2026-05-30 16:05:33
御温泉早在大学的时候就想去,但是那时候一来钱包不支持,二来当时也还没有接送车。现在呢,失业了有时间,去一次御温泉的钱还是有的,故意选了工作日,又便宜几百块,订了长盛庄,价格 1746。
而且现在有接送车,到了珠海站就能免费送到御温泉。不过还需要一个小时,也是舟车劳顿。

上次去珠海站还是疫情刚开放去澳门考托福,回想起来也是很感慨,但是此事当时也没有单独成文,只在2022 年终总结略有记载,其实当时也拍了不少照片,有点遗憾。
到站了想吃点东西,发现隔壁虽然似乎有一个独立于车站的商场,但实际上很多店铺的价格都是按车站的物价收费,考虑到晚上就要吃大餐了,干脆就在喜士多整个饭团撑过这一小段时间好了。

从广州到珠海站再到御温泉,经过一顿操作,到达时已经下午三点多,中午没吃饱立即在入住的时候薅了两个小蛋糕。因为周一人少,还给升级了房型,单床变双床,好评。这个时候我还有些担心人这么少,庙会没气氛咋办哦,不过很快事实就会证明这是无谓的担心。


初见这个复式房型,十分惊喜。整体感觉是日式的,很舒服的木构造,但是设计一点都不日式。一层一个榻榻米加一大片地板,只有两张懒人沙发,这样的设计,让两个人入住,实在有点寂寞了。要是四个人在这打桌游,看电影,枕头大战(误),那得多青春。这里真的好符合二次元对合宿的憧憬。


美中不足的是,这电视也真的太小了。投屏看个 B 站都觉得不够爽,从懒人沙发到这台电视的距离,感觉就像看个比较大的平板而已。

然后复式的二层是左右两个梯子直达床铺。这是升房型的结果,本来便宜的房型只有一个床位。床铺就是简单的一个软垫加一张被子,睡起来有点硬,但问题也不大。

房间就是这么个情况,稍微葛优躺在懒人沙发上刷了一下 B 站就去踩单车了。订房送了个单车票,不踩白不踩,但是去到踩完了,感觉还真像白踩,也没多少地方能踩。结果就是踩了个可能十来分钟吧,就回到原位了。
(废话文学,且此处忘记拍照。)
路过可以见到阿驴和阿牛,不过为什么要把牛和驴放在温泉景区,也是成谜。


单车之后,就是温泉部分了。

我们刚好住长盛庄 2 层,能直通长盛庄的温泉,十分方便。到了长盛庄的温泉区,基本没有人。走到主温泉区也还有一段路,那边人也不算多,不过一个小池两三个人,大池人与人之间的距离也很舒适,人少体验还是不错的。
另外温泉里面除了茶水,也有一些小甜品和雪糕,体验还是非常不错的。

接着就是激动人心的庙会,开场没多久就进去了,人就已经不少,也是挺奇怪的,在温泉明明看不到人呢,都是从哪里冒出来的呀,难道有人开车来专门吃自助餐?不过!有人气总是好的!
不得不说,庙会真的非常非常大。周一人不少有的厅还是稍空,真是不能想象寒暑假这里挤满人是个什么情况。


上图这么大的区域至少有 5 个,虽然有的摊位品类会有点重复,不过也是完全尝不完的程度。

庙会可以无限进出这个设定真的太棒了。吃一半吃撑了,回宿舍休息了一下,下去继续吃,吃到 10 点庙会结束。
但是即使如此,吃这个庙会,真的有一种前所未有的亏本感。以前吃自助餐觉得亏是单纯的觉得量没上去,而这个庙会东西真的太多了,五六条街数十个摊位,根本是想做到每一款想吃的都尝一遍都做不到……不过我的胃也确实是不争气的小就是了。而且菌菌又到吃自助的时候病了,真是小可怜菌。
到最后,把兑换券的燕窝和雪糕吃掉,然后喝杯草茶,玩玩游戏,时间就差不多了。


小可怜菌咳嗽了自己调个茶缓解一下:


然后庙会的游戏嘛,没有必要为了攒兑换券功利地去玩,因为最后都是会输光的哈哈,快乐过便好了。
庙会兑换区的饰品可以看出其成分极其复杂……
好几代的偶像大师 ↓

认全了就是老二次元的老角色 ↓

哎呀,尤其是这一桌,可可爱爱,看得心都化了~ 娜娜奇 Mua(づ ̄3 ̄)づ╭❤~

庙会出来,看到这个小庭院是怪好看的,好多小妹妹在拍照。可惜啊,年纪大了,放弃出片了。

不论整个景区、房间的风格,包括庙会这个设计,整体风格都是日式的,但是近来中日关系恶化导致的一种谜之混合风格,这也算是这趟旅行的一个槽点。

最后去换仙女棒,也是毫无准备,无法出片,随便拍拍。

再回宿舍已经快十一点了吧。这一路下来真的非常忙,要是还年轻的话,或许还能通个宵吧,温泉好像是 24 小时的,但是老了,不服老真的不行,而且我睡眠还分崩离析,再不躺下,我又要心跳漏一拍了。
就是这样,御温泉的一天,明明好像还有很多事没做,但是一天就这么结束了。
第二天不算早地起来去了一趟温泉,受到一种觉得泡一次也太亏了的心理驱使……
泡完就去吃早餐,其实挺好吃的,品类也不少。但是因为睡不好+一大早温泉消耗,吃两口碳水就晕了,一边吃一边想睡觉😂

