2026-05-29 20:31:47
自去年年底去过一次之后,我就喜欢上了在海岛上旅行的感觉,相比于大陆近岸的海水,海岛周围的颜色透着一种天空的蓝。
这次旅行又走了一圈环岛徒步,只花了不到 3 个小时,比上次要快得多。
碧蓝之海,启动!
远方还能看到几艘渔船。
靠近岸边的海水反而泛着一些浅绿色。
顺时针走到大约 1/4 的地方,可以看到一个废弃的村庄,似乎目前只然有一些海防人员在此居住。
回头望去,几座岛屿在海平线的地方,却是无法上去的无人岛。
无论何时何地,总会不经意间看到大橘的身影。
一直都很喜欢这种海水不断拍打着礁石的画面。
正午,整个海平面都泛着白光。
远方矗立着一个不知名的三角形箭头,不知道是做什么的。
似乎还有人居住的村庄,但也主要集中在东北角接近轮渡码头的地方。
当下午回来之后,就可以等待日落了,轮渡中心的码头就是一个不错的拍摄点,非常适合同时拍摄日落和岛上标志性的灯塔。
半隐。
稍微放大一些的画面。
想要看日出非常依赖天气,我只有第二次去的时候看到了,第一次只看到了早起的渔船在海上忙碌着。
这次比较幸运,看到了美丽的朝霞。
随后,太阳从海平线的云层中慢慢升起。
太阳完全升起,但天边的云彩仍然残留着一缕朝霞。
两个过于勇敢的人爬上了那块大石头。
最后仍然用刚上岛就能看到的灯塔作为结尾吧。
随着独立开发的时间增加,几乎完全失去了与其他人交流的机会,旅行成了排忧解闷的主要方式。尽管效果越来越不明显,但我仍然决定下半年出去,走完今年十个国家目标中剩余的七个。
2026-03-21 20:13:55
回来一个星期了,才开始动笔写新加坡和越南的旅行。相比于呆了 24 天的马来西亚,新加坡和越南都只呆了 3 天,尤其是因为越南航空晚点 16 个小时,导致越南之行实际上只有 2 天时间,非常匆忙。
从新山走陆路口岸通过,如预料之中,新加坡的电子化极其发达,包括海关都是直接刷护照即可自动通关,完全没有人工环节。公交或地铁也都可以直接刷 Visa 卡,尽管国内的 Visa 双币卡在国外就是废物一条着实坑了我,但仍然难以掩盖信息化的发达。
住在市中心附近,所以下午先去逛了会街,但大部分小店的商品总感觉是从义乌直接批发的。
走了一会就能看到地标建筑金沙酒店,三栋楼上面放着一艘船的样子。
沿着河边走,还能看到远处已经停运的巨型摩天轮。
偶然看到一个有趣的设计,通过一个凹面镜反射出周围的景色。
经典 CBD 照片,建筑密集度相当惊人。
去附近的商场吃个饭,似乎在下层还有一些给小孩子玩的设施。
之后出来继续沿河边散步,一个奇怪的 Apple Store 映入眼帘。
之后,就是经典的新加坡城市夜景了,稍微拍了几张。
完全出乎意料的是还看到了 MLP 的联名花展 Floral Fantasy,这是万万没想到的,当即去看了。
在路边走时突然就看到了这个,当机立断买票就去了。
门口的宣传把 Rarity 和 Apple Jack 放在后面也是日常了,她们算是 Mane Six 中人气最少的两个 Pony。
进入之后看到 Celestia 和 Luna 时旁边一个女孩直接说 “妈妈,看,是 Celestia”,真是温馨的小场景。
不过 Celestia 制作的确实太棒了!
还有 Twilight 和 Rainbow Dash,制作的也很棒。
唯一糟糕的就是没有 Starlight,不过她终究不是 Mane Six,也是可以理解的。
第二天去了附近的教堂,巨大的清真寺,旁边有一条网红打卡街道。
下午前往了海边,尽管新加坡是一个繁忙的货运港口,但海水的质量看起来也非常棒。
旁边的公园还能看到不知名的小鸟。
第三天仍然出去玩,超级喜欢新加坡的绿化,这种绿色看着太舒服了。
所以下午又跑去圣淘沙岛看海去了。
悬索吊桥晃晃悠悠,还挺好玩的。
碧蓝之海,启动!
一个完全不知何故水平生长的椰子树,几乎都长到了海里。
乘坐这个轻轨,离岛乘坐公交车回去准备前往越南。
刚下飞机,就感受到了强烈的共产主义国家的气息,宣传几乎无处不在。
殖民时期遗留的教堂,新增的大概只有胡志明的雕像?
傍晚的广场上人来人往的还挺热闹。
旁边就能看到胡志明市的最高建筑了。
这个压迫感有点引起 PTSD 了。
这里过马路有时只有斑马线没有红绿灯只能硬过也是体验到了。
第二天前往博物馆看到的东西还算有趣。
之后去了市博物馆(统一宫),建筑本身还可以拍几张,只是房间内部的装潢有些过于宣传了。
楼上能看到下面巨大的广场和远方的街道。
无论是新加坡还是越南,我都没能留下太多美好的回忆,可能我还是呆的时间太短了吧。但世事总是不如人意,希望今年还能继续走完七个国家,考虑到世界上有接近两百个国家和地区,就算每年走十个,也需要二十年才能完成,但这显然是一个值得去做的目标,至少对我来说是这样。
2026-03-21 18:44:17
自从之前的亚庇之行结束后,我就出发前往了仙本那。那是一个很小的小镇,基础设施极其糟糕,而且总体上似乎相当贫困,路边经常看到乞讨者,小孩子围着人转希望给她们钱的例子屡见不鲜。海洋看起来相当不错,但烈日极其毒辣,我刚到的第三天就已经被晒脱皮了,不过似乎主要活动是潜水,如果不喜欢它,可能也不太值得待太长时间。之后前往了新山,临近新加坡的第二大都市圈,但对我而言过于熟悉了,所以呆的两天基本没出去,尤其是第二天只是呆在住的地方,几乎不值一提。
