2026-06-28 09:25:45
接上文 《大语言模型的基石:Transformer 入坑笔记(二) - 基本原理和 Word Embeddings》,继续我们的 Attention Is All You Need/Transformer 学习之旅。
首先简单了解下传统的方案。
卷积神经网络(CNN)似乎更适合静态数据(比如图片处理、提取特征等)。 所谓静态数据,是指每个数据组都单独和目标矩阵运算,通过卷积层、池化层、全连接层等输出。 每个数据组都单独运算所以可以大规模并发,但是数据组之间也缺乏关联。 我大概看了下原理,和我们要关注的 Transformer 关系不大,先略过了。
2026-06-25 00:45:45
继续我们的 Attention Is All You Need 学习之旅。
我不是这个领域的,只是感兴趣想补一下基础,所以这一篇先只看最通用的原理:神经网络训练的大概流程、Embedding 是什么,以及 Word2Vec 里两种常见优化思路。
Attention Is All You Need 最早落在机器翻译任务上,它提出的核心架构就是 Transformer。工程上我们常接触到的 Transformers 库,则是围绕这类模型提供了更完整的封装。
2026-05-01 04:45:45
这几年 AI 的热度一直很高。日常问答、写代码、整理文档、做工具,它已经开始进入不少人的日常工程流。我最近也开始认真补这块东西,主要是想搞清楚:这些模型到底是怎么一步步训练出来的,以及它有没有机会更深入地帮我们优化游戏研发里的工作流。
2026-05-01 02:00:45
这两天 DeepSeek V4 Pro 刚上线,小米那边也送了一个月的 Mimo Token plan。我本来就在试着用 AI 做一个完整工具,正好顺手把几个国产大语言模型都拉进来跑了一轮:GLM 5.1、Kimi K2.6、Mimo v2.5 Pro 和 DeepSeek V4 Pro。
测试样本是我手头正在做的一个工具项目,后面只保留和模型表现有关的数据,不展开它自己的功能设计。
2026-04-23 06:45:45
今年国产大模型是真的热闹。新模型一出来,宣传话术一个比一个猛。
尤其是最近出来的 GLM 5.1。
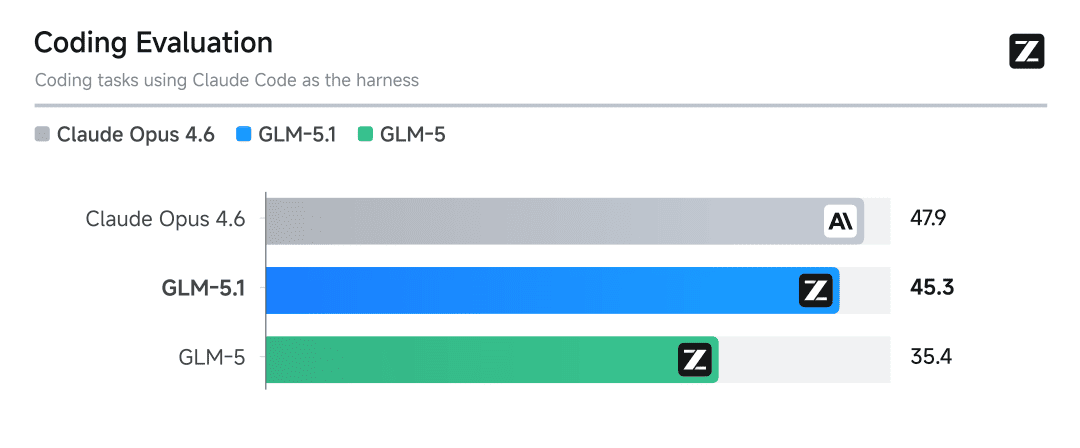
还有 Kimi K2.6。

海报和宣传图看着都很唬人,但真到自己拿去干活的时候,往往还是会闻到一点“跑分没输过,实战没稳过”的味道。所以我干脆把最近几个真实使用场景里的体验记了下来。
2026-03-28 00:45:45
在上一篇文章中,介绍了 libatbus 从静态子网树到动态拓扑注册表的路由设计变更。新的拓扑模型解决了代理层无法弹性伸缩和跨区域隔离的问题,但路由只是底层基座——上层应用框架 libatapp 才是真正面对业务开发者的接口。
这篇文章聚焦于 libatapp 在新架构下的连接管理层设计,涵盖以下核心问题: