱套。这个就是一个非常具象的名字,叫千年虫。
为什么要讲这事非常具象呢?完全不懂技术的人都能够一眼看明白威胁到底是怎么回事。于是怎么办呢?全世界像疯了一样去更换、去迭代、去重构、去升级他们的 IT 设备、IT 系统,需要的和不需要的通通都换一遍。
我们当时卖了大量的设备出去,他们压根就不需要换。其实从九几年开始,他们写的程序都已经是 4 位的年数了,就已经不是两位的年数了。那不管,反正有机会花钱,别人都花了,别人有的我也得有。整个 IT 产业借着这股力、借着这股劲,硬生生地上了一个大台阶。
所以我要说,我们现在面对的就是一个新的千年虫时刻,而且这个威胁比当年要真实得多,也可怕得多。那何不把它变成一次大的爆发的引擎呢?把大量的社会资源投到 AI 安全这个产业里边去,制造新的疫苗,建设新的防御,用 AI 来防御 AI,让整个 AI 产业再迎来一次像千年虫之前那样的巨大飞跃。这才是把今天这个有点吓人的故事讲成一个正向、积极过程的唯一办法。
美国现在做的恰恰相反。它在关门,去应对一个本来应该奔跑去应对的危险。它把最显眼的那扇门焊死了,惊动了所有守规矩的人,甚至损害了所有守规矩的人。可真正的危险,正从开源、从泄露的图纸里边、从一个个被逼走的人才身上,慢慢浮现出来。
门是焊不死的。与其追着去关那道关不严的门,去层层设卡,还不如赶紧低头,去造下一代的疫苗。能不能把这场惊吓变成下一轮的繁荣,就看我们是选择捂住、封住、关住,还是选择跑起来、造出来、赢回来。
这就是咱们今天要讲的故事。
2026-06-29 08:56:07

大家好,欢迎收听老范讲故事的 YouTube 频道。
前两天,也就是 6 月 23 日,在德国汉堡,全球超算一年两度的“华山论剑”——TOP500 榜单更新了。榜首换人了,一台叫做灵晟的中国超算悄无声息地空降第一,把霸榜一年多的美国机器 El Capitan 挤到了第二。
这是自 2017 年神威太湖之光之后,时隔 8 年多,中国超算重回世界第一。大家第一个上来喊“遥遥领先”吧?这个事跟遥遥领先还是有点关系的。第二个,有人说这不就是 AI 算力吗?还真不太一样。还有人说,谷歌呢?微软呢?他们怎么不来?怎么让中国这样的一个公司就冲上来了?这个机器、这种超算,难道把它运到德国去跑吗?大家都知道这种超算都挺大的。如果不到德国跑,那它怎么算的分数呢?
咱们把这个事跟大家稍微掰扯掰扯:这到底是个什么比赛,考的什么题,这个题是算什么的,程序是谁写的,成绩是怎么去验证的,这个机器到底有多大、多费电,以及现在这个超算跟 AI 到底是不是一回事。谷歌、微软、xAI、美塔、Oracle 都在这拼命地建算力中心,那咋中国的机器就跑去夺冠了呢?怎么觉得不对呢?中国还有多少这种超算?平时这些机器都干嘛的呢?最后,咱们再讲讲 AI 跟这种超算之间到底是怎么结合的,英伟达能不能顺手把这活干了呢?

首先要说清楚,这到底是一个什么样的比赛,考的是什么题。这个比赛叫 TOP500,它实际上是一个民间榜,从 1993 年开始办,每年 6 月份和 11 月份各发一次,是超算界的高考成绩单。只考一道题,叫做 LINPACK。说人话,就是解一个超大规模的线性方程组,每秒能够做多少次浮点运算,就考这玩意。
这里头要牢记两个词。一个叫实测,英文叫 Rmax,不是厂家吹的理论峰值 Rpeak。Rmax 就是说你要跑这个题,而且要跑稳定,跑很长时间。灵晟实测是 2.198,峰值是 2.736,压榨出了八成的算力,这已经是非常非常强的了。
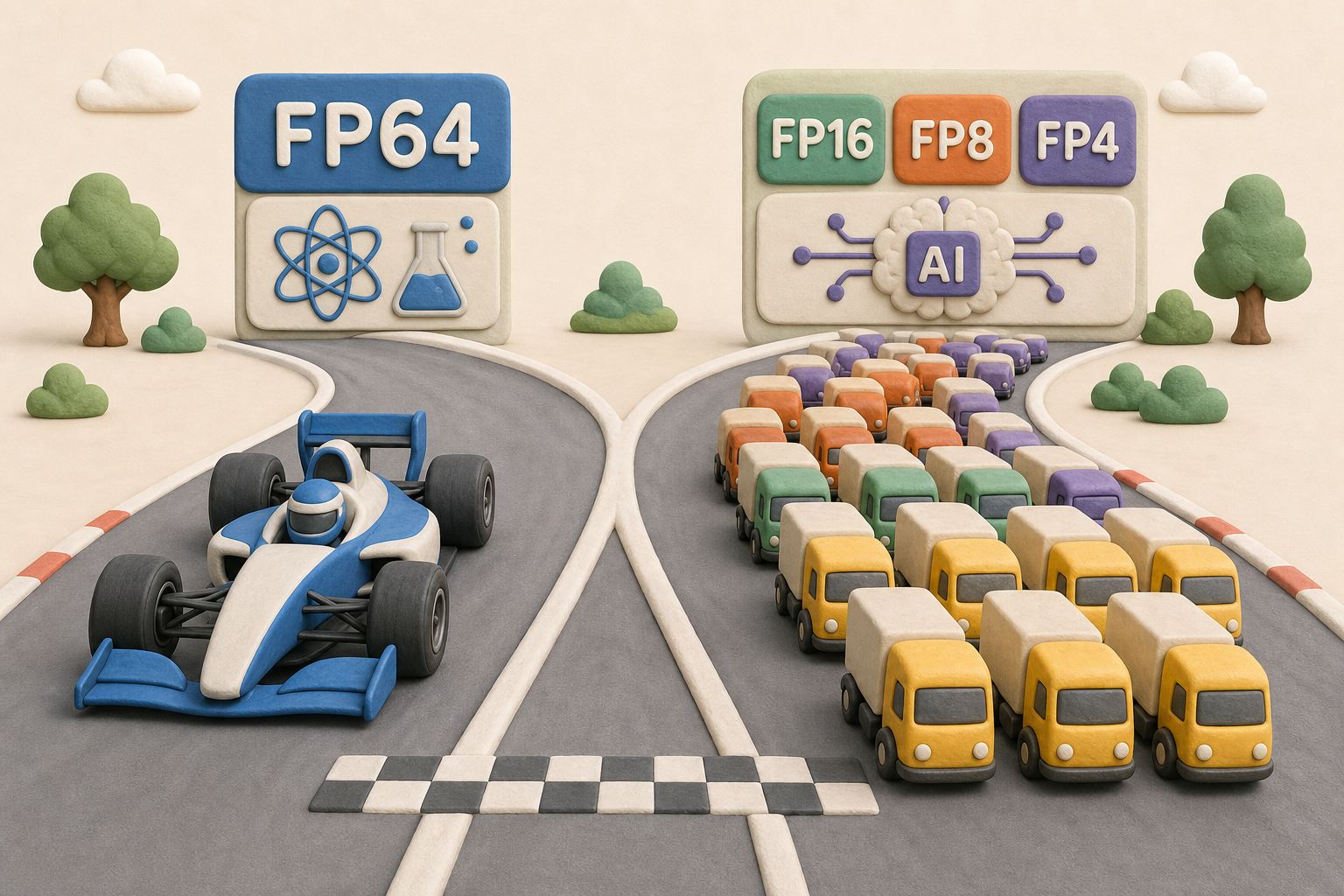
另外一个词是双精度,FP64。这个数咱们先记着,后边咱们再仔细讲它跟现在的 AI 算力到底有什么区别,就差在这数上了。

那么这道 FP64 的题到底算什么呢?咱们打个比方吧,一架飞机机翼周围应该有气流,我们要用计算机把空气切成几十亿个小方块,每一块的气压、风速、温度都由旁边几个方块来决定。你推我,我顶你,大概是这样的一个过程。
几十亿个方块就有几十亿个相互咬死的方程,必须同时解出来。走完了这一帧以后,你要再解一次下一步怎么样了,要反复算几万次、几十万次,这就是 LINPACK 这道题的真身。
为啥是 FP64 呢?就是它要求的是准,一定要准。因为 FP 后边这个数越高,说明小数点后边留的位数越多。我留得多了以后,最后就可以把误差算得相对比较小。
刚才咱们讲了,这个东西要算几十亿个小方块,里头要迭代几万次,一次模拟上万亿次的运算,一次模拟上万亿次的计算,误差会滚雪球,这个东西叫累计误差。低精度算到后边,模拟的飞机自己在电脑里就散架了,根本就飞不起来。它这个东西必须要特别准,到小数点后十几位的双精度,所以要用 64 位。记住这个“准”字。
那这台机器到底有多大呢?或者说这种机器分不分量级?咱们前面讲过张雪机车的故事,它这个机车比赛是分量级的。你去拳击比赛,也是分量级的,你不能找个大胖子跟人小瘦子去打。
这个 TOP500 分不分量级呢?要讲清楚,这个比赛是不分量级的,没有任何限制。所以这种比赛天然偏向于不差钱的国家队,你做的机器越大、越费电、越烧钱,你的得分就越高。基本上大家可以把它理解成不分重量级的拳击比赛。
当然它也有另外一个比赛,叫 Green500,叫绿色 500,它要计算能效比,就是我的 1 瓦到底能够算出多少次来。在这点上,中国这个机器灵晟比美国那机器就差好远了。

讲到这,机器肯定是巨了的个。这机器到底有多大呢?首先我们先说它的计算速度,是每秒 2.198 百亿亿次双精度。大家知道这数就完了,不需要细究这数到底有多大,反正现在这就是世界最快的了。
它使用的叫 LX2 处理器,一颗处理器上是 304 个核心,每两颗处理器是一个节点,2 万多个节点,4 万多颗 CPU,一共是 1,379 万个核心,装 92 个机柜,基本上可以摆满整个机房大厅。
这个东西肯定是耗电魔兽,这台机器满负荷是 42 兆瓦,跑一年 3.7 亿度电,电费 2 亿多,还得按中国的电费算,还得给它专门配变电站和整套的液冷系统。所以这个东西就是中国这套大力出奇迹的典范。

那你说这机器我能把它运到德国去吗?肯定都不会。你把这机器运到德国去,它连电我估计都烧不起。所以这种机器是在自家跑,提交成绩,然后官方来抽查,通过这样的一个方式去参加比赛的。1993 年起一直是自愿提交的一个状态。
那你说有没有人作弊?怎么能够保证提交的数据是准确的呢?有四道闸门。
而且耗电也是有标准的,因为后边还有 Green500 的这种分级。L1 测全机,还有一个就是 1/64 节点的外推,L2 是 1/8,L3 是整机连网络存储实测。所以超算比赛更像是交一份可复现、可抽查的实验报告。