到住处暂存行李之后就开始在镇上闲逛,偶然看到河边的“水上人家”,大量简陋的铁皮屋矗立在水面上。完全缺乏管道系统(下水道)是最大的问题,而且小孩子还在旁边的水里游泳,但水质极其糟糕。
岸边的房子也不遑多让,尽显破败之相,难以理解一个旅游胜地经济发展为何会如此不堪。
而他们的交通基本上依赖于这种木板桥,我可以保证,这看起来很危险,实际上一点也不安全。
但这儿的小孩子有一种国内好久没有看到的乐观和天真了,基本上国内的小孩子一看到人就跑了,根本不会让人拍照。
偶尔在楼房之间的通道中还能看到在街头生活的老人。
前面说了那么多糟糕的现状,但这边的海水确实非常棒,我的意思是,
不幸的是,贫困似乎是一种顽疾,即使在这种旅游区域,仍然有大量巴瑶族人在卖椰子,或者让小女孩爬上梯子向游客乞讨。
在报一日游浮潜去了一次马布岛之后,就一直想去岛上的居民区域转转,所以之后确实去住了一天水屋。
本地居民区可以看到小孩子聚居在一起玩,在手机时代之后国内很少看到这种景象了,往往是每个小孩子都抱着自己或父母的手机玩,这在我看来是一种悲哀。
岛上的海滩更是棒极了,
不幸的是,贫困总是如影随形,海边的房屋仍然缺乏管道系统,所有的脏水都是直接排入海洋中,而这对于健康而言绝对没有任何好处。
疯狂的是,如此年幼的孩子,只是坐着一块泡沫板,或者一个气阀,就出海帮助维持家庭生计了。
日落总是短暂的,只有远方废弃的钻井平台亮着灯。
总的来说,如果你喜欢潜水,仙本那几乎每天都有出海潜水的团,但如果像我一样更喜欢拍照,可能仙本那呆个 3~4 天也足够了。接下来,我将前往新加坡,看看传说中坡县是怎么样的。
2026-03-09 20:22:56
在春节之后,我来到了马来西亚旅行。这是我出国旅行的第三个国家。在此之前,我曾经在日本呆了半年,在关西走了一些地方,回国后又花了几个月的时间走完了整个中国的所有省份和直辖市,所以某种程度上我的阈值确实提高了。因此,直到目前为止,马来西亚给我的体验,可以用一个字来形容:烂。
落地首先到了吉隆坡,基建水平还行,但室内导航很困难,而且售票机只收取小额纸币导致我一度没有零钱可用,直到后面办了一张 TNG 的卡,但这张卡在槟城时公交完全用不了,后面的其他地方几乎没有公共交通可用,所以是的,基本上是个坑。去看了那个大佛像和彩色楼梯,确实不错,至少值得一去。
吉隆坡标志性的大佛像。
彩色楼梯栏杆上的猴子。
登至台阶顶处往上看。
独立纪念碑,附近值得多拍几张,有巨大的清真寺。
顺便骂一句 Booking,收费方式极其混乱,我经常忘记一个预定到底有没有付钱,有些是到店付款,有些是线上支付,而且使用者没办法决定,真是糟透了。
抱团一日游简直太糟糕了,除了最早的森林徒步,后面凑数的都是什么臭鱼烂虾。我自己也走了两条热门的原始森林徒步路线,确实很原始,大部分都是石头、泥土和树根组成,但也仅此而已。
徒步起点,直接楼梯加绳子真的很劝退,我差点就放弃了。
山上云雾缭绕,山下的建筑却早已变成了水泥盒子。
第二天抱团走的森林徒步,看到了下面色彩斑驳的森林。
朝露与青苔,可能是森林徒步中的一种“小确幸”了。
金马伦高原有名的茶园。
还算幸运的拍到了纹胸花蜜鸟。
一日游最后一个佛寺景点实在让我蚌埠住了。
作为推荐的汽车订票软件 easybook,web/app 设计水平之烂,ux 体验之痛苦,我会说在国内那些毒瘤 app 都是少见的。尤其是支付部分,每次购买时都必须填写相同的信息,而没有自动保存选项。微信支付集成就更有趣了,在 app 上显示一个二维码让扫码支付,这是什么鬼才设计?即使如此,也无法正常支付,我怀疑是否有人测试过。
据说是华人聚居的城市,面朝海边吃着当地小吃确实还不错。但我本身对壁画和艺术并不太感兴趣,然后升旗山真的真的没什么,我的意思是和香港的太平山没什么区别。树冠步道也没有什么,远不及后面兰卡威的天空之桥。
天还没亮时拍摄的槟城。
日出。
树冠步道。
一只蝴蝶。
醒来的槟城。
市政府。
槟城海港。
电子化是依托答辩,除了 711 之类的连锁大部分还是要现金,有的地方看起来有扫码选项实际不能用,公交卡不能用来刷(滨城)公交是什么鬼?
截至目前为止唯一感觉还不错的城市,在海边拍日落还不错,天空之桥值得一看,旁边的七仙井瀑布也可以顺便取一下,那里可以泡水,我还看到了水巨蜥,不过如果要租摩托车需要摩托车证,这是一开始没有预料到的。
刚到就看到了日落,太幸运了。
天空之桥,真的非常棒。
大海的分层实在太漂亮了。
站在桥上往下看去。
山泉泡水,夏天这样很舒服。
只是需要小心“可爱”的邻居,这显然是它的地盘。
第二天早上骑着自行车就去看日出去了,这很棒,没有驾照也可以租个自行车。
还能去机场附近近距离拍大飞机降落。
亚庇的京那巴鲁山登顶需要专门的设备和门票,而下面的公园其实没有太多值得说的,东南亚的原始丛林远不及预期,原本我会以为类似于西北野生动物很常见的情况,也许确实如此,但可能都太隐蔽了。一些景点也真的太糊弄人了,例如亚庇的红树林据说可以看到长鼻猴和萤火虫,怎么说呢,确实如此。能看到,但也仅此而已了,萤火虫和预期完全不同,完全不是河面上大片的萤火虫,只是一棵树上聚集了一些萤火虫,也没什么大不了的。值得花 8 个小时和 RM190 吗?至少我觉得并不值得。
尚未降落时的云海。
山上到处都是雾,几乎什么都看不清。
复杂的树根结构。
第二天早晨雾气稍微散去之后。
休息一天后前往红树林,河旁边就有一条鳄鱼。
确实看到了长鼻猴,但只能说还好?
日落还算不错,萤火虫就别提了,只是一点点。
必须吐槽的是公共交通的水平之低,我的天呐,没想到现在还要在路边挥手随机拦车,真是见了鬼。这比西北那边的公共交通水平还低,很难有什么准确的预期。
来之前对马来西亚的大海和丛林比较感兴趣,可以说,后者令人大失所望。至于大海,传闻国外最糟糕的海岸也比国内的更好,就吾辈实际经历而言,滨城、兰卡威、亚庇 三者中只有兰卡威有点意思,其余都是什么鬼。
目前正在前往仙本那,也许仙本那的大海会改变我的想法,但我想先写下这种感觉。
2026-01-26 08:27:04
在之前的 7 篇博客中,我们依次了解了一些扩展开发中的基本概念,并且每一篇都附上了一个扩展示例。现在,我们终于要演示如何发布扩展了。下面我们将演示如何将之前做的自动冻结不活跃标签页的那个扩展发布到 Chrome Web Store 中,还记得吗?就是我们在 Browser Extension Dev - 04. Background Script 和 Browser Extension Dev - 05. 存储和配置 中作为示例的那个扩展。
注册完成后打开 https://chrome.google.com/webstore/devconsole/ 应该可以看到如下页面。
接下来,开始演示如何从构建到最终发布扩展。
首先,在项目中打开终端,然后运行 pnpm zip,应该会看到类似下面这样的输出,可以看到 Chrome 扩展已经被正常打包成 zip。
1 |
|
在 .output 目录下找到这个文件,记住这个路径。
然后打开 https://chrome.google.com/webstore/devconsole/ 并点击右上角的 New Item 按钮。
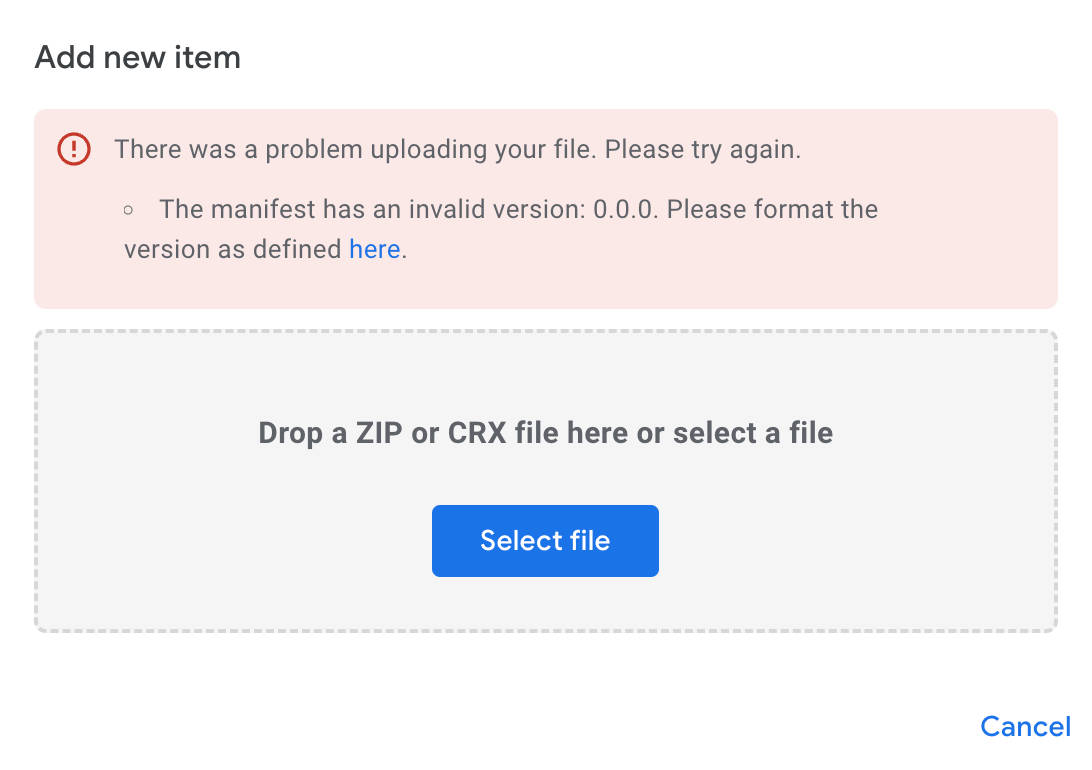
选择刚刚找到的 zip 文件上传,此时遇到了一个错误,提示 The manifest has an invalid version: 0.0.0. Please format the version as defined,也就是版本号不能为 0.0.0
使用 pnpm version patch 将版本号增加到 0.0.1,然后重新运行 pnpm zip 构建并上传,即可看到扩展发布管理页面。
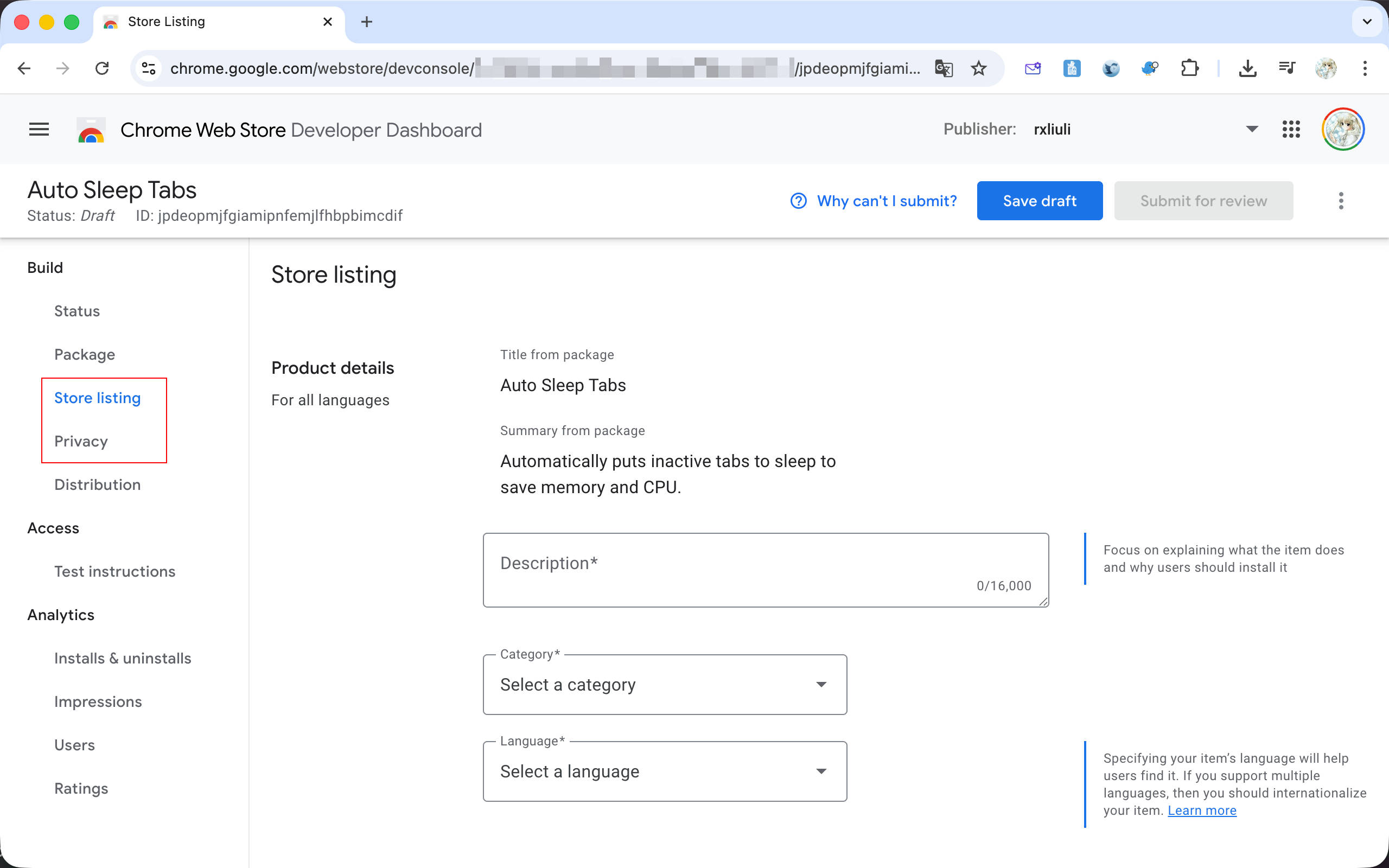
其中,对于发布而言,最重要的两个标签页是 Store listing 和 Privacy。前者用于配置扩展在 Chrome Web Store 中的展示信息,例如简介、分类、图标和截图等等,后者则是权限使用说明和隐私政策链接。
对于这个扩展而言,选择分类为 Productivity > Tools,语言选择 English。
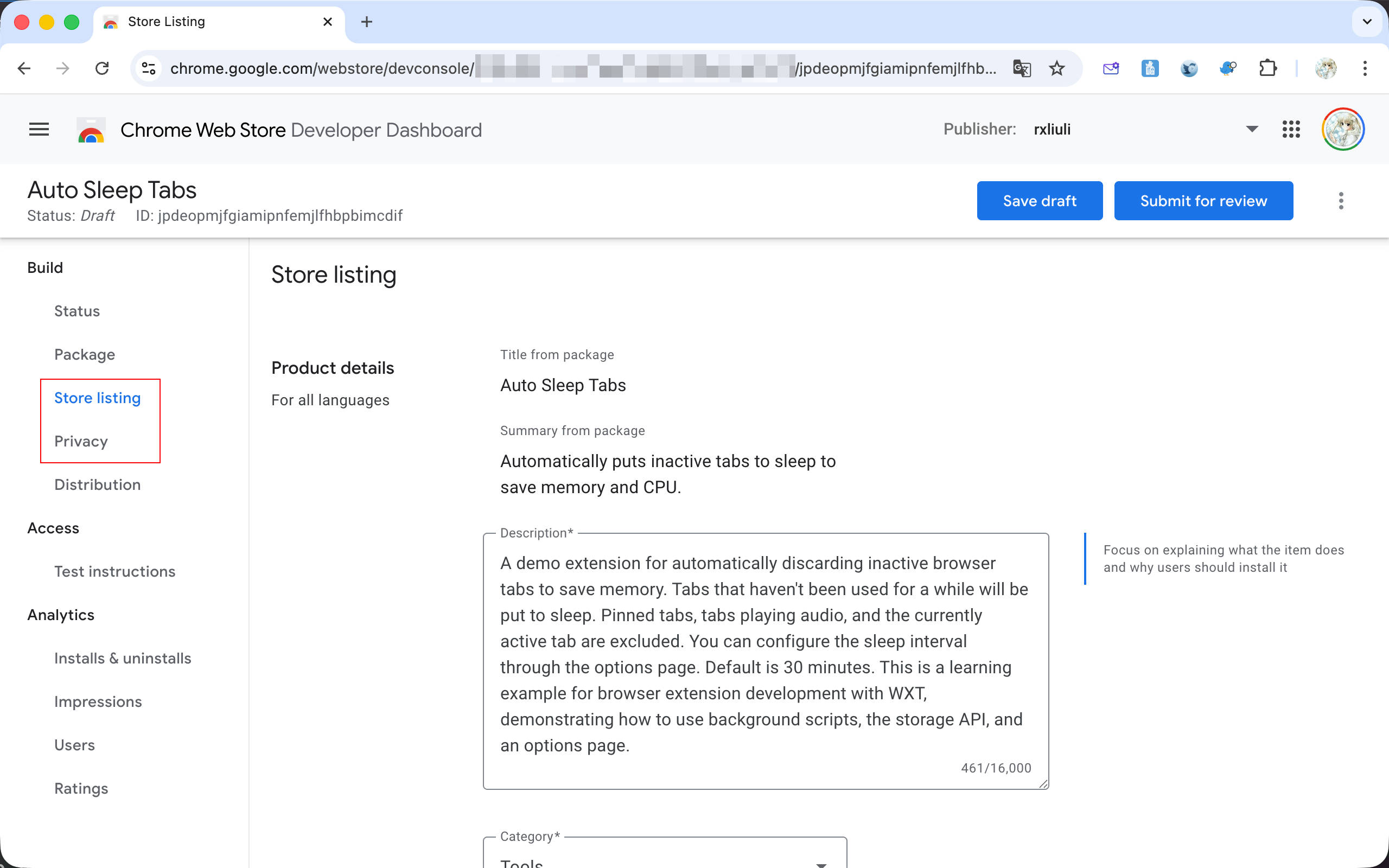
然后从 public/icon 目录选择 128.png 图标作为在商店显示的扩展图标。要截取精确 1280x800 像素的截图可能有点麻烦,但可以直接使用 https://squoosh.app 来调整截图的大小,使用 Resize 功能调整截图尺寸到 1280x800 就好了。
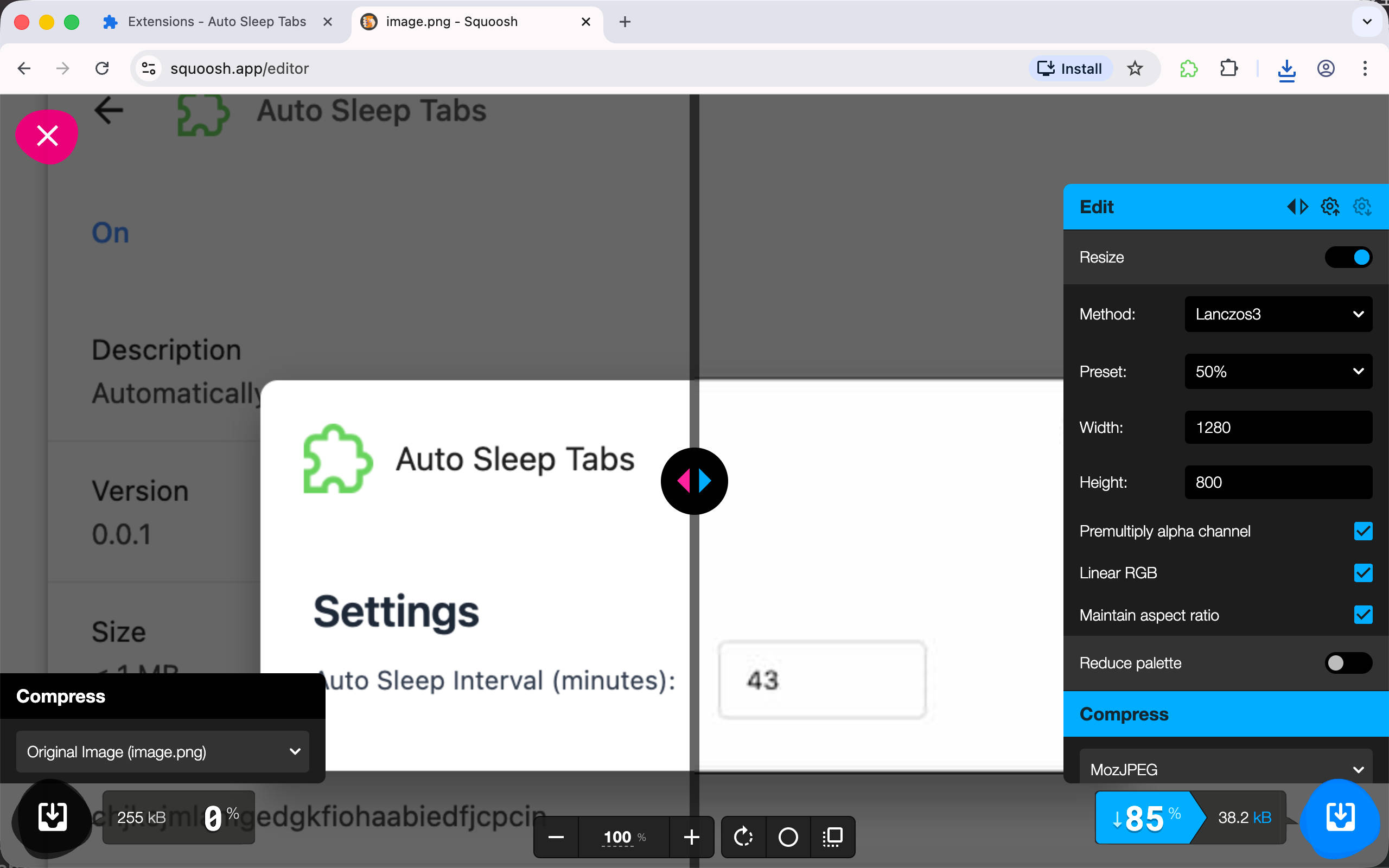
PS: 如果你使用 mac,可以使用小工具 Window Resizer 来将窗口尺寸修改为指定大小。
参考 Chrome 官方发布文档 https://developer.chrome.com/docs/webstore/publish
切换到 Privacy 标签,可以看到有几个主要区域
Are you using remote code?,Chrome 禁止使用远程代码,某些库(如 zod)可能会不小心引入远程代码,需特别留意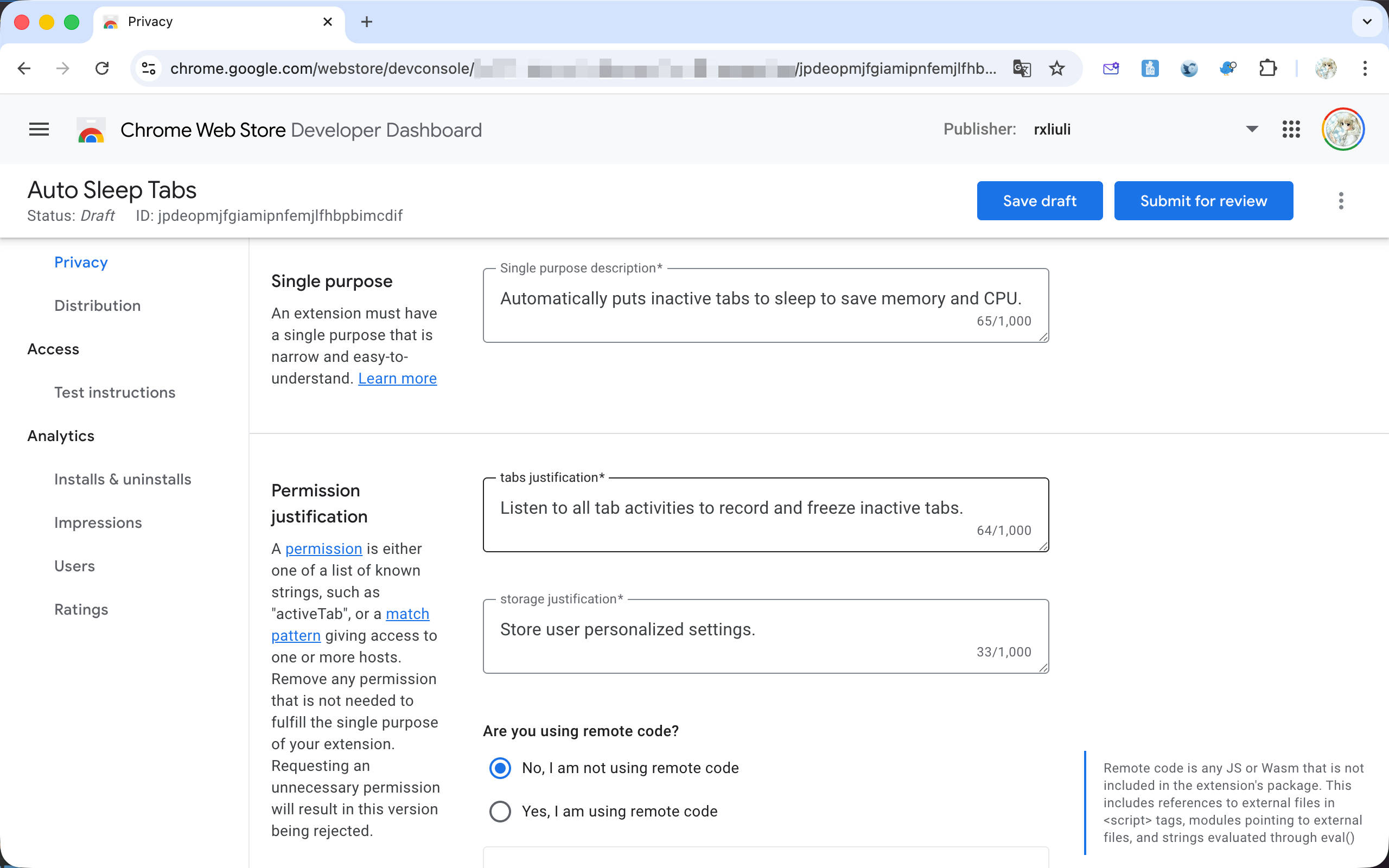
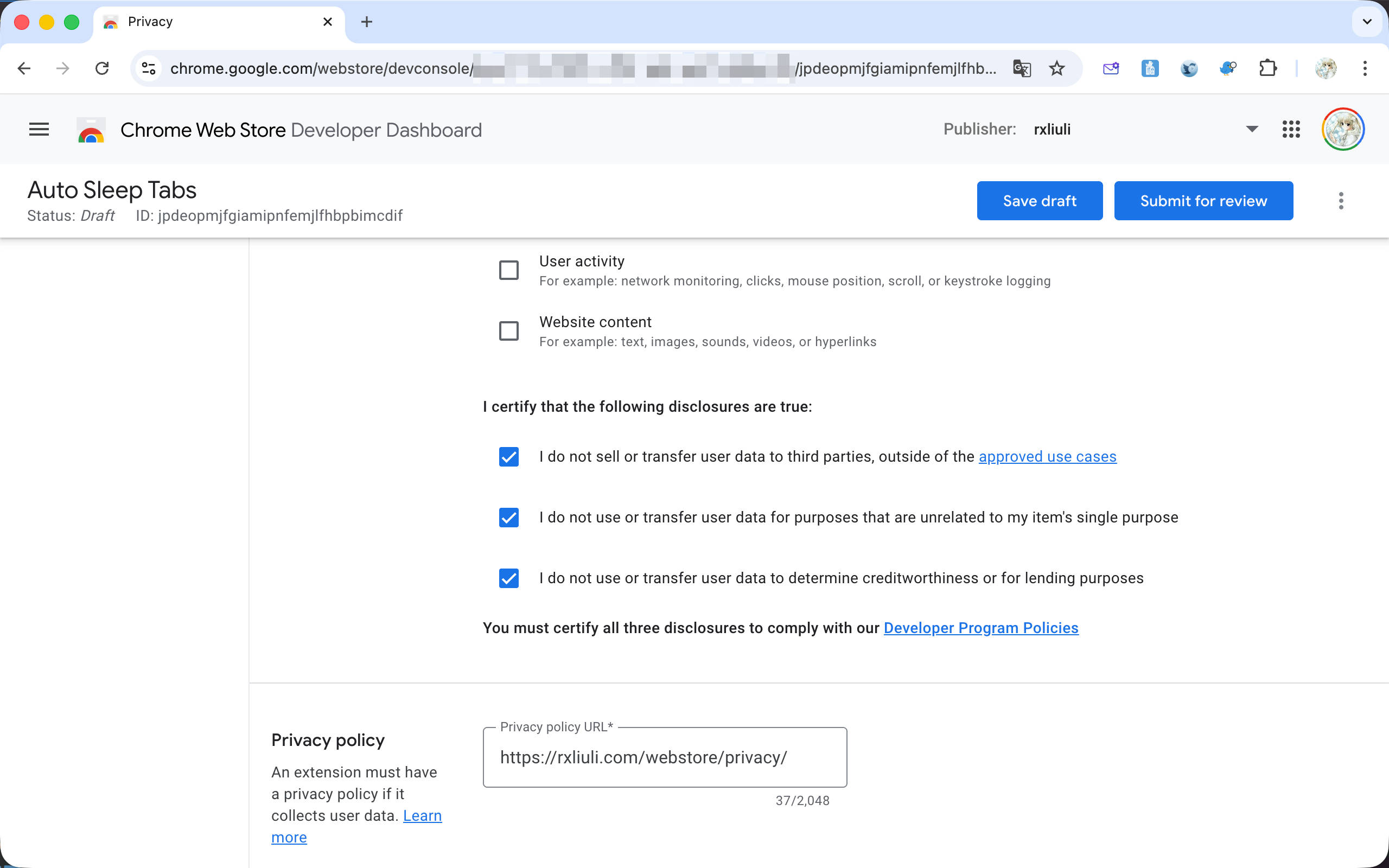
按下 Save draft 按钮之后,如果 Submit for review 按钮可用,那就说明可以提交扩展进行审核了。
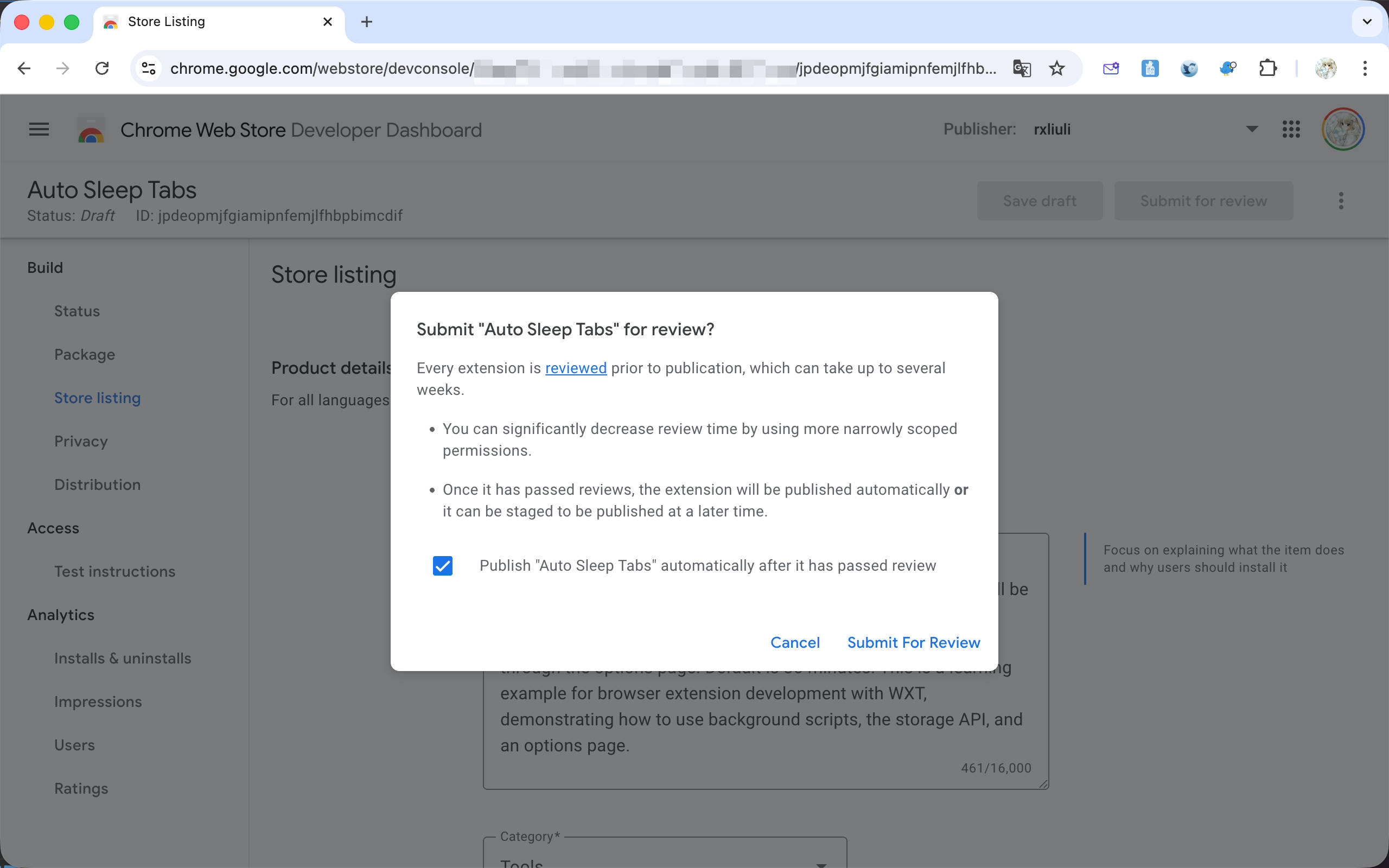
提交审核后,将会进入审核队列,通常需要几天甚至更长时间进行初次审核,所以还请耐心等待,某些使用高风险权限(例如向所有网站注入脚本)或者针对高风险网站(当然,吾辈是在说 YouTube)的扩展可能需要等待更长时间。
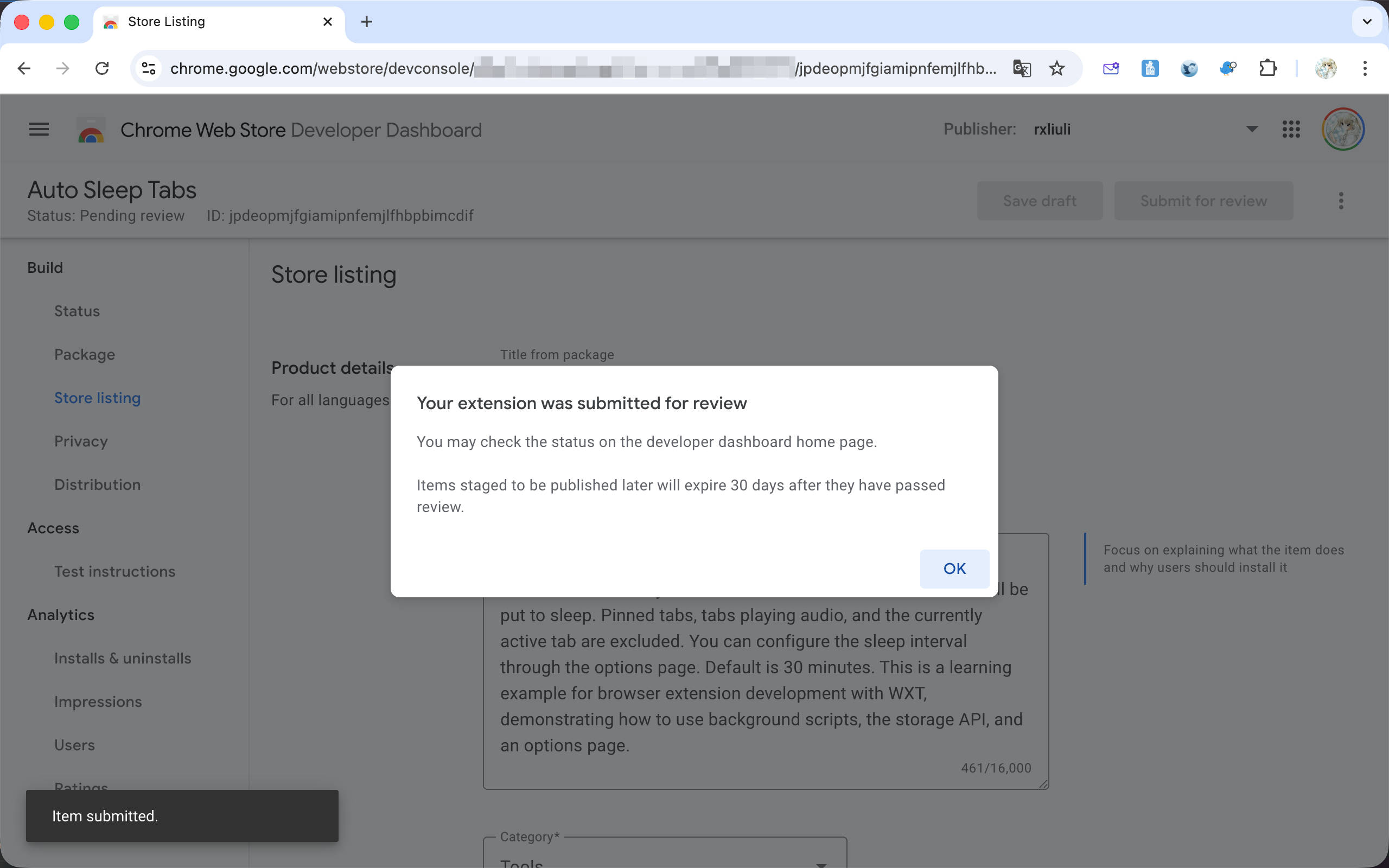
至此,浏览器扩展开发的基础内容就介绍完了。后续可能会有一些进阶主题的番外篇,比如国际化、GitHub Actions 自动发布等。
如果还对发布 Safari 扩展并上架 App Store 感兴趣,可以查看我之前写的博客 转换 Chrome Extension 为 Safari 版本 和 发布 Safari 扩展到 iOS 应用商店。提醒一下,这非常复杂,且开发者账户无试用期,必须满足 1)有一台 macOS 电脑并且安装 Xcode 等开发工具 2)开通 App Store 开发者账户并支付 $99/年的费用。
2026-01-21 22:33:45
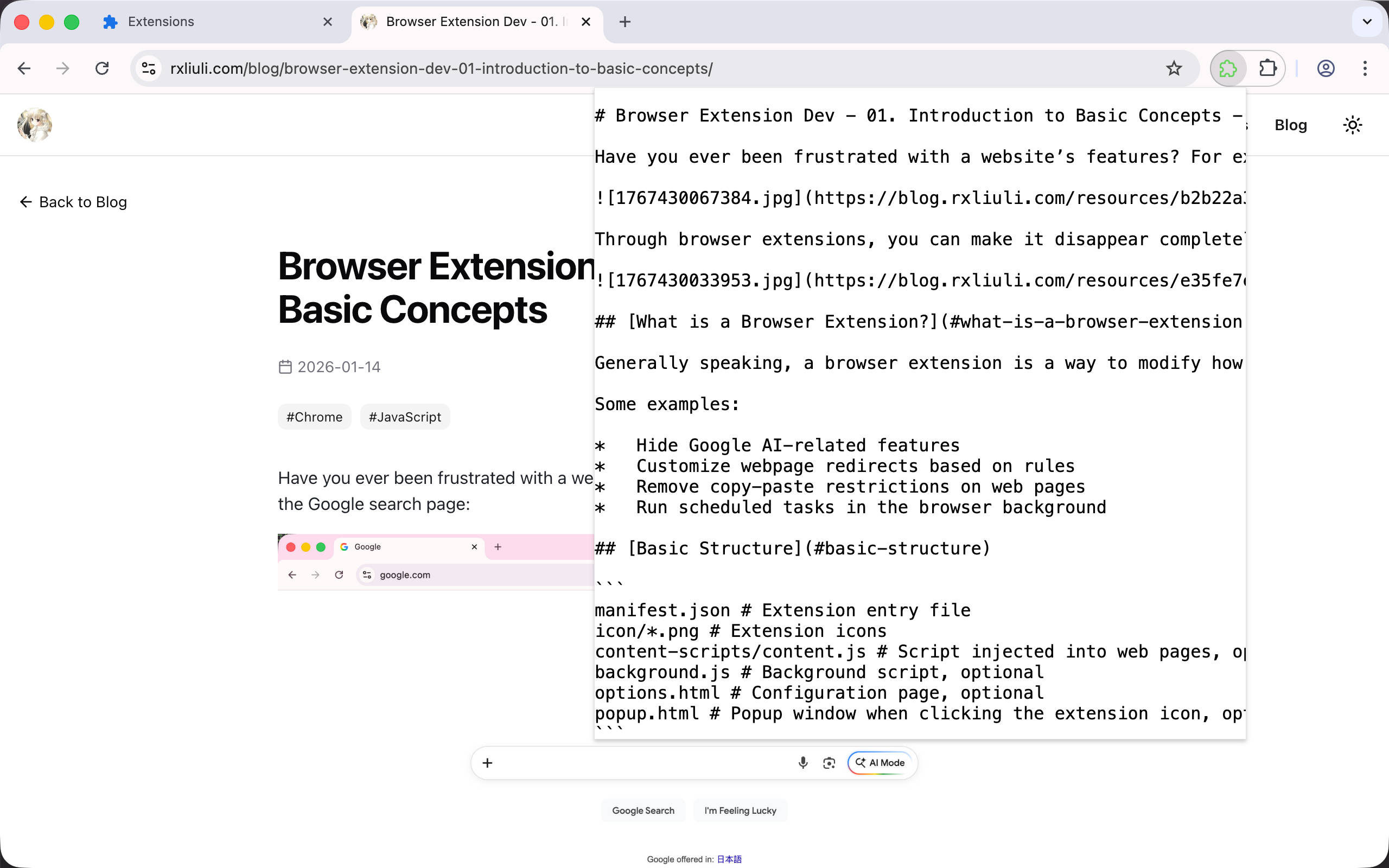
在上一章 Browser Extension Dev - 06. Inject Script on Demand 中,我们介绍了按需为网页注入脚本执行自定义的功能,还实现了一个简单的复制网页主要内容为 Markdown 的扩展。在这一章中,我们将继续实现一个 Popup 弹窗,用于显示页面主要内容转换得到的 Markdown,并支持在复制之前进行预览和编辑。
首先,需要明确 Popup 是什么?
之前我们已经接触过 Content Script 注入网页的 UI 和 Options 配置页面。Popup 类似于 Options 页面,独立运行,但权限相比 Background/Options 更加受限。通常而言,它和 Content Script UI 的应用场景非常接近,都是显示一些当前网页相关的内容,但它也有一些独有的适用场景:
Content Script UI 则有其他几个优势
接下来,让我们接着之前的实现继续完善吧。
