2025-08-21 08:00:00
经过半年多断断续续的努力,终于为 《小丑牌》 画上句号。获得了「完美主义者+」称号:使用所有卡组在金注难度下获得胜利。

一共有 15 个卡组,每个卡组,从白注到金注共 8 个难度,一共赢了 120 局。
赢下第一个白注花了一周,赢下第一个金注很激动,赢下最后一个金注如释重负。
游戏的随机性很强,即使是白注,也不一定能保证通关。紫注以上,基本需要反反复复地尝试才可能成功。
高难度下,筹码、倍率、倍数三者都要合格,如果有某一项拖后腿,就会比较难。
筹码小丑:
倍率小丑:
倍数小丑:
经济小丑:
功能小丑:
传奇小丑:
最后罗列一下所有被我贴了金注标签的小丑:
奸诈小丑、仪式匕首、神秘之峰、积分卡、致胜之拳、斐波那契、混沌小丑、抽象小丑、搭乘巴士、窃贼、黑板、跑步选手、冰淇淋、星座、老千、疯狂、全息影响、九霄云外、邮件回扣、冲上月球、占卜师、金牛、闪示卡、备用裤子、城堡、微笑表情、骷髅先生、喜与悲、吟游诗人、证书、回溯、未断选票、箭头、蓝图、小小丑、三重奏、特技演员、头脑风暴、驾驶执照、提靴带、卡尼奥、特里布莱、帕奇欧。
值得一提的是,这款横扫了众多奖项,并获得了 TGA 2024 最佳独立游戏的游戏,是一个人设计和开发出来的,而他开发这款游戏的初衷,竟然只是为了「使简历上更好看一些」。真是程序员的楷模。
2025-08-10 08:00:00
在两段工作经历之间的假期,我安排了一周的独自旅行。理论上,已婚有娃人士很难有独自旅行的机会。但是,此次从钉钉辞职,虽然早有预感,但真正决意也就在骤然之间 —— 说辞就要辞了。自己名下的二十多天假期须尽快休掉,晓辰最近又忙,一时无法脱身,这才有了我这次的独自旅行。人生啊,就是计划赶不上变化,我几乎没做攻略,只定了酒店,就登上了飞往东京的航班。
降落成田机场已是傍晚。我的住宿订在秋叶原,本想搭乘京成本线到上野,但我却误上了一列先走京成线,然后接入总武线的列车,往千叶方向去了。我在千叶换乘了中央线,到达秋叶原已经夜里十点多。
路上行人渐少,大多店铺也已经打烊。虽然下着绵绵的细雨,但我还是套上外套,下楼在附近的几个街区兴奋地溜达了一圈。
酒店就在秋叶原站上方,我的房间位于较高的楼层,视野很棒。我喜欢视野好的房间。

我在东京造访的第一个目的地是上野公园。这座公园历史悠久,又是赏樱圣地,名气很大,连鲁迅的《藤野先生》都是这样开头:「东京也无非是这样,上野的樱花烂漫的时节……」。公园里有几处古迹,有不忍池,但除此之外,这座公园似乎也没有什么大不同之处。孔子说「近则不恭」,看来也适用于人对物的情形。大概因为是早晨,游客不多,很是幽静,但是公园中心的长条喷泉池四周却很热闹,穿着宽大校服的小学生或列队,或席地而坐,颇像国内小学生春游的样子。
喷水池广场北侧就是东京国立博物馆。我买一张票,走进去,偌大的一个庭院。主馆建筑门前杵着一株茂盛的银杏,弯曲粗壮的树干顶着张牙舞爪的树冠,在行道上投下斑驳的影子。树木上了年纪,和人上了年纪一样,总能现出一些不修边幅的气质来。忽然「哇——哇——」两声,两只乌鸦从树冠上飞起,藏到主馆建筑屋顶的缝隙里去了。东京的乌鸦很多,后来我在银座和涩谷都有听到乌鸦的叫声。

博物馆的文物,印象最深刻的有两件:一件是遮光器土偶,日本绳纹时代陶偶,特点是巨大的宛如遮光器(即飞行员护目镜)的眼睛;我注意到这件文物,是因为《文明 7》游戏中就有一个名为「遮光器土偶」的领袖属性点 —— 原来是出自这里。另一件是日本武士铠甲中的一具,这套铠甲使用黑色的皮毛装饰,头盔上还配备了一个威武的金属面具,使我想起《只狼》中的苇名一心。
北斋美术馆位于墨田区,从两国站出来,步行一公里左右到达。美术馆拥有银灰色金属质感的外墙和现代风格几何形状的造型,坐落在一片安静的住宅区中。那幅最著名的神奈川冲浪里,虽然馆藏确有一幅真迹(浮世绘是近代的印刷品,所谓「真迹」的存世数量并不特别稀少),但不常驻展出,能见到的只是复制品。

美术馆北侧是一片空地,用栏杆围起,空地上立着有秋千,球门,还有一个小型的旋转木马。这种小型社区公园在日本似乎很常见,设施虽不很新,但维护得极好,几乎没有坏的。去年关西旅行的时候,我也多次注意到这样的小公园,傍晚时分,有很多七八九岁的孩子聚集在公园里呼喊着玩耍,而且不太见到在旁看护的家长。
这种社区氛围使我想起,自己七八九岁时,夏日傍晚,在公房前的泥土空地上,和玩伴们打玻璃弹珠的日子。必须太阳西沉,天色已昏暗到难以看清地面上的弹珠时,才肯依依不舍地回家。如今国内,已经很难想象家长会放心让七八九岁的孩子在外独立玩耍了。
晚上,好好逛了一下秋叶原最大的电器城友都八喜。顶楼的游戏机区域很是吸引我,可惜的是 Switch 2 国际版全部缺货;我很是想买些什么有趣的主机配件之类,但没有看到特别亮眼的,又不想空手而归,最后买了一个任天堂闹钟。
电器城这种业态,在国内已完全被电商取代了 —— 标准化产品的价格过于透明,消费者现场体验线上下单的问题,几乎是无解的。想不明白,日本的电器城为什么还能继续存活。
第三天早晨,出发去浅草寺。浅草寺周围主要是招待游客的商店街,我到得早,店铺大多还没开门,街道上空荡荡的。浅草寺占地不大,建筑也不多 —— 除了主殿和五重塔,就是影向堂(御朱印在里面),不似京都清水寺或杭州灵隐寺那般层层叠叠。洗过手,走进主殿。抽了一签,是吉签。签语是:「盘中黑白子,一着要先机。天龙降甘霖,洗出旧根基。」

当我沿着仲见世商店街离开时,店铺才陆陆续续开始营业,有游客聚集在雷门拍照。我前往隅田川方向,晴空塔矗立在远处。
银座大概是我到过的最豪华、最昂贵的商圈了。这里路网密集,一个街区只有一两栋建筑宽。我走马观花地穿过三越百货、银座松屋,打卡了百年老店和光百货。和光百货实在是高档,宽阔而一尘不染的走廊,老派而奢华的玻璃柜,衣着精美的工作人员,令我走进去的时候不由地屏住呼吸。

银座的街道给我的感受是「安静」,一种与其繁荣不匹配的安静:没有混杂着各种语调语气的高频人声,只能偶尔听到被刻意压低的窃窃私语。我能清晰地听到汽车驶过,引擎的突突声,轮胎摩擦地面的沙沙声,能听到皮鞋和高跟鞋踩在地面上的哒哒声,风吹动树叶的哗哗声,吹动广告旗帜的呼呼声,甚至能隐约听到远处,火车压过铁轨的咚咚声,车厢晃动的哐哐声。印象最深刻的是和光百货钟楼的整点报时:响亮的「当——当——」的钟声在沉默的人流上空盘旋,那一刻,这种安静的感受尤为强烈,我大概对日本社会中某些礼貌和压抑的特质也有了更生动的体会。
逛得最久的店铺,是银座的 MUJI 无印良品旗舰店。我很难掩饰对 MUJI 品牌的喜好,它的极简留白的「空容器」风格真是打在我的心头上。我大概有超过一半的衣物和各种日用品来自 MUJI,所以造访这家世界上最大的 MUJI,也算我到东京必做的事情之一。

这家 MUJI 的一楼是一整层食物,有新鲜面包、新鲜蔬菜(规格外野菜)、便当速食、零食饮料、甚至还有各种各样的调味料。其实我一直不理解国内 MUJI 门店怎么会有软糖和咖喱这种和家居主题完全不搭的商品,原来 MUJI 是有完整的食品板块的。二楼到五楼和国内门店差不多,只是商品的款式似乎更全一些。买了些小东西,退税柜台的收银员普通话比我还标准。六楼以上是 MUJI Hotel,餐厅对非住客也开放。我喝了一杯美式,然后离开了。
东京铁塔,因为频繁出现在《奥特曼》中,频繁被怪兽摧毁,成为儿时我对东京的第一印象。傍晚从秋叶原出发,搭日比谷线,到神谷町出站,天已黑了大半。这一带的城市风貌令我感到熟悉:宽阔的马路,高档而略冷清的玻璃外立面高楼,很像国内的一些地方。快到永井坂路口时,先是看见前方很多游客正举着手机拍照,再快速走几步,红通通的铁塔就忽然从楼宇背后跃出,高耸着矗立在我的眼前中。