再说第二名,美国这台 El Capitan 是一台什么样的机器呢?它是美国劳伦斯利弗莫尔国家实验室的机器,由惠普 Cray 制造,1,134 万核,大概是 29.7 兆瓦。它这个机器主要是干嘛的呢?主要是模拟核爆的。
刚才咱们讲,这个劳伦斯利弗莫尔国家实验室是美国能源部的实验室,就是做各种核实验的实验室。现在不让真的去做核试验了,那就只能在电脑里炸了。
它跟咱们的机器最主要的差别在哪呢?咱们这台灵晟是全 CPU 的机器,里头是没有 GPU 的。而惠普造的这个 El Capitan 是一半的 CPU、一半的 GPU,它实际上是 AMD 的算力核心,所以有 CPU 加上 GPU 二合一的这种加速芯片,里边用的是 MI300A APU 的这种芯片。这个芯片对中国也是禁运的,它靠 GPU 加速运算,所以差距就差距在这了。
灵晟是纯 CPU,1,379 万核,42 兆瓦,2.198,它是第一名。而 El Capitan 是 CPU 加 GPU,1,134 万核,29.7 兆瓦,1.809,它是第二。但是耗电我们也比它耗得多,灵晟多耗 4 成电,换来 2 成的性能提升。赢,在绝对值上肯定赢了,但是从能效上来说,稍微差那么点意思。
但是灵晟有一个比较强的地方是什么?全国产,CPU 也是国产的,操作系统也是国产的,就是费点电吧。
既然这个机器是全国产的,那我们就关心它这个 CPU 到底是一个什么样的情况。首先要说,这个 CPU 不是 X86 架构,也不是 RISC-V 架构,这个 CPU 是 ARM 架构,Armv9 架构的。大家注意,Armv9 的所有专利,华为都已经得到授权了,它在没有 ARM 新授权的情况下,可以继续使用 Armv9 架构去设计新的芯片出来。所以这事跟遥遥领先还是有关系的。
这颗芯片是华为参与设计,与鲲鹏系列芯片是一脉相承的。每颗 304 核,由两颗小芯片拼起来,32GB 片上 HBM 加上最多 256GB 的 DDR5 内存,把这玩意放在一起来使用。现在中国你说能有 HBM 吗?也有,就是稍微低一些。咱们现在长鑫存储也是可以做出这东西来的。
那为啥不要 GPU 呢?为啥全要 CPU 呢?它这个核里边内嵌了 ARM 的向量和矩阵单元,所以 CPU 里头干一部分 GPU 的活也是可以干的。在 GPU 的运算上,它叫够用,但是不能算碾压吧。
至于说这个芯片是谁代工、谁做出来的,官方并没有公开。但是华为参与设计,大概率不能在台积电去代工了,因为台积电现在不给咱们做了。所以它大概率还是在中芯国际做的 7 纳米芯片,也怪不得耗这么多电嘛。
那你说我能不能买一个 LX2 的 CPU 来使呢?这个东西是买不到的,因为这个 CPU 是专门给超算来设计的。但是你说我现在想用华为 ARM,也就是鲲鹏的架构,去做自己的服务器,行不行?这个也是可以的,这个芯片是有卖的。所以这个 LX2 算是特种定制款,但是它这套体系,就是鲲鹏这套体系,大家是可以买得到的。
下一件事,你说大家现在拼的都是 AI,都是英伟达,你做了一个这样的东西到底为啥?这跟 AI 有什么关系没有?或者微软、谷歌他们都哪去了?它参加这比赛,不是把中国队碾压了吗?
这要讲清楚。首先微软来了,微软是在微软云里的一台机器去参加了比赛,得了第 32 名吧,反正名次很靠后。谷歌确实没来参加,因为这事跟它没关系。但是要注意,AI 算力跟我们现在讲这超算,是完全两个不同的概念,算的题不一样。
刚才还记得咱们强调那数吗?FP64,它要求的是准,不能有误差,或者误差尽可能要缩小。而 AI 玩的是什么?玩的是快和多。AI 上来了以后就是 FP16,只有 16 位的浮点数,甚至还有 FP8。咱们最新的,比如像 DeepSeek V4,包括现在新的英伟达 GB300 以及华为的昇腾 950 这些芯片,人家玩的是 FP4。我只在 4 位的浮点数上去算,这样就可以同时算更多的数。我不需要你给我算这么准,这么小的误差,差不太多,我只要把这么多的向量算在一起,我就可以得到结果了。所以这完全是算两个不一样的东西的。
让它们这个比赛也会进行这种混合精度计算。混合精度的时候,美国那台 El Capitan 里头塞满了 GPU,它就可以得冠军。但是你说我不算这个低精度的,我就算 FP64 的,那咱们就比它强。
所以超算有点像 F1 赛车,单点登顶,就追求极致的精准。AI 中心有点像万人货运大队,几万张 GPU,求的是吞吐量。但是这个细致的活,你就别找我了。
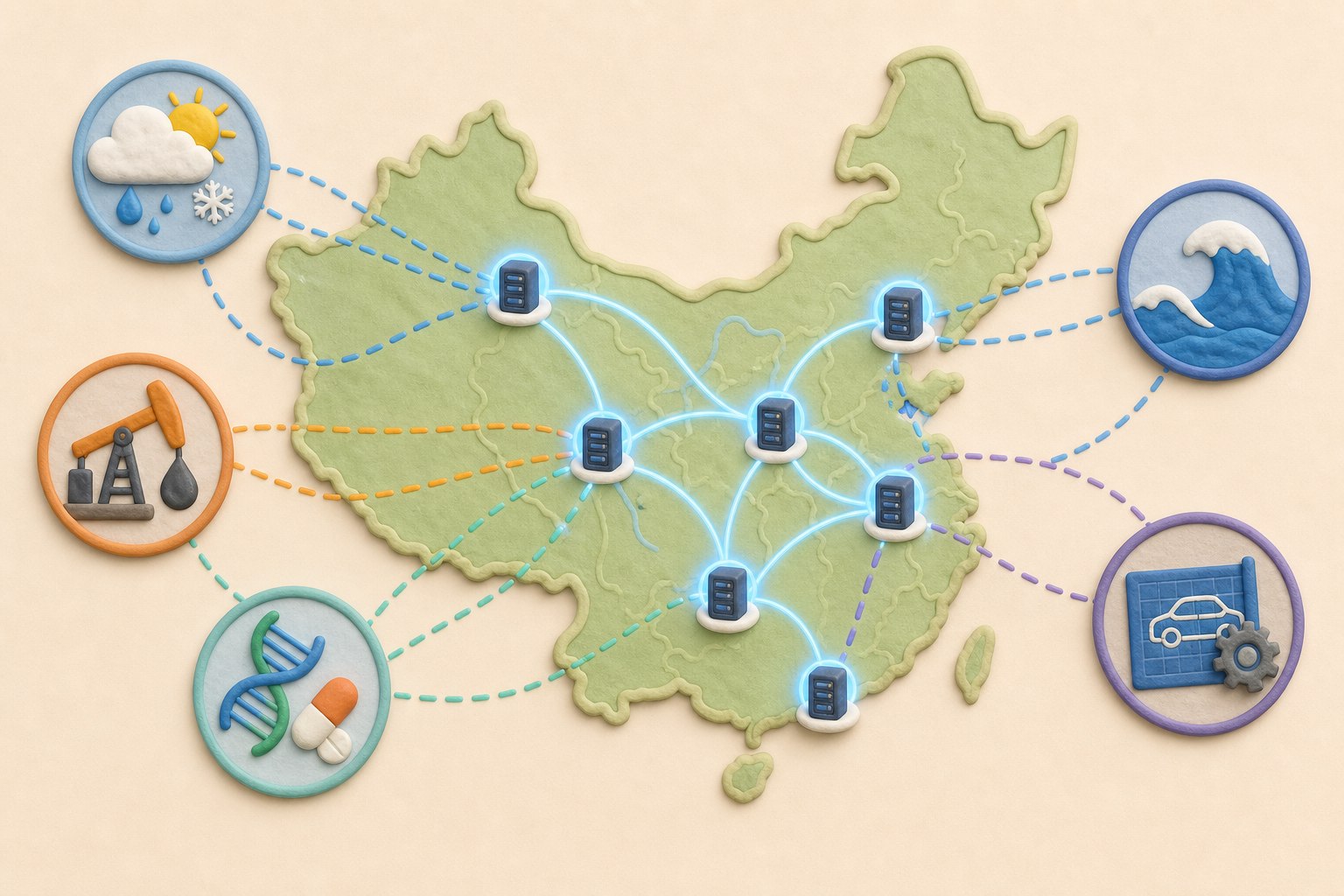
那咱们这台机器干嘛使的呢?刚才咱们讲了,美国那台机器是玩核爆的,咱们这台机器来自于深圳超算中心。深圳超算中心其实主要是算天气的,天气预报,各种天气的长期模拟和仿真,主要干这个使的。
中国还有很多的这种超算中心:
所以中国是有一套网络,骨子里边是给产业、科研当水电煤来使用的。美国是把最强的机器供起来做绝密国防的,这个是两个不同的模式吧。

很多人就说,这 AI 跟这种超算到底是什么关系呢?我在这上跑大模型行不行?肯定不行,这上跑大模型会跑得慢死的,因为里头没有 GPU,全是 CPU。
那你说我什么时候用超算,什么时候用 AI 呢?其实在这种配合上有两步。
什么意思呢?就是超算可以仿真地震、天气、核爆,做一大堆的仿真数据以后,直接把这些数据塞给 AI 大模型,让它把这个数据吞进去,训练了以后,你下次问这个 AI 大模型说,来,给我仿真一下核爆了以后会怎么样,它会快速地给你得出一个结果,而且这个结果相对来说还比较准确。
这个有点像什么呢?就是你上超算计算出一大堆的结果来,然后总结规律,变成这个九九乘法表。然后你让旁边的一个一年级小朋友说,来,把九九乘法表给我背下来。背完了以后说,给我算一下这个几乘几,啪就给你算出来了。它是这样的一个工作方式,这就是 AI 跟超算之间相互结合的玩法。
那有人说,上英伟达是不是可以碾压国内这台灵晟呢?还不行。英伟达现在为了能够进行更高效的 AI 运算,也就是低精度的高并发运算,它故意阉割了自己 FP64 的能力。现在英伟达的 GB300,它在 FP64 上的能力比它早期的这些芯片还要次,还要再差一些,这个就是不同的进化方向。
最后咱们总结一下。
所以灵晟能够在时隔 8 年之后夺冠,确实是我们做出了巨大的努力,这是值得肯定的。但是也不要上来就喊遥遥领先,我们什么都强,我们还是要理性地来看待这件事情。
好,今天这个故事就讲到这里。感谢大家收听,请帮忙点赞,点小铃铛,参加 Discord 讨论群,也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。

2026-06-28 08:52:15
大家好,欢迎收听老范讲故事的 YouTube 频道。大家看到这个节目的时候,应该就是 6 月 28 日,也就是老马的 55 岁生日。原来大家猜测 SpaceX 会在这一天上市,但是老马等不及了,6 月 12 号就把 SpaceX 给轰上市了。
为什么等不及呢?原因很简单,现在的股市波诡云谲。你看看每天蹭蹭蹭往上涨,蹭蹭蹭往下跌,这个速度实在是太快了。美国还有比较多的公司在上面折腾,像韩国这种,今天向上涨熔断,明天向下跌熔断,现在这个股市已经疯了。所以在这种情况下,早上市一天都是好的。
而且它上市了以后一顿骚操作,股票开市即巅峰,后面哗哗掉下来了,导致 OpenAI 说:
咱再等一等吧,咱明年上吧。
6 月 28 日,老马生日这天,咱们来讨论一下合并的事情。咱们分五个问题来讨论,看看有没有大家关心的问题。

