2026-06-30 03:33:49

Music streaming service Tidal announced it won’t pay royalties for AI-generated music in an email to users and an announcement on its website published Monday. “Tidal’s priority is ensuring royalties go to original works directly produced, written, and performed by people,” the announcement reads. “We will therefore not knowingly attribute royalties to music we identify as wholly AI-generated.”
Like much of the internet, music streaming services are awash in AI-generated slop. Spotify promised to fight AI spam with labeling and filtering but also embraced the broader trend of AI music. AI-generated bands like The Velvet Sundown and Breaking Rust have millions of listens on Spotify and make the service money. In May, Spotify announced a deal with Universal that would let fans create “covers and remixes of their favorite songs.”Soon Spotify customers will be able to push a button and discover what Metallica would sound like if it were a reggae band.
Tidal is trying something different. The streaming service isn’t a giant in the field — Apple Music, YouTube, and Spotify dominate the charts — but it’s built a reputation by collaborating with artists, giving them a bigger cut of the streaming profits, and focusing on delivering high quality versions of audio. Tidal is the streaming service for listeners obsessed with bit-rate and FLAC. It’s for people who have $200 digital-to-analog converters next to their computer.
The company said it won’t pay for “wholly” AI-generated music but it also said it won’t remove AI-tainted music from the platform entirely. Like Spotify before it, Tidal said it’s going to work to identify the AI slop on its platform, label it, and hold AI-generated music to a “higher standard of content integrity.” Spotify said something similar last year, but there are still plenty of unlabeled AI-generated tracks on the platform.
Tidal also said it won’t remove AI-tainted music entirely. “Artists should have the freedom to create with AI tools, and listeners should have the autonomy to choose the type of content they consume,” it said. As of this writing, The Velvet Sundown and Breaking Rust are both live on Tidal. Breaking Rust’s bio identified it as AI-generated country music, but The Velvet Sundown had no bio at all.
“Tidal will not allow music that is 100% AI-generated to be monetized. No royalties will go to such releases, nor will AI-generated uploads be eligible for direct-to-fan sales,” the company said in an email to its users.
It elaborated on its website. “Starting today, AI-generated music will not be monetizable,” it said. “We are only in the beginning of the era of AI-generated music. We acknowledge the ongoing debate regarding whether certain AI-generated music (e.g. AI-generated music developed from fairly and properly licensed models) should be entitled to earn royalties. This debate will continue as the technology advances and rightsholders and AI music platforms develop licensing models.”
It’s unclear if The Velvet Sundown and other bands like it will keep making money on Tidal. The company told 404 Media that it’s working with an external partner to manage detection and that “wholly AI-generated” was defined as a song where every component of the track was made using generative AI. “Our detection tools will determine how specific tracks and artists will be treated from July 15,” Tidal told 404 Media in an email. “The impact to royalties comes into effect starting July 15 so we don't have numbers to share just yet.”
On June 28, the day before Tidal’s announcement, The Velvet Sundown released a cover of Dolly Parton’s “I Will Always Love You” on Spotify and Tidal. It’s atrocious and it’s not labeled as AI-generated on either service.
“We exist to confuse music journalists, comfort robots, and help Spotify executives sleep at night,” says the frontpage of The Velvet Sundown’s website. “We were basically built for it, engineered to fill playlists, avoid royalties, and haunt your Discover Weekly like a ghost with good taste. Is it art? Is it a loophole? Either way, it streams beautifully."
Update 6/29/26: This story was updated to include comments from Tidal.
2026-06-29 21:43:39

