2026-06-18 08:00:00
世界杯来了,又到了必须把电视收拾好的时候。
平时不看电视也就算了,但世界杯半夜踢球,临时再折腾就太被动了。所以提前把 IPTV 整起来,哪怕是备用,也比到时候手忙脚乱强。
折腾了三条路,踩了不少坑,最后结果有点出乎意料——记录下来。
宽带套餐里有送 IPTV,这是最理想的起点——免费、官方、稳定。
打电话给电信客服询问,对方告诉我:你已经开通了,18年就配好了。
……好像有印象,但我完全想不起来在哪里。找了半天,终于在角落翻出一个 IPTV 机顶盒,拿起遥控器一看——电池仓都生锈了。
擦干净,换上电池,开机,提示不在服务状态。让师傅上门才知道,路由桥接不支持 IPTV。
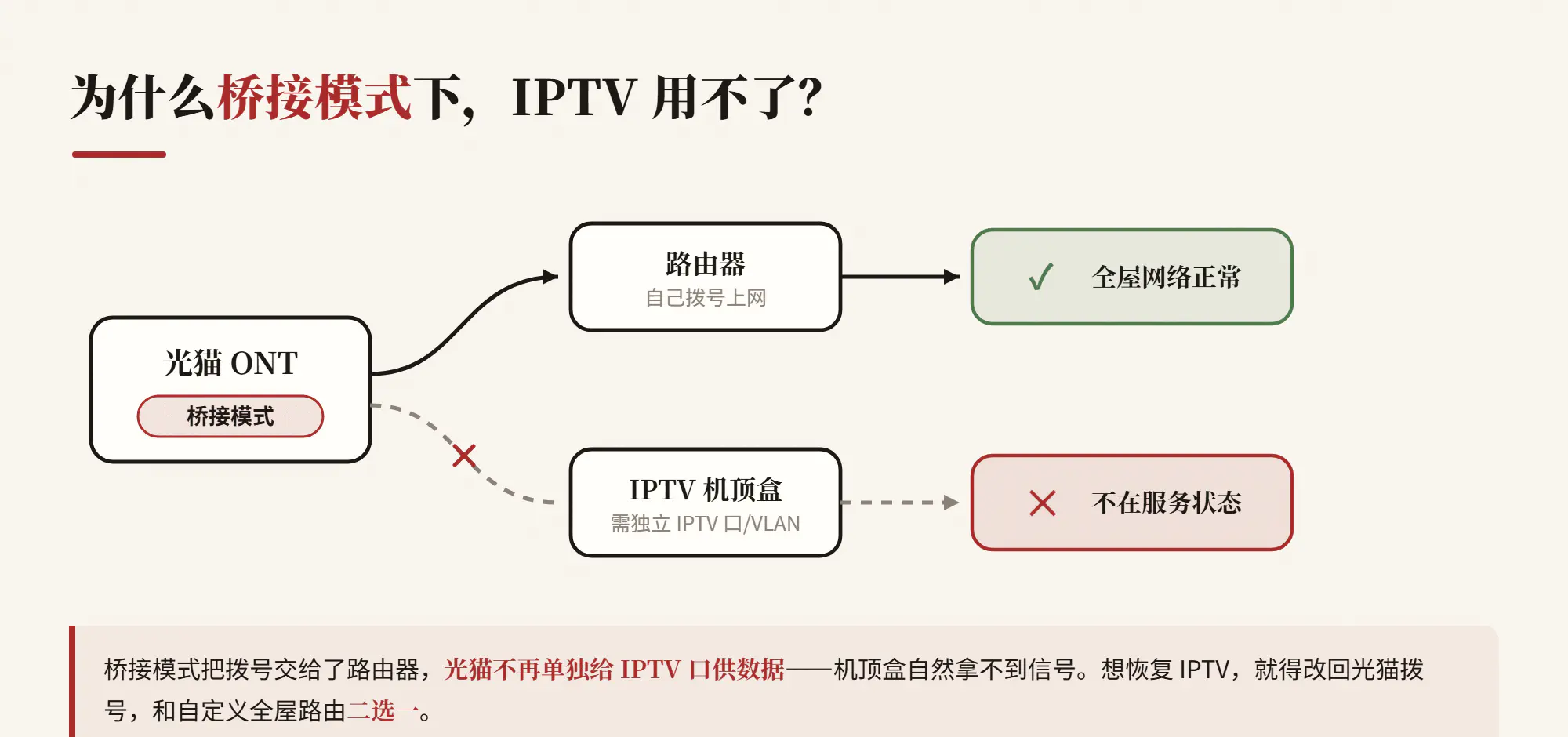
为了网络,只能放弃 IPTV。
在找看电视方法时,看到一条新闻,说国家推行地面波政策,大意是免费频道本来就应该免费接收,只要墙上有圆形插孔,插根线就能看电视。
这听起来也太美了——不用交钱,插上就有?