这个故事适合两类人来听。第一类是投资者,不管您是 SpaceX 投资者,还是特斯拉投资者,都可以听一听。但是本频道从来不做具体的投资意见和建议,赚了是您自己的,亏了不要来骂我,这是要跟大家讲清楚的。
第二类,是喜欢科技的人。对于航天、无人驾驶、机器人、AI 感兴趣,那这个故事也适合您来听一听。
下面我们就来依次分析这 5 个问题。
大家要注意,最核心的决策者就是马斯克自己。如果他不想合并,谁摁着他也没用;如果他想合并,8 头牛也拉不回来,他就一定能合得成。所以先看看马斯克乐不乐意。
2016 年 8 月 4 号,马斯克亲口说:
没有理由把 SpaceX 跟特斯拉合并,这两家公司之间的关系非常脆弱。
这是特斯拉 2016 年 Q2 分析师电话会上的原话,摩根士丹利提问,当场被否认了。
2024 年 SpaceX IPO 路演材料里头还写着,说在可预见的未来,不打算向 A 类股东派发股息。什么叫 A 类股东?就是上市以后买 SpaceX 股票的散户和机构,他们叫 A 类。B 类就是 10 倍投票权,是由马斯克和内部人员持有的这些股票。
什么人会分股息?我需要拉市值,这帮人会分股息。比如苹果、谷歌、Meta,它们过一段时间就是我回购吧,我分红吧。它为什么干这个事?一干这个事,你的股价就会上涨,整个市值会上涨,你就可以有更多的现金、更多的融资空间。但是 SpaceX 在路演文件里说了,我不干这事。那个意思就是说,我不需要钱,我不惦记再从股市上搞到更多的钱了。
既然不需要更多的钱,实际上也就不需要特斯拉反哺。原因很简单,SpaceX 缺钱,它是亏钱,特斯拉是挣钱的现金奶牛。他都不惦记向股市上去割韭菜了,那更不需要特斯拉的钱了。所以从马斯克前面的这些话来说,他并不特别着急把这两个公司合并起来,甚至他不太想合。
2026 年 5 月 26 日,CNBC 援引知情人士的话说,马斯克已经和他最信任的同事讨论过两家公司合并的问题了。5 月 30 日,《财富》杂志做的报道,合并可能诞生 3.4 万亿美元的公司。这句话什么意思?就是把两家公司市值直接一加,就是 3.4 万亿美金。

第二个就是,他认为 SpaceX 现在泡沫很大。SpaceX 这个股票其实不应该值这么多钱,而特斯拉是实打实在那挣钱的,但是又被明显低估了,因为特斯拉的股价从高点上已经回落了不少。如果用 SpaceX 去兑换特斯拉的这些股票,对于马斯克来说,肯定是特别划算的。
6 月 16 日 SpaceX 公布的招股书里边提到了特斯拉 87 次,提到了马斯克 174 次。人家是创始人,你肯定多提几次,但是特斯拉提到的次数也是非常多的,这个频次本身也是一种信号。
而且 2025 年 11 月份,马斯克在自己的 X 帖子上还写了:
我的公司在朝着融合的方向发展,这在某些方面可能会让人感到意外。
当然这个并不是指 SpaceX 要去合并特斯拉,而是指 SpaceX 合并了 xAI。发了这个帖子之后没过多长时间,就把 xAI 给吃进去了。
那你原来说两家没关系,后边怎么折腾折腾就要合起来呢?差不多 10 年的时间,怎么这弯子就转过来了呢?
2016 年没理由,是当时 SpaceX 不值钱,特斯拉正在烧钱,合并是没有协同性的。10 年后的今天,逻辑已经完全反过来了。SpaceX 的估值已经贵出天际来了,用任何的理性方式都已经没法去解释它为什么这么贵了;而特斯拉反而成为了现金奶牛。在这个时候,两家合并是有好处的。
SpaceX 故事讲得特别好。因为对于美国股市来说,最重要的不是你现在挣多少钱,而是你未来有没有故事。SpaceX 有未来故事,而特斯拉现在有现金,而未来的故事正好不太好讲了,那合并这个事情就顺理成章了。
所以咱们前面问会不会这个问题,答案几乎是板上钉钉的。只要马斯克还在,就一定会去合并,合并只是一个时间问题。
这个其实是一个很有意思的问题。很多大公司都喜欢分散上市,只是这些大公司分散上市了以后,并不喜欢合并。原因很简单,那些公司内部是通过很复杂的组织架构,以及各种有限合伙企业等等这样的协议控制这些公司。它可以让大家觉得这是不同的公司,你不光是可以向不同的人割韭菜,还可以干一件什么事?左手倒右手。都是我的东西,从这个口袋里揣到那个口袋里头,我又多了一笔收入进来。
但是马斯克走不了这条路。马斯克是特斯拉的 CEO,SpaceX 的也是 CEO;Neuralink,他是创始人;The Boring Company,就是那个做隧道的公司,他也是创始人。所有这些东西摆在面前,一眼就看出来都是你,没有别人。所以你最后只能合并,你骗不了别人。所以他跟其他公司确实是有一些差异的。
马斯克原来投资 OpenAI 的时候,他也去跟山姆·奥特曼说:
算了,别费劲了,你让我当 CEO,我来给你管吧。
他就是一个控制欲很强的人,所以最后只能合并。
你不合并的话,两套董事会、两套财报、两套审计、两套投资者关系,每年光折腾这些事,大概上千万美金的成本就扔出去了。其他人愿意去维持这么多壳的原因,是你可以去割韭菜,可以左手倒右手。马斯克又没闲心思跟你玩这个事。
另外,上市公司之间的关联交易本身也是很麻烦的。任何两家公司有共同控制人的时候,你去做关联交易,都是需要有更多的成本去进行披露、进行审核,甚至有的时候还要过董事会和股东会,这个非常非常麻烦。
那你说它们俩公司有什么事情是一起干的呢?SpaceX 买了特斯拉 Megapack,6.97 亿美金。什么是 Megapack?就是它那个电池做的储能电站。然后买了 Cybertruck,1.31 亿美金。这个是在 SpaceX 没上市之前干的。
如果 SpaceX 上市了以后,前面那一项还是说得过去的,因为你建算力中心,算力中心都要配这个东西,而美国做这玩意做得最好的就是特斯拉。但是你说你去买 Cybertruck,如果当时 SpaceX 上市了,这事没法弄。你为什么买这玩意?这有问题。当年的瑞幸咖啡就是因为类似这样的事情倒台的。
但是对于上万亿美金的公司来说,这个 1.31 亿不是什么特别大的事。另外大家也给马斯克一个面子,而且他自己内部做的这些账目应该还是比较平的。SpaceX 花真金白银把 Cybertruck 买回来了,而且只要发火箭、发星舰,他就开着 Cybertruck 满街跑,还给 Cybertruck 做个广告。这玩意你说算关联交易吗?打死了都得算。当两边都上市了以后,这个事是很麻烦的。

还有一个问题是什么呢?你同一个人管两家公司,股价差距太大了以后,散户百分之百会起诉你。
像国内其实也有很多这样的故事,比如说有很多房地产公司是上市公司,房地产下面的物业公司也是上市公司。但是物业公司通常很挣钱,房地产公司会亏得一塌糊涂。原因很简单,物业公司是个轻资产公司,他就错在这,给你做点服务,做点什么这些东西就搞定了。而且你还非买它不可,这房地产公司把房子盖了,你就必须要雇他的物业公司,你换不了。
那么下边就有人说:“你这有问题吧?你是不是把房地产公司的利润装到物业公司里头给大家发了?”房地产公司的股东肯定不乐意,这个是很正常的。以后如果特斯拉股价跌了,SpaceX 股价暴涨,那它股东肯定去告他。两边都是马斯克,你是 CEO,你是不是偏心了?
所以这就跟大家解释清楚了,为什么一开始不合并。一开始我要分头割韭菜。为什么现在合并?因为你就是马斯克一人管,控制欲很强,不合并肯定被人告死,所以只能合并了。
三种玩法到底怎么个玩法呢?首先给大家一个结论,一定是 SpaceX 吃特斯拉,不可能是剩下两种。
SpaceX 现在的估值,现在的股票水分要更大一些,用它去吃特斯拉划算。特斯拉的股价是老老实实用 PE 撑起来的,虽然 PE 也是 200 多倍,但是人家是有利润的,是现金奶牛。而 SpaceX 那是 PS,上百倍的 PS,从来没见过这样的公司上市,这个水分太大了。所以一定是要用有水分的这边去吃另外一边,这是第一个原因。
SpaceX 才代表未来的故事,而特斯拉代表的是昨天的故事。你想想汽车这个东西,除了在美国,其他地方其实没有那么好卖。你跟中国车打不过,比内卷这件事情,你真比不过中国汽车,真比不过中国新能源。美国是因为贸易保护,不让中国车去,要不然的话,早把它摁在地上摩擦了。
很多人说这不对,特斯拉的车做得非常好。特斯拉的车确实要比其他所有电车做得都好,但是你想想特斯拉的车是多少年更新一代?六七年,有的 10 年才更新一代。中国车呢?一年更新好几代,这玩意你咋比?
剩下的,比如说电池的业务、储能电站的业务,是挺挣钱的,这玩意一点都不性感。你说你特斯拉能干,比亚迪能不能干?宁德时代能不能干?
再有其他的,比如说机器人的业务,这个也很棒,但是你现在还没证明你到底能不能做出来,什么时候量产,量产出来会有什么新的问题,你不知道。而你做出来了以后,中国人也做。
还有就是它的 self-driving,无人驾驶出租车的业务,这个也是一个很有趣、很挣钱的业务,但是这件事情到目前为止也没有落地,就没有正式地在一个国家里头彻底推开过,这个都需要验证。所以一定要用一个有故事的公司 SpaceX,去吞那个故事比较旧、比较容易被质疑的公司。

当然还不是最重要的。最重要的还有一点,就是马斯克是一个控制欲很强的人。他在 SpaceX 里的投票权有 85.1%,而在特斯拉里的投票权只有 13%。如果特斯拉吞并了 SpaceX,等于他把 SpaceX 投票权也让给那些股东了。如果是反过来,SpaceX 吞并了特斯拉,等于是他拥有了 80% 多的投票权。这一定是马斯克会选择的。
那这事想明白了,还有一个可能性,就是中间建一个完全独立的财务公司,同时把 SpaceX 跟特斯拉一起吃进去。这条路为什么马斯克不会选呢?原因很简单,你如果选了这条路的话,后边的 Neuralink、The Boring Company 这些公司怎么办呢?你就没法独立融资、独立上市了。
前边 SpaceX 还比较弱小的时候,他可以出来讲,我跟特斯拉没什么关系,因为特斯拉是一个实打实造车的公司,你一个造火箭的公司,我可以说跟它没关系。但如果你中间有一个像 Alphabet 这样的纯财务公司,那你 Neuralink 脑机接口公司,你能说我跟它没关系吗?你不能说。那我拿它的钱不就完了吗?我为什么还要再出去融钱呢?它就会遇到这种融资渠道变窄的问题。
所以一定要用一个马斯克绝对控制的、有未来故事的、估值更高的,或者泡沫更大的,而且是有实体业务的公司去控制、去收购特斯拉。所以这个是唯一解。
当没有上市的时候,大家会去研究几股换几股的问题。但是如果两个都是上市公司,这个没什么好说的,就是按当时市值 1:1 去兑换就完了。这个相对来说比较简单。
有可能会做一个什么溢价呢?比如说,我现在要去吞并了,我从宣布这一天开始往前一个月,拿这一个月的平均价;或者说我用一个平均价,稍微给一个溢价,稍微乘那么一点零几的溢价,去买特斯拉的股票。这个是可以的。

