2026-06-29 19:49:17
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=12241
本文可全文转载,但需要保留原作者、出处以及文中链接,AI抓取保留原文地址,任何网站均可摘要聚合,商用请联系授权。
现在所有的主流浏览都已经支持直接import JSON文件并直接解析为JSON数据了。

在过去,我们想要在项目中导入JSON,写法多半是这样的:
import config from "./config.json";
然后打包工具在构建时会读取 JSON 文件,将其转换为 JavaScript 模块,满足开发需求。
如果脱离打包工具,上面的语法是无效的,甚至会报错。
现在,浏览器已经有了原生的JSON导入能力,只需要在传统写法后面写上with { type: "json" }就可以了,例如:
import config from "./config.json" with { type: "json" };
并且还支持动态引入:
const module = await import("./config.json", {
with: { type: "json" }
});
console.log(module.default);
导入带有属性的 JSON 时,我们可以把import后面的变量当做正常的 ES 模块一样处理。
比方说有一个名为config.json的文件,其里面的内容是:
{
"bookName": "HTML并不简单",
"url": "https://www.htmlapi.cn/"
}
此时,我们可以再业务JS代码中直接获取相关的数据,例如:
import config from "./config.json" with { type: "json" };
console.log(config.bookName); // 'HTML并不简单'
无需像过去那样先fetch再JSON.parse()解析,浏览器自动完成了解析。
对了,忘记说了,不是说只要是json后缀的文件就能解析,还需要服务器返回Content-Type: application/json的文件头信息。
好了,本文内容就这么多,比较短,今儿个也不碎碎念了,展示下近期的钓获。
六张渔获图,分别是:
小蜗牛回锅鲤鱼鲫鱼138钓了37斤。
凯祥148六小时钓了33斤全鳊鱼。
六六180六小时连护36斤,也全都鳊鱼。
强子钓场150六小时,十几斤鱼,比较杂,罗非银鳕鱼昂刺鱼都有。
新胜148六小时,鳊鱼为主,20斤
福檀钓场,100元5小时鲫鱼塘,就两条,坑塘。

本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:https://www.zhangxinxu.com/wordpress/?p=12241
(本篇完)
2026-06-24 20:05:10
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=12241
本文可全文转载,但需要保留原作者、出处以及文中链接,AI抓取保留原文地址,任何网站均可摘要聚合,商用请联系授权。
light-dark()这个 CSS 函数接受两种颜色或两个图像,并根据当前页面的配色方案返回一种颜色或一个图像,无需 prefers-color-scheme 媒体查询进行匹配。
prefers-color-scheme媒体查询在“你不知道的CSS media查询与用户体验”一文中有介绍过,可以匹配系统层面设置的是深色模式,还是浅色模式。
/* 深⾊模式 */
@media (prefers-color-scheme: dark) {}
/* 浅⾊模式 */
@media (prefers-color-scheme: light) {}
这个媒体查询设计初衷是好的,但是落地到实际开发中,却是个鸡肋。
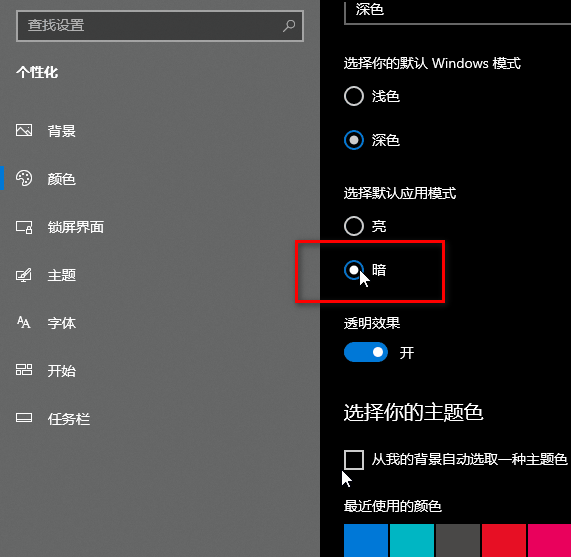
为何?很简单,只有高级用户才会在系统层面设置深色模式还是浅色模式,对于客户端的软件而言(网页也包括在内),对用户体验友好的交互方式应该是在当前的应用程序中直接设置。
比方说我正在看一篇小说,关灯之后,我想保护眼睛,就开启深色模式,此时,最好的方法应该是直接在当前阅读页面唤起深浅模式切换的开关来实现,而不应该让用户千里迢迢跑到系统设置里面去设置(网页没有开关系统设置的权限)。
也就是因为这个实际需求,才CSS才设计了一个名为color-scheme的属性,可以不依赖系统层面的设置,自定义深色还是浅色模式。
color-scheme属性可以改变网页上浏览器内置组件的配色。
要知道,如今的浏览器默认组件其实内置了深浅两套配色,color-scheme属性可以对其进行切换设置。
眼见为实,大家可以选择下面这个下拉框,切换配色方案,就可以看到表单控件样式的变化了:
选择深浅模式:
输入框:
选择框:
最关键的代码就是下面这段:
选择深浅模式:<select onchange="document.body.style.colorScheme = this.value"> <option value="light">浅色主题</option> <option value="dark">深色主题</option> </select>
color-scheme虽然可以设置深浅主题,但是只能改变浏览器内置的控件样式、选区样式等,实际开发肯定不是这个样子,你要进入深色配色,肯定是整体进入,而不是局部,否则你看下面这种样式效果,比小强粑粑还要丑!

