2026-04-27 10:18:36
本文内容来自《AI Engineering Building Applications with Foundation Models》这本书里面的总结。
对于评估不是简单的让地让 AI Judge 打个 1-5 分,这样做显然效果会很差,评估体系,评估方法,甚至评估标准都没明确说明, 即使是再牛逼的AI Judge也无法做好整个评估体系。
用一个例子说明。
假设你做一个 RAG 客服机器人,用户问:
我买的耳机用了 20 天,左耳没声音了,可以退货还是只能维修?知识库里有两条规则:
1. 商品签收后 7 天内可无理由退货。
2. 7 天后、保修期内出现质量问题,可申请维修或换货。模型回答 A:
你已经使用了 20 天,超过 7 天无理由退货期限。
如果左耳没声音属于质量问题,可以申请维修或换货。
建议你提交售后申请,并提供订单号和故障说明。模型回答 B:
可以退货。耳机质量有问题的话,一般都可以直接退款。模型回答 C:
根据政策,你的耳机已经超过 7 天无理由退货期限。
如果左耳没声音属于质量问题,可以申请维修或换货。
另外,我们会补偿你一张 50 元优惠券。如果只用一个 AI Judge 打分问:
这个回答好不好?可能会出现主观上觉得 C 不错,安抚了用户,并且有理有据,但是事实上编造了“50 元优惠券”。所以我们应该把这个问题拆细了看。
比如我们可以拆成这几类问题:
这个回答有没有违反硬性规则? → deterministic check
它有没有覆盖标准答案里的关键点? → reference-based evaluation
它有没有编造上下文没有的内容? → faithfulness / groundedness
它整体是否有帮助、清晰、符合语气? → AI judge
它比另一个版本更好吗? → pairwise comparison
它有没有线上真实用户认可? → user feedback / human audit也就是说:
开放式任务评估 = 硬规则检查 + 事实检查 + 语义覆盖 + 主观质量评分 + 版本对比 + 人工抽检那么我们再来给上面的回答评价,结果可信度就会高很多:
| 评估维度 | A | B | C |
|---|---|---|---|
| 是否符合政策 |  |
 |
|
| 是否覆盖关键事实 | |
|
|
| 是否有 hallucination |
无 |
无 |
有 |
| 是否回答用户问题 | |
部分 | |
| 是否清晰易懂 | |
|
|
| 是否安全可上线 | |
|
|
这组体系,主要是回答了什么是好,以及好在哪里。
上面也说明了,评估在与怎么定义好与坏,好与坏又是由一系列的指标定义的,所以这一节来讲讲怎么拆指标。
先评估能客观验证的部分,这部分可以用代码进行校验。
输出是否是合法 JSON?
是否包含必须字段?
是否调用了正确 tool?
是否调用了禁止 tool?
是否超过 token 限制?
是否包含敏感词?
是否引用了不存在的 source?
是否返回了空答案?例子:你要求模型输出:
{
"answer": "...",
"citations": ["doc_1", "doc_2"],
"confidence": 0.83
}那第一步直接校验:
JSON parse 是否成功
answer 是否非空
citations 是否存在
confidence 是否在 0 到 1 之间
citations 是否真的来自检索结果这个阶段不判断“回答是否优雅”,只判断格式和流程是否合规。
这层用于判断模型有没有覆盖标准答案里的关键点。比如可以给每个测试 case 写一个 reference answer,或者更工程化一点,写成 required facts。例如:
{
"query": "用了 20 天耳机坏了可以退吗?",
"required_facts": [
"超过 7 天无理由退货期限",
"质量问题可申请维修或换货",
"需要提交售后申请"
],
"forbidden_claims": [
"可以直接退款",
"一定可以退货",
"补偿优惠券"
]
}然后评估:
required_facts_coverage = 覆盖了几个必要事实
forbidden_claims_count = 出现了几个禁止说法比如有这么几个回答:
| 回答 | required facts coverage | forbidden claims |
|---|---|---|
| A | 3/3 | 0 |
| B | 0/3 | 1 |
| C | 3/3 | 1 |
这样你就能区分:
模型说的每一句事实,是否都能被 context 支持?
还是刚才的回答 C:
根据政策,你的耳机已经超过 7 天无理由退货期限。
如果左耳没声音属于质量问题,可以申请维修或换货。
另外,我们会补偿你一张 50 元优惠券。前两句有 context 支持,最后一句没有。
你可以让 AI Judge 做 claim-level 检查:
Context:
1. 商品签收后 7 天内可无理由退货。
2. 7 天后、保修期内出现质量问题,可申请维修或换货。
Answer:
根据政策,你的耳机已经超过 7 天无理由退货期限。
如果左耳没声音属于质量问题,可以申请维修或换货。
另外,我们会补偿你一张 50 元优惠券。
请逐条抽取 Answer 中的事实声明,并判断每条是否被 Context 支持。
输出:
- claim
- supported: true/false
- evidence可能输出:
[
{
"claim": "超过 7 天无理由退货期限",
"supported": true,
"evidence": "商品签收后 7 天内可无理由退货"
},
{
"claim": "质量问题可申请维修或换货",
"supported": true,
"evidence": "7 天后、保修期内出现质量问题,可申请维修或换货"
},
{
"claim": "会补偿 50 元优惠券",
"supported": false,
"evidence": null
}
]这个比问“回答是否 grounded,打 1-5 分”更稳,因为它把判断拆到了事实声明级别。
有些维度没法完全用代码判断,比如:
是否有帮助?
是否解释清楚?
是否啰嗦?
是否符合品牌语气?
是否安抚了用户情绪?
是否给了下一步行动?这时候主要靠 AI Judge ,但 judge prompt 必须明确标准。使用 AI judge 时要说明任务、评价标准、评分系统;而且分类式评分通常比连续数值评分更可靠。
例如你可以不要让它打 0.73 分,而是让它分类:
请评估回答是否满足“客服可上线标准”。
评价维度:
1. 是否直接回答用户问题
2. 是否给出明确下一步
3. 是否语气专业、不过度承诺
4. 是否没有多余营销话术
输出:
- pass / fail
- failed_dimensions
- reason比如回答 A:
{
"pass": true,
"failed_dimensions": [],
"reason": "回答直接说明不能无理由退货,但可申请维修或换货,并给出提交售后申请的下一步。"
}回答 B:
{
"pass": false,
"failed_dimensions": ["不过度承诺", "政策准确性"],
"reason": "回答承诺可以退货/退款,但知识库只支持维修或换货。"
}注意:AI Judge 适合判断“软质量”,但不应该替代前面的硬规则和事实检查。
这层不是判断一个回答绝对好不好,而是判断:
Prompt v2 是否比 Prompt v1 更好?
RAG 策略 B 是否比 RAG 策略 A 更好?
模型 B 是否比模型 A 更适合这个场景?例如你在优化 prompt。
用户问题:
我买的耳机用了 20 天,左耳没声音了,可以退货还是只能维修?Prompt v1 输出:
超过 7 天一般不能退货,可以联系售后。Prompt v2 输出:
你已经超过 7 天无理由退货期限,因此通常不能直接退货。
如果左耳没声音属于质量问题,可以申请维修或换货。
建议你提交售后申请,并附上订单号和故障说明。Pairwise judge:
在不编造政策的前提下,哪个回答更适合作为客服回复?
A: ...
B: ...
输出 winner: A/B/tie,并说明原因。结果:
{
"winner": "B",
"reason": "B 同时说明了退货限制、质量问题处理方式和下一步操作,比 A 更完整。"
}但是它有一个限制:
B 比 A 好,不代表 B 一定可以上线。
所以你还需要绝对指标,除了上面所说的指标以外还可以结合 ai agent工程化用到的指标:tool call 成功/准确率、延迟情况、用户差评率等。
AI 系统评估不能只看最终答案,也不能只靠一个总分。你要把系统拆成组件,把“好回答”拆成明确评价标准和评分标准,再用多套评价数据覆盖真实分布、高风险场景、历史 bad case 和越界输入。
所以评估 AI Agent Pipeline 不是一个“打分脚本”,而是 AI 应用的质量控制系统。可以理解为:
Evaluation Pipeline = AI Agent 的 CI/CD 质量门禁 + 回归测试 + 线上质量监控 + bad case 归因系统真实 AI 应用不是一个单模型调用,而是一条链路。比如要做一个简历 PDF 提取当前雇主:
Step 1: 从 PDF 提取文本
Step 2: 从文本中提取当前雇主如果最终雇主提取错了,原因可能是:
PDF → Text 解析错了
Text → Employer 抽取错了如果只看最终结果,你不知道系统失败在哪一步。
假设我们 AI Agent 整个流程是这样:
User Query
↓
Intent Detection
↓
Query Rewrite
↓
Retrieval / Tool Selection
↓
Tool Call
↓
Context Assembly
↓
Final Answer Generation
↓
Guardrail / Safety Check
↓
Response那么应该分别评估:
| 组件 | 要评估什么 |
|---|---|
| Intent Detection | 是否识别对用户意图 |
| Query Rewrite | 改写后是否保留原意,是否更利于检索 |
| Retrieval | 是否召回正确文档,context 是否相关 |
| Rerank | 正确文档是否排在前面 |
| Tool Selection | 是否选择正确工具 |
| Tool Arguments | 参数是否正确、完整、合法 |
| Context Assembly | 是否拼接了必要上下文,是否塞入无关信息 |
| Final Answer | 是否事实正确、完整、有帮助 |
| Guardrail | 是否拦截危险请求或违规输出 |
| End-to-End | 用户任务是否最终完成 |
这样你才能做故障归因。例如用户问:
我的订单 12345 为什么退款失败?Agent 最终回答错了,你要知道到底是:
没有识别成 refund_failure_query
没有调用 order_refund_status 工具
调用工具时 order_id 参数错了
工具返回了正确结果,但模型解释错了
模型回答正确,但安全策略误拦截了如果没有组件级评估,你只能看到“最后错了”,无法知道该改 Prompt、改 Retriever、改 Tool Schema,还是改业务逻辑。
创建 guideline ,不仅要定义应用应该做什么,也要定义它不应该做什么。比如客服机器人是否应该回答和产品无关的选举问题?如果不应该,就要定义什么是 out-of-scope,怎么检测,以及应该如何回复。
首先我们要明确一点:正确答案不等于好答案。模型回答“你非常不适合这份工作”可能事实上是正确的,但它不是一个好回答,因为它没有帮助用户理解差距,也没有告诉用户如何改进。一个好回答应该解释职位要求和候选人背景之间的差距,并说明候选人可以怎么弥补这些差距。
这句话对 AI 应用评估很关键:
Correct ≠ Good再来一些例子比如:
事实正确,但语气伤人
事实正确,但没有下一步建议
事实正确,但没有引用依据
事实正确,但太长,用户看不懂
事实正确,但违反业务策略
事实正确,但暴露内部信息除此之外还要让模型明白 should do 和 shouldn’t do,guideline 不仅要定义应用应该做什么,也要定义它不应该做什么。比如客服机器人是否应该回答和产品无关的问题;如果不应该,就要定义哪些输入是 out-of-scope、怎么检测、怎么响应。
很多团队只写正向要求:
回答要准确
回答要有帮助
回答要简洁但没有写负向边界:
不能编造政策
不能承诺退款
不能提供法律建议
不能回答产品无关问题
不能暴露内部 SOP
不能执行高风险写操作
不能在缺少订单号时查询订单
不能把用户引导到不存在的流程结果模型出了问题之后,团队才补规则。
一个好的 guideline 应该先把边界写清楚:
| 类型 | 应该定义的问题 |
|---|---|
| In-scope | 哪些问题属于应用职责范围 |
| Out-of-scope | 哪些问题不应该回答 |
| Refusal | 不回答时应该怎么说 |
| Escalation | 什么时候转人工 |
| Safety | 哪些内容必须拦截 |
| Business policy | 哪些承诺不能做 |
| Tool boundary | 哪些工具可读,哪些工具可写,什么时候能调用 |
| Privacy | 哪些用户信息不能输出 |
| Source boundary | 回答必须基于哪些上下文,不允许用哪些来源 |
比如客服应用的三个常见 criteria:
1. Relevance:回答是否和用户问题相关
2. Factual consistency:回答是否和上下文事实一致
3. Safety:回答是否安全、无毒、有边界也就是说,一个好回答至少要相关、和上下文事实一致,并且不含有害内容。那么这些标准其实和业务本身有关的。一个比较完整的 Agent evaluation criteria 可以是:
| Criterion | 评价问题 |
|---|---|
| Relevance | 是否回答了用户真正的问题 |
| Faithfulness | 是否严格基于 context / tool result |
| Completeness | 是否覆盖必要信息 |
| Instruction Following | 是否遵守格式、角色、输出约束 |
| Tool Correctness | 是否选择了正确工具 |
| Tool Argument Correctness | 工具参数是否正确、完整、合法 |
| Task Success | 最终是否完成用户任务 |
| Safety / Policy | 是否违反安全或业务规则 |
| Helpfulness | 是否给出有用下一步 |
| Efficiency | 是否用尽量少的轮次、工具和 token 完成任务 |
| User Experience | 语气是否合适,是否减少用户负担 |
为了形成 criteria,可以先拿一些测试 query,最好是真实用户 query;对每个 query 生成多个 response,可以人工写,也可以用 AI 生成,然后判断哪些好、哪些坏。一般可以这么做:
收集真实 query
↓
生成多个候选回答
↓
人工判断好坏
↓
归纳坏回答类型
↓
把坏回答类型变成 criteria
↓
把 criteria 写成 rubric定义 criteria 还不够,还要定义评分标准,也就是 rubric。每个 criterion 都要选择评分系统,可以是二分类 0/1、1 到 5、0 到 1,或者其他形式。比如评估回答是否和上下文一致,有的团队用 0/1,有的团队用三值:contradiction、entailment、neutral。选择哪种评分方式取决于你的数据和需求。
选择哪种评分体系取决于数据和需求。然后要为每个分数写清楚样例,并让人类验证 rubric 是否容易理解。
例如你要评估客服 Agent 的回答是否忠实于知识库,可以这样定义:
| 分数 | 标准 |
|---|---|
| 5 | 所有事实声明都能被 context 支持,没有额外编造 |
| 4 | 基本正确,有轻微泛化,但不影响用户决策 |
| 3 | 主要结论正确,但有部分不被 context 支持的描述 |
| 2 | 存在关键事实错误,可能误导用户 |
| 1 | 编造关键政策、承诺、赔偿或流程 |
对应例子:
Context:
7 天内可无理由退货。
7 天后质量问题可维修或换货。
Answer A:
你已超过 7 天无理由退货期限。如果属于质量问题,可以申请维修或换货。
Score: 5
Answer B:
你已超过 7 天,但可以直接退款。
Score: 2
Answer C:
你可以直接退款,并获得 50 元补偿券。
Score: 1最后我们这套体系需要标注的评估数据来评估系统的每个组件和每个 criterion。能用真实生产数据最好;如果应用天然有标签,就直接利用;如果没有,可以用人类或 AI 标注。
数据不是只给最终回答用的,很多人构建 eval set 时只写:
{
"query": "...",
"reference_answer": "..."