这里就有一个小问题:什么时间干这个活?现在普遍的看法是在 2026 年年底,或者是 2027 年的上半年,这个事情就会发生,不会拖得特别久。因为到那个时候,双方的市值还都差不太多。
在什么样的情况下会失败呢?如果 SpaceX 暴跌,跌得已经爹妈都不认识了,这个事就没法干了。
这件事咱们要讲清楚,一共分四层:

因为你做合并这事,肯定是要股东大会开投票的。
从反垄断上来说,普遍认为是不会造成什么问题的。因为这俩公司确实有点八竿子打不着,一个造车、造机器人,另外一个是 AI 和发火箭,它们两个确实没有什么相关性。
大家注意,垄断这个事不是因为你们俩大,然后合并了叫垄断,是你们俩原来在同一个行业里头都是领导地位,一合并以后,这个行业里已经有定价权了,这玩意才叫垄断。所以这个合并的过程应该不会受到反垄断法的调查。
第二个,刚才咱们讲了,马斯克是乐意的。
董事会能不能同意呢?大家要注意,2024 年特拉华州的法官取消马斯克 2018 年 560 亿美金薪酬包的时候,给出的理由是什么?特斯拉的董事会是由马斯克主导,过程不公平,缺乏独立性。
那你说特斯拉的董事会缺乏独立性,SpaceX 的董事会有没有独立性呢?不可能有,对吧,一定是更没有独立性的一个地方。
而且这两个公司的董事会是有很大交叉的:
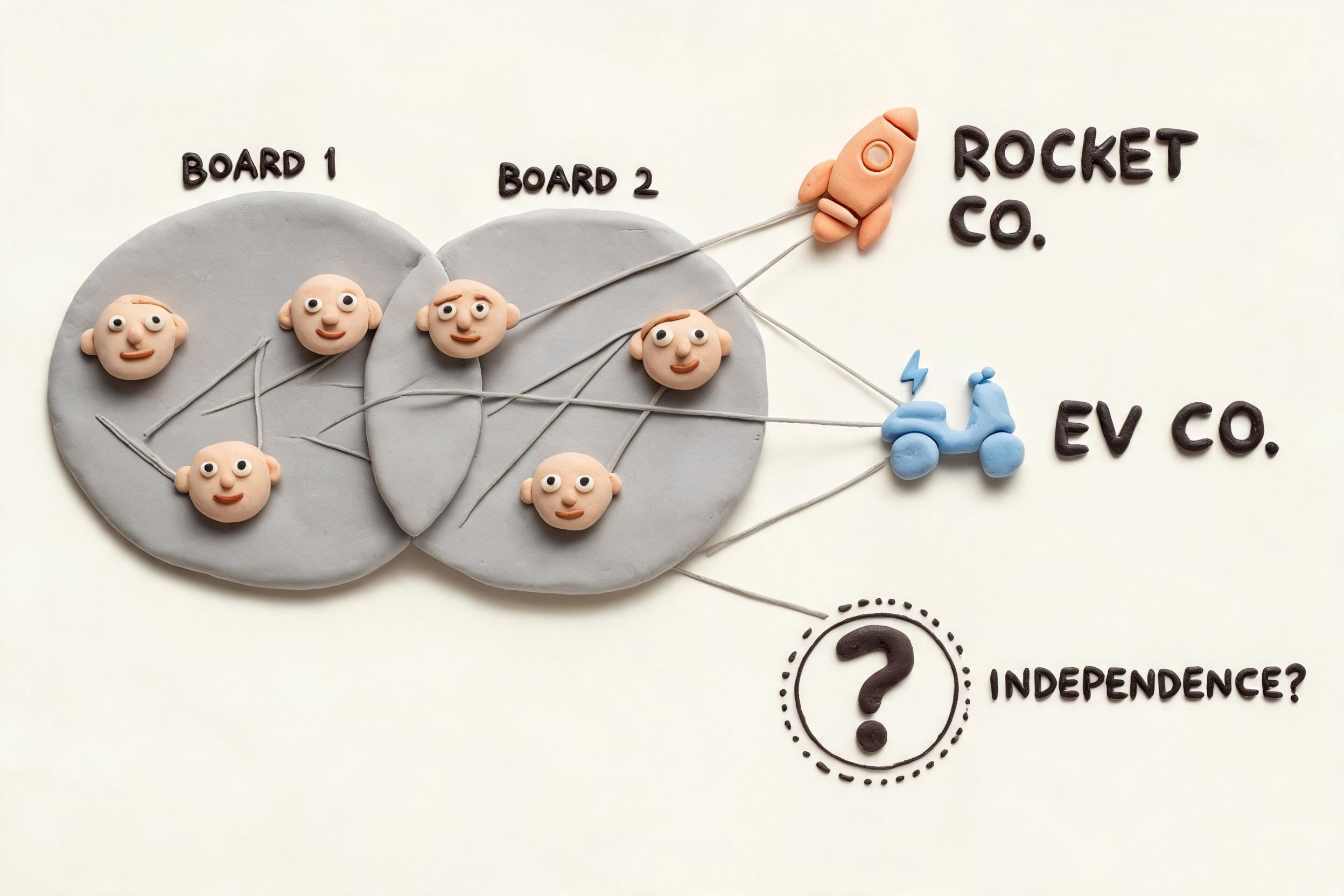
所以这些董事跟马斯克本来就是千丝万缕的商业绑定,本来应该代表小股东利益的董事,跟马斯克本人都有直接的股权和合伙关系。所以马斯克只要点头,董事会是不可能反对的。
马斯克同意了,董事会也同意了,两个公司合并,股东大会也得同意。但是大家要注意,特斯拉的股东大会是一个很奇葩的股东大会。怎么个奇葩法呢?散户主导。
马斯克特别喜欢散户主导。像 SpaceX 上市的时候,还专门要留出更多的股票让散户去买。他真的是想让散户挣钱吗?把马斯克想得太善良了。散户握有更多的股票、握有更多的投票权是有好处的。当你的创始人是一个世界级大网红的时候,这个事就有好处。
这个事有证明吗?有。2025 年 11 月 6 日,特斯拉在得州奥斯汀召开年度股东大会,马斯克的 1 万亿美元薪酬包,以 76.63% 的赞成率直接通过了。这是特斯拉在 SEC 2025 年 11 月 10 号备案的信息。当时,挪威主权基金,还有一些号称是特斯拉大股东的人,都是扬言我们一定要反对。但是只要散户足够多,你们这些号称的大股东都白给。
所以,作为世界级超级大网红的马斯克,他对于股东会的控制,要比他对于董事会的控制更加严密、更加有力。
那你说这事有没有一些小风险呢?也有。就跟特拉华州那个法官似的,直接说你这个董事会缺乏独立性,咔嚓一下把你摁这了。而且你这么多散户股东,谁买个一股就可以作为原告出来告你。这个风险肯定是无法避免的。
最后咱们结个尾。会不会合并?基本上板上钉钉,剧本已经都写好了。分散上市的甜头已经吃完了,一个人管理两家公司管不住了,你必须得把它合起来,否则麻烦太多。
一定是 SpaceX 吃特斯拉,而且一定是在 SpaceX 比较贵的时候去买。反垄断不卡,董事会会跟,散户绝对会同意。除了有人会去起诉他,闹出一点小幺蛾子,即使是闹了,也就是拖慢进程,不会有大的什么变化。所以这个事是拦不住的。

回到人身上。大家看我节目的时候,是 2026 年 6 月 28 日,老马同志的 55 岁生日。他要在有生之年看到火星 100 万人定居,时间窗口也就是 20 到 30 年了,所以他一定会加快脚步去做这些事情。
我们展望一下未来吧。明年有望看到 SpaceX 的 HLS 和 NASA 的阿特米斯 3 去登月,x 也已经在为火星发射做准备了。机器人方面,弗里蒙特工厂 7 月到 8 月就要准备投产,年产目标是 100 万台。未来几年,就有可能会出现机器人帮咱们倒咖啡的事情了。
脑机接口如果要继续做下去,估计也会走独立上市这条路。2025 年已经完成 3 例植入了,2026 年准备是 20 到 30 例。
人类和机器的边界正在变得模糊,近地轨道可能会随着 Starship、随着星舰的成功变得越来越繁忙。至于马斯克最新开的这个新炮,反物质研究,这个事我觉得您还是先把前面的坑好好填一填吧。
未来十年,我们要看的不是 SpaceX 吞特斯拉,而是人类能不能去月球,火星能不能住下 100 万人,机器人能不能走进我们的生活。这些事比任何市值,任何 PE、PS 都要更重要一些。马斯克这个 55 岁的南非人,正在一条一条地把它们都做出来。
最后,我们再祝老马同志 55 岁生日快乐。
今天的故事讲到这里,感谢大家收听。请帮忙点赞,点小铃铛,参加讨论群,也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。

2026-06-26 08:45:59

突发,Anthropic 实锤阿里巴巴正在丧心病狂地蒸馏 Claude。
大家好,欢迎收听老范讲故事的 YouTube 频道。
首先给三个数字,咱们稍微细品一下:25,000 个假账号,2,880 万次对话,连续 44 天不分昼夜地去蒸馏。这不是黑产薅羊毛,这是有人在系统地偷一个顶级 AI 的脑子。Anthropic 点名的就是阿里巴巴。
很多人就说,中国人又跑去偷美国 AI 了。这个事不需要讨论,中国人一直在蒸馏他们的 AI,这个事不需要否认。但是今天我们要讲的是另外三件事。

先把这个事情跟大家说一下。既然叫突发,怎么个突法呢?
2026 年 6 月 24 日,彭博社发了一篇文章,说我们看到了,一封信。这封信是 Anthropic 写给美国参议院银行委员会和白宫的,落款大概是 6 月 10 号,在一场 AI 听证会前面发出去的。这不是法庭质证的证据,是一方写给立法者的举报材料,还踩着听证会的点递上去了。这个细节是整件事情的一个关键。
4 月 22 日到 6 月 5 日,也就这 44 天里头,约 25,000 个假账号跟 Claude 对话了 2,880 万次,专挑两样东西去问:
这就是 Claude 真正的看家本领。
今年 2 月份,Anthropic 实际上就已经投诉过一次了。当时是 DeepSeek、月之暗面和 MiniMax 三家,加起来是 24,000 个账号、1,600 万次的问询。而这一次阿里就一家,25,000 个账号、2,880 万次问询,比那三家加起来还多,真的是够狠,要么说丧心病狂呢。
但是这个事就是 Anthropic 说了,阿里这边并没有任何回复,就跟前面 DeepSeek、月之暗面和 MiniMax 是一样,他们是不会回复的。