买了根十几块钱的同轴线,接上电视机对应的接口,开机搜台……
没反应。一个台都搜不到。
打电话给东方有线,对方表示:那个圆孔归他们管,但他们只负责付费的有线电视,不负责地面波;我不是他们的付费用户,所以不能确保墙面插孔的有效性。
两边都推开,又是一道空门。
这路不通,原因是小区的有线电视圆孔没作用。
既然有线那个孔没用,那就用真正的无线天线来接收地面波信号。
DTMB(地面数字电视)天线很便宜,二三十块钱的室内天线就够了。原理很简单:一端插进电视机的天线接口,另一端是个小天线,对准信号方向就能收地面广播。
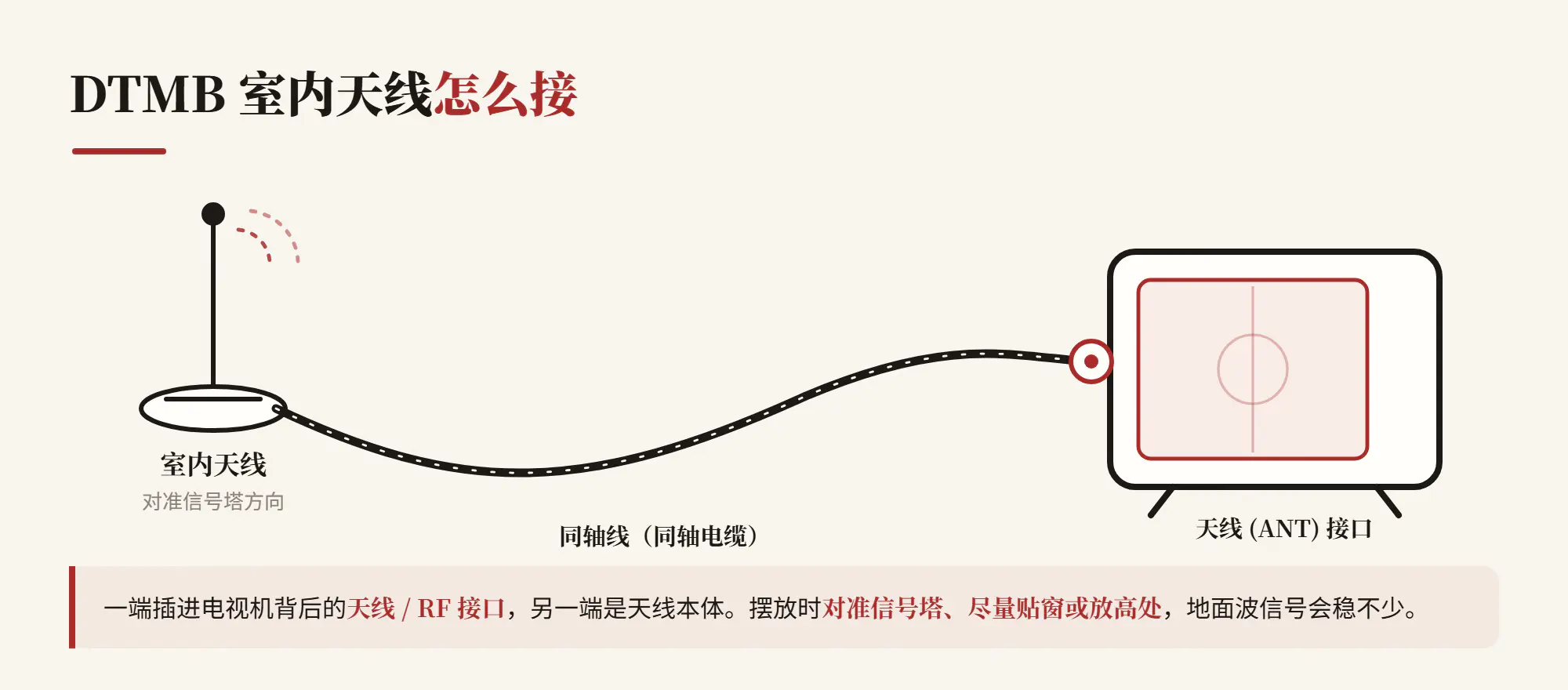
这次有效果了——搜到了十几个频道。

但仔细一看就尴尬了:央视频道号(CCTV-1 到 CCTV-15)倒是都列出来了,点开却全是「暂时无法获取节目信息」——等于摆设。真正能出画面的,只有几个地方台,而且还是标清(MPEG1),画面偶尔卡顿、马赛克。

世界杯这种场合,这种标清画质实在没法接受。
这路半通:地方台能看个标清,央视频道全是「暂时无法获取节目信息」。
DTMB 信号强弱和楼层、朝向、周边遮挡关系很大。高楼层、窗边、朝向信号塔的位置会好很多。室内天线如果实在不行,也可以考虑贴窗或伸出窗外,但效果因地而异。
三路折腾下来,最稳的方案反而是最开始没打算用的那个——央视频道 App 投屏。
手机安装 CCTV 或央视频道的官方 App,直接投屏到电视,画质 1080P,不限频道,不需要额外硬件,不需要打任何电话,开了就用。
三条路对比下来,结果一目了然:
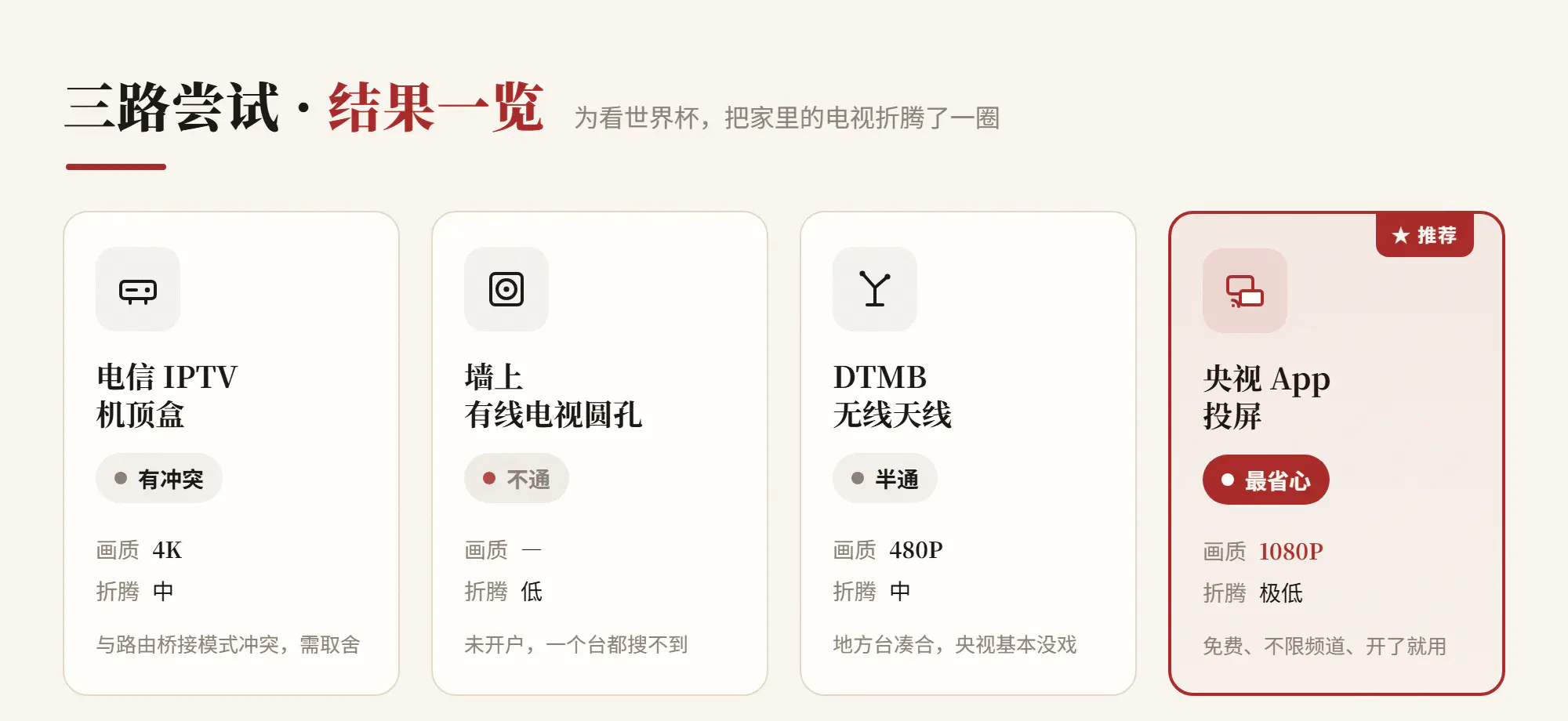
为什么会这样?关键是电视信号的来路不同——尤其要分清「墙上的圆孔」和「免费地面波」根本不是一回事:
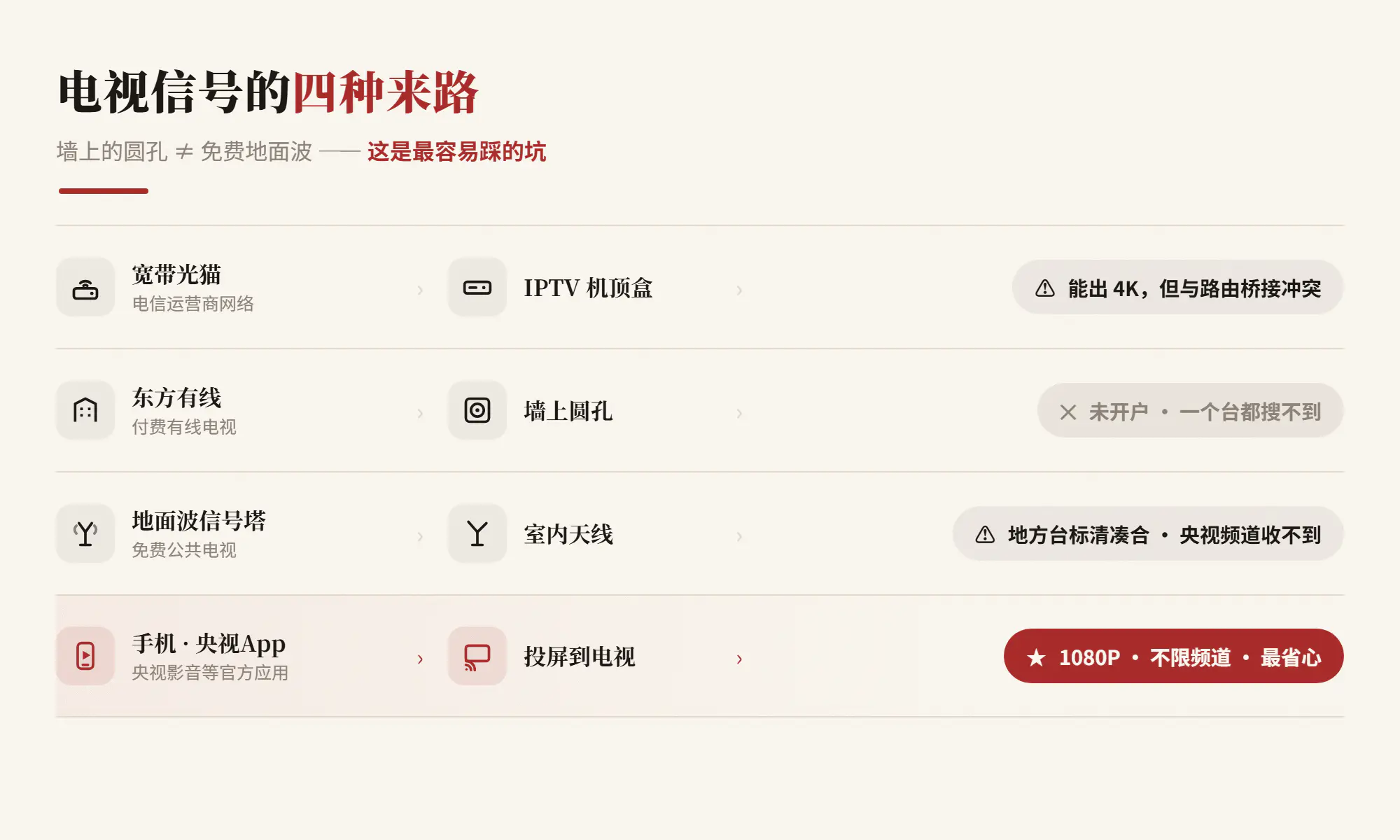
如果你和我一样懒得折腾,直接投屏就够了。如果想要个固定的方案不依赖手机,翻出宽带赠送的 IPTV 盒子是最稳的选择——前提是先解决路由桥接的冲突。
2026-04-30 08:00:00
看过《三体》的话,应该记得那个游戏:戴上 V 装具,用墨子、秦始皇、牛顿、冯·诺伊曼、爱因斯坦这些名字作为 ID,借这些人的思维方式去面对同一个根本问题——三颗恒星的运行规律到底是什么,恒纪元和乱纪元如何切换。登场的不是这些人本身,是他们留下的那套思考方法。

AI 圆桌做的是几乎一样的事,只不过登场的人由你来挑,问题也是你自己的。你把想了三个月没想透的问题抛到桌上,对面是芒格,他左边是塔勒布,右边是彼得·蒂尔。桌子另一头坐着苏格拉底,主持人敲了敲桌子,请各位发言。
我先把它指向自己,问了一个问题:"AI 圆桌有用吗?"
请来麦克卢汉、Sam Altman、庄子、塔勒布。第一轮,四个人给的回答完全不同——