游客大部分是南亚、东南亚人,也有少数白人,中国人很少。我跟着人流向前,很快就到了塔底的游客中心。我便去买票,排队乘电梯上塔。
塔上的夜景令人震撼:几乎无遮挡的视野中,全是密密麻麻,连成一片的灯火,似乎要从所有的缝隙里都生长出来,就像丛林一样 —— 令我想起在香港太平山顶观景台所见的灯火 —— 饱含着一种健壮无序的力量。
观景台内部就没有什么特别之处了。主观景台上的顶层观景台,排队时间太久,而且排进去后的流程也是无趣冗长,竟然还有免费(半强制)拍照,收费取照的桥段,令人大跌眼镜。十一点多,我才回到酒店。
从地图上看,东京的周边地区似乎是由一个个小镇组成,每个小镇都有一个火车站,火车站辐射出相当规模的繁华商圈,再往外是安静的住宅区。吉祥寺就是这样一个小镇,去吉卜力美术馆需要在这里下车,然后步行过去。这里位于东京西部,与东京核心区有一段距离,从秋叶原搭火车花了一个小时才到。再往西,就到立川了,那里是 Falcom 法老控公司的所在地,也许可以朝圣一二,我想。但我还是在吉祥寺下了车。
吉卜力美术馆的门票有严格入场时间,我到早了,因此在吉祥寺闲逛了一两个小时。这个理论上只服务周边地区的小镇,它的繁荣程度大大出乎我意料。这里有密集的超市、特色餐厅、咖啡厅,各种各样文具店、电子产品商店,连锁书店,还有一整栋楼的优衣库,甚至还有专门卖烟斗和卖灯油的店 —— 真是不敢相信。本地人悠闲地在精致的街道和店铺里消磨时光,就像乐高街景里的人偶与建筑一样协调。可以说,与长三角地区普通地级市 —— 比如我的家乡南通,或扬州、无锡、嘉兴、金华这类城市 —— 市中心最好的商圈相比,也完全不输。可是,这只是东京市郊的一个普通小镇,这么说,东京可真是踏踏实实的繁荣啊。
从吉祥寺前往吉卜力美术馆,需要穿过井之头恩赐公园。高大的乔木,茂密的草丛,没有铺装的泥土小径,使我联想起《龙猫》中姐妹俩居住的乡下房屋。美术馆内,有以影片中形象为素材,展示视觉暂留原理的设施;有真实的早期手稿、原型图等「文物」;还有一个龙猫主题的儿童乐园 —— 真的可以进入到龙猫巴士内部;门票还包含一场小剧场中的动画短片(似乎不会在外部渠道放映,而且会定期轮换)。美术馆唯一可以拍照的地方是屋顶的天空之城机器人塑像。

搭乘京王井之头线,从吉祥寺到涩谷。我匆匆打卡了世界上人流量最大的涩谷十字路口。这种路口的信号灯是「行人全向通行」的。当行人绿灯亮起,数百人甚至上千人同时从四个街角像鱼群一样涌出,形成若干股巨大的人流,四个方的车流全部停下,你会产生有一种身在舞台的感觉。
因为没有预定,我没能上得去涩谷最有名的天空观景台。简单逛了逛,我就开始在庞大的由天桥、通道组成的迷宫中,寻找前往代官山的路。经过涩谷溪流大厦时,我有看到 Google 的指示牌 ——查询后发现,这里正是 Google 东京的两个主要办公地点之一。
沿着涩谷溪流大厦楼下的一条无名小路,向东南方向步行一段,然后经猿乐桥跨过铁路。街道一下子安静了,这就到了代官山区域。再向前走两公里,就到了代官山森林之门 —— 这个建筑和上海天安千树有点相似。

在森林之门这个路口右转,折进一条文艺的小路,很快就来到了代官山茑屋书店。这家茑屋书店可比杭州天目里的那一家茑屋书店大了不少,由三栋相互连接的二层建筑组成,其中一栋建筑二层是酒吧,几乎满座了。
这家茑屋书店有挺大一片区域是关于汽车主题的,里面有各个汽车品牌的相关的书籍、画册、海报、模型等等,挺有意思的。另外还有一块 SHARE LOUNGE 区域 —— 也就是收费休息/办公区,即使不点任何饮食,进入休息区也要收费,而且是按时长计费。比起更为常见的把餐食和空间捆绑售卖的商业模式,以及随之而来的「消费落座」或者「最低消费」的别扭规则,这种业态倒是更对我的口味。
我对书店很着迷,每到一个新的城市,我几乎总要寻找当地的有名的书店游览一番 —— 即使在日本,满屋子都是日文书,我还是情不自禁。这大概和我的童年经历有关:在从小镇刚搬入市区的头两年,家里没有空调,夏天特别热。为了避暑,有两个暑假,我几乎每一天都泡在南通书城里看书,早出晚归,中午就在摊子上吃一个油饼。
满满四层楼的书,给当时的我带来了极大的震撼 —— 任何能想到的问题,似乎都能在这里找到答案,我产生了「和世界连接上」的感觉。那两个暑假泡在书城的日子,其实也是我第一次脱离父母老师管束,自由安排活动 —— 因此直到现在,每次我步入书店,都本能地涌起一股轻松的情绪,令我上瘾。
在代官山站搭乘副都心线,一会儿就到新宿三丁目。出站后,我把步行导航目的地设置为歌舞伎町一番街:怀着纯粹的好奇心,我有意探索这片东京最著名的「红灯区」。
新宿的街道没有明显的区域风格,也没有令人瞩目的标志性地点 —— 到处是商店、霓虹灯、人流 —— 和其他地方一样。新宿给我的感觉是巨大、沉闷、没有尽头。时不时地,脚底隐隐传来火车行驶的震动时,我觉得自己在一颗孜孜不倦地跳动着的心脏里 —— 就是这个感觉,巨兽的心脏。
在跨越新宿站的桥梁上,我看到有大概是乌克兰人/裔在组织谴责俄罗斯的示威活动,举着蓝黄相间的旗帜。街头政治,国内几乎不可能见到。最近日本好像正在进行的选举,有一天在秋叶原酒店楼下也看到国民民主党的街头宣传。
歌舞伎町一番街,其实很短,大概只有两三百米长,街道两边一楼主要是餐厅、酒吧,二楼以上,根据霓虹灯招牌判断,应该有相当比例是软色情营业场所 —— 窄窄的楼道通往地面,只在一楼开一个小门,门前摆着包括价格明细的广告牌,还有女仆或其他 cosplay 装扮的年轻女性在门前招揽顾客。之前和晓辰一起在泰国旅行时,我们也探索过芭堤雅的红灯区,歌舞伎町与之相比,更加整洁清冷 —— 还有正常营业的餐厅,也没有人主动搭讪。

出卖身体换取金钱,真是一件颇为可悲的事情 —— 但是,联想起国内普遍超长的工作时间与缺乏尊严的职场环境,我又有什么资格去评判别人呢。
前一天晚上,我就一直在考虑接下来是去台场还是镰仓,毕竟来东京旅行,怎么着也得见一见东京的海才行。台场可以去丰州市场看三文鱼拍卖,还有富士电视台大楼,而且台场比较近,下午回来还能去东京大学逛一逛;镰仓比较远,但可以打卡高德院大佛和镰仓高校前。后来我发现,这天是周一,丰州市场没有拍卖,于是就就选择去了镰仓。
去镰仓的火车,坐了一个半小时。从镰仓站出来,我沿着由比滨大通步行,去往长谷和高德院方向。其实直接搭乘江之电更快,但我喜欢步行。我在由比滨大通上发现了一栋极具年代感的建筑,这里曾是镰仓银行由比滨出张所,现在是一个酒吧。

走了两三公里,到长谷大道路口,右拐上坡,游客开始多起来了 —— 不仅有国际游客,也有不少日本国内游客(甚至很多应该就来自东京)。恰巧,我和三四个中国游客擦肩而过,他们正在说南通话 —— 南通话是如此小众又难懂,以至于我和晓辰已经习惯于把南通话当做「公共场合的加密语言」来使用。当我听到这几名游客在用南通话点评一家古旧店铺内的商品时,我甚至感受到一种窥听的紧张。
整体上,镰仓的街道给我的感觉有点像冲绳,有一种「历史的厚重」和「度假的轻松」糅合在一起的味道:上了年龄的木质老屋和稍新的现代房屋交错在一起,沿街的建筑大多布置成餐厅或各种商店,店铺门口的冲浪用品和远处若隐若现的大海提醒着你,这里是海边。
高德院,其实不算太大,检票进去直接就看到了露天的大佛:青绿色的金属材质,大概三四层楼高。据说之前可以进到大佛内部,但是我没有看到。高德院大佛最早不是露天的,而是在大殿之中,但是大殿毁于海啸。后来镰仓幕府衰落,日本政治中心重新移回京都,镰仓当地也不再有资源来重建这座大殿,久而久之,露天的大佛就成了新的地标景观。《文明 6》游戏里的世界奇观高德院,建成时大佛就是露天的,并不严谨。

日本的景点,即使如镰仓大佛这种,极具分量的历史遗迹,其配套设施也比较简单,不占用太多土地,能够和周边环境融洽共处,就像放在纸盒中的珍珠一样。而国内的很多历史遗迹,修建大量配套设施和商铺,一道门套着一道门,甚至还需要用上接驳车,高下是不言而喻的。
镰仓高校前的丁字道口,因出现在《灌篮高手》片头中而成为著名的动漫圣地,以至国内很多同时拥有有铁路轨道和海岸风光的地方,在社交媒体上都被称为「小镰仓」。
从高德院出来,原路下坡,走到长谷电车站,搭江之电前往镰仓高校前。电车上很热闹,中国人很多,我旁边的两个男人大声谈论着上海和东京的房价,还有举着小红旗的导游扯着嗓子提醒团里的游客下车地点。我是一个不喜欢喧嚣的人,但在当时,作为一个独自在异国旅行了快一周的游客,我感到切实的亲切和轻松。列车冲到开阔地带,湛蓝的太平洋一下子映入眼帘,整个车厢的中国人一起发出了「哇哦」了呼喊,然后继续沉入喧嚣之中。
很快电车就到站了。镰仓高校前站特别小,简单说就是一个长条形的亭子。列车离开后,我在站里找了一个座位坐下来,直接就面朝大海了。我吹了一会儿海风,在隐约的海浪声中发了一会儿呆。