吃完了再回宿舍睡了一小时,真的可以走了。

走了走了,再见御温泉,旅程结束啦。
这趟旅程整体体验还是很满意的,但是总是有种中登的疲态……
欲买桂花同载酒,终不似,少年游。
终于轮到我说这句话了。
临走前看到御温泉候车区的书架上还有这种书,刺伤了本失业者的神经🤣。

多年没见的珠海渔女,小学的时候老爸在珠海工作好像去过一次,应该是故地重游了。可惜因为天色原因不够好看。

这个色调让我想起多年前公司旅游那个雨天厦门……那段傻事仍然尘封在 Obsidian 里还没发出来,想起来就有点哀伤……
大概就写这么多吧……看标题可知这已经是 4 月 19 日的旅行,拖到 5 月 30 日发,中间不能说摸鱼,只能说混合着纠结与忙个不停……不过终于发出来了,恭喜自己。
然后,在这个满是 AI 的互联网上,又多了一篇手写流水账。
2026-04-10 16:19:37
昨天终于心一横开了苹果开发者,一大早开了,想着我要一天搞定上架提交!然而,钱是付了,等到晚上九点多,才成功开通。好嘛,那第二天再努力吧,带着兴奋入睡,第二天一早起来开干。
事实是我把这想得太简单,出了舒适区,就真的想踏入泥沼一样寸步难行。搞了大半天才终于把不用上架的版本签好,晚上之前也把 pkg 打出来了。不容易啊!
下面讲讲一些值得注意的点吧。如果你也打算入坑 Tauri 开发,而且打算构建 macOS 应用或者 iOS 应用,记得收藏,以后会用到的。
你先得搞清楚,CSR、CER、P12 这些概念分别是啥,不然肯定被 N 个证书搞得晕头转向。
在数字证书和公钥基础设施(PKI)领域,这三个缩写分别代表了证书申请、证书本身以及证书存储的不同阶段和格式。 简单来说,它们的关系可以看作是一个从申请到签发再到打包的过程。
本质:申请表
当你需要一个正式的 SSL/TLS 证书时,你首先要在服务器上生成一对密钥(私钥和公钥)。CSR 就是由你的公钥和一些身份信息(如域名、公司名称、国家等)组成的请求文件。
本质:正式证件
CA 收到你的 CSR 并核实身份后,会用他们的私钥对你的信息进行签名,生成一个证书文件,通常后缀是 .cer 或 .crt。
本质:全家桶安装包
.p12 是一种二进制格式的容器,它可以把私钥、公钥(CER)以及中间证书链全部打包在一个文件里,并且通常由密码保护。
在解决了证书本质上区别之后,你还要搞清楚苹果自己的 N 种证书。Developer ID Application 用于不上架的分发,上架还要用到 Distribution 和 Mac Installer Distribution 两个证书。
机子里证书有两个,一个 Apple Development,一个 Developer ID Application,不小心把证书导错了一次,排查又卡住。
其次 Tauri 一定程度上有点黑盒,加上对苹果应用开发不熟悉,从 Tauri 那不算太完整的文档里逐步实现签名。而且关键是这些信息还散落在 macOS Application Bundle、macOS Code Signing、App Store 三个页面。
为了理清这三个页面的内容,又得把一堆苹果开发流程中的重要概念搞清楚。
它是一组 key-value 对(权利字典),告诉操作系统“这个 App 允许使用哪些特殊能力”。例如:访问 iCloud、HomeKit、推送通知、相机、App Sandbox 等。这些权利会嵌入到 App 的二进制代码签名里。
iOS / macOS 上架时必须正确声明;Xcode 会自动生成 .entitlements 文件,签名时合并进去。
Notarization 翻译过来就是做公证。你把已签名的 macOS App 上传给苹果,它会扫描恶意代码、检查签名问题。
扫描通过后,苹果给你的 App 发一个“公证票据”(ticket),你可以把它“钉”(staple)到 App 上。macOS Gatekeeper(门卫)看到有公证票据,就会放心让用户运行,而不会弹出应用损坏的错误。
使用 Developer ID 证书在 App Store 外分发的 macOS App 必须公证。
一个由苹果服务器签名的 .mobileprovision / .provisionprofile 文件,里面包含:
上架必须,非上架不需要。
在搞清楚上面的概念之后就大概能明白了,Tauri 的构建配置必须分两种。
之前的一个卡点是,签名成功了也公证了,结果反而打不开,签名之前还能用 xattr -cr,现在用了都不行。
{
// ...
"macOS": {
"entitlements": "./entitlements.plist",
"signingIdentity": "Developer ID Application: XXX"
}
// ...
}
问了一轮 AI 以为是不知道什么原因导致的 entitlements 没写进去。但是后来又发现即使通过 codesign --force --deep --options runtime 手动把 entitlements 写进去了,依然打不开。
最后才恍然大悟,Tauri 文档上写的分开 tauri.appstore.conf 文件的必要性……
实际上打包非上架包的时候应该把 entitlements 删掉,这样反倒是打出来的包可以正常运行。于是!Mind Elixir v1.7.0 终于不用绕过安全策略,支持直接运行啦!
然后发布 App Store 的版本我们外加一个配置文件 tauri.appstore.conf.json:
{
"bundle": {
"macOS": {
"entitlements": "./entitlements.plist",
"signingIdentity": "Apple Distribution: Dexter Chow (9J69XMW5FC)",
"files": {
"embedded.provisionprofile": "./provisioning/MindElixirMac.provisionprofile"
}
}
}
}
构建时运行:
pnpm tauri build --config src-tauri/tauri.appstore.conf.json --target universal-apple-darwin
App Store 版本不需要公正,跑公正只会提示你需要用 Developer ID Application 证书。因此我们需要把环境变量里公正用到的值清空,这样 Tauri 就不会自动公正了。
pnpm tauri build 之后拿到了 .app,接着还要用 pkgbuild 打包成 pkg。
这两步就用到了上面提到的两个证书:
最后使用 Transporter 上传 pkg 包(开了虚拟网卡 Transporter 传不了),注意打包兼容 Intel 芯片的 universal 包,如果不想兼容 Intel 芯片,系统要限定在 12.0 以上。
我真的不敢想象没 AI 我看这些文档要看到何年何月。但是做好了,又觉得其实没那么难。所以确实,一件事做到过和没做到过就是完全不一样。没做到过你会怀疑每一个细节有问题,脑子炸炸的,做到了你就知道大致什么是没问题的。后续再处理问题就简单多了。
2026-03-12 18:43:14
失业之后多次想写点东西,也确实写了,不过都是零散地写在 Obsidian 里面,时间过了,又暂时不想整理发到博客。于是今天还是直接在博客写吧,最近的非日常生活。
2026-02-17
初二被 CC 邀请去他家烧烤,一扫除夕初一的无聊。工具食材都到位了,结果生火生了好久都生饿了。

