2026-06-01 12:03:31
这些笔记是在自己的 Mac Mini 上面折腾了一些记录,主要是安装一些重要的大模型工具,把这些工具连接起来,建立自己的私有本地知识库等等,以备查阅。后续不定时更新。
OrbStack 是专门为 MacOS 设计的快速、轻量级的虚拟化工具,可以作为本地 Docker、K8s 和 Linux VM 的超容易替代品。因为它丢掉了跨平台的包袱,直接在系统内核级别支持虚拟机指令,动态分配内存等等做法,让它变得超快。就以 Docker 为例,它可以把冷启动速度从几十秒优化到一两秒。
我是在 Apple M4 芯片的 Mac mini 上面折腾的,首先要保证我的应用全部都是 M4 芯片直接支持的,而不是通过 Rosetta 2 兼容性转换过来的。在检查 Homebrew 的时候,发现 brew 命令的路径在/usr/local/bin/brew,这就是说 brew 在 Intel CPU 的模拟路径上,因此重新安装了 Homebrew,修改 PATH 以后检测发现 brew 已经在 ARM 的原生路径上了:/opt/homebrew/bin/brew。
这再安装 OrbStack 就行了:
brew install --cask orbstack使用 orb 命令启动的时候,OrbStack 列出了三大核心功能:Docker、K8s 和 Linux VM,基本上足以完成我日常折腾的最核心需要了。
安装以后,docker 的命令就完全支持了,启动一下看看:
docker run -p 80:80 docker/getting-started我在公司里代码编辑器使用的是 Intellij 和 Windsurf,后者是真正的 AI 原生 IDE。不过现在打算安装 Cursor,作为 Windsurf 的竞品,它有更优秀的综合体验。
首先要安装 Conda,有很多其他的库管理系统,但因为 Conda 是一个更通用的环境管家,不仅限于 Python,包括 Python 库底层的 C++一并搞定。
Miniforge 把 Conda 工具包装了一下,并且针对 Mac 定制化了一下。Conda 的定制化有很多,Miniforge 是其中之一,开源免费,支持原生 ARM。
Ollama 是一个可以在本地电脑上运行 LLM 的工具。然后可以跑 Llama 模型了:
ollama run llama3.2用 Cursor 写一段小程序来调用它:
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.time.Duration;
public class LocalLLMClient {
public static void main(String[] args) {
String endpoint = "http://localhost:11434/api/generate";
String jsonPayload = "{"
+ "\"model\": \"llama3.2\","
+ "\"prompt\": \"Who are you?\","
+ "\"stream\": false"
+ "}";
HttpClient client = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(10))
.build();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(endpoint))
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(jsonPayload))
.build();
try {
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println("HTTP status code: " + response.statusCode());
System.out.println(response.body());
} catch (Exception e) {
e.printStackTrace();
}
}
}运行它,可以得到:
HTTP status code: 200
{"model":"llama3.2","created_at":"2026-03-29T23:54:11.011864Z","response":"I'm an artificial intelligence model known as Llama. Llama stands for \"Large Language Model Meta AI.\"","done":true,"done_reason":"stop","context":[128006,9125,128007,271,38766,1303,33025,2696,25,6790,220,2366,18,271,128009,128006,882,128007,271,15546,527,499,30,128009,128006,78191,128007,271,40,2846,459,21075,11478,1646,3967,439,445,81101,13,445,81101,13656,369,330,35353,11688,5008,16197,15592,1210],"total_duration":868990167,"load_duration":99794167,"prompt_eval_count":29,"prompt_eval_duration":263381208,"eval_count":23,"eval_duration":497184294}Ollama 这个工具是最核心的部分,其他很多工具都需要连接在 Ollama 上面跑的大模型来完成。