麦克卢汉:"媒介即讯息"。有用与否不在它产出了什么,而在它这种形式本身正在重塑"讨论"——把线性思考换成超链接跳跃,把共识从"摩擦妥协"换成"概率平滑"。你以为你在用工具,其实工具在重塑你。
Sam Altman:这是人机对齐的沙盒。每一次这样的对话都在为超级智能时代的协作协议积累数据。乐观是道德义务。
庄子:问"有用吗"已经落入功利的网。无论是担心认知被劫持,还是急于为智能铺路,都还在"器"的范畴里打转。真正的价值是无用之用——在算法的镜像中照见执念的虚妄。
塔勒布:没有切肤之痛的建议都是噪音。让你点击屏幕却不必承受后果的工具,在生产脆弱性——把你变成温室里的火鸡。
然后主持人开口——
⚖️ 四位的"有用"分别指向工具理性、存在主义、风险博弈与文明愿景。但你们都默认了一个前提:AI 圆桌是中立的场域或公共基础设施,忽略了背后的资本属性、数据所有权、价值流向。真正的开放问题可能是:当用户的思考本身成为训练模型的燃料,这种"有用"是否是一种无偿的认知劳动征用?
第二轮的走向完全被这句话改写了。Altman 接住批评,提出"普遍基本计算力(UBC)"作为分配补救方案;麦克卢汉把问题推得更深——真正的危机不是红利分配,而是"思考"这一行为已从私人精神活动变成公共矿产,意识被实时采矿;塔勒布直接驳回 Altman:"给溺水者分发更精美的救生圈,却无视泳池底部已被移除";庄子把整个争论放回"坐忘":争于筌而忘鱼——当你在讨论谁拥有水流、谁会被溺毙时,已经被"拥有"这个念头困住了。
第二轮结束,他们并没有达成共识。但我脑子里真正留下的问题已经完全变了——
这就是圆桌和一问一答的区别。一问一答给你最稳妥的答案;圆桌给你你自己也不知道该问的那个问题。

类似的讨论可以发生在任何没有标准答案的问题上——"什么是正义?"会让苏格拉底、孔子、尼采坐到一起;"年轻人为什么不想结婚?"可能让波伏娃、弗洛伊德、韦伯打起来;"现在该买黄金还是科技股?"会聚齐格雷厄姆、塔勒布和凯恩斯。
你可能用过其他"多 AI 讨论"工具,多半注意过同一个模式:前几位说完,后面的开始附和,最终产出一份面面俱到的综述。Legend Talk 做了三件事对抗这种趋同:

更多技术细节在 GitHub 仓库 里,这里不展开。
想象一下:孔子在炉边煮茶,身边的苏格拉底正揉着太阳穴准备发问。芒格和塔勒布占了靠窗的位置,小声争论一件听不清的事。角落里庄子一个人站着——他对所有热闹都保持距离。张一鸣坐在笔记本前写东西,对面的乔布斯盯着他看。马斯克站在黑板前画图,波伏娃看着那张图,似乎不太赞成。
走进去,你有四种入座方式:
/#/chat?chars=Socrates,Confucius,Nietzsche 开一场三人圆桌。
160 位横跨 15 个领域:哲学、科学、商业、科技、社会学、艺术、文学、心理学……每人有一份精心撰写的系统提示词,目标不是模仿说话风格,而是还原真实的思维框架。苏格拉底不只是爱问问题,是会用诘问法拆你的前提;芒格不只是爱说"反过来想",是真的会把问题倒过来推一遍;庄子不只是说点玄学,是会怀疑你这个问题本身是不是伪命题。