山姆的羊扒真香嘻嘻!

从天亮吃到天黑,要是我找不到工作,要不要落魄前端在线烧烤呢(

最后摸摸 CC 的猫,乖乖的好猫~
2026-02-28
迫于准备结婚,过完年 2 月底,把送礼的任务完成,又解决一件事。结婚真花钱呀。

2026-03-11
快要领证了,在领导强烈建议下去修脸,换一个更好懂的词,那就是美容。第一次修脸,感觉还不错。
这是直接在大众点评搜的一家店,在石围塘地铁站附近,就地理位置来说比较偏僻,但是因为也住得偏僻,所以一拍即合了。
店的评分很高,可能因为位置比较偏,价格跟同类相比也算实惠,一百多的套餐,服务还挺多的,躺了一个多小时顺便当休息了。按摩挺舒服的最后一步都快睡着了🥱。洁面和剃须的步骤有点小痛不过第二天没什么问题,摸着是挺滑的。
2026-03-12
之前看到工行有羊毛,换一千外汇送积分和微信立减金,于是换了些港币,今天去取。
发现了一个问题,储蓄卡过期了不能在柜台取钱。我倒是知道卡过期了,但是提示只写着过期后 ATM 不能取钱,没想到柜台也不能取。
这一刻,我终于记起来了,ATM 的全称是自动柜员机,柜员机不行,所以柜员也不行(狗头)。
那怎么办呢,就换卡呗,然后被告知工本费 20 元。绝了,宇宙行是我见过第一家办储蓄卡还收工本费的银行。贵行开成宇宙行的资金,就是从这里薅来的吧?
换卡取钱,完事之后我突然想起来,噢,我旧卡还能拿回来吗?被告知不行,已经被剪了,而且不能拿回来。我知道这个需求也是比较怪,但那好歹也是大学交学费的卡,跟了我十几年,它就这样被砍头了,尸骨都不能交由我处理它后事,有点伤感。
2026-03-10 13:42:32
最近新鲜出炉的一个 Obsidian 插件 mindelixir-mindmap:https://github.com/SSShooter/obsidian-mindmap
主要有两个功能:
mindelixir-mindmap 可以根据标题和列表的层级关系把 markdown 文件转换为思维导图。
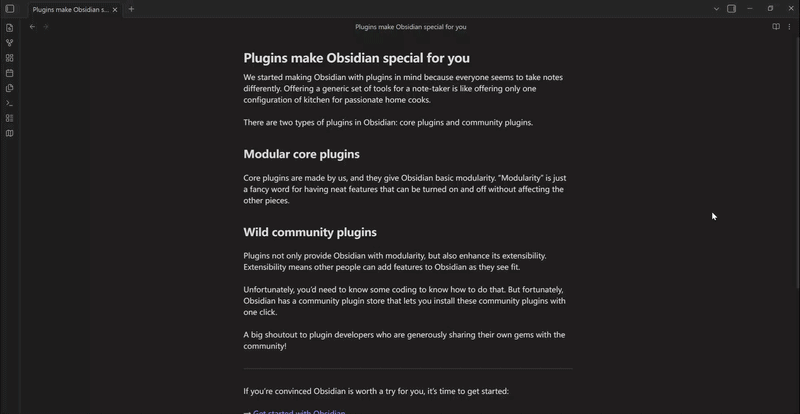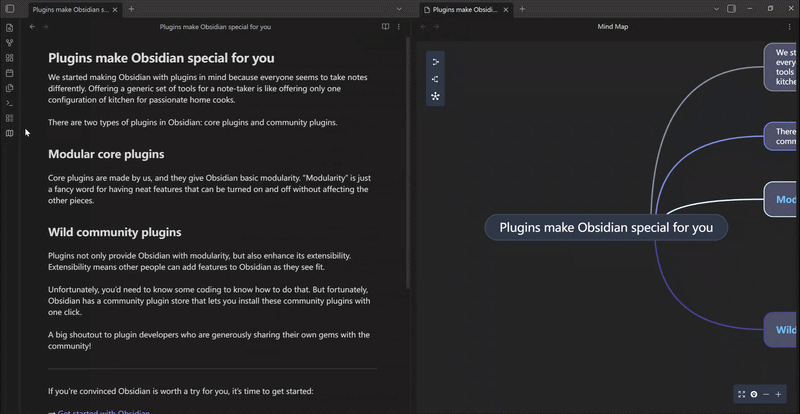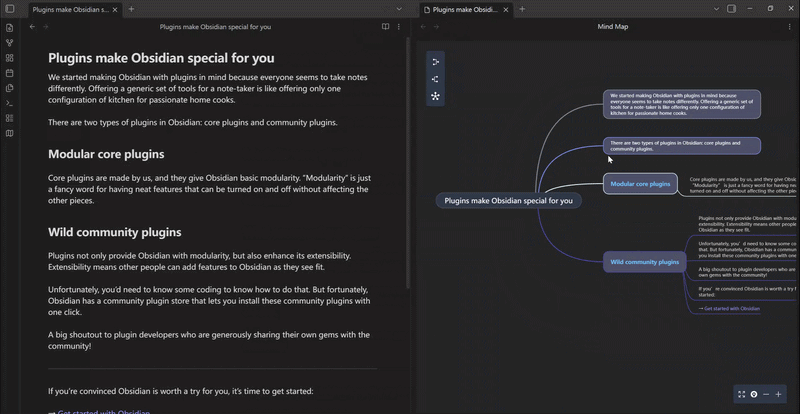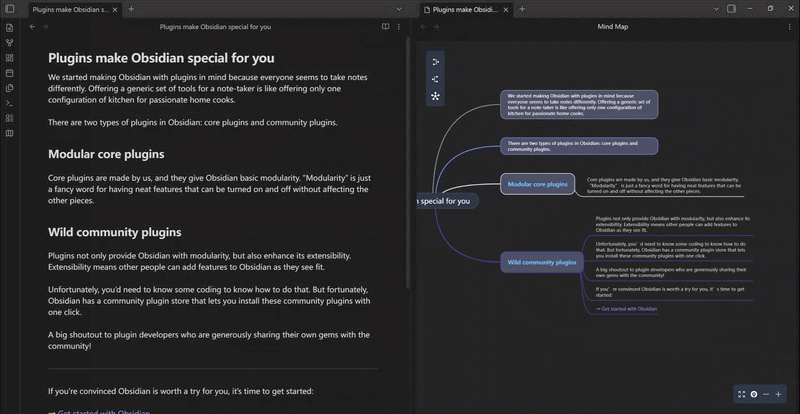
Mind Elixir Plaintext 是一种类似 markdown 嵌套列表的格式,不过加上了连线、总结和样式的语法。
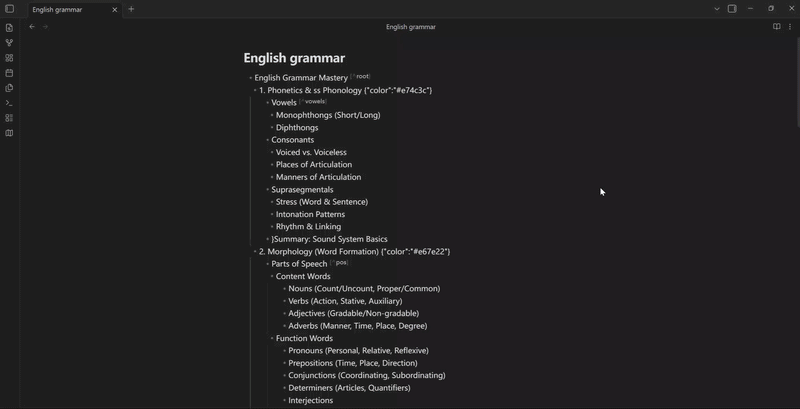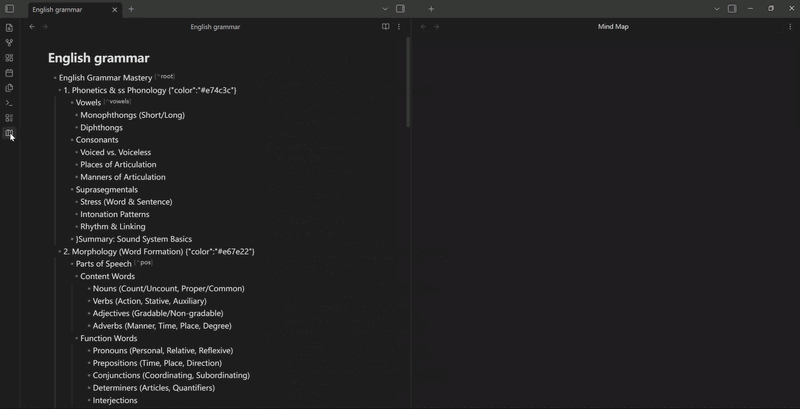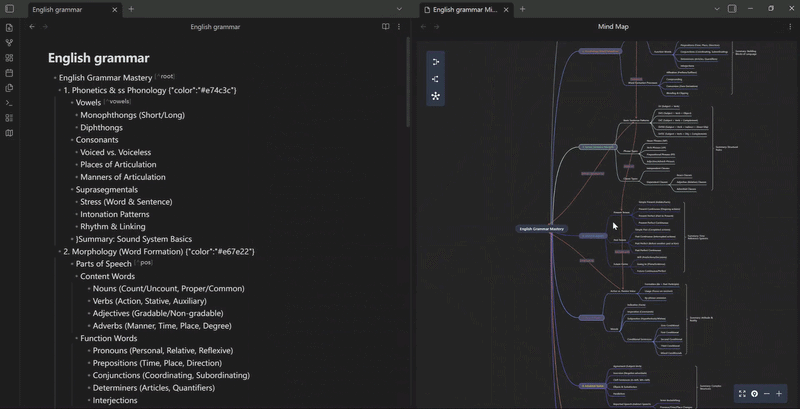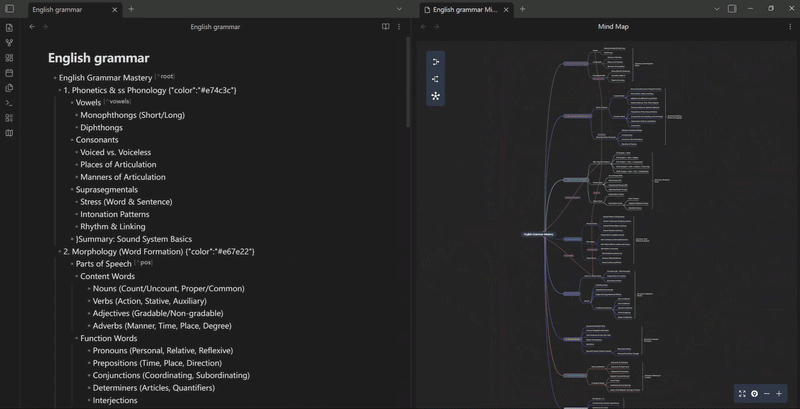
你可以通过简单的缩进、ID 引用和类似于 JSON 的尾部声明,快速在文本里构建复杂的思维导图结构。同时,这种结构 AI 生成起来也非常方便。
- 产品研发流程
- 调研阶段 [^research]
- 用户访谈 {"color": "#3298db"}
- 竞品分析 {"color": "#3298db"}
- }:2 调研总结
- 开发阶段 [^dev]
- 架构设计 {"color": "#2ecc71"}
- 前后端联调 {"color": "#f39c12"}
- } 开发总结
- > [^research] >-进入-> [^dev]
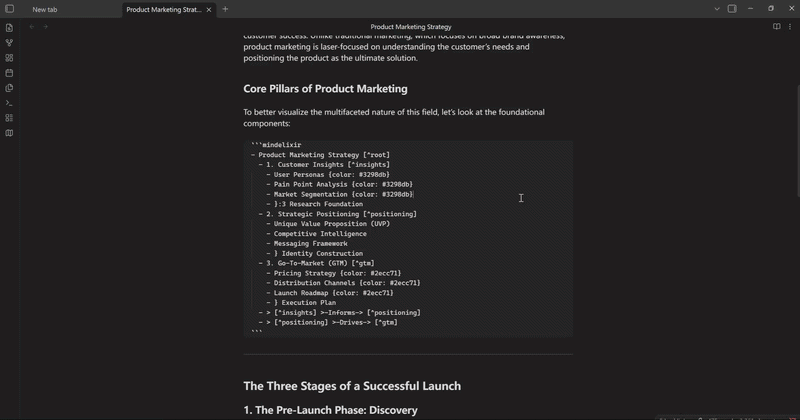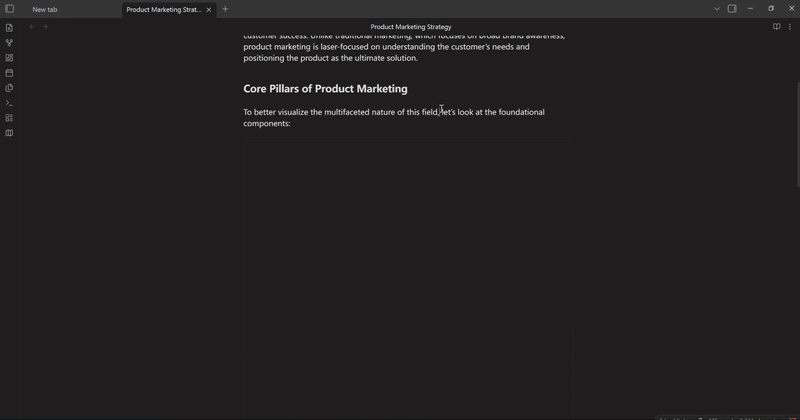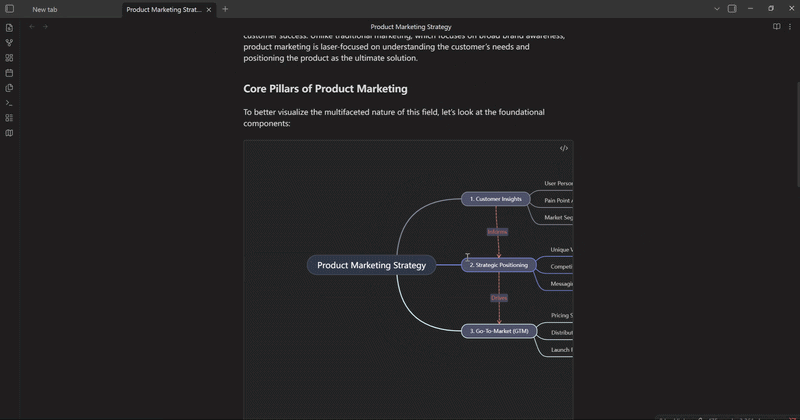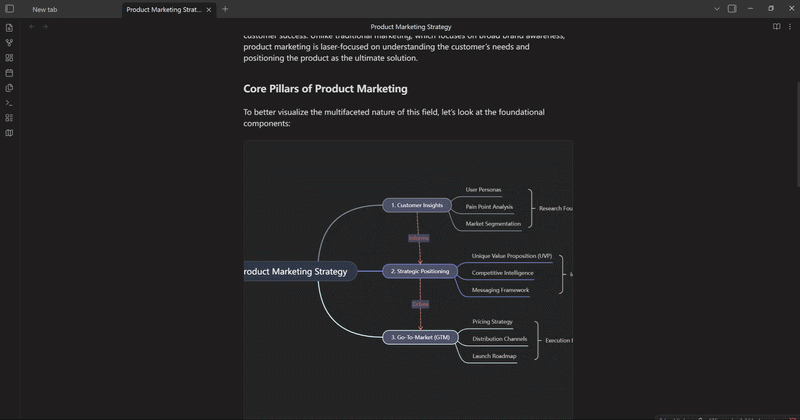
Mind Elixir Plaintext 同样也可以作为代码块嵌入到现有的文章中,顺便看看移动端的显示效果:

普通 markdown 只能通过编辑文本更新思维导图,针对 Mind Elixir Plaintext 文本,现在正在开发编辑思维导图反向更新文本的功能。
尽管已经提交了官方插件列表的 PR,但是现在 AI 时代随手出插件,前面一千个 PR 排着队……我估计维护团队都要放弃审批第三方插件了。
所以呢,下面推荐两种非官方安装方式。
BRAT 是一个已上架的 Obsidian 插件,本意是可以让你更方便地测试你的插件。但是实际上你完全可以用这个插件来安装生产级的插件。
在社区插件列表搜索 BRAT 安装:
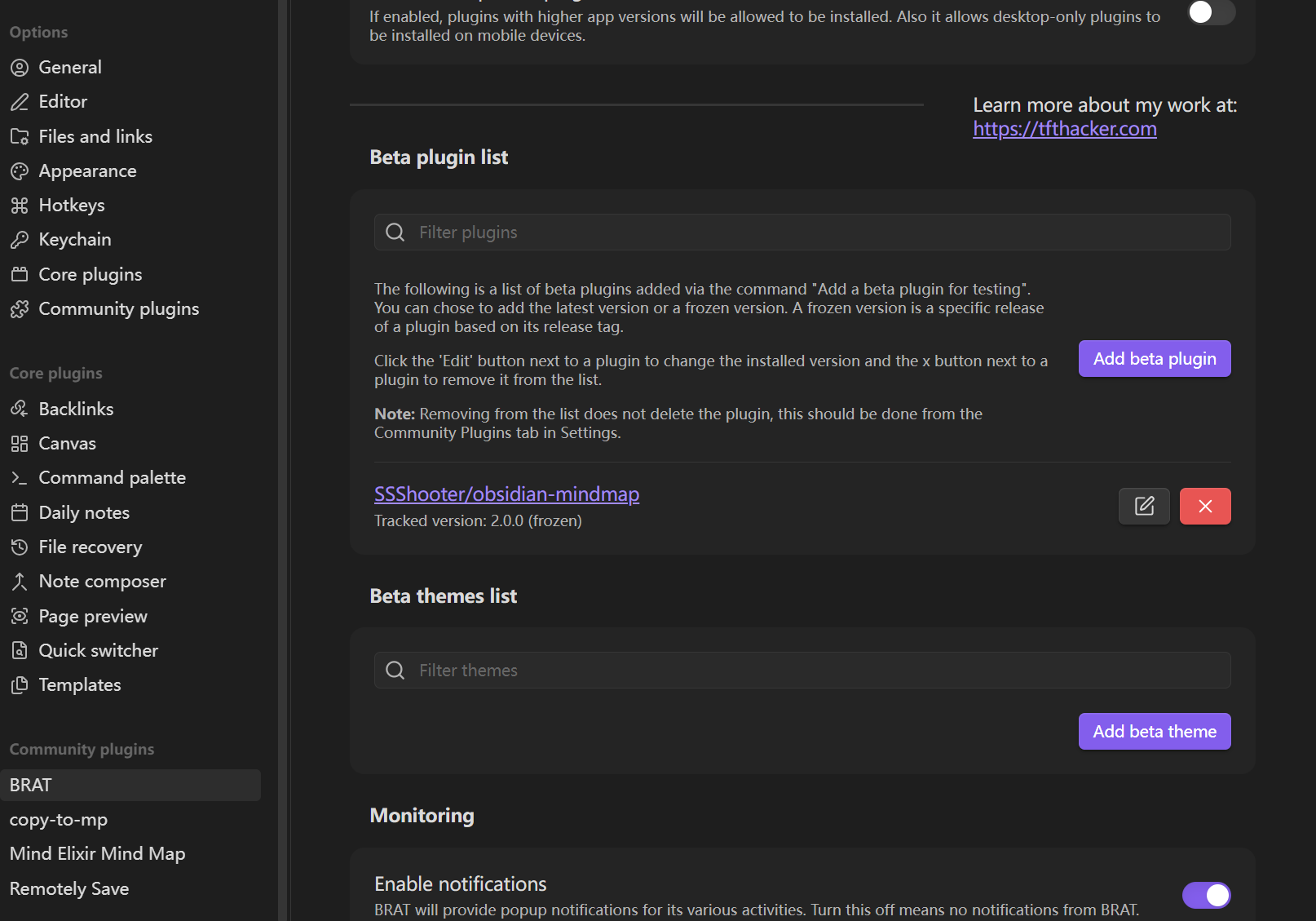
安装后在 BRAT 配置里点击 Add beta plugin 按钮,填入 https://github.com/SSShooter/obsidian-mindmap,就能自动安装思维导图插件:
不想使用 BRAT 也可以进入插件 Release 页面下载以下 3 个文件:
main.jsstyle.cssmanifest.json然后在 Obsidian 的设置中,打开插件目录,建一个文件夹把这三个文件放进去,然后刷新一下插件列表即可。
目前 mindelixir-mindmap 仍在持续迭代优化中,如果你在使用中遇到任何问题,或是对新功能有什么好想法,非常欢迎到 GitHub 提交 Issue 和 PR 🤗
2026-02-27 16:24:32
React 引入 useSyncExternalStore 也很长一段时间了,但是存在感还不太强。简而言之,它专门用来搞定那些不受 React 内部生命周期控制的外部数据源。
过去最大的问题其实是 React 渲染时的 「撕裂」,这是 React 为了优化页面响应速度引入的并发渲染机制带来的副作用。
简单来说就是 React 为了防止在渲染时长时间无法响应用户输入,把渲染过程拆分成多个可中断的小任务,这就能小任务的间隙中插入用户响应,从而模拟出「并发」的感觉。更完整的前因后果可以参考《React 的设计哲学》。
在 React 并发渲染机制下,如果用普通的 useEffect 去同步外部数据,可能会出现渲染进行到一半时数据突然发生变化,导致同一份页面中,一半的组件拿着老数据,另一半拿着新数据的灵异现象(但是实际上出现这个问题的几率其实非常小,大家都忽略了,这就导致了 useSyncExternalStore 的存在感很低)。使用 useSyncExternalStore 后,如果在渲染过程中快照发生变化,React 会丢弃当前渲染并重新开始,从而保证同一次提交中的所有组件看到的是同一个版本的数据。
拿监听网络状态来说。不使用这个 Hook 之前,我们通常得在组件里写个包含完整挂载和清理逻辑的 useEffect 去监听 online 和 offline 事件。
function subscribe(callback) {
window.addEventListener("online", callback);
window.addEventListener("offline", callback);
return () => {
window.removeEventListener("online", callback);
window.removeEventListener("offline", callback);
};
}
function getSnapshot() {
return navigator.onLine;
}
// 组件里直接这么用
const isOnline = useSyncExternalStore(subscribe, getSnapshot);
监听媒体查询(Media Queries)响应式布局也是同样的套路:
const query = window.matchMedia("(max-width: 600px)");
function subscribe(callback) {
query.addEventListener("change", callback);
return () => query.removeEventListener("change", callback);
}
const isMobile = useSyncExternalStore(subscribe, () => query.matches);
如果你接手了一个极小的项目,不想引入 Redux 或 Zustand 这样繁琐的包,但又迫切需要在几个跨层级的组件间共享某部分状态。这时候你可以直接手搓一个简易的 Store:
// 丢在 React 外面的状态中心
let internalState = { count: 0 };
const listeners = new Set();
const store = {
increment() {
internalState = { count: internalState.count + 1 };
listeners.forEach((l) => l());
},
subscribe(callback) {
listeners.add(callback);
return () => listeners.delete(callback);
},
getSnapshot() {
return internalState;
},
};
// 任何组件里都可以直接同步获取状态
const state = useSyncExternalStore(store.subscribe, store.getSnapshot);
注意:useSyncExternalStore 内部用 Object.is 比较前后快照,如果 getSnapshot 在数据未变的情况下每次都返回新对象,会导致无限循环重渲染。
只要把这段代码看懂,你就掌握了 Zustand 这种现代状态管理库的核心原理。
曾经大家都习惯在 useEffect 里监听外部变化,如果变了,再跑一下 setState 触发更新。
这就又到了日常批判 useEffect 的时候了。
useEffect 带来重复渲染和闪烁问题。如果你的外部状态和页面初始计算的状态不对齐,页面渲染就会经历「旧值 -> 闪烁 -> 新值」这三步。而 useSyncExternalStore 在渲染中途就能直接取走最新的正确值。
另外,在处理服务端渲染时,用副作用很容易抛出水合(Hydration)错误,因为服务端和客户端首次生成的 HTML 大概率因为外部数据对不上。useSyncExternalStore 为此专门开了一个叫 getServerSnapshot 的参数,让你传能兜底服务端的静态快照。
很多人滥用 Context 做全局状态,但如果是频繁变动的数据,Context 的广播机制简直是一场灾难。只要 Provider 提供的值发生了变动,它底下所有的子组件也会跟着无脑重跑 Render,除非你给每个组件层级套一层 React.memo(当然现在有 compiler,但也不是毫无代价)。
相比之下,useSyncExternalStore 实现了高精度的按需订阅——只有从 Store 取出的快照真的有了变化,关联的组件才会再次渲染。在这里还是顺便强调一下,没事别用 Context。
要判断何时使用 useSyncExternalStore 其实很简单,只要你的数据依然在 React 的生命周期里流转(例如表单实时输入、控制弹窗开闭的布尔值),那就老老实实用回你的 useState 和 useReducer。