LM Studio 基本上就是本地的大模型图形化工具,和 Ollama 在功能上是有重叠的。一般说来,Ollama 可以用作后台程序运行和工程化调用,但是 LM Studio 适合选型和调试。
模型文件都比较大,已经使用 Ollama 下载了的,就不需要 LM Studio 再下载一遍了。模型都被下载到了~/.ollama/models/blobs/sha256-xxx,根据文件大小可以找到那个实际的模型文件。
然后创建 gguf 的软链接,比如:ln -s ~/.ollama/models/blobs/sha256-3e4cb14174460404e7a233e531675303b2fbf7749c02f91864fe311ab6344e4f ~/AI/models/LM_Models/Ollama/qwen3-4b/model.gguf,这样在加载以后,这个文件就能够被识别了:
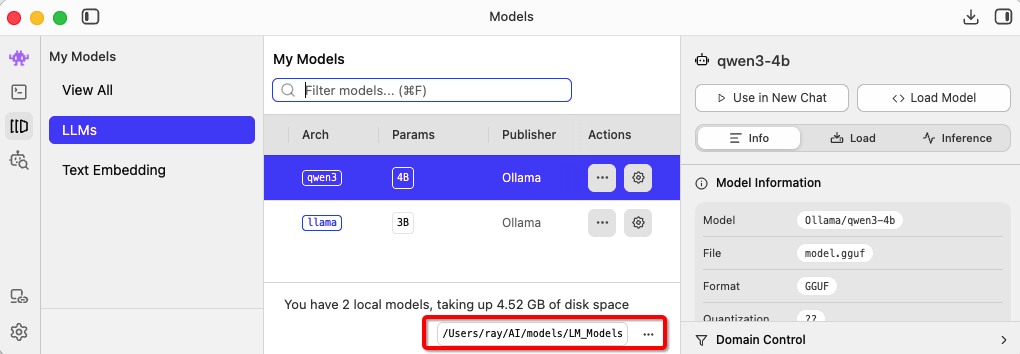
我们可以配置 /Users/ray/Library/Application Support/Claude 来允许 Ollama 来访问 Claude 的 MCP 接口:
{
"preferences": {
"coworkWebSearchEnabled": true,
"coworkScheduledTasksEnabled": false,
"ccdScheduledTasksEnabled": false
},
"mcpServers": {
"local_ollama": {
"command": "/usr/local/bin/npx",
"args": [
"-y",
"ollama-mcp-server",
"http://localhost:11434"
]
}
}
}再去问 Claude 的时候,它就能访问 Ollama 并得到安装的模型了:
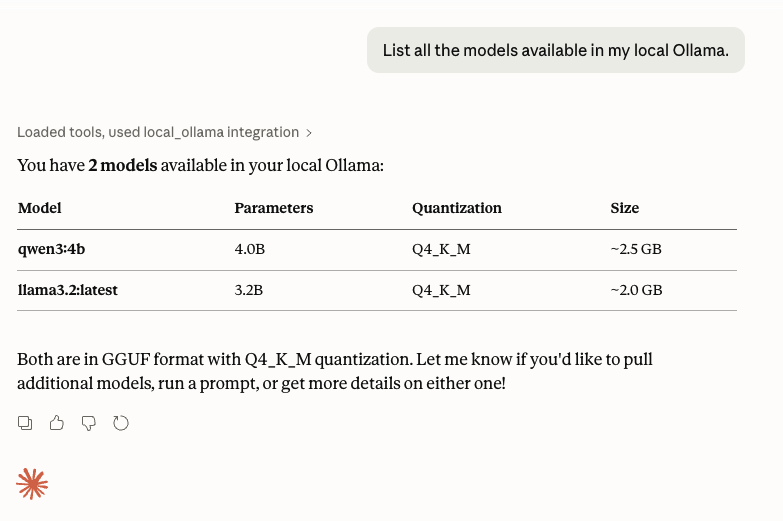
它的这个操作,其实是和本地运行 curl http://localhost:11434/api/tags 或者 ollama list 是一样的。
为了能更方便地使用,最好打开语音操作支持。在 Mac 的设置里面,找到 keyboard,语言列表里面需要把中文英文都勾上:
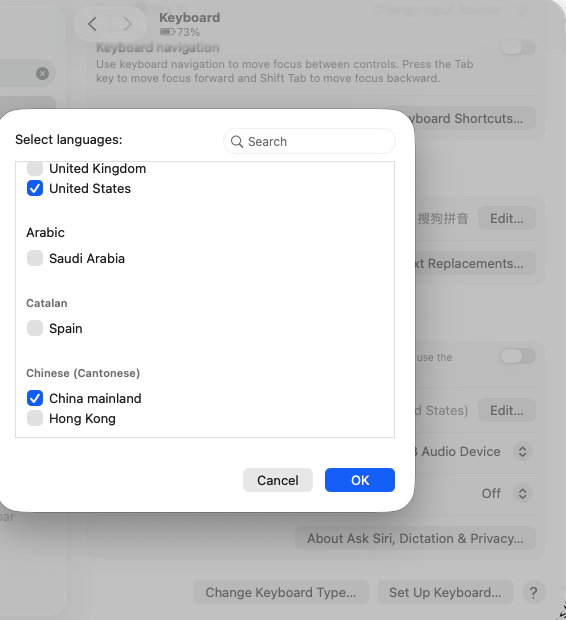
并且还可以设置为双击 Command 按键就可以调出语音输入。
在 general 的语言和地区设置里面,加上中文:

再配置好 Gmail 的 connector,就可以让 Claude 做一些更有意义的工作了。比如,我让它分析最近看的房子,生成一份详细的报告发到家人的邮箱里。
下载安装 AnythingLLM,下面使用它来选择本地模型,选择远程网站或者本地文件,并进行本地 RAG(检索增强生成,Retrieval-Augmented Generation),生成属于自己的私有/本地知识库。
设置里面,先选择推理模型(LLM Preference):
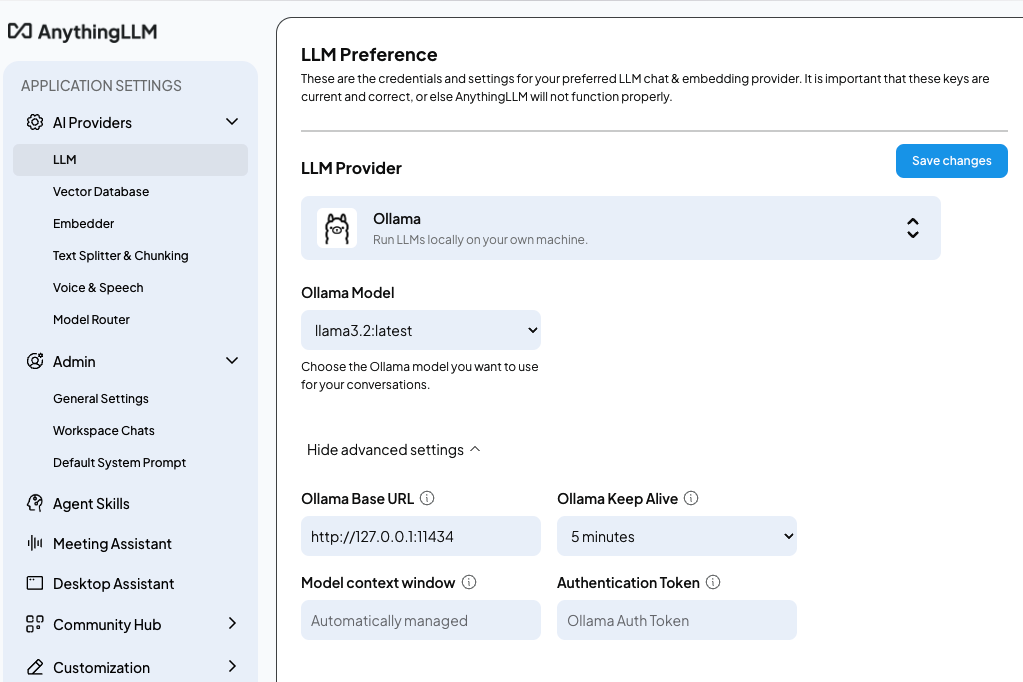
再选择嵌入模型(Embedding Preference):
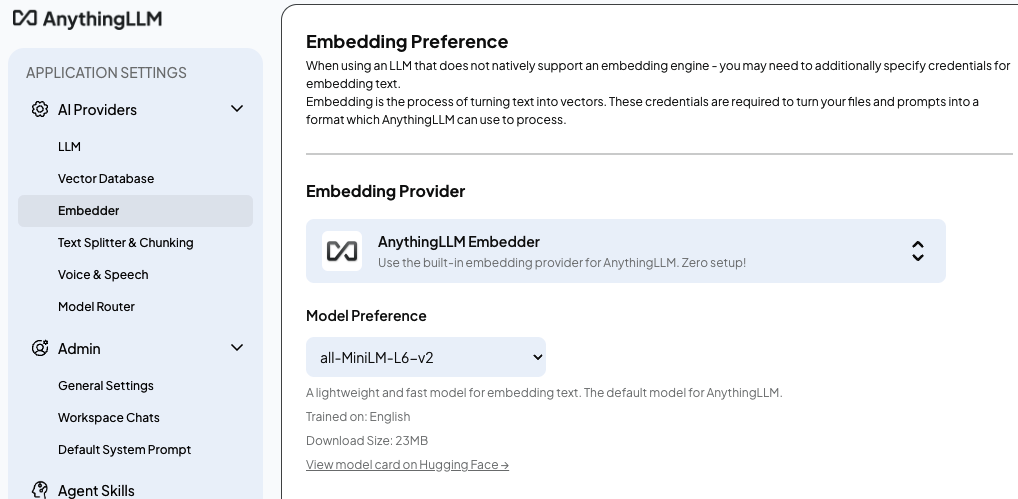
最后选择向量数据库 (Vector Database),保持默认。
使用 Bulk Link Scraper 这个 Data Connector 可以去扒拉网站上的内容:
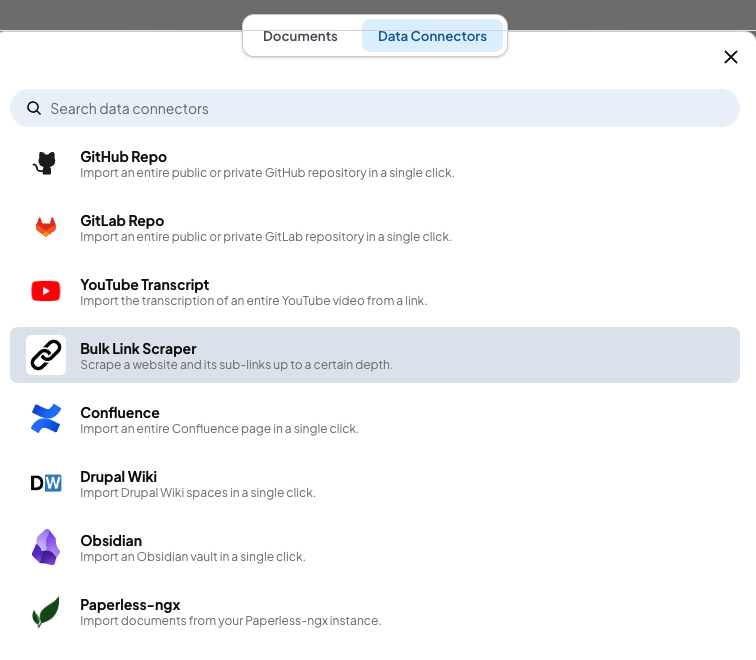
运行 tail -f ~/Library/Application\ Support/anythingllm-desktop/storage/logs/collector*.log 可以看到抓取的详细信息。
抓取完成后,回到 Documents 页就可以把抓到的内容加到 Workspace 里面去:Move to Workspace -> Save and Embed。
除了抓取网页,也可以上传一些本地的文件给它。
不过,文件较多的时候,它的可用性就比较差了。我们需要一些其他的工具。
为了解决前述问题,下面搭建搭建 Dify + 本地 Ollama 的组合。Dify 是一个 “Agentic Workflow Builder”,它底层集成了非结构化数据解析引擎,可以把各种格式的文件转成文本。
首先修改 Ollama 的环境变量,使其监听所有网卡:
launchctl setenv OLLAMA_HOST "0.0.0.0"这一步需要重启 Ollama。
现在本地有的 qwen3 和 llama3 都是 chat 模型,还需要专属的 Embedding 向量模型:
ollama pull nomic-embed-textDify 官方提供了完整的 Docker 编排文件,包含前端、后端、PostgreSQL 数据库、Redis 缓存以及向量索引组件。
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env再把上面.env 文件的 EXPOSE_NGINX_PORT 这一项端口从 80 改成 8080,以避免冲突。
还需要加上这样的配置以放宽文件上传限制:
UPLOAD_FILE_SIZE_LIMIT=10000
UPLOAD_FILE_BATCH_LIMIT=20000环境配置文件准备好以后,就可以启动所有容器组件了。
docker compose up -d于是乎,pull 了一大堆 image:
启动了一堆 container。以后要启动和停止,以及看日志,使用:
docker compose down
docker compose up -d
docker compose logs -f访问 http://localhost:8080/ 并创建用户。
接着 Settings 里面添加 Ollama 的 plugin,
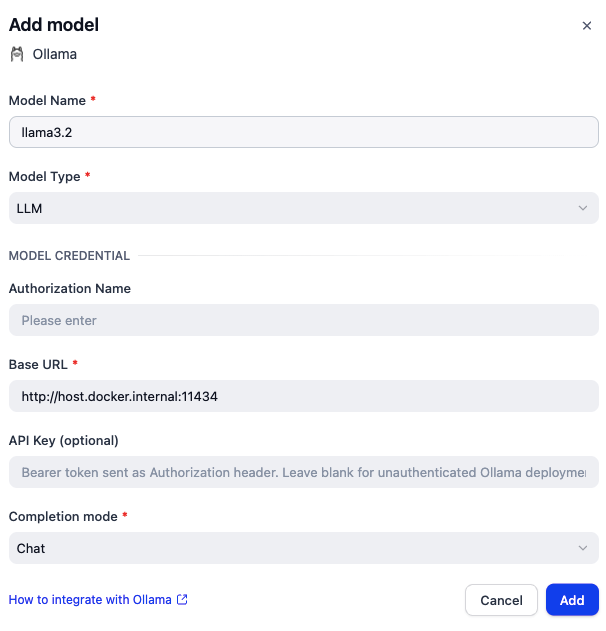
先配置 LLM 的 llama3 模型,再配置 Text Embedded 的 nomic-embed-text 模型。这其中的 Base URL 不能用 localhost,而是要使用 host.docker.internal,因为 Dify 在 Docker 内部运行。
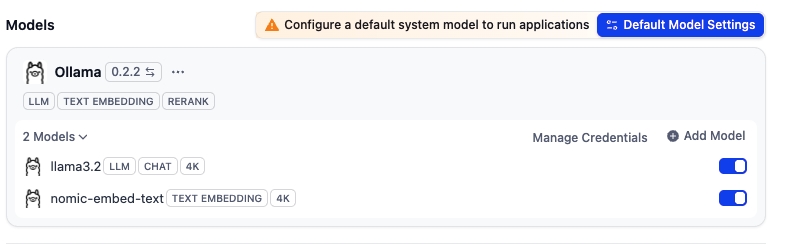
之后,就选中一个知识库,然后分批追加文件。因为软件一次性没法导入一个太大的文件夹,否则页面会卡死,所以这一点需要注意。
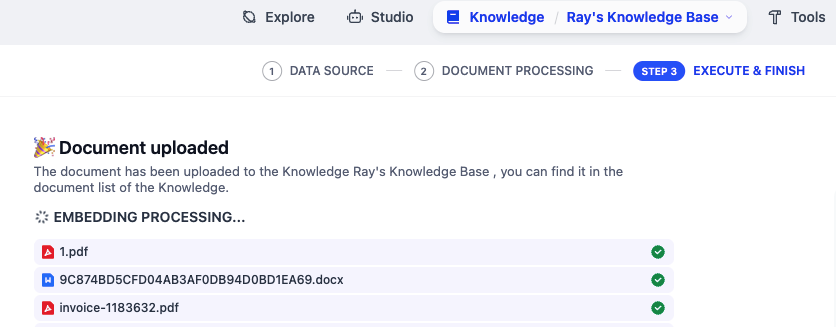
之后,还可以把网站等其它形式的数据导进来,这样自己的知识库就会更加全面。如果是爬网站的话,可以去 Firecrawl 注册一个账号,得到一个 API Key(免费版好像是最多只有 2 active browsers 一起工作,单月 1000 个 credit,不过对我来说也够了),填到 Dify 的 Firecrawl 插件配置中:
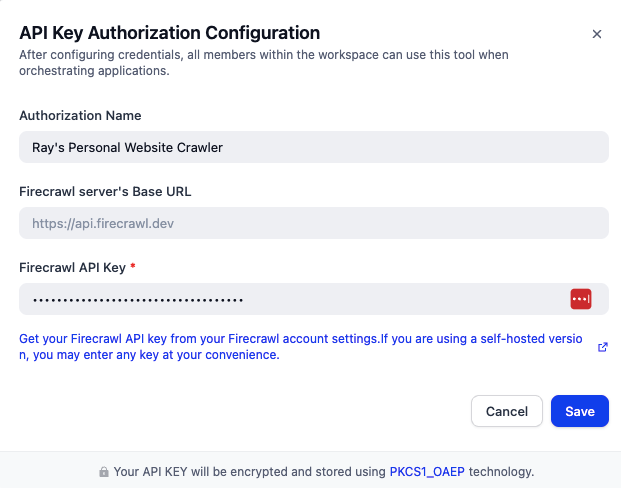
然后就可以去爬网站了。
最后,在 Studio 菜单里创建一个 Chatbot 或 Agent,在右侧的 “上下文” 中关联这个知识库。
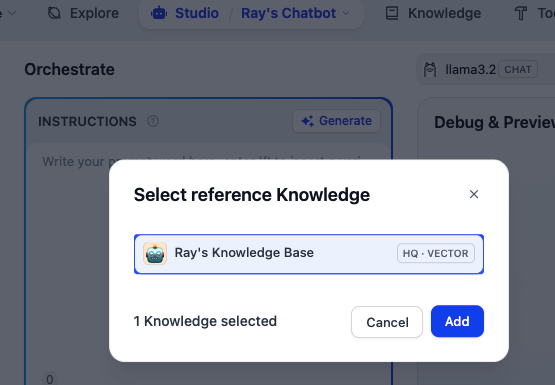
这样,后续问它任何问题,都可以从这个具备个人信息的知识库中进行检索。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
2026-05-25 08:04:10
raychase.net 这个域名是好些年前申请的,最近申请了个更适合作为我个人标签的 rayxiong.me,简单记录下我把新域名应用到 blog(新、老域名都可以访问 blog),以及创建并使用新域名的邮件地址收发邮件的操作。
在 Squarespace 上面配置好 DNS 的两个 A 记录:
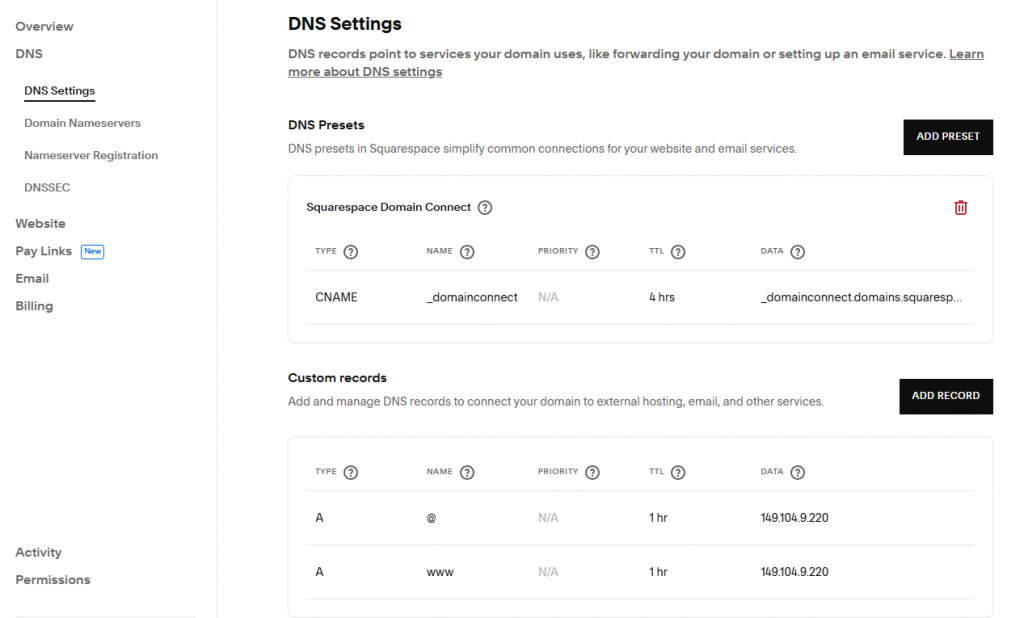
其中 @表示不带任何前缀,它和 www 前缀这样被视为两条独立的记录。没法再简单了,不过需要等几个钟头生效。
在网站的 Nginx 配置文件上面添加:
server_name www.rayxiong.me rayxiong.me;
以及:
if ($host = rayxiong.me) {
return 301 https://$host$request_uri;
}
if ($host = www.rayxiong.me) {
return 301 https://$host$request_uri;
}
做完之后检查一下有没有语法错误:
/usr/local/nginx/sbin/nginx -t我已经忘记之前证书怎么处理的了,重新安装 acme.sh:
curl https://get.acme.sh | sh -s [email protected]使用 acme.sh 来申请多域名证书:
~/.acme.sh/acme.sh --issue --nginx -d raychase.net -d www.raychase.net -d rayxiong.me -d www.rayxiong.me -w /home/www.raychase.net再把证书部署一下:
~/.acme.sh/acme.sh --install-cert -d raychase.net \
--key-file /etc/letsencrypt/live/www.raychase.net/privkey.pem \
--fullchain-file /etc/letsencrypt/live/www.raychase.net/fullchain.pem \
--reloadcmd "/usr/local/nginx/sbin/nginx -s reload"完工。访问网站看看证书的情况,再检查一下定时任务是不是已经顺利加上了:
crontab -lBlog 的文章里面,不能有写死域名的链接,全部要使用相对路径。接着就是给 wp-config.php 添加动态设置 Home 和 SiteURL,否则首页到不同栏目的链接都还是老地址:
if (isset($_SERVER['HTTP_HOST'])) {
define('WP_HOME', 'https://' . $_SERVER['HTTP_HOST']);
define('WP_SITEURL', 'https://' . $_SERVER['HTTP_HOST']);
}设置了之后,WordPress 的管理台的 General Settings 里面,这两个变量会置灰:
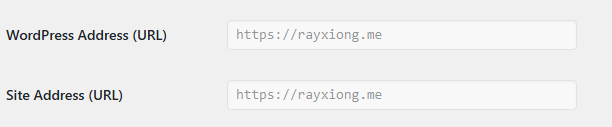
此外,考虑到两个域名包含相同的内容,需要告诉搜索引擎谁才是canonical的版本,否则搜索引擎可能会做出负面的判定。在Wordpress菜单的Apperance->Theme File Editor->Theme Functions (functions.php) 的尾部,写上:
remove_action( 'wp_head', 'rel_canonical' );