然后出站,去网红道口看了一眼,很多人在排队拍照。电车很久才会有一趟,恰好能与电车合影的,都是幸运儿。
接下来,我沿着高校前路口上坡,本想随意探索一番,结果走了好长一段,大约三四公里路程,最后到达了腰越站。这一路都是安静的住宅,几乎没有商店,甚至没见到什么人。在腰越站穿过轨道后,又回到了海边。沿着 134 过道向西,又走了一两公里路,就到了须花通。
这是一条通向江之岛的小道,路边有不错的西餐厅、售卖奶油布丁的小店、海洋风的纪念品商店、颇具设计感的首饰和服装店,和刚刚走过那么远的「荒芜之地」相比,实在是太可爱了。又累又饿,还没吃午饭的我在这里吃了一个虾仁奶油三明治,喝了一大杯热拿铁。
太阳有点斜了,我决定返程。从湘南江之岛搭乘湘南线到大船,再换火车到东京。湘南线是吊挂式的轨道,车体悬于轨道下方,这是我第一次乘坐吊挂式列车。
晚上,重新逛了逛秋叶原。第一天重点在友都八喜这种电器卖场,其实秋叶原还有海量的中古品(二手商品)商店:中古的动漫周边店,中古手机和游戏主机店、中古相机、镜头和拍立得店,中古书籍、漫画和音像制品店等等。可以感受到,日本的中古商品零售产业相当发达,只要是批量生产的标准化产品,都能按照年份,成色,稀有度等因素,匹配出一个合理的价格 —— 就连银座 MUJI 都有一小块售卖中古家具的区域。
返程有一个小插曲:原计划乘坐的航班,在执飞前序航班(上海-东京)执飞过程中机械故障,备降了大阪,所以我的航班取消了。庆幸之余,改签了下午稍晚的另一个航班。
在秋叶原站搭山手线到上野站,换京成本线前往成田机场,虽然还是慢车,但总算没有绕到千叶去。我惊奇地发现,在华语梗圈小有名气的「我孙子市」,就在这条线上。
傍晚时分,降落上海浦东,搭市域铁到虹桥,搭高铁到杭州,搭 19 号线回家。公共交通是如此完备便捷,普通人的活动半径之大,在一百年前的人们看来,根本难以想象。这是时代给普通人的福利,一定要珍惜啊。
2023-05-03 08:00:00
命名,无论如何强调都不过分。
命名的本质是概括,换言之,代码必须形成概念。
命名做不好,根本原因往往是,代码背后的概念本就含糊不清。不深究本因,一味追求「命名规范」,其实是颠倒了因果关系,无异于水中捞月。
代码复用,绝不是简单把重复代码抽离为公共模块。如果代码没有形成完整概念,如果你给不了它一个简短的名字,那么即使有再多地方出现这段重复的代码,也不要复用。
为使一个概念从残缺变完整,不一定要增加什么,常常也可以扔掉什么。
如果某件东西,把其任意一个部件移除,它就彻底坏了:我愿称之为「精妙」。
分治法:把一个问题拆解成为数不太多的若干个独立子问题。
面对复杂问题,自顶向下不断分治,将问题拆解为树,使每个叶子节点都足够简单。这是设计复杂系统最重要的方法论。
分治的结果,不应是子问题的简单加和(把一箱苹果拆分为每个苹果),而应是子问题的有机组合(把一箱苹果拆分为一些苹果和一个纸箱,苹果在纸箱内)。
一个问题的拆解,必须由架构师一人独立完成,因为概念只能源于一人的脑海。
架构师的职责:划分边界,规定依赖。一个项目中,谁能在这两件事上做决定,使他人遵照你的方案,谁就是架构师;如果没人能在这两件事上做决定,那就没有架构师。
为什么架构师追求形式正确?因为分治的结果(至少在未实现前)是形式。
为什么架构师关注接口甚于实现?因为正确的接口能够避免错误的实现导致的 bug 在各个子系统间传染。
举一个追求形式 / 接口正确的极端案例:考虑「根据 id 查询 item 详情」的接口,返回的详情数据中,是否应该包含 id 本身?我认为,如果不包含,接口就从形式上就杜绝了出错的可能。调用方原本就知道 id,试问如果详情数据中包含的 id 与调用时传入的不同,调用方应如何自处?如果采信了错误的 id,责任究竟在调用方还是接口提供方呢?
我认为「技术债」这个比喻并不恰当:首先,你可以永远不偿还技术债,因为技术债不影响软件运行,背负沉重技术债的软件甚至可以运行得非常稳定;其次,你似乎永远可以借到技术债:不管现状是多么的千疮百孔,你似乎总能找到「临时方案」。
如果把软件开发活动,视为使用「开发资源」这种货币来购买「软件需求实现」这种商品,那么我更愿意把「技术债」称为「技术贷」:一种特殊的消费贷。如果你看上某件商品,但囊中羞涩,可以选择贷款,自己只需支付 5% 的首付即可买下。这笔贷款没有任何偿还期限,但贷款存续期间,其他支付行为会增加 5% 手续费。结束贷款的方式有两种:重新按原价购买商品,或再次支付 5% 的手续费来扔掉商品(需注意,结束贷款支付的费用,也会受存续贷款的影响)。同时,银行承诺永远提供这样的贷款合约。
举债似乎是完全无成本的,但是举贷必须有 5% 的首付(再巧妙的临时方案都有开发成本)。最终压垮软件系统的,并不是无债可借,而是在大量存续贷款手续费的加持下,我们连最廉价商品的 5% 首付都无力承担。
如何评价软件的腐败程度:开发新功能时,多少精力投入在功能本身的开发上,又有多少精力投入在防止把原有功能弄坏上。
如何把不稳定复现的问题转化为稳定复现的问题?把复现的过程自动化,然后重复运行足够多次。
软件性能问题就像发烧。发烧不是一种病,而是一种症状,你不应指望「退烧药(性能最佳实践)」能真正治好什么大病。
「再多的药也比不上一次正确的诊断」——《霍乱时期的爱情》。
问程序员「这个 bug 什么时候可以修好」,可类比于问医生「这个病什么时候可以看好」。
程序员喜欢抬杠,因为赞同意见不会实质地推动讨论的进展,可以不说(只会在心里默默赞同)。
我不喜欢「打磨」的说法,它暗示了这件事是容易的、表面的、可替代的。软件开发工作中不存在容易的部分,因为容易的部分已经被优秀的工程师自动化了。
当队友说「这个盒子真好看,我要留着装东西」时,我听到的是:「房子太大了,这块空间扔了吧」。
软件开发工作中的沟通成本比任何外行估计的都高。这就是为什么单枪匹马的程序员,与传统的开发团队相比,有着巨大的成本优势。个人英雄主义在软件开发行业并未过时。
2022-01-16 08:00:00
前段时间我钻研了 《How to master advanced TypeScript patterns》 这篇文章,这是 ts-toolbelt 的作者 Pierre-Antoine Mills 的一篇早期博客文章。文章提出了一个很有挑战的题目:TS 如何为柯里化函数编写类型支持?
我参考原文进行了一些实践,然后似乎领悟到一些关于 TS 泛型的更接近实质的知识 —— 从集合的视角。基于这些知识,我发现原文中的大部分泛型都有更严密的写法。我认为这次实践和思考的过程值得记录下来,因此有了本文。
和原文一样,本文不展开讨论柯里化或函数式编程的问题,柯里化只是用以讨论 TS 泛型开发的素材。本文的线索是我的这份完整实现中,每一个泛型的作用,但这不是重点,重点是背后的领悟 —— 在文章前半部分,我常常会围绕一条简单的泛型讨论较长篇幅,请不要直接跳过。
柯里化是函数式编程领域的一个重要概念,它表示这样的过程:把一个多参数的函数转化成「一次接收一个参数」的函数,比如把 f(a,b,c) 转化为 f(a)(b)(c)。举个更详细的例子:
// toCurry 函数为待柯里化的普通函数
declare const toCurry: (a1: 1, a2: 2, a3: 3, a4: 4) => 0;
// curry 是柯里化转换函数,接收普通函数 toCurry,返回转换后的函数(先用 unknown 类型表示)
declare const curry: (toCurry: Function) => unknown;
// curried 是柯里化转换后的函数,调用者按次序每次传入一个参数,所有参数传入后,得到最终的返回值
const curried = curry(toCurry);
curried(1)(2)(3)(4); // => 0
最简单的柯里化,一次仅能接收一个参数。
高级的柯里化,一次可以接收不定项个参数:
// 调用 curried 一次传入多个参数
curried(1)(2,3)(4); // => 0
甚至还可以支持剩余参数和占位符:
// toCurry 中包含剩余参数
declare const toCurry: (a1: 1, a2: 2, a3: 3, a4: 4, ...args: 5[]) => 0;
const curried = curry(toCurry);
// 调用 curried 时也可以传入剩余参数
curried(1)(2, 3)(4, 5, 5, 5, 5); // => 0
// 调用 curried 时通过传入占位符把参数 2 移到了 3 之后
curried(1)(__, 3)(2, 4, 5); // => 0
柯里化转换函数 curry 是柯里化的核心。转换函数接收一个普通函数 toCurry —— 暂时用 Function 类型来表示;并返回柯里化转换后的函数 curried(后面也称柯里化的函数或柯里化函数)—— 暂时用 unknown 类型来表示。如何写出它的合法的类型表达,就是这篇文章的主线。
最简单的,一次只接收一个参数的柯里化,我的实现如下:
type Length<T extends unknown[]> = T['length'];
type Head<T extends unknown[]> = T extends [] ? never : T[0];
type Tail<T extends unknown[]> = T extends [] ?
never : T extends [unknown, ...infer R] ? R : T;
type CurriedV1<P extends unknown[], R> = P extends [] ?
R : (arg: Head<P>) => CurriedV1<Tail<P>, R>;
type Curry = <P extends unknown[], R>(fn: (...args: P) => R)
=> CurriedV1<P, R>;
declare const curry: Curry;
declare const toCurry: (a1: 1, a2: 2, a3: 3, a4: 4) => 0;
const curried = curry(toCurry);
curried(1)(2)(3)(4); // => 0
Length
第一条泛型 Length 返回元组的长度。
type Length<T extends unknown[]> = T['length'];
首先需要领悟的是,类型是对象的集合。比如,类型 number 是所有数字的集合,类型 1 表示由数值 1 组成的单一元素集合,类型 string[] 是所有「每一项都是字符串的数组」的集合。
泛型,从形式上看,是类型的函数(把一种类型转化为另一种类型);从集合的角度看,是集合的映射(把一个集合变为另一个集合)。
集合的映射,必须基于作用于集合内元素的规则。假设有集合 A 和 B,只有当 A 中的任意元素,按照某种规则,可以转化为 B 中的一个元素,我们才能说 A 和 B 之间存在映射关系。
既然映射只能从一个集合映射到另一个集合,如何理解多个泛型参数的情况?回答:把多个泛型参数看作一个元组类型。
以 Length 为例:
type Length_Test1 = Length<[unknown]>; // => 1
type Length_Test2 = Length<unknown[]>; // => number
将类型 [unknown] 传递给 Length 得到类型 1,描述了这样的事实:属于类型 [unknown] 的无数个元素中任意一个,不管是 [1] 还是 ['foo'] 还是 [{foo: true}],对它求取长度,得到的结果都是 1。这些元素经过 Length 这条规则,都被转化成了数值 1 这个元素;换言之,类型 [unknown] 所代表的集合通过 Length 这条规则映射为只包含一个元素(也就是 1 这个数值)的单元素集合,这个集合对应的类型就是类型 1。
将类型 unknown[] 传递给 Length 得到类型 number,这是因为:属于类型 unknown[] 的无数个元素中的任意一个,不管是 [] 还是 [1] 还是 ['foo', true],对它求取长度,得到的结果 0,1 或 2 等等,都是 number 类型。注意,Length 不能保证经过规则转换后的值占满映射得到的集合:因为没有什么数组的长度是 0.5 或 -1。所以,泛型运算 Length<unknown[]> 的结果 number 其实是真实世界中映射得到的结果集的超集。
泛型返回「真实结果集」的超集,时常比我们预期的集合要宽泛,这是不可避免的。从集合的角度看,编写泛型的目的,就是提供「真实结果集」的可以用类型规则描述的,同时尽可能小的超集。理解这一点很重要。
如果 JS 支持无符号整数类型,
Length<unknown[]>,似乎就可以得到完美的结果集,但这其实只是巧合。更多场合是无法得到完美结果集的:比如Length<[unknown, ...unknown[]]>需要返回「由大于 1 的整数」构成的集合。
TS 是如何知道 Length<unknown[]> 的结果是 number 的呢?在 Length<unknown[]> 和 number 之间,是否还存在某种原理可以被理解呢?我认为:已经没有什么原理性的内容了,TS 仅仅是根据先验性(公理性)的知识来直接给出答案。