一旦数据满足游离于 React 管理之外、会随时间变化、且你要让 UI 能自动响应这种变化这三个条件,就毫不犹豫上 useSyncExternalStore。日常写前端页面也许碰不到几次,但之后你要是去造底层 Hook 库,或者需要硬啃第三方库内部暴露出的状态时,useSyncExternalStore 绝对好使~
2026-02-24 23:08:12
useLayoutEffect 与大家熟悉的 useEffect 语法完全一致,从产生副作用的角度上看,功能上也是一样的,唯一差别就是调用时机。
useEffect 会在画面绘制后异步执行,而 useLayoutEffect 会在画面绘制前同步执行。为了讲清楚这个时机的具体区别,得先复习一下浏览器渲染页面的过程。
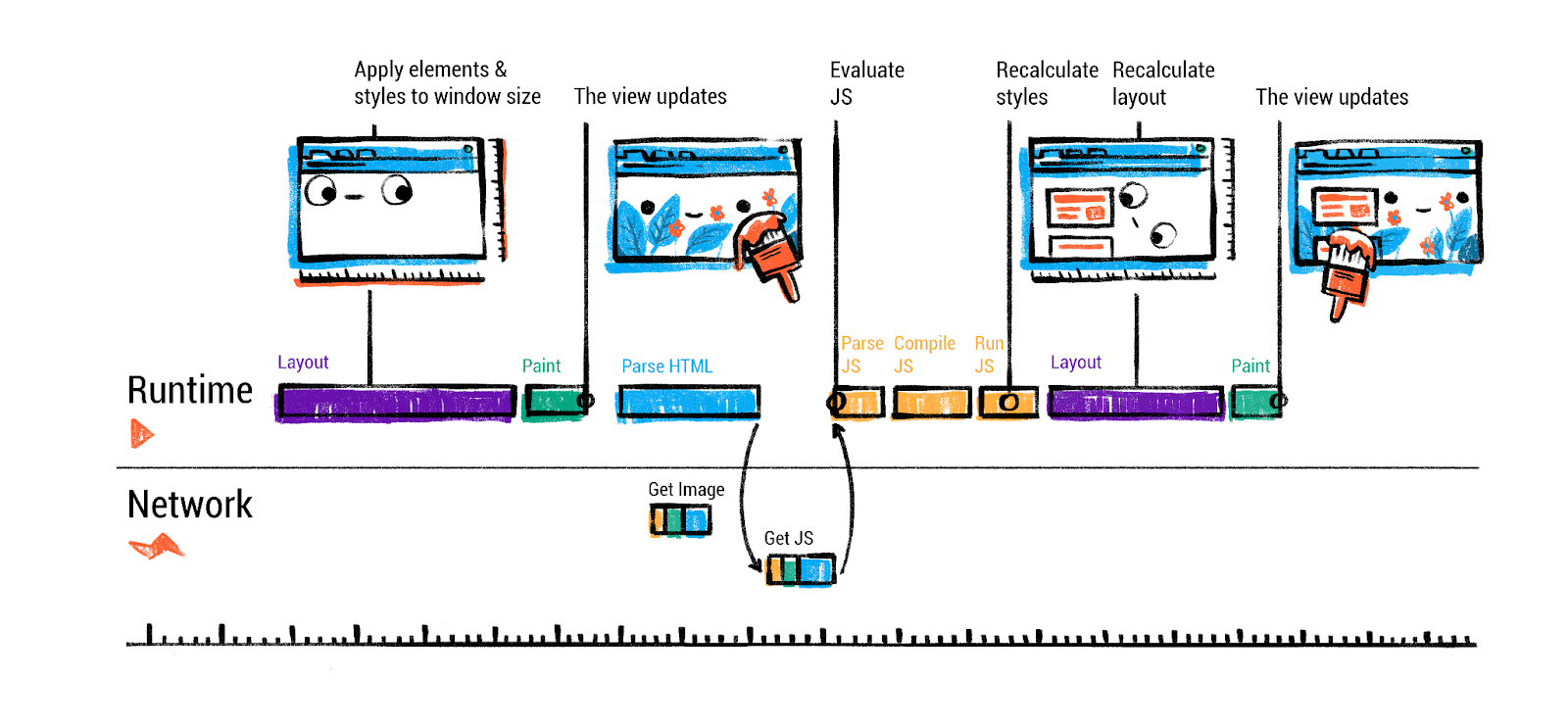
注意最后 js 运行的那一块,useLayoutEffect 和 useEffect 就分别位于 paint 之前和之后。
执行的顺序是:
顺便我们也能看出来,useLayoutEffect 之所以叫 useLayoutEffect 就是因为它的运行时间点沾着 layout。
知道这两个函数的区别,我们还需要知道,到底什么时候用 useLayoutEffect 呢?
答案是,如果进行了 DOM 操作,且这个 DOM 操作会引起回流(reflow)、重绘(repaint),那么就应该使用 useLayoutEffect,例如:
function Tooltip() {
const ref = useRef<HTMLDivElement>(null);
const [pos, setPos] = useState({ top: 0, left: 0 });
// 如果用 useEffect,这里会先渲染一次默认位置,再跳到正确位置 → 可能会造成闪烁
useLayoutEffect(() => {
const rect = ref.current!.getBoundingClientRect();
setPos({
top: rect.top + rect.height + 8,
left: rect.left + rect.width / 2,
});
}, []);
return (
<>
<div ref={ref}>hover me</div>
<div style={{ position: 'fixed', top: pos.top, left: pos.left }}>tooltip</div>
</>
);
}
因为如果你用 useEffect,在浏览器绘制之后又要重新跑一遍 reflow、repaint,用户可能会看到画面“闪烁”。
如果你有代码洁癖,想要一个最优解,那么你确实该按上面说的这么做,但是事实上在这个场景使用 useEffect 可能也不会有很明显的问题。
其实即使是官网的例子里,作为反模式使用 useEffect,用户也不会感知到明显的“闪烁”,因为两次渲染的时间其实是快到肉眼看不清的,为了确定真的存在区别你还要故意写个 while 循环卡一下主进程。
既然一般情况下无论 useEffect 和 useLayoutEffect 都不会有明显区别,那么我觉得,作为一个有专业素养的 React 开发者,应该优先使用 useEffect,只在 reflow、repaint 造成闪烁的场景下,使用 useLayoutEffect。
当然,useEffect本身也不能乱用,之前在useEffect 清除计划里已经讲述了它的必要使用场景。
useLayoutEffect 适用于“需要在浏览器绘制前同步完成的副作用”,典型场景是读取布局信息并立即修改 DOM,避免视觉闪动。
但因其会阻塞浏览器绘制,影响性能,因此不应滥用。在绝大多数副作用场景下,优先使用 useEffect,只有在感知到闪动才改为使用 useLayoutEffect。