add_action( 'wp_head', function() {
echo '<link rel="canonical" href="https://www.raychase.net' . esc_url( $_SERVER['REQUEST_URI'] ) . '" />' . "\n";
});有了新的域名,打算搞一个个人标识鲜明的邮件地址 [email protected]。但是我打算只是创建一个邮件地址,邮箱服务依然使用 Gmail。
先配置收信,收信比较简单,保证 email 转发到原有邮件地址:
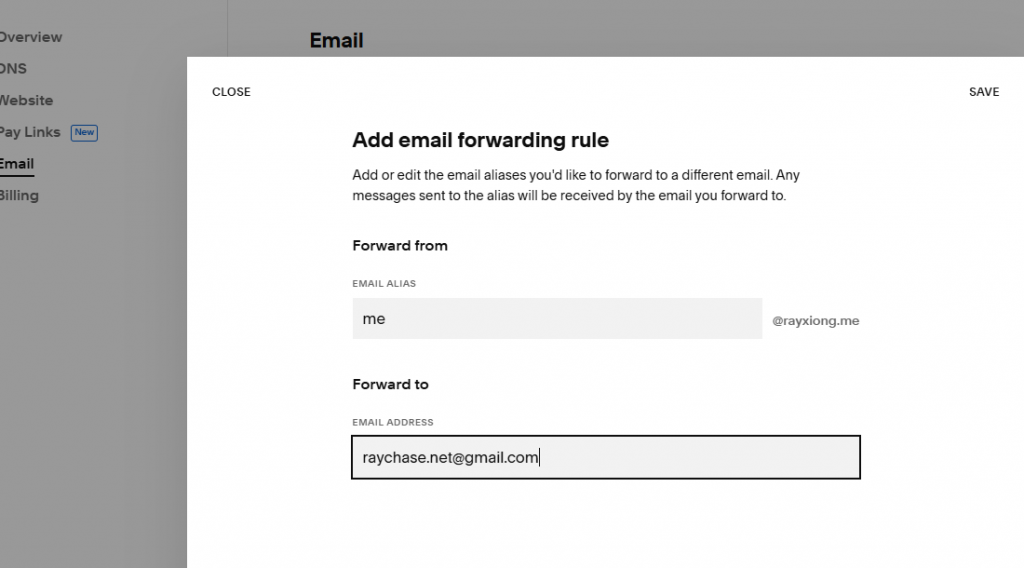
得花些时间生效,测试一下,发送到这个新邮件地址一旦成功,那收信路径就通了。
接着是发送。这需要 Resend 这样的工具。
建立一个 rayxiong.me 的 domain,然后添加如下的 DNS 记录:
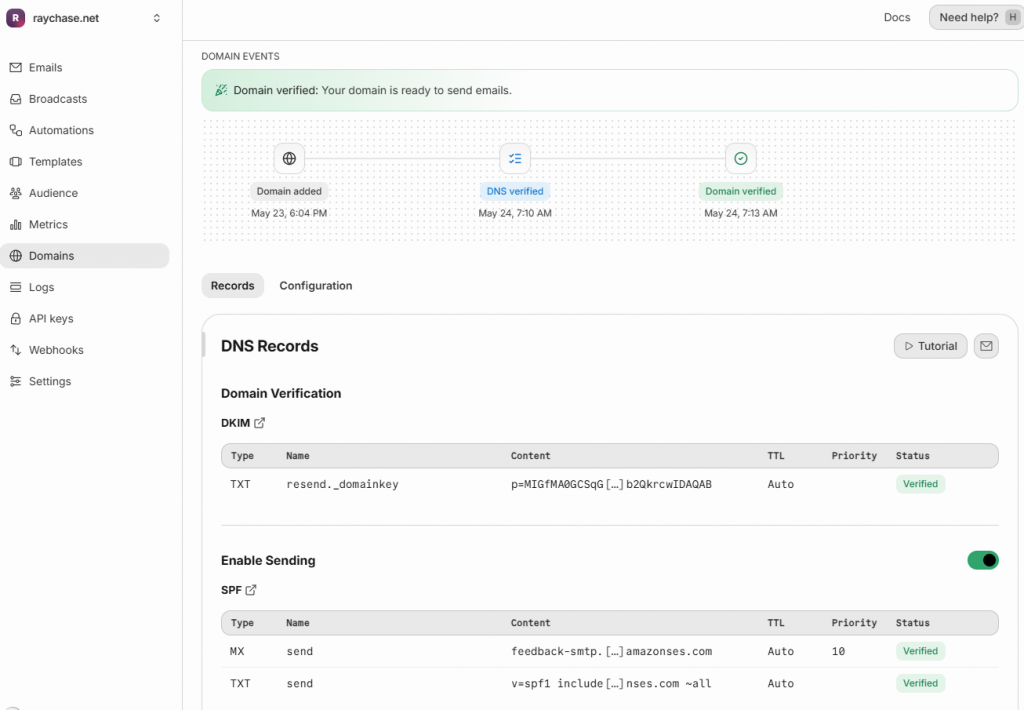
把这些 records 拷贝到 Squarespace 的 DNS 设置里面,然后再回到 Resend 上面来验证,确保验证通过。
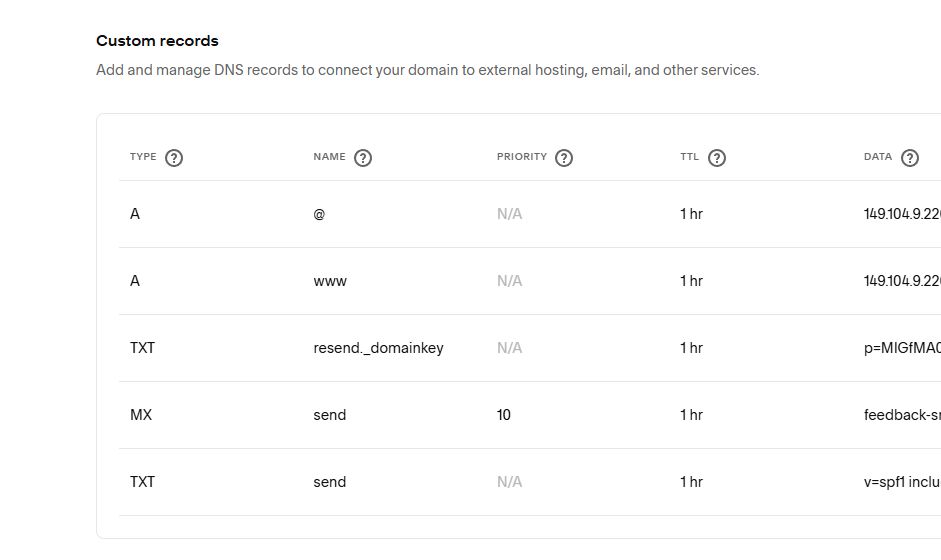
如果失败了,可以去 Logs 页面看错误信息。
现在,去 Sender 的 API keys 里面,给配一个 Gmail-SMTP 的 API Key:
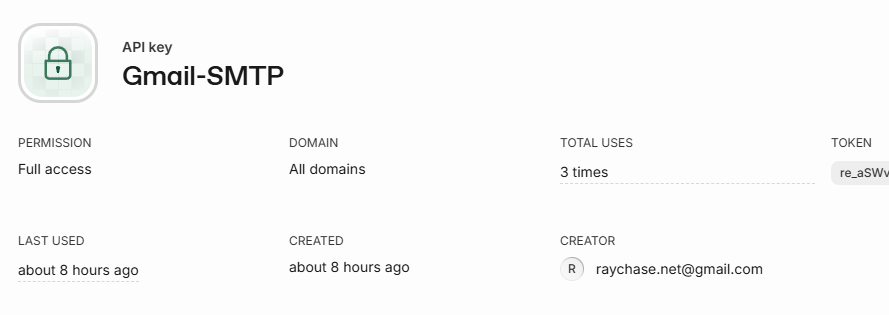
接着就可以给 Google 邮箱配置这个新的 email 地址了:
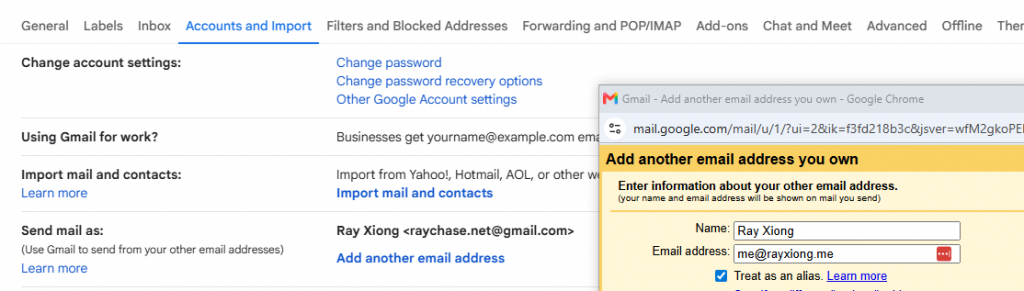
SMTP 服务器是 smtp.resend.com,这里需要使用到前面配置的 API key:
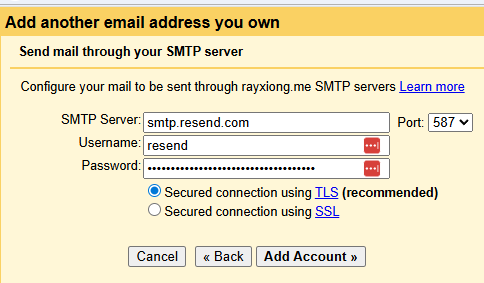
手机上面配置起来有点麻烦,需要创建一个新账户。
收邮件的部分,host name 写 imap.gmail.com,用户名写原本的 gmail 邮箱名,密码的话需要去 Google 的 App passwords 创建一个只能查看一次的密码,填在这里。
发邮件的部分,配置 SMTP 为 smtp.resend.com,用户名是 resend,密码就是前面的 API key。
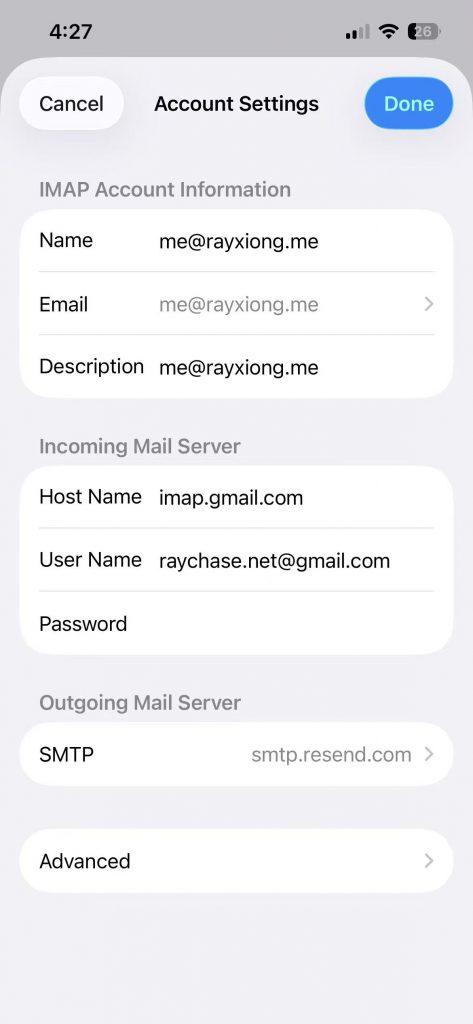
此外,Resend 的 DNS records 目前只配置了 sending,并没有 receiving。因为现在邮件的 receiving 是通过 Squarespace 的 Mailgun forwarding 来实现的,如果要配置 Resend 的 receiving,那是用于把邮件内容转成 JSON 数据并根据配置的 Webhook 来调用 API 只用了,目前不需要。
除了 blog 和 email,对于这样一个个人标签浓厚的域名,不知道还有哪些有趣的事情可以做。我想到的几个包括:
只是我的一些想法,不知道还有什么有意思的主意。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
2026-03-23 07:38:30
 作为一个老暗黑粉,二十年前,写过一点关于它的碎文。那时候我还在读书,《暗黑破坏神 2》应该是对我影响最大的一款游戏。还记得第一次接触到暗黑的那天——在家乡暑假的某个阴沉的下午,窗外雨绵绵,一进入游戏,第一幕的罗格营地,就被呼应的下雨细节打动,音乐、雨滴声,还有可以追随地散布的鸡,一切都让我觉得有巨大的沉浸感。于是我一遍又一遍地杀到城外去,杀到地下洞穴去。暗黑游戏的视觉效果我相信不是最好的,但是游戏性和耐玩度却是顶级的。在这以后,也玩过不少类暗黑的游戏,比如《流放之路》(那时候还写过一点关于它游戏中通货膨胀的思考),再没有一款能给我带来那样的体验。
作为一个老暗黑粉,二十年前,写过一点关于它的碎文。那时候我还在读书,《暗黑破坏神 2》应该是对我影响最大的一款游戏。还记得第一次接触到暗黑的那天——在家乡暑假的某个阴沉的下午,窗外雨绵绵,一进入游戏,第一幕的罗格营地,就被呼应的下雨细节打动,音乐、雨滴声,还有可以追随地散布的鸡,一切都让我觉得有巨大的沉浸感。于是我一遍又一遍地杀到城外去,杀到地下洞穴去。暗黑游戏的视觉效果我相信不是最好的,但是游戏性和耐玩度却是顶级的。在这以后,也玩过不少类暗黑的游戏,比如《流放之路》(那时候还写过一点关于它游戏中通货膨胀的思考),再没有一款能给我带来那样的体验。
后来我慢慢知道,原来有这样感受的不止我一人。《暗黑破坏神 2》是整个电子游戏历史上具里程碑意义的作品,它几乎凭借一己之力奠定了整个 ARPG 的游戏框架和标准,如今的 ARPG 砍杀的游戏方式,就是从它开始的。暗黑 2 的装备系统、技能树,还有怪物系统等等,在当时都是首创,并且都引领了后来的游戏发展方向。比方说,从暗黑 2 开始,装备的颜色分级制和词缀系统开始流行开来,也是从暗黑 2 开始,一类被称为 “刷子游戏” 的游戏类型,也开始被玩家逐渐认识;再比方说,技能树和后来资料片引入的技能加成系统,也逐渐演化出了游戏角色流派构建的理论。
暴雪的暗黑 3、暗黑 4,尤其是暗黑手游版,口碑时好时坏,但拿暗黑 2 的标准来比,可真是不怎么样。其实,对于一款过于成功的游戏,推出续作总是充满挑战,甚至可以说凶多吉少。不过,暗黑 2 之后的续作充满故事的张力——暗黑 3 一开始是糟糕的,尤其是那个著名的拍卖行,彻底让游戏失去了原有的平衡,之后《夺魂之镰》的资料片,挽回了一定的名声。再是暗黑 4,一开始黑暗压抑的美术风格获得了好评,但在游戏性,尤其是可重复玩性上大不如前几作,后来才在装备系统的改革等变更中逐步挽回名声。但无论如何,我觉得和暗黑 2 的那种哥特式氛围,装备驱动的打怪逻辑,还有高自由度的角色培养系统这些方面比起来,如若拿巅峰之作和优秀作品类比一样,这两者完全不可同日而语。