TS 的类型系统是为 JS 量身定制的:任意 JS 字面量都是 TS 的单元素类型;JS 的基础类型如 number 或 string 也构成了 TS 的基础类型;通过类似定义数组、JSON 对象、函数的语法,我们可以创建数组类型和元组类型、对象类型、函数类型,来表示包含符合条件的数组元素、对象元素或函数元素的集合。TS 当然熟悉 JS 里所有对象类型的习性 —— 它们有什么成员属性,它们之间如何转化等等 —— 这些知识对 TS 来说是先验性的,所以 TS 才能轻易且正确地进行基础类型的运算。
// 基础类型间的运算
type T1 = number['toFix']; // => () => string
type T2 = [number, string][1]; // => string
type T3 = keyof { foo: number, bar: string }; // => 'foo' | 'bar'
Head
第二条泛型 Head 取出元组 T 中的第一个元素的类型。
type Head<T extends unknown[]> = T extends [] ? never : T[0];
Head 首先判断是否满足 T extends [],如果满足,说明 T 是只包含空数组的单元素集,返回 never;否则,说明 T 不是空数组单元素集,可能有第一个元素,返回 T[0]。
为什么条件泛型里只有 extends 关键字,而没有 equals 关键字或 == 运算符?我的领悟是:在集合运算中,只有包含运算才能产生「是」或「否」的结果,而集合的其他运算:交集、并集、补集、映射,他们的运算结果都是另一个集合。在集合的语境下,A 包含于 B,意味着 A 是 B 的子集;切换到类型语境下,即 A 是 B 的子类,也就是 A 继承自 B。
如何判断两个类型完全相同?只需判断它们互相包含(互相继承)。
对 Head 进行一些测试:
type Head_Test1 = Head<[1, number]>; // => 1
type Head_Test2 = Head<string[]>; // => string
type Head_Test3 = Head<unknown>; // ts error
type Head_Test4 = Head<[]>; // => never
前三条测试的结果是符合直觉的。第四条,当我们把包含空数组的单元素集传递给 Head,得到的结果是 never 类型,表示空集,也没有什么问题。
让我们再看一眼第二条测试:请问空数组是不是 string[] 集合的元素?当然是了。那么,在真实世界的 Head 映射中,空数组被映射为了什么元素?
集合论中,映射的前提是,映射规则对源集合内的所有元素都生效。我们应该如何理解 Head?
我的理解是:TS 中存在一个写不出来(JS 中没有)的 never 对象,而能写出来的 never 类型表示包含 never 对象的单元素集。同时,TS 中任何能写出来的类型都隐式包含了 never 对象,这使得任何类型与 never 类型求并集得到的都是自身,从而使本来是单元素集的 never 类型在概念上变成了空集。
从这个角度理解 Head<string[]> 就说得通了:string[] 集合中的空数组元素被映射为了 never,而其他元素被映射为了 string;因为 string | never 依然是 string,所以最终返回 string。
Tail
第三条泛型 Tail 提取元组 T 的尾项(即除去第一项后剩余的那些项)的类型。
type Tail<T extends unknown[]> = T extends [] ?
never : T extends [unknown, ...infer R] ? R : T;
有点复杂。
让我们先来看一个简易版本:
type SimpleTail<T extends unknown[]> = T extends [unknown, ...infer R] ? R : never;
SimpleTail 在形式上和 JS 代码很像:使用剩余参数运算符,把元组中除去第一项的剩余部分提取出来。简单的测试也没有问题:
type SimpleTail_Test1 = SimpleTail<[]>; // => never
type SimpleTail_Test2 = SimpleTail<[1, 2, string]>; // => [2, string]
type SimpleTail_Test3 = SimpleTail<[1, 2, ...string[]]>; // => [2, ...string[]]
但是,如果用 string[] 测试一下,得到了 never。这就不太对劲了:
type SimpleTail_Test3 = SimpleTail<string[]>; // => never
在真实世界中,string[] 集合中的几乎所有元素(除空数组对象外),取尾项操作都是有意义的。事实上,如果我们举一些例子进行归纳的话,一定可以得出结论:对 string[] 取尾项的结果就是 string[]。但是,根据 SimpleTail 的实现:string[] 又确实不是 [unknown, ...unknown[]] 的子集,我们只能返回 never。
再来看正式版本的 Tail:
type Tail<T extends unknown[]> = T extends [] ?
never : T extends [unknown, ...infer R] ? R : T;
T 是空数组单元素集的子集,我们可以断定:T 只能是空数组单元素集或 never,此时返回 never;T 是「由所有「拥有第一项的数组」组成的集合」的子集,我们可以断定:T 不可能包含空数组元素,此时用类似 SimpleTail 中的形式提取出尾项类型。T。传入 string[] 测试一下,通过分支 3,得到了预期的类型:string[]。
type Tail_Test4 = Tail<string[]>; // => string[]
你真的笃定吗?如果 T 即不满足分支 1 也不满足分支 2,就一定是类似于 string[] 或 number[] 这种纯粹的数组类型,而不可能是其他类型吗?
让我们归纳一下数组(包括元组)类型的写法:(我们不关心数组项的具体类型,全部用 unknown 代替)
[];unknown[];[unknownA, unknownB, unknownC];[unknownA, unknownB, ...unknownC[]]。经过归纳,我们发现定义数组类型的写法只有上面这 4 种,没有其他的了!能够写出来的数组类型,能够算出来(其他泛型返回)的数组类型,最后都能归纳到其中。这 4 种写法就是 TS 处理数组类型的边界,换言之 TS 无法产生「无法用这 4 种写法组合出来」的数组类型。
正是基于对以上知识的理解,我们确信只有第 2 种写法(纯粹的数组类型)才能走到分支 3。才能够放心地在分支 3 里返回直接 T。
注意,这里还有一个陷阱。考虑传入并集的情况:
type Tail_Test5 = Tail<[] | string[] | [1, 2, 3]>; // string[] | [2, 3]
根据集合论,并集的映射,应由组成并集的每个单个集合,分别映射之后,再对多个结果集取并集,作为最终的结果。
Tail 没有令我们失望,它正确地返回了预期的类型。但这是有条件的,泛型中的分支条件必须满足分发条件类型的约束:即条件必须是泛型参数直接 extends 某个类型(形如 T extends SOMETYPE),如果我们把 Tail 实现中的第一个条件 T extends [] 换成 Length<T> extends 0,分发条件类型的约束失效,命题「T 只可能是这 4 种写法之一」不复存在,—— 大厦由此坍塌。
type BrokenTail<T extends unknown[]> = Length<T> extends 0 ?
never : T extends [unknown, ...infer R] ? R : T;
type BrokenTail_Test6 = BrokenTail<[] | [1, 3] | string[]>; // => [] | [3] | string[]
你是否已经体会到泛型编程的某种笨拙之处?集合映射的规则(即泛型的语义)是基于集合内元素的,但泛型的实现者必须基于集合本身的运算来回答「映射之后是什么集合」的问题。这需要从真实世界的角度切实地归纳总结,才能保障映射的正确性和最小性。
目前,柯里化转换函数 curry 的类型定义如下:接收一个任意函数,返回 unknown。
type Curry = (toCurry: Function) => unknown;
declare const curry: Curry;
我们要把 unknown 换成一个更精巧的类型,这样用户在使用 curry 返回的结果(即柯里化函数)时,就能够获得正确的类型提示了。
显然,这个「更精巧的类型」具体是什么,取决于调用 curry 时传入的那个函数。我们使用泛型约束把传入函数的参数 P 和返回类型 R 提取出来:
type Curry = <P extends unknown[], R>(toCurry: (...args: P) => R) => Curried<P, R>;
然后,将 P 和 R 传递 Curried 泛型,作为柯里化函数的类型(即前述的「更精巧的类型」)。
注意,
Curry不是泛型映射,只是一个具有泛型约束的函数类型。
CurriedV1
CurriedV1 是 Curried 泛型的第一版实现,它支持最简单的柯里化(每次只消费一个参数)。
type CurriedV1<P extends unknown[], R> = P extends [] ?
R : (arg: Head<P>) => CurriedV1<Tail<P>, R>;
泛型是可以递归调用的,CurriedV1 就是这样,当它每次递归地调用自己,元组 P 的规模就减一,直到其变为空数组,结束递归。
测试一下,很完美:
type CurriedV1_Test1 = CurriedV1<[1, 2, 3], 0>; // => (arg: 1) => (arg: 2) => (arg: 3) => 0
你可能会问:如果传入一个无限(未知)长度的数组类型,比如 number[],TS 会不会陷入死循环?让我们试一试:
type CurriedV1_Test2 = CurriedV1<number[], 0>; // => (arg: number) => ...
TS 没有报错或陷入死循环,而是仍然映射出了一种可以无穷调用下去的函数类型。所以,我们可以得出结论:递归时逐渐缩减规模并不是泛型递归的必要条件。
事实上,泛型的某种惰性机制允许我们去为诸如 JS 中的循环引用对象或返回自身的函数定义类型:
type Foo<T> = { foo: Foo<T> };
declare const foo: Foo<number>;
foo.foo.foo.foo.foo.foo; // => 属性 foo 可以无限取下去
type Bar<T extends () => number> = () => Bar<T>;
declare const bar: Bar<() => 1>;
bar()()()()(); // => 函数 bar 可以无限调用下去
讲到这里,其实大部分「从集合视角看泛型」的领悟已经陈述完毕了。接下来,我会加快一些速度,把更高级的柯里化的类型实现讲完。
如果柯里化函数可以接收不定项参数(形如 curried(1)(2,3)(4)),就会更易用一些。我的实现是:
type Prepend<E, T extends unknown[]> = [E, ...T];
type Drop<N extends number, P extends unknown[], T extends unknown[] = []> =
Length<T> extends N ? P : Drop<N, Tail<P>, Prepend<unknown, T>>;
type PartialTuple<T extends unknown[]> = Partial<T> & unknown[];
type CurriedV2<P extends unknown[], R> =
Length<P> extends 0
? R
: <T extends PartialTuple<P>>(...args: T) => CurriedV2<Drop<Length<T>, P>, R>;
type Curry = <P extends unknown[], R>(fn: (...args: P) => R) => CurriedV2<P, R>;
declare const curry: Curry;
declare const toCurry: (a1: 1, a2: 2, a3: 3, a4: 4) => 0;
const curried = curry(toCurry);
curried(1, 2)(3, 4); // => 0
Prepend
泛型 Prepend 在元组类型前加上一项。
type Prepend<E, T extends unknown[]> = [E, ...T];
type Prepend_Test1 = Prepend<1, [2]>; // ==> [1, 2]