事情理清楚了,真正值得我们担心的是什么?是阿里在换方向。阿里一边换人,一边换方向,一边换赛道。
我们要看这个事情是从哪天开始的呢?是从 4 月 22 日开始的。那 4 月 22 日发生了什么呢?要注意,3 月 4 日半夜,阿里千问的灵魂人物、技术负责人林俊旸,在 X 上发了一句话说:
我要撤退了,离开我热爱的千问。
然后他就离开阿里出去创业去了。
当然他发完了这个以后,还稍微拉扯了一下,阿里内部还跟他稍微讲了讲,说你是不是能够留下来呀?最后不,我一定要走。而且在发这个 X 之前的 4 天,林俊旸还在小红书上挂招聘。说走就走,这事是非常非常反常的。
而且不只是他,同一天,后训练的负责人余博文,在更早一个月,千问 Code 的负责人惠彬原,都离开了阿里。公开的口径是架构拆分跟他的技术信仰冲突。当时圈里最火的标题是:千问开源时代要变了吗?
现在这个事基本上实锤了。林俊旸 3 月份走了,4 月份就开始大面积的蒸馏。到 5 月 19 日,千问 3.7-Max 上线,但是千问 3.7 就不再开源了。原来千问 3.6 是开源的,3.7 就不开源了。
所以基本上就是新来的一拨人,这拨人就是急功近利的一拨人,没有千问的各种品牌包袱,也不需要去维护任何名声,就直接生干了。最简单粗暴的方式就开干,干完了以后直接出闭源作品,就是这样的一个玩法。
咱们把四个日期定在一条时间轴上看一下:
林俊旸还在千问高举开源的那几年,那个时候一次都没有报过说千问蒸馏谁的这样的问题。偏偏是在林俊旸走了以后,转向闭源整整 7 周之后才开始。闭源旗舰 5 月 19 号发布,正卡在这场蒸馏,也就是 4 月 22 日至 6 月 5 日的正中间。
一只手疯狂汲取 Claude 的看家本领,另一只手把闭源旗舰直接推上了货架:以后我们就玩闭源了,以后不再玩开源了。
阿里没有回应,证据也没有落实,仍是单方面的说法。但当两条线在日历上扣得这么紧,这真的是巧合吗?换了个人,换了个方向,换了个赛道,那打法会不会也跟着变呢?
原来你自己收集数据,自己去训练;现在别费劲了,人家都已经蒸馏 Claude,都已经做出产品来了。特别是有新人上来的时候,大家注意,新人上来第一件事要干嘛?要证明前面那个人是傻瓜,我才厉害呢。那怎么能够做这个证明?弯道超车。怎么去弯道超车?蒸馏。一定是走这条路。
转进闭源红海,要抢写代码、做智能体这种硬的护城河,就有了抄近路的动机。而蒸馏就是最快的近路。这是阿里第一条线。

下一个线是什么?就是 Anthropic 自己。Anthropic 自己也正被摁在地上摩擦呢。
6 月 9 日,Anthropic 高调上线了两款旗舰:Fable 5 和 Mythos 5。三天之后,6 月 12 日,商务部长卢特尼克亲笔信给了 CEO 达里奥·阿莫迪,说全球所有外国人立刻下架这两款模型。这个外国人,即使是在美国也不行,即使在你公司里的雇员也不行。
导火索是什么?导火索是亚马逊的研究员把这两个模型的安全护栏完全给绕过去了。Anthropic 在举报信里头特意警告,被蒸馏的模型往往缺乏安全护栏。结果他自己的旗舰,护栏先被当场捅穿了。到今天还关着呢,关了十来天了。嘴上说过几天恢复,外边押注的大概是 7 月份,Fable 应该能够回来。
一边自己被禁,急着解禁;一边跳出来当受害的国家队,告诉国会、白宫:中国在偷我,你们得保护我,给我松绑,让我赶快往前跑,要不然的话这事就危险了。这一告,是举报,是公关,更是游说。
别忘了钱。Anthropic 是一个估值 9,650 亿美元的公司,马上要去冲 IPO 的。他 6 月 1 号偷偷提交的 IPO 申请,而且他这个 IPO 应该真的是近在眼前了。谷歌现在很多人在往 Anthropic 跑,为什么?就是跟他一块 IPO 的。对于硅谷的公司来说,IPO 就是最大的造富机会。现在这么多谷歌已经很资深的人过去,就是先分股股票,IPO 上市的时候我们挣一笔,就要干这个事。
在这个时候,Anthropic 最怕的其实并不是被人山寨、被人蒸馏。他现在最怕的是,把他的模型摁在地上不让发布的这段时间里头,别人追上。而现在看来的话,追上 Fable、追上 Mythos 本身这件事情并没有那么难,因为 OpenRouter 的 Fusion 以及日本 Sakana AI 的 Fugu,其实已经通过使用多模型编排的方式,可以接近 Fable 5 和 Mythos 5 的能力了。
如果它这个真正最强的模型一直被摁着不让发布的话,那他这个优势就很容易失去了。这里边就有两笔账:一个是地缘账,一个是股价的账。

6 月 8 日,五角大楼 1260H 中国军工企业的清单里头,一口气加了 65 家,阿里就在里边,意味着 6 月底美国国防部不许跟你们做生意了。阿里咽不下去,6 月 23 日反手起诉了美国国防部,要求除名。
而且中国这边也进行了对等反制,把不可靠实体名单上加上了洛克希德·马丁、雷神什么都挂上了,还对 28 家美国军工企业搞两用物资的出口管制。两边互拉黑名单,军火商对军火商,科技巨头对科技巨头,这就是修昔底德陷阱:守成大国和崛起大国的结构性冲突。
正好阿里是在名单里头,8 号进的名单,10 号 Anthropic 就直接把信送上去了。这个事情都是紧锣密鼓跟在一起的。现在彭博社把这个信公开出来以后,阿里的股票马上跌了 3%,跌破了 100 美金。拉长了看,今年以来已经跌了 32%。
阿里做 AI 这件事情,这么长时间给阿里的股价其实没有什么帮助。就像小米一样,小米做了半天 AI,对于它的股价应该也是没有什么帮助的。但是公道地说,华尔街整体还是看多阿里的,更多的标签是强力买入,目标价是 190 美金,也就是短期挨锤,长期有戏。
矛盾就在,越 All in AI,短期就越难看;可掉队,长期故事就没了。

在这里,我们不去研究阿里蒸馏 Anthropic 到底谁对谁错的问题。蒸馏肯定是有问题的,人家有用户协议,你去用人家的产品,你就要遵守用户协议,要不然你可以不用。你既然说我要用 Anthropic 的产品,我也花钱买了 25,000 个账号,也花钱去提了 2,880 万个问题,就说明什么?阿里是知法犯法。我明知道你不让,我非要干,这个肯定是偷,没什么好说的。
但是比偷这件事情更让我们痛苦的是什么呢?就是最后一根全尺寸开源的支柱就塌了。
阿里这一转身到底动了谁的奶酪?我的答案可能很颠覆:动的是全世界开发者赖以生存的开源生态。
你会说不对,大家都开源,不是只有阿里一家开源。Kimi、MiniMax、智谱 GLM、百度的文心、小米 MiMo,全都开源。就算阿里千问 3.7 闭源了,那前面 3.6 还是开源的呢。怎么一说阿里千问闭源,这个生态就塌了呢?
大家要注意一点,其他的这些开源,比如 Kimi、MiniMax、智谱,它都是开源一个巨大的模型权重出来。我开源了以后,你爱怎么用怎么用。但是这个东西普通人是部署不了的,你必须得到云计算的机房里,才能把这种大模型部署上去。
你像 Kimi 大概是 1T 参数,也就是 1 万亿参数;MiniMax 大概是接近 229B 这个参数了;智谱的话应该跟 MiniMax 差不太多;小米应该是 1T 的,都是这么大参数了。对于普通人来说,你开不开源跟我有屁关系?
但你说,我现在要使用开源模型,我现在需要一个从 0.6B 到 1.7B,到 7B,到 14B,到 32B,到 35B,到 72B,一直这么上来的一个模型。我在每一个大小上都需要一个开源模型,然后我要根据我自己的使用需求,在上面去进行微调,再去做后训练,去得到自己的模型。
原来干这个活最早是谁干?Llama 在干,就是 Meta 干。后来 Meta 说我不干了,再出到 Llama 4 的时候,只出一个最大的,其他都不出了。然后 Meta 说我彻底不开源了,我就自己闭源再折腾了。那么最后一个在干这件事情的人就是阿里千问,其他人都不干,只有他干。
所以现在谁想去用这种小模型,只能拿千问的模型去后训练、去微调,其他人都不做了。像前面咱们讲的,日本的 Sakana AI 使用的 Fugu,它里边就是用千问 2.5 的 7B 模型去做的后训练、去做的微调。
现在没人干了。从千问 3.7 以后,就再也没有新的这种全尺寸开源模型出来了。那么开源模型这条路可能就崩菜了。

开源模型其实是两件事:一个就是开源大模型,一个是全尺寸开源小模型。原来阿里是做全尺寸开源小模型的,Kimi、MiniMax、GLM、DeepSeek 都是做全开源大模型的,这是两条不同的赛道。
你说我要做一些小的项目,比如嵌入式设备,你必须要用开源小模型才能搞定。以后没人做了,这个还是非常非常遗憾的一个事情。
阿里原来的路线,也就是林俊旸的路线,是真正把开源做成普惠的基础设施,从手机到机房整条线都喂饱。全世界就阿里一家干这个活。别人开源只做旗舰展品,阿里开源是做整个货架的。
所以开源生态原来就是阿里唯一的一家上去维护这样的一块地方,维护全套设施的人只有阿里一个。他一转身去圈地搞闭源了,现在开源还在,但是人人都用得起的开源、全尺寸开源就没有了。
表面上吵的是阿里偷没偷 Claude,真正发生的是最后一根全谱系开源的顶梁柱正在叛逃,正在叛逃。

最后扒完了这么多层,给大家压箱底三句话。
这两个问题,欢迎大家在评论区跟我去讨论。
好,故事就讲到这里。感谢大家收听,请帮忙点赞,点小铃铛,参加 Discord 讨论群,也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。

2026-06-25 08:46:12

大家好,欢迎收听老范讲故事的 YouTube 频道。
5月12日,深圳一位50多岁的医学博士,在小红书上以“靠谱老王”的账号发帖称,纸尿裤里测出了有毒物质。当时没有多少人理他,甚至有很多人骂他。原因是这位“靠谱老王”是做检测设备的,有人质疑他是在贩卖焦虑,惦记多卖几台自家的检测设备,认为他居心不良。
但在被骂之后的41天,也就是6月22日,四部委——市监总局、工信部、卫健委、疾控局——联合成立调查组,进场调查婴幼儿纸尿裤问题。再往后,就出现了一个特别神奇的“四天五个反转”的罗生门事件。
贯穿所有调查的核心问题是:孩子身体里肯定检测出了有毒物质甲酰胺,但它到底从哪里来,到现在为止谁也说不清楚。
今天是6月24日,调查组还没有最新结论。咱们今天分四层把这个事情掰扯清楚:

首先讲一下甲酰胺到底是啥。客观地说,并没有人说“我因为接触甲酰胺,急速中毒,人就没了”。甲酰胺应该是泡沫材料加热以后可能产生的一种物质。它的半衰期其实很短,3到6个小时,进入体内以后还是可以排出去的,通过皮肤吸收的比例也不是很高,所以损害剂量并没有一个特别统一的标准。
离开剂量谈毒性就是耍流氓。
但是,如果这个东西出现在婴幼儿纸尿裤里,就不一样了。纸尿裤是24小时贴身穿的,而且小孩要穿一两年时间。即使是低剂量累积,也没有一个权威研究机构能够确定它到底会不会对人体产生害处。
在国内标准里,化妆品是禁用甲酰胺的,GB15979 等规定中也不允许有甲酰胺。但是在婴幼儿纸尿裤的国标里,没有这一项,也没有规定到底应不应该有这个东西。
国标里有甲酰胺的检测方法,但并没有把它列成强制检测项目。所以,如果厂商说“我这个产品符合国标”,哪怕检测出了甲酰胺,它也依然可能是符合国标的。
在欧盟标准里,甲酰胺是有规定的。它被列为一类生殖伤害物质,也就是欧盟认为它经过动物实验证明对人类是有害的。所以欧盟的婴幼儿标准规定,每公斤不得高于200毫克。法国在2010年就把这个事情定下来了。
但是美国在这件事情上没有标准,日本在这件事情上也没有标准。
所以这就是这个物质的核心争议:它有毒吗?欧洲说这东西有毒,美国没说;中国说它不能放在化妆品里,但是纸尿裤里没有明确规定。
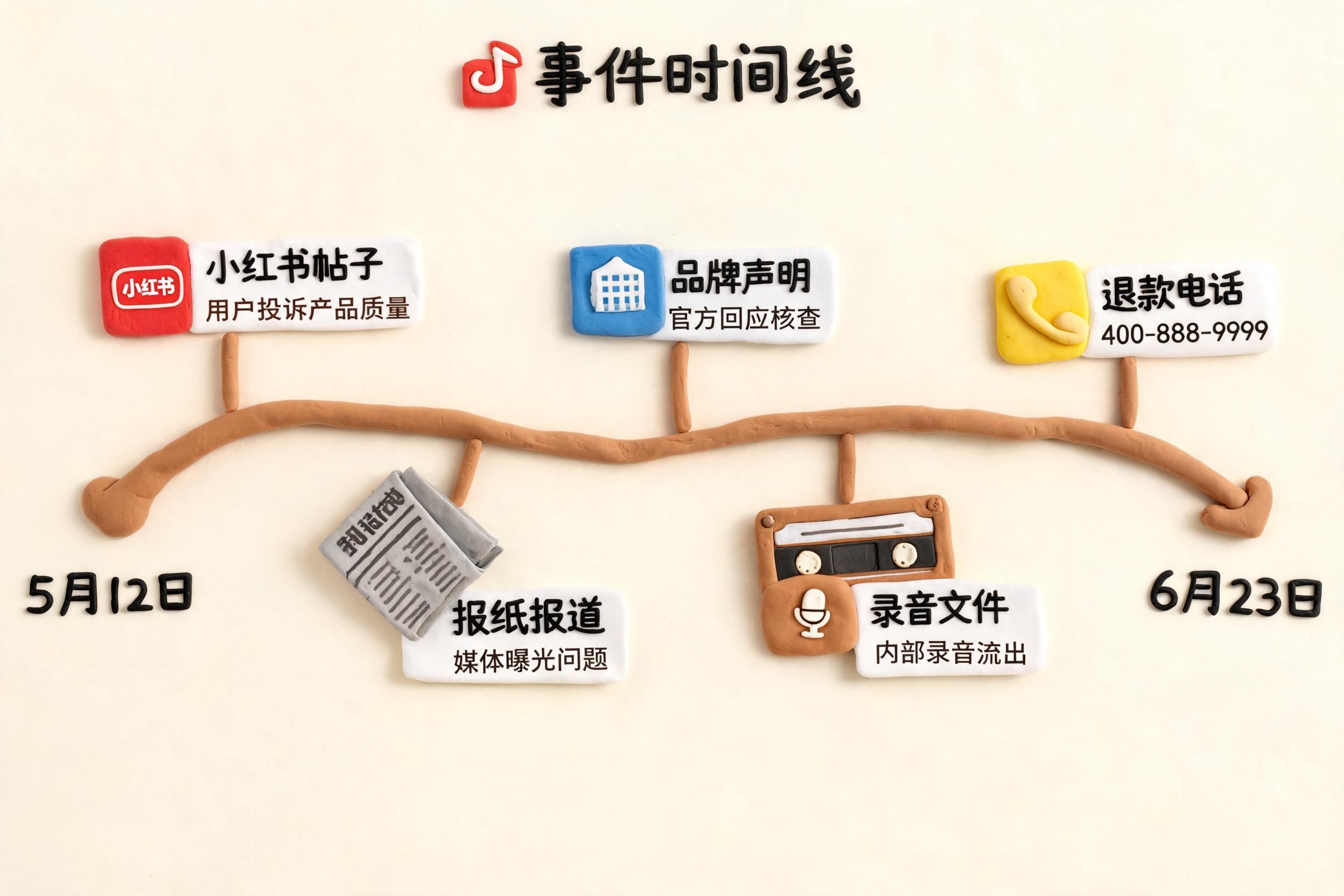
时间线就比较有意思了。这个故事之所以被称为罗生门,核心就在时间线上。
5月12日,深圳的王博士王东鉴,首先在小红书上发帖。他说,他们公司里有几个宝妈,也就是孩子刚出生的母亲,发现小孩使用纸尿裤以后出现红屁屁的情况,于是拿他们自家的检测仪检测了一下,发现纸尿裤里含有甲酰胺。
随后,他的小红书账号被禁言了。
真正把这件事引爆的,其实不是王东鉴,而是6月18日《经济参考报》调查记者王文志发布的一篇报道。报道称,好奇、碧芭宝贝、Babycare 检出了甲酰胺。
这里面有两个硬核信息:
这是6月18日发生的事情。
6月18日到6月19日,三个品牌出来否认,表示:
我们没事,跟我们没关系,我们都是符合国标的。
随后,给记者做检测的山东省公共卫生临床中心也发声明称:
我们从来没进行过这样的研究,这事跟我们没关系,我们没干。
甚至给检测签字的特聘主任也出来签字,称:
这事我没干,不是我干的。
于是很多人开始骂记者,说他为了骗流量瞎编,人家明明没有给他做实验。
6月19日,中国造纸学会卫生用品专项委员会三连质疑,称企业是合规的,市面上都是安全可控的,并质疑检测是否按照正常流程、是否合法合规。
6月19日晚上,调查记者王文志放出录音。录音中的于兆衍,就是前面提到的山东省公共卫生临床中心特聘主任。
需要注意的是,特聘主任并不是机构里有编制的人。这意味着:
于兆衍在录音里表示,领导压着他签字,这不是他想签的,上面有压力,一定要逼他这么说。他还说:
用我这条老命把实验保下来,就是数据不能丢。
6月21日晚上再次反转。三个品牌都表示:
我们没检查出来,我都送检了,我们这里头没有甲酰胺。
但即使它们检测出来了,也没有公信力。这里不仅仅是送检或抽检的问题,还有一个更严重的问题,会导致任何在纸尿裤里进行甲酰胺检测的结果都没有公信力,后面会讲为什么。
之后,王文志发公开信,表示自己只为那些体内检出甲酰胺的孩子,其他不管、不关心。
他的核心意思是:厂家到底有没有问题,跟他没关系;但孩子身体里已经有甲酰胺,这东西到底是哪来的?他也质疑这三个品牌方是不是做了一些特供样品去送检。
6月23日,王东鉴,也就是深圳这位卖检测器的医学博士接受专访。他说:
如果我错了,我去坐牢,没问题。
他还表示,这件事不只是用他们自家的检测设备测了,还找了第三方检测。只是第三方检测机构的法务刚给他打电话,给他退钱了。也就是说,他去检测,对方现在把钱退给他,检测报告作废。
随后,山姆超市把好奇品牌的纸尿裤全线退款,不管拆没拆,都可以拿回来退。其他两个品牌的纸尿裤估计没有进山姆,只有好奇品牌进了。
这就是所谓的四天五反转。为什么称之为罗生门?因为写剧本都不敢这么写,就这么来回翻。

王东鉴是步锐生物的法人,医学博士,原来是500强医疗销售总监。公司主营医疗呼气检测,自研了名为 SPI-TOFMS 的质谱仪。
他出来爆料后,很多人质疑他是否是在制造焦虑,想卖设备。
王文志是《经济参考报》调查报道室主任,从业20多年,八次获得中国新闻奖。
他曾参与祁连山非法采矿报道,该报道获得第31届中国新闻奖一等奖,并牵出一位副省长、19位县处级干部。2024年11月,在合新铁路暗访时,他被中铁七局打伤。
要致敬这位硬汉记者。
于兆衍是山东省公共卫生临床中心质谱中心的特聘主任。所谓特聘,就是不完全受机构保护、没有编制的人。
关于他,出现了三个版本:
第一个是好奇,是美国金佰利公司旗下品牌,市占率16%,在中国纸尿裤市场中排名第一。它的产品大部分是自产,但也有一小部分是外包生产。
第二个是碧芭宝贝,属于爱朵集团,在中国的市占率大概是2%,100%完全自产。
第三个是 Babycare,属于杭州白贝壳集团,在中国的市占率大概是8%。它完全没有自己的工厂,100%全代工。但给它代工的是中国纸尿裤代工第一企业,也就是最大的代工企业豪悦护理。
山姆退款退的是好奇。
接下来讲一个有趣的事情:法务退款。检测机构给人做了检测,检测完又把钱退了。
这个事跟《经济参考报》的调查记者王文志无关。王文志找的是山东公共卫生临床检测中心,在山东省各地收集血样、尿样做检测,而且记者自己也做了把纸尿裤绑在胳膊上的实验,绑了一段时间后,数值出现明显变化。
退款发生在王东鉴这条线上。王东鉴自己是卖设备的,所以他知道“我自己说这东西有问题”肯定不行,于是委托了第三方。
这个第三方后来经过一些记者核实,应该是合肥广测产品检测研究所。他们给出的报告也是检测出了甲酰胺。
6月23日早晨,合肥广测的法务给王东鉴打电话,要求退款、报告作废、不担责任,意思是这个事到此为止,检测费还给他。

王东鉴问对方:报告是否客观反映了送检产品?法务没有否认。因为如果否认,就相当于把检测机构的牌子砸了。
他又问:报告上写的是不是能够证明里面有甲酰胺?法务说是,确实里面有,但是他们不能出具报告,钱退回,报告作废。
王东鉴也表示理解,因为这个事压力肯定很大。合肥广测和步锐,也就是王东鉴的公司,并非完全没有关系,往上隔几层后还是有一定股权关联,但没有直接关联。所以这件事到底是完全公正的检测,还是另有情况,现在也没法说,还是等国家给报告。
王东鉴自己对这件事情的猜测是,他把纸尿裤整个拆开,一块一块去检测,也测出了到底是哪一块有问题。
他说,他们测出来有问题的东西,实际上是里面的一些胶,特别是类似橡皮筋的东西。因为纸尿裤要绑在身上,需要有一部分是有弹性的。
他表示,如果用食品级的胶,大概是1万二到1万八一吨,价格很贵;如果用回收的 EVA 改性胶,就是几千块钱,差3到5倍的价钱。