说起来,2021 年,暗黑 2 曾出了高清重制版,让那些二十年前的充满情怀的老玩家,得已不借助非官方的高清分辨率补丁,在如今的高配置机器上重温暗黑 2。回想起来,其实这样炒冷饭的做法也不算特别,印象中不少以前一样感动一票玩家的游戏,比如《最终幻想》系列的好几款游戏,都出过重制版。不过,在暗黑 2 发售的将近 25 年后,居然再推出一个完整的新角色 “术士”——《术士君临》资料片,却是真正让所有人都大吃一惊。
从商业上看,这次试一次非常精明的商业决策,整个过程保密性做得非常好,间隔超过 25 年的产品营销,这冷饭炒得也可以说登峰造极了。同时,也算对玩家社区给足情面了,之前暴雪被微软收购,微软是下了一步绝好的棋,但是玩家群体之间的口碑需要建立起来,这次看起来是一次非常成功的操作。无论如何,从数据上看,日活玩家增长超过了 50%,这是一个非常正面的信号,这些玩家的粘性可比一般游戏高得多。别忘了,这个资料片只是增加了一个角色,它并没有增加任何主线故事情节上的内容,它卖得并不能算便宜。
现在,我好奇的是暴雪下一步会如何打算。如果往回倒退几年,你问暗黑 2 还会出资料片吗,那一定会被喷痴人说梦。但是现在随着术士资料片的上线,我觉得暗黑 2 再续写下去,看起来完全合理。如果我们再回想到 25 年前,很明显暗黑 2 的第四幕是明显缩短的,有一种讲故事草草收尾的感觉,而且分辨率那时候也只有 640×480,于是一年之后的 2001 年,暗黑 2 资料片《毁灭之王》就以一个内容足量的第五幕弥补了玩家的遗憾,并且带来了更高分辨率、引入技能加成、引入符文和宝石系统等等巨量变更。可是想一想,一款成功到载入史册的游戏,从游戏内容上看,有什么理由会只出这么两部资料片,尤其是只有第一部是有 “主线剧情” 的,无论是从商业上考量还是情怀上考量,完全可以制作第六幕啊。
如果是一个新玩家接触暗黑 2,他的视角会是怎样的?我觉得暗黑 2 的视觉效果肯定不算好,虽说重制版让它和当年相比有了改进——可是话说回来,暗黑 2 从来都不是一个以画面取胜的游戏,它的可重复玩的游戏性无可匹敌,它的社区有一群坚持原教旨主义的硬核支持者,它在这个游戏史上写下了独一无二、浓墨重彩的一笔,而我觉得,二十五年过去了,这一笔却还远没有写完。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
2026-02-16 13:09:33
 这是一个很多人都讨论的大问题。
这是一个很多人都讨论的大问题。
我一直在思考,也一直没有一个足够确信的答案。去年这个时候,写了一点体会,如今的体会更深了。但是我觉得,我可以把凌乱的内容整理出来。
在一两周前,Google Genie 3 出来的时候,因为 demo 展示了它可以很容易地生成一整个可以游玩的世界,游戏引擎 Unity 的投资者就被吓坏了,疯狂抛售,一天就跌了二、三成。Unity 的 CEO 站出来喊话,核心观点还是——AI 再强大它也是概率性的,而 Unity 程序员的工作,却是追求确定性的。因此 AI 应该是软件开发的加速器,帮助提升创作的真实性和速度,而非替代者。
朋友推荐我这篇 《The Eternal Return of Abstraction: Why Programming Was Never About Code》,这篇读起来有些费劲,不过它的核心思想大概是,编程一直以来的本质是什么?它的本质是把人的意图转化为机器可以理解的形式。它的意义比代码高多了,因为代码只不过是表达这个意图的一种形式而已,还有什么形式?有了 AI,自然语言就可以是这个新的形式。大语言模型的一个功绩在于提升了抽象级别,以前我们必须要准确地使用编程语法来告诉机器应该怎么做,现在不是了,自然语言就是基于概率的描述,这个不确定性的问题是从根上就有的。
今年初的 SaaS 软件板块抛售潮,伴随着一系列事件,被称为 SaaSpocalypse,所谓的 SaaS 末日。它缘起于市场突然意识到 AI 不再仅仅是程序员的工具,而是可能称为自主运行整个 SaaS 程序编写,并完成复杂流程的 “数字员工”。这其中包括 Anthropic 发布的 Claude Cowork,它可以直接操作软件界面,这被认为很多 SaaS 的按人头付费的模式崩塌;Klarna 公开宣布,决定停止使用 Salesforce 和 Workday 这样的 SaaS 服务,因为他们启用了 AI,这让市场怀疑起 SaaS 的护城河硬度;再有早些时候的 Chegg,使用率锐减,主要是 AI 都可以直接、免费地获取答案了,学生们不再需要它了;还有 Adobe 因为 Sora 的发布而受到质疑,虽然专业用户的门槛不好说,但是大众用户的视频和图像生成似乎已经可以通过说几句话就完成了。
如果看看 SaaS 公司的财报,似乎是另一番光景。比如 ServiceNow,Q4 的营收增长超过了 20%。似乎,能看得到的事情是,面对科技行业的大幅裁员,更少的程序员可以做更多的事情,这也是市场担心的一个主要由来。那么反过来想,如果是按照按人头卖的形式,显然 SaaS 的收入会大幅下降。不过,如果定价按照解决的问题、feature 使用的次数和使用 AI 能力的 token 来收钱,这也许就完全不是那么回事了。我们目前能看到一些收费方式的变化(也看到了一些抵触,比如很多企业不喜欢这样的新方式,因为缺乏财务上的可预测性),但是市场需要看到更多。
好,现在冷静下来想想,到底哪些 SaaS 商业模式会出局?