type Prepend_Test2 = Prepend<1, [2, ...3[]]>; // ==> [1, 2, ...3[]]
type Prepend_Test3 = Prepend<1 | 2, 3[]>; // ==> [1 | 2, ...3[]]
注意,Prepend 不是条件类型,自然不满足分发条件类型,所以 Prepend_Test3 是 [1 | 2, ...3[]] 而不是 [1, ...3[]] | [2, ...3[]]。如果你想要得到后者,可以将 Prepend 的实现放在条件类型内,如下所示:
type DistributedPrepend<E extends unknown, T extends> = E extends unknown ?
[E, ...T] : never;
type DistributedPrepend_Test1 =
DistributedPrepend<1 | 2, 3[]>; // ==> [1, ...3[]] | [2, ...3[]]
本文后续讨论假设所有传入的类型都是不分散的(即非并集的形式),也不再讨论分发条件类型的问题。
Drop
泛型 Drop 负责从元组中删掉头部的 N 个元素。Drop 也是递归的,每次递归删掉一个元素,同时放置一个 unknown 到元组 T 中。当元组 T 的长度与 N 相等时,说明已经删掉了足够多的元素,把剩下的元素返回即可。
type Drop<N extends number, P extends unknown[], T extends unknown[] = []> =
Length<T> extends N ? P : Drop<N, Tail<P>, Prepend<unknown, T>>;
简单地测试,没有问题。
type Drop_Test1 = Drop<2, [1, 2, 3, 4]>; // => [3, 4]
type Drop_Test2 = Drop<5, [1, 2, 3, 4]>; // => never
type Drop_Test3 = Drop<5, [1, 2, ...3[]]>; // => 3[]
Drop 的关键在于,使用了一个空数组,也就是第三个泛型参数 T 来进行计数。
有趣的是,类似的机制可以用来实现整数的加减法:
type FromLength<N extends number, P extends unknown[] = []> = Length<P> extends N ? P : FromLength<N, Prepend<unknown, P>>; type Add< A extends number, B extends number, Res extends unknown[] = FromLength<A>, Count extends unknown[] = [] > = Length<Count> extends B ? Length<Res> : Add<A, B, Prepend<unknown, Res>, Prepend<unknown, Count>>; type Sub< A extends number, B extends number, Res extends unknown[] = [], Count extends unknown[] = FromLength<B> > = Length<Count> extends A ? Length<Res> : Sub<A, B, Prepend<unknown, Res>, Prepend<unknown, Count>>; type Eight = Add<3, 5>; // => 8 type Four = Sub<9, 5>; // => 4
PartialTuple
泛型 PartialTuple 的故事要从 TS 的官方泛型 Partial 开始讲。我们知道 Partial 泛型可以将一个对象类型的所有属性都变得可选。当它作用于数组时,会使数组的每一项变成可选,比如 Partial<[number, string]> 可以得到类似于 [number?, string?] 的类型。
我们期望 CurriedV2 支持不定项参数,因此需要从定项参数元组中抽取出「元组的前任意项」类型:比如定项参数是类型 [1, 2, 3],那么不定项参数可以是 [1],[1, 2] 或者 [1, 2, 3]。然而,TS 目前的类型运算没办法实现「元组的前任意项」这样的映射规则,而 Partial 是最接近的实现(最小超集)。
为什么又需要 PartialTuple 呢?因为被 Partial 转换后的类型已经不再是元组了:诸如 length,map 等属性也成了可选属性,这使得形如 {0: 'Hello'} 这样的对象也在 Partial<[string]> 的集合内。PartialTuple 将这部分不属于元组的元素剔除在外。
type PartialTuple<T extends unknown[]> = Partial<T> & unknown[];
原文直接使用 Partial 而不报错,这是 TS 的一个 bug:对于 Partial 传入元组类型后,究竟还是不是元组,在不同的条件下判断不一致。我提交了 issue 和最简复现。
CurriedV2
CurriedV2 与 CurriedV1 在框架上有点类似:
type CurriedV1<P extends unknown[], R> =
P extends [] ? R :
(arg: Head<P>) => CurriedV1<Tail<P>, R>;
type CurriedV2<P extends unknown[], R> =
P extends [] ? R :
<T extends PartialTuple<P>>(...args: T)
=> CurriedV2<Drop<Length<T>, P>, R>;
最重要的一点区别是,CurriedV2 为柯里化函数引入了泛型约束,这样每次调用时,就能动态提取出传入参数的数量,并据此计算此次调用应该返回的类型。
type CurriedV1_Test1 = CurriedV1<[1, 2, 3], 0>;
// => (arg: 1) => (arg: 2) => (arg: 3) => 0
type CurriedV2_Test1 = CurriedV2<[1, 2, 3], 0>;
// => <T extends PartialTuple<[1, 2, 3]>>(...args: T)
// => CurriedV2<Drop<Length<T>, [1, 2, 3], []>, 0>
简单测试,我们发现 CurriedV2_Test1 无法直白给出柯里化函数的类型,因为每一步调用后得到类型,只有调用的时候才能(根据参数)确定。
有些函数的参数分为两个部分:固定参数和剩余参数。比如这样的 toCurry:在前四个固定参数之后,你可以传入任意个类型为 5 的剩余参数:
declare const toCurry: (a1: 1, a2: 2, a3: 3, a4: 4, ...args: 5[]) => 0;
// 必须在最后一次调用时一次性传入所有剩余参数
curry(toCurry)(1, 2, 3)(4, 5, 5);
如果柯里化可以支持这种函数,无疑会更好:这就是 CurriedV3 的目标。我的实现是:
type CurriedV3<P extends unknown[], R> =
P extends [unknown, ...unknown[]]
? <T extends PartialTuple<P>>(...args: T) => CurryV3<Drop<Length<T>, P>, R>
: R;
type Curry = <P extends unknown[], R>(fn: (...args: P) => R) => CurriedV3<P, R>;
declare const curry: Curry;
declare const toCurry: (a1: 1, a2: 2, a3: 3, a4: 4, ...args: 5[]) => 0;
const curried = curry(toCurry);
const result = curried(1, 2, 3)(4,5,5);
CurriedV3 与 CurriedV2 的区别仅仅在于递归结束条件不同:CurriedV3 通过判断满足 P extends [unknown, ...unknown[]] 推断出 P 仍然包含固定项,此时继续递归;不满足此条件说明 P 中只有剩余参数了,结束递归。
得益于严密的 Drop 以及背后的 Tail —— 它们妥善处理了纯粹数组和包含剩余项元组的情况 —— CurriedV3 的递归部分和 CurriedV2 是完全一致的。
type Drop_Test3 = Drop<5, [1, 2, ...3[]]>; // => 3[]
type Tail_Test5 = Tail<1[]>; // => 1[]
如果 Drop 和 Tail 对上述较为边缘的处理不够完善(比如直接返回 never 或 []),CurriedV1 和 CurriedV2 并不会受什么影响,但是 CurriedV3 的实现就没那么容易了。
柯里化中的占位符,能够帮助我们延迟传入参数的时机。比如:
// 普通的调用
curried(1, 2, 3)(4, 5);
// 占位符调用
curried(1, __, 3)(2, 4, 5);
// 甚至
curried(1, __, 3)(__, 4)(2, 5);
这就是 CurriedV4 的目标。我的实现是:
type Equal<X, Y> = X extends Y ? Y extends X ? true : false : false;
type Item<T extends unknown[]> = T extends (infer R)[] ? R : never;
type PlaceholderTuple<T extends unknown[], M extends unknown> =
{ [P in keyof T]?: T[P] | M } & unknown[];
type Reverse<T extends unknown[], R extends unknown[] = []> =
Equal<Length<T>, number> extends true
? Item<T>[]
: T extends [unknown, ...unknown[]]
? Reverse<Tail<T>, Prepend<Head<T>, R>>
: R;
type Join<P extends unknown[], T extends unknown[]> =
P extends [unknown, ...unknown[]] ? Join<Tail<P>, Prepend<Head<P>, T>> : T;
type Concat<P extends unknown[], T extends unknown[]> = Join<Reverse<P>, T>;
type PlaceholderMatched<
T extends unknown[], S extends unknown[], M extends unknown, R extends unknown[] = []
> = T extends [unknown, ...unknown[]] ?
PlaceholderMatched<Tail<T>, Tail<S>, M, Head<T> extends M ? Prepend<Head<S>, R> : R>
: Reverse<R>;
type __ = '__';
type CurriedV4<P extends unknown[], R> =
P extends [unknown, ...unknown[]]
? <T extends PlaceholderTuple<P, __>>(...args: T) =>
CurriedV4<Concat<PlaceholderMatched<T, P, __>, Drop<Length<T>, P>>, R>
: R;
type Curry = <P extends unknown[], R>(fn: (...args: P) => R) => CurriedV4<P, R>;
declare const curry: Curry;
declare const toCurry: (a1: 1, a2: 2, a3: 3, a4: 4, ...args: 5[]) => 0;
declare const __: __;
const curried = curry(toCurry);
curried(1, __, 3)(2, 4, 5, 5); // => 0
curried(1, __, 3)(__, 4)(2); // => 0
Equal
泛型 Equal 判断两个类型是不是完全相等(注意,仍然是集合运算,true 和 false 表示包含布尔值的单元素集合)。
type Equal<X, Y> = X extends Y ? Y extends X ? true : false : false;