I am standing just outside of the Yahoo Explorer’s Society, where the line for DJ Tiësto stretches well past Microsoft Gardens, out toward the Canva Creator Cabana and Influential Beach. Thankfully the line doesn’t cross with “Make Noise, Not Just Content” featuring Diplo at Salesforce Beach, or Mumford & Sons at Spotify Beach. Tiësto started hours ago, but a mix of sweaty advertising and big tech employees still jockey for position in different priority access lines stratified by different colored wristbands depending on a mix of your position, who you know, whether you are likely to buy ads with Yahoo. Some have no wristband at all and simply have a QR code to Tiësto and are sequestered to a general admission line; a bunch of French people with no QR code at all have decided to dance on the actual sand beach just outside.
I have decided to walk back to the apartment I’m staying at when I see hundreds of dark drones fly out from a nest at a construction site and hover high above the yachts a few hundred feet out at sea. Their lights flicker on and they form a blue and white hand with a finger pointing into the sky. The drones rearrange themselves into huge letters: “AI.” The drones shift again to read “ART & INTELLIGENCE.” They shift again to say “KARGO.”
This is Cannes Lions, where everything is an advertisement for advertisements, a glitzy, week-long “conference” and “awards show” in Cannes, France. Big tech companies and any major company that buys or sells ads send thousands of their employees here to wine and dine each other on yachts, in bars and cafes, at brand “activations” on the beach, and in chateaus and villas. Cannes is the biggest advertising conference in the world—or at least the most glamorous—where advertising execs and brand execs form the relationships that will ultimately result in billions of dollars of ad spend, and which will shape the way we buy things, the way we’re advertised to, and the way the internet works.
After years of hearing about Cannes from executives at VICE who went every year, I decided to go this year because some of my friends were going as part of their job. A big emphasis this year was on advertisers collaborating with creators, and we do sell ads at 404 Media and are creators, in a way. I was able to get a press pass from Cannes Lions and thought I would spend part of my time reporting, part of my time trying to meet with potential advertisers, part of my time seeing which parties I could get into, and part of my time going to the beach in the middle of one of the worst heat waves on record in Europe. I have reported on tech and advertising for a long time, have been to some big tech conferences and many tech company campuses, and I expected the entire thing to be quite ridiculous, but the conference was over-the-top in every conceivable way.








The entire conference is an advertisement for different types of advertising, and everything that can be turned into an ad has been. The Cannes trolley cars that run up and down the beach have been bought out by Strava (“Ads don’t get people active. Strava Sponsored Challenges do. Reach over 195 million active people on Strava,” the ads on the trolleys say.) About half of the cars navigating the winding Cannes streets have been wrapped with ads for advertising on Uber or Lyft or some other platform. DoorDash took over a store directly next to Versace, PayPal took over a patisserie. There are billboards for billboard ads, though every billboard advertising employee I spoke to insisted their job was “boring” and that the buzz had moved from “outdoor” (a euphemism for billboard ads) to “IRL,” a euphemism for events that have video billboard ads at them. KARGO’s drone ad was advertising drone advertising. Serve Delivery robots were driving around advertising the fact you can advertise on the robots; the United Arab Emirates was advertising the fact that its government is willing to do ideas others “said no to.” Life360, the app that lets parents surveil their kids, threw a full week of programming which included tips about advertising on Life360. The JW Marriott had information about how to advertise via the Marriott BonVoy rewards program; United Airlines had information about how to advertise on United flights; Chase had a building about how to advertise to Chase cardholders. OpenAI and Reddit had big presences, explaining how to advertise to Redditors and ChatGPT users; Reddit’s executives tried to tow a careful line about how Reddit is “the most human place on the internet” but is also widely scraped by LLMs, while OpenAI tried to explain that humans make decisions based on what its robots say. I wandered into Meta’s beach compound and caught a portion of a panel about using Gen Z influencers to advertise in which the video sign said “Cringe or Cool? Creators who educate instead of entertain.” Free streaming tv giant Tubi was there with an indoor activation where you had to walk through a curtain that looked like Goatse. I walked by a panel where someone was explaining in great detail the creativity behind a specific tweet made by the KitKat account. Kevin Durant and Shaquille O’Neal and Oprah and Alex Rodriguez and Seth Meyers and Bryson DeChambeau were all there talking about their new podcasts or video series or partnerships or creative visions or about how talent and vision are important and in Durant’s case, about “building culture not just content.”

The conference is so big, and represents every possible type of advertising—it is impossible to have one single takeaway or to analyze one specific trend. Some of the people I spoke to said they were worried about AI, others saw it as an opportunity. Some said advertising needed to be more human, but many of the billboards and panels suggested much of the work could be automated. Basically, if you came into Cannes with a narrative or grand pronouncement about the future of advertising, you could probably find a panel that would help you confirm that belief. But what was immediately clear is that the main purpose of Cannes is for the advertising industry to hang out and drink rosé and spritzes on the beach, on yachts, in bars, and bistros, either at specific parties or on their own company’s expense account. It would be possible to do the business part of this conference at a hotel in Pennsylvania or Maryland or Vegas, but that would defeat the overall purpose, which appears to be drinking champagne in the south of France.
Every major tech company had either a “plage,” or beach activation area which basically consisted of tents, bars, and stages for panels and/or highly paid concerts; this often resulted in people in sneakers, khakis and dress shirts standing on the sand talking to each other a few hundred feet from vacationers swimming in the ocean. Besides Salesforce Beach, Microsoft Gardens, and Canva Creative Cabana, there was “Sport Beach,” The Female Quotient, Google/YouTube Beach, the “Reddit Cafeteria,” and more. Just behind the plages are other brand activations that happen either in hotels or luxury stores. A DoorDash Ads store was located directly next to Versace, for example. The Carleton hotel was divided into “TikTok Jardins,” LinkedIN Rooftop, MIQ House (an adtech company), and then rooms for something called “The Team,” Vox Media, and Fox. These plages were not to be confused with “BRAND BEACH,” which was a separate area along the beach filled with little cubes for brands to take meetings in.