首先想到的,知识库似乎会出局,因为 AI 可以非常方便地给出结论;其次,是文字组织和润色类工具,因为 AI 的文字能力比一般人都出色;再次,就是一些数据、声音、视频分析类的工具,这种把数据可视化,让人更容易从中找规律的软件,AI 也基本可以比较容易地代替。如果尝试泛化一些,似乎容易出局的软件模式是:需要的答案已经有了,只是要把它们从大量的内容中找出来,这种为了寻找答案而使用的专业工具,可能会被 AI 这种能够接受人类语言的特性所替代。换言之,如果提供的服务,没有硬核的、实质上的不可替代性,只有 “便捷性”,那就可能被踢出局。
那么,哪些 SaaS 商业模式很难被踢出局?
第一种,大概是拥有不可替代的数据。这样的 SaaS 软件拥有私有的、历史的和被视作宝贵资源的数据,而不是公开的、简单的和比较容易获得的数据。前面说的 Chegg 拥有的其实就是公开的数据,比如所谓的习题,还有像是 LeetCode 题解这样的也差不多;而 ServiceNow、Salesforce,以及 Atlassian 等等,这些企业专有的数据,让你没有办法直接使用一个公有的 AI 服务来直接替代掉。
第二种,就是高度复杂化和专业性的,AI 可以充当一个外行,但是没有办法触及最核心的精确性的。这包括某些媒体内容的制作,AI 可以提供丰富的素材,动画的画师可以使用 AI,但是主干必须要手动主导和干预,AI 可能能够生成关键帧之间的连接。
第三种,大概就是脱离软件的虚拟世界,和真实世界有着紧密的连接。比方说,对于很多 IoT 应用,通过各种各样的特定传感器来获知状态并连接。这些硬件的 “眼睛”、“耳朵” 和 “嘴” 需要特定的驱动程序,或是说,特定的软件才能工作。
还有一些 SaaS 应用,居于二者之间——可能能够暂时活一段时间,但是长远看,护城河也会被侵蚀。
第一种,复杂流程已经根植入企业人事流程的。这种只是代价高,但并非有那么强的不可替代性。
第二种,已经发展出专业技能的。有些学校里面都会教。比如 Unity 的技能和 Adobe 的技能等等。
第三种,那就是生态。比如 Jira 就有插件生态等等,生态意味着有很多为了方便提供某些特性而做出的定制化。
在说软件工程师之前,先跳出来想一下,哪些行业更容易被 AI 革命?
初级(简单劳动)的白领,是最容易被革命的。“简单劳动” 很容易理解,但是 “白领” 被淘汰是 AI 时代的特殊之处。如果说工业革命初期受到最大影响的是 “蓝领”,那 AI 革命初期受到最大影响的就是 “白领” 了。这一类初级白领,就是看似坐在电脑前工作,但是工作却是一些复制粘贴、流程安排和文字组织等等简单的活动,比方说翻译、秘书等等。
相应地,我记得李开复的《AI·未来》书上也讲到的,需要和真实世界的人交互的行业,影响可能是最小的。比如养老护理,体育竞技等等。还有一些行业,是蓝领,但是目前的 AI 和硬件设备的结合还要慢一步,比如汽车修理等等——AI 又没有手,因此这样的行业暂时也算安全,只不过随着机器人等强烈依赖硬件行业跟上来,这些也依然有被淘汰的风险。
好,接着再来看软件工程师。软件工程师,算是白领,但是算是 “初级” 白领吗?
其实,大家似乎比较容易能够达成共识的是,单纯编码,就是一个很容易就被 AI 淘汰的工种了。想起来其实也很容易理解,编码,说到底和英语或者任何其他人类语言的 “翻译” 到底有多大区别?可能区别也不过是,交流的对象从活生生的人变成了冷冰冰的机器,还是需要语义、语法,还是需要语言逻辑。如果从这样的角度来看,似乎 “编码员”(coder)可替代性真的太高了。
再深入一步,是用的更为广泛的 “程序员”(programmer)。这意味着,再代码的基础上,程序员设计逻辑、算法,从而把一个具体问题实现为程序代码。程序员也会关心程序员生命周期的其他活动,比如 bug 修改、feature 添加等等,但是核心依然是代码。程序员似乎比编码员好一点,但是 AI 的可替代性依然很高。
再来,就是软件工程师。我认为软件工程师是一群能够利用一定系统和规范的方法,来把软件工程化的专业人员。这就意味着他们解决的问题是实际世界的问题,需要把问题抽象成为软件可解的问题,以工程的方式实现,并且维护整个软件生命周期。
渐渐地,整个行业会有更加成熟的方法来知道 AI 实现需求,但是软件工程师依然会需要 “亲自阅卷”,他们也许会大大减少亲自实现的代码量,但会花更多时间评审 AI 的代码实现,寻找其中的问题,评估其中的风险等等。在整个软件工程流程上,也需要分析和思考用户的需求,敲定大体的方案,把大块复杂的任务拆分成小块的任务,交给 AI 来实现等等。总而言之,AI 成为了助手,或者是团队中的 “初级程序员”。传统观念上软件工程师的核心能力有了些许区别,比如说,如何提问 AI 的表述能力会被放到更加重要的位置。
这么看来,“初级软件工程师” 似乎非常容易被替代。比如说,初级软件工程师,经常会拿到设计方案,然后去实现。这在如今的互联网大厂是常态,大的 feature 或者系统,不太会完全丢给一个没什么经验的新兵来实现,这样的角色确实是比较容易被 AI 替代的。可是,成长是要有过程的,如果这个阶段不给足时间,那么初级软件工程师就不能成长为高级软件工程师,如果 AI 替代了这个阶段,势必会造成人才的断层。从长远来看,这才是让我最为忧心的。
如果我们仔细思考 AI 的擅长与不擅长,AI 目前还是有很大的局限性的。比方说,AI 还是更适合做具体的、明确的工作,对于一个复杂系统,对于用户的痛点感知,还是需要软件工程师开动大脑来分析思考,基本上这种活动都需要比较长的时间和比较丰富的积累。再有一个,AI 现在的两大问题,一个是 hallucination,就是 “一本正经说瞎话”;另一个是 sycophancy,就是在一些决策上面没有啥 backbone,很容易倒向谄媚的一侧。我可以想象,几年以后,AI 做更多的执行和辅助,然后把信息提炼、分析以后交给软件工程师,而软件工程师会做更多的思考和决策,并为结果负责。
我们还在这个时代变革的开头,这些观念只能说是目前的思考,两三年之后,它们还有效吗,我可以说完全没有什么信心。不过我确定的是,我们不能回避,要拥抱这个时代;既然选择了这一行,就要尽量保持开放,去倾听和接触新鲜事物,持续学习,那种抱着自认为 “经得起考验” 的过往成功的经验不放的自称 “老派” 的家伙,可能会吃大亏。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
2026-02-01 13:22:59
 打算把我相对能看得懂的公司商业模式捋一遍,今次讲讲迪士尼。老规矩,内容都是来着我自己这个老股东的理解,从开始建仓到现在,核心仓位拿了很多年了,也是我较大仓位长持的公司中整体回报率最低的一家。我一直奉行只买自己熟悉和(相对能)看得懂的公司这样一个基本原则,因此职业的关系手里大部分持仓都是科技股,像迪士尼这样的公司显得比较另类。
打算把我相对能看得懂的公司商业模式捋一遍,今次讲讲迪士尼。老规矩,内容都是来着我自己这个老股东的理解,从开始建仓到现在,核心仓位拿了很多年了,也是我较大仓位长持的公司中整体回报率最低的一家。我一直奉行只买自己熟悉和(相对能)看得懂的公司这样一个基本原则,因此职业的关系手里大部分持仓都是科技股,像迪士尼这样的公司显得比较另类。
迪士尼是一家传统媒体公司,核心就是内容创作和内容分发,不过和它的竞争对手比起来,它也是向科技激进转型(并且挣扎的)的 “新媒体”。如果说传统媒体有 Comcast 或者 Paramount,纯粹的新媒体像是 Netflix,那么迪士尼就好像是夹在中间。
就像之前分析阿里巴巴这艘商业巨轮一样,要去理解迪士尼的商业模式,可以从这样三个部分来分别审视:
迪士尼大概是地球上护城河最宽的非必须消费类公司之一,它的乐园、游轮,还有流媒体,都是护城河,但是一切护城河的核心在于 IP。所有的乐园、游轮、电影、商品,全都是围绕 IP 来运作的,没有 IP,就没有百年迪士尼。