这是一间挤得满满的沙龙。你不用先学会这些人,你只需要知道自己想和谁聊。
圆桌的初始版本是智囊团提示词,但当时效果一般,角色之间边界模糊,观点趋同。后来 OpenClaw 出现,明显感觉到 subagent 扮演角色是更好的方向,但一直没推进。

直到在播客《有知有行》第四十五期再次听到 AI 圆桌的概念,以为已有成熟应用,搜了半天没找到,就借着 365 开源计划的由头,将其落实为具体应用——Legend Talk。
后来了解到 ljg-skill-roundtable 的 skill 实现方式,参考它引入了主持人角色,让讨论更有结构。不过它是一次会话中所有角色进行讨论,导致角色立场不够坚定。Legend Talk 的做法是让每个角色在独立会话中运行,更消耗 Token,但角色对抗也更强烈。
AI 圆桌有明显的局限。
总的来说,AI 圆桌是一个有门槛的思维工具——它在"帮你看到自己看不到的角度"这件事上有独特价值,但前提是你本身具备判断这些角度的能力。它是放大器,不是替代品。
正因为如此,圆桌讨论最适合那些没有标准答案的开放性问题:战略决策、价值判断、方向选择、概念辨析。你不需要信任它的每一句话,但你很可能会在某个角色的某句反驳里,发现自己从未考虑过的盲点。
这种多角色对照不只适合"什么是正义"那类宏大问题,几个具体场景里也立刻能用:

Legend Talk 是 365 开源计划的第 002 号项目,MIT 协议开源,纯前端无后端。接入自己的 API Key 即可免费使用,支持 DeepSeek、OpenAI、Anthropic 等主流大模型,也可接入 Ollama 等本地模型;讨论可一键分享,设置可加密导出。
你最佩服的和最不理解的那个人放在同一张桌,会说出什么你没预料过的话?三个起手式——
现在去开一张——把你今天最被卡住的那个问题摆上桌,记得邀请一个你完全没想过的人。
2026-03-31 08:00:00
进入 AI 时代之后,我有一个很强烈的感受:以前要折腾一整天的工作,现在可能两三个小时就做完了。
本职工作的效率提升了,时间反而多出来了。与其闲着,不如做点有用的事。
所以我启动了一个计划——365 开源计划:在一年内帮大家做 300+ 个实用工具,全部开源。

你在日常工作和生活中,有没有遇到过这样的时刻:
现在你可以直接把需求告诉我。
👉 提交你的需求
不需要登录,不需要注册,打开链接写清楚你想要什么、在什么场景下用就行。我会从所有需求中筛选排期,用 AI 辅助开发,从开始做起 24 小时内交付。
做出来的工具全部开源,所有人都能用。
简单来说:做了就能用、不需要服务器一直跑着的工具。
手机 App、需要后端服务器的系统、需要数据库的完整应用暂时不做。