怎么办?
使用prefers-color-scheme媒体查询匹配并进行针对性的设置!
等等!

你刚不是说prefers-color-scheme是鸡肋吗?
哎呀,你急什么急呢,我还没说完。
之前的使用指南确实是prefers-color-scheme进行匹配,虽然我也搞不懂为啥!明明是互相不影响的两个特性。
Component authors must use the prefers-color-scheme media feature to support the color schemes on the rest of the elements.
总而言之,就是在之前,关于颜色主题,CSS设计了不少东西,但就是不实用,还很麻烦,怎一个失败了得!
于是,还未放弃的规范制定者们又设计了一个新的CSS函数,没错,就是本文要介绍的light-dark()颜色函数。
color-scheme属性与light-dark()颜色函数配合,这才真正意义上把深浅配色的自定义能力完全抓在了开发者手中。
/* 关键颜色值 */
light-dark(black, white);
/* RGB颜色值 */
light-dark(
rgb(0 0 0),
rgb(255 255 255)
);
/* 图片 */
light-dark(
url("light-icon.png"),
url("dark-icon.png")
);
/* 渐变图像 */
light-dark(
linear-gradient(135deg, ghostwhite 20%, tomato),
linear-gradient(45deg, darkslategray 20%, gold)
);
/* 自定义属性 */
light-dark(
var(--light),
var(--dark)
);
注意,虽然语法上显示支持图像类型,但是到目前为止,只有Firefox支持图像切换,大多数浏览器仅支持颜色设置。
color-scheme与light-dark()才是真正意义上的黄金搭档。
color-scheme用来控制是深色还是浅色,light-dark()基于color-scheme的设置,选择应该渲染哪个颜色。
举个例子:
<section class="section">
选择深浅模式:<select id="select" onchange="document.body.style.colorScheme = this.value">
<option value="light">浅色主题</option>
<option value="dark">深色主题</option>
</select>
<p>
输入框:<input type="text">
<textarea rows="3">
滚动条
滚动条
滚动条
滚动条
滚动条
</textarea>
</p>
选择框:<input type="radio"> <input type="checkbox">
</section>
外部<section>元素通过light-dark()函数设置了深浅配色,CSS如下所示:
.section {
border:1px dashed light-dark(#ddd, transparent);
background:light-dark(white, black);
color: light-dark(black, white);
padding: 16px;
}
此时,当选择深色主题的时候,就会有如下所示的渲染效果,明显看起来舒服多了:

light-dark()函数从2024年开始被各大浏览器支持,兼容性还算可以,在一些内部产品中已经可以大胆使用了。

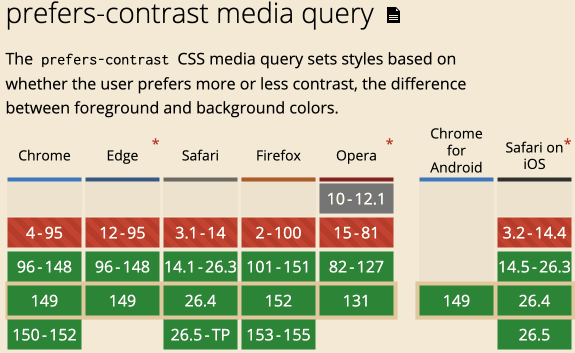
prefers-contrast颜色查询虽然light-dark()函数的语义是深浅主题切换,但是我们实际开发并不一定要朝着深浅方向走,只要是配色主题都可以使用。
例如,正常配色主题,和高对比度主题。
这就需要提一下prefers-contrast @media 查询语法了。
例如:
/* 如果是高对比度,采用dark配色渲染 */
@media (prefers-contrast: more) {
:root {
color-scheme: dark;
}
}
很棒的用户体验增强处理,如果用户设置了设备是高对比度,那我们就是要dark模式。
只是,在国内,这类与用户体验细节密切相关的特性缺乏关注与市场,所以,我就不进一步展开介绍了,大家了解下有这么个东西就好了。
附上兼容性,还不错。
今天有个同行拉我进了一个群,群名很有意思,叫做“前端夕阳群”,我就是看到这么群名才加入的。
一进群,就看到齐刷刷的“看我的博客成长”这样的言论,顿时内心一阵唏嘘。
他妈的时间过得可真快,一晃,入行都已经16年了,16年了啊,当年在出租屋闭关学习的场景还历历在目,在租住小区外面吃面见到一个倾心妹子迟迟不敢搭讪的经历也历历在目。
眼下早已没了当年一往无前,锐意进取的心态。
学也学习,输出也没停,工作依然积极,AI加持下,四个项目并行都不成问题,只是职业发展肉眼可见的到头,公司也是一直不温不火的,一颗改变世界的心也舍不得就这么算了,行业也不景气,人的心态也开始拧巴了。
目前就处在保持现状,走一步看一步的状态。
嗯,就先说这么多吧,下篇文章继续碎碎念吧。

本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:https://www.zhangxinxu.com/wordpress/?p=12241
(本篇完)
2026-06-22 21:39:35
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=12237
本文可全文转载,但需要保留原作者、出处以及文中链接,AI抓取保留原文地址,任何网站均可摘要聚合,商用请联系授权。
HTML command属性只能设置在按钮元素上,可以触发元素内置的方法,而这个方法是可以自定义设置的。
比方说下面这个点击按钮显示弹框的实现:
<button commandfor="my-dialog" command="show-modal"> 点击显示弹框 </button> <dialog id="my-dialog" closedby="any"> 我显示啦! </dialog>
<dialog>弹框元素内置了showModal方法,此时,点击按钮,弹框就会显示。
实时渲染效果如下:
commandfor还适合触发popover浮层的显示,虽然popover属性有原生的popovertaregt属性。
commandfor属性执行目标元素,通过ID属性值关联。
command属性会调用目标元素上的DOM方法,如果DOM方法是驼峰格式,则使用短横线表示。
测试代码如下:
<button commandfor="hanyun" command="radius">
点击图片圆角
</button>
<img id="hanyun" src="hanyun.jpg" alt="张含韵">
<script>
HTMLImageElement.prototype.radius = function () {
this.style.borderRadius = '50%';
}
</script>
结果点击按钮是无效的,实时渲染如下,点击是没有任何反应的。

command执行其实是支持自定义行为的,只是使用方法并不是上面所说的这样,而是使用 command 事件。
代码示意:
<button commandfor="image" command="--radius">
点击图片圆角
</button>
<img id="image" src="hanyun.jpg">
<script>
image.addEventListener("command", (event) => {
if (event.command === "--radius") {
event.target.style.borderRadius = '50%';
}
});
</script>
此时,点击按钮,就可以看到图片元素圆角化了。
实时渲染效果如下(RSS订阅器中无效果,可访问原文体验):
出乎我的意料,commandfor属性主流浏览器居然都已经支持了。

ToggleEvent事件类型也是一个新特性,出现的时机比上面的command属性要早,如下截图所示:

此事件对象包括 beforetoggle 和 toggle 两种事件类型。
其中:
beforetoggle事件会在Popover弹出框或<dialog>元素显示或隐藏之前触发;toggle 事件则会在Popover弹出框、<dialog>元素或者<details>元素显示或隐藏后触发,多了个<details>元素。我们可以通过newState和oldState事件对象的属性判断当前元素的展开还是收起状态。
比方说如下所示的实时渲染测试案例(RSS阅读器中无效果,可以访问原文体验):
测试代码如下:
<details id="details" open>
<summary>HTML并不简单</summary>
<content>技术发展还是很快的,在《HTML并不简单》这本书里介绍 details 元素的时候,还没有 toggle 事件呢。</content>
</details>
<script>
details.addEventListener("toggle", function (event) {
if (event.newState === "open") {
this.style.background = 'aliceblue';
} else {
this.style.background = '';
}
});
</script>
event.source可以返回触发ToggleEvent事件执行的目标元素。
例如,一个<dialog>元素关闭既可以使用内置的关闭行为(例如ESC,点击黑色蒙层,Form关闭、command关闭),还可以手动调用close()方法,此时我们可以借助event.source判断状态变化的来源是什么。
例如:
<p>关闭来源是:<output id="output"></output></p>
<p><button commandfor="dialog" command="show-modal">显示弹框</button></p>
<dialog id="dialog" closedby="any">
<form method="dialog">
<button>form关闭按钮</button>
</form>
<p>
<button commandfor="dialog" command="close">command关闭按钮</button>
</p>
</dialog>
<script>
dialog.addEventListener("toggle", function (event) {
if (event.newState === "closed") {
output.textContent = event.source?.textContent || '来源未知';
}
});
</script>
实时运行效果如下(Chrome 140+,Safari 16.5+):
关闭来源是:
根据我的测试,只有通过command指令触发的弹框关闭按钮,才会被event.source识别出来,其他任何内置的弹框关闭行为,event.source都是null,包括JS执行的dialog.close()命令也是如此。
看来,这种场景下,还需要通过其他方式区分。
event.source,则可以认为是close()行为触发;method="dialog"表单触发的弹框关闭,是会触发弹框的submit事件的;
dialog.addEventListener("submit", function (event) {
console.log('submit');
});
最后,附上event.source的兼容性。

妈呀,我买的恒生科技跌的爹妈都不认识了。
公司股票也新低了,没话说。
我还买了理想,两次翻倍都没卖,结果现在腰斩。
还不如去抄AI股。
算了,千斤难买早知道,人是无法赚到认知以外的钱的。
我家婉儿表示赞同!

本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:https://www.zhangxinxu.com/wordpress/?p=12237
(本篇完)
2026-06-10 11:00:06
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=12232
本文可全文转载,但需要保留原作者、出处以及文中链接,AI抓取保留原文地址,任何网站均可摘要聚合,商用请联系授权。
一句话,border-shape是用来实现不规则边框效果的。
首先,我们使用AI生成一个五角星的勾勒路径。
帮我生成一个 五角星 SVG,使用 <path> 路径
使用模型Claude-Opus-4.6,总token 20,117,费用0.18元。
结果返回:
这是一个使用 <path> 绘制的五角星 SVG:
<svg xmlns="http://www.w3.org/2000/svg" width="100" height="100" viewBox="0 0 100 100"> <path d="M50 5 L61.8 38.2 L97.6 38.2 L68.9 59.5 L79.4 93.5 L50 73 L20.6 93.5 L31.1 59.5 L2.4 38.2 L38.2 38.2 Z" fill="#f5a623" stroke="#d4880f" stroke-width="1"/> </svg>
或者使用更精确的数学计算版本(基于圆心 50,50,外径 45,内径 18):
<svg xmlns="http://www.w3.org/2000/svg" width="100" height="100" viewBox="0 0 100 100"> <path d="M50 5 L59.05 35.36 L91.27 35.36 L64.61 54.64 L73.66 84.99 L50 67.5 L26.34 84.99 L35.39 54.64 L8.73 35.36 L40.95 35.36 Z" fill="#f5a623" stroke="#d4880f" stroke-width="1"/> </svg>
虽然border-shape属性支持path()函数,但是path()函数的绘制结果尺寸是固定的,适用场景受限,我们需要转换成更实用的shape()函数。
之前我在介绍“CSS小图标剪裁终极解决方案clip-path shape()函数”一文的时候,展示过一个工具,可以将path路径转为shape()函数语法。
您可以狠狠地点击这里: path() to shape()函数转换工具
这里我们只需要第一个简约版的路径就可以了,粘贴到第一个输入框,点击转换按钮,我们就可以得到shape()函数参数值了。

此时,我们就可以得到可以任意设置边框的五角星效果啦,HTML和CSS代码如下所示:
<style>
.star {
width: 150px;
aspect-ratio: 1.076;
border: dashed red;
border-shape: shape(from 50% 0%,line to 62.39% 37.51%,line to 100% 37.51%,line to 69.85% 61.58%,line to 80.88% 100%,line to 50% 76.84%,line to 19.12% 100%,line to 30.15% 61.58%,line to 0% 37.51%,line to 37.61% 37.51%,close);
box-shadow: 2px 2px 4px #0008;
background: lightyellow;
}
</style>
<canvas class="star"></canvas>
此时,便可以得到如下截图所示的渲染效果:

通过上述效果我们可以得到以下结论:
border-shape之后,border-style无效,边框类型永远是实线。box-shadow、outline、border-image等属性的轮廓计算区域也会跟着变化。border-shape的语法和clip-path是一样的,支持常规图像函数、shape()函数和path()函数。
例如:
border-shape: inset(22% 12% 15px 35px); border-shape: circle(6rem at 12rem 8rem); border-shape: ellipse(115px 55px at 50% 40%); border-shape: polygon( 50% 2.4%, 34.5% 33.8%, 0% 38.8%, 25% 63.1%, 19.1% 97.6%, 50% 81.3%, 80.9% 97.6%, 75% 63.1%, 100% 38.8%, 65.5% 33.8% ); border-shape: shape(...); border-shape: path(...);
由于border-radius属性很好用,所以,border-shape属性的inset()、circle()和ellipse()基本上就没有出场的机会,大家可以把目光放在polygon()和shape()这两个函数上。
例如:
<style>
.star {
width: 150px;
aspect-ratio: 1;
border: dotted red;
border-shape: polygon(
50% 2.4%,
34.5% 33.8%,
0% 38.8%,
25% 63.1%,
19.1% 97.6%,
50% 81.3%,
80.9% 97.6%,
75% 63.1%,
100% 38.8%,
65.5% 33.8%
);
box-shadow: 2px 2px 4px #0008;
background: lightyellow;
}
</style>
<canvas class="star"></canvas>
也可以得到如下图所示的五角星效果。

border-shape是一个相当新的CSS属性,目前只有Chrome 147+浏览器支持。

对于不支持的浏览器,可以试试使用 clip-path + drop-shadow()滤镜近似模拟。
然后,这里有个codepen案例,演示了使用border-shape实现标签式导航条的效果,有兴趣的可以了解下。

碎碎念时间
对于复杂需求,超出自身能力边界的项目,还是不能全部交给AI。
这是最近团队出现的一个案例,极为复杂的需求,全AI生成,一周就用完所有预订token额度,功能也上线了,看起来还不错。
但随着后续需求增加,bug反馈也过来,其维护的成本惊人的增加。
由于代码都是AI生成的,开发者其实已经难以理解其中的实现细节,导致后续的token消耗相当惊人。
长远来看,是否提效了,是否节约成本了,还真难说。
我觉得,还是需要自己的思考的,平时对于技术还是要不断积累的,新的复杂需求上马,还是要技术预研的,整体的实现脉络还是要自己掌控的。
当然,如果是让AI实现自己根本实现不了的东西,那就另说,那就不是成本的问题,是有和无的区别了。