}这对简单问答够用,但对 Agent 不够。因为 Agent 有很多中间组件:
intent detection
query rewrite
retrieval
rerank
tool selection
tool args
planning
final answer
safety check所以 eval data 也应该包含组件级标注。例如:
{
"case_id": "refund_001",
"user_query": "我的耳机用了 20 天坏了,可以退吗?",
"expected_intent": "after_sales_policy",
"gold_documents": ["return_policy_v3", "warranty_policy_v2"],
"expected_tool_calls": [
{
"tool": "get_order_status",
"required": false
}
],
"required_facts": [
"超过 7 天无理由退货期限",
"质量问题可维修或换货"
],
"forbidden_claims": [
"可以直接退款",
"补偿优惠券",
"一定可以退货"
],
"reference_answer": "超过 7 天无理由退货期限,不能直接无理由退货。如果属于质量问题,可以申请维修或换货,并提交售后申请。",
"tags": ["refund", "after_sales", "high_risk"]
}这样你就可以分别评估:
intent 是否正确
retrieval 是否命中 policy
tool 是否该调用
最终回答是否覆盖 required facts
是否出现 forbidden claims把数据拆成多个 subset,然后分别看系统在每个 subset 上的表现。这样可以避免偏差、帮助 debug、发现改进方向。比如对于某个场景如果你只看整体:
overall task_success_rate = 88%你可能觉得系统不错,但切开之后可能是:
普通 FAQ:95%
退款政策:72%
多轮订单查询:68%
英文输入:91%
中英混合输入:61%
prompt injection:35%这时候整体 88% 没意义,因为关键风险场景很差。
引用 OpenAI 的粗略估计:如果你想以 95% 置信度判断一个系统比另一个系统好,能检测到的差异越小,需要的样本越多。大致是:
| 想检测的分数差异 | 需要样本量 |
|---|---|
| 30% | 约 10 |
| 10% | 约 100 |
| 3% | 约 1,000 |
| 1% | 约 10,000 |
作为参考,Eleuther 的 lm-evaluation-harness 里 benchmark 的中位样本数约 1,000,平均约 2,159;Inverse Scaling Prize 组织者建议 300 是绝对最低值,更希望至少 1,000,尤其当样本是合成生成的。
不用一开始就追求 10,000 条 eval case。可以分层:
开发调试集:30-50 条
日常回归集:200-500 条
发布前主评估集:1,000+ 条
核心高风险集:100-300 条,但人工精标
线上抽样评估:持续积累如果你只是想快速判断 prompt_v2 是否明显比 prompt_v1 好,几十到几百条可能够用。
这一部分主要是我想要把整个评价体系设计成一个 闭环 workflow,分成 5 个阶段:
Stage 0:定义评估标准
Stage 1:离线评估
Stage 2:发布前门禁
Stage 3:线上评估 / A/B Test
Stage 4:线上数据回流到离线评估集由这 5 个阶段构建成一个循环:
离线评估:用可控数据判断“能不能发”
↓
灰度 / A/B:用真实流量判断“上线后是否真的更好”
↓
线上反馈与日志:发现真实 bad case / good case
↓
人工或 AI 标注:沉淀成新的离线评估集
↓
下一轮 prompt / RAG / agent / model 迭代在离线和线上之前,必须先定义同一套 criteria。比如你做的是 AI Agent / RAG 客服系统,criteria 可以是:
| Criterion | 离线怎么评 | 线上怎么观察 |
|---|---|---|
| Relevance | AI judge / semantic similarity | 用户是否继续追问“你没回答我” |
| Faithfulness | claim-level judge / NLI | 点踩、投诉、人工客服纠错 |
| Tool Correctness | expected tool match | tool error rate、人工介入率 |
| Task Success | 标注任务是否完成 | 用户是否完成退款/查询/下单 |
| Safety / Policy | rule + classifier + judge | 违规拦截、投诉、风控命中 |
| Helpfulness | AI judge / 人工打分 | 点赞率、二次追问率、转人工率 |
| Cost / Latency | telemetry | p95 latency、cost per task |
首先就是和上面提到一样,离线评估数据集的构建,要做到离线数据集分层和细化,比如分成几类:
| 数据集 | 用途 |
|---|---|
dev_eval_set |
日常 prompt / RAG / agent 调试 |
golden_eval_set |
高质量人工标注,用于核心回归 |
production_like_set |
模拟真实线上分布 |
high_risk_set |
退款、账单、赔偿、合规等高风险 |
known_bad_cases_set |
历史 bad case,防止回归 |
tool_required_set |
必须调用工具的问题 |
no_tool_set |
不应该调用工具的问题 |
out_of_scope_set |
越界请求,测试拒答 |
prompt_injection_set |
测试攻击鲁棒性 |
multi_turn_set |
多轮任务完成 |
然后就是离线评估打分 / 分类。
第一层:确定性检查,能用代码判断的,不要交给 LLM。比如 JSON schema 是否合法;
第二层:参考答案 / 必要事实评估,用于判断回答是否覆盖关键点;
第三层:AI Judge / 人工评估,用于开放式质量;
最后就是离线评估输出,并且输出详细的subset结果,而不是一个总分。
离线评估跑完后,不是看“总分高一点就发”,而是设 release gate。
例如:
必须满足:
- overall task_success_rate >= 85%
- high_risk_policy_pass_rate >= 99%
- forbidden_claim_rate <= 0.5%
- tool_call_correct_rate >= 98%
- faithfulness_avg >= 4.5
- known_bad_cases_pass_rate = 100%
- p95 latency <= 5s
- cost_per_task <= $0.01这里有一个重点:
known_bad_cases_pass_rate 最好要求 100%。历史上踩过的坑,不能回归。
如果你是做 prompt 迭代,发布前可以这样比较:
| 指标 | baseline | candidate | 是否通过 |
|---|---|---|---|
| task success | 84% | 87% | |
| high-risk pass | 99.2% | 98.7% | |
| faithfulness | 4.4 | 4.6 | |
| latency p95 | 3.8s | 4.9s | |
| cost/task | $0.004 | $0.007 | |
虽然 candidate 总体更好,但 high-risk pass 下降了,所以不能直接上线。
这一部分可以包括线上用户打分:点赞 / 点踩。建议点踩时让用户选择原因:
- 没有回答我的问题
- 回答不准确
- 信息过时
- 编造内容
- 太啰嗦
- 没有给下一步
- 工具结果错误
- 其他点赞也可以收集轻量原因:
- 解决了我的问题
- 解释清楚
- 推荐有用
- 操作步骤明确还可以做线上隐式反馈 implicit feedback,比如下面信号:
| 信号 | 可能含义 |
|---|---|
| 用户继续问同一个问题 | 上一轮没解决 |
| 用户改写问题重问 | 回答不相关或不清楚 |
| 用户要求转人工 | Agent 没解决或用户不信任 |
| 用户点击推荐项 | 推荐可能有效 |
| 用户完成操作 | task success |
| 用户退出 | 可能解决了,也可能放弃了 |
| 投诉 / 工单升级 | 高风险失败 |
| 人工客服改写答案 | Agent 输出质量不足 |
A/B test 的价值是判断线上真实效果。比如对于 AI Agent,A/B test 应该这样设计:
Control:当前线上版本
Treatment:新 prompt / 新 model / 新 RAG 策略 / 新 agent planner一次实验尽量只改一个主要变量,否则无法归因。具体设计应该要根据当前的任务和需求而定。
因为真实的例子更有利于构建我们的评估体系,并且只收集好的例子不够,评价体系最值钱的通常是 bad cases 和 hard cases,所以总体应该包括:
抽样真实好例子 + 真实坏例子 + 边界例子,经过验证后,构建和更新离线评估数据集。抽取完这些线上的例子之后,就可以构建数据回流流程,可以是这样:
线上日志采集
↓
自动打标签:点赞/点踩、转人工、投诉、tool error、latency、cost
↓
规则过滤:去 PII、去重、去低质量日志
↓
样本分桶:good / bad / hard / high-risk / out-of-scope
↓
AI 预标注:required facts、错误类型、风险类型
↓
人工复核:重点看 high-risk、bad、ambiguous
↓
写入离线评估集
↓
版本化:eval_dataset_vN《AI Engineering Building Applications with Foundation Models》
2026-04-06 22:47:01
opencode 的 context也是分为这几部分:
AGENTS.md / CLAUDE.md / CONTEXT.md,全局 ~/.claude/CLAUDE.md,config.instructions 中配置的文件或 URL┌─────────────────────────────────────────┐
│ System Prompt │
│ ├── 环境信息(模型名、目录、平台、日期) │
│ ├── Skills 列表 │
│ └── 指令文件(AGENTS.md / CLAUDE.md) │
├─────────────────────────────────────────┤
│ Messages(历史 + 本轮) │
│ user → assistant → user → assistant… │
└─────────────────────────────────────────┘除此之外,上下文窗口管理还有三层机制防止上下文溢出(下面也会详细介绍):
"[Old tool result content cleared]"。工具调用的结构(input/output 字段)保留,只清空 output 内容,这样不会破坏 Anthropic 要求的 tool_use/tool_result 配对。Prompt Caching 是大模型提供商提供的一种优化机制:将某些内容(通常是较长且重复的前缀)在服务端缓存起来,后续请求命中缓存后跳过对该部分的重新计算,从而降低延迟和成本(缓存命中的 token 通常价格更低)。
Prompt Caching 通过一般是在调用的时候通过给 context 打标记实现,比如当使用 Claude 的时候会选择前两条 system + 最后两条对话打标记,因为System prompt 内容几乎不变,最后两条对话消息是模型下一步推理的直接上文,命中率最高。
打了标记后,Anthropic API 会在服务端把这段内容写入缓存,下次相同请求直接复用,不重新计算。
大致装配好之后是这样:
messages = [
{ role: "system", content: system[0] }, // ← cache 标记
{ role: "system", content: system[1] }, // ← cache 标记
...历史对话消息,
...最后两条 // ← cache 标记
]compact 是“总结历史,重建上下文”。
prune 是“保留历史骨架,清空很老的 tool 输出正文”。
Compact
之后在正常对话里,filterCompacted() 会以这条 summary 为边界,只保留“summary 之后的有效历史”,见 message-v2.ts (line 810)。
什么时候用 compact
主要在上下文接近/超过模型限制时。触发点在 prompt.ts (line 547):
if (task?.type === "compaction") {
const result = await SessionCompaction.process({
messages: msgs,
parentID: lastUser.id,
abort,
sessionID,
auto: task.auto,
overflow: task.overflow,
})
if (result === "stop") break
continue
}Prune
SessionCompaction.prune({ sessionID })第一层是“单次工具输出截断”
在 truncation.ts (line 11):
这意味着一次工具调用就算返回特别大的文本,也不会原样塞回会话上下文。MCP 工具返回文本时就会走这层,见 prompt.ts (line 894) 附近 Truncate.output(…)。
最后会输出成:
const hint = hasTaskTool(agent)
? `The tool call succeeded but the output was truncated. Full output saved to: ${filepath}\nUse the Task tool to have explore agent process this file with Grep and Read (with offset/limit). Do NOT read the full file yourself - delegate to save context.`
: `The tool call succeeded but the output was truncated. Full output saved to: ${filepath}\nUse Grep to search the full content or Read with offset/limit to view specific sections.`
const message =
direction === "head"
? `${preview}\n\n...${removed} ${unit} truncated...\n\n${hint}`
: `...${removed} ${unit} truncated...\n\n${hint}\n\n${preview}`第二层是“跨多轮的旧 tool output 清理”
就是上面提到到 prune:
SessionCompaction.isOverflow() 在 compaction.ts (line 25) 会根据:
判断是否接近上下文上限。
一旦超限,就自动创建 compaction 任务,把旧历史总结掉。
在 processor.ts (line 126):
这防的是 agent 在循环里重复打同一个工具,导致历史疯狂增长。
2026-03-22 17:51:12
所有LLM都受到有限上下文窗口的限制,这迫使模型在“一次可以看到什么”方面做出艰难的权衡。上下文工程就是将这个窗口视为一种稀缺资源,并围绕它设计一切(检索、记忆系统、工具集成、提示等),以确保模型只将其有限的注意力预算花在有价值的token。
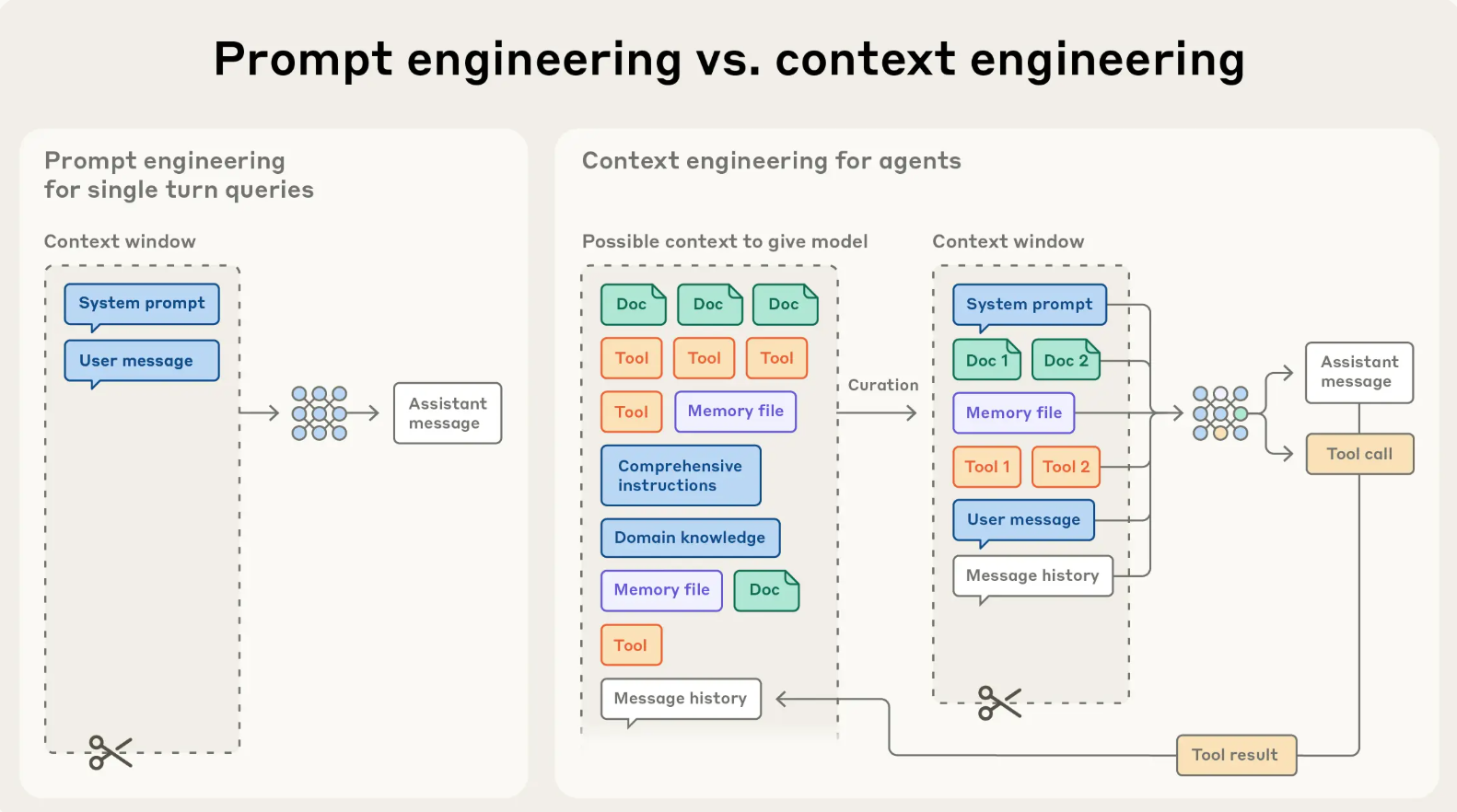
看起来和 Prompt Engineering 差不多,但是侧重点是不一样的。Prompt Engineering 侧重是提示词文本本身,Context Engineering 是模型看到的整个输入上下文系统,也就是prompt 只是 context 的一部分,真正决定模型输出质量的,往往不只是那段 instruction,而是整个上下文构造过程。
在早期使用逻辑逻辑模型(LLM)进行工程设计时,prompt是人工智能工程工作中最重要的组成部分,因为大多数日常聊天交互之外的应用场景都需要针对一次性分类或文本生成任务优化的prompt。顾名思义,prompt工程的主要重点在于如何编写有效的prompt,尤其是系统prompt。然而,随着我们朝着构建功能更强大的智能体方向发展,这些智能体需要在多轮推理和更长的时间跨度内运行,我们需要管理整个上下文状态(系统指令、工具、MCP、外部数据、消息历史记录等)的策略。
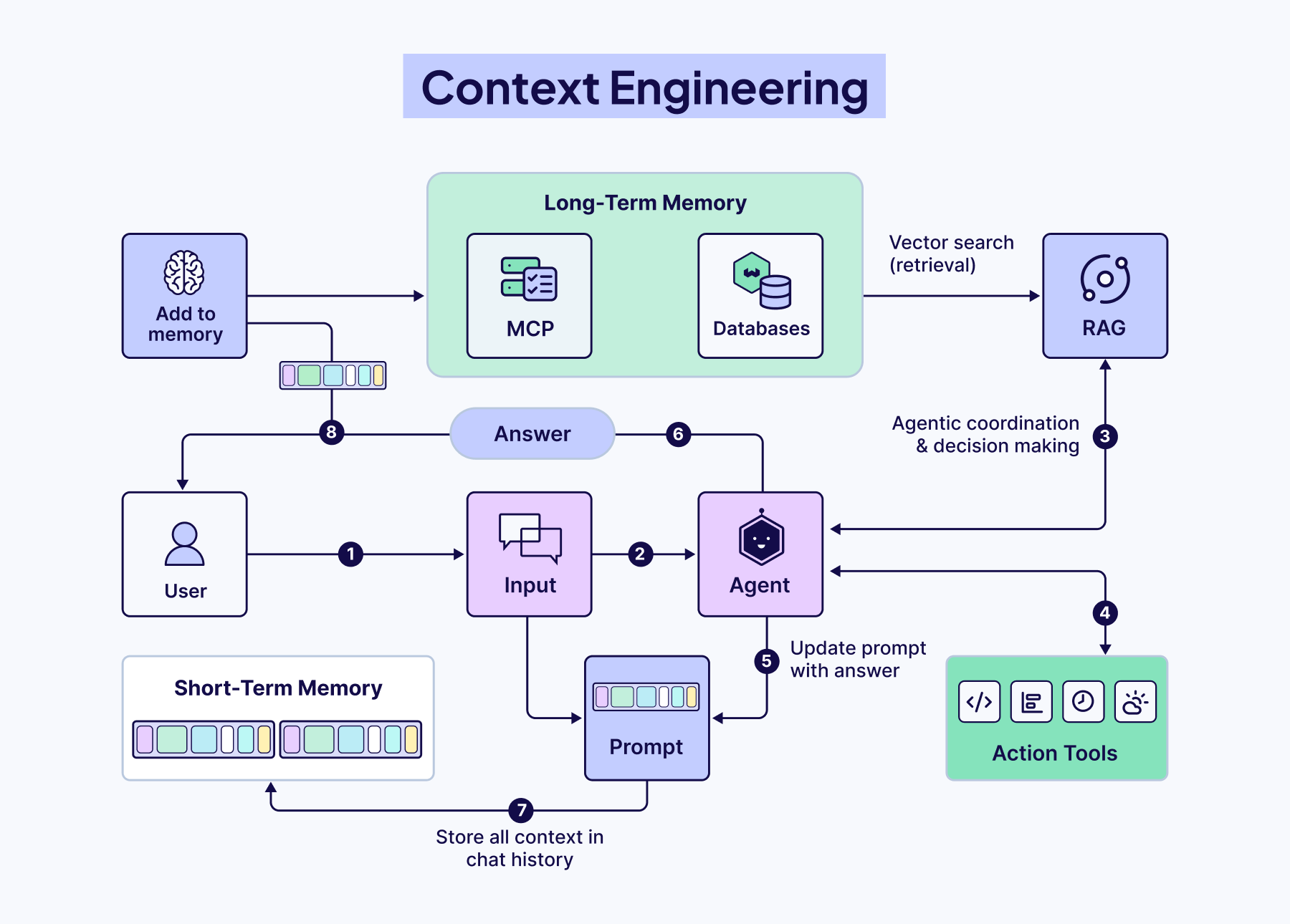
也就是在单轮请求场景中,模型的输入主要只有两块:System prompt、User message,只是做一个简单的输入然后回答。但是对于 agent 场景要复杂的多,因为 agent 不是纯聊天,它的执行流程很长,一般会有:
所以 agent 是一个循环式工作流,不是一次性输入输出,那么在多轮工作流中,就需要从这些上下文中输出中“捞出”并“整理”出最正确的素材,而怎么筛选出最正确的内容就是Context Engineering 要做的事情。
虽然现在的模型号称拥有百万级甚至千万级的上下文窗口(Context Window),但它们对信息的处理并不是“一视同仁”的。随着上下文变长,模型提取和处理信息的能力会像有机物腐烂一样逐渐变差,这种现象也叫 context rot。
典型的代理循环包含两个主要步骤:模型调用 ->工具执行,这个循环会持续到LLM决定结束,这些返回都会不断的拼接到模型的 context 里面。特别是工具调用后返回的结果会作为Observation拼接到模型里面,这部份内容经常会特别长,这样长的Observation不断地拼接到上下文message中,最后很有可能超过了模型最长能够接受的上下文长度(比如128K~1M)。
如果没有有效的 Context Engineering 来应对,Context Rot 会导致以下几个层面的严重后果:
Context Engineering 对上下文的管理并不是简单的“复制粘贴”,而是一套精密的信息物流系统。其核心目标是:在不超出 Token 限制的前提下,将最高价值的信息精准送达模型最敏感的“注意力区域”。
Compression 压缩
其本质是:在尽量保留原始语义(Information Integrity)的前提下,通过算法减少传递给模型的 Token 数量。一般有几种做法:
{"status": 200, "data": {"user": {"id": 1, "name": "Alice", "bio": "Extremely long bio text..."}}},可以裁剪成:Found user: Alice (ID: 1);Sub-agent architectures 子代理架构
子代理架构提供了另一种绕过上下文限制的方法。与其让一个代理尝试维护整个项目的状态,不如让专门的子代理在清晰的上下文窗口中处理特定的任务。主代理负责协调高层计划,而子代理则执行深入的技术工作或使用工具查找相关信息。每个子代理可能进行广泛的探索,使用数万个或更多令牌,但最终只返回其工作的精简摘要(通常包含 1000 到 2000 个令牌)。
如果你让一个 Agent 重构整个项目:
这种方式确保了编写代码的 Agent 不会被上千行的“语法报错日志”或“冗长的库文档”干扰注意力。
Use the File System as Context 使用文件作为上下文的补充
因为在 Agent 的多轮交互当中即使现在 context 可以达到 200M 以上的大小,但是依然可能会不够,因为 Tool result 可能会非常的大,尤其是在 Agent 与网页或 PDF 等非结构化数据交互时,很容易超出上下文限制。并且 Agent 在多轮交互过程中,需要保存各种 reasoning 信息,成功或失败的调用 tool 的结果都需要保存,导致再长的context也不够用。
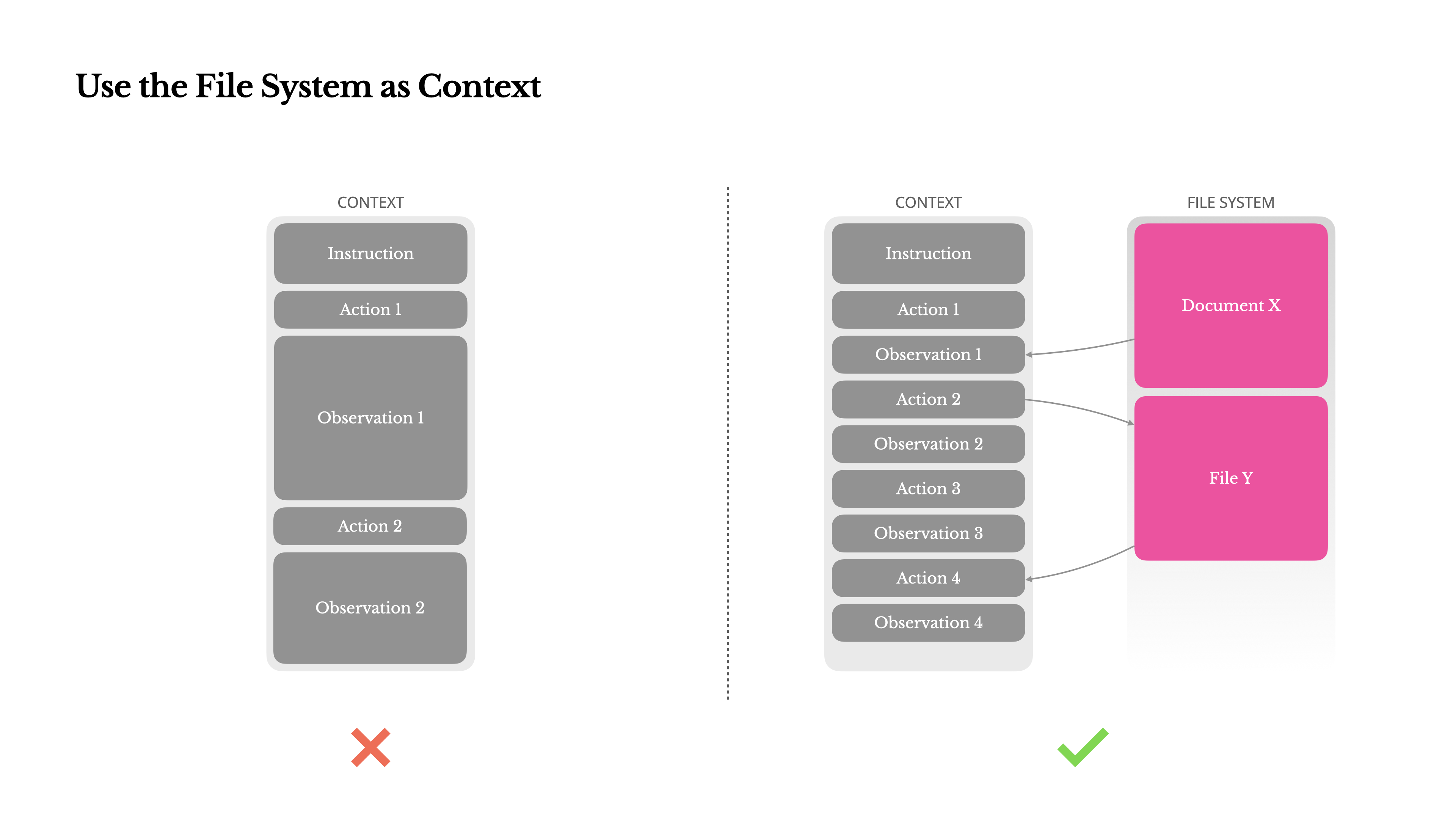
为了解决这个问题,许多 Agent 系统都采用了上下文截断或压缩策略。但过度压缩不可避免地会导致信息丢失。所以不管是 Claude 还是 Manus 都建议将文件作为外部的 context 来使用。可以利用文件系统来存储 Agent 的中间思考状态,解决长时程任务中的 Context Rot 问题。
比如可以让 Agent 在该文件中实时记录:
auth.py 的报错是因为版本不兼容”)。然后提供一套能够精准操作文件系统的工具,Agent 后续可以通过head、tail、grep等命令渐进式地查看,或一次性读取整个文件。这种方式既减少了上下文占用,又保留了完整信息。
由于模型存在“中间信息丢失(Lost in the Middle)”的倾向,必须将最重要的信息放在 Prompt 的两端。顺序上通常是:
System / Global Instructions
User Profile / Long-term Memory
Relevant Conversation History
Current Task / Current Question
Retrieved Knowledge / Tool Results
Working Summary / Constraints / Output format核心逻辑是:
如果中间数据太长,建议在底部 Query 之前增加一句:请基于上述 <context> 里的信息回答以下问题:。
因为模型最容易根据上下文有关联的链路来理解内容例如:
问题 -> 证据 -> 回答而不是下面这样:
证据A -> 旧history -> 证据B -> memory -> question后者很容易让模型搞不清哪些证据是给当前任务用的。
使用明确的 XML 标签 或 Markdown 标记 是目前公认最有效的隔离方式,因为它能显著降低模型对“数据”和“指令”的混淆。比如这样:
<system_instructions>
你是一个代码审计专家。请遵循 <security_policy> 进行分析。
</system_instructions>
<security_policy>
1. 严禁泄露 API Key。
2. 优先检查 SQL 注入漏洞。
</security_policy>
<context_data>
[此处存放 RAG 检索到的代码片段或文档]
</context_data>
<tool_outputs>
[此处存放上一步执行 grep 或 linter 的原始输出]
</tool_outputs>
<user_query>
基于以上背景,分析 src/auth.py 的安全性。
</user_query>在拼接之前,必须对各部分内容进行预处理,提升信号密度:
data 字段,丢弃 headers、metadata 等噪音。Summary。Token 预算动态分配
在拼接逻辑中,建议为各部分设置权重(Weights),防止某一部分过长导致“爆仓”或挤掉核心指令。
| 模块 | 建议权重/策略 | 溢出处理 |
|---|---|---|
| System Prompt | 100% 保留(最高优先级) | 绝不截断 |
| Current Query | 100% 保留(最高优先级) | 绝不截断 |
| RAG Context | 40% 预算 | 按相似度评分从低到高丢弃 |
| History | 30% 预算 | 采用滑动窗口或摘要化 |
| Tool Results | 20% 预算 | 只保留最新结果,旧结果仅保留结论 |
并非所有上下文都需要同时存在于 context window 中。透过 LLM 驱动的路由逻辑,系统可以根据当前查询的性质和业务领域,动态决定注入哪些知识片段。例如,当使用者询问财务问题时,系统注入财务相关文件与对话历史;当话题转向技术问题时,动态替换为技术文件。
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
https://manus.im/zh-cn/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
https://docs.langchain.com/oss/python/langchain/context-engineering#the-agent-loop
https://weaviate.io/blog/context-engineering
https://zhuanlan.zhihu.com/p/2012088406826562496
https://research.trychroma.com/context-rot
https://blog.langchain.com/context-engineering-for-agents/
AI Agent 的上下文系统:Context Engineering 指南最先出现在luozhiyun`s Blog。
2026-03-08 16:07:08
随着 AI Agent 技术演进,从目前来看 AI Agent 架构大概被划分越来越清晰,我们参考《The Rise and Potential of Large Language Model Based Agents: A Survey》这篇论文里面的 Agent 架构定义,大概划分为以下几个部分:
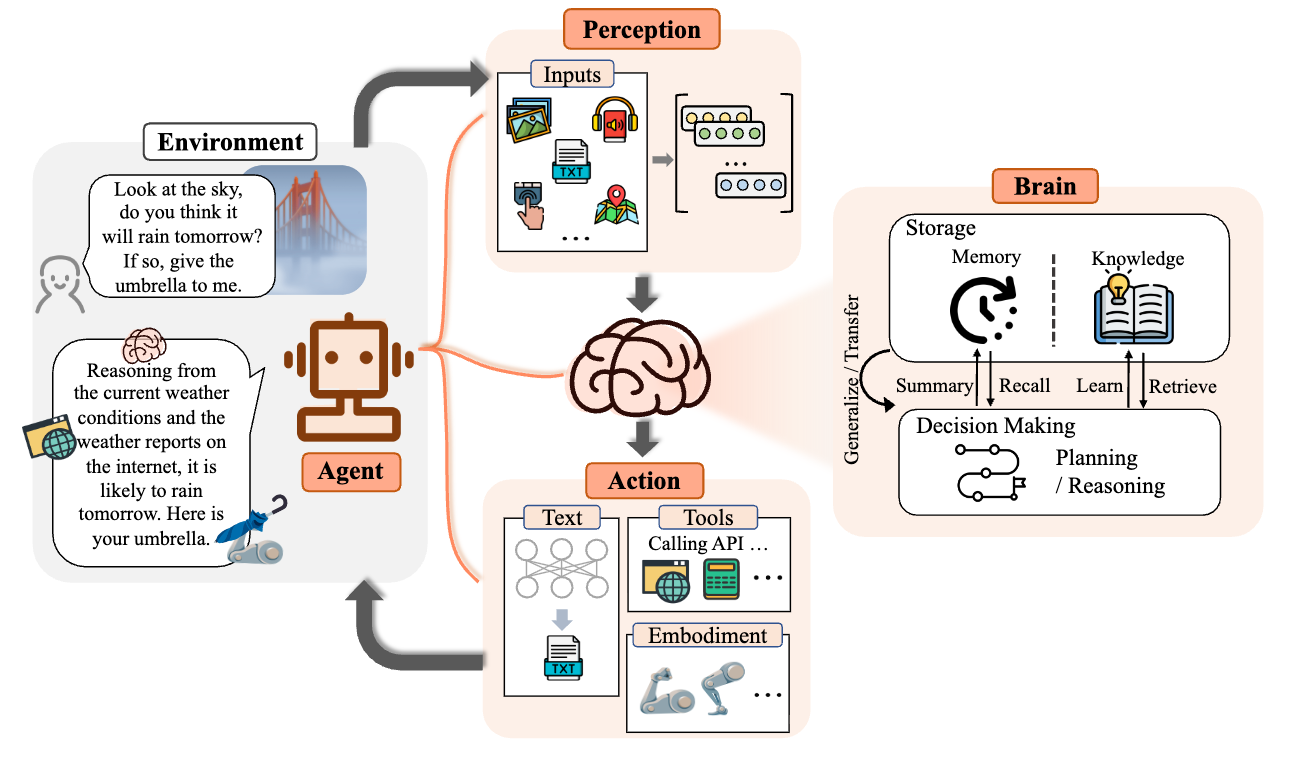
那么我们本篇文章讨论的“记忆”其实是更广泛的存储区这块功能。对于 AI Agent 记忆来说,记忆其实就有点像脑容量,其核心必要性体现在以下三点:
上下文一致性 (Contextual Consistency):
Agent 需要记住之前的对话内容,才能理解当前的指令。例如,如果你先说“帮我订一张去上海的机票”,接着说“改到明天”,Agent 必须记得“去上海的机票”这个前提。
长期偏好学习 (Personalization):
通过记忆,Agent 可以学习用户的习惯(如:你偏好 Python 而不是 Java,或者你习惯在周五下午复盘)。
复杂任务拆解 (Task Decomposition & Planning):
在执行多步任务(如:写代码 -> 测试 -> 找 Bug -> 修复)时,Agent 需要记录每一步的状态,确保不会陷入循环或丢失进度。
在 AI Agent 领域记忆通常效仿人类的认知结构,分为以下层次:
短期记忆 (Short-term Memory):利用大模型的 Context Window(上下文窗口),将最近的几轮对话记录直接放入 Prompt 中发送给模型,抑或是工具调用结果、中间推理状态、任务临时变量,但是受限于模型能够处理的最大 Token 数量,一旦对话过长,旧的信息就会被“挤出”。
这部份数据我们可以存储在内存中,配合TTL(Time To Live)机制进行自动清理。这种设计的优势在于访问速度极快,但也意味着工作记忆的内容在系统重启后会丢失。这种特性正好符合工作记忆的定位,存储临时的、易变的信息。
长期记忆 (Long-term Memory):这相当于人类的“经验仓库”,可以存储海量信息并在需要时检索,可以通过各种数据库进行存储,一般来说可以做如下分类:
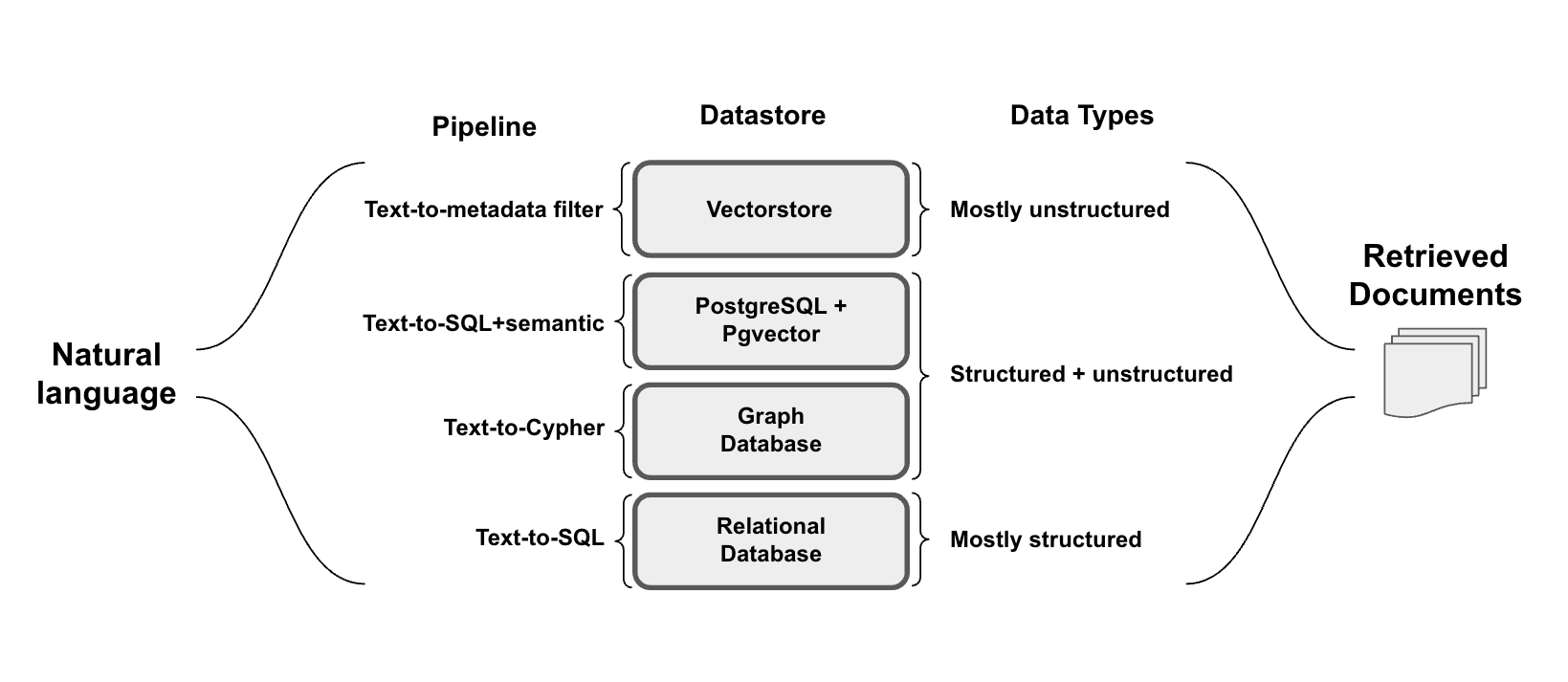
所以我这里借用一下 langchain 官方的一张图,agent memory 的存储其实就是选用合适存储的过程,针对不同数据类型将自然语言查询转化为特定数据库查询的方法。
记忆的核心操作其实就两个:
对于存储关于世界和 Agent 自身的事实性知识,我们通过 RAG(检索增强生成)所调用的外部知识库来实现,这部份我们单独拿出来说。这里我们先说说记录 Agent 过去的经历和日志的情境记忆 (Episodic Memory)。
我们将这种Episodic Memory分为三部份来进行存储:
存储的核心主要包含两个关键阶段:
提取阶段(Extraction Phase):
系统从当前的对话消息和历史背景中,动态地提取出“显著信息”(Salient Information)。它不是简单地存储对话记录,而是将其转化为简练、事实性的“记忆片断”。
更新与整合阶段(Update Phase):
当新的记忆提取出来后,将其与现有的相似记忆进行对比:
做提取核心原因是把“原始对话”压缩成“可检索、可更新、可复用”的结构化记忆。
我们这里使用 LLM 抽取,让模型按固定格式输出{"facts":[...]},灵活、效果好,是现在最常见方案。主要是分成这么几步来实现:
user:/assistant:/system ;{"facts":[...]}
我们来看个例子具体怎么提取的:
对话输入:
user 会提取出:
{
"facts": [
"名字是小王",
"在北京做后端开发",
"乳糖不耐受",
"平时喜欢跑步"
]
}assistant 会提取出:
{
"facts": [
"擅长 Python 和系统设计",
"回答风格尽量简洁",
"偏好用表格总结"
]
}再看一个“无可提取信息”的例子,对话输入:
{"facts": []}这一阶段会用第一阶段提取出来的 facts 来进行记忆的更新与整合。主要是分成这么几步来实现:
我们在让 LLM 做更新决策的时候需要根据 4 个明确模块,降低 LLM 自由发挥空间:
放入“操作规则与判定标准”
在我们给定的 UPDATE_MEMORY_PROMPT 里面需要定义了 ADD/UPDATE/DELETE/NONE 的语义和多个 few-shot 示例,让 LLM 具体了解到更新规则;
放入“当前记忆状态”
如果有旧记忆,就把旧记忆数组包在代码块里;否则明确写 Current memory is empty。这样 LLM 是在“当前状态机”上做增删改,而不是凭空生成。比如这样拼接 prompt:
if retrieved_old_memory_dict:
current_memory_part = f"""
Below is the current content of my memory which I have collected till now. You have to update it in the following format only:
{retrieved_old_memory_dict}
else:
current_memory_part = """Current memory is empty. """放入“新 facts 输入”
把新抽取的 facts 明确告诉模型:你只需要判断这些新事实对当前记忆该怎么处理。比如这样:
The new retrieved facts are mentioned in the triple backticks. You have to analyze the new retrieved facts and determine whether these facts should be added, updated, or deleted in the memory.最后强约束输出格式
函数把目标输出 schema 写死为:{"memory":[{"id","text","event","old_memory"}]},并加“Do not return anything except JSON format”这能显著提高可解析性,方便后续程序按 event 执行。
我们举个完整例子:
假设旧记忆是:
[
{"id": "0", "text": "喜欢奶酪披萨"},
{"id": "1", "text": "是后端工程师"}
]新 facts 是:
["喜欢鸡肉披萨", "在准备转管理岗"]然后 LLM 可能返回:
{
"memory": [
{
"id": "0",
"text": "喜欢奶酪和鸡肉披萨",
"event": "UPDATE",
"old_memory": "喜欢奶酪披萨"
},
{
"id": "1",
"text": "是后端工程师",
"event": "NONE"
},
{
"id": "2",
"text": "在准备转管理岗",
"event": "ADD"
}
]
}后续程序按 event 执行真正落库(新增/更新/删除)。
再来将一下Graph存储怎么做。Graph核心优势在于它不再是零散的“事实点”,而是形成了“知识网”。在处理复杂逻辑、跨时空关联和深度偏好挖掘时,这种方式比简单的纯文本记忆要强大得多,并且不像向量数据库只能进行相似度进行检索,而是可以沿着已知的节点和边,像找地图一样寻找关联。
我们来举例几个场景:
复杂的人际关系网(社交/CRM 场景)
如果一个 AI 助理只记录纯文本,它可能记得“王总喜欢红酒”和“李女士是王总的太太”。但当你要策划一场晚宴时,基于图的记忆能迅速通过“配偶”关系推导出两者的关联,AI 就可以根据提问信息进行实体和关系的抽取:
王总、李女士、红酒
[王总] --(配偶)--> [李女士],[王总] --(偏好)--> [红酒]
跨 session 的逻辑排产与项目追踪
在长期的项目管理中,任务之间存在前置、后置和依赖关系。比如根据我们的文档 AI 可以抽离出下面实体和关系:
模块 A 设计、前端开发、后端 API、张工
[前端开发] --(依赖于)--> [后端 API],[张工] --(负责)--> [后端 API]
如果张工今天请假了,基于图的记忆能立刻感知到:这不仅会耽误“后端 API”,还会连锁反应导致“前端开发”停滞。
个性化推荐中的“归因”与“反转”
传统的向量检索(Vector Search)有时会因为语义接近而产生误导,但图结构可以做到精准的时间戳与状态管理。比如用户在 2023 年说“我最讨厌吃香菜”,但在 2024 年说“我尝试了香菜拌牛肉,竟然觉得不错”,那么可以抽取出:
时间、态度、物品
[用户] --(2023 态度: 厌恶)--> [香菜],[用户] --(2024 态度: 接受)--> [香菜]
图结构可以带标签(如时间、强度)。当 AI 决定今天点餐建议时,它能通过有向边的“时间戳”属性,识别出最新的态度已经覆盖了旧的态度,从而避免因为检索到旧文本而一直提醒你“别放香菜”。
同样的我们也需要分几步通过约束和关系的抽取让我们产生的结果更加可控:
LLM 抽实体+类型
这一步主要是做主体的提取相应实体和类型,规范输出结果,主要用于后续入库时给节点打 label/type(以及默认类型回退),比如输入文本:
我叫小王,在字节跳动做后端开发,住在北京。
得到结果大致会变成:
{
"name": "extract_entities",
"arguments": {
"entities": [
{"entity": "小王", "entity_type": "person"},
{"entity": "字节跳动", "entity_type": "organization"},
{"entity": "后端开发", "entity_type": "profession"},
{"entity": "北京", "entity_type": "location"}
]
}
}LLM 抽关系三元组
这一步是为了把上一步抽取的实体和类型让 LLM输出 source/relationship/destination,比如上面的例子这里会生成:
{
"name": "establish_relationships",
"arguments": {
"entities": [
{"source": "小王", "relationship": "works_at", "destination": "字节跳动"},
{"source": "小王", "relationship": "has_profession", "destination": "后端开发"},
{"source": "小王", "relationship": "lives_in", "destination": "北京"}
]
}
}用实体 embedding 在图里查相近旧节点/关系,再用 LLM 判定要删哪些旧关系,再执行 ADD / UPDATE / DELETE
这里我举例说明一下,比如用户先后两次输入:
我在字节跳动做后端,住在北京。(首次输入)
抽到关系后入图:
我现在在字节工作,搬到北京市朝阳区了。(过了一段时间后)
新实体可能是:小王 / 字节 / 北京市朝阳区
接下来就会检索和新旧关系的判定
查 字节 最相近旧节点
查 北京市朝阳区 最相近旧节点
拿这些相近节点的旧关系给 LLM 看
最终图可能变成:
对记忆的提取也是分两块进行提取:
这里就是常规逻辑。
上面我们有提到过,当需要关于世界和 Agent 自身的事实性知识,它不依赖于具体的Agent经历。例如,“北京是中国的首都”或者用户的基本偏好,在技术实现上,这通常对应于 RAG(检索增强生成)所调用的外部知识库。
RAG 核心思想是:在生成回答之前,先从外部知识库中检索相关信息,然后将检索到的信息作为上下文提供给大语言模型,从而生成更准确、更可靠的回答。
一个完整的 RAG (Retrieval-Augmented Generation,检索增强生成) 应用流程可以分为两个核心阶段:离线数据处理 (Ingestion) 和 在线检索生成 (Inference)。
离线阶段:数据准备与索引 (Data Ingestion)
这是 RAG 的“地基”,目的是将非结构化的知识变成 AI 能够理解和检索的格式。
文档加载 (Loading): 从 PDF、Word、Markdown 或数据库中提取文本。
文本分割 (Chunking): 将长文章切分为较小的、语义完整的段落(Chunks)。
为什么? 因为 LLM 有上下文窗口限制,且过长的信息会稀释检索精度。
向量化 (Embedding): 调用 Embedding 模型(如 OpenAI text-embedding-3 或本地的 BGE),将文本转换为高维向量。
向量存储 (Vector Storage): 将这些向量连同原始文本存储在向量数据库中(如 Pinecone, Milvus, Chroma)。
在线阶段:检索 (Retrieval)
当用户提出问题时,系统开始“翻书”。
通过我们上面的简单介绍,应该可以知道写入流程是这样:
任意格式文档 → MarkItDown转换 → Markdown文本 → 智能分块 → 向量化 → 存储检索下面我们简单的讨论一些细节。
MarkItDown 是微软(Microsoft)开源的一款非常实用的工具。它主要的目的是用来处理多模态的数据,无论是 PDF, Word (docx), PowerPoint (pptx), Excel (xlsx) 还是图片、音频内容,将各种格式的非结构化数据,一键转换为干净、标准的 Markdown 格式。
对于图片数据,它会调用多模态模型通常配置指向一个多模态大模型(如 GPT-4o 或 Claude 3.5 Sonnet),模型会分析图片中的场景、物体、文字(OCR)以及图表趋势,将生成的描述文字。比如 PDF 里面有一张图片,那么会抽取成:
对于音频内容,MarkItDown 一般会结合 OpenAI Whisper 等语音识别模型将音频中的对话或旁白完整转录为文本,转录后的文本会作为该音频文件的“代表内容”存入 Markdown 结果中,使其可以被向量化并检索。
在 RAG 应用中,分块(Chunking) 是决定检索质量的生死线。如果分块太小,会丢失上下文;如果分块太大,会引入过多噪音并导致 LLM 无法处理。
目前市面上主流的几种分块策略有:
# 标题、## 子标题)进行切分。 识别 Markdown 或 HTML 的标题标签,将属于同一标题的内容聚合成一个块;["\n\n", "\n", " ", ""]),首先尝试按段落(\n\n)切,如果某一段还是太长,再按句子(\n)切,依然太长,就按空格切;其实上面智能程度和计算成本是成反比的,越只能的策略通常来说也越贵。
| 策略 | 智能程度 | 计算成本 | 适用场景 |
|---|---|---|---|
| 固定字符 | 低 | 极低 | 性能要求极高的基准测试 |
| 递归结构 | 中 | 低 | 通用场景(推荐首选) |
| 语义相似度 | 高 | 中 | 缺乏明显格式的非结构化论文/报告 |
| Agentic/LLM | 极高 | 高 | 高价值、高准确度要求的核心文档 |
RAG系统将数据存好之后,核心的竞争力还是在检索。RAG 的基本思路是根据用户输入检索出最相关的内容,但是用户输入是不可控的,可能存在冗余、模糊或歧义等情况,如果直接拿着用户输入去检索,效果可能不理想。所以我们可以通过一些策略来优化查询效果。
查询扩展(Query Expansion) 就是把用户的原始提问“整容”或“分身”,变成更多、更丰富的表达方式。它的存在是为了解决 RAG 系统中的一个顽疾:词项不匹配(Term Mismatch)。比如用户搜“番茄”,但文档里写的是“西红柿”,基础检索可能就会完美错过。
查询扩展有多种不同的实现,比如:
多查询(Multi-Query)
这是最常见的扩展方式。让 LLM 站在不同角度,把你的问题重写成 3-5 个意思相近的问题。比如提问:“如何让猫爱上喝水?”,可以被扩展成:
“猫咪饮水习惯的诱导方法有哪些?”
“增加宠物猫饮水量的实用技巧。”
“哪些因素会影响猫对水源的偏好?”
后退提示 (Step-back Prompting)
它是 Google DeepMind 团队在论文 Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models 中提出的一种新的提示技术。
基本原理简单来说就是,如果你的问题太细节,检索效果往往不好。查询扩展会先退一步,问一个更宏观的原理。比如提问:“为什么我的 2023 款 MacBook Pro 跑 Python 特别烫?”,后退一步可能是:
帮助系统先检索到大框架知识,辅助回答具体细分问题。
假设文档 (HyDE)
HyDE 是 Luyu Gao 在 Precise Zero-Shot Dense Retrieval without Relevance Labels ,它的核心思想是"用答案找答案"。传统的检索方法是用问题去匹配文档,但问题和答案在语义空间中的分布往往存在差异——问题通常是疑问句,而文档内容是陈述句。HyDE 与其用一个“问题”去搜“答案”,不如先编一个“假答案”,然后用“假答案”去搜“真答案”
比如提问:“那个两个粒子互相感应的物理现象叫什么?”,检索效果差往往是因为 Query(问题) 和 Document(文档) 处于不同的语义空间,因为文档通常很长且是陈述句: “当两个或多个粒子以特定的方式结合在一起时,它们的状态就变得不可分割。即使你把这两个粒子分别放在宇宙的两端,它们依然保持着这种奇……”。
所以,我们可以让LLM 生成假答案: “这种现象通常指量子纠缠,即两个粒子在空间上分离但状态紧密关联……”,带着这段话去搜。因为假答案里包含了“量子纠缠”、“空间分离”、“状态关联”等学术词汇,它能精准地在论文中找到对应的章节。
RAG Fusion
最后还需要提一下 RAG Fusion,这是它的论文地址 https://plg.uwaterloo.ca/~gvcormac/cormacksigir09-rrf.pdf 。比如当你用查询扩展生出了 5 个问题,去检索得到了 5 份不同的答案排名,这时候就会出现矛盾:文档 A 在问题 1 里排第一,在问题 2 里排第十。RAG Fusion 就是那个负责“打分合并”的裁判。它利用 RRF(倒数排名融合) 算法进行打分。
比如现在有个原始问题: “如何在北京申请居住证?”,然后我们扩展成:
分身 1: 北京居住证办理流程是什么?
分身 2: 北京居住证申请需要什么材料?
分身 3: 外地人在北京办居住证的条件。
然后我们得到检索结果,文档 A(《北京人口管理条例》):在分身 1 搜到排第 3,分身 2 搜到排第 2,分身 3 搜到排第 5。文档 B(一篇非官方博客):在分身 1 搜到排第 1,但在其他两个搜索里都没出现。
经过 RRF 计算,文档 A 虽然没有拿过第一,但因为它在三个维度都被认定为高度相关,最终总分会反超文档 B。这样就过滤掉了偶然性极高的干扰信息。
Xinbei Ma 等人在论文Query Rewriting for Retrieval-Augmented Large Language Models提出了一种 Rewrite-Retrieve-Read 的方法,对用户的输入进行改写,以改善检索效果。在传统的 RAG(检索 -> 阅读)流程中,用户的原始输入往往不是“搜索引擎友好”的,比如包含大量的冗余、代词或模糊表达等。
查询重写主要思想就是使用一个专门的“重写器”(Rewriter)将原始查询转化为一个或多个更适合搜索引擎的检索词(Search Queries),然后使用这些优化后的词去数据库中捞取知识。
总而言之,AI Agent 的记忆系统是其迈向高度智能的核心支柱,通过构建包含短期工作记忆与长期经验库的多层架构,结合基于大模型的事实提取、动态更新机制及知识图谱技术,并配合深度优化的 RAG 检索流程,Agent 能够实现精准的上下文维持与知识内化,从而在复杂场景中提供更具一致性、个性化且可靠的智能支持。
https://github.com/mem0ai/mem0
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents https://blog.langchain.com/how-we-built-agent-builders-memory-system/
https://arxiv.org/abs/2309.02427
https://arxiv.org/abs/2504.19413
https://www.youtube.com/watch?v=cHQyugatz6M
https://www.aneasystone.com/archives/2024/06/advanced-rag-notes.html
2026-02-20 13:33:01
我们先以一个全局的视角看看 redis 的数据是怎么存放的:
redisDb (数据库)
└── dict (全局字典)
└── ht[0] (哈希表数组)
└── [Bucket] ──> dictEntry (节点)
├── key: [ SDS ("mykey") ]
└── val: [ redisObject ]
├── type: REDIS_STRING
├── encoding: EMBSTR (或 RAW)
└── ptr ──> [ SDS ("hello") ]Redis 的顶层存储核心是用全局字典(Global Dict,也叫 Keyspace)来管理所有的数据,Dict 采用的是双哈希表结构来保存数据主要是用来做渐进式 rehash,双哈希表结构用ht[0] 和 ht[1]来表示,通常数据只在 ht[0] 中,当哈希表需要扩容或缩容时,Redis 会一边处理请求,一边分批将数据从 ht[0] 迁移到 ht[1]。
哈希表其实就是一张大 bucket 数组,每个 bucket 是 dictEntry,由 dictht 数据结构来进行管理:
typedef struct dictht {
// 哈希表的槽
dictEntry **table;
// 哈希表槽个数,是2的整数次幂
unsigned long size;
// size-1,计算出一个key的hash后,直接 hash & sizemask即可算出所属的槽
unsigned long sizemask;
// 已使用大小
unsigned long used;
} dictht;在全局字典中,每一个键值对都被封装在一个 dictEntry 结构体中:
redisObject 结构体(或其指针)。redisObject 就像一个通用容器,它封装了所有 Redis 数据类型(String, List, Hash 等)。在 Redis 中使用 redisObject 统一来管理底层的数据结构,无论底层是SDS、ziplist 或 dict统一用 redisObject 来进行封装,然后通过 type 来进行标识。
在 Redis 的 C 语言源码中,它的定义如下(以 64 位系统为例):
| 字段名 | 占用空间 | 作用说明 |
|---|---|---|
| type | 4 bits | 逻辑类型:标识它是 String、List、Hash、Set 还是 ZSet。 |
| encoding | 4 bits | 物理编码:标识底层具体是用什么实现的(如 ziplist、skiplist、int 等)。 |
| lru / lfu | 24 bits | 对象热度:记录最后一次被访问的时间(LRU)或访问频率(LFU),用于内存淘汰。 |
| refcount | 4 bytes | 引用计数:记录有多少地方引用了这个对象。为 0 时对象被销毁。 |
| ptr | 8 bytes | 数据指针:指向底层真实数据的内存地址。 |
合计算下来,一个 redisObject 固定占用 16 字节。
这样做就是统一了接口,当你执行 DEL 命令时,Redis 不需要关心你删的是 String 还是 List,它只需要操作 redisObject 这个通用结构。
除此之外它有三大作用:
类型检查与多态
当你输入 LPOP key 时,Redis 会先检查这个 redisObject 的 type 是不是 REDIS_LIST。如果不是,直接返回错误。如果是,它会根据 encoding 字段去调用对应的函数(比如是从 linkedlist 弹出还是从 listpack 弹出)。
内存管理与共享
通过 refcount 的引用计数来控制内存的释放,当引用计数归零,Redis 才会真正释放内存。
内存淘汰(LRU/LFU 算法)
LRU 模式就会通过时间戳来看该对象是否应该被淘汰。LFU 模式它根据数据被访问的频率来决定淘汰对象,高 16 位存时间,低 8 位存访问计数。 如果这个字段很久没更新,当 Redis 内存不足时,它就会优先被“踢出”内存。
虽然在全局字典看来,所有的 Value 都是一个 redisObject,但 redisObject 内部通过 type 和 ptr 指向了完全不同的底层世界:
| 命令示例 | redisObject -> type | redisObject -> ptr 指向的内容 |
|---|---|---|
SET key "val" |
REDIS_STRING | 指向一个 SDS(可能是 int, embstr 或 raw) |
HSET user:1 name "A" |
REDIS_HASH | 指向一个 Dict 或 listpack/ziplist |
LPUSH list "item" |
REDIS_LIST | 指向一个 quicklist(由多个 listpack 组成的双端链表) |
SADD tags "java" |
REDIS_SET | 指向一个 Dict (value 为 NULL) 或 intset |
ZADD rank 100 "A" |
REDIS_ZSET | 指向一个 zset 结构(内含 Skiplist + Dict) |
Redis 设计了简单动态字符串(Simple Dynamic String,SDS)的结构,用来表示字符串,动态字符串结构如下图所示:
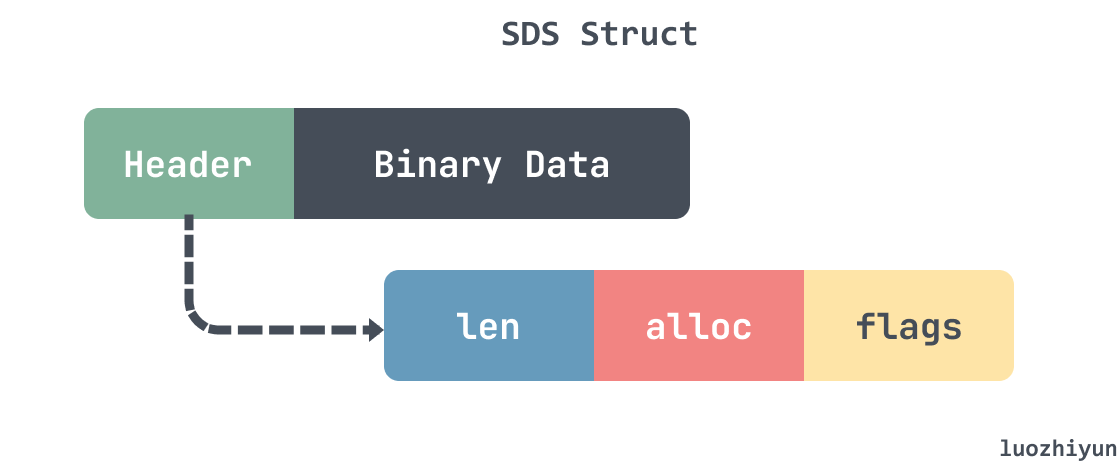
SDS 大致由两部分构成:header以及 数据段,其中 header 还包含3个字段 len、alloc、flags。len 表示数据长度,alloc 表示分配的内存长度,flags 表示了 sds 的数据类型。
在以前的版本中,sds 的header其实占用内存是固定8字节大小的,所以如果在redis中存放的都是小字符串,那么 sds 的 header 将会占用很多的内存空间。
但是随着 sds 的版本变迁,其实在内存占用方面还是做了一些优化:
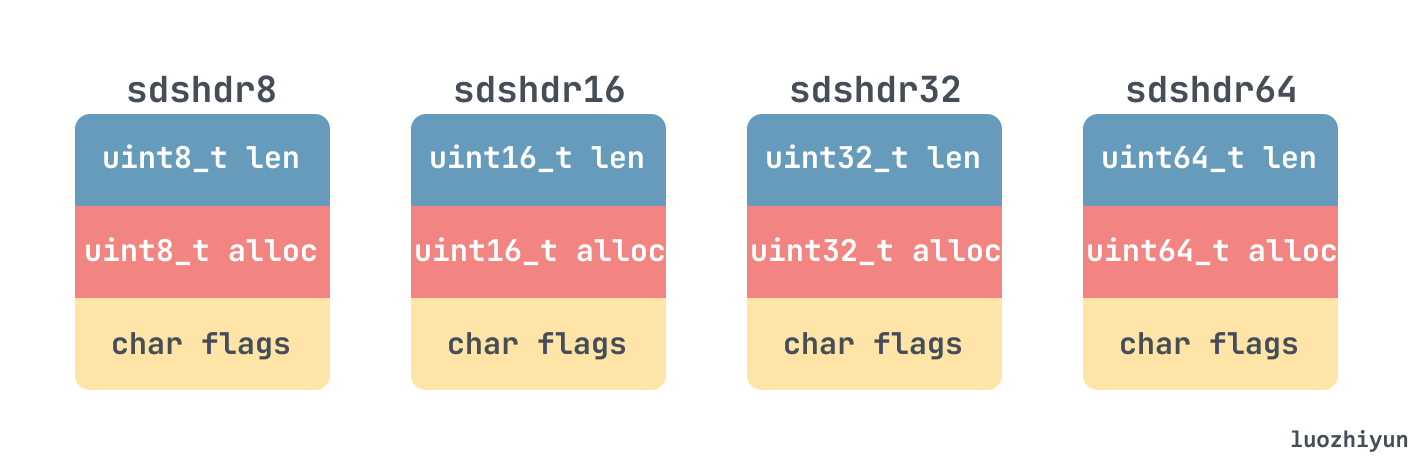
__attribute__ 修饰,这里主要是防止编译器自动进行内存对齐,这样可以减少编译器因为内存对齐而引起的 padding 的数量所占用的内存。目前的版本中共定义了五种类型的 sds header,其中 sdshdr5 是没用的,所以没画:
当执行 SET key value 时,对于 key 来说存放方式就是:
DictEntry
│
└── key (指针)
│
▼
┌──────────────────────────────────────────────────────────────┐
│ [ SDS Header ] [ SDS Body (buf) ] [ \0 ] │
└──────────────────────────────────────────────────────────────┘
▲ ▲ ▲
│ │ │
│ │ └── 结尾 (1 byte)
│ │
│ └── 你的 1MB 甚至 512MB 的数据
│
└── 这里的元数据结构会根据大小变化
(sdshdr8 -> sdshdr16 -> ... -> sdshdr64)对于 value 来说,Redis 会根据 value 的情况选择以下三者之一:
int 编码redisObject 的 ptr 指针位置(指针 8 字节,正好存下一个 long)。embstr 编码redisObject 结构体与 SDS 结构体在内存中是连续的一块空间。raw 编码redisObject 和 SDS 是两块独立的内存区域,通过指针连接。redisObject。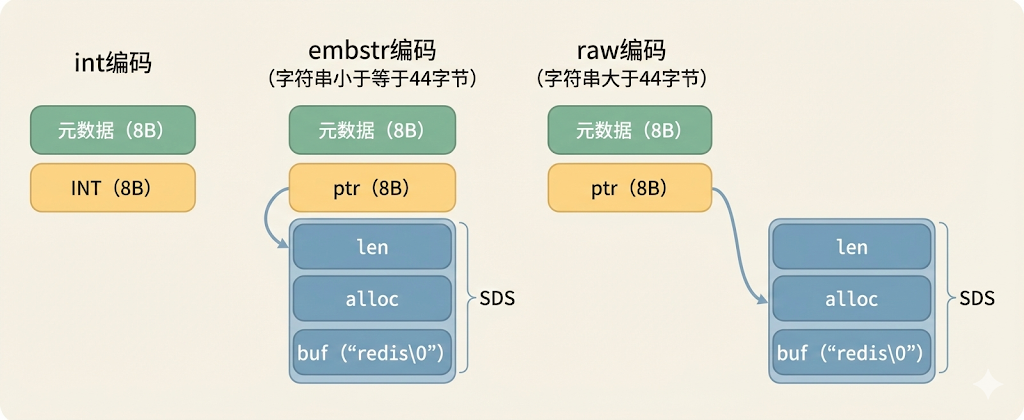
所以我们可以看到 key 和 value 其实是分两部分存储:
Value (值):可能会因为 RAW 编码 而导致 redisObject 和 SDS 分离(不挨着)。
Key (键):永远没有 redisObject 包装,它直接就是一个 SDS。所以 Key 的 Header 和数据永远是连在一起的,没有任何例外。
在估算容量之前,我们来看看 redis 使用的 jemalloc 是怎么做内存分配的。
jemalloc 预先定义了一系列固定的内存块大小(称为 Size Class)。当 Redis 请求分配 N 字节时,jemalloc 会查找第一个大于等于 N 的规格(Size Class)内存块进行分配。
为了减少浪费,jemalloc 的规格设计得很科学,并不是单纯的 2 的幂次方(2, 4, 8, 16…),而是更加细密:
| 规格区间 | 具体的 Size Class (字节) |
|---|---|
| 8B – 128B | 8, 16, 32, 48, 64, 80, 96, 112, 128 |
| 128B – … | 160, 192, 224, 256, 320 … |
假设你在 Redis 里存一个简单的字符串,算上 SDS 头部等开销,Redis 向系统申请了 20 字节。
结果:
虽然看起来浪费了一点点空间(内部碎片),但对整个系统来说,收益巨大:
所以根据我们上面的介绍,应该知道一个 String 键值对的总内存占用主要由三部分组成:
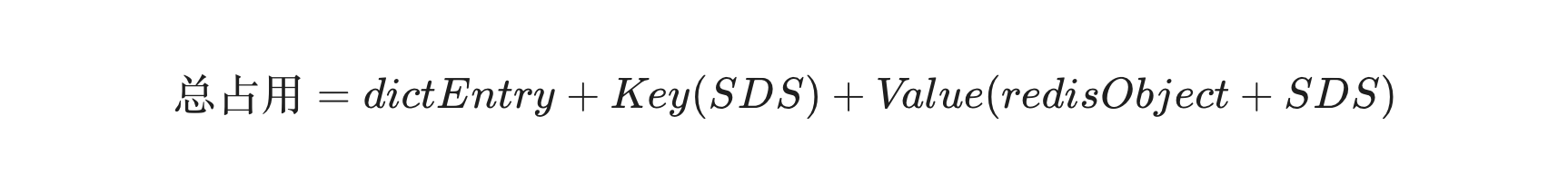
全局字典节点 (dictEntry):固定 24 字节
键 (Key):SDS 结构
值 (Value):取决于编码方式,上面我们有介绍,就不细说了 int、embstr、raw 编码;
| 编码方式 | 计算公式 | 说明 |
|---|---|---|
| INT | 16 字节 | 只有 redisObject,数值直接存在指针里。 |
| EMBSTR | $malloc(16 + 3 + len(Val) + 1)$ |
redisObject 与 SDS 连续分配,整体向上取整。 |
| RAW | $16 + malloc(3 + len(Val) + 1)$ |
redisObject 与 SDS 分开分配,各自取整后再求和。 |
SET "key" "value"
我们来算一下这个极小键值对实际占了多少地儿:
所以我们可以看到个有趣的事实,存储 8 字节的原始数据,Redis 实际需要 64 字节,膨胀率高达 8 倍。
不要试图用数学公式去死算每一个字节(因为 jemalloc 和 struct padding 很难完全算准),而是采用 “小规模采样 + 线性推演”。
我们可以启动一个空的 Redis 实例,记录初始内存 used_memory(通常在 1MB 左右,是 Redis 自身的启动开销)。编写脚本,写入 10,000 个 具有代表性的 Key-Value 数据(长度和类型要符合你的生产场景)。
然后计算初始内存使用 和 最终内存使用的差值,然后计算出单挑数据消耗,将单条数据消耗 X 预计总数据量就可以得到最终的预估结果。
如果你没法做测试,只能盲算,必须根据 Key/Value 的平均大小 来应用不同的膨胀系数。
小对象场景(最容易翻车)
场景:Key = 10 字节,Value = 10 字节。
原始数据:20 字节。
Redis 实际占用:约 64 ~ 80 字节。
膨胀系数:3倍 ~ 4倍。
dictEntry (24B) + redisObject (16B) 即使什么都不存就已经 40B 了。加上 jemalloc 的 8B/16B/32B 对齐,开销巨大。中等对象场景
大对象场景
场景:Key = 50 字节,Value = 10 KB。
膨胀系数:接近 1.05倍。
2026-01-25 15:31:36
本文章的实践代码提交在:https://github.com/luozhiyun993/skill-workflow
本文将深度解析 Agent Skill 的模块化设计:从 Skill 间的层级调用、工具脚本的自动化执行,到 Subagent 的专业化分工。我们将通过“小红书爆款生产线”这一实战案例,展示如何利用文件传递、状态追踪与清单模式,解决复杂任务中上下文过载与输出不可控的痛点。告别臃肿的单一 Prompt,让你的 Agent Workflow 变得可验证、可断点续传且高度精准。
有时候任务比较复杂,我们就可以抽取出不同的 skill,通过 skill 之间的调用来简化单个 skill 的复杂度,或者可以把一些公用到的 skill 抽取出来,变成单一的 skill。
比如我们每次在开发完之后都需要:运行测试,本地合并到基础分支、推送并创建 Pull Request,那么我们就可以创建一个 finishing-a-development-branch skill,然后在其他的 skill 里面指定调用:
### Step 5: Complete Development
After all tasks complete and verified:
- Announce: "I'm using the finishing-a-development-branch skill to complete this work."
- **REQUIRED SUB-SKILL:** Use finishing-a-development-branch skill
- Follow that skill to verify tests, present options, execute choice比如我们可以在 skill 里面指定使用方法,运行脚本,以及输出结果是什么,让 agent 自动执行:
## 使用方法
这是一个基于 TypeScript 的脚本 Skill。
### 运行脚本
# 在项目根目录下运行
npx ts-node .claude/skills/demo.ts
### 输出结果
脚本运行后,会在 workflow-agent/outputs/demo/ 目录下生成两个文件:
1. demo_[timestamp].json: 原始数据。
2. tdemo_analysis_[timestamp].md: Claude 生成的分析报告。当 Claude 执行复杂、开放式的任务时,它可能会出错。假设你让克劳德根据电子表格更新 PDF 中的 50 个表单字段,我们就可以通过添加一个中间的 changes.json 文件,在应用更改之前对其进行验证。工作流程变为:分析 → 创建文件 → 验证 → 执行 → 验证。
这一步特别重要:所有中间结果都保存成本地文件。
三个好处:
比如我们可以这样在 SKILL 里面指定文件的存放目录以及存放格式:
## Instructions
When this skill is invoked:
1. Create the `./input` directory if it doesn't exist
2. Get the user's input message (passed as arguments or prompt for it)
3. Generate a timestamp-based filename (format: `YYYY-MM-DD_HH-MM-SS.txt`)
4. Save the input to `./input/<timestamp>.txt`
5. Confirm the file has been saved with the full pathskill 里面是可以调用 subagent 的,subagent 有几个优势是:context 独立,可以并发执行,并且是可以进行专业化分工的,那么我们就可以在 skill 在有需要的时候调用 subagent,提升执行效率,比如下面我创建了一个 go-file-author-attribution agent,那么在 skill 里面就可以指明调用:
**Batch Process Files**
- For each eligible file, use the Task tool to invoke the `go-file-author-attribution` agent
- Pass the author name and file path to the agent
- Process files sequentially to avoid conflicts但是如果这样简单的调用,有时候会把一大段内容直接塞给 subagent,上下文窗口很快就撑满了。但如果只传路径,subagent 自己去读文件,上下文就干净很多。
Subagent 之间只传文件路径,不传内容,这条规则很重要。
比如可以设置一个 writer-agent 启动时只需要三个参数:source 文件路径、analysis 文件路径、outline 文件路径。它自己读取内容,写完保存到指定路径,返回输出文件路径。
这样做还有个好处:可以并行启动多个 subagent。三个 writer-agent 同时跑,各自处理一个提纲方案,互不干扰。
在 skill 里面通常来说,不建议把所有的信息都平铺到 SKILL.md 里面,因为上下文太长会浪费很多不必要的 token,并且让 agent 不够聚焦,那么我们可以使用 reference 的方式提供外部的文档提供:
## References
See `references/` folder for detailed documentation:
- `bdi-ontology-core.md` - Core ontology patterns and class definitions
- `rdf-examples.md` - Complete RDF/Turtle examples
- `sparql-competency.md` - Full competency question SPARQL queries
- `framework-integration.md` - SEMAS, JADE, LAG integration patterns将复杂的操作分解成清晰的、循序渐进的步骤。对于特别复杂的流程,提供一份清单 checklist,这样可以让 agent 逐步勾选完成,如下所示:
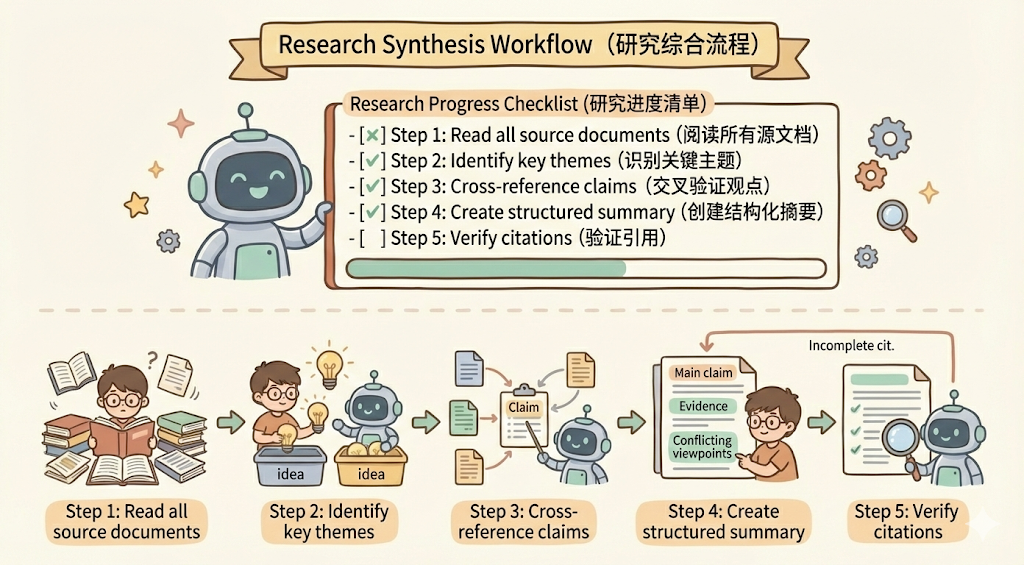
## Research synthesis workflow
Copy this checklist and track your progress:
Research Progress:
- [ ] Step 1: Read all source documents
- [ ] Step 2: Identify key themes
- [ ] Step 3: Cross-reference claims
- [ ] Step 4: Create structured summary
- [ ] Step 5: Verify citations
**Step 1: Read all source documents**
Review each document in the sources/ directory. Note the main arguments and supporting evidence.
**Step 2: Identify key themes**
Look for patterns across sources. What themes appear repeatedly? Where do sources agree or disagree?
**Step 3: Cross-reference claims**
For each major claim, verify it appears in the source material. Note which source supports each point.
**Step 4: Create structured summary**
Organize findings by theme. Include:
- Main claim
- Supporting evidence from sources
- Conflicting viewpoints (if any)
**Step 5: Verify citations**
Check that every claim references the correct source document. If citations are incomplete, return to Step 3.除此之外,也可以让 claude 在 workflow 里面去执行代码,比如把代码放入到 scripts 中,我们可以看一下 claude pdf skill 的目录结构:
.
├── forms.md
├── LICENSE.txt
├── reference.md
├── scripts
│ ├── check_bounding_boxes_test.py
│ ├── check_bounding_boxes.py
│ ├── check_fillable_fields.py
│ ├── convert_pdf_to_images.py
│ ├── create_validation_image.py
│ ├── extract_form_field_info.py
│ ├── fill_fillable_fields.py
│ └── fill_pdf_form_with_annotations.py
└── SKILL.md在 SKILL.md 里面直接指明什么时候去调用脚本: `python scripts/check_fillable_fields <file.pdf>。
下面提供一个demo:
## PDF form filling workflow
Copy this checklist and check off items as you complete them:
Task Progress:
- [ ] Step 1: Analyze the form (run analyze_form.py)
- [ ] Step 2: Create field mapping (edit fields.json)
- [ ] Step 3: Validate mapping (run validate_fields.py)
- [ ] Step 4: Fill the form (run fill_form.py)
- [ ] Step 5: Verify output (run verify_output.py)
**Step 1: Analyze the form**
Run: python scripts/analyze_form.py input.pdf
This extracts form fields and their locations, saving to fields.json.
**Step 2: Create field mapping**
Edit fields.json to add values for each field.
**Step 3: Validate mapping**
Run: python scripts/validate_fields.py fields.json
Fix any validation errors before continuing.