There were also lots of companies you probably haven’t heard of, with inscrutable names and impossible-to-explain products. I went to numerous panels where one of the panelists listed a series of acronyms or products, and another panelist or the moderator responded “I have no idea what you just said.”
“DSPs are on the TV sidelines: Tatari gets brands in the big game,” one billboard I saw in Cannes read. “Tell us what Braze does,” another huge billboard read; when I walked by the Braze tent, I heard someone ask them what Braze does and it was deeply unclear (The answer, according to its website: “Braze is a customer engagement platform that empowers brands to Be Absolutely Engaging.™” Conveo pitched “Always on customer understanding,” and MiQ pitched the idea that you can buy ads with an AI and can create digital AI personas: “Sigma’s upgraded gen-AI omnichannel audiences gives advertisers over 1 million targeting options,” its ad in front of the Carleton hotel read. I saw a billboard that just said “Infillion Yieldmo.” One billboard I saw just read “Creative as an AI-operated system.” A car driving around Cannes read “an AI bought this ad.”
Nominally, Cannes Lions is an award show that honors the most creative and innovative advertisement campaigns of the past year. The basement of the Palais des Festivals, which is basically a huge convention center, is filled with images of iconic ads from the last few decades, and there is a red carpet and daily awards ceremonies. The Cannes Lions website notes it is “where creativity drives progress,” and states that “The Awards underpin everything that makes Cannes Lions what it is—the home of creative excellence and effectiveness—and each year a new global benchmark for creativity is set.” Inspirational messages inside the Palais highlighted creativity and the human touch with empty little platitudes; one read “Personal growth is no longer a nice to have. It’s a must have.” Another said “DRIVE PROGRESS. THIS IS YOUR MOMENT.” A third said “CREATE EMOTIONAL STORIES.”

A billboard on the outside of the Palais for a company called Smartly, however, reads “Creativity gets you the trophy. Our ROAS gets you the yacht.”
A lot of the point of Cannes, it seemed to me, was to get onto a yacht, have a yacht, know someone on a yacht. There is an entire yacht section of Cannes. Most of the yachts do not leave the port where they are docked; their private rooms are turned into meeting spaces and their decks just throw tightly controlled parties all day. Big companies rented entire yachts, other companies shared them. I was invited to take a meeting on the Hewlett Packard yacht, which was actually a yacht called The Room, which was shared by HP, Outfront (which sells billboard space), something called Xumo, and a company called InMarket. There was a Mercedes Benz/F1 yacht, a Samsung Ads yacht, an Integral Ad Sciences adtech company yacht, an Accenture yacht, a White Lotus / HBO yacht, among others. Some of the yachts had hot tubs, all of them had lots of free alcohol (rosés and spritzes), hors d'oeuvres, and men in knit polos and sneakers and women in sundresses.
While inside the Palais there was lots of high-minded discussion about the creativity of advertising, a lot of the actual conversations I heard were about making more money, who was meeting with who, what parties were happening, did someone have a colleague or friend who could get them on a party invite list. There did not seem to be much discussion about the broader concerns of an increasingly stratified economy, other than “this is ridiculous,” as in, ridiculously over-the-top, ridiculously hot, ridiculous that partying this hard was “work.” The most immediate concerns I heard from people seemed to be how to get into exclusive parties, where the next bottle of rosé would come from, and whether they would be invited back next year.