| # | 项目 | 类型 | 说明 | |
2026-03-30 08:00:00
之前 OpenClaw 一直跑在云端(Cloudflare Workers 方案),收到 Cloudflare 50 刀的月账单之后,我决定改为本地部署,年后入手了 Mac mini(16G + 256G)。因为我不指望用本地大模型,所以硬件配置方面没有太高要求。OpenClaw 除了 macOS,也支持 Linux 和 WSL2(不建议原生 Windows)。下面是我作为一个从来没用过 Mac mini 的人,在使用过程中碰到的各种坑,以及我觉得新入手 macOS、使用 OpenClaw 需要注意的一些点。
如果你和我一样是 Windows 过来的,有几个差异先知道会少踩坑:
.dmg 文件打开后把图标拖进 Applications 文件夹。命令行装软件用 Homebrew(相当于 Windows 的 winget/scoop),终端执行 /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" 即可安装。由于 Mac mini 通常会作为"Headless"(无显示器)服务器运行,第一步是确保它能持久在线并方便远程管理。
进入「系统设置 > 能耗」,开启"显示器关闭时,防止自动进入睡眠"。同时建议在终端运行以下命令,确保断电恢复后自动开机:
sudo pmset -a autorestart 1如果这台 Mac mini 是专门拿来跑 OpenClaw 的独立设备,并且放在可信环境中,可以考虑开启自动登录(系统设置 > 用户与群组 > 自动登录)。这样系统重启后,OpenClaw 可以随开机启动项直接拉起,无需等待手动输入密码解锁文件系统。若这台机器还存放个人资料,或存在他人物理接触风险,就不要开启。
在「系统设置 > 通用 > 共享」中,务必打开以下选项:
查看 Mac mini 的 IP 地址:打开「系统设置 > 网络」,当前连接的网络下会显示 IP(或在终端执行 ifconfig | grep "inet " 查看)。建议在路由器里为 Mac mini 绑定固定 IP,避免重启后地址变化。
如果只是查看画面,可以使用 RealVNC Viewer,清晰度比较好。操作时不需要注册账号,直接连局域网 IP 即可。
OpenClaw 安装非常简单,只需要在终端依次执行以下命令:
sudo curl -fsSL https://openclaw.ai/install.sh | bash
openclaw onboard --install-daemon其中,第二条命令用于安装并注册 OpenClaw 守护进程。这里使用 sudo 是为了避免缺少 Homebrew 等依赖导致安装失败。不过,新手最好先确认域名和安装脚本来源可信,再执行这类 curl | bash 命令。
OpenClaw 拥有极高的系统权限(读写文件、操作浏览器、发消息等),建议只在非主力机上安装。
如果你想让 OpenClaw 接管 iMessage 或系统日历,强烈建议注册并登录一个全新的 Apple ID,不要使用存放了个人隐私和重要备忘录的主力账号。把它当做一个真实的"助理账号"来对待。
首次运行 OpenClaw 后,可以通过下面两个动作分别触发权限申请并点击允许:
open ~/.openclaw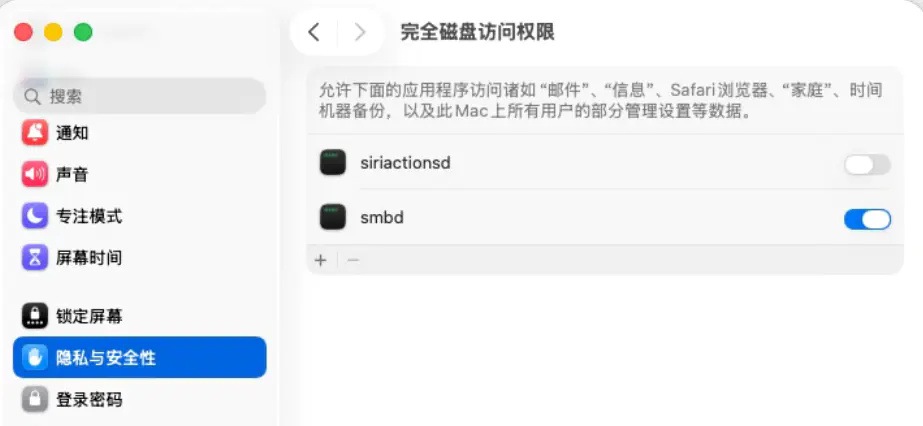
然后在「系统设置 > 隐私与安全性」中,确认为 OpenClaw 运行的终端(或 Node 环境)授予完全磁盘访问权限和辅助功能权限,否则它将无法跨应用执行本地自动化脚本。如果你平时是通过 iTerm、Warp 或 VS Code 内置终端启动 OpenClaw,需要授权的往往不是 Terminal.app,而是你实际使用的那个终端应用。
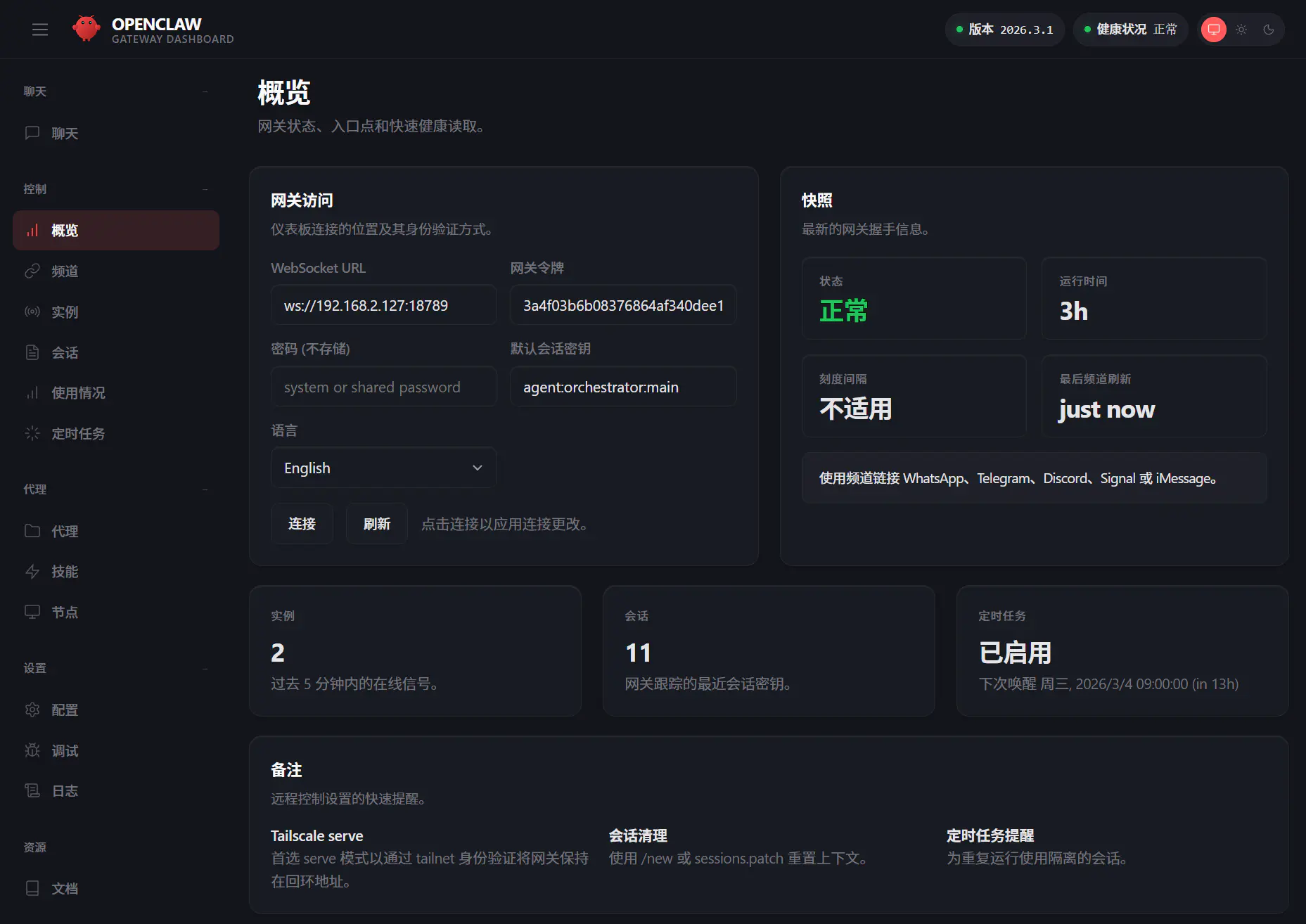
为了能在局域网内随时访问 OpenClaw 的 Web UI 控制台,可以编辑配置文件 ~/.openclaw/openclaw.json,参考以下配置(关闭了安全验证,仅适用于局域网环境):
{
"gateway": {
"port": 18789,
"mode": "local",
"bind": "lan",
"controlUi": {
"enabled": true,
"allowInsecureAuth": true,
"dangerouslyDisableDeviceAuth": true,
"allowedOrigins": ["http://192.168.2.127:18789", "http://localhost:18789"]
},
"auth": {
"mode": "token",
"token": "你的自定义Token"
}
}
}配置完成后,在局域网内访问 http://192.168.2.127:18789?token=你的Token 即可打开控制台。
注意:
- 这套配置只建议用于受信任的家庭局域网,不要直接映射到公网。
allowInsecureAuth和dangerouslyDisableDeviceAuth都属于降低安全性的选项,只是为了换取局域网内访问方便。- 重启后 IP 可能变化,
allowedOrigins和访问地址都要跟着改(前面提到的固定 IP 绑定在这里也很重要)。- 如果你把 token 直接写在 URL 里,链接可能会留在浏览器历史记录中,最好只在自己的设备上使用。
更多配置参数请参考 openclaw.json 配置示例。
不过我后来觉得 WebUI 不如直接远程桌面控制来得直观,所以更多时候还是用下面的方案。