现在这个市场已经是红海,而且以后小孩越来越少,大家都不生了,做纸尿裤的人也要降本增效。
但有一点必须注意:到目前为止,甲酰胺长期接触人体,特别是长期接触婴幼儿人体一两年之后,到底会对人产生什么伤害,其实并没有一个特别明确的确认。这一点还是要讲清楚。
为什么所有人去测甲酰胺都没有公信力?这是中国一个更神奇的规定。
在中国,要想让检测报告有公信力,上面要盖两个章:一个叫 CNAS,一个叫 CMA。
但是中国规定,如果国标里没有这一项,你去检测了,就不给你盖这个章。只要国标里没有甲酰胺这一项,不管检测结果是有还是没有,这两个章都不给盖。

所以不管是送检、抽检还是全检,只要检测的是这一项,就没有公信力。这是中国管理国家标准的一个很奇葩的规定。
因此,记者最后也咬死了一件事:不管这东西是怎么来的,只关心孩子身体里已经检测出了甲酰胺。哪怕不是纸尿裤来的,也要搞清楚孩子身体里的甲酰胺到底是怎么来的。
在这个事件中,行业协会从来没有想着怎样维护行业的整体高水平,怎样把害群之马干掉。他们想的永远是如何维护行业的颜面。
所以一出事,他们没有做调查研究,而是直接上来开骂。这也是很让人讨厌的一点。
有没有可能厂家也是冤枉的?老范一般不会逮着一头锤。有没有可能大家都是对的:记者也是对的,深圳这位博士也是对的,厂家也被冤枉了?
很多人会说,怎么可能,总有坏人。对,是总有坏人。但这里还有一个特别神奇的案例。
2025年315晚会上有一个案例,叫梁山希希案。
山东梁山有一家叫希希纸业的公司,做了一件特别奇葩的事情:他们跑到山东附近这些做纸尿裤、卫生巾的厂商那里,把人家的残次品收购回来。收购回来以后,重新敲打蓬松、装包,然后贴上名牌再销售出去,谋取30倍暴利,涉及很多品牌,其中就包括 Babycare。
这个案子叫翻新黑产案。

需要注意的是,Babycare 虽然所有产品都是代工的,但它找的也是大号、靠谱的代工厂。可是,如果生产过程中有残次品,这些东西应该销毁还是怎么处理?销毁也有成本。有人说“你给我吧,我帮你处理掉”,梁山希希就是这样的公司。
它重新包装以后,仍然叫 Babycare,但并不是 Babycare 真正授权的合规代工商,卖的是假货。
所以现在你在超市里买到的纸尿裤、卫生巾或者纸质用品,未必是从原厂出来的,也未必是由原厂认证、签协议的代工厂造出来,再经过原厂抽检或检测后的合格产品。
因此,两边都有可能是冤枉的,这种可能性是存在的。

这导致一个问题:我们现在根本不知道该信谁,这个事情变得无解。
甚至现在国内很多社交媒体会传播一些特别弱智的内容,比如:
农民洗菜居然敢用一种叫一氧化二氢的东西去洗菜,这个东西是化学的,多危险呀。
大家知道一氧化二氢是什么吗?那不就是水吗?但就是有人信,信完以后就开始骂:怎么可以放一氧化二氢?如果孩子长期吃了怎么办?
除了“一氧化二氢”,还有一种很奇葩的东西叫“脱碳甲醛”。甲醛大家都知道对身体有害,房子里有甲醛可能会得白血病。但脱碳甲醛是什么?脱碳甲醛其实还是水。把甲醛分子式里的碳去掉,剩下的还是 H2O,还是水。
还有人玩得更花。该放盐的时候,他说“我们这放的不叫盐,我们这放的叫氯化钠”。很多人就会说,怎么可以放氯化钠,怎么可以放化学的东西?其实盐就是氯化钠,学过初中化学的人都知道。
但没办法,现在你说有人往菜里放氯化钠,还是有人会跳起来。
中国为什么会出现这么奇葩的事情?有一个词叫塔西佗陷阱。
塔西佗是古罗马的一位史学家,他曾经有一句名言:
一旦皇帝成了被憎恨的对象,他做的好事和坏事就同样会引起人们的厌恶。
现在等于我们什么事都不信,什么事都讨厌。有人说不可以放一氧化二氢,有人说不可以放脱碳甲醛,有人说饭馆做菜不可以放氯化钠,这实际上都是塔西佗陷阱。
到底谁可信,谁不可信?卖检测器的人敢去检测别人的纸尿裤,就一定是坏人。实际上,这都是塔西佗陷阱在起作用的结果。
所以今天讲的,不是某个厂子黑心那么简单,而是几件事情叠加在一起:
所以整个体系基本上是无解的。
其实讲到最后,最该回答的问题都被绕开了。
什么才是最该回答的问题?现在小孩身体里有甲酰胺,这个东西哪来的?
哪怕说它不是纸尿裤里来的,或者说这些孩子买的纸尿裤是假的,这也没问题。但是现在这个东西已经在孩子身上出现了,就必须找出出处。这才是真正现在要做的事情。
最后,还是要致敬一下。
一地鸡毛里,只有一个人咬死了一句话,就是王文志。他说:
我不关心纸尿裤怎么来的,我只关心孩子身体里的甲酰胺是怎么来的。
中国非常需要调查记者。如果这批人都被收拾干净了,我们吃的、穿的、用的就更没有保障。
虽然现在这个状态,我也不知道未来会怎么改善,但至少像王文志这样的人还在努力折腾,还在努力调查,我觉得还是要向他们致敬。
一个社会愿不愿意保护多管闲事的人,决定了普通人能不能买得安心。这次医生没有闭嘴,记者没有缩头,就冲这一点,这件事情还是值得我们继续关注下去。
好,这个故事今天就讲到这里。感谢大家收听,请帮忙点赞,点小铃铛,参加 Discord 讨论群,也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。

2026-06-24 08:53:11
日本在 AI 领域里终于追上来了?终于不是中美两国的游戏了?Sakana AI,也就是“鱼 AI”,超越 Mythos 了?
昨天,6 月 22 日,日本一家叫 Sakana AI 的公司发布了一个东西。Sakana 在日语里是“鱼”的意思,它发布的这个东西叫 Fugu,日语里应该就是“河豚”。一上来,它就放了一张跑分图:在 SWE-bench Pro 编程榜上,它最高档拿到了 73.7 分,把 Anthropic 的 Claude Opus 4.8 的 69.2 分,以及 OpenAI 的 GPT-5.5 的 58.6 分,全都压在身下了。
它甚至宣称,连 Anthropic 两个最强的 Mythos 和 Fable,它都已经部分超越了,也就是有些分数比它们还高。于是网上一片欢呼,说日本终于在 AI 领域里赶上来了,不再是中美两国在这玩耍了。
先把结论放在这:别急着高兴。这事看起来像追上来了,扒开一层看看,根本不是那么回事。
Sakana 这条鱼到底是真追上来了,还是又一次聪明的投机取巧?咱们就把这条鱼从头到尾拆开来看一看。
这里要补充一句:Mythos 和 Fable 是 Sakana 自己宣布的口径,没有独立的第三方评测。原因也很简单,这两个模型现在禁用了,只要不是美国公民就用不了,所以他们也没有办法拿出评测数据来。
首先把表面一层打开看看,这条鱼到底长什么样。Sakana 并不是一个突然冒出来的草台班子,它有来头,有产品,有跑分,表面上看起来确实比较唬人。
这家公司在东京创建,2023 年成立。它一直主打的不是从零打造大模型,这句话大家要仔细听:它没有从零打造大模型,而是把现成的模型重新组合、编排一下。
它的产品线上一共有三条鱼:
它一共有三位创始人。
CEO 叫 David Ha,名字是 David,后边是 Ha。按照广东拼音来说,这个人应该姓夏,应该是一位华裔。虽然他在日本创业,但他出生在香港,年幼时随父母去了加拿大,多伦多大学本科,东京大学博士,曾在谷歌大脑做神经网络和进化算法,还当过 Stability AI 的研究负责人。
第二位是 CTO,叫里昂·琼斯,英国人,伯明翰大学出身,是 Transformer 那篇论文 Attention Is All You Need 的八个作者之一,是真大神。他在谷歌干了 12 年,在这个团队里真正管技术和方向的人,就是这位大神。
还有一个人叫伊藤,是这家公司的 COO。东京大学法学,纽约大学法学院,带过日本独角兽的全球化市场。更关键的是,这哥们出身于日本外务省,有外交和政府背景。
所以,这家公司是一个华人创始人,一个写了 Transformer 论文的英国人管技术,一个有日本政府背景的伊藤在管关系。真正的日本本土、又偏官方的,其实是伊藤。这个细节非常重要。

下一个问题:这一次跑赢了 Anthropic 大模型的这个“河豚”到底是什么?
它不是一个模型,它是一个系统。所谓超越 Mythos,超越的方法很关键。河豚自己没有前沿大模型,它是个编排器,把别人家的模型拼出来一个高分。大家觉得日本行了,其实不是这么回事。
为什么我会管河豚叫系统,而不叫模型?因为它的核心是一套 AI 工作流编排系统。现在有一个新词叫 Loop Agent,循环智能体。
过去我们干活都是过程管理,或者叫顺序执行:先干什么,后干什么,从哪进去,从哪出来。画过流程图的人都知道,流程图里有一个开始节点,有一个结束节点,我们在这两个节点之间画整个流程。
而 Loop Agent 干的活是什么?它是转着圈干。它有输入,有要求,然后有很多大模型在里边承担不同的角色。有人负责拆解任务,有人负责执行,有人负责检查结果。如果检查不满意,那就再转一圈,一直转到满意为止。这就是现在比较流行的一种新的 AI agent 工作方式。河豚恰恰是这样的一套系统。
河豚最鸡贼、也是最关键的一点是什么?它不告诉你里头到底放了哪些模型,但是它保证里头没有放 Fable 5 和 Mythos 5,因为它需要跟 Fable 5 和 Mythos 5 竞争。而且按照现在美国商务部的要求,它也不能用 Fable 5 和 Mythos 5。
但是,你说这里头有没有 GPT-5.5?有没有 Gemini 3?有没有 DeepSeek?有没有 Claude Opus 4.8?这个它不说。它只说,我们跑分跑得比 Claude Opus 4.8 还高一些。
所以它大概率是怎么干活的?比如说一个任务进来,Opus 4.8 负责拆解;拆解完以后,GPT-5.5 去执行;一些不是特别关键的任务,可能就扔给 DeepSeek 去执行;执行完以后,可能又扔回给 Claude Opus 4.8,让它检查一下有没有问题。有问题的话,再转一圈,一直转到“我觉得可以了”,再把东西吐出来。
在这样的情况下,它跑分比 Claude Opus 4.8 高,比 GPT-5.5 高,甚至在个别指标上可以超越 Fable 5 和 Mythos 5。它就是这样一套系统。
那河豚里头到底有没有自己家的模型?还是有的。不是前面那个鲶鱼模型,鲶鱼模型实际上是在 DeepSeek V3.1 的一个版本上做后训练出来的,也不是从头做的,待会再讲那个模型。
河豚系统里有一个叫“指挥模型”的东西,一上来可以稍微指挥调度一下。这个模型是用 Qwen 2.5 7B 做的后训练。每一次任务进来,拆解可能还是要用大模型去拆解,但它负责在里边进行循环调度。所以你说它完全没有自己的模型,这也不对。