比方说,现在有环球影城这样的主题乐园,发展很快,但是它们始终没法威胁到迪士尼的乐园。原因很简单,因为其它的主题乐园它们再豪华,也不是迪士尼认证的,没有迪士尼那些孩子们心中卡通人物的乐园。你也可以建造最刺激的过山车,但是它肯定不是星球大战过山车,也肯定不是冰雪奇缘过山车。你还可以生产便宜的玩具,但它肯定不是正版的米奇和他的朋友们,也不会是钢铁侠、绿巨人,或者朱迪或者尼克。所以,一句话,IP 就是护城河,IP 就是溢价。
从这个角度来说,IP 的推广,占据用户心智,才是迪士尼的根基。这也是我后来慢慢理解为什么迪士尼要自己做流媒体,砸钱做,即便一年一年亏钱还要继续砸。这里并不是一个简单的自己做流媒体远期能够提高利润率等方面的问题,这是一个生死存亡的问题。如果继续使用 Netflix 的平台,那么哪一天 Netflix 决定掐住迪士尼的喉咙,不让电视上继续播放迪士尼的的卡通形象,这些 IP 不能深入新一代孩子们的内心,无论这个过程有多缓慢,那最终迪士尼的这个经典的盈利的飞轮就彻底转不起来了。
前面说的体验部分和娱乐部分,基本都是围绕着迪士尼那些著名 IP 展开的,这是迪士尼最根基的商业模式。在此之上,也能看到一些其它次要一点的护城河,比如乐园、游轮也好,度假区也罢,都具备一个完整的消费环境,衣食住行,全部都在这个密闭的环境里面完成,结果就是,请把美好回忆带走,但务必把钱留下,这也是它第二重要的商业模式。通常来说,我是不太喜欢重资产的商业模式的,不过它的商业模式和护城河太经典和强悍了,我觉得可以为迪士尼开一个例外。
不过迪士尼的体育板块,还是和上面的略有区别,它的护城河主要是长期锁定的直播权。这部分逻辑上比较简单,并且是租来的,成本肯定没有完全自有的护城河那么可控,也没有那么强悍。
先说娱乐版图,它包含传统电视、流媒体和占比较小的内容销售。传统电视已经基本上是夕阳产业,现在在娱乐部分依然是贡献大头的利润,但是这部分没有成长性,逐渐萎缩。流媒体是 “转型的主力” 和 “全村的希望”,其实也可以说是刚刚转盈利,但是毕竟开始赚钱了,希望它是一个真正的困境反转。
流媒体伴随着盈利逐渐改善,有一个变化,就是不再纠结于用户数量的提升,而是通过涨价提升 ARPU 和增加广告收入。市场是很乐于看到涨价的,涨价也说明了用户粘性和护城河。
接着是体验版图,这有点像是阿里巴巴的传统电商部分,营收最高并且利润率低于娱乐部分,但能够不断提供源源不断的现金流来发展新业务(特别是前几年持续支持流媒体烧钱)。
美国的本土乐园其实保持低速增长就不错,但是国际乐园还是有很大的空间。只要没有疫情这样的黑天鹅,游轮业务也能逐渐缓慢扩张。总之,这部分通常比较稳定,这部分也是较重的资产和员工人数的主要来源。
最后是体育版图,ESPN 是盈利的,但是面临体育版权费越来越贵的压力。从内容上看,Hulu 和 ESPN 最初似乎都和 Disney 的背景格格不入,但是这是迪士尼扩展用户群的一着棋。ESPN 曾经是非常赚钱的,包括联盟费和广告费等等,但是现在因为有线电视的衰退,这部分有点往鸡肋方向靠拢。然而,无论利润率如何,ESPN 有它的战略地位,ESPN 是 Disney 和 Netflix 竞争的重要筹码。
和很多巨头不一样的是,从 2015 年到现在(2026 年),差不多十年了,迪士尼的股价一直在一个范围内波动,没能获得突破。这挺让人感慨,然而看似卡住的股价背后,发生了天翻地覆的变化。这个转身对于如此传统的一家媒体巨头来说,实属不易。这让我想起了微软 Office 上云的商业模式迁移。
首先,710 亿天价收购 Fox,主要目的是扩充 IP 库。Fox 收购是伤筋动骨的(别忘了当时的净利润只有 120 多亿),为此背负了巨额债务。但是老 Bob(Bob Iger)还真的是既有眼光,又有魄力,如果没有这笔收购,没有内容怎么做流媒体,只有那米老鼠和漫威等等几十部电影。而且除了内容,还拿到了 Hulu 的控制权,这不但从儿童动画拓展到成人剧集,而且技术和运营上它的经验对于做 Disney+是很有帮助的。这笔收购的战略意义太过重大,要是没有 Fox 收购,就没有今天的阿凡达,就没有 X 战警,也没有辛普森和冰河世纪;要是没有 Fox 收购,迪士尼就没法做流媒体,IP 和品牌就会慢慢衰落,前面已经说到了。看看 Paramount,它也是传统媒体,也有海绵宝宝和 Paw Patrol 之类的一堆 IP,但是现在呢,被 Oracle CEO 拉里埃里森的儿子收购和合并。所以,从今天的角度看,这把操作代价是巨大的,但是整体看来还是正确而重要的一步。
然后就是做 Disney+烧钱,跟 Netflix 正面刚。就像一个退休了的老头重新出山来和年轻人在科技领域竞争,学习怎么玩互联网,很不容易,直到现在也谈不上 “擅长”——现在 Netflix 的利润率接近三成,而 Disney+只有个位数。但是因为传统的电视领域的衰落,这是它没有退路的一步棋。从这个角度看,百年老店迪士尼还是非常值得尊敬的,我相信大多数企业都抗不过这个时代的变革。
之后再加上疫情的打击(这类非必须消费而且是重资产,疫情打击是非常大的),分红被迫暂停,股本也一路膨胀,一直到 2023 年结束。之后因为财务状况改善,才慢慢通过回购好起来,现在大致还算处于一个变革期,但是从回购恢复和分红增长来看,最艰难的时间可能已经过去了。
如今,市场关心 Bob Iger 二次出山之后,他需要再次隐退,那谁来接班呢?这可能是短期内迪士尼最大的风险,想起之前 CEO Bob Chapek 被认为把财务放在艺术和传统之上,得了大罪,于是 Bob Iger 被迫重新出山。其次,是袭来的 AI 革命,对于传统动画制作门槛的降低,那么多不确定性都等待尘埃落定。再一个,就和很多重资产的经营一样,这一类生意的脆弱性——疫情也好,衰退也好,一旦出现,它就会受到直接的打击。
再来说说和 Netflix 的竞争,市场迫切希望看到 Disney+能将迪士尼的增长带出来。在我看来,如果要去和 Netflix 拼内容宽度,是没有胜算的。Netflix 在流媒体这块的统治力太足了,无论是内容库的丰富程度还是技术的成熟度,都是迪士尼无法望其项背的。
那么,迪士尼还是要靠自己的 IP,也许用户量没法和 Netflix 比,但是用户心智对于 IP 的深度要培养起来。如果流媒体搞成功了,迪士尼的未来可以打八十分往上,但是如果没搞成功呢?也未必是世界末日,如果我们换个角度思考,和流媒体起着生死攸关作用的 Netflix 不同,对于迪士尼来说,或许流媒体未必非得要有多少盈利,它完全可以只扮演一个 “药引子”——流媒体本身只是渠道,用户看了 Netflix 的动画,整个消费场景就结束了;而用户看了迪士尼的动画,消费场景才刚刚开始,之后他会去乐园、去游轮,去买周边等等。
最后,在这个竞争上,迪士尼还有一个优势,就是 Disney+的动画、Hulu 的神剧和 ESPN 的体育直播捆绑起来的优势,这里面有很多 Netflix 完全没法竞争的内容。
我们在比护城河的时候,主要是在比商业模式。Netflix 呢,它虽然成长很快,但它只有单纯的流媒体和相应的内容,全球用户已经到 3.25 亿了,往上的空间不大,增长很快会遇到天花板(从它最近要收购华纳兄弟来看,也许管理层觉得这一天已经到来了)。因此把时间放长来看,除非它有了新的业务拓展曲线,否则我认为 Netflix 的护城河和 Disney 是完全没法比的。
总之,迪士尼是一家成熟,但在努力转型以根上时代的公司,成长性看起来没有很多互联网公司那么强,但是我还是相信它在这些经典 IP 上的积累,相信它的商业模式,也相信它能平安度过科技转型和困境反转的阶段,价值得到回归。百年迪士尼为我们童年带来过美好的回忆,我真心希望它可以再继续创造经典的角色,陪更多的孩子们度过童年。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
2026-01-26 13:18:29
 之前聊到过拼多多,今天聊一下阿里巴巴。阿里巴巴作为中概元老,很多人都讨论过,我只发表从我的角度浅显的看法。作为利益相关者,我持有阿里巴巴个股,且在中国科技相关的 ETF 和基金中的被动持有仓位。