type Equal_Test1 = Equal<number, 1>; // => false
type Equal_Test2 = Equal<number, number>; // => true
Item
泛型 Item 从数组类型中提取出数组项的可能类型。
type Item<T extends unknown[]> = T extends (infer R)[] ? R : never;
type Item_Test1 = Item<string[]>; // => string
type Item_Test2 = Item<[string, ...1[]]>; // => string | 1
PlaceholderTuple
泛型 PlaceholderTuple 与 PartialTuple 很类似,它不仅使元组的每一项变成可选,而且使每一项都可能是传入的类型 M。
type PlaceholderTuple<T extends unknown[], M extends unknown> =
{ [P in keyof T]?: T[P] | M } & unknown[];
Reverse
泛型 Reverse 将元组头尾翻转。
type Reverse<T extends unknown[], R extends unknown[] = []> =
Equal<Length<T>, number> extends true
? Item<T>[]
: T extends [unknown, ...unknown[]]
? Reverse<Tail<T>, Prepend<Head<T>, R>>
: R;
泛型 Reverse 值得稍作展开。先看核心部分(从 T extends 开始):接收数组类型 T,递归地调用自己,每次递归将 T 的头元素取下来,从头部推入 R 中。当 T 消耗殆尽,R 自然就是翻转后的数组。
对于固定长度的元组类型,这样做没问题。但是,如果想要翻转不固定长度的数组类型呢?
通过真实世界中的简单的归纳,我们知道 Reverse<string[]> 应该是 string[],映射仍然是完美的;对于 Reverse<[string, ...number[]]>,我们只能将其映射为 Array<string | number> —— 我们之前说过,泛型的返回时常比我们预期的类型要宽泛,这不可避免。
Reverse 实现的前两行(非核心部分),就是用来处理上述两种不固定长度数组类型的。
测试一下:
type Reverse_Test1 = Reverse<[1, 2, 3]>; // => [3, 2, 1]
type Reverse_Test2 = Reverse<unknown[]>; // => unknown[]
type Reverse_Test3 = Reverse<[string, ...number[]]>; // => Array<string | number>
Join
泛型 Join 将两个元组类型「头对头连接起来」。注意,第一个参数必须是固定项的元组类型。
type Join<P extends unknown[], T extends unknown[]> =
P extends [unknown, ...unknown[]] ? Join<Tail<P>, Prepend<Head<P>, T>> : T;
type Join_Test1 = Join<[1, 2], [3, 4]>; // => [2, 1, 3, 4]
type Join_Test2 = Join<[1, 2], [3, ...4[]]>; // => [2, 1, 3, ...4[]]
type Join_Test3 = Join<[1, ...2[]], [3, 4]>; // => ts error
Concat
泛型 Concat 将两个元组类型顺序连接起来。同理,第一个参数也必须是固定项的元组类型。
type Concat<P extends unknown[], T extends unknown[]> = Join<Reverse<P>, T>;
type Concat_Test1 = Concat<[1, 2], [3, 4]>; // => [1, 2, 3, 4]
type Concat_Test2 = Concat<[1, 2], [3, ...4[]]>; // => [1, 2, 3, ...4[]]
type Concat_Test3 = Concat<[1, ...2[]], [3, 4]>; // => ts error
PlaceholderMatched
泛型 PlaceholderMatched 将元组 T 中的类型为 M 的项找出来,然后从元组 S 中提取出对应位置的项,顺序存放在一个新的元组里 R,并最终返回。
type PlaceholderMatched<
T extends unknown[], S extends unknown[], M extends unknown, R extends unknown[] = []
> = T extends [unknown, ...unknown[]] ?
PlaceholderMatched<Tail<T>, Tail<S>, M, Head<T> extends M ? Prepend<Head<S>, R> : R>
: Reverse<R>;
有一点拗口。简单看一下测试就知道 PlaceholderMatched 的具体作用了:
type __ = '__';
type PlaceholderMatched_Test1 =
PlaceholderMatched<[1, __, __, 4], [1, 2, 3, 4, 5], __>; // => [2, 3]
CurriedV4
最后来看柯里化后函数类型的完全体 CurriedV4:
type __ = '__';
type CurriedV4<P extends unknown[], R> =
P extends [unknown, ...unknown[]]
? <T extends PlaceholderTuple<P, __>>(...args: T) =>
CurriedV4<Concat<PlaceholderMatched<T, P, __>, Drop<Length<T>, P>>, R>
: R;
CurriedV4 与 CurriedV3 的区别在递归部分。我们用 PlaceholderTuple<P, __> 约束柯里化函数的入参,这样调用者就可以传入占位符常量 __ 了。
单次递归中,我们将「被占位的元素」构成的元组类型提取出来(即 PlaceholderMatched<T, P, __>),然后与此次调用消耗参数后剩余的参数(即 Drop<Length<T>, P>>)连接起来,作为新的参数 P,传入下一次递归。
测试一下,完美。
type Curry = <P extends unknown[], R>(fn: (...args: P) => R) => CurriedV4<P, R>;
declare const curry: Curry;
declare const toCurry: (a1: 1, a2: 2, a3: 3, a4: 4, ...args: 5[]) => 0;
declare const __: __;
const curried = curry(toCurry);
curried(1, __, 3)(2, 4, 5, 5); // => 0
// => CurriedV4<[1, 2, 3, 4, ...5[]], 0> => CurriedV4<[2, 4, ...5[]], 0>
curried(1, __, 3)(__, 4)(2); // => 0
// => CurriedV4<[1, 2, 3, 4, ...5[]], 0> => CurriedV4<[2, 4, ...5[]], 0>
// => CurriedV4<[2, ...5[]], 0>
虽然本文中,对集合的讨论主要集中在前半部分,但是促使我去思考的,其实是对后面几个更高级的场景的实践。我发现,把这些实践的领悟套用在最开始的几个简单泛型上进行陈述,似乎更加清晰。
原文中,一开始的基础泛型就不是很严密,比如 Head 泛型是这样的:
type Head<T extends any[]> = T extends [any, ...any[]] ? T[0] : never;
这导致 Head<string[]> 返回的是 never,明显与从集合视角看上去的情形不符。
原文的很多基础类型,都存在没有处理妥善的边缘用例,所以当问题越来越复杂之时,泛型实现就会越来越不可控。后来原作者开始引入 Cast 泛型,把推导到边缘的不准确的类型强行转换回来。
type Cast<X, Y> = X extends Y ? X : Y;
这引发了我的思考,这些基础泛型究竟应该实现成什么样?在反复的实践中,我发现凭借直觉写出来的代码往往不够准确,有那么一刻,我领悟到我缺少的其实是一种集合的视角;而一旦从集合的视角理解了泛型运算的实质,似有一种豁然开朗之感:什么能做,什么不能做,哪里可以妥协,哪里只能放弃,就都可以确定地分析出来了。
(完)
2021-02-16 08:00:00
2019 年开始的 Flutter Framework 源码解析系列,一下子竟然搁置了接近两年。这两天过年,又想重新拾起来。仔细读了自己之前写的那两篇,幸好还能看懂,试了试电脑上的运行环境,居然也还能跑起来。近两年过去了,Flutter 升级到了 1.20,而我还是用的 1.2.2 版本,好在 UI 渲染的内核原理,想来不会发生什么大变化,所以这篇文章仍将基于老版本来进行。
我们直接开始吧:
两年前,我们讲到了 Layer —— 离 Engine 最近的一层。Layer 层之上是 RenderTree,这是 Flutter 渲染的核心:Flex 布局,绝对定位,文字排版,等等都是在 RenderTree 中完成的。本质上,你看到的每一个字、每一个色块、图片为什么出现在了屏幕的那个位置,就是由 RenderTree 决定。从这一层开始,我们会接触到一些和 CSS 中相通的概念。
顾名思义,RenderTree 在运行时是一棵树,其中的每一个节点都是一个 RenderObject 对象。这棵树的根,一般是 RenderView 对象(RenderView 继承自 RenderObject)。
我们从一个最简单的 demo 开始:
void main(){
PipelineOwner pipelineOwner = PipelineOwner();
RenderView rv = RenderView(configuration: ViewConfiguration(
size: window.physicalSize / window.devicePixelRatio,
devicePixelRatio: window.devicePixelRatio,
), window: window);
rv.attach(pipelineOwner);
rv.scheduleInitialFrame();
RenderDecoratedBox rdb = RenderDecoratedBox(
decoration: BoxDecoration(color: Color.fromARGB(255, 0, 0, 255))
);
rv.child = rdb;
window.onDrawFrame = (){
pipelineOwner.flushLayout();
pipelineOwner.flushCompositingBits();
pipelineOwner.flushPaint();
rv.compositeFrame();
};
window.scheduleFrame();
}
在这个例子中,我们创建了一个 RenderView 对象 rv,又创建了一个 RenderDecoratedBox 对象 rdb,并且把 rdb 设置成为 rv 的子节点。具体的,这里我们把 rdb 赋值给了 rv.child,这是因为 RenderView 是「只可以有一个子节点」的 RenderObject;如果遇到那些可能有多个子节点的 RenderObject,比如后面要说的 RenderStack,就需要使用 insert 等相关方法来管理子节点了;当然,还有一部分 RenderObject 是不可以有子节点的。
在正常的 Flutter 应用中,RenderTree 由更上游的模块维护,在这个例子中,我们手动创建和管理 RenderTree。
其实在此之前,我们还创建了一个 PipelineOwner 对象 pipelineOwner,这是渲染管线主对象。在创建完 RenderView 对象后,我立刻把 rv 挂载到了 pipelineOwner 对象上。由于 rv 是根节点,所以后续的子节点都会自动与 pipelineOwner 产生关联。
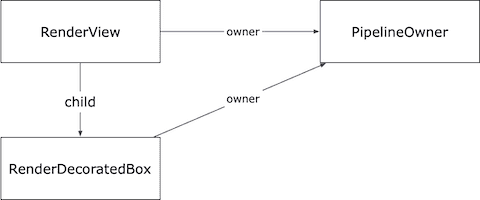
这是一棵最简单的 RenderTree 了。根节点 RenderView 对象 rv 的尺寸和屏幕一致,而 rv 的子节点,RenderDecoratedBox 对象 rdb 的尺寸也被拉伸为和 RenderView 相同,所以整个屏幕都是蓝色的。如下图所示:

RenderView 和 RenderDecoratedBox,都继承自 RenderBox。Flutter 目前只有 RenderBox 这一种形状的 RenderObject,几乎所有的 RenderObject 对象都派生自 RenderBox(RenderObject 也许是为其他不规则形状预留的基类),所以在这篇文章里,RenderBox 和 RenderObject 基本是等价的。
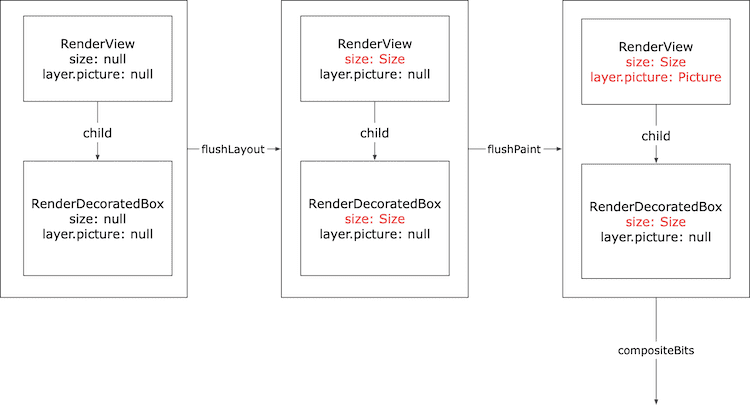
完成了 RenderTree 的构建,只是搭建好了一个数据结构。真正的渲染(包括布局、绘制、合成)是由 PipelineOwner 驱动的。
因此,我们在 window.onDrawFrame 方法(如果你看过前两篇文章,应该已经熟悉这个方法了,我这里就是把他当做类似 Web 环境中的 requestAnimationFrame 来使用)中手动调用 PipelineOwner 上的各个方法来驱动渲染。具体的,我们依次调用了 flushLayout,flushCompositingBits,flushPaint 方法,来进行布局和绘制。所谓布局,就是确定 RenderTree 每个节点的位置和尺寸;所谓绘制,就是根据 RenderTree,生成一个或多个栅格图像(在这个例子中,只有一个),用于屏幕上的显示。
下面这段代码是 flushLayout 方法的核心逻辑:对 RenderObject 列表 _nodesNeedingLayout 按照深度进行排序(这个深度其实就是在 RenderTree 中节点的深度,比如这里 rv 的深度就是 0,rdb 是 1),并依次调用其中每个元素的 _layoutWithoutResize 方法,然后清空 _nodesNeedingLayout。
// PipelineOwner#flushLayout
void flushLayout() {
while (_nodesNeedingLayout.isNotEmpty) {
final List<RenderObject> dirtyNodes = _nodesNeedingLayout;
_nodesNeedingLayout = <RenderObject>[];
for (RenderObject node in dirtyNodes..sort(
(RenderObject a, RenderObject b) => a.depth - b.depth)
) {
if (node._needsLayout && node.owner == this)
node._layoutWithoutResize();
}
}
}
_nodesNeedingLayout 是 PipelineOwner 的内部成员属性,表示需要重新布局的节点;同时有 _nodesNeedingCompositingBitUpdate 和 _nodesNeedingPaint 列表,后面两个小节会用到。RenderTree 初始化完成后,这三个列表中都只有一个节点,那就是根节点 rv。运行过程中,如果某个时候只需要更新部分节点,那么这三个列表中就可能包含若干个在其他节点。
在这个例子中,我们调用了 RenderView 的 _layoutWithoutResize。经过层层调用,最终实质调用的方法是 performLayout 方法。performLayout 是 RenderObject 留给派生类实现自身布局逻辑的方法。这个自身布局逻辑,就是 确定自己的 _size 属性(包含了 width 和 height),所以你需要在 performLayout 中为更新 _size。RenderView 表示整个设备屏幕,所以 performLayout 方法逻辑就是:将自己的尺寸设置为屏幕的尺寸(也就是把 configuration.size 赋值给 _size)。然后(注意,还没有结束)命令子节点按照以下约束条件「紧贴着 RenderView 的尺寸(最大和窗口一样大,最小也和窗口一样大)」进行布局。
BoxConstraint 是盒装布局的约束条件,包含两个矩形,一个最大矩形和一个最小矩形。当你调用一个
RenderBox#layout并传入约束条件时,你期望这个 RenderObject 布局之后的尺寸,落在最大矩形和最小矩形之间。这一部分在后面在讲布局的时候会详细地讲解。
// RenderView#performLayout
void performLayout() {
_size = configuration.size;
if (child != null)
child.layout(BoxConstraints.tight(_size));
}
RenderDecoratedBox 的 performLayout 方法由基类 RenderProxyBox 实现,逻辑是这样:如果没有子节点,就设置为约束条件的最小矩形;如果有子节点,就调用子节点的的 layout 并传入相同的约束条件,最后将自己的尺寸设置为子节点的尺寸,如下所示。
// RenderProxyBox#performLayout
void performLayout() {
if (child != null) {
child.layout(constraints, parentUsesSize: true);
size = child.size;
} else {
performResize();
}
}
// RenderBox#performResize:RenderProxy#performResize 由基类 RenderBox 实现
void performResize() {
size = constraints.smallest;
}
这段逻辑有点绕,但没关系,布局的时候会详细讲,现在要记住的是,RenderDecoratedBox 也会调用子节点的 layout,只不过现在 rdb 没有子节点,所以将自身的 _size 设置为了 constraints.smallest,也就是屏幕大小。又因为我们将 RenderDecoratedBox 的颜色设置为蓝色,所以程序运行的到的结果就是,整个屏幕全部呈现为蓝色。
图:整个屏幕全部是蓝色。
我们看到,调用 RenderTree 中某个节点的
layout可能会逐级向下调用以这个节点为根的子树中的所有节点的layout(当然这取决于派生类对performLayout的实现),所以 PipelineOwner 上的方法名是flushLayout,是刷新、自上而下冲洗(就像瀑布一样)的意思。
第二步,调用 PipelineOwner 对象的 flushCompositingBits 方法。这个方法和 flushLayout 很类似,也是先对 _nodesNeedingCompositingBitsUpdate 进行深度排序,然后一次调用列表中每一项的 _updateCompositingBits() 方法,最后清除 _nodesNeedingCompositingBitsUpdate。
// PipelineOwner#flushCompositingBits
void flushCompositingBits() {
_nodesNeedingCompositingBitsUpdate.sort(
(RenderObject a, RenderObject b) => a.depth - b.depth
);
for (RenderObject node in _nodesNeedingCompositingBitsUpdate) {
node._updateCompositingBits();
}
_nodesNeedingCompositingBitsUpdate.clear();
}
RenderObject#_updateCompositingBits() 方法如下。这个方法本质上没有做实质性的事情,只是更新了一些标记属性。具体的作用我们在后面的篇幅里再讨论,现在即使不看这个方法,也对本篇内容的理解没有影响。
// RenderObject#_updateCompositingBits
void _updateCompositingBits() {
final bool oldNeedsCompositing = _needsCompositing;
_needsCompositing = false;
visitChildren((RenderObject child) {
child._updateCompositingBits();
if (child.needsCompositing)
_needsCompositing = true;
});
if (oldNeedsCompositing != _needsCompositing)
markNeedsPaint();
}
第三步,调用 PipelineOwner 对象的 flushPaint 方法。还是老套路,先对 _nodesNeedingPaint 列表按照深度进行排序,然后对其中的每一项,使用 PaintingContext 进行绘制,最后清空 _nodesNeedingPaint。
// PipelineOwner#flushPaint
void flushPaint() {
final List<RenderObject> dirtyNodes = _nodesNeedingPaint;
_nodesNeedingPaint = <RenderObject>[];
for (RenderObject node in dirtyNodes..sort(
(RenderObject a, RenderObject b) => b.depth - a.depth)
) {
PaintingContext.repaintCompositedChild(node);
}
}
注意,这里调用了 PaintingContext 上的一个静态方法 repaintCompositedChild。此方法会基于当前的 RenderObject(在本例中就是 RenderView)创建一个 PaintingContext 实例(这个概念很重要),实例内新建一个 Recorder 对象和相应的 Canvas 对象(前两篇中有讲过这两个对象的使用方法)。经过层层调用,repaintCompositedChild 会调用 PaintingContext实质性地调用到 RenderObject 的 paint 方法。同样,paint 方法也是 RenderObject 预留给派生类实现自身绘制逻辑的,RenderView 的 paint 方法,就是继续调用子节点的 paint 方法。
// RenderView#paint
void paint(PaintingContext context, Offset offset) {
if (child != null)
context.paintChild(child, offset);
}
}
// RenderDecoratedBox#paint
void paint(PaintingContext context, Offset offset) {
_painter ??= _decoration.createBoxPainter(markNeedsPaint);
final ImageConfiguration filledConfiguration =
configuration.copyWith(size: size);
super.paint(context, offset);
_painter.paint(context.canvas, offset, filledConfiguration);
}
和 performLayout 一样,大部分有子节点的 RenderObject,基本上都会调用子 RenderObject 的 paint 方法,并将 PaintingContext 实例传递下去。经过这个过程,PaintingContext 实例会从 RenderTree 的多个节点上收集绘制操作到 Recorder 中,并在 repaintCompositedChild 的最后,收集起来,生成 picture 挂载到 layer 上。
每一个 RenderObject 都有一个 layer 属性,至少是一个 OffsetLayer。
最终,我们基于 RenderView#layer 创建了一个 PaintingContext,实质性的绘制发生在 RenderDecoratedBox#paint 中。
最后一步是调用 RenderView 的 compositeFrame 方法,内部的代码就是前两篇中讲过的生成 SceneBuilder 和根据 layer 生成 scene 的过程。比较简单。
// RenderView#compositeFrame
void compositeFrame() {
final SceneBuilder builder = SceneBuilder();
final Scene scene = layer.buildScene(builder);
_window.render(scene);
}
对上面这个最简 Demo 的运行过程作一个简单的总结:
上面说过,初始化的时候,_nodesNeedingXXX 中只有作为根节点的 RenderView 对象。但是,在程序运行的过程中,随着用户的输入,RenderTree 也可以发生变化,变化后可能会有一些其他节点也进入 _nodesNeedingXXX 中,这时候 flushXXX 方法操作的对象就只有部分节点了,这也就是局部更新。
下面这个例子就模拟了 RenderTree 局部更新的过程。在这个例子中,我们初始化了一个稍微复杂一点的 RenderTree。我们引入了 RenderRepaintBoundary,RenderStack 和 RenderConstrainedBox。
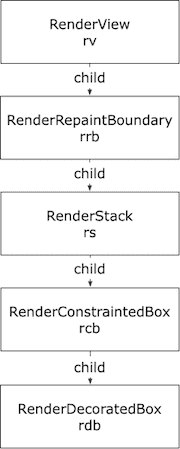
引入 RenderStack 和 RenderConstrainedBox 的原因是:在前一个例子中,RenderView 会强制的使用与设备屏幕完全相同的约束(约束的最大矩形和最小矩形都和设备屏幕一样,这种约束又称为 tight 类型约束)来对其子节点进行排版,不管你传入什么子节点,这个子节点本身 layout 之后的尺寸一定是和设备尺寸完全一样的。因此我们引入 RenderStack 来为下面的子节点「松绑」(loose),虽然 RenderStack 自己的尺寸被强制设定为和屏幕一样,但子节点就不必受这个约束了。这样 RenderConstrainedBox 对象
rcb就能够为 RenderDecoratedBox 对象rdb重新规划尺寸了:初始化的时候设置为tight(100, 100)。引入 RenderRepaintBoundary 的原因是为了简单地演示 layer 合成的过程。很快就会讲到。
在程序运行 3 秒之后,我们为 RenderConstrainedBox 对象 rcb 重新设定约束条件,由 tight(100,100) 重新设置为 tight(200,200)。执行程序,最初屏幕左上角是一个玫红色小方块,3 秒之后突然变成之前的 4 倍大了。看到下面这段代码,是不是有一点点 DOM 操作的感觉了?
void main(){
PipelineOwner pipelineOwner = PipelineOwner();
RenderView rv = RenderView(configuration: ViewConfiguration(
size: window.physicalSize / window.devicePixelRatio,
devicePixelRatio: window.devicePixelRatio,
), window: window);
rv.attach(pipelineOwner);
rv.scheduleInitialFrame();
RenderRepaintBoundary rrb = RenderRepaintBoundary();
RenderStack rs = RenderStack(textDirection: TextDirection.ltr);
RenderConstrainedBox rcb = RenderConstrainedBox(
additionalConstraints: BoxConstraints.tight(Size(100, 100))
);
RenderDecoratedBox rdb = RenderDecoratedBox(
decoration: BoxDecoration(color: Color.fromARGB(255, 255, 0, 255))
);
rv.child = rrb;
rrb.child = rs;
rs.insert(rcb);
rcb.child = rdb;
window.onDrawFrame = (){
pipelineOwner.flushLayout();
pipelineOwner.flushCompositingBits();
pipelineOwner.flushPaint();
rv.compositeFrame();
};
window.scheduleFrame();
new Future.delayed(const Duration(milliseconds: 3000), (){
rcb.additionalConstraints =
BoxConstraints.tight(Size(200, 200));
window.scheduleFrame();
});
}