The festival went all week, and by the second day people are hungover and sunburnt. As the week went on, I saw less khakis and more shorts, with people desperate to do anything to cool down (ironically the best way to do this would have been to go swimming; we were at the beach, after all). Because I did not have a sales quota to hit or a number of meetings I had to do, I spent most of my time wandering around, taking pictures of billboards, taking breaks to swim, going to panels inside little air conditioned tents, and yes, drinking rosé and spritzes.
The last night I was there was Tiësto, which I vaguely tried but couldn’t get into. I decided to have a beer outside at a bar nearby and people watch. It was then that I saw the drones hovering high over Salesforce Beach. The drones looked kind of beautiful, and were forming into a figure. It was the Kool-Aid man punching through a wall. “BREAKTHROUGH IMPACT,” the drones formed to read. “KARGO.” It was just another ad. I walked home, thinking that I’d had fun, in the way that a music festival or Vegas can be fun, in the way that after you leave, you feel like you’ve been hit by a Strava-sponsored bus.
2026-06-28 01:02:33

Welcome back to the Abstract! Here are the studies this week that yucked it up, went interstellar, controlled the weather, and sang our praises.
First, the sounds of ape laughter have been gracing our planet for 15 million years. Then: a visit from a cosmic elder, a meteorological martial art, and bops by blowhards.
As always, for more of my work, check out my book First Contact: The Story of Our Obsession with Aliens, or subscribe to my personal newsletter the BeX Files.
You’ve heard about getting the last laugh, but who got the first one? Scientists have now determined that laughter, a behavior common to all great apes, may have initially appeared in chortling primate ancestors that lived 15 million years ago, according to a new study that analyzes the evolutionary roots of getting the giggles.
In addition to being the best medicine, laughter plays an outsized role in human cultures and interpersonal relationships. The fact that all other great apes, from bonobos to gorillas, also enjoy a good chuckle suggests that this form of vocal expression has broad benefits and potentially deep evolutionary origins.
To probe the history of hilarity, scientists analyzed recordings of laughter from four orangutans, two gorillas, three bonobos, four chimpanzees, and four human children during bouts of playtime, roughhousing, and tickling.
The results revealed that the isochronous nature of laughter—meaning clear sound intervals like “ha ha ha”—was likely present in the last common ancestor of the Hominid family, which contains all great apes including extinct relatives such as Neanderthals.
“While all major branches of the Hominid family have evolved distinct call repertoires shaped by their species-specific socio-ecologies, one vocalization has been conserved across species and age-sex classes: laughter,” said researchers led by Chiara De Gregorio of the University of Warwick.
The team’s analysis reveals that “great apes have been laughing in a recognizable way to modern humans for at least 15 million years” and that apes that are more closely related to humans have more complex and variable laughs similar to our own diversity of guffaws, cackles, and snorts.
To sum up: lol…lmao.
In other news…
Cordiner, Martin et al. “Isotopic Evidence for a Cold and Distant Origin of 3I/ATLAS.” Nature.
The interstellar comet 3I/ATLAS caused a sensation last summer when it was first discovered streaking through the solar system, partly because it revived the debate over whether these objects from other star systems could be alien handiwork.