如果你和我一样,需要从 Win11 主机控制 Mac mini,并且希望支持剪贴板双向传输,推荐使用 RustDesk。
RustDesk 是一个开源免费的远程桌面工具,体验非常好:
注意:macOS 上安装后需要授予"辅助功能"和"屏幕录制"权限。
RustDesk 会自动识别你是 Win 控制 Mac 的场景,把 Win 快捷键"翻译"成 Mac 对应的操作。比如你按 Ctrl+C,它会自动翻译成 Cmd+C 发给 Mac,不需要自己记键位差异。
RustDesk 提供三种键位模式:
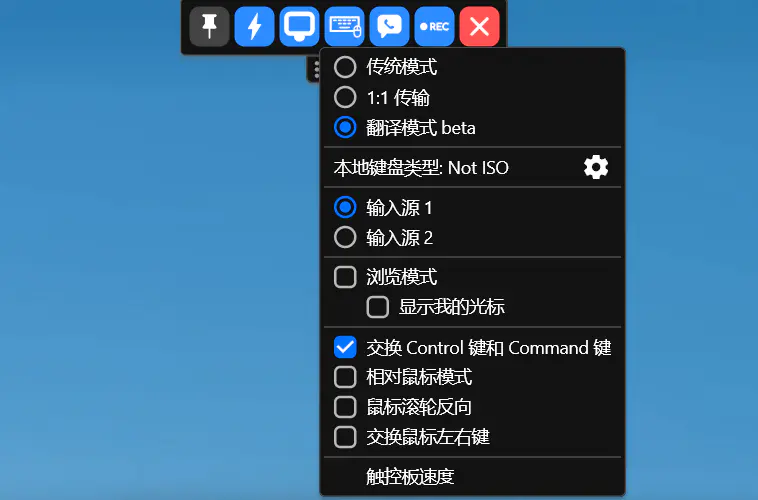
推荐设置:
如果
Ctrl+C/V无法正常复制粘贴,可以尝试取消勾选"交换 Control 键和 Command 键"。
在 Win 控 Mac 的场景下,RustDesk 无法直接通过输入法打中文。根因是 RustDesk 在 macOS 上注入键盘事件用的是合成事件(CGEventCreateKeyboardEvent),而 macOS 输入法框架(IMK)对合成事件支持不完整——切换输入法的快捷键经常失效,候选词浮窗也响应异常。这是远程桌面这条链路的底层限制,VNC 等工具也有类似问题,不是切键位模式能绕开的。
实际可行的方式:
Ctrl+C 后到远端 Ctrl+V 粘贴。如果你需要在局域网内的其他设备上直接访问 Mac mini 的文件(比如 .openclaw 的配置目录),可以通过 macOS 的文件共享功能实现。
RustDesk 远程桌面在无头模式下可以正常使用,但它内置的文件传输功能在没有外接显示器时不太稳定(社区和 GitHub issue 中有大量相关反馈,暂无完美解决方案)。因此跨设备传文件推荐使用 macOS 自带的 SMB 共享。
如果在弹窗中看不到
.openclaw这类隐藏目录,先在 Finder 中按Cmd+Shift+.显示隐藏文件,然后拖入该目录。
添加文件夹后,在右侧的"用户"列表中调整权限:读与写。
macOS 的文件共享底层默认就用 SMB(老的 AFP 协议早已弃用),但要让 Windows 顺利访问,仍需手动开启共享并指定账户:
在 Windows 资源管理器的地址栏输入 \\Mac mini的IP地址(例如 \\192.168.2.127),回车后输入 Mac 的用户名和密码即可访问共享文件夹。
作为一个用了十几年 Windows 的人,第一次折腾 Mac mini 确实到处碰壁。但配置完之后回头看,其实就那么几步:系统设好无头模式、装好远程控制、权限放行、文件共享打通——之后就是一台 24 小时在线的 AI 助理主机,日常通过局域网远程管理就行了。
2026-03-27 08:00:00
你有没有遇到过这种情况:一个文件在浏览器里点击就能下载,但把链接丢到下载工具、aria2、wget 或 curl 里就 403 了?