**Step 4: Fill the form**
Run: python scripts/fill_form.py input.pdf fields.json output.pdf
**Step 5: Verify output**
Run: python scripts/verify_output.py output.pdf
If verification fails, return to Step 2.通过 Run validator → fix errors → repeat 这种循环模式来不断提升输出的质量
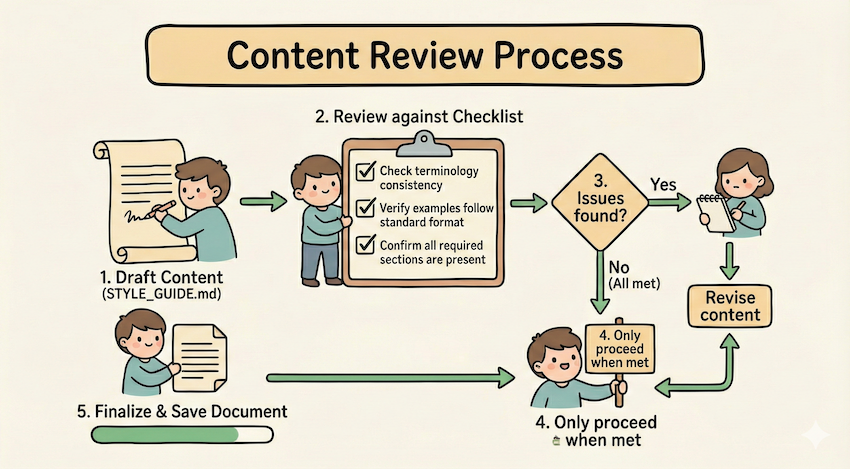
## Content review process
1. Draft your content following the guidelines in STYLE_GUIDE.md
2. Review against the checklist:
- Check terminology consistency
- Verify examples follow the standard format
- Confirm all required sections are present
3. If issues found:
- Note each issue with specific section reference
- Revise the content
- Review the checklist again
4. Only proceed when all requirements are met
5. Finalize and save the document比如上面的例子中,使用 STYLE_GUIDE.md 作为验证器,agent 通过通过读取和比较来执行检查,不通过则循环修改之后再进行验证。
我们可以在 md 里面引导 agent 做出条件选择,运行符合条件的 workflow :
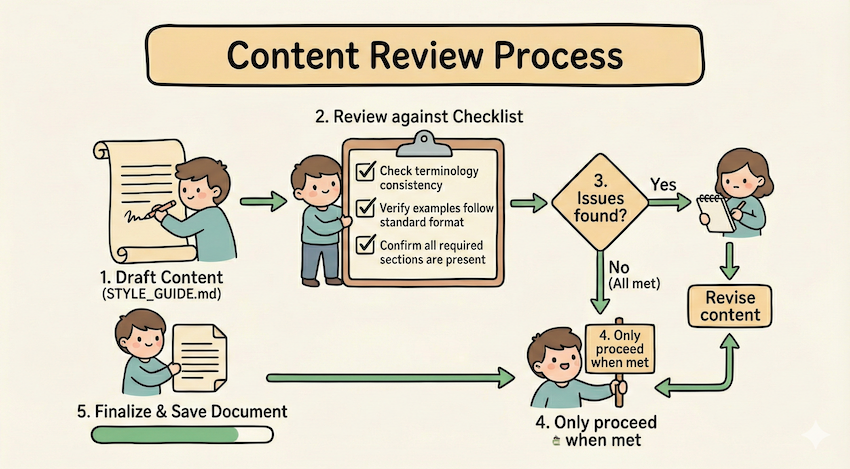
## Document modification workflow
1. Determine the modification type:
**Creating new content?** → Follow "Creation workflow" below
**Editing existing content?** → Follow "Editing workflow" below
2. Creation workflow:
- Use docx-js library
- Build document from scratch
- Export to .docx format
3. Editing workflow:
- Unpack existing document
- Modify XML directly
- Validate after each change
- Repack when complete我们可以在 skill 里面提供示例以提升 agent 的能力,最好可以明确 input/output 这样更明确,如下所示:
## Commit message format
Generate commit messages following these examples:
**Example 1:**
Input: Added user authentication with JWT tokens
Output:
feat(auth): implement JWT-based authentication
Add login endpoint and token validation middleware
**Example 2:**
Input: Fixed bug where dates displayed incorrectly in reports
Output:
fix(reports): correct date formatting in timezone conversion
Use UTC timestamps consistently across report generation比如我们现在输出的结果就是需要按照一定要求输出,那么我们可以在 skill 提供模版,让 agent 按照模版输出:
## Report structure
ALWAYS use this exact template structure:
# [Analysis Title]
## Executive summary
[One-paragraph overview of key findings]
## Key findings
- Finding 1 with supporting data
- Finding 2 with supporting data
- Finding 3 with supporting data
## Recommendations
1. Specific actionable recommendation
2. Specific actionable recommendation
一般的情况,我们用 传统workflow的做法(比如在dify里),需要这么做:
但是如果用 skill 就完全不需要这样,比如可以简单的用我上面讲的 pattern 就足够实现一套比较复杂的 workflow了。
比如目前要搭建一个一个小红书热门爆款写作的workflow,首先是从热门网站爬取,然后分析爆款热点,再来写作,最后输出到小红书,那么整个 workflow 的编排任务也可以通过 skill 来完成。
那么我们可以这样编排 workflow:
.claude/
├── skills/
│ ├── workflow-runner/ # 核心编排引擎
│ │ ├── SKILL.md # 解析 YAML 并调度任务的指令
│ │ └── workflow_schema.json # 约束 workflow.yaml 的格式
│ ├── web-scraper/ # 基础采集工具
│ │ ├── SKILL.md # 爬虫调用指令
│ │ └── scripts/ # 存放 Python/Playwright 爬虫脚本
│ └── xhs-utils/ # 小红书专用工具箱
│ ├── SKILL.md # 包含格式化、Emoji 注入、标签生成逻辑
│ └── templates/ # 爆款文案模板库
├── agents/ # 专门化的 Sub-agents 定义
│ ├── crawl-agent.md # 负责从乱码网页中清洗出有效信息的 Agent
│ ├── trend-analyst-agent.md # 负责拆解爆款逻辑、提炼“钩子”的 Agent
│ └── xhs-writer-agent.md # 负责不同人格化写作的文案 Agent
└── workspace/ # 运行时的中转站 (执行过程中动态生成)
└── xhs-factory/ # 存放 raw_data, analysis, drafts 等中间文件我上面这套 workflow 可以利用到 skill 和 subagent 相互协调来实现。skill 主要用来运行脚本和润色;subagent 因为有单独的context,所以将拆分的任务并发执行,提升处理效率。
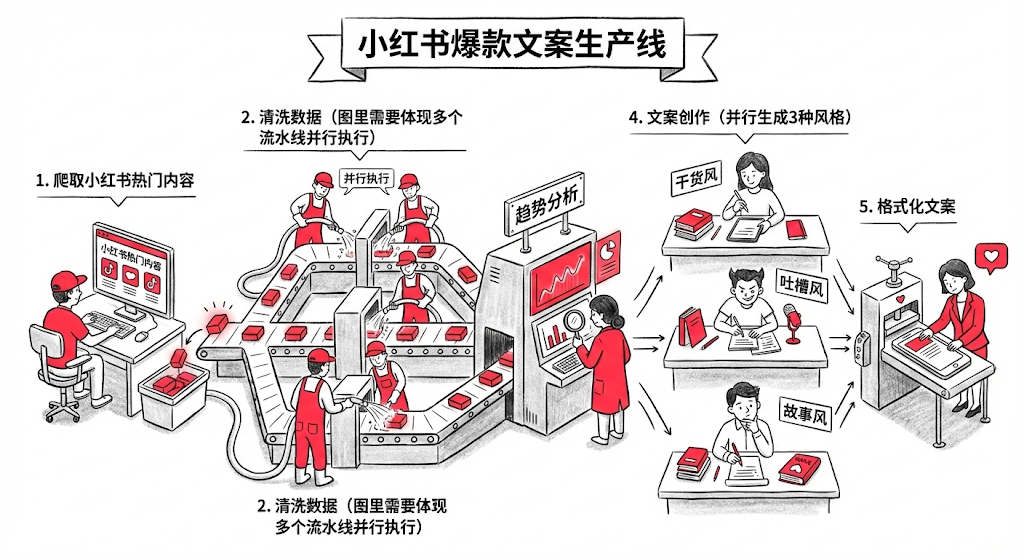
第一步:执行编排 workflow-runner (编排器) ,它会通过读取配置,我把它定义为 xhs_vlog.yaml,它里面规定了执行步骤,以及输出到什么文件夹:
name: "小红书爆款文案生产线"
version: "1.0"
workspace: "workspace/xhs-factory"
steps:
# 步骤 1:爬取小红书热门内容
- id: scraping_stage
type: skill
skill: web-scraper
params:
target: "xiaohongshu_trending" # 爬取小红书首页热门
limit: 20 # 爬取20篇热门笔记
output_dir: "{{workspace}}/raw_data"
# 步骤 2:清洗数据
- id: cleaning_stage
type: agent
agent: crawl-agent
depends_on: [scraping_stage]
params:
input: "{{steps.scraping_stage.output}}"
output: "{{workspace}}/cleaned_data.json"
# 步骤 3:趋势分析
- id: analysis_stage
type: agent
agent: trend-analyst-agent
depends_on: [cleaning_stage]
params:
input: "{{steps.cleaning_stage.output}}"
output: "{{workspace}}/analysis/hooks_and_patterns.json"
# 步骤 4:文案创作(并行生成3种风格)
- id: writing_stage
type: agent
agent: xhs-writer-agent
mode: parallel # 并行执行
depends_on: [analysis_stage]
params:
styles: ["干货风", "吐槽风", "故事风"]
analysis: "{{steps.analysis_stage.output}}"
output_dir: "{{workspace}}/drafts"
# 步骤 5:格式化文案
- id: formatting_stage
type: skill
skill: xhs-utils
depends_on: [writing_stage]
params:
drafts_dir: "{{steps.writing_stage.output}}"
output_dir: "{{workspace}}/final"
然后通过设置 run_state.json文件的方式每完成一个步骤,agent 必须强制更新这个文件,然后上一步和下一步通过 ouput 来进行对接,每一步完成之后会标记状态和完成时间,比如这样:
{
"workflow_file": ".claude/workflows/xhs_vlog.yaml",
"workspace": "workspace/xhs-factory",
"current_step_id": "writing_stage",
"global_context": {},
"steps": {
"scraping_stage": {
"status": "completed",
"output": "workspace/xhs-factory/raw_data",
"timestamp": "2026-01-19T14:17:19.344205",
"error": null
},
"cleaning_stage": {
"status": "completed",
"output": "workspace/xhs-factory/cleaned_data.json",
"timestamp": "2026-01-19T14:22:17.638192",
"error": null
},
"analysis_stage": {
"status": "completed",
"output": "workspace/xhs-factory/analysis/hooks_and_patterns.json",
"timestamp": "2026-01-19T14:29:11.210193",
"error": null
},
"writing_stage": {
"status": "completed",
"output": "workspace/xhs-factory/drafts",
"timestamp": "2026-01-19T14:34:22.027580",
"error": null
},
"formatting_stage": {
"status": "pending",
"output": null,
"timestamp": null,
"error": null
}
}
}第二步:原子执行 web-scraper (Skill),Skill 会调用运行 Python 脚本进行网站的爬取,脚本运行成功并生成文件后,Runner 立即将 scrapping_stage 标记为 completed,并写入文件到当前项目的 raw_data 文件夹;
第三步:启动 crawl-agent 批量的对抓取的页面进行数据清洗,并且在 crawl-agent.md 文件中还用示例的方式指出了输出格式:
[
{
"id": "note_0",
"title": "绝绝子!这个方法让我一周瘦了5斤",
"content": "姐妹们,今天分享一个超好用的减肥方法...",
"likes": 12000,
"comments": 456,
"favorites": 0,
"tags": ["减肥", "健康", "生活方式"],
"published_at": null
}
]第四步:启动并行创作xhs-writer-agent,启动多个 subagent 完成不同风格的文案写作工作,比如我在 agent 里面规定了三种风格,可以根据自己的运营经验进行微调:
### 干货风
- **标题**:数字+动词+效果(如"3招让你的皮肤嫩到发光✨")
- **开头**:直接抛出核心价值,吸引读者
- **正文**:步骤拆解,每步用 emoji 标记,内容具体可操作
- **结尾**:总结+互动引导(如"姐妹们快试试吧💕")
- **长度**:300-500字
### 吐槽风
- **标题**:痛点+共鸣(如"姐妹们,别再踩这些坑了!😭")
- **开头**:描述痛点场景,引发共鸣
- **正文**:吐槽+解决方案+对比,情绪化表达
- **结尾**:反转或金句收尾
- **长度**:250-400字第五步:执行汇总格式化 xhs-utils (Skill),只有当 run_state.json 显示所有创作子任务都为 completed 时,才会触发最后的格式化 Skill。
最终生成的文件全部都通过文件来传递,可以极大的减少 token 的消耗:
└── workspace
└── xhs-factory
├── analysis
│ └── hooks_and_patterns.json
├── cleaned_data.json
├── drafts
│ ├── 吐槽风.md
│ ├── 干货风.md
│ └── 故事风.md
├── final
│ ├── 吐槽风_final.md
│ ├── 干货风_final.md
│ └── 故事风_final.md
├── raw_data
│ ├── note_0.json
│ ├── ....
│ └── note_9.json
└── run_state.jsonAgent Skill 的核心魅力在于它将大模型的逻辑能力与软件工程的模块化思想深度融合。通过这篇文章的实践,我们可以体会到几个比较有用的实践:
https://x.com/dotey/status/2010176124450484638
https://platform.claude.com/docs/en/agents-and-tools/agent-skills/best-practices