While the evidence overwhelmingly suggests that 3I/ATLAS is not an extraterrestrial spaceship, it is nonetheless unlike any comet seen in human history. Scientists have revealed that the comet is by far the oldest object ever detected in the solar system, having “accreted as long ago as 12 billion years, following a period of intense, early star formation,” according to researchers led by researchers led by Martin Cordiner of the Catholic University of America.
In other words, 3I/ATLAS is nearly three times older than the solar system, formed when the observable universe was only a third of its current size. The age is based on the comet’s ratio of deuterium to hydrogen (D/H), which was measured by the James Webb Space Telescope, the most powerful observatory ever launched.
JWST revealed a “surprisingly high” ratio of deuterium enrichment, about 30 times the level of solar system bodies, with the exception of Venus. “3I/ATLAS thus represents a preserved fragment of an ancient planetary system,” concluded the team.
So long to this primordial pilgrim, and may it live to be 13 billion.
Finally, we have an answer to the age-old question: Can we use martial arts to control the weather? In a new study, scientists propose the concept of “weather jiu-jitsu,” which uses gentle atmospheric “nudges” to redirect potentially catastrophic weather events, such as hurricanes, heat waves, or droughts.
“Imagine harnessing the power of nature to help steer hurricanes away from land, redirect atmospheric rivers to spread their rain safely and evenly, or defuse extreme weather patterns like heatwaves, freezes, or prolonged droughts before they take hold,” said researchers led by Qin Huang of Arizona State University. “It’s a vision where we partner with Earth’s own forces to create resilience, rather than reacting to disasters.”
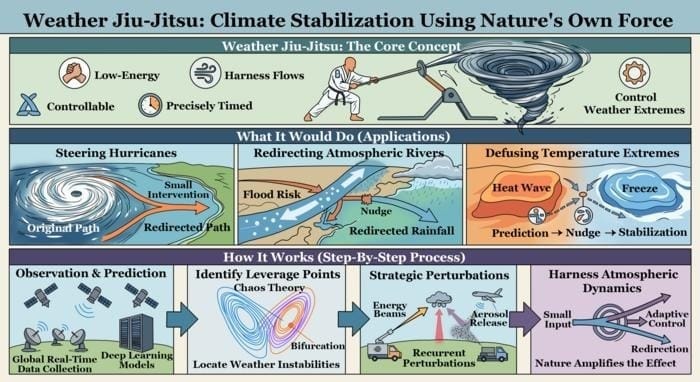
Weather jiu-jitsu involves seeding clouds with particles to influence weather outcomes, but it differs from existing methods by opting for light touches in advance of a developing weather event, as opposed to the heavier lift of weakening an event that is already ongoing.
The team’s models suggest this method could have nudged Hurricane Sandy well away from New York City in 2021, warmed Texas by about 18 degrees Fahrenheit during its deadly 2021 freeze, and reduced the rainfall that caused widespread flooding in California from 2022 to 2023 by about 5 percent.
That said, the study emphasized that the technique is only a proof-of-concept and it will take far more research to determine if it would be useful in the real world. In the meantime, let’s try some other martial arts-inspired approaches and figure out how to crane-kick a tornado or karate-chop a heat dome.
While the Song of Summer 2026 has yet to be determined, odds are that it will be singularly self-absorbed. That’s the hook of a study that discovered popular music has shown “a significant increase in self-focused language over time in individualistic societies” such as the United States or Germany, while no comparable trend was observed in more collectivistic societies such as Japan or Hong Kong.
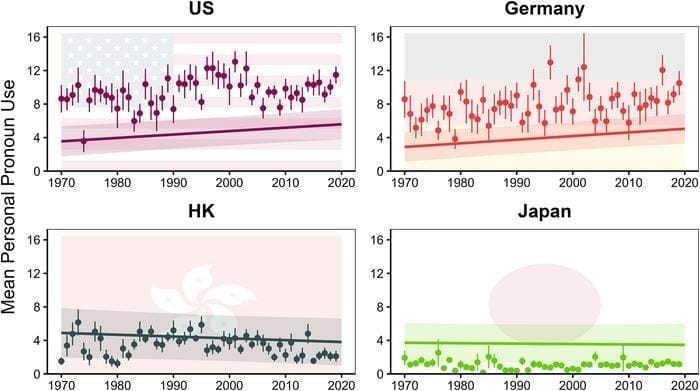
Scientists led by Marius Golubickis of United Arab Emirates University analyzed the lyrics of top 10 hits from 1970 to 2019 by quantifying the use of the plural pronouns like “we” and “us” compared with the first-person singular pronouns like “I” and “me” (check out the full list here). The results revealed that while “Western societies exhibited a clear increase in self-focused language over time, East Asian societies showed relative stability.”
This all checks out with my go-to playlist for narcissists, featuring “I Me Mine” by the Beatles, “Me Myself and I” by De La Soul, and, of course, “ME!” by Taylor Swift.
Thanks for reading! See you next week.
2026-06-27 01:04:16