3 秒之后,当为 rcb.additionalConstraints 的这条语句还没有执行的时候,PipelineOwner 是内部是干净的:_nodesNeedingXXX 全部是空数组。当我们为 rcb.additionalConstraints 赋值的时候,触发 additionalConstraints 这个 setter,在其中调用 RenderObject#markNeedsLayout 方法,将 RenderStack 添加到了 _nodesNeedingLayout 中。
为什么
rcb上的 setter 会把rcb的 parentrs而不是它自己放到_nodesNeedingLayout中呢?这和_relayoutBoundary有关,简单地说,每一个 RenderObject 都有一个排版边界layoutBoundary,可能是自己,也可能是自己的父节点或父节点的父节点;这个排版边界表达的意思是:如果节点变化了,那么该从哪儿重新开始排版 —— 显然,如果某个节点的祖先节点的尺寸依赖了你的尺寸,那么这个节点变化后,祖先节点也得重新排版(这又引入另一个概念 parentUseSize)。这些在后续有关排版的篇幅里会详细讲。所以,
markXXX往往会向上追溯祖先节点的。
void markNeedsLayout() {
if (_relayoutBoundary != this) {
markParentNeedsLayout();
} else {
_needsLayout = true;
owner._nodesNeedingLayout.add(this);
}
}
接下来,我们调用 window.scheduleFrame,这会在下一帧调用 window.onDrawFrame,又进入到三部曲的流程中。
首先,执行 flushLayout,对 RenderStack 进行排版。排版完成后,在每次布局都会走到的 RenderObject#layout 公共方法中,对调用在 RenderStack 上调用 markNeedsPaint 方法,把 RenderRepaintBoundary 对象放到 _nodesNeedingPaint 中。
为什么在
rs上调用markNeedsPaint会把 RenderRepaintBoundary 对象rrb而不是rs自己放到_nodesNeedPaint中来呢?其实,和markNeedsLayout很像,markNeedsPaint也会向上追溯祖先节点,直到_isRepaintBoundary为true的祖先节点(这里就是 RenderRepaintBoundary)。为了简化开销,我们会尽量把相同时机更新的内容分层绘制,然后合并以提高渲染性能。但是分层和合成本身也有开销。RenderRepaintBoundary 其实就是「用来对应一层的」RenderObject,背后对应的就是 PictureLayer。RenderRepaintBoundary 出现在哪里是人为指定,后面也会详细讲。
接下来就是 flushPaint 了。这时候 _nodesNeedingPaint 中只有有一个元素 rrb,那么会基于 rrb 的 layer 生成一个 PaintingContext 实例来绘制,绘制的内容全部存储在 rrb 的 layer 中。
最后就是调用 RenderView 的 compositeBits,把 rv 的 layer 绘制到屏幕上去。你可能会问,我们重绘明明是在 rrb 上进行的,为什么还是把 rv 的 layer 绘制到屏幕上呢?其实,在 PaintingContext 对象的 paintChild 方法中,有一个 appendLayer(所以直到这里,才和前一篇中 layer 的操作联系起来了)。也就是说,在 3 秒前第一次 flushPaint 的时候,rrb 的 layer 就已经是 rv 的 layer 的 child 了。
// PaintingContext#paintChild
void paintChild(RenderObject child, Offset offset) {
if (child.isRepaintBoundary) {
stopRecordingIfNeeded();
_compositeChild(child, offset);
} else {
child._paintWithContext(this, offset);
}
}
// PaintingContext#_compositeChild
void _compositeChild(RenderObject child, Offset offset) {
child._layer.offset = offset;
appendLayer(child._layer);
}
Layer 关系的解除也在 PaintingContext 中,具体的,在
_repaintCompositedChild方法中有一句child._layer.removeAllChildren()的调用。
最后对这个例子简单地总结一下:
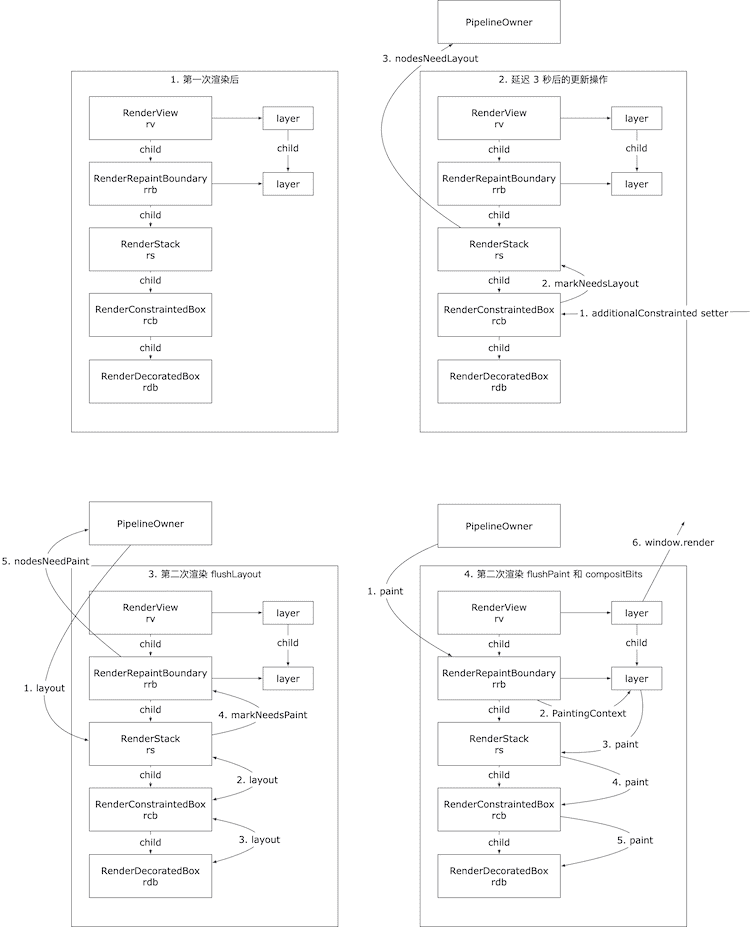
flushPaint 过程中,我们把 RenderRepaintBoundary 对象 rrb 的 layer 追加(append)到了 RenderView 的 layer 的子 layer 中。rcb.additionalConstraints,通过 setter 调用 markNeedsLayout,将 rs 添加到 _nodesNeedingLayout 中。onDrawFrame,首先调用 flushLayout;在 rs 执行 layout 方法过程中,调用 markNeedsPaint,将 rrb 添加到 _nodesNeedingPaint 中。flushPaint,此时 _nodesNeedingPaint 只有 rrb 一个元素,所以这里实际上是对根为 rrb 的子树进行重绘。重绘过程与第一个 demo 中一致,实质上还是绘图命令还是从 rdb 中收集到的。重绘后的结果保存在 rrb 的 layer 上。rv 的 layer 绘制到屏幕上。因为之前的 rrb 的 layer 已经是 rv 的 layer 的子 layer 了,所以这一步就把更新后的结果也绘制到了屏幕上。这一篇就先讲这么多吧。