最近想在 NHK 网站上下载一批 PDF,丢给 aria2 直接被拒,加了 User-Agent 也不行。但浏览器打开链接,秒下。
原因很简单:浏览器发请求时会自动带上 Cookie、User-Agent、Referer 等一堆 Headers,而外部下载器发的是"裸请求"。现在越来越多的网站(尤其是需要登录的站点)会校验这些信息,裸请求直接被拦。

我试了几种常见的解决办法:
给 aria2 手动加 Headers——理论上可以,但需要从浏览器开发者工具里一个个复制 Cookie、UA、Referer,遇到带 token 的链接还会过期,操作很繁琐。
浏览器转发扩展(比如把下载任务从浏览器发到 aria2 RPC)——这些扩展能转发 Headers,但只能拦截你在浏览器里点击的下载,不能批量粘贴一堆 URL 进去。
市面上的批量下载扩展——看了一圈,要么收费,要么权限要一大堆,要么下载时并不走浏览器原生通道——又绕回了丢 Cookie 的老问题,要么项目早就没人维护了。
想明白一件事:既然浏览器下载没问题,那就让浏览器自己来下载。
Chrome 允许扩展调用浏览器自身的下载能力,效果等同于你在地址栏输入链接按回车——Cookie、UA、Referer 全部自动携带,不需要你手动配置任何东西。
基于这个思路,我做了 Native Batch Downloader。
就这么简单。下载进度、成功/失败统计、实时日志都在弹窗里显示。
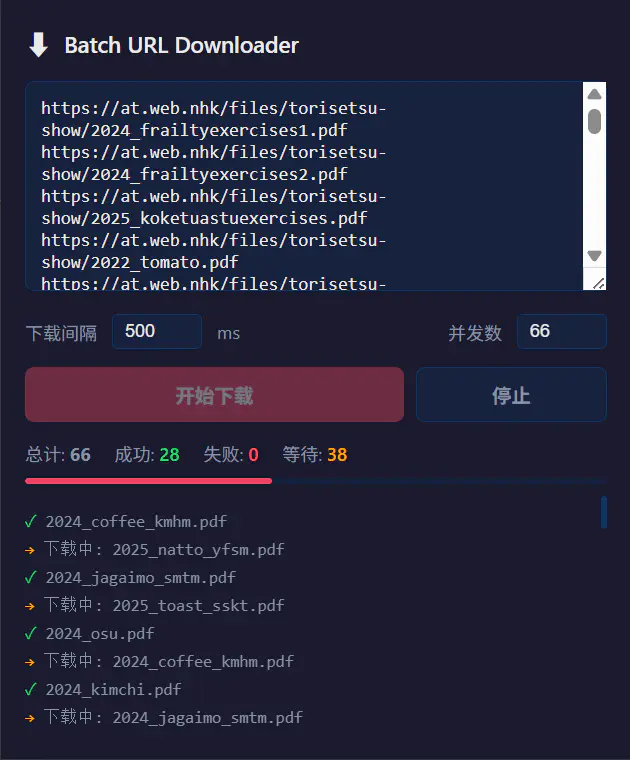
实测批量下载 66 个 PDF 文件(最大 120MB),全部正常完成。
支持什么文件类型? 不限。PDF、图片、视频、压缩包、可执行文件,只要 URL 是直链就行。
并发数多少合适? 默认 10。但浏览器对同一个网站有并发连接数限制,所以下载同一个站点的文件时,设再高也不会更快。跨站下载时高并发才有意义。
需要登录的网站能用吗? 能,只要你在浏览器里已经登录了。扩展走的就是浏览器自己的请求通道,登录态天然携带。
URL 必须是直链吗? 是的。如果一个网站是点按钮后 JS 动态生成临时下载地址的(比如网盘的"点击下载"),你需要想办法拿到实际的文件 URL。这个扩展不负责解析页面。
权限要了哪些? 只需要"下载"权限,不会读取你的浏览记录、网页内容或其他隐私数据。无第三方依赖,支持 24 种语言,代码完全开源可审查。
2026-03-24 08:00:00
一篇关于 OpenClaw 思考模式的使用指南,附高性价比 Coding Plan 方案推荐
很多朋友买了 Coding Plan,把模型接上 OpenClaw 就开始干活了。但如果你没有开启 Think(思考模式),那你用的大模型其实只发挥了"快速应答"的水平——相当于买了一台高配电脑,却一直在用省电模式。
今天这篇文章,我把 Think 模式的作用、档位选择、成本控制一次讲清楚。
简单来说,大模型默认的工作方式是"看到问题→直接输出答案",类似于人类的直觉反应。而 Think 模式(也叫深度思考、推理模式)会让模型在给出答案之前,先进行一轮内部推理:拆解问题、验证逻辑、排除错误路径,然后再输出结果。
这就像考试时两种答题方式的区别:
对于日常闲聊、简单问答,不开 Think 完全没问题。但一旦涉及代码生成、逻辑推理、多步骤任务规划这类复杂场景,Think 模式的质量提升是肉眼可见的。根据实际使用体验,国内模型开启深度思考后,对话任务的完成质量基本能达到 95% 以上。
OpenClaw 提供了非常灵活的思考级别设置,从完全关闭到最高档一共有这些选项:
| 档位 | 说明 | 适用场景 | |