参考 Chrome 官方文档 https://developer.chrome.com/docs/extensions/develop/ui/add-popup
现在面临一个问题:如何在 Popup 中获取页面的内容?
答案是无法直接获取,需要通过 Background Script 中转,大致流程如下:
Popup → Background → executeScript(inject.js) → 返回 markdown → Popup 显示
但是等等,scripting.executeScript 可以有返回值吗?当然可以,它支持同步和异步返回值,但返回值必须是可结构化克隆的。
参考 Chrome scripting API 关于 Promise 返回值的官方文档 https://developer.chrome.com/docs/extensions/reference/api/scripting#promises
首先添加一个 popup 页面,在 entrypoints/popup 下添加 index.html 和 main.ts
1 |
|
1 |
|
在浏览器中加载扩展之后,点击 action 可以看到弹窗出现了。
在实现通信部分之前,需要修改一下之前注入的 Inject Script,不再复制 Markdown 到剪切板,而是使用 return 返回给调用者。
1 |
|
下面开始实现 Popup 与 Background Script 的通信部分,由于 Chrome 原生的通信 API 使用起来非常痛苦,这里使用一个浅包装 @webext-core/messaging。
安装依赖
1 |
|
然后在 lib/messager.ts 中定义接口
1 |
|
然后在 Background Script 定义实现
1 |
|
最后在 Popup 中调用,出于简化考虑,这里直接使用 pre 渲染了 Markdown,我们将在下一步引入所见即所得的 Markdown 编辑器。
1 |
|
由于并未使用 react,所以这里直接使用一个 vanilla JS 实现的 markdown 编辑器 easymde。
还是先安装依赖。
1 |
|
然后在 Popup 中使用它。
1 |
|
现在就可以看到最终的效果了。
在这一章,我们介绍了 Popup 的应用场景、Popup 与 Background Script 的通信、以及从网页获取数据的功能与实现。在下一章,我们终于要发布插件了,我将演示如何将插件发布到 Chrome Web Store,以便让其他人也能使用开发的扩展。
如果有任何问题,欢迎加入 Discord 群组讨论。
https://discord.gg/VxbAqE7gj2
完整代码:https://github.com/rxliuli/browser-extension-dev-examples/tree/main/packages/07-popup-ui


























































































