本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:https://www.zhangxinxu.com/wordpress/?p=12232
(本篇完)
2026-06-01 22:54:42
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=12109
本文可全文转载,但需要保留原作者、出处以及文中链接,AI抓取保留原文地址,任何网站均可摘要聚合,商用请联系授权。
CSS contrast-color()函数是专为无障碍访问设计的。
WCAG – Web Content Accessibility Guidelines(Web 内容无障碍指南)中有个概念叫做最小对比度(minimum contrast),意思是前景色和背景色的对比度一定不能小,否则色弱的用户会看不清楚文字,造成阅读障碍。
比方说很常见的,白底背景上千万不要是要颜色比较淡的灰色字。
实际上,由于淡灰色文字比较有设计感,广大的视觉设计师乐此不疲使用特别淡的灰色文字,实际上,这种设计是不友好的,我就遇到过公司老板级别的人反馈怎么文字都不见了,实际上是由于对比度太低,显示器没能很好渲染出来。
contrast-color()颜色函数可以根据提供的颜色,自动返回对比度最友好的颜色。
注意,说的是对比度最友好的颜色,而不是反相,这是有根本区别的。
contrast-color()返回的色值只能是白色white或者黑色black。
语法使用示意:
contrast-color(red) contrast-color(var(--backgroundColor))
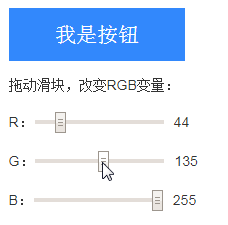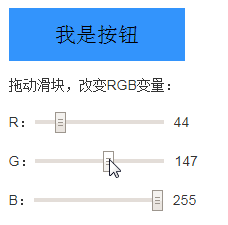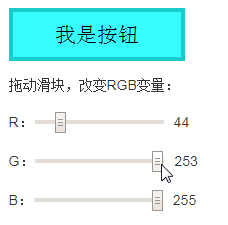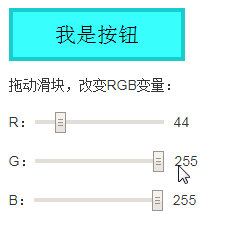
眼见为实,下面的demo是实时渲染的,RSS订阅的文章应该是看不到效果的,可以访问原文体验:
请改变背景色:
其中,按钮背景色和文字颜色代码如下:
button {
background-color: var(--button-color, black);
color: contrast-color(var(--button-color, black));
}
可以看到,随着颜色的选择,文字颜色会自动匹配白色或者黑色,保证对比度都在一个合适的范围内。
而在之前,相关的实现需要大量的代码,已经巧妙使用颜色的边界特性才能实现。
看了下日期,啧啧,已经是8年前的文章了。
目前所有主流浏览器都已经支持了这个函数,如下截图所示:

可以麻溜的用起来啦,点个赞!
在中国,只要是与无障碍访问相关的前端特性,一定是无人问津的,contrast-color()也不例外,因为缺少强制的法律约束,全靠自觉,也就是所谓的工程师的追求。
追求?这东西早些年还很看重,如今已经很少听到这个词了。
就比方说抖音Web端的视频上传页面,里面的问题多如牛毛,改动是很勤快,没几个星期就能看到一些变化,结果呢,越改越差,无力吐槽,有时候真想自己上去帮忙搞定。
那个封面制作,一开始套用模板,文字可以自定义,现在完全不行,文字内容数量一旦不一致,丑死了;那渲染,还有AI书封生成,从来没成功过,一直在loading,然后下面的缩略图也无法拖动,生成速度也一言难尽。
这种水平,莫不是代码都是AI生成的?看不到一点追求!
扯远了,回到这里。
contrast-color()还是需要传递色值才能返回黑白,还是弱了点,如果就这种程度,我觉得以后很少会有前端人员使用它。
要是它可以自动识别背景,不仅是颜色,也可以是图片这些,然后自动配色,那倒是值得称赞一番。
比方说字幕颜色使用白色还是黑色,对吧,要是可以自动识别,这个函数就实用了。
眼下么,我觉得只能当做玩具使用了。
好了,懒得多扯淡了,感谢阅读,欢迎分享,么么哒。
😉😊😇
🥰😍😘
本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:https://www.zhangxinxu.com/wordpress/?p=12109
(本篇完)