再转过来说鲶鱼模型。鲶鱼模型是基于 DeepSeek V3.1 Terminus 做的后训练。除了 DeepSeek V3.1 Terminus 之外,它也参考了 Llama 3.1 405B 的一个开源底座,然后自己训练出模型。
别看咱们现在嘲笑它拿别人的模型去后训练,大部分人连这一步都做不到。能够在人家的基础上做后训练,训练完以后还有更好的效果,不是一般人能搞定的。
有一个非常有意思的细节:DeepSeek 原版对于日本政治历史敏感问题会拒绝回答,72% 的问题都会拒绝。中国人训练的模型,你去问它“抗日战争怎么回事”,很多内容它是答不上来的。而 Sakana 用自己的日语数据后训练之后,拒答率几乎降到了零。
这说明它的价值是本土化适配,而不是造更强的脑子。它没有触及最硬的东西,也就是自己的前沿底层模型。

下一个问题大家就要问了:没有前沿底层模型,人家不也跑得好好的吗?你怎么就说日本人不行呢?
今天要讲的是,没有底层模型就没有护城河。编排这件事本身是没有门槛的,谁都能做,而且你的命门是拿捏在别人手里的。
这条路不光 Sakana 这一家“鱼公司”在走。全球最大的模型聚合平台 OpenRouter,6 月 12 日就上线了一个几乎一模一样的东西,叫 Fusion。它可以把最多 8 个模型编排在一起,跑同一个问题,再让一个裁判模型把大家的答案融合成一个,号称不用 Fable 5 就能够逼近 Fable 5 的质量,成本只有 Fable 5 的一半。
它的角色分工和河豚是一个思路:干活的和检查的分开,而且干活的不允许自己检查,避免自己给自己打高分。OpenRouter 自己说了,约 75% 的提升来自裁判的融合,只有 25% 来自模型的多样性。
用这个对照就能说明,多模型编排是一个公开的、谁都能拼的工程手段,不是 Sakana 的独门秘技。一个东西如果连聚合平台都能顺手做一个,它就不构成护城河。
那么到底什么是护城河?底座和价格才是护城河。底座模型是我自己的,我可以有底座模型价格的定价权,这才叫护城河。
而现在这些东西都在谁手里?都在 AI 大厂手里:OpenAI、Anthropic、谷歌,都在他们手里。而且这些做编排系统的公司只能用大厂已经公开发布的模型,可是大厂经常会捂着一两代模型,甚至有很多模型从来就不发布。这些大厂自己最清楚什么时候发新产品,几款产品之间到底差在什么地方。
等这些做编排系统的公司,也就是像 Sakana 这样的公司,拿到大厂最新的模型,开始研究怎么编排、怎么优化的时候,人家大厂内部的编排系统、Loop Agent 系统,早就已经迭代了不知道多少回了。所以你想跟他们比,根本就比不了。
而且价格也不是 Sakana 这样的公司能够控制的。你编排了半天,最后还得老老实实给 Anthropic 付 token 的钱去。而且 Anthropic 没准哪天一开心,还给你把账号封了。Anthropic 干这种事太正常不过了,OpenAI 也是这样的。
你说我用了 GPT-5.5 作为底层模型,上头给你编排了一下。那你干完活以后,得给 OpenAI 交钱。那我把账算好了,最后把自己该挣的钱挣到,不就完事了吗?
这里就有一个新的问题:大厂 AI token 的价格是不透明的。它可以把 token 价格搞得很贵,把自己的套餐,比如 20 美金的 Plus 套餐,价格搞得很便宜;或者说虽然是 20 美金,但是给你的量很大,导致套餐里的 token 很便宜,而外边的 token 很贵。
大厂做这样的动作以后,花钱买 token 的像 Sakana 那样的公司,不一下就没了吗?你的利润空间完全在人家的报表上,什么时候想弄死你,什么时候就弄死你。所以这是完完全全没有护城河的。没有自己的底层模型,也没有模型的定价权,这就是 Sakana 这类公司的尴尬之处。
编排这套手法本身就不保密。OpenRouter 能上 Fusion,大厂自己当然也都把编排内置到自己的产品里去了。前面我们还专门录了一期视频分析 Fable 5 被人破解出来的 12 万字系统提示词,实际上就是一套这样的 Loop Agent 系统在运作。
而且大厂随时可以决定哪天去摁按钮。按完按钮以后,没准把你的 API 接口封了,或者把价格调整一下,把 token 价格涨一涨,把套餐里的用量涨一涨,那你们这些做编排的公司,不一下就被人挤死了吗?
所以这种纯编排公司,本质上吃的是一个结构性的窗口期。窗口开着的时候,你有饭吃;窗口一关,你连桌子都上不了。
而且这个事你自己完全没有任何主动权,所有权力都在大厂手里,人家随时想给你关,就随时给你关上。

当年谷歌就是这么把一堆小广告平台干掉的。核心的价格和流量在谷歌手里,你在某个环节优化得再漂亮,也架不住人家从源头上直接弄死你。
讲到这,稍微把过去这段历史跟今天的 Sakana 对比一下。把时间拉回到互联网刚开始的时候,那时候所有人都想明白了一件事:广告就是唯一的出路。大家都去做广告吧。
于是有一大批公司跑出来,在广告各个细节、各个环节进行优化,比如投放优化、竞价优化、归因优化、广告网络之间的交换怎么优化、怎么进行计件,做了好多这样的系统出来。
你说这种系统技术有价值吗?有,而且很多人的技术还是很扎实的。结果这些公司今天都哪去了?这些公司都死了,或者被大厂收购了。现在一提互联网广告公司,就是谷歌、Meta、苹果、X;中国的就是腾讯、字节跳动,其他没了。那些小公司都被他们干掉了。
原因很简单,这些大平台自己是有流量的,它可以随时决定涨价降价。你那些小公司优化了半天,最后还是要用它的流量,那只能被它干掉。
像我以前在猎豹移动,我们也做广告,但是必须要接谷歌和 Meta 的 API,要在那边把流量跑出来。那它随时就可以弄死我,就是这么简单的情况。
这些广告公司里,绝大部分是雨打风吹去就没了,极个别做得特别好的会被收购,大厂重新把它买回来就完事了。而且买进去以后,其实也不是要它们的技术,而是要它们的用户、要它们的流量。这就是当年的历史,跟今天的 Sakana AI 非常非常像。
那你说日本这一次是不是又完蛋了?Sakana AI 耍了一把小聪明,骗了人的钱,最后做不出来东西,还让大家跟着白开心了半天?也不能这么讲。
Sakana AI 死不了。它最终有可能成为什么?可能会被谷歌日本收购,或者被 OpenAI、Anthropic 日本直接收购,这个可能性是很大的。实在不行,字节跳动没准还来收你。
正是因为没有护城河,被收购反而是 Sakana AI 最好的结局。它这个团队里坐着一位 Transformer 论文的作者,光这一块招牌,被日本 OpenAI 或者日本谷歌收购的底层逻辑就算通了,定价也不会低。
买它的人买的是三样东西:
这三样东西恰恰是从外边砸钱也比较难买到的。
做纯编排的公司,顶尖的结局就是被收购。这恰恰说明它是有价值的。Sakana 真正的护城河根本就不在技术上。即使它被谷歌收购了,谷歌会用它的编排系统吗?不会。谷歌要的是你的政府关系、你的整个团队、你懂日本,要的就是这东西。
而且日本有一个特别奇葩的地方,就是它对于本土产业保护得非常好。
以前我们的一个合作伙伴叫 JVC,日本胜利公司。这公司哪来的?美国电气公司在 1920 年代在日本建的分公司,后来打仗的时候分离了,叫 JVC,一直发展得非常好,500 强有时候在前边,有时候在后边,现在这几年不知道了。
还有一个案例是日本雅虎。雅虎在全球基本上都废了,但是日本雅虎依然是日本最大的门户网站。虽然日本雅虎现在跟 LINE 合并了,母公司叫 LY Corporation,但是它还是以日本雅虎的底子出来的。
所以,如果谷歌、OpenAI、Anthropic,也许是字节跳动,把 Sakana AI 直接买下来,就让它好好做日本这个生意,把所有关系打透。剩下技术的事情它就别问了,大厂有的是人给它搞定。这可能就是它未来的一个出路。
Sakana AI 未来不是要去跟 OpenAI、Anthropic、谷歌这些大厂竞争,它抢的生态位叫“日本第一”。这也不是日本追上来了,而是日本又长出了一个只在日本有用的本土冠军。

今天这个故事对于普通人、创业者、投资人有什么启示?
首先跟创业者讲清楚,不要在自己没有底层模型的情况下做纯编排系统,做 Loop Agent,也不要把这个东西当成主业去赌。这条路的天花板只有两个结局:做得好,能够被大厂收购;做得差,就什么都不剩,最后会被价格战清洗掉。
你要么手里有自己的模型、独家的数据、流量入口;要么就像 Sakana 一样,去卡一个本地市场或者政企关系,一个不可替代的位置。只优化中间环节,说我技术做得特别好,但命门握在别人手里,长期一定是个死。
第二,对于普通用户来说,能够使用原厂的,尽量使用原厂的,不要去使用这种第三方的编排系统。它们在技术逻辑上有不可克服的先天缺陷,因为它们只能拿别人已经公开发布的模型再去进行优化,这肯定是有问题的。
而且像 Sakana AI 这样,它不告诉你后台是怎么运作的,不告诉你底层用了哪些模型,你就没有办法相信它的结果。跑了半天,这个结果自己看着好像还行,但你要想清楚一点:AI 的运作速度是非常非常高的,它可以一分钟出一大堆结果出来,人的鉴别能力在这个面前是非常苍白无力的。
所以我们现在控制结果的最好方法是什么?就是底层可知,底层有保障。Sakana AI 这些东西是给不了的。
对于投资者和内容创作者来说,看一家 AI 公司,先问两件事情:
编排层公司的估值,要按照被收购的可能性和被收购的预期来算,不能按照下一个 OpenAI 来算。把跑分超过谁当成卖点,尤其要警惕:跑分是借来的,护城河才是自己的,这个一定要记住。

最后给出结论。表面上,这是“日本终于在 AI 开始追赶中美了”的一个叙事;实际上,这是一家没有自己底层模型的编排公司,在重演互联网广告小平台的老路。技术很聪明,商业没有护城河,命门全在别人手里。
更长期来看,今天这条鱼公司,也就是 Sakana AI,最大概率不会变成大海里的鲨鱼,而是会变成日本自家鱼缸里那条最贵的锦鲤。好看,值钱,被别人买走,但是它始终游不出那个缸。
对于整个 AI 大潮来说,它只是一个小小的水花,不会给整个行业带来任何变化。