之前聊到过拼多多,今天聊一下阿里巴巴。阿里巴巴作为中概元老,很多人都讨论过,我只发表从我的角度浅显的看法。作为利益相关者,我持有阿里巴巴个股,且在中国科技相关的 ETF 和基金中的被动持有仓位。
首先,要理解阿里巴巴,需要从它的五块构成来分别理解:
这是我对阿里最初的印象。中国是互联网电商发展最快的国家之一,阿里巴巴作为时代的开拓者,当然也吃到了其中的红利。不过,现在看起来要守住市场份额也开始烧钱了,一旦一家公司要在某个成熟的业务上大手笔地烧钱,我认为这可能就是一个极其危险的信号。凡是进行价格战的生意,基本都很难说是好生意,真正有护城河的生意,是不屑于降价的。
这个烧钱,说到底,主要是为了和拼多多抗衡,打出了百亿补贴的牌。但是阿里的降价不仅关乎到陡降的利润率,也打击了天猫上商户的品牌形象。到了去年,尤其是下半年,又开始大干特干即时零售。这种烧掉利润来稳住市场份额的行为,有点像是医疗上的激素冲击,是最 “简单粗暴” 的方式,却也终究是不可持续的。
其实我又想起了京东几年前的一波降价,之后股价就被打到地板上了,如今基本上作为一家重资产的 PE 在个位数的电商,可以作为烟蒂股了。说到底,那件事和如今阿里巴巴做的事情也没有什么本质区别,零售业就是一门苦生意。
张勇作为 CEO,战略上畏手畏脚,思维圈子也似乎跳不出一个 CFO 的局限,虽说没像百度一样把一副好牌完全打烂,却也做错了很多事情。比如一开始对下沉市场彻底放弃,后来再搞淘特,发现根本打不过拼多多;比如低效率的中台战略,让阿里巴巴变成了一家看起来有着严重大公司病的企业。
蔡崇信(董事会主席)和吴泳铭(CEO)的组合上任以后,情况终于有了转机,阿里终于从一大堆业务当中分清主次,只有两个核心业务:电子商务和云计算,其它都靠边站。阿里一直以来都为流量入口的事情烦恼,这两年它做对的一件事情就是接入微信支付。第二件就是它搞清楚了对它最大价值的人是谁(这是它和拼多多商业模式不一样的地方,我在分析拼多多的文章里面谈到过),是商家还是消费者,它选择没有跟风拼多多的 “仅退款” 跟到底,而是给高信用的商家一定的申诉通道。还有就是卖掉那些实体零售,利润率低,或者就是亏钱的重资产,像什么大润发和苏宁易购等等。这些都是这两年做对了的事情,虽说这些目前还没有从根本上改变电商基本盘的所处格局。
阿里云和 AI 基本就是阿里增长的最大希望,市场认可的估值弹性得有好大一部分是来自于它(差不多一半?)。这也是 2025 年阿里市值回弹比很多对手快得多的原因之一。如果没有这部分,阿里就基本是查理芒格说的 “该死的零售商” 而已了。
云计算在近年来增速加快的同时,盈利也终于在电商疲软的时候撑起了一片天。其实中国的云计算整体起步并不算晚,由于企业数字化和需求各异性太强等问题,盈利一直是一个问题。现在市场希望的是,阿里能像当年的 AWS 一样,把阿里云做成增长和利润的大头来源。
想起来移动互联网最火的时期,阿里云的增速是能够超过 50% 的,后来掉下来了,一方面是 TikTok 跑了,另一方面是在线教育等多个行业遭受寒冬,需求减少了。不过 2025 年以来,借助 AI 的东风,云计算增速重启(这部分差异全是 AI 带来的,传统云服务增速依然只有个位数)。但是这个趋势能够维持多久,就决定了从目前的角度看,阿里的估值能维持多久。这个答案对我而言是不确定的。相对来说,腾讯的估值倍数和阿里差不多,但是它的利润和增长,或者说到护城河,都要稳健得多。
阿里当年是差点要拆分阿里云出去单独上市的,如果真那么做了。如今的阿里云就要弱小得多,发展基本肯定不如现在,而阿里集团就会因为电商的侵蚀被打到地板上,那就可以说是双输的结果。还好,这一步险棋没有走出去。
说到 AI 模型,就要提到阿里的通义千问,它的 API 几乎要成为中国国内的标准了,我也看到它把阿里旗下的各个业务串起来的潜力。阿里卖模型 API 的时候,也就把模型本身和 AI 算力都一起卖出去了。阿里还有一件事做得很对,就是把模型开源,这样开发者使用了模型,会更愿意部署在阿里云上。
中国 AI 云市场接下去好几年年均增长都可以超过四成,阿里云既包括云基础设施,又包括模型服务,两个细分领域都是龙头,属于高增长板块中的龙头,也就难怪市场愿意给相对的高估值了。
要说这部分的风险,主要有两个方面。
一个是老生常谈的芯片卡脖子问题,但是这部分市场盯得紧,而且后果未必有想象得那么严重,可能高端芯片缺乏,较低端的芯片会降低计算效率。对于自研芯片,阿里的平头哥可能会独立融资,但是芯片不像电动车,商业地位上要产生实质性竞争力,需要走的路还远得很。
另一个是,现在属于烧钱抢市场阶段可以理解,但等 AI 大模型慢慢成熟以后,利润率到底还能不能保持高位是一个问题,或者说,到时 AI 大模型会不会又会变成零售一样,卷到天上去。现在的大模型属于百花齐放期,但是我认为这里的护城河没有很多人想象得宽,就像大多数领域一样,最后只能剩下几家大的玩家,并且很可能大部分钱都会被最大的一家赚走。总之,届时对于大多数用户来说,不同大模型的质量差异也可能并不大,那种情况下鉴于可替代性,利润率就不可能挺得住。
2025 年经历了一波大甩卖,无底洞都摆脱了,剩下的都还是比较不错的业务。阿里出海基本上 breakeven 了,结合菜鸟物流,阿里速卖通就能够用配送时间去和 Temu 竞争。电商出海的营收规模接近阿里云,从营收看,淘宝、天猫是阿里的身体,那阿里云和电商出海就是走路的两条腿。
对于其他业务,除去菜鸟,大部分还是亏损的。2025 年大卖特卖的也都是这部分的业务。
再说投资,阿里之前的投资水准实在不能算好。不过,阿里在蔡、吴二人上任后卖掉了很多移动互联网时期开始投资的股权,一种是战略关联性低的业务,比如小鹏汽车、B 站和快狗打车等等;另一种是重资产业务,比如大润发和苏宁易购等等。并且,很多卖出都是止损而非止盈,这些为了打云计算和 AI 的战役筹备了弹药。看起来撑面子的营收规模下降了,但这让阿里聚焦核心业务,变得更加轻资产,最实质的利润率却是提升的。
现在阿里主要的投资,首先是蚂蚁集团,不知道什么时候还能再上市,但是目前盈利能力不容置疑,大概是这里面最值钱的资产。其它投资还包括中国国内 AI 的独角兽们,几大物流公司,还有媒体领域的微博,基本上都是具备战略地位的。阿里对投资人的回报也在改进。阿里开始提供一定的分红,并且大量回购,把自己定位为一个开始偏向成熟的企业。
总体来看,阿里的投资,从张勇时代的重资产,开始逐渐转向新时代的轻资产和科技。从过往张勇时期的记录来看,看看腾讯的投资能力,比一比就能发现,阿里差远了。有句话叫做 “腾讯投资是把半条命交给合作伙伴,而阿里巴巴则是想要对方的整条命”。腾讯投资给对方资金和流量(京东、美团、拼多多,还有无数游戏公司),而阿里则是把对方买回来阿里化(饿了么、优酷、土豆等),全部融入进来管,结果还往往管不好。
基本上,中国的企业当中,大概阿里巴巴就是能看懂一些的少数几家之一。它最初的牌兴许比腾讯还好,但是后来打烂了,但是又没有像百度那样彻底烂掉。如今的它还是给了市场很多正面的回馈,不过,现在这个价格,我认为确定性是要低于腾讯的。
我认为阿里的电商护城河还将继续持续被侵蚀,而 AI 对于阿里就相当于 “全村的希望”,这基本是阿里最大的希望,如果 AI 能够做成,它会是一笔很好的投资,但是风险上看,显然是高于腾讯的。我目前还继续持有阿里巴巴的仓位,但是 conviction 没有那么强烈,因此仓位也不很大。如今考虑进去地缘政治因素,阿里巴巴已经不再严重低估,但也不能算有多贵,但是我更关心的是我操作上的逻辑,只要哪天我确认阿里云的增速下来了,或者 AI 并没有预期的那么强大,我清仓个股的逻辑就会确立。在当前的价格,如果未来我找到优质得多的标的,我也许也会换出去。当然,我依然相信中国的科技,依然会持有中国科技的基金和 ETF,这部分中阿里巴巴的被动持有会依然存在。
阿里巴巴记录了中国科技一个又一个时代,从电子商务到云再到 AI,衷心希望阿里巴巴能够巨人苏醒,王者归来。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》