This is Behind the Blog, where we share our behind-the-scenes thoughts about how a few of our top stories of the week came together. This week, we discuss talking aloud to computers, Cannes, and “Engineering Creativity: Guac Is Extra."
JASON: This week I was in Cannes, France for the Cannes Lions advertising conference, which is a sentence you probably did not expect to be reading and is definitely not a sentence I expected to be writing. It’s rare that I BTB something before I actually write about it, but in this case I think it’s OK, as this is going to be significantly different from the actual articles I do. There is no sense in being coy about it—Cannes, which at least in the media business stands for both the beach town in the south of France and the advertising conference (but not the film festival), is a ridiculous place and experience filled with excess and extravagant displays of money wasting. Back when we worked at VICE, every year around this time there would be a bunch of whispers around the office about which executives and higher level sales people were going to Cannes and who was not (us journalists definitely were not). Then, during Cannes, there was a barely spoken sentiment that we, the journalists, should try extra hard to not fuck up lest we create some sort of situation that a VICE executive in Cannes would have to deal with from another time zone while drinking rosé on a yacht.
2026-06-25 21:47:00

In February, police in Claremore, Oklahoma arrested farmer Darren Blanchard for speaking a little too long during a community meeting about data centers. The city charged Blanchard with criminal trespass, a crime with a $200 penalty, but he’s vowed to fight the charge. He recently shared video of the bodycam footage for the first time with 404 Media and answered our questions about the moment cops arrested him for going over his time at a February 17 community meeting of the Claremore City Council.
The plan in February was for the City Council to listen to the concerns citizens had about a planned data center called Project Mustang. The residents of Claremore don’t want the data center and largely feel like the construction project was approved without their input. City officials signed non-disclosure agreements on behalf of the project’s developers and haven’t been forthcoming with details about its construction.
2026-06-24 23:00:43

Scientists have discovered new evidence that the cosmic structures connecting the universe are much larger than previously predicted—persisting over billions of light years—a finding that challenges a core tenet of cosmology and hints at the possibility of new physics, according to a study published on Wednesday in Nature.
The standard model of cosmology, a well-corroborated framework for understanding the universe that is also known as the Lambda cold dark matter (ΛCDM) model, predicts that the large-scale structure of space looks the same in all areas (homogeneity) and in all directions (isotropy). While there is variation in the distribution of matter on small scales, such as thousands or millions of light years, these distinctions should smooth out into a uniform pattern on the scale of the cosmic web, which is a network of large-scale structures made of dark matter, gas, and galaxies that stretches across the universe.
But in recent years, new observational data has started to hint that galaxies cluster in “preferred directions,” forming distinct structures known as “anisotropies” that are not uniform, even across vast distances. Now, a pair of physicists has discovered that these distinct directions and patterns persist even to the scale of a gigaparsec, which is a unit equal to 3.26 billion light years, possibly signalling “the need for a shift in modern cosmology,” according to their new study.
“The structures observed in the real Universe are significantly larger and more persistent than those formed in state-of-the-art simulations based on the standard model of cosmology,” said authors Francesco Sylos Labini of the Enrico Fermi Research Center in Rome, Italy, and Marco Galoppo of the University of Canterbury in Christchurch, New Zealand, in an email exchange with 404 Media.
“The key advance of our analysis is that it allows this difference to be quantified,” they added. “By measuring the spatial extent and coherence of the observed structures and comparing them directly with theoretical predictions, we found that the discrepancy is statistically highly significant. In other words, the largest structures in the real Universe appear to be substantially larger than expected in standard models of galaxy formation.”
According to existing models, the cosmic web emerged from small density fluctuations in the early universe and gradually developed into large-scale filaments and nodes made of dark matter that gravitationally attract gas, galaxies, and other forms of matter.
Last year, the Dark Energy Spectroscopic Instrument (DESI), a major astronomical survey based in Arizona, released the largest high-resolution 3D map of the universe, which has revolutionized cosmology and allowed scientists to test those theories against observational data.
Labini and Galoppo analyzed the DESI release with statistical tools, including the Angular Distribution of Pairwise Distances (ADPD), which is especially effective for detecting and characterizing large-scale anisotropies in DESI’s dataset.
“The idea was to try to really test whether the idea that isotropies reached very large scales is now supported by data,” said Galoppo in a follow-up call. “Even just five or ten years ago, we didn't really have the data to test on gigaparsec scales. But now, we had a chance, so we decided to take it.”
“What we are able to do is to characterize how large are the largest structures inside this sample” of DESI observations, added Labini in the call.
The results revealed that even in DESI’s super-zoomed-out observations, large-scale structures create preferred directions of galaxy distribution, as opposed to an overall isotropic pattern. This contrasts with expectations derived from the cosmic microwave background, the oldest light in the universe, which suggests that directional correlations should fade rapidly at large scales.
“In the standard model, it's not that there aren’t structures,” said Galoppo in the call. “It is just that they are supposed to be smaller and less persistent than what we found. That's the crux of the matter.”
To that end, DESI is expected to release a new batch of observations within a year, and similar datasets will also be forthcoming from Europe’s Euclid space telescope and the Vera C. Rubin Observatory in Chile in the near term. These new and improved views of the universe will help scientists grapple with just how vast these large-scale structures are, and what that means for our understanding of our cosmic surroundings.
“At present, there is no simple or widely accepted modification of the ΛCDM framework that naturally explains structures of this size while remaining consistent with the observed uniformity of the cosmic microwave background,” Labini and Galoppo wrote over email. “That is precisely why these observations are so interesting: they point to a potentially important gap between theory and observation that deserves further investigation.”
“If future surveys continue to find coherent directional structures on even larger scales, the implications for cosmology would be profound,” they concluded.